私たちはデータ爆発の時代に生きています。IDC のデータによると、2022 年だけでも、人間が作成するデータは 97ZB を超えます。2012 年の時点で、人間が作成したすべての印刷物のデータ量は 200PB であることを知っておく必要があります。それはわずか 2022 年です。1 年間に作成されるデータ量の 1/500,000 です。中国のデータ量規模は2022年の23.88ZBから2027年には76.6ZBに増加し、年平均成長率は26.3%で世界第1位になると予測されている。
データ量は急速に増加しており、データドリブン企業はより大きな課題に直面しています

ビッグデータの爆発的な増加は、企業の発展に機会と課題の両方をもたらします。データ量の急増により、企業はデータに対するさらなる価値創造が必要となり、それを推進していく過程で、自然とデータドリブンな企業へと変革していきます。
そして、データドリブン企業は 6 つの大きな課題に直面しています: ほとんどの企業は明確なデータ プラットフォーム戦略を欠いている、データの高速増加によってもたらされるストレージ、分析、データ イノベーションのコストが高すぎる、最大化するシナリオを見つけるのが難しいデータの価値 ビジネス革新をサポートするためにどのような新しいテクノロジーや製品を使用すべきかが明確ではない 企業の内部スキルが一部の革新的なデータ プロジェクトをサポートするには不十分である 企業にデータ ガバナンスとセキュリティ保護の能力が欠けている
課題をチャンスに変えるにはどうすればよいでしょうか? まず、データの孤島を打破し、データの統合と融合の分析を実現します。2 つ目は、革新的な製品を使用してイノベーション エンジンを再構築する、データ駆動型のインテリジェント イノベーション、3 つ目は、企業がデータを使用してビジネス イノベーションを推進できるようにクラウド ネイティブ アーキテクチャを採用することです。
従来のビッグデータ テクノロジー アーキテクチャの制限を打ち破り、クラウド ネイティブと K8 が連携して動作します

Hadoop を中心としたビッグ データ エコシステムは、2006 年にオープンソース化されて以来、ほとんどの企業がビッグ データ プラットフォームを構築するために選択してきました。しかし、人々がそれを深く使用するにつれて、次のような問題がますます発生します。システムコンポーネントが複雑で、クラスタリソースの利用効率が低く、運用保守の作業負荷が高く、データアプリケーション開発の反復効率が低く、新しい開発ツールの統合が非常に複雑です。これらの問題は、企業のデジタル変革の加速とアップグレードにとって重要な障害となっています。
従来のビッグデータプラットフォームが引き起こす問題を解決するには、Hadoopエコロジー技術の開発そのものに頼ることはできないため、最新の技術開発トレンド、つまりコンテナやK8s技術に代表されるクラウドネイティブに注目する必要があります。
2013 年のコンテナ プロジェクトと 2014 年の K8s プロジェクトの正式リリース後、クラウド ネイティブ テクノロジは急速に発展しました。現在、すべての主要なパブリック クラウド ベンダーが K8 をサポートしており、何百ものテクノロジー企業が K8 の反復と更新に投資を続けています。現在、CNCFの生態パノラマには1,000以上のクラウドネイティブ技術製品が含まれており、データベース、メッセージレベルのストリーム処理、スケジューリングとタスクの配置、ストレージシステムなど10以上の技術分野をカバーしている。
