どのブログでも、どのモットーでも、人は自分が思っている以上のことができる。
https://blog.csdn.net/weixin_39190382?type=blog
0. 序文
外れ値の検出も理解しやすくなります。
クラスメイトは全員70点のテストを受けて、あなたも70点のテストを受けました、それでいいのです。
生徒は全員テストで 90 点を取得しますが、あなたはテストで 70 点を取得します。
1.本文
Local Outlier Factor (LOF) は、密度ベースの古典的なアルゴリズムの
論文です: https://www.dbs.ifi.lmu.de/Publikationen/Papers/LOF.pdf
1.1 概要
外れ値検出には、主に統計、クラスタリング、分類、情報理論、距離、密度などに基づいた多くの方法がまだあります。
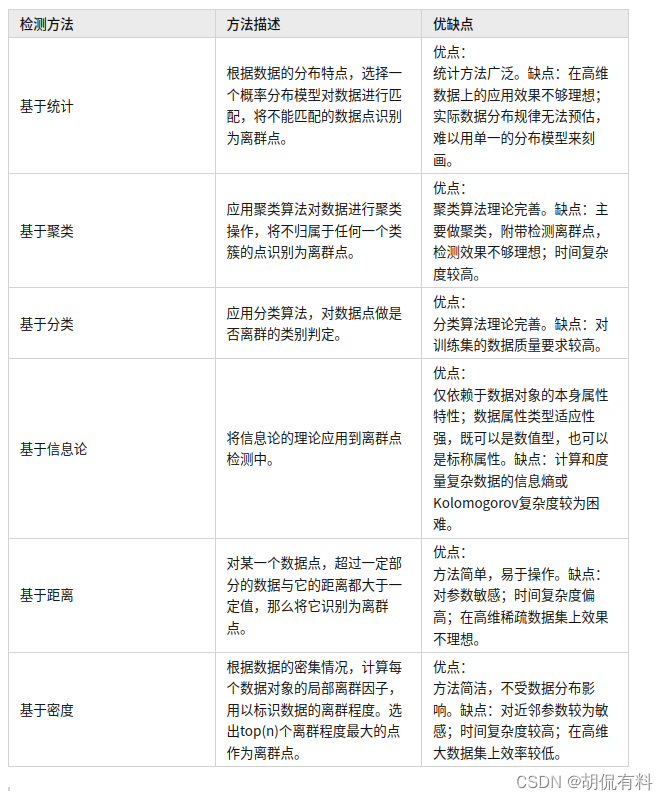
1.2 関連アプリケーション
アプリケーションは次のようにさらに広範囲にわたっています。
- 不正検知:クレジットカード、テレホンカードの不正使用
- 産業用検出: コンピュータ ネットワークへの違法侵入
- アクティビティ監視: 携帯電話の不正行為を検出するためのリアルタイムの携帯電話アクティビティ
- ネットワークパフォーマンス: コンピュータのネットワークパフォーマンスの検出
- 生態モニタリング:生態系の不均衡、異常な自然気候などの検出。
- 公共サービス: 公衆衛生における異常な病気の発生。
1.3 初期理解
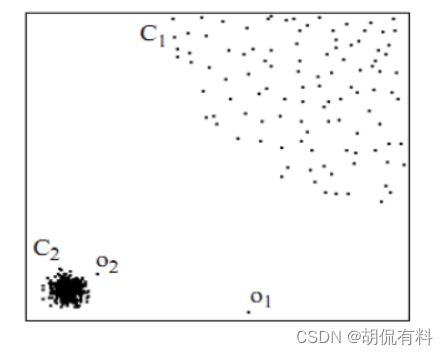
C1 と C2 は 2 つのクラスターを形成し、o1 と o2 は 2 つの外れ値であるため、タスクではそれらを見つける必要があります。
距離ベースの場合、o2から最も近いC1までの距離がC1の内部要素の距離よりも小さい場合があり、正しく検出できない場合があります。地球規模の密度に基づいた場合にも、同じことが当てはまる可能性があります。
したがって、正しいアプローチは局所密度に基づいており、これは私たちの直観的な感覚であり、その方法については以下を参照してください。
1.4 基本概念
(1). 2点間の距離
d(p,o): 2 点 P と O の間の距離を示します。
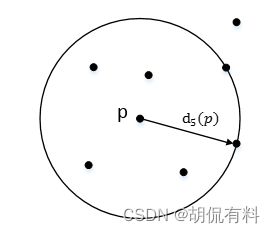
(2). k番目の距離
k 距離
距離点 p (近くから遠くまで) k 番目に近い点と p の間の距離。点 p のk 隣接距離と呼ばれ、k 距離§ で表されます。
(3). k番目の距離近傍
p
点 p の k 番目の距離近傍N k ( p ) N_k(p)Nk( p )は、 k 番目の距離を含む、 の k 番目の距離ですしたがって、 p∣ N k ( p ) ∣ ≥ k |N_k(p)| \geq k
の k 番目の近傍点の数∣N _k( p ) ∣≥k (pから同じ距離に点があるので、より大きい)
(4). 到達距離
到達距離
注:ここでは次のことを理解する必要があります。
点 o から点 p までのk 番目の到達可能な距離は、次のように定義されます。
到達距離 − 距離 k ( p , o ) = max ( k − 距離 ( o ) , d ( p , o ) ) 到達距離_k(p, o) = max( k-距離(o), d(p,o) )到着しました−距離_ _ _ _ _ _k( p ,o )=マックス( k _−距離( o ) 、_ _ _ _ _d ( p ,o ))
ここでは 2 つの距離のうちの最大の距離を示します。これは、以前のクラスタリング アルゴリズムで導入されたものとは少し異なります。これは主に、ここには **「kth」** がさらにあるためです。
実際、次の方が理解しやすいです。
- 点 p が点 oの k 番目の距離の外側にある場合、到達可能な距離は直線距離d(p,o)になります。
- 点 p が点 oから k 番目の距離以内にある場合、到達可能な距離はk 番目の距離d 5 ( o ) d_5(o) になります。d5( o )
