© 2022 Uriel Singer 他 (メタ AI)
© 2023 Conmajia
この記事は、論文「Make-A-Video: Text-to-Video Generation without Text-Video Data (2209.14792)」に基づいています。
この記事は、論文の筆頭著者である Uriel Singer の承認を得ています。

要約我々は、Wensheng Graph (T2I) の最近の大きな進歩を Wensheng Video (T2V) に直接変換する手法である Make-A-Video (Make-A-Video) を提案します。私たちのアプローチはシンプルです。ペアになったテキストと画像のデータから世界がどのように見えるか、それがどのように記述されるかを学び、教師なしのビデオ クリップから世界がどのように動くかを学びます。Make-A-video には 3 つの利点があります: (1) T2V モデルのトレーニング プロセスを高速化します (ビジュアルおよびマルチモーダル表現を最初から学習する必要がありません)、(2) ペアになったテキストとビデオのデータを必要としません、(3) ) 生成されたビデオ 今日の画像生成モデルの幅広さ (美的多様性、ファンタジー描写など) を継承します。私たちは、T2I モデル上に斬新で効率的な時空間モジュールを構築するための、シンプルかつ効果的な方法を設計します。まず、フルタイム U-Net テンソルとアテンション テンソルを分解し、それらを空間と時間で近似します。次に、高解像度およびフレームレートのビデオを生成するための時空間パイプラインを設計します。これには、ビデオ デコーダー、補間モデル、および T2V を含むさまざまなアプリケーションをサポートできる 2 つの超解像度モデルが含まれています。空間的および時間的解像度、テキストの適合性、およびビデオ品質の点で定性的および定量的な測定を行った結果、Make-A-Video は現在の最先端の Vincent ビデオ テクノロジと呼ぶに十分に進歩していると考えられます。
以下が本文です。
1 はじめに
インターネットにより、[替换文字,图片]このようなデータのペアを HTML ページから何十億もの収集できるようになり、テキストから画像への変換 (T2I、ヴィンセント グラフ) モデリングの最近の進歩につながりました。[文字,视频]ただし、ビデオの場合、これまで同様のサイズのデータセットを簡単に収集する方法がなかったため、この成功を(ペアのデータを使用して)再現することで得られるメリットは限られています。画像を生成できるモデルがすでに市販されているときに、テキストからビデオへの変換 (T2V、Vincent Video) モデルを最初からトレーニングするのは無駄です。さらに、教師なし学習 (つまり、ラベルなしデータの使用) を使用すると、ネットワークはより多くのデータから学習できるようになります。微妙で珍しい概念的表現を学習するには、大量のデータが重要です。教師なし学習は、自然言語処理 (NLP) の分野の進歩に長い間使用され、大きな成功を収めてきました。この方法で事前トレーニングされたモデルは、教師ありで個別にトレーニングされたモデルよりもはるかに高いパフォーマンスをもたらします。
これをヒントに、私たちはMake-A-Video(ビデオを作った)を提案します。Make-A-Video は、T2I モデルを活用してテキストと視覚世界の対応を学習し、ラベルなし (ペアになっていない) ビデオ データの教師なし学習手法を利用して実際のオブジェクトの動きを学習します。Make-A-Video では、[文字,视频]このようなペアデータを使用せずに、テキストから直接ビデオを生成できます。明らかに、画像を説明するテキストでは、ビデオで観察される内容全体を捉えることはできません (また、その必要もありません)。とはいえ、画像ベースの行動認識システムと同様に、コーヒーを飲む女性やサッカーをする象など、静止画像から物体の行動や出来事を推測できることもよくあります。さらに、文字による説明がなくても、ビーチの波や象の鼻の動きなど、世界のさまざまな存在がどのように動き、相互作用するかを学ぶには、教師なしのビデオで十分です。時間拡散ベースの手法で実証されているように、画像を説明するテキストだけを見たモデルは、短いビデオを生成するのに驚くほど効率的であることがわかりました。Make-A-Video は、T2V 時代に新しいテクノロジーを開拓しました。

関数保存変換を使用して、モデルの初期化フェーズ中に時間情報を含めるように空間レイヤーを拡張します。拡張された時空間ネットワークには、ビデオ コレクションから時間ダイナミクスを学習するための新しいアテンション モジュールが含まれています。この手順により、以前にトレーニングされた T2I ネットワークから新しい T2V ネットワークに知識が瞬時に転送されるため、T2V トレーニング プロセスが大幅に高速化されます。視覚的な品質を向上させるために、空間超解像度モデルとフレーム補間モデルをトレーニングします。これにより、生成されるビデオの解像度が向上し、管理可能なほど高いフレーム レートが可能になります。
私たちの主な貢献は次のとおりです。
- 私たちは、「Make-A-Video: 時空間因子拡散モデルによる拡散ベースの T2I モデルを T2V に拡張する効率的な方法」を紹介します。
- テキストと画像の結合事前分布を利用して、テキストとビデオ データのペアの必要性を回避し、より大量のビデオ データへのスケーラビリティを可能にします。
- 私たちは、ユーザーが指定したテキスト入力を基に、高解像度、高フレームレートのビデオを初めて生成する、空間的および時間的な超解像度戦略を提案します。
- 私たちは既存の T2V システムに対して Make-A-Video を評価し、(a) 最先端の定量的および定性的測定、および (b) T2V に関する既存の文献よりも徹底的な評価を提示します。また、後にリリースされる予定のゼロショット T2V の人による評価用に、300 個のキューのテスト セットも収集しました。
前職2件
