OpenAI が GPT-4 アーキテクチャを非公開にしているのは、人間に対する何らかの実存的リスクのためではなく、構築したものが再現可能であるためです。実際、Google、Meta、Anthropic、Inflection、Character、Tencent、ByteDance、Baidu などの企業が、短期的には GPT-4 と同等かそれ以上に強力なモデルを開発すると予想されます。
誤解しないでください。OpenAI には驚くべきエンジニアリング能力があり、彼らが構築したものは素晴らしいものですが、彼らが見つけたソリューションは魔法ではありません。これは、多くの複雑なトレードオフを伴う洗練されたソリューションです。スケールアップは戦いの一部にすぎません。OpenAI の最も永続的な競争上の利点は、最も実用的なアプリケーションと優れたエンジニアリング人材を擁し、将来のモデルでも他の企業を上回り続けることができることです。
私たちは複数のソースから GPT-4 に関する豊富な情報を収集したので、今日はそれを共有したいと思います。これには、モデル アーキテクチャ、トレーニング インフラストラクチャ、推論インフラストラクチャ、パラメータの数、トレーニング データセットの構成、トークンの数、レイヤーの数、並列戦略、マルチモーダル ビジョンの適応、さまざまなエンジニアリング トレードオフの背後にある思考プロセス、実装された独自のテクニック、およびそれらがどのように一部を軽減するかが含まれます。巨大なモデルの推論に関連する最大のボトルネックについて説明します。
GPT-4 の最も興味深い点は、GPT-4 が特定のアーキテクチャ上の決定を行った理由を理解することです。
さらに、A100 での GPT-4 のトレーニングと推論のコストと、それが次世代モデル アーキテクチャで H100 に合わせてどのように拡張されるかについて概要を説明します。
まず、問題文を見てみましょう。OpenAIはGPT-3から4まで100倍に拡張したいと考えているが、問題はコストだ。Dense Transformer モデルはそれ以上スケールされません。Dense Transformer は、OpenAI GPT-3、Google PaLM、Meta LLAMA、TII Falcon、MosaicML MPT およびその他のモデルで使用されるモデル アーキテクチャです。これと同じアーキテクチャを使用して LLM をトレーニングしている企業の名前を簡単に 50 社以上挙げることができます。これは素晴らしいアーキテクチャですが、スケーリングに関しては欠陥があります。
GPT-4 のリリース前に、トレーニング コストと今後の AI の壁との関係について議論しました。そこでは、GPT-4 アーキテクチャに対する OpenAI の高レベルのアプローチと、さまざまな既存モデルのトレーニング コストを明らかにします。
過去 6 か月間で、トレーニングのコストは無関係であることがわかりました。
確かに、モデルのトレーニングに数千万ドル、さらには数億ドルものコンピューティング時間を費やすのは、一見するとおかしなことのように思えるかもしれませんが、これらの企業にとって、それは取るに足らない出費です。これは実際には、スケーリングに関して常により良い結果を生み出す固定の設備投資です。唯一の制限要因は、人間がフィードバックを得てアーキテクチャを変更できるタイムスケールまで計算をスケーリングすることです。
今後数年間で、Google、Meta、OpenAI/Microsoft などの複数の企業が、1,000 億ドル以上の価値があるスーパーコンピューターでモデルをトレーニングする予定です。メタは「メタバース」で年間160億ドルを浪費し、グーグルはさまざまなプロジェクトで年間100億ドルを無駄にし、アマゾンはアレクサで500億ドル以上を失い、暗号通貨は価値のないものに1000億ドル以上を浪費している。
これらの企業と社会全体は、単一の巨大なモデルを訓練できるスーパーコンピューターの開発に 1,000 億ドル以上を費やすことができ、またそうするつもりです。これらの巨大なモデルは、さまざまな方法で製品になる可能性があります。この作業は複数の国や企業にまたがって複製される予定です。これは新たな宇宙開発競争だ。過去の無駄とは異なり、今日の AI には、人間のアシスタントや自律エージェントから短期間で得られる具体的な価値があります。
AI のスケーリングにおけるより重要な問題は推論です。