2021 年は、クラウド ネイティブのビッグ データ テクノロジの開発におけるマイルストーンとなるはずです。2021 年 3 月に、Apache は、Spark 3.1 が K8s を正式にサポートすると発表しました。さらに、2021 年 5 月には、Apache Kafka の背後にある営利会社 Confluent も、K8s で Confluent をリリースしました。 . K8 上で実行される、非公開でリリースされた Kafka 実稼働クラスター システム。これら 2 つの重要な出来事は、ビッグ データ プラットフォームのクラウド ネイティブ化が一般的な傾向であることを示しています。この傾向に従って、Hadoop は徐々に K8 に移行しています。
先進的なクラウド ネイティブへの道、ビッグ データ プラットフォームの K8s への移行

この傾向に伴い、ますます多くの企業がビジネス システムの負荷をクラウド ネイティブなものに徐々に変換し、Kubernetes ベースのプライベート クラウド プラットフォームまたはパブリック クラウド プラットフォームに移行した後、クラウド ネイティブ システムの外部で従来のビッグ データ プラットフォームのセットを独立して実行しています。運用により、多くの不必要な複雑さとリソースの無駄が追加されました。
そこで、Zhilingyun が独自に開発したクラウドネイティブ アーキテクチャに基づく Kubernetes ビッグ データ プラットフォーム (略称 KDP) は、上記の問題を解決するための重要なプラットフォームです。ビッグデータプラットフォームをK8sに移行することで、国内企業がK8sを利用する場合、その多くがクラウドコンピューティング関連のスケジューリングを行っているが、ビッグデータの分野では従来のビッグデータプラットフォームという別の複雑なシステムを管理しているという問題を解決する。 。
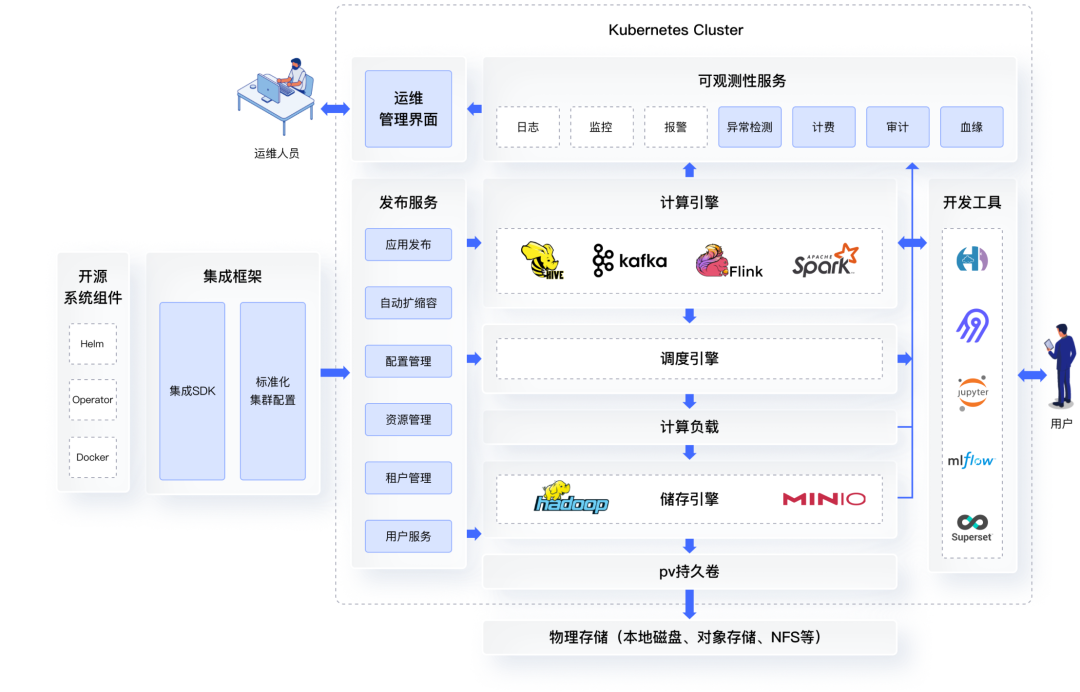
KDP システム アーキテクチャ図
KDP は、リソース スケジューリング プラットフォームとして Kubernetes を使用し、ビッグ データ コンポーネントとデータ アプリケーションを均一にスケジュールおよび管理します。このプラットフォームは、オープンソースのビッグデータコンピューティングおよびストレージエンジンの変換と統合に基づいて、Zhilingyunデータコンポーネントによって開発されたビッグデータ統合ベースを通じて、標準的な方法で主流のビッグデータの展開、リリース、管理、運用および保守を実現します。
たとえば、Windows リソース マネージャーを使用したことがあるはずです。KDP は、ビッグ データ コンポーネントのリソース マネージャーのようなものです。すべてのビッグ データ コンポーネントを管理し、ユーザーがそれらをより便利に使用できるようにすることで、システムの運用効率が大幅に向上し、運用と保守のコストが削減されます。 。
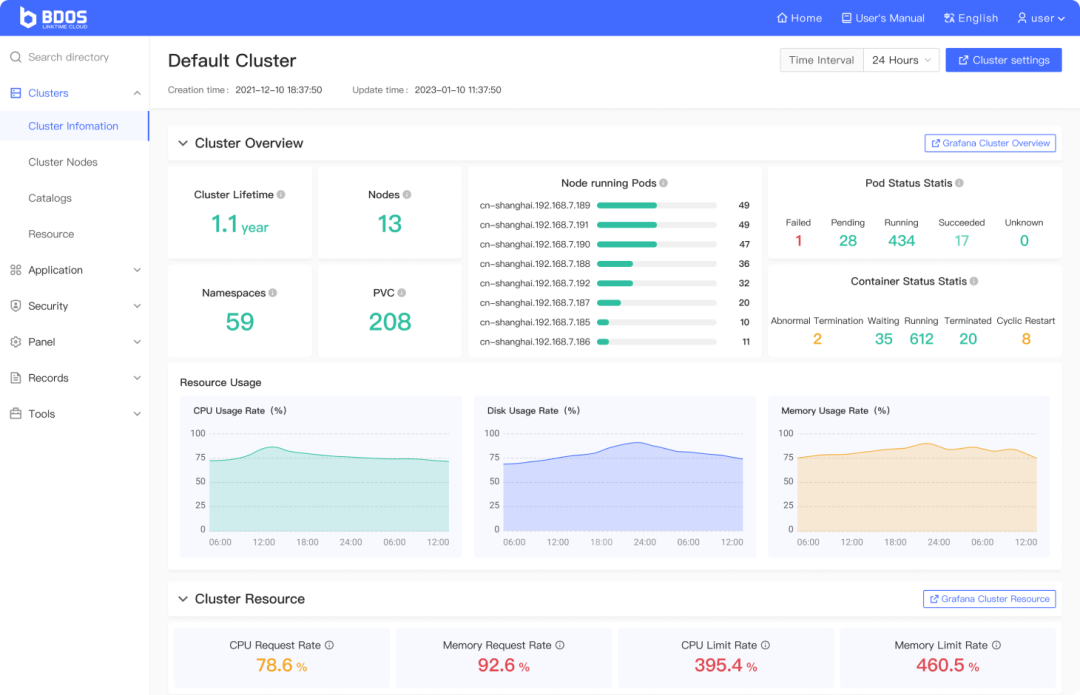
KDP 管理インターフェイスの図
KDP は企業に何をもたらすのでしょうか?
