序文
1. これは、データセット、トレーニング コード、検出モデル コード、変換モデル、およびモデルを展開してプロジェクトに適用する方法の完全なプロセスを含む、ヘルメットを着用するかどうかを検出するための完全なプロジェクトです。
2. トレーニングおよび開発環境は win10、グラフィックス カード RTX3080、cuda10.2、cudnn7.1、OpenCV4.5、yolov5 は 2020 年 8 月 13 日にリリースされた 5s モデルを使用しています。バージョン v3.0、ncnn バージョンは20210525 ; C++ IDE vs2019、Anaconda 3.5。
3. 達成された効果:




1. 環境のインストール
1. まず、anaconda 環境をインストールします(ここでは Anaconda 3.5 を使用しています)。
2. 環境を起動し、管理者として環境を実行してみます。
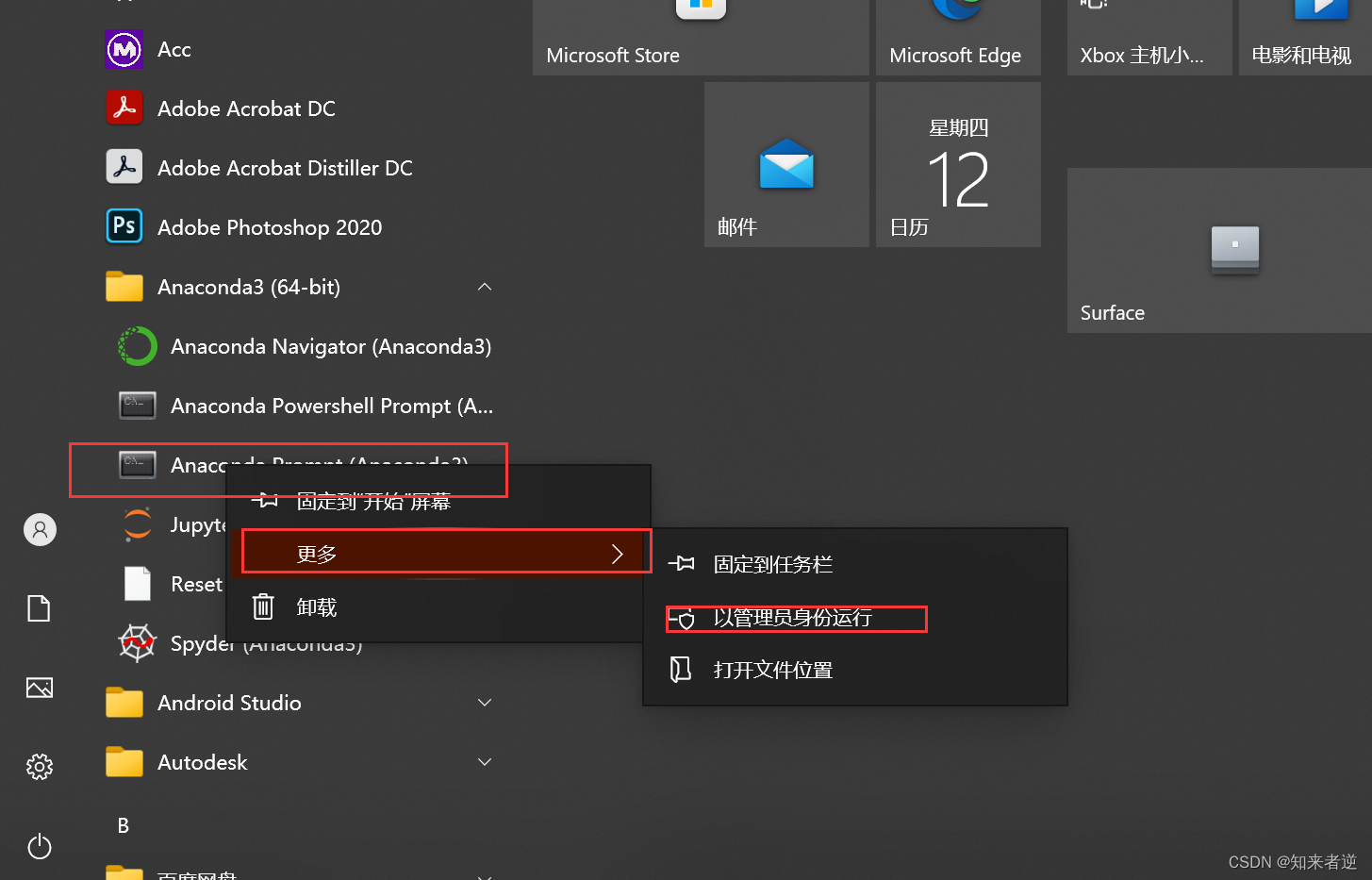
3. 環境を構築する
conda create --name yolov5 python=3.7
activate yolov5
2. 依存関係をインストールする
git clone https://github.com/ultralytics/yolov5.git
cd yolov5
pip install -r requirements.txt
また
git clone https://github.com/ultralytics/yolov5.git
cd yolov5
conda install pytorch torchvision cudatoolkit=10.2 -c pytorch
pip install cython matplotlib tqdm opencv-python tensorboard scipy pillow onnx pyyaml pandas seaborn
2. データ処理
1. ラベリングデータ
ここで判定するのは「人体」「ヘルメットを着用している人の頭部」「ヘルメットを着用していない人の頭部」の3種類で、ラベリングツールはVOC2007に準拠したlabelImgを使用します。データ 注釈の注釈形式。
頭にかぶるヘルメットのみにマークが付き、頭部と一緒にマークされ、手に持ったり地面に置いたりするヘルメットにはマークが付きません。

2. データの加工
ラベル付けされたデータの形式は voc ですが、ここで使用する yolo はデータを yolo の txt 形式に変換し、トレーニング セットとテスト セットに分割する必要があります。
Python スクリプトを使用してデータを処理するgenerate_txt.py
import os
import glob
import argparse
import random
import xml.etree.ElementTree as ET
from PIL import Image
from tqdm import tqdm
def get_all_classes(xml_path):
xml_fns = glob.glob(os.path.join(xml_path, '*.xml'))
class_names = []
for xml_fn in xml_fns:
tree = ET.parse(xml_fn)
root = tree.getroot()
for obj in root.iter('object'):
cls = obj.find('name').text
class_names.append(cls)
return sorted(list(set(class_names)))
def convert_annotation(img_path, xml_path, class_names, out_path):
output = []
im_fns = glob.glob(os.path.join(img_path, '*.jpg'))
for im_fn in tqdm(im_fns):
if os.path.getsize(im_fn) == 0:
continue
xml_fn = os.path.join(xml_path, os.path.splitext(os.path.basename(im_fn))[0] + '.xml')
if not os.path.exists(xml_fn):
continue
img = Image.open(im_fn)
height, width = img.height, img.width
tree = ET.parse(xml_fn)
root = tree.getroot()
anno = []
xml_height = int(root.find('size').find('height').text)
xml_width = int(root.find('size').find('width').text)
if height != xml_height or width != xml_width:
print((height, width), (xml_height, xml_width), im_fn)