目標は、トレーニングの計算を推論の計算から分離することです。これが、導入されるモデルに関係なく、有意義なトレーニングがチンチラの最高のものを超える理由です。これが、スパース モデル アーキテクチャが使用される理由であり、推論中にすべてのパラメータをアクティブにする必要はありません。
本当の課題は、これらのモデルをユーザーやエージェントに拡張するにはコストがかかりすぎることです。推論のコストはトレーニングのコストの何倍もかかります。これは、モデル アーキテクチャとインフラストラクチャに関する OpenAI の革新的な目標です。
大規模なモデルでの推論は多変量問題であり、高密度モデルの場合、モデルのサイズは致命的です。ここではエッジ コンピューティングに関連する問題について詳しく説明しましたが、データセンターの問題点も非常に似ています。簡単に言うと、大規模な言語モデルで特定のレベルのスループットを達成するのに十分なメモリ帯域幅がデバイスに備わることはありません。帯域幅が十分な場合でも、エッジ コンピューティング デバイス上のハードウェア コンピューティング リソースの使用率は非常に低くなります。
データセンターやクラウドでは、利用率が非常に重要です。Nvidia がその優れたソフトウェアで賞賛される理由の半分は、Nvidia が GPU の寿命を通じて、チップ内、チップ間、メモリ間でデータをよりインテリジェントに移動することにより、低レベルのソフトウェアを継続的に更新し、使用率を高めるためです。フロップス。
現在のほとんどのユースケースでは、LLM 推論の目標はリアルタイム アシスタントとして実行することです。つまり、ユーザーが実際に使用するのに十分な高いスループットを達成する必要があります。平均的な人間の読書速度は 1 分あたり約 250 ワードですが、1 分あたり 1,000 ワードに達する人もいます。これは、すべてのケースをカバーするには、少なくとも 1 秒あたり 8.33 トークンを出力する必要があることを意味しますが、33.33 トークン/秒に近づく必要があります。
メモリ帯域幅の要件を考慮すると、最新の Nvidia H100 GPU サーバーでは、メガパラメータの高密度モデルは数学的にこの種のスループットを達成できません。
生成されたすべてのトークンでは、すべてのパラメーターをメモリからチップにロードする必要があります。生成されたトークンはプロンプトに入力され、次のトークンが生成されます。さらに、アテンション メカニズムの KV キャッシュをストリーミングするには、追加の帯域幅が必要です。
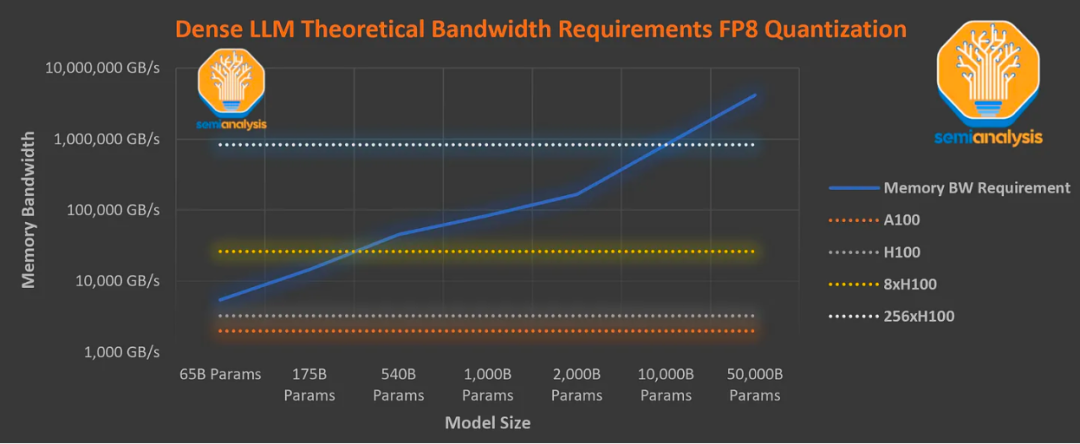
このグラフは、各操作を融合できないこと、アテンション メカニズムに必要なメモリ帯域幅、およびハードウェア オーバーヘッドにより、効率がパラメータ読み取りと同等であると仮定しています。実際、Nvidia の FasterTransformer ライブラリのような「最適化された」ライブラリを使用しても、全体的なオーバーヘッドは大きくなります。
上のグラフは、単一ユーザーにサービスを提供するのに十分な高いスループットを達成するために LLM を推論するために必要なメモリ帯域幅を示しています。これは、8 つの H100 を使用しても、1 メガパラメータの高密度モデルを毎秒 33.33 トークンで提供することは不可能であることを示しています。
さらに、1 秒あたり 20 トークンで 8 つの H100 を使用した場合の FLOPS 使用率は依然として 5% 未満であり、結果として推論コストが非常に高くなります。実際、8 方向テンソル並列処理に基づく現在の H100 システムには、約 3,000 億の順方向パラメーターの推論制限があります。
しかし、OpenAI は A100 を使用して人間の読み取り速度を実現し、1 兆を超えるモデル パラメーターを使用し、1,000 トークンあたりわずか 0.06 ドルという低価格で広く入手できるようにしています。これは、それがスパースであるため、つまり、すべてのパラメータが使用されるわけではないためです。
GPT-4 のモデル アーキテクチャ、トレーニング インフラストラクチャ、推論インフラストラクチャ、パラメーターの数、トレーニング データセットの構成、トークンの数、レイヤーの数、並列戦略、マルチモーダル ビジュアル エンコーダー、さまざまなエンジニアリング トレードオフの背後にある思考プロセス、実装固有のテクニックとそれらの軽減方法についてこれは、大規模なモデルの推論に関連する最大のボトルネックの一部です。
#1 GPT-4 モデルのアーキテクチャ