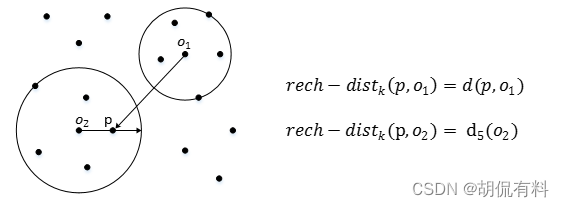
以下に示すように:
- p はo1 から k 番目の距離の外側にあるため、到達可能な距離は直線距離になります。
- p はo2 に対して k 番目の距離内にあるため、到達可能な距離はk 番目の距離です
(5). ローカル到達可能密度
ローカル到達可能性密度
密度は距離の逆数として表され、距離が小さいほど密度は大きくなり、その逆も同様です。
したがって、点 p のローカル到達可能密度は次のように表されます。
lrdk ( p ) = 1 / ( ∑ o ∈ N k ( p ) reack − distk ( p , o ) ∣ N k ( p ) ∣ ) lrd_k(p) = 1 / ( { \sum_{o \in N_k(p) )} reack-dist_k(p,o) \over |N_k(p)| })l r dk( p )=1/ (∣N _k( p ) ∣∑o ∈ Nk( p )再確認_ _−違う_ _ _k( p ,o ))
ローカル到達可能密度:平均距離ドメイン内の距離の合計を近傍内のポイントの数で割った
注:到達可能距離は非対称であるため (あなたは私に最も近いですが、私はあなたに最も近い地点ではありません)、到達可能密度も非対称です。
(6). 局所外れ値係数
ローカル到達可能密度
ポイントのローカル到達可能密度では、周囲のポイントの到達可能密度と比較する限り、このポイントが外れ値ポイントであるかどうかを判断する方法は非常に簡単です。
以下のように表現:
LOF k ( p ) = ∑ o ∈ N k ( p ) lrdk ( o ) ∣ N k ( p ) ∣ / lrdk ( p ) LOF_k(p) = { \sum_{o \in N_k(p)} { lrd_k( o) } \over |N_k(p)|} / lrd_k(p)ローフ_ _k( p )=∣N _k( p ) ∣∑o ∈ Nk( p )l r dk( o )/ l r dk( p )
表す:点 p のフィールド内の点N k ( p ) N_k(p)Nk( p )の局所的な到達可能な密度の点 p の到達可能な密度の比。
簡単に言うと、周りの人が 70 点のテストを受けたら、あなたもそのテストで 70 点を獲得しても問題ありません。
- 比率は 1 に近く、p がその隣接点密度に類似しており、隣接点と同じクラスターに属している可能性があることを示しています。
- 比率は 1 より小さく、p の密度は隣接する点の密度より高く、p は密度点です。
- 比率は 1 より小さく、p の密度はその隣接点の密度より小さく、p は外れ値である可能性があります。
1.5 アルゴリズム処理
- 各ポイントの lof スコアを計算します
- lof が大きいほど異常であり、その逆も同様です。
1.6 メリットとデメリット
A. 利点
- シンプルな思考。アルゴリズムがシンプルで実装が簡単
- グローバルよりもローカルを使用する方が合理的です
B. 短所
- LOF アルゴリズムにおけるローカル到達可能性密度の定義は、実際には、k 以上の繰り返しポイントは存在しないという仮定を意味します。k 個を超える重複点がある場合、それらの間の距離は 0 になり、密度は無限大になります。したがって、距離には小さな値が加算されるのが一般的である。
- 距離を計算する必要があるため計算オーバーヘッドが高く、高次元で大規模なデータには適していません。
参考
[1] https://www.cnblogs.com/wj-1314/p/14049195.html
[2] https://blog.csdn.net/wangyibo0201/article/details/51705966
[3] https://zhuanlan .zhihu.com/p/607616813
[4] https://zhuanlan.zhihu.com/p/28178476
[5] https://zhuanlan.zhihu.com/p/37753692
[6] https://zhuanlan.zhihu .com/p/385238291