continue
for obj in root.iter('object'):
cls = obj.find('name').text
cls_id = class_names.index(cls)
xmlbox = obj.find('bndbox')
xmin = int(xmlbox.find('xmin').text)
ymin = int(xmlbox.find('ymin').text)
xmax = int(xmlbox.find('xmax').text)
ymax = int(xmlbox.find('ymax').text)
cx = (xmax + xmin) / 2.0 / width
cy = (ymax + ymin) / 2.0 / height
bw = (xmax - xmin) * 1.0 / width
bh = (ymax - ymin) * 1.0 / height
anno.append('{} {} {} {} {}'.format(cls_id, cx, cy, bw, bh))
if len(anno) > 0:
output.append(im_fn)
with open(im_fn.replace('.jpg', '.txt'), 'w') as f:
f.write('\n'.join(anno))
random.shuffle(output)
train_num = int(len(output) * 0.9)
with open(os.path.join(out_path, 'train.txt'), 'w') as f:
f.write('\n'.join(output[:train_num]))
with open(os.path.join(out_path, 'val.txt'), 'w') as f:
f.write('\n'.join(output[train_num:]))
def parse_args():
parser = argparse.ArgumentParser('generate annotation')
parser.add_argument('--img_path', type=str, help='input image directory')
parser.add_argument('--xml_path', type=str, help='input xml directory')
parser.add_argument('--out_path', type=str, help='output directory')
args = parser.parse_args()
return args
if __name__ == '__main__':
args = parse_args()
class_names = get_all_classes(args.xml_path)
print(class_names)
convert_annotation(args.img_path, args.xml_path, class_names, args.out_path)
Python スクリプトを実行します。
python generate_txt.py --img_path data/XXXXX/JPEGImages --xml_path data/XXXXX/Annotations --out_path data/XXXXX
実行後は正規化されたtxt形式の座標に自動的に変換され、指定したディレクトリに学習に使用する2つのtxtファイルtrain.txtとval.txtに変換できます。
3. トレーニングモデル
1. ここで使用するモデルは s より大きく精度の高い m モデルです。model/yolov5m.yaml で nc の数を変更します。
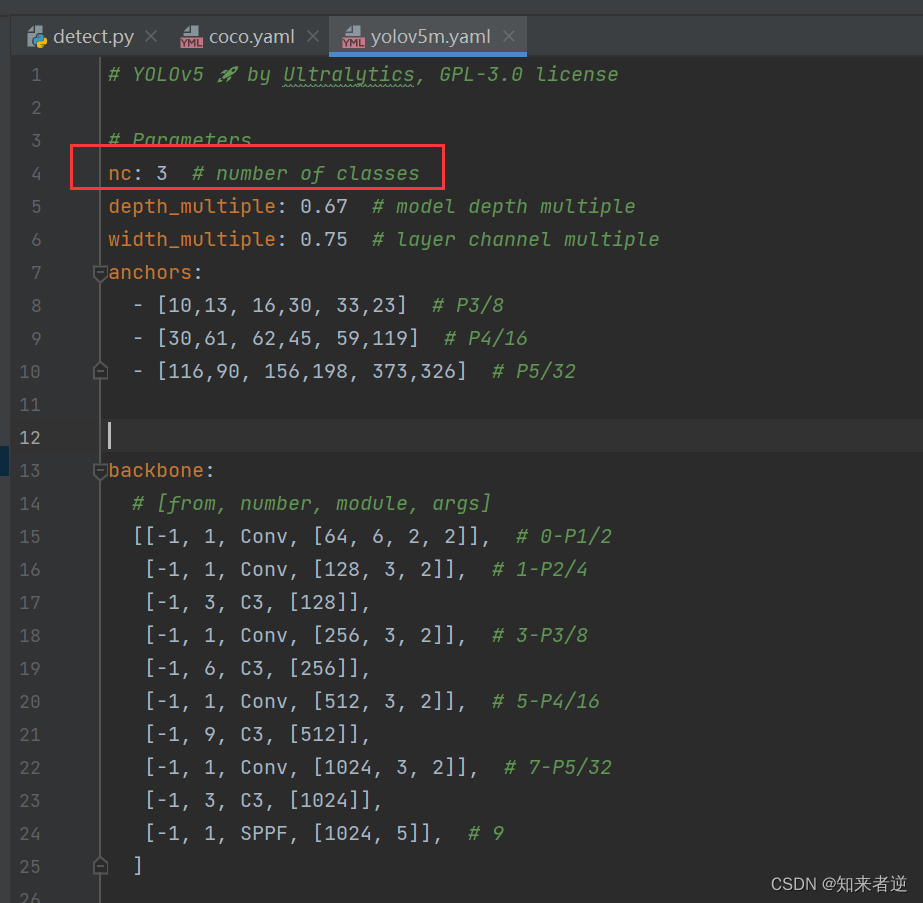
2.在data目录下添加一个复制coco.yaml重新命名为helmet.yaml的训练数据配置文件。
```markup
# download command/URL (optional)
download: bash data/scripts/get_voc.sh
# 训练集txt与验证集txt路径
train: data/train.txt
val: data/val.txt
# 总类别数
nc: 3
# 类名
names: ['person', 'head', 'helmet']
3. トレーニングパラメータ
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='yolov5s.pt', help='initial weights path') # 权重文件,是否在使用预训练权重文件
parser.add_argument('--cfg', type=str, default='', help='model.yaml path') # 网络配置文件
parser.add_argument('--data', type=str, default='data/coco128.yaml', help='data.yaml path') # 训练数据集目录