GPT-4 は GPT-3 の 10 倍以上の大きさです。私たちが知っている限り、GPT-3 には約 1 兆 8,000 億のパラメーターがあり、120 レイヤーにまたがっていますが、GPT-3 には約 1,750 億のパラメーターがあります。
OpenAI は、専門家混合 (MoE) モデルを使用してコストを管理しました。MoE に詳しくない場合は、一般化された GPT-4 アーキテクチャとトレーニング コストに関する 6 か月前の記事をお読みください。
さらに、OpenAI はモデルに 16 人のエキスパートを使用しており、各エキスパートの MLP パラメータは約 1,110 億です。各フォワードパスには 2 人の専門家がルーティングします。
文献では、各トークンをルーティングするエキスパートを選択するための高度なルーティング アルゴリズムについて説明されていますが、OpenAI の現在の GPT-4 モデルのルーティング アルゴリズムはかなり単純であると言われています。
さらに、アテンション メカニズムは約 550 億のパラメータを共有します。
推論の各前方パス (1 つのトークンの生成) では、約 2,800 億のパラメーターと 560 TFLOPS のみが使用されます。これは、純粋に高密度のモデルの場合、フォワード パスごとに最大 180 万のパラメーターと 3700 TFLOPS が必要となるのとは対照的です。
#2 データ統合
OpenAI は、約 13 兆のトークンで GPT-4 をトレーニングしました。RefinedWeb の CommonCrawl に約 5 メガバイトの高品質トークンが含まれていることを考慮すると、これは理にかなっています。参考までに、Deepmind のチンチラ モデルと Google の PaLM モデルは、トレーニングにそれぞれ約 1.4 メガ トークンと 0.78 メガ トークンを使用しました。PaLM 2 は約 5 兆個のトークンでトレーニングされたとも言われています。
このデータセットには 13 兆個の一意のトークンは含まれていません。対照的に、このデータセットには高品質のトークンが不足しているため、複数のエポックが含まれています。テキスト データの場合は 2 エポック、コード データの場合は 4 エポックがあります。興味深いことに、これはチンチラにとって最適なオプションには程遠く、モデルを 2 倍の数のトークンでトレーニングする必要があることがわかります。これは、ウェブ上で簡単に入手できるトークンが不足していることを示しています。高品質のテキスト トークンは 1000 倍あり、さらに多くのオーディオおよびビジュアル トークンがありますが、それらを取得するのは Web スクレイピングほど簡単ではありません。
彼らには、Scale Al および内部からの数百万行の命令微調整データがありますが、残念なことに、それらに関する強化学習データはあまり見つかりません。
事前トレーニング段階のコンテキスト長は 8k です。32k トークン長バージョンは、事前トレーニングされた 8k に加えて微調整されています。
バッチ サイズは数日かけて徐々に増加しましたが、最終的に OpenAI は 6,000 万のバッチ サイズを使用しました。もちろん、すべてのエキスパートがすべてのトークンを参照できるわけではないため、実際にはエキスパートごとのバッチあたり 750 万トークンにすぎません。
#3 並行戦略
すべての A100 GPU での並列化戦略は非常に重要です。8 方向のテンソル並列処理が使用されているのは、これが NVLink の制限であるためです。また、15 方向のパイプラインを並行して使用していると聞いています。計算時間とデータ通信の観点から、理論的には並列パイプラインの数が多すぎますが、メモリ容量によって制限されるのであれば、それは理にかなっています。
純粋なパイプライン + テンソル並列処理では、各 GPU はパラメータだけで約 30GB (FP16) を必要とします。KV キャッシュとオーバーヘッドを追加すると、OpenAI の GPU のほとんどが 40GB A100 であることは理論的には理にかなっています。おそらくZeRo Phase 1を使用したと思われます。おそらく、ブロックレベルの FSDP または混合共有データ並列処理が使用されていたと思われます。
なぜフルモデルの FSDP を使用しなかったのかというと、通信のオーバーヘッドが高かったためかもしれません。OpenAI のほとんどのノード間には高速ネットワーク接続がありますが、すべてのノードが接続できるわけではありません。少なくとも一部のクラスターでは、クラスター間の帯域幅が他のクラスターよりもはるかに低いと考えられます。