実際、KDP がユーザーにもたらす効率は本物です。例えば、大手事業者の例で言えば、データセンター内には約3万台のサーバーがあり、そのサーバーの稼働率は著しく不足しており、平均利用効率は20~30%程度にすぎません。しかし、KDP プラットフォームの統一されたリソース割り当ての下では、本来の効果を達成するために必要なデバイスは約 6,000 台だけで済み、設備、電力、スペースなどへの投資が大幅に節約され、顧客の競争力が向上します。
具体的には、KDP は構成管理を標準化することができます。つまり、統一された Kubernetes ファイル構成方法を採用して、ビッグ データ コンポーネントに対して標準化された構成管理を実行し、ビッグ データ コンポーネントと Kubernetes クラスターの統合を簡素化し、効率的なリソース利用を実現し、クラスター リソースを共有可能なものとして実現します。リソースプールはリアルタイムとオフラインの混合展開を実現し、クラスターリソースの利用率は従来のビッグデータプラットフォームの30%と比較して60%に増加し、Kubernetesの伸縮自在な拡張技術を使用して伸縮自在に拡張します。コンピューティング操作のパフォーマンスのボトルネックに対処し、コンピューティング リソースとクラスター リソースの動的な拡張を実現し、Kubernetes 標準の Operator 操作モードに基づいて、運用とメンテナンスを簡素化し、展開、アップグレード、拡張、バックアップなどを完了するための統合された操作とメンテナンス インターフェイスを実現します。ビッグデータコンポーネントの運用を強化し、運用と保守の効率を向上させます。
そして、ビッグデータ テクノロジー導入の特定のシナリオでは、このプラットフォームは従来のビッグデータ プラットフォームをうまく置き換え、企業がデジタル変革のプロセスでコストを削減し、効率を向上させるという目標を達成するのに役立ちます。
効率的なクラスターの導入と運用と保守: 一部の企業は、テクノロジー プロバイダーとして、複数の内部または外部の組織に対してビッグ データ クラスターを導入および実装する必要があります。優れたソリューションは比較的複雑で、多くの手動導入手順が必要であり、その結果、クラスターの導入サイクルが長くなります。 、高いプロジェクト実施コスト、複雑な運用および保守プロセス、および運用および保守担当者に対する高い要件。このシナリオでは、KDP を使用すると、実装プロジェクトの展開効率が大幅に向上し、プロジェクト実装の運用と保守にかかる人的コストと時間コストを削減できます。
IT アーキテクチャのリソース効率の向上: 一部の企業では、実稼働環境で複数の種類のデータ アプリケーション、さまざまな種類のストレージ エンジン、リアルタイムおよびバッチ コンピューティング ジョブを実行しています。従来のビッグ データ プラットフォーム環境では、通常、独立した仮想マシン クラスターを使用してこのような運用環境を展開するため、リソース使用率が低くなります。KDP を採用すると、企業は混合ジョブ スケジューリング、ストレージと計算の分離、洗練されたスケジューリングなどのプラットフォーム機能を使用して、全体的なリソース利用効率を向上させ、IT アーキテクチャ投資コストを削減できます。