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.yaml', help='hyperparameters path') #超参数配置文件
parser.add_argument('--epochs', type=int, default=300) # 训练迭代次数
parser.add_argument('--batch-size', type=int, default=32, help='total batch size for all GPUs') # batch-size大小
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes') # 训练图像大小
parser.add_argument('--rect', action='store_true', help='rectangular training') #矩形训练
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training') # 是否接着上一次的日志权重继续训练
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint') # 不保存
parser.add_argument('--notest', action='store_true', help='only test final epoch') # 不测试
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters') #超参数范围
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training') #是否缓存图像
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu') # 用GPU或者CPU进行训练
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%') #是否多尺度训练
parser.add_argument('--single-cls', action='store_true', help='train as single-class dataset') # 是否一个类别
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer') # 优化器先择
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
parser.add_argument('--log-imgs', type=int, default=16, help='number of images for W&B logging, max 100')
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers') #win不能改,win上改不改都容易崩
parser.add_argument('--project', default='runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
opt = parser.parse_args()
4. トレーニングコマンド
- シングルカード:
python train.py --cfg models/yolov5s.yaml --data data/ODID.yaml --hyp data/hyps/hyp.scratch.yaml --epochs 100 --multi-scale --device 0
- ドカ:
python train.py --cfg models/yolov5s.yaml --data data/ODID.yaml --hyp data/hyps/hyp.scratch.yaml --epochs 100 --multi-scale --device 0,1
4. モデルのテスト
1. テストモデル
python detect.py --source TestImagesPath --weights ./weights/yolov5m.pt
2. 検出結果を出力します。画像の検出値は約 1 です。




5. モデルの展開
1. 変換モデル モデル
のデプロイには多くのオプションがあります。デプロイ言語には C++ または Python を使用できます。推論フレームワークには onnxruntime、libtorch、mnn、ncnn などを使用できます。ここでは、私が使い慣れている C++ と NCNN を使用します。
変換モデル
python models/export.py --weights weights/yolov5m.pt --img 640 --batch 1
yolov5m.onnx モデルが生成されます。onnx モデルは、推論に onnxruntime または opencv の dnn を使用できます。
2. ncnn モデルに転送します。