このような高いパイプライン並列処理で、バッチごとに巨大なバブルをどのように回避できるのか、私たちは理解できません。おそらくオーバーヘッドをカバーしているだけでしょう。
#4 トレーニングコスト
OpenAI は、GPT-4 でのトレーニングに約 25,000 個の A100 チップを使用し、90 ~ 100 日間で約 32% ~ 36% の MFU (平均関数使用率) を達成しました。この極端に低い使用率の原因の 1 つは、チェックポイントからの再起動を必要とする障害の数が多く、前述のバブルにより非常にコストがかかることです。
もう 1 つの理由は、非常に多くの GPU にわたるグローバルな削減には非常にコストがかかることです。私たちの推測が正しければ、クラスターは実際には、クラスター間の非常に薄いネットワーク接続、つまりクラスターの異なる部分間の 800G/1.6T ノンブロッキング接続を備えた多くの小さなクラスターで構成されていますが、これらの部分は 200G/1.6T でのみ接続できます。 400Gの速度。
クラウド上に 1 時間あたり約 1 ドルの A100 チップがある場合、そのトレーニングだけで約 6,300 万ドルの費用がかかります。これには、すべての実験、失敗したトレーニングの実行、およびデータ収集、強化学習、人件費などのその他のコストは考慮されていません。これらの要因により、実際のコストはさらに高くなります。また、チップ/ネットワーク/データセンターを購入し、設備投資を負担してリースしてくれる人が必要であることも意味します。
現在、事前トレーニングは、約 8,192 個の H100 チップを使用し、1 時間あたり 2 ドル、約 2,150 万ドルの費用で約 55 日で実行できます。今年末までに 9 社がさらに多くの H100 チップを搭載すると考えられることに注意してください。これらすべての企業が 1 回のトレーニングの実行にすべてを使用するわけではありませんが、使用する企業ははるかに大規模なモデルを使用することになります。Meta は年末までに 100,000 個を超える H100 チップを保有する予定ですが、それらのチップのかなりの数が推論のためにデータ センター全体に分散される予定です。最大の単一クラスターは依然として 25,000 個を超える H100 チップになります。
今年末までに、多くの企業は GPT-4 の規模でモデルをトレーニングするのに十分なコンピューティング リソースを手に入れるでしょう。
#5 MoE のトレードオフ
MoE は、推論中にパラメータの数を増やしながらパラメータの数を減らす良い方法です。十分な高品質のトークン カードを取得するのは非常に難しいため、トレーニング トークンごとにより多くの情報をエンコードする必要があります。OpenAI が本当にチンチラの最適化を達成しようとした場合、トレーニングでは現在の 2 倍のトークンを使用する必要があります。
それでも、OpenAI にはいくつかのトレードオフがあります。たとえば、トークン生成ごとにモデルのすべての部分が使用されるわけではないため、推論中に MoE を扱うのは非常に困難です。これは、ユーザーにサービスを提供している間、一部の部分がアイドル状態にあり、他の部分が使用されている可能性があることを意味します。これは使用率に大きな悪影響を及ぼします。
研究者らは、64 ~ 128 人の専門家を使用した方が、16 人の専門家を使用した場合よりも損失が少ないことを示していますが、これは純粋な研究です。専門家の数を減らす理由はいくつかあります。OpenAI が 16 人の専門家を選んだ理由の 1 つは、より多くの専門家が多くのタスクを一般化するのが難しいためです。また、より多くの専門家を使用して収束を達成することはより困難になる可能性があります。このような大規模なトレーニングの実行において、OpenAI は専門家の数をより控えめにすることを選択しました。
さらに、専門家の数を減らすことは、推論インフラストラクチャにも役立ちます。専門家による混合推論アーキテクチャを採用する場合には、さまざまな困難なトレードオフが存在します。OpenAI が直面したトレードオフと OpenAI が行った選択を検討する前に、LLM 推論の基本的なトレードオフから始めます。
#6 推論のトレードオフ