従来のテクノロジーのアップグレード: 従来のビッグデータ プラットフォームでは、テクノロジー拡張の反復プロセスが遅いため、運用とメンテナンスで発生するパフォーマンスのボトルネックをタイムリーに解決できません。同時に、ビッグデータ コンポーネント間のソフトウェア パッケージの依存関係が非常に複雑です。新しいコンポーネントの統合には時間と労力がかかります。従来のビッグデータ プラットフォームを使用している技術チームは、運用と保守のプレッシャーで疲弊しており、ビジネス開発やデータ価値の発見に集中するエネルギーがありません。従来のビッグデータ プラットフォームがクラウドネイティブのビッグデータ プラットフォームに徐々に移行された後は、運用と保守の効率が大幅に向上し、運用と保守のコストが削減され、技術チームの生産性が解放されます。
セルフサービスのデジタル イノベーション: 一部の企業では、さまざまなビジネス部門にサービスを提供するために複数のビッグ データ クラスターが必要であり、ビジネス部門のデータ サイエンティストは、新しいクラウドネイティブな人工知能機械学習ツールを独自に試したいと考えています。明らかに、従来のビッグ データ プラットフォームではこのセルフサービスのニーズを満たすことができません。企業は、KDP 導入を通じてマルチプラットフォーム管理の効率を向上させ、データ分析および人工知能開発ツールのセルフサービス リリースを提供し、全体的なリソース消費のコストを削減し、データの価値と創造的なプロセスを加速します。
そのメリットは何にも代えがたいものであり、すべてのビッグデータコンポーネントが統一・標準化された管理を実現します。

まず、KDP はすぐに使用できる状態にあり、いくつかのコマンドと操作で簡単に使い始めることができます。第 2 に、視覚的な管理機能と可観測性機能を備えています。第 3 に、スケジューリングの革新とビッグ データ プラットフォームの移行を実現します。 K8sに。
もちろん、Zhiling Cloud KDP の最大の利点、および他の製品との違いは、すべての標準化されたビッグ データ コンポーネントが KDP のサポートにより Kubernetes 上でシームレスに実行できることです。さらに、KDP は業界のほぼすべてのメインストリーム Kubernetes リリースと完全に互換性があり、優れた互換性を備えています。
Kubernetes 上でビッグ データ プラットフォームを実行すると、次の 4 つの利点があります: 1 つ目は、統合管理、Kubernetes インフラストラクチャの再利用、複雑さの大幅な軽減、2 つ目は、リソース ミックス、共有リソース プールの効率的な使用で、各コンポーネントとクラスター全体が非常に優れています。柔軟な拡張が容易であること、第三に、システム全体が新しいアプリケーションの統合と迅速な反復を迅速にサポートできること、第四に、システムの安定性が大幅に向上し、運用と保守の効率が高いことです。KDP は、さまざまなビッグ データ コンポーネントのインストールと統合リソース管理に重点を置いています。たとえば、Windows エクスプローラーと比較すると、KDP はビッグ データ プラットフォームのリソース マネージャーに似ています。
現時点では、Zhilingyun KDP は次のタイプのユーザーに適しています。
クラウド ネイティブ開発者、データ エンジニア、データ アナリストなど、Kubernetes 上でビッグ データ コンポーネントとアプリケーションをデプロイして実行する必要があるユーザー。