モデルの簡略化、モデルの簡略化 ここではまだ古い 0.36 バージョンを使用していますが、最新の簡略化バージョンを使用しようとしましたが、簡略化モデルにはまだ onnx プレフィックスが付いた大量の操作があり、onnxruntime と ncnn の後では、推論することは完全に不可能です。長い間働いていましたが、うまくいかず、あきらめました。onnx-simplifier: https://github.com/daquexian/onnx-simplifier
onnx から ncnn モデル
onnx2ncnn yolov5s-sim.onnx yolov5s.param yolov5s.bin
- onnx を ncnn モデルに変換すると、サポートされていないスライス ステップが大量に出力されます。, これはフォーカス モジュール変換のエラー レポートです。
ここでは、nihui ボスの Zhihu 記事を直接参照して変更することができます。記事のアドレス: https://zhuanlan.zhihu.com/p/275989233。
3. NCNN 推論コード、動的に登録された YoloV5Focus レイヤー。
#include "YoloV5Detect.h"
class YoloV5Focus : public ncnn::Layer
{
public:
YoloV5Focus()
{
one_blob_only = true;
}
virtual int forward(const ncnn::Mat& bottom_blob, ncnn::Mat& top_blob, const ncnn::Option& opt) const
{
int w = bottom_blob.w;
int h = bottom_blob.h;
int channels = bottom_blob.c;
int outw = w / 2;
int outh = h / 2;
int outc = channels * 4;
top_blob.create(outw, outh, outc, 4u, 1, opt.blob_allocator);
if (top_blob.empty())
return -100;
#pragma omp parallel for num_threads(opt.num_threads)
for (int p = 0; p < outc; p++)
{
const float* ptr = bottom_blob.channel(p % channels).row((p / channels) % 2) + ((p / channels) / 2);
float* outptr = top_blob.channel(p);
for (int i = 0; i < outh; i++)
{
for (int j = 0; j < outw; j++)
{
*outptr = *ptr;
outptr += 1;
ptr += 2;
}
ptr += w;
}
}
return 0;
}
};
DEFINE_LAYER_CREATOR(YoloV5Focus)
int initYolov5Net(std::string& param_path, std::string& bin_path, ncnn::Net& yolov5_net,bool use_gpu)
{
bool has_gpu = false;
yolov5_net.clear();
//CPU相关设置(只实现了安卓端)
/// 0 = all cores enabled(default)
/// 1 = only little clusters enabled
/// 2 = only big clusters enabled
//ncnn::set_cpu_powersave(2);
//ncnn::set_omp_num_threads(ncnn::get_big_cpu_count());
#if NCNN_VULKAN
ncnn::create_gpu_instance();
has_gpu = ncnn::get_gpu_count() > 0;
#endif
yolov5_net.opt.use_vulkan_compute = (use_gpu && has_gpu);
yolov5_net.opt.use_bf16_storage = true;
//动态注册层
yolov5_net.register_custom_layer("YoloV5Focus", YoloV5Focus_layer_creator);
//读取模型
int rp = yolov5_net.load_param(param_path.c_str());
int rb = yolov5_net.load_model(bin_path.c_str());
if (rp < 0 || rb < 0)
{
return -1;
}
return 0;
}
static inline float sigmoid(float x)
{
return static_cast<float>(1.f / (1.f + exp(-x)));
}