ちなみに、始める前に、私たちが話を聞いたすべての LLM 企業は、Nvidia の FasterTransformer 推論ライブラリはかなり悪く、TensorRT はさらに悪いと考えていたことを指摘しておきたいと思います。Nvidia のテンプレートを使用したり変更したりできないという欠点は、独自のソリューションを最初から作成する必要があることを意味します。Nvidia で働いている場合は、この記事を読んだ後、できるだけ早くこの問題を修正する必要があります。そうしないと、サードパーティのハードウェア サポートをより簡単に追加できるように、デフォルトの選択がオープン ツールに変更されます。モデルの大きな波が来ています。推論にソフトウェアの利点がなく、依然としてカーネルを手書きする必要がある場合、AMD の MI300 やその他のハードウェアの市場が大きくなるでしょう。
大規模な言語モデルの推論では、バッチ サイズ (サービスを同時に提供するユーザーの数) と使用されるチップの数の間に 3 つの主なトレードオフが発生します。
-
レイテンシー - モデルは適切なレイテンシーで応答する必要があります。人々は、出力がチャット アプリケーションに流れ始めるまで数秒待つことを望んでいません。プリロード (入力トークン) とデコード (出力トークン) の処理には異なる時間がかかります。
-
スループット - モデルは 1 秒あたり特定の数のトークンを出力する必要があります。人間が使用するには 1 秒あたり約 30 トークンが必要です。他のさまざまな用途では、スループットが低くても高くても許容されます。
-
使用率 - モデルを実行するハードウェアは高い使用率を達成する必要があります。そうしないと、コストが法外に高くなります。待ち時間が長く、スループットが低い、より多くのユーザー要求をグループ化することで使用率を高めることは可能ですが、これにより難易度が高くなります。
LLM の推論は、メモリ帯域幅と計算という 2 つの主要な要素のバランスを取ることにあります。最も単純化して言えば、各パラメータを読み取る必要があり、それに関連付けられるのは 2 FLOP です。その結果、ほとんどのチップ (たとえば、H100 SXM チップのメモリ帯域幅は 3 TB/s しかありませんが、FP8 のメモリ帯域幅は 2,000 TFLOP/s) の比率は、バッチ サイズ 1 での推論において完全にアンバランスになります。バッチ サイズ 1 で 1 人のユーザーのみが処理される場合、トークン生成ごとに必要なメモリ帯域幅が推論時間の大半を占めます。計算時間はほぼゼロです。大規模な言語モデルを複数のユーザーに効率的に拡張するには、バッチ サイズが 4 を超える必要があります。複数のユーザーがパラメータ読み取りのコストを共有します。たとえば、バッチ サイズが 256 または 512 の場合、メモリ読み取りバイトあたり 512 FLOP/s または 1024 FLOP/s になります。
この比率は、メモリ帯域幅と H100 の FLOPS の比率に近くなります。これにより、使用率が向上しますが、遅延が長くなります。
多くの人は、大規模なモデルでは推論に複数のチップが必要であり、メモリ容量が大きければ少ないチップに収まるという事実から、メモリ容量が LLM 推論の主要なボトルネックであると考えていますが、実際には、必要以上に多くのチップを使用する方が良いのです。チップの容量を増やすことで、レイテンシが低くなり、スループットが向上し、より大きなバッチ サイズを使用して使用率をますます高めることができます。
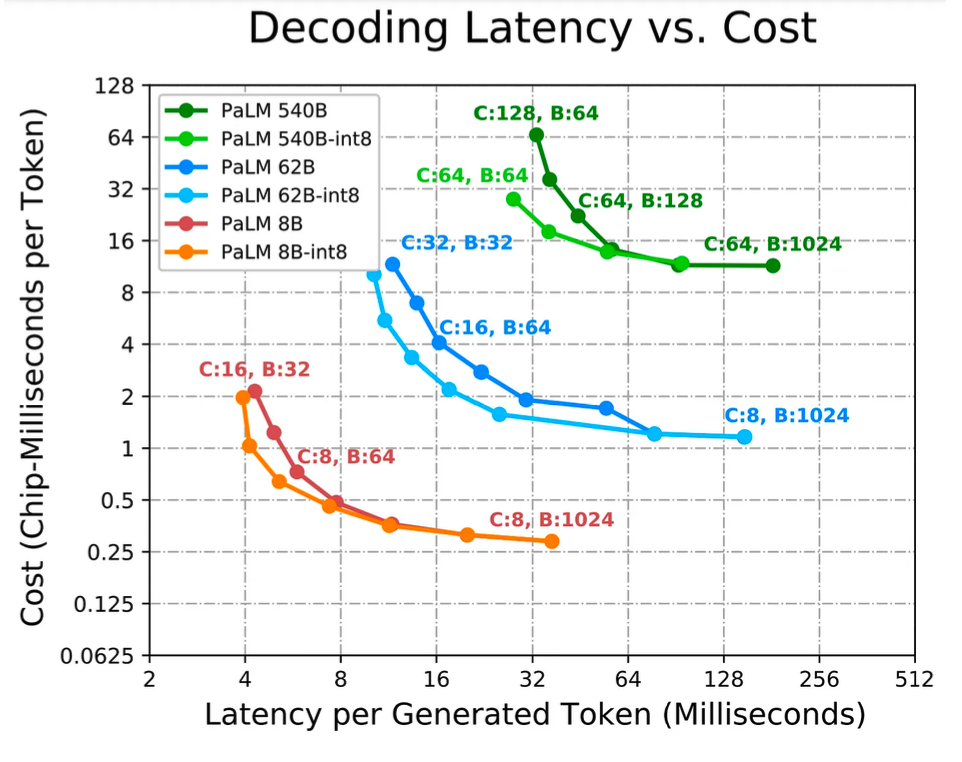
Google は、PaLM 推論論文の中でこれらのトレードオフを実証しています。ただし、これは GPT-4 のような疎モデルではなく、PaLM のような密モデルを対象としたものであることに注意してください。
アプリケーションが最小のレイテンシーを必要とする場合、より多くのチップを適用し、モデルをできるだけ多くの部分に分割する必要があります。一般に、バッチ サイズが小さいほどレイテンシーは低くなりますが、バッチ サイズが小さいと使用率も低下し、その結果、トークンあたりの総コスト (チップ秒数またはドル単位) が高くなります。アプリケーションがオフライン推論を必要とし、遅延が問題にならない場合、主な目標はチップあたりのスループットを最大化する (つまり、トークンあたりの総コストを最小限に抑える) ことです。
通常、バッチが大きくなると使用率が向上するため、バッチ サイズを増やすことが最も効率的ですが、小さいバッチ サイズでは効率的でない特定のパーティション化戦略は、バッチ サイズが大きくなると効率的になるためです。より多くのチップとより大きなバッチ サイズを使用すると、使用率が増加するためコストが安くなりますが、これにより、ネットワーク時間という 3 番目の変数も発生します。チップ間でモデルを分割する特定の方法はレイテンシ効率が高くなりますが、使用率とトレードオフになります。