テキストから画像への生成。Reid が発表したこの方法は、T2I 生成に無条件敵対的生成ネットワーク (GAN) を使用した最初の研究の 1 つです。その後の GAN バリアントは、プログレッシブ生成、つまり画像とテキストの位置合わせの向上に重点を置いています。DALL-E の研究は、配列間変換問題として T2I 生成の先駆者となり、離散変分オートエンコーダー (VQVAE) とトランスフォーマーを使用して実装しました。それ以来、新しい亜種が継続的に導入されています。たとえば、Make-A-Scene では、セマンティック マッピングを使用した制御可能な T2I 生成を研究しています。Parti はマルチコンテンツの生成を目指しており、エンコーダ/デコーダ アーキテクチャと改良された画像トークナイザを通じてその機能を完成させます。一方、ノイズ除去された拡散確率モデル (DDPM) は、T2I 生成の開発をうまく活用しました。GLIDE は、カスケード生成用に T2I およびアップサンプリングされた拡散モデルをトレーニングします。GLIDE が提案する分類子を使用しないガイダンスは、画像品質とテキスト コンプライアンスを向上させるために T2I 生成で広く使用されています。DALLE-2 は、CLIP 潜在空間と以前のモデルを利用します。VQ 拡散と安定拡散は、ピクセル空間ではなく潜在空間で T2I 生成を実行し、作業効率を向上させます。
テキストからビデオへの生成。T2I 生成機能の目覚ましい進歩にもかかわらず、T2V 生成の進歩は 2 つの主な理由により大幅に遅れています。それは、高品質のテキストとビデオのペアを備えた大規模なデータセットの欠如と、高次元ビデオ データのモデリングの複雑さです。初期の研究の中には、動く人物や特定の人間の動作など、単純な領域でのビデオ生成に焦点を当てたものもありました。私たちの知る限り、Sync-DRAW は、繰り返しの注意を利用した変分オートエンコーダー用の最初の T2V 生成方法です。中国科学技術大学の Pan Yingwei 氏とデューク大学の Li Yitong 氏も、それぞれの研究で GAN ネットワークを画像生成の分野から T2V まで拡張しました。
最近、GODIVA は、より現実的な T2V 生成シナリオをサポートするために、2D VQVAE とスパース アテンションを初めて使用しました。NÜWA は GODIVA を拡張し、マルチタスク学習スキームにおけるさまざまな生成タスクの統一表現を提供します。T2V 生成のパフォーマンスをさらに向上させるために、清華大学の Hon Wenyi らは、解散した CogView-2 プロジェクトに基づいて時間的注意を追加した CogVideo T2I モデルを開発しました。ビデオ拡散モデル (VDM) は、画像データとビデオ データの両方を使用して、ビデオの時空間表現をトレーニングします。CogVideo と VDM はトレーニング用に 1,000 万のプライベート テキストとビデオのペアを収集しましたが、私たちの研究ではオープンソース データセットのみを使用しているため、一般の人々がより簡単に再現できます。
画像事前分布を使用したビデオ生成。ビデオ モデリングの複雑さと高品質のビデオ データ収集の課題により、学習プロセスを簡素化するためにビデオに関する画像の事前知識を活用することを検討するのは自然なことです。結局のところ、写真は 1 フレームだけのビデオです。無条件ビデオ生成では、MoCoGAN-HD はビデオ生成を、事前トレーニングされた固定画像生成モデルの潜在空間内で軌道を見つけるタスクとして定義します。T2V 生成では、NÜWA はマルチタスクの事前トレーニング段階で画像とビデオのデータセットを結合し、微調整のためのモデルの一般化を向上させます。CogVideo は、T2V 生成に事前トレーニング済みの固定 T2I モデルを利用します。これにより、トレーニング中のメモリ使用量を削減するために、少数のトレーニング可能なパラメーターのみが必要になります。ただし、固定オートエンコーダーと T2I モデルには、T2V の生成に関して特定の制限があります。VDM のアーキテクチャは、画像とビデオの生成の組み合わせを実現できます。ただし、ソースとしてランダムなビデオから独立した画像をランダムにサンプリングし、大規模なテキスト画像データセットを利用しませんでした。
Make-A-Video はいくつかの点でこれらの作品とは異なります。 まず、私たちのアーキテクチャは、T2V 世代におけるテキストとビデオのペアのトレーニング サンプルへの依存を打ち破ります。これは、狭い範囲に制限する必要があった、または大規模なテキストとビデオのペア データが必要だった以前の研究に比べて、大きな利点です。第 2 に、ビデオ生成用に T2I モデルを微調整し、効果的な調整モデルの重みを取得しました。 CogVideo のように重みを凍結するのではなく、第 3 に、私たちの結果は、擬似 3D 畳み込み層と時間的注意層を使用した、ビデオおよび 3D ビジョン タスクの効率的なアーキテクチャに関する以前の研究からインスピレーションを得ています。これにより、T2I アーキテクチャがより有効に活用されるだけでなく、VDM と比較して時間情報の融合も向上します。
3つの方法
Make-A-Video は 3 つの主要コンポーネントで構成されます: (i) テキストと画像のデータ ペアでトレーニングされた T2I ベース モデル (セクション 3.1 を参照)、(ii) 時空間コンボリューション レイヤーとアテンション レイヤー。時間次元に拡張されたネットワーク (ビルディング ブロック) (セクション 3.2 を参照)、(iii) 時空間層と T2V 生成に必要な別の重要な要素を含む時空間ネットワーク - 高フレーム レート生成のためのフレーム補間ネットワーク (セクション 3.3 を参照)。
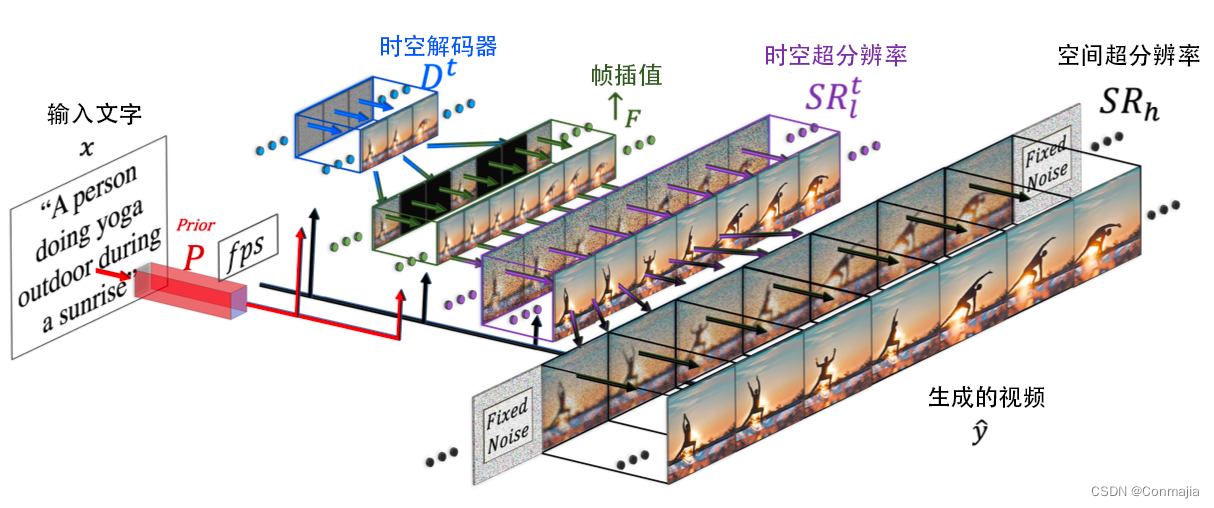
Make-A-Video の最終的な T2V 推論スキーム (図 2 を参照) は次のように表現できます。
yt ^ = SR h ∘ SR lt ↑ F ∘ D t ∘ P ∘ ( x ^ , C x ( x ) ) , (1) \hat{y_t}=\mathrm{SR}_h\circ\mathrm{SR}_l ^t\uparrow_F\circ\mathrm{D}^t\circ\mathrm{P}\circ\left(\hat{x},\mathrm{C}_x\left(x\right)\right),\tag {1}yた^=SRふ○SR私た↑ふ∘ Dt○P○(バツ^、C×( × ) )、( 1 )
ここでyt ^ \hat{y_t}yた^結果のビデオ、SR h \mathrm{SR}_hSRふSR l \mathrm{SR}_lSR私これらは空間的および時間的超解像ネットワーク (セクション 3.2 を参照)、↑ F \uparrow_F↑ふはフレーム補間ネットワーク (セクション 3.3 を参照)、D t \mathrm{D}^tDtは時空デコーダ (セクション 3.2 を参照)、P \mathrm{P}Pは以前の値 (セクション 3.1 を参照)、x ^ \hat{x}バツ^は BPE エンコードされたリテラル、C x \mathrm{C}_xC×CLIP テキスト エンコーダ、xxはxは入力テキストです。3 つの主要なコンポーネントについては、後続のサブセクションで詳しく説明します。