static void generateProposals(const ncnn::Mat& anchors, int stride, const ncnn::Mat& in_pad, const ncnn::Mat& feat_blob, float prob_threshold, std::vector<Object>& objects)
{
const int num_grid = feat_blob.h;
int num_grid_x;
int num_grid_y;
if (in_pad.w > in_pad.h)
{
num_grid_x = in_pad.w / stride;
num_grid_y = num_grid / num_grid_x;
}
else
{
num_grid_y = in_pad.h / stride;
num_grid_x = num_grid / num_grid_y;
}
const int num_class = feat_blob.w - 5;
const int num_anchors = anchors.w / 2;
for (int q = 0; q < num_anchors; q++)
{
const float anchor_w = anchors[q * 2];
const float anchor_h = anchors[q * 2 + 1];
const ncnn::Mat feat = feat_blob.channel(q);
for (int i = 0; i < num_grid_y; i++)
{
for (int j = 0; j < num_grid_x; j++)
{
const float* featptr = feat.row(i * num_grid_x + j);
// find class index with max class score
int class_index = 0;
float class_score = -FLT_MAX;
for (int k = 0; k < num_class; k++)
{
float score = featptr[5 + k];
if (score > class_score)
{
class_index = k;
class_score = score;
}
}
float box_score = featptr[4];
float confidence = sigmoid(box_score) * sigmoid(class_score);
if (confidence >= prob_threshold)
{
// yolov5/models/yolo.py Detect forward
// y = x[i].sigmoid()
// y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i].to(x[i].device)) * self.stride[i] # xy
// y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
float dx = sigmoid(featptr[0]);
float dy = sigmoid(featptr[1]);
float dw = sigmoid(featptr[2]);
float dh = sigmoid(featptr[3]);
float pb_cx = (dx * 2.f - 0.5f + j) * stride;
float pb_cy = (dy * 2.f - 0.5f + i) * stride;
float pb_w = pow(dw * 2.f, 2) * anchor_w;
float pb_h = pow(dh * 2.f, 2) * anchor_h;
float x0 = pb_cx - pb_w * 0.5f;
float y0 = pb_cy - pb_h * 0.5f;
float x1 = pb_cx + pb_w * 0.5f;
float y1 = pb_cy + pb_h * 0.5f;
Object obj;
obj.rect.x = x0;
obj.rect.y = y0;
obj.rect.width = x1 - x0;
obj.rect.height = y1 - y0;
obj.label = class_index;
obj.prob = confidence;
objects.push_back(obj);
}
}
}
}
}
static inline float intersectionArea(const Object& a, const Object& b)
{
cv::Rect_<float> inter = a.rect & b.rect;
return inter.area();
}
static void qsortDescentInplace(std::vector<Object>& faceobjects, int left, int right)
{
int i = left;
int j = right;
float p = faceobjects[(left + right) / 2].prob;
while (i <= j)
{
while (faceobjects[i].prob > p)
