pytorch公式コード: https://github.com/lcy0604/EraseNet
論文: 2010.EraseNet: End-to-End Text Removal in the Wild network ディスク抽出コード: 0719
1. 画像文字除去効果
図 10 SCUT-EnsText 実データセットの削除
最初の列はテキストを含む元の画像、2 列目は削除されたラベル、残りの列はさまざまなアルゴリズムの削除効果 (この記事では pix2pix、scenetextEraser、EnsNet、EraseNet) です。

図 11合成的データセット内のテキストと画像の削除効果の比較

図12 インパンティング法との除去効果の比較

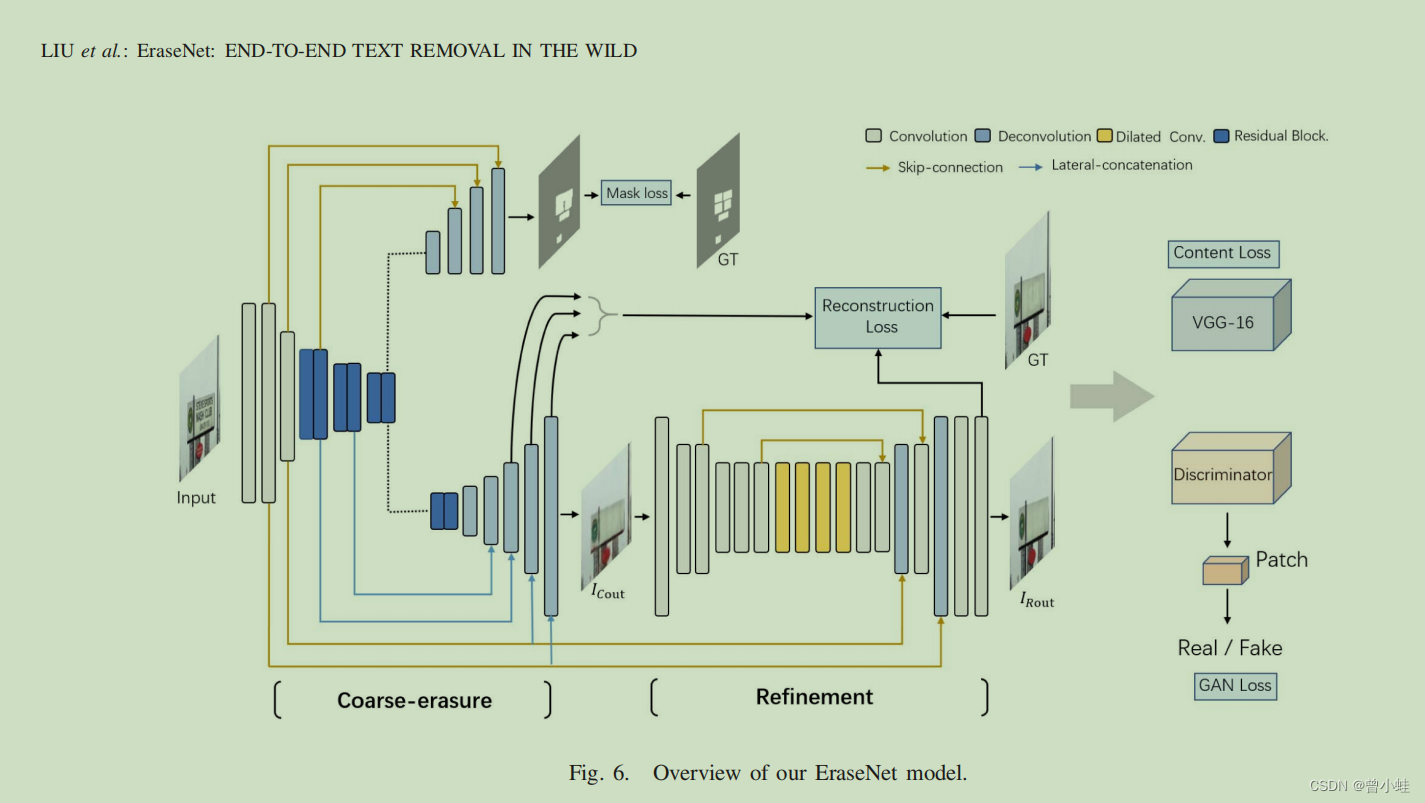
2. 手法の概要
このモデルは、2 段階の粗いから細かいまで (2 段階・粗いから細かいまでのジェネレータ ネットワーク)生成器ネットワークとローカル グローバル識別器鉴别器ネットワーク (ローカル - グローバル識別器ネットワーク) を設計します。(この論文では、著者は SN-GAN を改良し、テキスト領域を認識するためのアルゴリズム全体と統合された追加ヘッドとlocal-global SN-Patch-GAN 呼ばれるアーキテクチャを提案します。语义分割网络
同時に、外部の事前トレーニング済みVGG-16ネットワーク抽出機能の助けを借りて、生成された偽のサンプルとグラウンドトゥルースの間の高レベルのセマンティクスの違い (高レベルのセマンティクスの不一致) を監視するために使用されます。 8
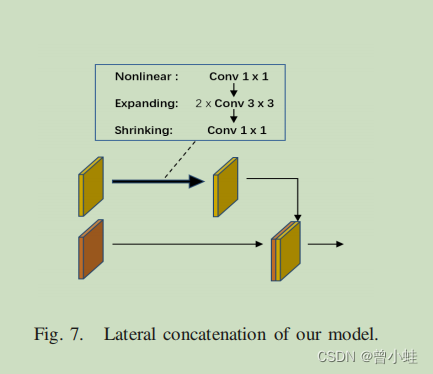
差別アーキテクチャ
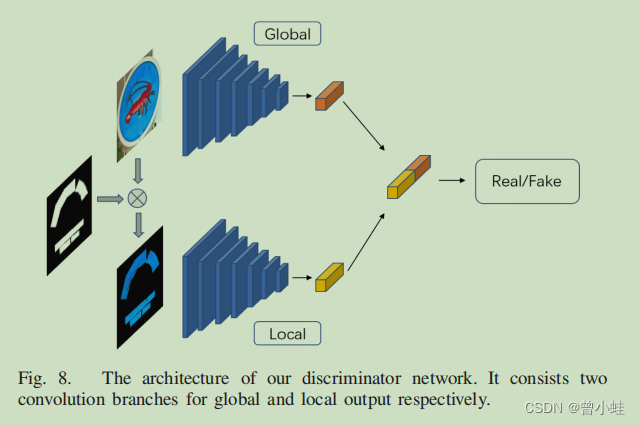
図 9 さまざまなアルゴリズムの効果の比較

トレーニングの詳細
单个NVIDIA 2080TI GPU、バッチサイズ = 4
使用
データセット
SCUT-EnsText: 華南理工大学によって提案および収集されました。
データセットを合成するには、2016 年にヘッダー コード ライブラリによって提案された自然画像内のテキスト ローカライゼーションのための合成データを参照してください。
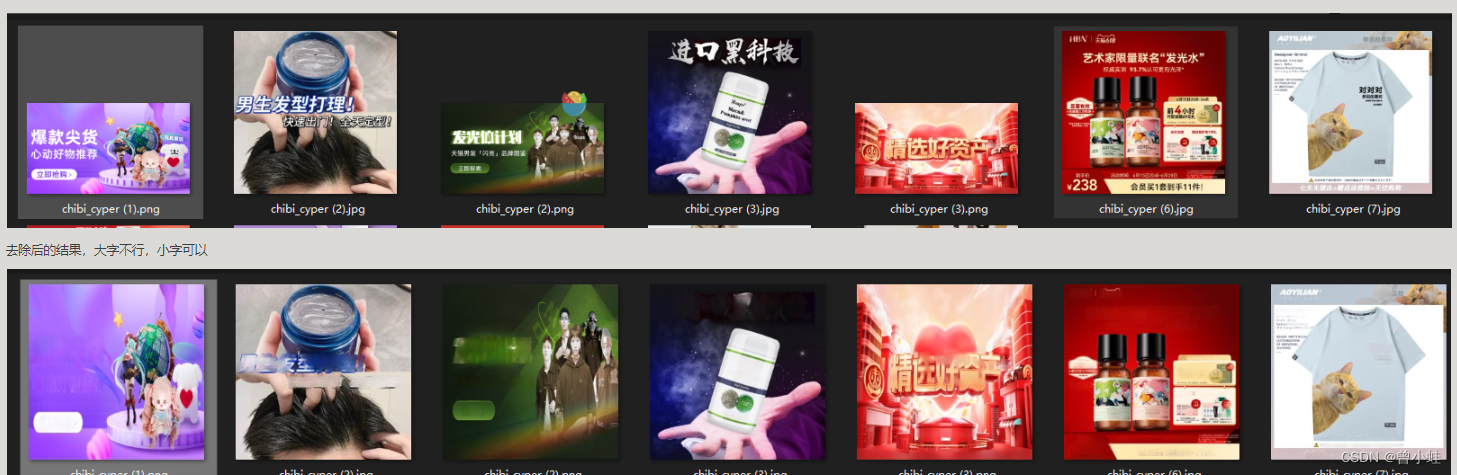
3. 現地での自己数据集実験結果
ショッピングマップの変換
推論コード
# -*- coding: utf-8 -*-
# @Time : 2023/7/6 20:36
# @Author : XyZeng
import os
import math
import argparse
import torch
import torch.nn as nn
import torch.backends.cudnn as cudnn
from PIL import Image
import numpy as np
from torch.autograd import Variable
from torchvision.utils import save_image
from data.dataloader import ErasingData,ImageTransform
from models.sa_gan import STRnet2
parser = argparse.ArgumentParser()
parser.add_argument('--numOfWorkers', type=int, default=0,
help='workers for dataloader')
parser.add_argument('--modelsSavePath', type=str, default='',
help='path for saving models')
parser.add_argument('--logPath', type=str,
default='')
parser.add_argument('--batchSize', type=int, default=16)
parser.add_argument('--loadSize', type=int, default=512,
help='image loading size')
parser.add_argument('--dataRoot', type=str,
default='./')
parser.add_argument('--pretrained',type=str, default='./model.pth', help='pretrained models for finetuning')
parser.add_argument('--savePath', type=str, default='./output')
args = parser.parse_args()
cuda = torch.cuda.is_available()
if cuda:
print('Cuda is available!')