3.1 テキストから画像へのモデル
時間コンポーネントを追加する前に、メソッドの主要部分、つまりテキストと画像のペアでトレーニングされた T2I モデルをトレーニングしました。そのコアコンポーネントは、Ramesh の研究で使用されたものと同じです。
次のネットワークを使用してテキストから高解像度画像を生成します: (i)事前ネットワーク P \mathrm{P}P、テキスト埋め込みxe x_eバツえBPE エンコードされたテキスト トークンx ^ \hat{x}バツ^、推論中に画像埋め込みを生成しますye y_eyえ; (ii) デコーダネットワークD \mathrm{D}D、写真を埋め込んでくださいyえ条件として低解像度64 × 64 64\times 64を生成します64×64 RGB 画像yl ^ \hat{y_l}y私^; (iii) 2 つの超解像度ネットワークSR l \mathrm{SR}_lSR私、SR h \mathrm{SR}_hSRふ、それぞれ、生成された画像yl ^ \hat{y_l}y私^解像度は256 × 256 256\times 256に増加します。256×256および768 × 768 768\times768768×768ピクセル、つまり最後の1 枚の画像y ^ \hat{y}y^。
3.2 時空層
2 次元 (2D) 条件付きネットワークを時間次元に拡張するために、2 つの主要な構成要素を変更します。ビデオ生成を容易にするために、空間的次元だけでなく時間的次元も必要になりました: (i) 畳み込み層 (セクション 3.2.1 を参照) と (ii) アテンション層 (セクション 3.2.2 を参照)。他のレイヤー (完全に接続されたレイヤーなど) は、構造化された空間情報および時間情報に関連していないため、追加の次元を追加するときに特別な処理を必要としません。ほとんどの U-Net ベースの拡散ネットワークは、時空間デコーダD t \mathrm{D}_tによって時間的に変更されます。Dたそれぞれのサイズが64 × 64 64\times 64 の16 個の RGB フレームを生成するようになりました。64×64、新しく追加されたフレーム補間ネットワーク↑ F \uparrow_F↑ふ、生成された 16 個のフレーム (図 2 を参照) と超解像度ネットワークSR lt \mathrm{SR}_l^tの間を補間することで実効フレーム レートを向上させます。SR私た。
超解像には幻覚情報が含まれることに注意してください。ちらつきのない制作のためには、フレーム間で錯覚が一貫していなければなりません。したがって、SR lt \mathrm{SR}^t_lSR私たモジュールは空間的および時間的次元にわたって動作します。定性検査では、これがフレームごとの超解像処理を実行するよりも大幅に優れていることがわかりました。メモリと計算の制約、および高解像度ビデオ データの不足により、SR h \mathrm{SR}_hSRふ時間次元へのスケーリングは困難です。つまりSR h \mathrm{SR}_hSRふ空間次元でのみ機能します。ただし、フレーム間で細部の一貫した錯覚を促すために、各フレームを同じノイズで初期化します。
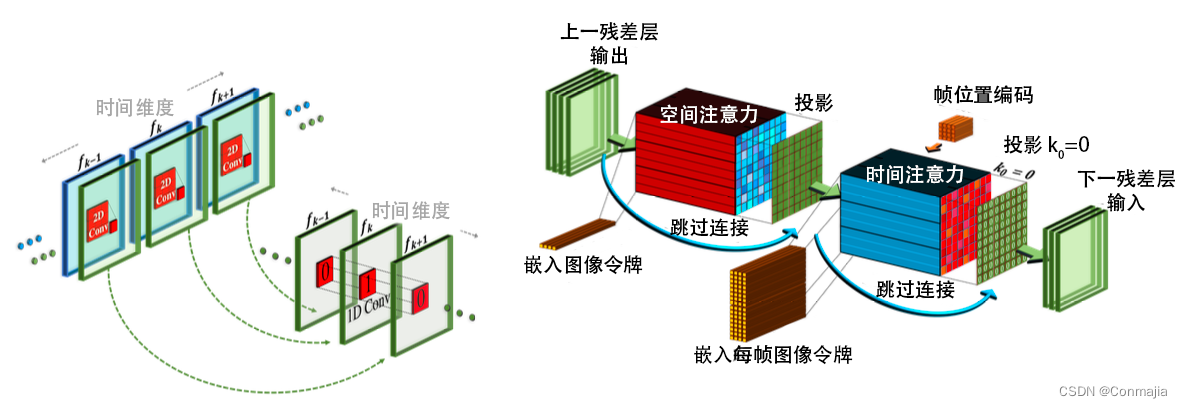
3.2.1 擬似 3D 畳み込み層
図 3 に示すように、分離可能な畳み込みを動機として、各 2 次元 (2D) 畳み込み層の後に 1 次元 (1D) 畳み込みをスタックします。これにより、3 次元 (3D) 畳み込み層の大きな計算負荷を受けることなく、空間軸と時間軸の間での情報共有が容易になります。さらに、事前トレーニングされた 2D 畳み込み層と新しく初期化された 1D 畳み込み層の間に具体的なパーティションが作成され、以前の Learn 空間知識を維持しながら時間畳み込みを最初からトレーニングできるようになります。
入力テンソルh ∈ RB × C × F × H × W h\in\mathbb{R}^{B\times C\times F\times H\times W} が与えられるとします。h∈RB × C × F × H × W、ここでBBB、CCC、FFF、HHH、WWWはそれぞれバッチ次元、チャネル次元、フレーム次元、高さ次元、幅次元であり、擬似 3D 畳み込み層は次のように定義されます。
変換 P3D ( h ) ≔ 変換 1D ( 変換 2D ( h ) ∘ T ) ∘ T , (2) \text{Conv}_{\text{P3D}}\left(h\right)\coloneqq\text{Conv} _{\text{1D}}\left(\text{Conv}_{\text{2D}}\left(h\right)\circ T\right)\circ T,\tag{2}コンバージョンP3D( h ):=コンバージョン1D(変換2D( h )○た)○て、( 2 )
ここで、転置演算子∘ T \circ T∘ T は空間と時間の次元を交換するために使用されます。初期化プロセスをよりスムーズにするために、Conv 2D \text{Conv}_{\text{2D}} を実行コンバージョン2Dレイヤーが事前トレーニングされた T2I モデルから初期化される場合、Conv 1D \text{Conv}_{\text{1D}}コンバージョン1Dレイヤーは恒等関数に初期化され、トレーニングされた純粋な空間レイヤーから時空間レイヤーへのシームレスな移行が可能になります。初期化時に、ランダム ノイズを使用するため、ネットワークはKKを生成することに注意してください。K個の異なる画像。それぞれは入力テキストに準拠していますが、時間的な一貫性がありません。
3.2.2 擬似3Dアテンションレイヤー
T2I ネットワークの重要なコンポーネントはアテンション層です。セルフ アテンションによって抽出された特徴に加えて、文字通りの情報が、拡散時間ステップなどの他の関連情報とともにいくつかのネットワーク階層に注入されます。3D 畳み込み層の使用は計算コストが高くなりますが、アテンション層に時間次元を追加することは、メモリ消費量の観点から完全に不可能です。VDM の研究に触発されて、次元分解戦略を注目層まで拡張しました。各 (事前トレーニングされた) 空間アテンション層の後に、時間アテンション層をスタックします。これは、畳み込み層と同様に、完全な時空間アテンション層に近似します。具体的には、入力テンソルhhが与えられると、h、\text{ flatten} を平坦化Flatten は、空間次元を h ′ ∈ RB × C × F × H × W h'\in\mathbb{R}^{B\times C\times F\ times H\times W} に平坦化する行列演算子として定義されます。h』∈RB × C × F × H × W。平坦化を解除 \text{Un flatten}Un flatten (反平坦化) は、逆行列演算子として定義されます。したがって、擬似 3D アテンション レイヤーは次のように定義されます。