メモリ時間と非注意的計算時間はどちらもモデルのサイズに比例し、チップの数に反比例します。ただし、特定のパーティション レイアウトでは、チップ間通信に必要な時間の減少が遅くなる (またはまったく減少しない) ため、チップの数が増加するにつれてその重要性が増し、ボトルネックがますます重要になります。今日はこれについて簡単に説明するだけですが、バッチ サイズとシーケンスの長さが大きくなるにつれて、KV キャッシュのメモリ要件が大幅に増加することに注意してください。アプリケーションがより長いアテンションコンテキストを含むテキストを生成する必要がある場合、推論時間は大幅に増加します。
マルチヘッド アテンションを備えた 500B+ モデルの場合、アテンション KV キャッシュは大きくなります。バッチ サイズ 512、コンテキスト長 2048 の場合、KV キャッシュは合計 3TB に達します。これは、モデル パラメーター サイズの 3 倍です。オンチップ メモリは、この KV キャッシュをオフチップ メモリからメモリにロードする必要があり、この期間中、チップのコンピューティング コアは基本的にアイドル状態になります。シーケンスの長さが長いと、メモリ帯域幅とメモリ容量に特に悪影響を及ぼします。OpenAI の 16k シーケンス長の GPT 3.5 ターボと 32k シーケンス長の GPT 4 は、メモリの制約により大きなバッチ サイズを使用できないため、コストがはるかに高くなります。
バッチ サイズが小さくなると、ハードウェアの使用率が低くなります。また、シーケンス長が増加すると、KV キャッシュも大きくなります。KV キャッシュはユーザー間で共有できないため、個別のメモリ読み取りが必要となり、メモリ帯域幅がさらにボトルネックになります。
#7 GPT-4 の推論のトレードオフとインフラストラクチャ
GPT-4 推論では上記のすべてが困難ですが、モデル アーキテクチャでは専門家混合 (MoE) が採用されており、これによりまったく新しい一連の困難が生じます。トークンによって生成された各転送パスは、異なるエキスパートのセットにルーティングできます。これにより、大きなバッチ サイズでのスループット、レイテンシ、使用率の間で達成されるトレードオフに問題が生じます。
OpenAI の GPT-4 には 16 人のエキスパートがおり、各フォワード パスに 2 人のエキスパートがいます。これは、バッチ サイズが 8 の場合、各エキスパートが読み取るパラメータはバッチ サイズ 1 のみである可能性があることを意味します。さらに悪いことに、1 人のエキスパートのバッチ サイズが 8 である一方で、他のエキスパートは 4、1、または 0 である可能性があります。トークンが生成されるたびに、ルーティング アルゴリズムは別の方向にフォワード パスを送信するため、トークン間の遅延が発生し、エキスパート バッチ サイズに大きな差異が生じます。OpenAI が少数の専門家を選んだ主な理由の 1 つは、推論インフラストラクチャです。より多くの専門家を選んだ場合、メモリ帯域幅が推論のボトルネックとなるでしょう。
OpenAI は、推論クラスターで定期的にバッチ サイズ 4k+ に達します。これは、エキスパート間で最適な負荷分散を行ったとしても、エキスパートのバッチ サイズはわずか 500 程度であることを意味します。これを実現するには、非常に大量の使用量が必要です。OpenAI は 128 個の GPU のクラスターで推論を実行することがわかりました。これらのクラスターは、複数のデータセンターおよび地理的な場所に複数存在します。推論は 8 方向のテンソル並列処理と 16 方向のパイプライン並列処理で実行されます。8 つの GPU で構成される各ノードのパラメーターは約 130B のみです。つまり、FP16 モードでは GPU あたり 30GB 未満、FP8/int8 モードでは 15GB 未満です。これにより、すべてのバッチの KV キャッシュ サイズが大きすぎない限り、推論を 40 GB A100 チップで実行できるようになります。
さまざまなエキスパートを含む単一のレイヤーは、異なるノードに分割されません。これは、ネットワーク トラフィックが不規則になりすぎ、トークン生成ごとに KV キャッシュを再計算するのにコストがかかりすぎるためです。MoE モデルと条件付きルーティングを将来拡張する場合、KV キャッシュのルーティングをどのように処理するかが最大の課題です。