従来の Hadoop プラットフォームのユーザー、システム効率を向上させ、運用保守コストを削減する必要があるユーザーなど、既存のビッグデータ システムのクラウドネイティブ変換と移行を実行する必要があるユーザー。
デジタル革新と変革のユーザー、複数のデータ シナリオとアプリケーションをサポートする必要があるユーザーなど、エンタープライズ レベルのクラウドネイティブ ビッグ データベース プラットフォームを迅速に構築する必要があるユーザー。
Zhilingyun KDP を使用してビッグ データ コンポーネントとアプリケーションを展開および実行する場合は、次の手順を参照してください。
まず、Zhilingyun KDP プラットフォームを Kubernetes クラスターにインストールする必要があります。これは、Kubernetes 上でビッグ データ コンポーネントとアプリケーションを管理できるコンテナ化されたクラウドネイティブ ビッグ データ プラットフォームです。
次に、Zhilingyun KDP プラットフォームで必要なビッグ データ コンポーネントとアプリケーション (Hive、Spark、Flink など) を選択し、関連パラメーターを構成できます。
最後に、Zhilingyun KDP プラットフォーム上でビッグ データ コンポーネントとアプリケーションを開始および停止し、関連するステータスとログを表示できます。Zhilingyun KDP プラットフォームを通じてデータ ソースとストレージにアクセスし、データの分析と処理を実行することもできます。
Kubernetes は、ビジネス アプリケーションのリリースと管理を標準化します。Zhiling Cloud の最終目標は、データ アプリケーションのリリースと使用を標準化することです。Zhilingyun は、コンテナ化されたクラウドネイティブのビッグデータ プラットフォームからスタートして、一歩ずつ前進しています。
● LinkTimeCloudについて_
Zhilingyun は、中国におけるクラウド ネイティブ ビッグ データ テクノロジーの革新的なリーダーであり、クラウド ネイティブ データ統合開発プラットフォームやクラウド ネイティブ データ資産運用を含む、クラウド ネイティブ ビッグ データ プラットフォームに基づくクラウド ネイティブ DataOps 製品シリーズを企業顧客に提供しています。プラットホーム。Zhilingyun は、企業が製品とサービスを通じてデータと AI のミドル プラットフォームを構築し、ビジネス データ機能のクローズド ループを簡単に構築し、デジタル オペレーション システムを確立し、最終的にデータ駆動型のデジタル変革を完了するのを支援します。
Zhilingyunは、エネルギー、教育、医療健康、モノのインターネット、金融などの分野で国内外の多くの有名企業にサービスを提供しており、クラウドネイティブエコロジーの分野で多くのパートナーと緊密な協力を行っています。それぞれの利点を最大限に活用して共同でサービスを提供し、企業顧客がより価値のあるクラウド コンピューティング、ビッグ データ製品、および技術サービスを提供します。
-フィン-

 KDPを理解するには「原文を読む」をクリックしてください
KDPを理解するには「原文を読む」をクリックしてください