ATTN P3D(h) = 非平坦化 (ATTN 1D (ATTN 2D ( flatten(h) ) ∘ T ) ∘ T )。(3) \text{ATTN}_{\text{P3D}}\left(h\right)=\text{非平坦化}\left(\text{ATTN}_{\text{1D}}\left(\text {ATTN}_{\text{2D}}\left(\text{ flatten}\left(h\right)\right)\circ T\right)\circ T\right).\tag{3}注意P3D( h )=平らにしない(注意1D(注意2D(平らにする( h ) _○た)○た)。( 3 )
Conv P3D \text{Conv}_\text{P3D}を使用コンバージョンP3D同様に、時空間の初期化をスムーズに行うには、ATTN 2D \text{ATTN}_\text{2D}注意2Dレイヤーは、事前トレーニングされた T2I モデルATTN 1D \text{ATTN}_\text{1D}から初期化されます。注意1D層は恒等関数として初期化されます。
因数分解された時空間アテンション レイヤーは、VDM と CogVideo でも使用されます。CogVideo は、各 (凍結された) 空間レイヤーに時間レイヤーを追加し、それらを共同でトレーニングします。ネットワークが画像とビデオを交互にトレーニングできるようにするために、VDM はアンチフラット化された1 × 3 × 3 1\times 3\times3を使用します。1×3×3 つの畳み込みフィルターは 2D U-Net を 3D に拡張するため、後続の空間的注意は 2D のままであり、相対位置を介して 1D の時間的注意を埋め込むことができます。対照的に、追加の3 × 1 × 1 3\times1\times13×1×1 つの畳み込み射影 (各1 × 3 × 3 1\times3\times3)1×3×3 )、時間情報も各畳み込み層を通過するようになります。
フレームレート調整。CogVideo と同様に、T2I 条件に加えて、追加の条件パラメータfps \text{fps}を追加します。fps は、生成されたビデオの 1 秒あたりのフレーム数を示します。1 秒あたりの異なるフレームを調整することにより、追加の拡張方法を使用して、トレーニング時に限られた利用可能なビデオに対処し、推論時に生成されたビデオに対する追加の制御を提供します。
3.3 フレーム補間ネットワーク
セクション 3.2 で説明した時空間の変更に加えて、新しいマスクされたフレームの内挿および外挿ネットワーク↑ F \uparrow_Fをトレーニングします。↑ふ。フレーム補間によって生成されるビデオのフレーム数を増やして、よりスムーズなビデオを実現したり、前後のフレームを外挿してビデオの長さを延長したりすることができます。メモリと計算の制約の下でフレーム レートを高めるために、マスクされたフレーム補間タスクで時空間デコーダD t \text{D}^tをトレーニングします。Dtは、マスクされた入力フレームをゼロ パディングすることでビデオをアップサンプリングするように微調整されます。マスクされたフレーム補間を微調整する場合、U-Net の入力に 4 つのチャネルを追加します。RGB マスクされたビデオ入力用に 3 チャネル、およびどのフレームがマスクされているかを示す追加のバイナリ チャネルです。可変フレームスキップとfps \text{fps}がありますfpsスケーリングは、複数の時間的アップサンプリングを可能にするために微調整されています。私たちは↑ F \uparrow_Fを行います↑ふマスクされたフレーム補間によって指定されたビデオ テンソルを拡張する演算子を表します。すべての実験に↑ F \uparrow_Fを適用しました。↑ふそして、フレーム値 5 をスキップし、ビデオの 16 フレームを 76 フレームにアップサンプリングします ( ( 16 − 1 ) × 5 + 1 (16-1)\times 5+1( 16−1 )×5+1 )。ビデオの先頭または末尾でフレームをマスクすることにより、ビデオ外挿または画像アニメーションに同じアーキテクチャを使用できることに注意してください。
3.4 トレーニング
上で説明した Make-A-Video のコンポーネントは独立してトレーニングされます。テキストを入力として受け取る唯一のコンポーネントは、前のP \text{P}です。P._ _ 動画で微調整するのではなく、ペアになったテキストと画像のデータでトレーニングします。デコーダー、以前のコンポーネント、および 2 つの超解像度コンポーネントは、最初に画像のみ (位置合わせされたテキストなし) でトレーニングされます。デコーダは CLIP 画像埋め込みを入力として受け取り、超解像度コンポーネントはトレーニング中にダウンサンプリングされた画像を入力として受け取ることを思い出してください。画像でトレーニングした後、新しい時間レイヤーを追加して初期化し、ラベルのないビデオ データで微調整します。元のビデオから 1 ~ 30 フレームの範囲の 16 フレームがランダムにサンプリングされます。ベータ関数を使用してサンプリングを行い、デコーダーのトレーニング時に高い FPS 範囲 (モーションが少ない) から開始して、低い FPS 範囲 (モーションが多い) に移行します。オクルージョン フレーム補間コンポーネントは、タイミング デコーダによって微調整されます。
4つのテスト
4.1 データセットと設定
データセット。画像モデルをトレーニングするには、テキスト言語が英語である Laion-5b データセットの 2.3B サブセットを使用します。NSFW 画像 2 、スパム、またはウォーターマークを含むサンプルのペアを 0.5 を超える確率で除外します。生成ビデオ モデルのトレーニングには、WebVid-10M および HD-VILA-100M3 の 10M サブセットを使用します。ビデオのみを使用していることに注意してください (対応するテキストは使用していません)。デコーダD t D^tDtおよび補間モデルは WebVid-10M でトレーニングされます。SR lt \text{SR}^t_lSR私たトレーニングは WebVid-10M および HD-VILA-10M で実行されます。T2V 生成のためにプライベートのテキストとビデオのペアを収集した、Hong、Ho らの以前の研究とは対照的に、私たちはパブリック データセットのみを使用します (ビデオのペアになったテキストは使用しません)。また、ゼロ学習設定でのUCF-101とMSR-VTTの自動評価も試みました。