モデルには 120 のレイヤーがあるため、15 の異なるノードに均等に分散するのは簡単ですが、最初のノードはデータのロードと埋め込みを行う必要があるため、推論クラスターのマスター ノードに配置するレイヤーの数を減らすことには意味があります。さらに、後で説明する推論の推測的な解読に関するいくつかの噂を聞いていますが、それらを信じるべきかどうかはわかりません。これは、マスターノードに含まれるレイヤーを少なくする必要がある理由も説明します。
#8 GPT-4の推論コスト
175B パラメータを持つ Davinchi モデルと比較すると、GPT-4 は 3 倍高価ですが、フィードフォワード パラメータは 1.6 倍しか増加しません。これは主に、GPT-4 では大規模なクラスターが必要であり、使用率が低いためです。
GPT-4 8k シーケンス長ポイントを推論するための 128 個の A100 については 1k トークンあたりのコストが 0.0049 セント、128 個の H100 については 1k トークンあたり 0.0021 セントであると考えられます。
高い使用率を想定し、バッチ サイズを高く保つことに注目してください。OpenAI が十分に活用されていないことがあるのは明らかなので、これは間違った仮定である可能性があります。OpenAI が谷期にクラスターをシャットダウンし、チェックポイントから小規模なテスト モデルでのトレーニングを再開するようにそれらのノードを再スケジュールすることを想定して、さまざまな新しい手法を実験しました。これは推論コストの削減に役立ちます。OpenAI がそうしていなかったら、その使用率は低くなり、コストの見積もりは 2 倍以上になっていたでしょう。
#9 マルチクエリの注意
MQA は他の企業も使用している技術ですが、OpenAI も使用していることを指摘しておきます。簡単に言うと、必要なヘッダーが 1 つだけなので、KV キャッシュのメモリ容量を大幅に削減できます。それでも、シーケンス長 32k の GPT-4 は 40GB A100 チップ上では実行できませんし、シーケンス長 8k の GPT-4 は最大バッチ サイズに制限があります。MQA がなければ、8k シーケンス長の GPT-4 の最大バッチ サイズは非常に制限され、経済的に実行できなくなります。
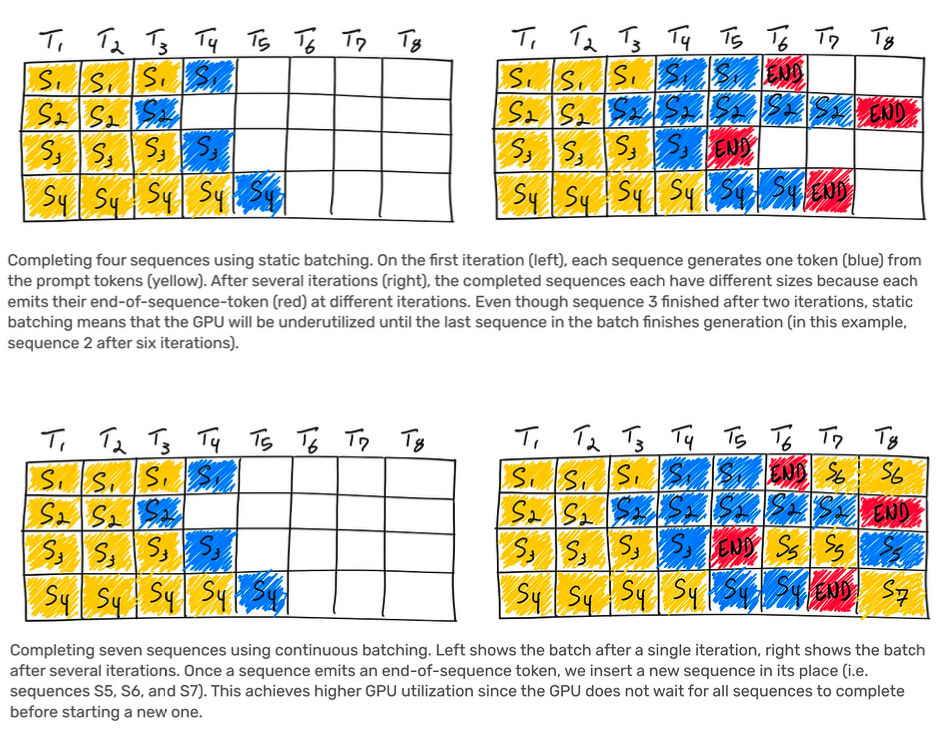
#10 連続バッチ処理
OpenAI は、可変バッチ サイズと連続バッチ処理を実装します。これにより、レイテンシーをある程度まで最大化でき、推論コストが最適化されます。この概念を初めて理解する場合は、AnyScale によるこの記事を読む価値があります。
#11 解決策の推測について
いくつかの信頼できる情報源から、OpenAI は GPT-4 推論で推測デコーディングを使用していると聞きました。それを完全に信じているかどうかはわかりません。トークン間のレイテンシの一般的な変動と、単純な取得タスクを実行する場合とより複雑なタスクを実行する場合の違いは、これが可能であることを示唆しているように見えますが、変数が多すぎて確信を持てません。念のため、ここでは「セグメント化された推測デコーディングを使用した LLM 推論の高速化」のテキストの一部を使用し、若干の変更/説明を追加します。
通常、LLM の使用には 2 つのフェーズがあります。1 つ目は事前入力ステージで、プロンプト テキストをモデルに渡して、最初の出力の KV キャッシュとロジット (可能なトークン出力の確率分布) を生成します。通常、ヒント テキスト全体を並行して処理できるため、この段階は高速です。
第 2 段階はデコードです。出力ログからトークンが選択され、モデルにフィードバックされて次のトークンのログが生成されます。必要な数のトークンが生成されるまで、このプロセスを繰り返します。デコードは逐次的に実行する必要があり、単一のトークンを生成するたびに重みが計算ユニットを介してストリーミングされるため、ミニバッチで実行する場合の第 2 段階の演算強度 (つまり、計算の FLOP / メモリ帯域幅のバイト数) は非常に低くなります。
したがって、デコードは通常、自己回帰生成で最もコストがかかる部分です。OpenAI の API 呼び出しでは、入力トークンが出力トークンよりもはるかに安価になるのはこのためです。