i++;
while (faceobjects[j].prob < p)
j--;
if (i <= j)
{
// swap
std::swap(faceobjects[i], faceobjects[j]);
i++;
j--;
}
}
#pragma omp parallel sections
{
#pragma omp section
{
if (left < j) qsortDescentInplace(faceobjects, left, j);
}
#pragma omp section
{
if (i < right) qsortDescentInplace(faceobjects, i, right);
}
}
}
static void qsortDescentInplace(std::vector<Object>& faceobjects)
{
if (faceobjects.empty())
return;
qsortDescentInplace(faceobjects, 0, faceobjects.size() - 1);
}
static void nmsSortedBboxes(const std::vector<Object>& faceobjects, std::vector<int>& picked, float nms_threshold)
{
picked.clear();
const int n = faceobjects.size();
std::vector<float> areas(n);
for (int i = 0; i < n; i++)
{
areas[i] = faceobjects[i].rect.area();
}
for (int i = 0; i < n; i++)
{
const Object& a = faceobjects[i];
int keep = 1;
for (int j = 0; j < (int)picked.size(); j++)
{
const Object& b = faceobjects[picked[j]];
// intersection over union
float inter_area = intersectionArea(a, b);
float union_area = areas[i] + areas[picked[j]] - inter_area;
// float IoU = inter_area / union_area
if (inter_area / union_area > nms_threshold)
keep = 0;
}
if (keep)
{
picked.push_back(i);
}
}
}
int targetDetection(cv::Mat& cv_src, ncnn::Net& yolov5_net, std::vector<Object>& objects, int target_size,
float prob_threshold, float nms_threshold)
{
int w = cv_src.cols, h = cv_src.rows;
float scale = 1.0f;
if (w > h)
{
scale = (float)target_size / (float)w;
w = target_size;
h = h * scale;
}
else
{
scale = (float)target_size / (float)h;
h = target_size;
w = w * scale;
}
ncnn::Mat ncnn_in = ncnn::Mat::from_pixels_resize(cv_src.data, ncnn::Mat::PIXEL_BGR2RGB, cv_src.cols, cv_src.rows, w, h);
//边缘扩展检测的尺寸
//源码在 yolov5/utils/datasets.py letterbox方法
int wpad = (w + 31) / 32 * 32 - w;
int hpad = (h + 31) / 32 * 32 - h;
ncnn::Mat in_pad;
ncnn::copy_make_border(ncnn_in, in_pad, hpad / 2, hpad - hpad / 2, wpad / 2, wpad - wpad / 2, ncnn::BORDER_CONSTANT, 114.f);
const float norm_vals[3] = {
1 / 255.f, 1 / 255.f, 1 / 255.f };
in_pad.substract_mean_normalize(0, norm_vals);
//创建一个提取器
ncnn::Extractor ex = yolov5_net.create_extractor();
ex.input("images", in_pad);
std::vector<Object> proposals;
//stride 8
{
ncnn::Mat out;
ex.extract("750", out);
ncnn::Mat anchors(6);