自動メトリクス。UCF-101では、クラスごとにテンプレート文(ビデオを生成せず)を作成し、評価用に修正しました。以下の 10,000 サンプルの Fresche Video Distance (FVD) と Inception Score (IS) を報告します。私たちが生成するサンプルは、トレーニング セットと同じクラス分布に従います。MSR-VTT については、テスト セット内の 59794 個のキャプションすべてを使用して、Fresche Inception Distance (FID) と CLIPSIM (ビデオ フレームとテキスト間の平均 CLIP 類似度) を報告し、Wu Chengfei らの研究に従います。
人間による評価セットと指標。Amazon Mechanical Turk (AMT) を介して 300 のプロンプトで構成される評価セットを収集します。また、これらのプロンプトの単語にマークを付けたネチズンに、「T2V システムが存在する場合、何を生成することに興味がありますか?」と尋ねました。不完全なキーワード(例:「水に飛び込む」)、抽象的すぎる言葉(例:「気候変動」)、または攻撃的なキーワードを除外しました。次に、5 つのカテゴリ (動物、ファンタジー、人物、自然と風景、食べ物と飲み物) を特定し、これらのカテゴリの手がかりとなる単語を選択しました。これらの手がかりとなる単語は、ビデオが生成されることなく選択され、固定されたままになっています。さらに、人間による評価には Imagen の DrawBench キューワードを使用します。主にビデオ品質とテキストからビデオへの適合性を評価します。ビデオの品質については、2 つのビデオをランダムな順序で表示し、キューワードのアノテーターにどちらのビデオの品質が高いかを尋ねます。適合性を評価するために、テキストも表示し、どのビデオがテキストによく対応しているかをアノテーターに尋ねます (気が散るのを避けるため、品質の問題を無視するようアドバイスします)。さらに、人間による評価を実行して、補間モデルと Reda らが研究した FILM ビデオのモーション リアリズムを比較します。比較ごとに、5 人の異なるアノテーターからの投票の過半数を最終結果として採用します。
4.2 定量的結果
MSR-VTT の自動評価。MSRVTT に関する GODIVA と NÜWA のレポートに加えて、正式にリリースされた CogVideo モデルについても推論を実行し、中国語と英語の入力を比較しました。CogVideo と Make-A-Video の場合、ゼロ学習設定では、キューごとにサンプルが 1 つだけ生成されます。評価モデルにはこれより高い解像度とフレーム レートを使用する必要はないため、16 × 256 × 256 16\times 256 \times 256のみを生成しました。16×256×256本のビデオ。結果を表 1 に示します。Make-A-Video のゼロ学習パフォーマンスは、MSR-VTT でトレーニングされた GODIVA および NÜWA のパフォーマンスよりも大幅に優れています。また、中国語と英語の設定でも CogVideo よりも優れたパフォーマンスを発揮します。したがって、Make-A-Video は前作よりも優れた生成能力を備えています。
| 方法 | 学習ゼロ | サンプル/入力 | FID( ↓ \下矢印↓) | CLIPSIM( ↑ \uparrow↑) |
|---|---|---|---|---|
| ゴディバ | いいえ | 30 | – | 0.2402 |
| ヌワ | いいえ | – | 47.68 | 0.2439 |
| CogVideo (中国語) | はい | 1 | 24.78 | 0.2614 |
| コグビデオ (英語) | はい | 1 | 23.59 | 0.2631 |
| メイク・ア・ビデオ (当社のもの) | はい | 1 | 13.17 | 0.3049 |
UCF-101 自動評価。UCF-101 はビデオ生成を評価するための一般的なベンチマークであり、最近 T2V モデルで利用できるようになりました。CogVideo は、事前トレーニングされたモデルを微調整して、分類基準に基づいてビデオを生成します。VDM は無条件のビデオ生成を実行し、UCF-101 でゼロからトレーニングされます。私たちの意見では、これらの設定はどちらも理想的ではなく、T2V 発電能力の直接の評価として役立つべきではありません。また、FVD 評価モデルではビデオが 0.5 秒 (16 フレーム) であると想定されていますが、これは実際のビデオ生成に使用するには短すぎます。ただし、前作との比較のため、UCF-101 をゼロショットおよび微調整設定で評価します。結果を表 2 に示します。Make-A-Video のゼロショット パフォーマンスは、すでに UCF-101 でトレーニングされた他のメソッドと同等であり、CogVideo よりもはるかに優れています。これは、Make-A-Video が特定のコンテンツの生成においてさらに優れていることを示しています。微調整された設定により、FVD が大幅に低くなり最先端の結果が得られます。これは、Make-A-Video が以前の作品よりも一貫したビデオを生成できることを示唆しています。
| 方法 | 事前トレーニング | 分類 | 解決 | IS( ↑ \uparrow↑) | FVD( ↓ \下矢印↓) |
|---|---|---|---|---|---|
| ゼロ学習セットアップ | |||||
| CogVideo (中国語) | いいえ | はい | 480×480 | 23.55 | 751.34 |
| コグビデオ (英語) | いいえ | はい | 480×480 | 25.27 | 701.59 |
| メイク・ア・ビデオ (当社のもの) | いいえ | はい | 256×256 | 33.00 | 367.23 |
| 設定を微調整する | |||||
| TGANv2 | いいえ | いいえ | 128×128 | 26.60±0.47 | – |
| 言う | いいえ | いいえ | 32.70±0.35 | 577±22 | |
| MoCoGAN-HD | いいえ | いいえ | 256×256 | 33.95±0.25 | 700±24 |
| コグビデオ | はい | はい | 160×160 | 50.46 | 626 |