推測デコードの基本的な考え方は、より小型で高速なドラフト モデルを使用して複数のトークンを事前デコードし、それらをバッチとして Oracle モデルにフィードすることです。ドラフト モデルが予測したトークンが正しい場合、つまりより大きなモデルが一致する場合、複数のトークンを 1 つのバッチでデコードでき、トークンごとにかなりのメモリ帯域幅と時間が節約されます。
ただし、より大きなモデルがドラフト モデルによって予測されたトークンを拒否した場合、残りのバッチは破棄され、アルゴリズムは自然に標準のトークンごとのデコードに戻ります。推測デコードには、元の分布からサンプリングするための拒否サンプリング スキームが伴う場合もあります。これは、帯域幅がボトルネックとなる小規模なバッチ設定でのみ役立つことに注意してください。
推測デコードでは、計算と帯域幅がトレードオフになります。推測デコードは、2 つの主な理由からパフォーマンス最適化の対象となります。まず、モデルの品質はまったく低下しません。第 2 に、そのパフォーマンスはシーケンシャル実行をパラレル実行に変換することで得られるため、他のメソッドとは通常関係のない利点があります。
現在の推測方法では、バッチの単一シーケンスを予測します。ただし、これは、大きなバッチ サイズまたは低ドラフト モデルの位置合わせでは適切に拡張できません。直観的には、2 つのモデルが連続する長いシーケンスに一致する確率は指数関数的に減少します。これは、演算強度がスケールアップするにつれて、復号を推測することに対する報酬が急速に減少することを意味します。
OpenAI が推測デコードを使用する場合、おそらく約 4 つのトークンのシーケンスに対してのみ使用されると考えられます。ちなみに、品質を下げるという GPT-4 の陰謀は、おそらく、推測デコード モデルからのより低い確率のシーケンスをオラクル モデルに受け入れさせたからにすぎないと思われます。もう 1 つの注意点は、Google がシーケンス全体をユーザーに送信する前にシーケンスの生成が完了するのを待っていたため、Bard が推測によるデコードを使用したのではないかという憶測がありますが、私たちはこの推測が真実であるとは考えていません。
#12 視覚的なマルチモダリティについて
視覚的なマルチモーダル機能は、少なくとも主要な研究と比較して、GPT-4 の最も印象に残らない部分です。確かに、マルチモーダル LLM の研究を商業化した企業はまだありません。
これは、テキスト エンコーダーとは別の独立したビジュアル エンコーダーですが、クロスアテンションを備えています。アーキテクチャはFlamingoに似ていると聞きました。これにより、GPT-4 の 1.8T パラメータにさらにパラメータが追加されます。テキストのみの事前トレーニングの後、さらに約 2 兆個のトークンで微調整されます。
OpenAI はビジョン モデルについて、ゼロからトレーニングすることを望んでいましたが、この方法は十分に成熟していなかったので、リスクを軽減するためにテキストから始めることにしました。
次のモデルである GPT-5 は、視力を一から訓練され、独自に画像を生成できるようになると言われています。さらに、オーディオも処理できるようになります。
このビジョン機能の主な目的の 1 つは、自律エージェントが Web ページを読み取り、画像やビデオからコンテンツを転写できるようにすることです。トレーニングに使用されるデータの一部は、結合データ (レンダリングされた LaTeX/テキスト)、Web ページのスクリーンショット、YouTube ビデオ: サンプル フレーム、および文字起こしを取得するための Whisper の実行です。
LLM の過剰な最適化で興味深いのは、ビジュアル モデルのコストがテキスト モデルのコストと同じではないことです。「Amazon クラウドの危機」の記事で説明したように、テキスト モデルではコストが非常に低くなります。ビジョン モデルでは、データ読み込みの IO が約 150 倍高くなります。各トークンは 600 バイトであり、テキストの場合は 4 バイトではありません。画像圧縮に関しては多くの研究が行われています。
これは、今後 2 ~ 3 年間の LLM のユースケースと比率に基づいてハードウェアを最適化するハードウェア ベンダーにとって非常に重要です。彼らは、すべてのモデルが強力なビジュアルおよびオーディオ機能を備えた世界にいるかもしれません。自分のスキーマが不適応であることに気づくかもしれません。全体として、アーキテクチャは、現在の簡略化されたテキストベースの高密度モデルや MoE モデルを超える段階に進化することは確実です。