anchors[0] = 10.f;
anchors[1] = 13.f;
anchors[2] = 16.f;
anchors[3] = 30.f;
anchors[4] = 33.f;
anchors[5] = 23.f;
std::vector<Object> objects8;
generateProposals(anchors, 8, in_pad, out, prob_threshold, objects8);
proposals.insert(proposals.end(), objects8.begin(), objects8.end());
}
stride 16
{
ncnn::Mat out;
ex.extract("771", out);
ncnn::Mat anchors(6);
anchors[0] = 30.f;
anchors[1] = 61.f;
anchors[2] = 62.f;
anchors[3] = 45.f;
anchors[4] = 59.f;
anchors[5] = 119.f;
std::vector<Object> objects16;
generateProposals(anchors, 16, in_pad, out, prob_threshold, objects16);
proposals.insert(proposals.end(), objects16.begin(), objects16.end());
}
// stride 32
{
ncnn::Mat out;
ex.extract("791", out);
ncnn::Mat anchors(6);
anchors[0] = 116.f;
anchors[1] = 90.f;
anchors[2] = 156.f;
anchors[3] = 198.f;
anchors[4] = 373.f;
anchors[5] = 326.f;
std::vector<Object> objects32;
generateProposals(anchors, 32, in_pad, out, prob_threshold, objects32);
proposals.insert(proposals.end(), objects32.begin(), objects32.end());
}
// sort all proposals by score from highest to lowest
qsortDescentInplace(proposals);
// apply nms with nms_threshold
std::vector<int> picked;
nmsSortedBboxes(proposals, picked, nms_threshold);
int count = picked.size();
objects.resize(count);
for (int i = 0; i < count; i++)
{
objects[i] = proposals[picked[i]];
// adjust offset to original unpadded
float x0 = (objects[i].rect.x - (wpad / 2)) / scale;
float y0 = (objects[i].rect.y - (hpad / 2)) / scale;
float x1 = (objects[i].rect.x + objects[i].rect.width - (wpad / 2)) / scale;
float y1 = (objects[i].rect.y + objects[i].rect.height - (hpad / 2)) / scale;
// clip
x0 = std::max(std::min(x0, (float)(cv_src.cols - 1)), 0.f);
y0 = std::max(std::min(y0, (float)(cv_src.rows - 1)), 0.f);
x1 = std::max(std::min(x1, (float)(cv_src.cols - 1)), 0.f);
y1 = std::max(std::min(y1, (float)(cv_src.rows - 1)), 0.f);
objects[i].rect.x = x0;
objects[i].rect.y = y0;
objects[i].rect.width = x1 - x0;
objects[i].rect.height = y1 - y0;
}
return 0;
}
void drawObjects(const cv::Mat& cv_src, const std::vector<Object>& objects,std::vector<std::string> & class_names)
{
cv::Mat cv_detect = cv_src.clone();
for (size_t i = 0; i < objects.size(); i++)
{
const Object& obj = objects[i];