| VDM | いいえ | いいえ | 64×64 | 57.80±1.3 | – |
| TATSベース | いいえ | はい | 128×128 | 79.28±0.38 | 278±11 |
| メイク・ア・ビデオ (当社のもの) | はい | はい | 256×256 | 82.55 | 81.25 |
人間の評価。DrawBench 上の CogVideo (唯一公的に利用可能なゼロ学習 T2V 生成モデル) とテスト セットと比較します。また、VDM Web ページに表示されている 28 個のビデオも評価しました (これは、モデルの強度を示すために偏っている可能性があります)。これは非常に小さなテスト セットであるため、入力ごとに 8 つのビデオをランダムに生成し、8 回評価して平均結果を報告します。76 × 256 × 256 76\times 256 \times 256を生成します。76×256×実際の人物による評価のための256解像度のビデオ。結果を表3に示す。すべてのベンチマークと比較において、Make-A-Video はビデオ品質とテキストからビデオへの準拠の点で優れたパフォーマンスを達成しました。CogVideo と比較すると、DrawBench と評価セットの結果は似ています。VDM に関しては、厳選を行わずに大幅に優れた結果を達成したことは注目に値します。また、フレーム補間ネットワークを FILM と比較します。まず、DrawBench のテキスト プロンプトと評価セットから低フレーム レートのビデオ (1 FPS) を生成し、次に各メソッドを使用してサンプルを 4 FPS にブーストします。私たちの評価セットでは、評価者は私たちの方法が 62% の確率でより現実的なモーションを生成し、DrawBench では 54% の確率でより現実的なモーションを生成すると感じています。フレーム間に大きな差がある場合に私たちの方法がうまく機能することがわかりました。この場合、オブジェクトがどのように移動するかについて実際の知識を持っていることが重要です。
| 比較 | ランポイント | 品質 | コンプライアンス |
|---|---|---|---|
| Make-A-Video (当社) vs. VDM | VDM プロンプトワード(28) | 84.38 | 78.13 |
| Make-A-Video (弊社) vs. CogVideo (中国語) | ドローベンチ (200) | 76.88 | 73.37 |
| Make-A-Video (当社) vs. CogVideo (英語) | ドローベンチ (200) | 74.48 | 68.75 |
| Make-A-Video (弊社) vs. CogVideo (中国語) | 独自評価セット(300) | 73.44 | 75.74 |
| Make-A-Video (当社) vs. CogVideo (英語) | 独自評価セット(300) | 77.15 | 71.19 |
4.3 定性的結果
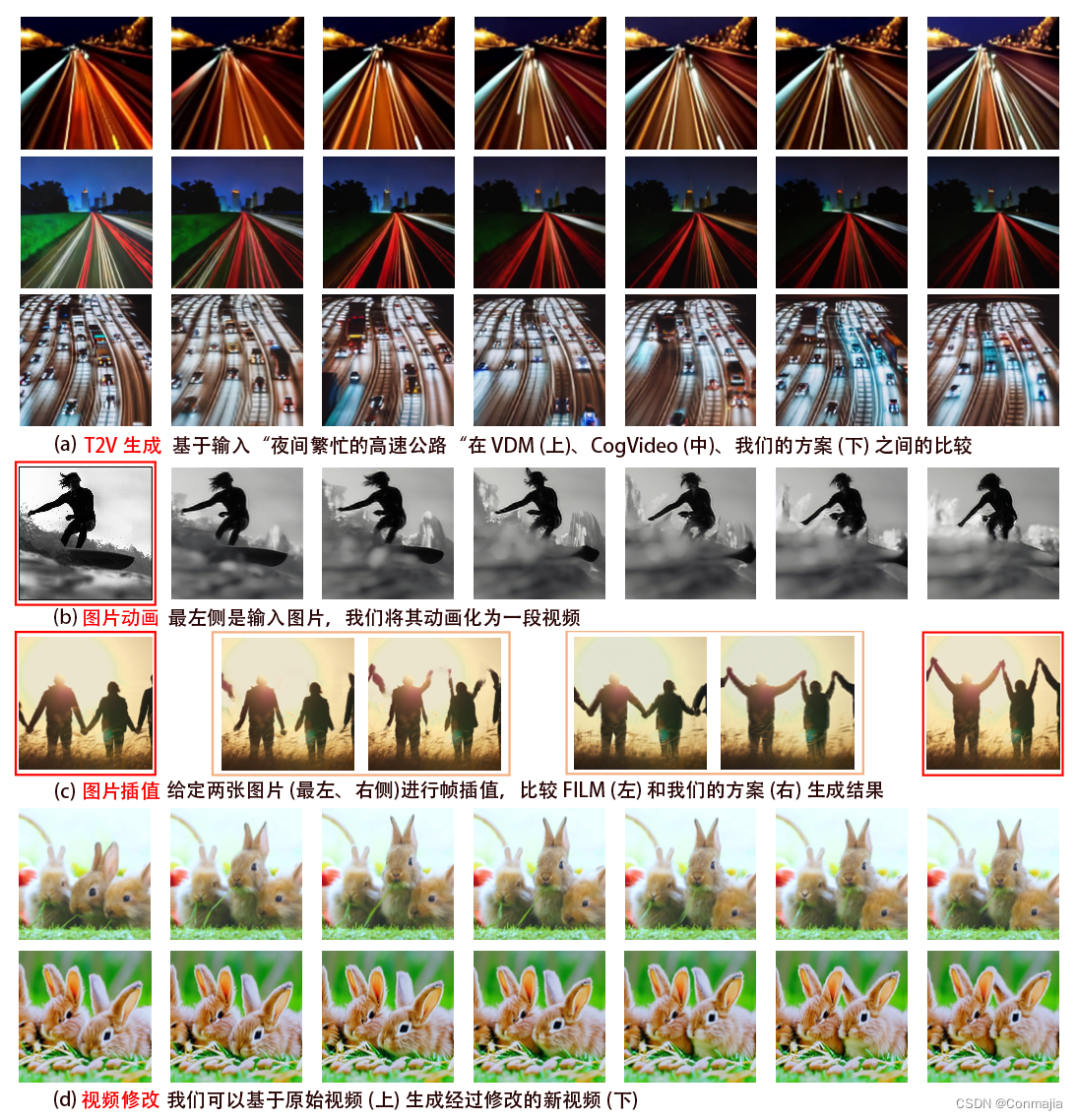
生成された Make-A-Video のサンプルを図 1 に示します。このセクションでは、T2V 生成を CogVideo および VDM と比較し、ビデオ補間を FILM と比較する方法を示します。さらに、私たちのモデルは、画像アニメーション、ビデオ変換など、他のさまざまなタスクにも使用できます。スペースの制限があるため、それぞれの例を 1 つだけ示します。図 4.a は、Make-A-Video と CogVideo および VDM の比較を示しています。Make-A-Video は、モーションの一貫性とテキストの対応を通じて、よりリッチなコンテンツを生成できます。図 4.b は、画像および画像セグメントの埋め込み上でマスクされたフレームの内挿および外挿ネットワークを調整する画像アニメーションの例を示しています。↑ F \uparrow_F↑ふビデオの残りの部分を推測します。これにより、ユーザーは独自の画像を使用してビデオを生成できるようになり、生成されたビデオをパーソナライズして直接制御する機会が得られます。図 4.c は、2 つの画像間の補間タスクにおける私たちの方法と FILM の比較を示しています。これを行うには、2 つの画像を開始フレームと終了フレームとして受け取り、生成時に 14 フレームをシェーディングする内挿モデルを使用します。私たちのモデルは、より意味的に意味のある補間を生成しますが、FILM は、何が動いているのかを意味的に現実的に理解することなく、フレーム間の移行をほとんど滑らかにしているようです。図 4.d はビデオのバリエーションの例を示しています。意味的に類似したビデオを生成するには、ビデオ内のすべてのフレームの平均的な CLIP 埋め込みを条件とします。その他のビデオ生成の例とアプリケーションについては、Web サイトmake-a-video.github.ioを参照してください。
議論
人間の知性の最大の強みの 1 つは、周囲の世界から学ぶ能力です。私たちが観察を通じて人、場所、物、行動を認識することをすぐに学ぶのと同じように、生成システムが人間の学習方法を模倣できれば、はるかに創造的で便利になるでしょう。教師なし学習を使用して高次のビデオから世界のダイナミクスを学習することは、研究者がラベル付きデータへの依存から脱却するのに役立ちます。現在の研究では、これを達成するために、ラベル付き画像とラベルなしビデオ クリップを効果的に組み合わせる方法が示されています。
次のステップとして、いくつかの技術的な制限に対処する予定です。前述したように、私たちの方法では、ビデオ内でのみ推測できるテキストと現象の間の関連性を学習することはできません。これらをどのように組み合わせて (たとえば、人が左から右、または右から左に手を振るビデオを生成する)、複数のシーンやイベントを含むより詳細なストーリーを描いた長いビデオを生成する方法は、今後の課題となります。
Web データでトレーニングされたすべての大規模モデルと同様に、私たちのモデルは Web データから学習し、社会的偏見を伴う有害なコンテンツを誇張する可能性があります。当社の T2I 生成モデルは、NSFW コンテンツと有害な単語が削除されたデータでトレーニングされています。私たちのデータ (画像とビデオ) はすべて公開されているため、モデルに透明性のレイヤーが追加され、現場の人々が私たちの作業を再現できるようになります。
ありがとう
ムスタファ・サイド・メフメトグル、ジェイコブ・シュー、カタヨン・ザンド、ジア・ビン・ファン、ジエボ・ルオ、シェリー・シェイニン、アンジェラ・ファン、ケリー・フリード。ご貢献いただきありがとうございます!