cudnn.benchmark = True
def visual(image):
im =(image).transpose(1,2).transpose(2,3).detach().cpu().numpy()
Image.fromarray(im[0].astype(np.uint8)).show()
batchSize = args.batchSize
loadSize = (args.loadSize, args.loadSize)
dataRoot = args.dataRoot
savePath = args.savePath
# result_with_mask = savePath + 'WithMaskOutput/'
# result_straight = savePath + 'StrOuput/'
#import pdb;pdb.set_trace()
import torch.nn.functional as F
# if not os.path.exists(savePath):
os.makedirs(savePath,exist_ok=True)
# os.makedirs(result_with_mask,exist_ok=True)
# os.makedirs(savePath,exist_ok=True)
netG = STRnet2(3)
netG.load_state_dict(torch.load(args.pretrained))
#
if cuda:
netG = netG.cuda()
for param in netG.parameters():
param.requires_grad = False
print('OK!')
import time
start = time.time()
netG.eval()
ImgTrans=ImageTransform(args.loadSize)
def get_img_tensor(path):
img = Image.open(path)
# mask = Image.open(path)
ori_img_size = img.size
### for data augmentation
# Use Image.Resampling.NEAREST (0), Image.Resampling.LANCZOS (1), Image.Resampling.BILINEAR (2), Image.Resampling.BICUBIC (3), Image.Resampling.BOX (4) o
img=img.convert('RGB').resize((args.loadSize,args.loadSize) ,2)
inputImage = ImgTrans(img).unsqueeze(0)
# mask = ImgTrans(mask.convert('RGB'))
# inputImage = F.interpolate(inputImage, size=(512,512), mode='bilinear') # Adjust size to 115
print('inputImage',inputImage.size())
print('ori_img_size',ori_img_size)
return inputImage,ori_img_size
def torch_img_2_pil(gpu_tensor):
# 将数值范围从[0, 1]映射到[0, 255]
cpu_tensor = gpu_tensor.cpu().mul(255).add(0.5).clamp(0, 255)
# 将CPU上的Tensor转换为NumPy数组
numpy_array = cpu_tensor.squeeze().permute(1, 2, 0).to(torch.uint8).numpy()
# 将NumPy数组转换为PIL图像
pil_image = Image.fromarray(numpy_array)
return pil_image
if __name__ == '__main__':
# path=r'F:\code\23_0613_image_translate\EraseNet-master\example\all_images\118.jpg'
# print('path',path)
# inpur_dir=r'example\all_images' # 改为'./你需要转换的图片目录'
inpur_dir=r'F:\code\23_0613_image_translate\inpainting_datasets' # 改为'./你需要转换的图片目录'
for name in os.listdir(inpur_dir):
path=os.path.join(inpur_dir,name)
imgs,ori_img_size=get_img_tensor(path)
if cuda:
imgs = imgs.cuda()
# masks = masks.cuda()
'''
看论文喝源码能发现5个输出的对应
'''
out1, out2, out3, g_images,mm = netG(imgs)
g_image = g_images.data.cpu()
mm = mm.data.cpu()
# save_image(g_image_with_mask, result_with_mask+path[0])
dir,name=os.path.split(path)
out_path=os.path.join(savePath,name)
mask_path= os.path.join(savePath,name+'_mask.png')
# 将CPU上的Tensor转换为NumPy数组
'''
还原图片合适与大小
'''
numpy_array = g_image.numpy()
# 将NumPy数组转换为PIL图像
# visual(g_image)
# pil_image = Image.fromarray(numpy_array.squeeze(0).transpose((1, 2, 0)).astype('uint8'))
pil_image=torch_img_2_pil(g_image)
result_img = pil_image.resize(ori_img_size)
result_img.save(out_path)
#src=Image.open(path)
#src.save(mask_path)
save_image(g_image, out_path)
save_image(mm,mask_path)
# print(out_path,mask_path)
# break