std::cout << "Object label:" << obj.label << " Object prod:" << obj.prob
<<" Object rect" << obj.rect << std::endl;
cv::rectangle(cv_detect, obj.rect, cv::Scalar(255, 0, 0));
std::string text = class_names[obj.label] + " " +std::to_string(int(obj.prob * 100)) +"%";
int baseLine = 0;
cv::Size label_size = cv::getTextSize(text, cv::FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
int x = obj.rect.x;
int y = obj.rect.y - label_size.height - baseLine;
if (y < 0)
y = 0;
if (x + label_size.width > cv_detect.cols)
x = cv_detect.cols - label_size.width;
cv::rectangle(cv_detect, cv::Rect(cv::Point(x, y), cv::Size(label_size.width, label_size.height + baseLine)),
cv::Scalar(255, 255, 255), -1);
cv::putText(cv_detect, text, cv::Point(x, y + label_size.height),
cv::FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar(0, 0, 0));
}
cv::imshow("image", cv_detect);
}
int main(void)
{
std::string parma_path = "models/ODIDF16.param";
std::string bin_parh = "models/ODIDF16.bin";
ncnn::Net yolov5_net;
initYolov5Net(parma_path,bin_parh,yolov5_net,true);
std::vector<std::string> class_names{
"ida", "idb", "idback", "idhead" };
std::string path = "images";
std::vector<std::string> filenames;
cv::glob(path, filenames, false);
for (auto name : filenames)
{
cv::Mat cv_src = cv::imread(name);
if (cv_src.empty())
{
continue;
}
std::vector<Object> objects;
double start = static_cast<double>(cv::getTickCount());
targetDetection(cv_src, yolov5_net, objects);
double time = ((double)cv::getTickCount() - start) / cv::getTickFrequency();
std::cout << name <<"Detection time:" << time << "(second) " << std::endl;
drawObjects(cv_src, objects, class_names);
cv::waitKey();
}
return 0;
}
実行結果:
ハゲ頭:


ヘルメットを着用:


帽子をかぶっていると、それがヘルメットではないことも検出できます

通常の状態:



6. ソースコード構成
1. C++ デプロイメント モデルのプロジェクト ソース アドレス: https://download.csdn.net/download/matt45m/85384651
2. トレーニング コード アドレス: https://download.csdn.net/download/matt45m/85384016
4. 設定インクルードディレクトリ
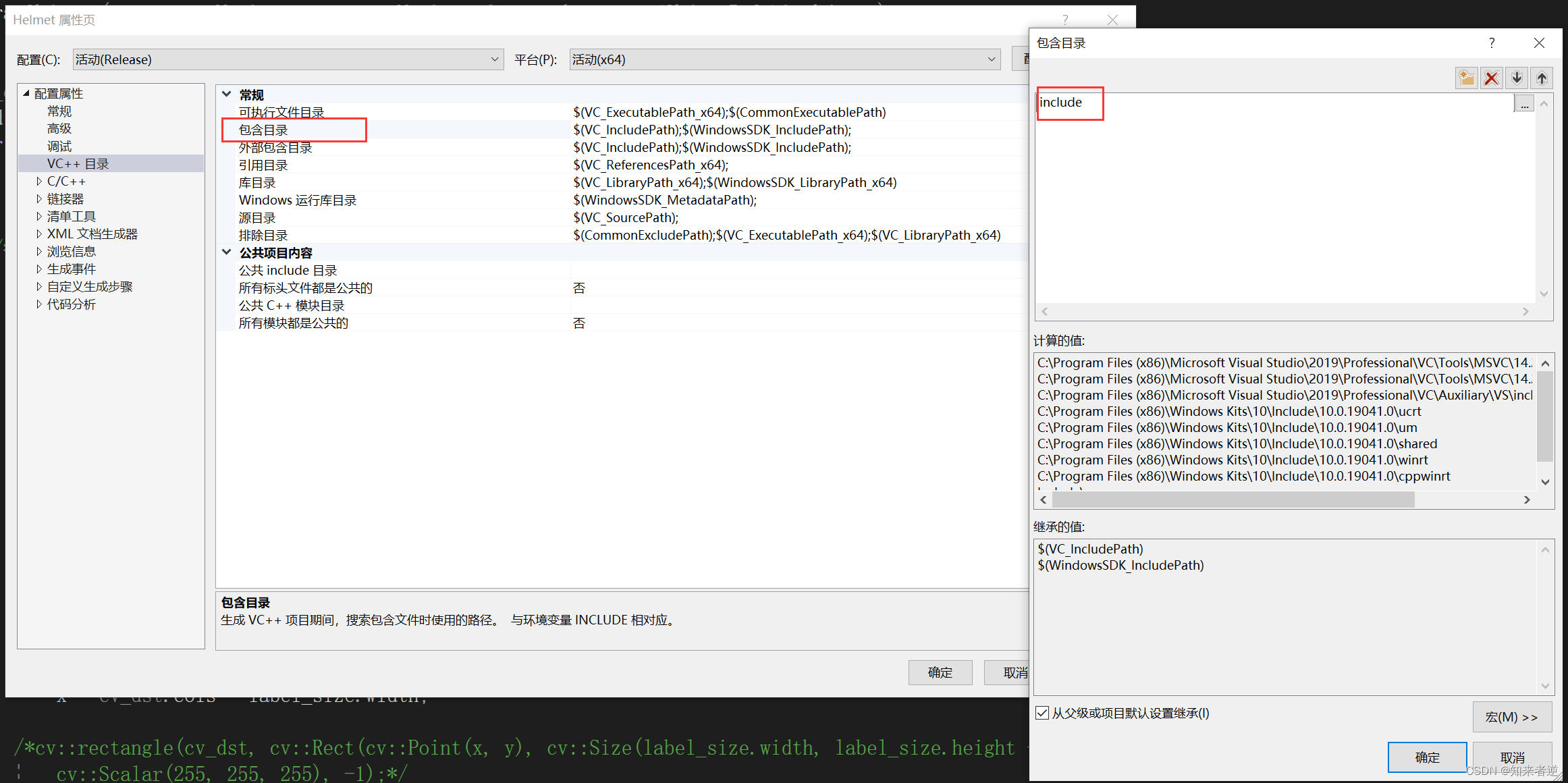
5. lib ディレクトリを設定します。
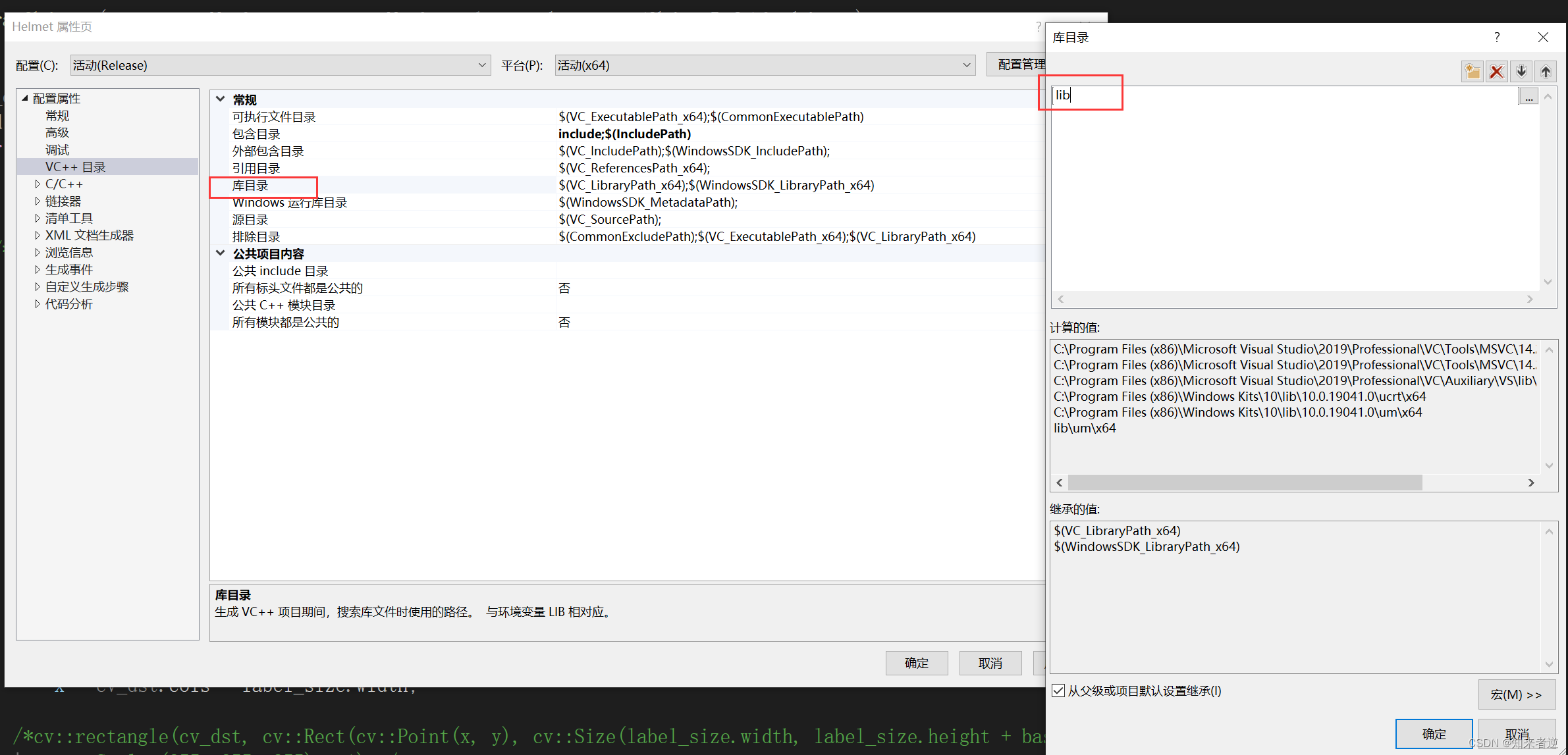
5. 依存関係を追加します。
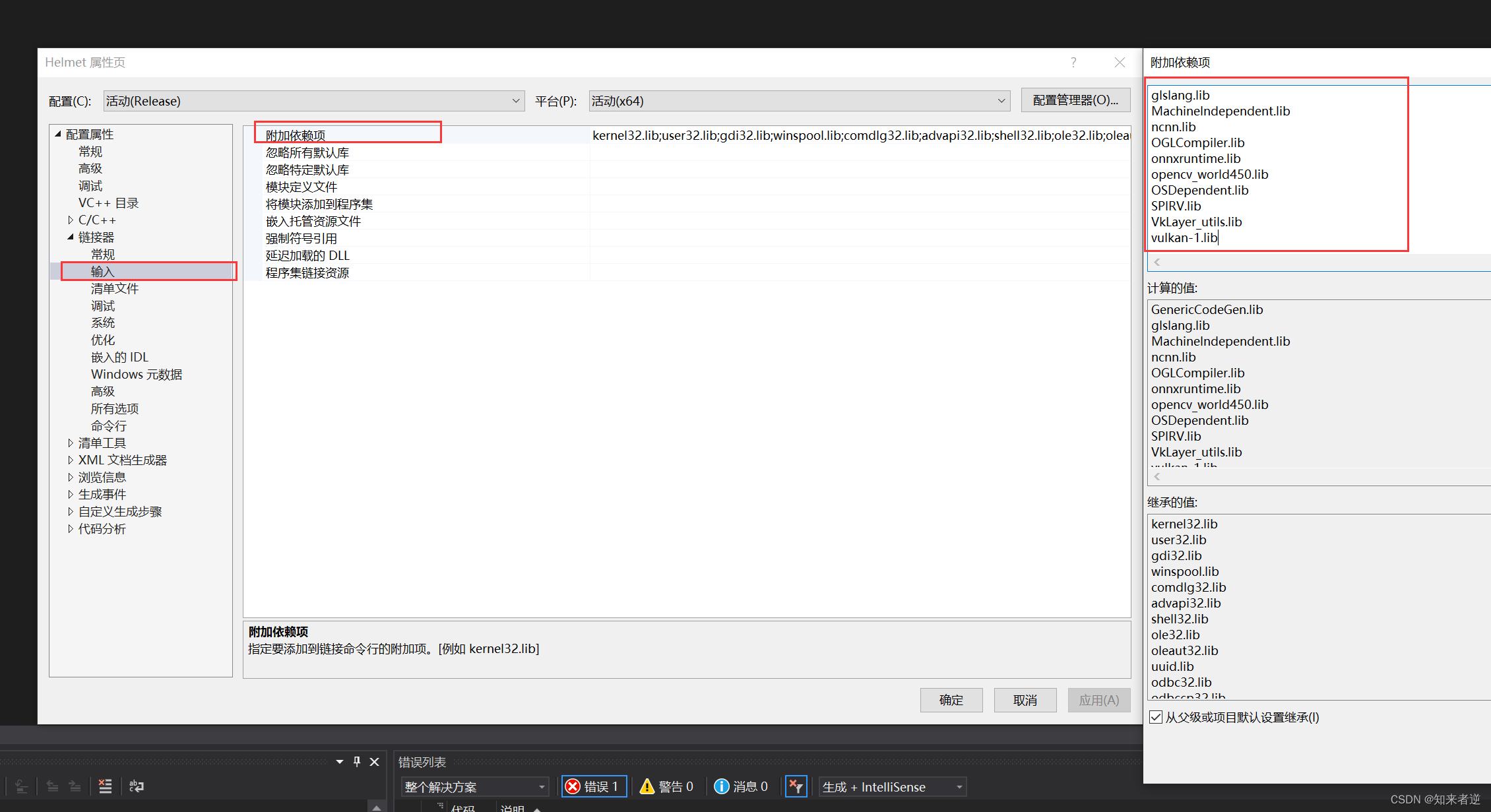
GenericCodeGen.lib
glslang.lib
MachineIndependent.lib
ncnn.lib
OGLCompiler.lib
onnxruntime.lib
opencv_world450.lib
OSDependent.lib
SPIRV.lib
VkLayer_utils.lib
vulkan-1.lib
4. 動作環境の設定