参考文献
- マックス・ベイン、アルシャ・ナグラニ、グール・ヴァロル、アンドリュー・ジッサーマン。
Frozen in time:エンドツーエンドの検索のためのビデオと画像の共同エンコーダー。ICCV、1728–1738 ページ、2021 年。 - トム・B・ブラウン、ベンジャミン・マン、ニック・ライダー、メラニー・サブビア、ジャレッド・カプラン、プラフラ・ダリワル、アルビンド・ニーラカンタン、プラナフ・シャム、ギリッシュ・サストリー、アマンダ・アスケル、サンディニ・アガルワル、アリエル・ハーバート=ヴォス、グレッチェン・クルーガー、トム・ヘニハン、レウォン・チャイルド、アディティア・ラメシュ、ダニエル・M・ジーグラー、ジェフリー・ウー、クレメンス・ウィンター、クリストファー・ヘッセ、マーク・チェン、エリック・シグラー、マテウシュ・リトウィン、スコット・グレイ、ベンジャミン・チェス、ジャック・クラーク、クリストファー・バーナー、サム・マッキャンドリッシュ、アレック・ラドフォード、イリヤ・サツケヴァー、ダリオアモデイ。言語モデルは少数回の学習です。CoRR、abs/2005.14165、2020。URL https://arxiv.org/abs/2005.14165。
- フラン・ワ・ショレ。Xception: 深さ方向に分離可能な畳み込みを使用した深層学習。コンピューター ビジョンとパターン認識に関する IEEE 会議議事録、1251 ~ 1258 ページ、2017 年。
- ミン・ディン、ウェンディ・ジェン、ウェンイー・ホン、ジエ・タン。Cogview2: 階層トランスフォーマーを介した、より高速かつ優れたテキストから画像への生成。arXiv プレプリント arXiv:2204.14217、2022。
- オラン・ガフニ、アダム・ポリアク、オロン・アシュアル、シェリー・シェイニン、デヴィ・パリク、ヤニフ・タイグマン。シーンの作成: 人間の事前分布を使用したシーンベースのテキストから画像への生成、2022 年。URL https://arxiv。org/abs/2203.13131。
- ソンウェイ・ゲー、トーマス・ヘイズ、ハリー・ヤン、シー・イン、グアン・パン、デビッド・ジェイコブス、ジアビン・ファン、デヴィ・パリク。時間に依存しない vqgan と時間に敏感なトランスフォーマーによる長時間ビデオの生成。ECCV、2022年。
- ディープタ・ギリッシュ、ヴィニータ・シン、アンカ・ラレスク。静止画における動作認識を理解する。pp. 1523–1529、2020 年 6 月。土井: 10.1109/CVPRW50498.2020.00193。
- イアン・グッドフェロー、ジャン・プージェ=アバディ、メディ・ミルザ、ビン・シュー、デヴィッド・ウォード=ファーリー、シェルジル・オゼール、アーロン・クールヴィル、ヨシュア・ベンジオ。敵対的生成ネットワーク。生理学研究所、2014 年。
- Shuyang Gu、Dong Chen、Jianmin Bao、Fang Wen、Bo Zhang、Dongdong Chen、Lu Yuan、および Baining Guo、テキストから画像への合成のためのベクトル量子化拡散モデル、CVPR、10696 ~ 10706 ページ、2022 年。
- タンメイ・グプタ、ダスティン・シュウェンク、アリ・ファルハディ、デレク・ホイエム、アニルッダ・ケンバヴィ。想像してみてください!脚本とか作品とかビデオとか。ECCV、pp.101-1 改訂 598–613、
- Thomas Hayes、Songyang Zhang、Xi ying、Guan Pang、Sasha Sheng、Harry Yang、Songwei Ge、Is-abelle Hu、および Devi Parikh. Mugen: ビデオ、オーディオ、テキストのマルチモーダル理解と生成のための遊び場. ECCV、2022.
- ジョナサン・ホー、アジェイ・ジェイン、ピーター・アッビール。ノイズ除去拡散確率モデル、2020。URL https://arxiv.org/abs/2006.11239。
- ジョナサン・ホー、ティム・サリマンス、アレクセイ・グリツェンコ、ウィリアム・チャン、モハマド・ノルージ、デイビッド・J・フリート。ビデオ放送モデル、2022 年。URL https://arxiv.org/abs/2204.03458。
- ホン・スンフン、ヤン・ディンドン、チェ・ジョンウク、イ・ホンラック。階層的なテキストから画像への合成のためのセマンティック レイアウトの推論。CVPR、7986–7994 ページ、2018 年。
- Wenyi Hon、Ming Ding、Wendi Zheng、Xinghan Liu、および Jie Tang.Cogvideo: トランスフォーマーによるテキストからビデオへの生成のための大規模事前トレーニング、2022. URL https://arxiv.org/abs/2205.15868。
- イートン・リー、マーティン・ミン、ディンハン・シェン、デイビッド・カールソン、ローレンス・カリン。テキストからのビデオ生成。『AAAI』第 32 巻、2018 年に掲載。
- yinghan Liu、Myle Ott、Naman Goyal、Jingfei Du、Mandar Joshi、Danqi Chen、Omer Levy、Mike Lewis、Luke Zettlemoyer、Veselin Stoyanov. Roberta: 堅牢に最適化された BERT 事前トレーニング アプローチ. CoRR、abs/1907.11692、2019a. URL http https://arxiv.org/abs/1907.11692。
- Yue Liu、Xin Wang、Yitian Yuan、Wenwu Zhu。文章からビデオへの生成のためのクロスモーダル二重学習。第 27 回 ACM 国際マルチメディア会議議事録、1239 ~ 1247 ページ、2019b。
- ターニャ・マルワ、ガウラフ・ミタル、ヴィニース・N・バラスブラマニアン。キャプションを使用した、注意深くセマンティックなビデオの生成。ICCV、1426–1434 ページ、2017 年。
- ガウラフ・ミタル、ターニャ・マルワ、ヴィニース・N・バラスブラマニアン。Sync-draw: 深く再帰的な注意深いアーキテクチャを使用した自動ビデオ生成。マルチメディアに関する第 25 回 ACM 国際会議議事録、1096 ~ 1104 ページ、2017 年。
- アレックス・ニコル、プラフラ・ダリワル、アディティア・ラメシュ、プラナフ・シャム、パメラ・ミシュキン、ボブ・マックグルー、イリヤ・サツケヴァー、マーク・チェン。Glide: テキストガイドによる拡散モデルを使用したフォトリアリスティックな画像の生成と編集を目指します。arXiv プレプリント arXiv:2112.10741、2021。
- Yingwei Pan、Zhaofan Qiu、Ting Yao、Houqiang Li、Tao Mei。伝える内容を作成するには: キャプションからビデオを生成します。マルチメディアに関する第 25 回 ACM 国際会議議事録、1789 ~ 1798 ページ、2017 年。
- ガウラフ・パルマー、リチャード・チャン、ジュンヤン・ジュー。エイリアスによるサイズ変更と gan の評価における驚くべき微妙な点について。CVPR、2022年。
- Zhaofan Qiu、Ting Yao、Tao Mei。擬似 3D 残差ネットワークを使用した時空間表現の学習。ICCV、5533–5541 ページ、2017 年。
- アレック・ラドフォード、キム・ジョンウク、クリス・ハラシー、アディティア・ラメシュ、ガブリエル・ゴー、サンディニ・アガルワル、ギリッシュ・サストリー、アマンダ・アスケル、パメラ・ミシュキン、ジャック・クラーク 他 自然言語の監視から転送可能な視覚モデルを学習します。ICML、8748 ~ 8763 ページ。PMLR、2021年。
- アディティア・ラメシュ、ミハイル・パブロフ、ガブリエル・ゴー、スコット・グレイ、チェルシー・ボス、アレック・ラドフォード、マーク・チェン、イリヤ・サツケヴァー。ゼロショットのテキストから画像への生成。ICML、8821 ~ 8831 ページ。PMLR、2021年。
- アディティア・ラメシュ、プラフラ・ダリワル、アレックス・ニコル、ケーシー・チュー、マーク・チェン。階層テキスト - クリップ潜在を使用した条件付き画像生成、2022 年。URL https://arxiv.org/abs/2204.06125。
- フィッサム・レダ、ヤンネ・コントカネン、エリック・タブレリオン、デチン・サン、キャロライン・パントファル、ブライアン・カーレス。動画: ワイドモーションのフレーム補間。arXiv プレプリント arXiv:2202.04901、
- スコット・リード、ゼイネプ・アカタ、シンチェン・ヤン、ラヤヌゲン・ローゲスワラン、ベルント・シーレ、ホンラック・リー。敵対的なテキストから画像への生成合成。ICML、1060 ~ 1069 ページ。PMLR、2016 年。
- ロビン・ロンバック、アンドレアス・ブラットマン、ドミニク・ロレンツ、パトリック・エッサー、ビョ・ルン・オマー。潜在拡散モデルを使用した高解像度画像合成。CVPR、10684 ~ 10695 ページ、2022 年。
- チトワン・サハリア、ウィリアム・チャン、サウラブ・サクセナ、ララ・リー、ジェイ・ファン、エミリー・デントン、シード・カムヤル・シード・ガセミプール、ブルク・カラゴル・アヤン、S・サラ・マハダヴィ、ラファ・ゴンティホ・ロペス、ティム・サリマンズ、ジョナサン・ホー、デヴィッド・J・フリート、そしてモハマド・ノルージ。深い言語理解によるフォトリアリスティックなテキストから画像への拡散モデル、2022 年。URL https://arxiv.org/abs/ 2205.11487。
- 斉藤正樹、斉藤俊太、小山正則、小林宗介。まばらにトレーニングし、高密度に生成: 高解像度時間ガンのメモリ効率の高い教師なしトレーニング。コンピューター ビジョンの国際ジャーナル、128(10):2586–2606、2020。
- クリストフ・シューマン、ロマン・ボーモント、ケイド・W・ゴードン、ロス・ワイトマン、テオ・クームス、アーシュ・カッタ、クレイトン・マリス、パトリック・シュラモウスキー、スリヴァツァ・R・クンダーシー、キャサリン・クロウソン、他。Laion-5b: 次世代の画像テキスト モデルをトレーニングするためのオープンな大規模データセット。
- クリストフ・シューマン、リチャード・ヴェンキュ、ロマン・ボーモント、テオ・クームス、ケイド・ゴードン、アーシュ・カッタ、ロバート・カチュマルチク、ジェニア・ジツェフ。LAION-5B: laion- 5b: オープンな大規模マルチモーダル データセットの新時代。https://laion.ai/laion-5b-a-new-era-of-open-large-scale-multi-modal-datasets/、2022 年。
- クルラム・スムロ、アミール・ロシャン・ザミル、ムバラク・シャー。Ucf101: 野生のビデオからの 101 の人間のアクション クラスのデータセット。arXiv プレプリント arXiv:1212.0402、2012。
- ユー・ティアン、ジェン・レン、メングレイ・チャイ、カイル・オルシェフスキー、シー・ペン、ディミトリス・N・メタクサス、セルゲイ・トゥリャコフ。高解像度のビデオ合成には、優れた画像ジェネレーターが必要です。ICLR、2021年。
- アシシュ・バスワニ、ノーム・シェイザー、ニッキー・パーマー、ジェイコブ・ウスコレイト、ライオン・ジョーンズ、エイダン・N・ゴメス、ルカシュ・カイザー、イリア・ポロスキン。必要なのは注意だけです。2017 年。URL https://arxiv。org/abs/1706.03762。
- Chenfei Wu、Lun Huang、Qianxi Zhang、Binyang Li、Lei Ji、Fan Yang、Guillermo Sapiro、Nan Duan. Godiva: Generating open-domain videos from Natural description. arXiv プレプリント arXiv:2104.14806, 2021a.
- ChenfeiWu、JianLiang、LeiJi、FanYang、YuejianFang、DaxinJiang、NanDuan. NU ̈wa: ニューラル視覚世界作成のための視覚合成事前トレーニング、2021b. URL https://arxiv.org/abs/2111.12417.
- Saining Xie、Chen Sun、Jonathan Huang、Zhuowen Tu、Kevin Murphy。時空間特徴学習の再考: ビデオ分類における速度と精度のトレードオフ。ECCV、305–321 ページ、2018 年。
- ジュン・シュウ、タオ・メイ、ティン・ヤオ、ヨン・ルイ。Msr-vtt: ビデオと言語の橋渡しをするための大規模なビデオ記述データセット。CVPR、5288–5296 ページ、2016 年。
- Tao Xu、Pengchuan Zhang、Qiuyuan Huang、Han Zhang、Zhe Gan、Xiaolei Huang、および Xiaodong He. Attngan: 注意生成敵対的ネットワーク機能を使用したきめ細かいテキストから画像への生成. CVPR において、1316 ~ 1324 ページ、2018 年。
- Honwei Xue、Tiankai Hang、Yanhong Zeng、Yuchong Sun、Bei Liu、Huan Yang、Jianlong Fu、および Baining Guo. 大規模なビデオ トランスクリプションによる高解像度ビデオ言語表現の進歩. CVPR において、5036 ~ 5045 ページ、2022 年。
- Rongtian Ye、Fangyu Liu、Liqiang Zhang です。3D 深さ方向の畳み込み: 3D ビジョン タスクのモデル パラメータを削減します。カナダ人工知能会議、186 ~ 199 ページ。スプリンガー、2019年。
- JIAHUI Yu、Xin Li、Jing Yu Koh、Han Zhang、Ruoming Pang、James qin、Alexander Ku、Yuanzhong xu、Jason Baldridge、Yonghui wu. vqgan が改良された Vector-Qualized Image Mod Mod eling. Arxiv プレプリント Arxiv: 2110.04627, 2021 。
- Jiahui Yu、Yuanzhong Xu、Jing Yu Koh、Thang Luong、Gunjan Baid、Zirui Wang、Vijay Vasudevan、Alexander Ku、Yinfei Yang、Burcu Karagol Ayan、Ben Hutchinson、Wei Han、Zarana Parekh、Xin Li、Han Zhang、Jason Baldridge、および Yonghui Wu. コンテンツリッチなテキストから画像への生成のための自己回帰モデルのスケーリング、2022a. URL https://arxiv.org/abs/2206.10789。
- ユ・シヒョン、タック・ジフン、モ・サンウ、キム・ヒョンス、キム・ジュノ、ハ・ジョンウ、シン・ジヌ。ダイナミクスを意識した暗黙的な敵対的生成ネットワークを使用してビデオを生成します。ICLR、2022b。
- Han Zhang、Tao Xu、Hongsheng Li、Shaoting Zhang、Xiaogang Wang、Xiaolei Huang、および Dimitris N Metaxas. Stackgan: スタックされた敵対的生成ネットワークを使用したテキストからフォトリアリスティックな画像への合成. ICCV、pp. 5907–5915 、2017年。
- Han Zhang、Jing Yu Koh、Jason Baldridge、Honglak Lee、および yingfei Yang.テキストから画像への生成のためのクロスモーダル対照学習.CVPR において、833–842 ページ、2021 年。
著者リスト
Uriel Singer +、Adam Polyak +、Thomas Hayes +、Xi ying +、Jie An、Songyang Zhang、Qiyuan Hu、Harry Yang、Oron Ashual、Oran Gafni、Devi Parikh + 、 Sonal Gupta +、Yaniv Taigman +
Meta AI
注+はこの論文の主な貢献者です。連絡著者: ウリエル・シンガー[email protected]
次に、バイキュービック補間を使用してサンプルを 512 まで減らし、よりクリーンな美しさを実現します。高解像度ビデオのクリーンな美しさを維持することは、仕事の未来の一部です。↩︎
このモデルを使用します: https://github.com/GantMan/nsfw_model ↩︎
これらの 1 億クリップはすべて 310 万のビデオから派生したものです。HD-VILA-10M サブセットからビデオごとに 3 つのクリップをランダムにダウンロードしました。↩︎