ふふ〜
それは本当に疲れますか? 私は元の日で 1 日半を費やしましたが、まだその文についてコメントしていません。道士仲間は皆、自分の意見を持っています。
私の雑務は、また小さな予期せぬものを発見しました。これがオフラインでも起こるとは予想していませんでした。
以下は私自身の考えと分析の一部です。ご質問やご提案がございましたら、いつでも私にご連絡ください。
2023年第7回河南省高等教育情報セキュリティコンテスト-Yuwang Cup-ISCC2023オフラインコンテスト
以下は、misc と croto の洞察とアイデアです。
添付ファイルをダウンロードする
リンク: https://pan.baidu.com/s/1qaIl_ZJVaBY4Kpnkl3NFMw?pwd=lulu
抽出コード:
Baidu Netdisk スーパー メンバー V3 からの lulu --share
目次
皆様、お越しください( •̀ ω •́ )またお会いできるのを楽しみにしています
その他
色

txt ファイルは 1 つだけ
ファイルが開いて中のファイルが目の前に現れると、すごいですね。
多くの退役軍人はその方法をすぐに理解できると思います
これは非常に単純なRGB から画像への問題であり、言うまでもなく、ファイル名がまだヒントです
(もちろん初心者はもっと貯めないといけません)
ここでスクリプトに進みます(解析あり)
空の RGB 画像を作成するスクリプトを作成し、指定されたファイル「color.txt」からカラー情報を読み取り、そのカラー情報を画像の各ピクセルに 1 つずつ適用する必要があります。最後に、 im.show()メソッドによって画像が表示されます。
from PIL import Image
# 定义图像的宽度和高度
x = 500
y = 500
# 创建一个新的RGB图像
im = Image.new("RGB", (x, y))
# 打开并读取颜色文件
file = open("./color.txt", "r")
# 遍历图像的每个像素for i in range(x):
for j in range(y):
# 从文件中读取一行颜色信息,并去除换行符
line = file.readline().strip("\n")
# 去除括号并分割RGB值
line = line.replace("(", "").replace(")", "")
rgb = list(line.split(","))
# 将颜色值转换为整数,并将RGB值应用到当前像素
im.putpixel((i, j), (int(rgb[0]), int(rgb[1].strip(" ")), int(rgb[2].strip(" "))))
# 显示图像
im.show()コードの説明
上記のコードでは、画像処理に PIL (Python Imaging Library) ライブラリを使用します。具体的な手順は次のとおりです。
- Image クラスのインポート: Image モジュールを PIL ライブラリからインポートして、その関数とメソッドを使用できるようにします。
- 画像サイズを定義します。変数 x と y を使用して、画像の幅と高さをそれぞれ指定します。ここでは 500 に設定します。
- 空の画像を作成する: Image.new() 関数を使用して新しい RGB 画像オブジェクトを作成し、パラメータ「RGB」を使用して画像のカラー モードを赤、緑、青 (RGB) として指定し、幅とパラメータとして高さを指定します。
- カラー ファイルを開く: open() 関数を使用して「color.txt」という名前のファイルを開き、読み取り専用モードとして指定します。ファイルには、一連の RGB カラー値が 1 行に 1 つのカラー値として含まれている必要があります。
- 画像ピクセルの走査: ネストされた for ループを使用して画像の各ピクセルを走査します。外側のループは行数を制御し、内側のループは列数を制御します。
- カラー情報の読み取り: file.readline() 関数を使用してファイル内のカラー情報を行ごとに読み取り、.strip("\n") メソッドを使用して各行の末尾の改行文字を削除します。
- カラー情報を解析します。文字列操作を通じて括弧を削除し、.split(",") メソッドを使用して RGB 値を文字列のリストに分割します。
- カラー値を変換する: int() 関数を使用して RGB 文字列を整数に変換し、それをそれぞれ赤、緑、青の変数に割り当てます。
- カラー情報を適用する: im.putpixel() メソッドを使用して、現在走査されているピクセルに RGB 値を適用し、パラメーターを現在のピクセルの座標 (i, j) とカラー値 (赤、緑、青) として渡します。
- 画像表示:im.show()メソッドで生成された画像を表示します。
- コードを実行する前に「color.txt」という名前のファイルを準備し、1 行に 1 つの色の値の形式で保存していることを確認してください。たとえば、(255, 0, 0) は赤を意味します。
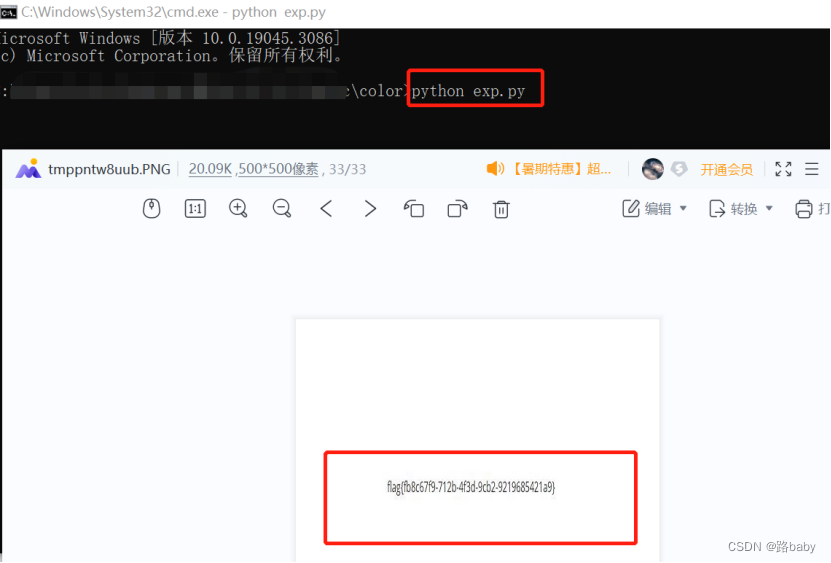
直接実行してフラグを取得します
フラグ{fb8c67f9-712b-4f3d-9cb2-9219685421a9}
お互い

ファイルはまだ 1 つだけですが、今回はオーディオです
歌はいいです
音声を確認するための最初のステップは何ですか
A: それはオーディオの最初のステップです。波形図を確認する必要があります。
B: やあ、misc の種類は関係ありません。最初のステップはファイルのソース コードを確認することです。
私: オーディオを入手するための最初のステップは、曲を楽しむことではないでしょうか? 草原で最も美しい花は燃えるような赤いサリランです
さて、本題に戻ります
実は最初に波形図も見ましたが、役に立ちませんでした。
それでは、ソースコードから 010 を見て始めましょう。
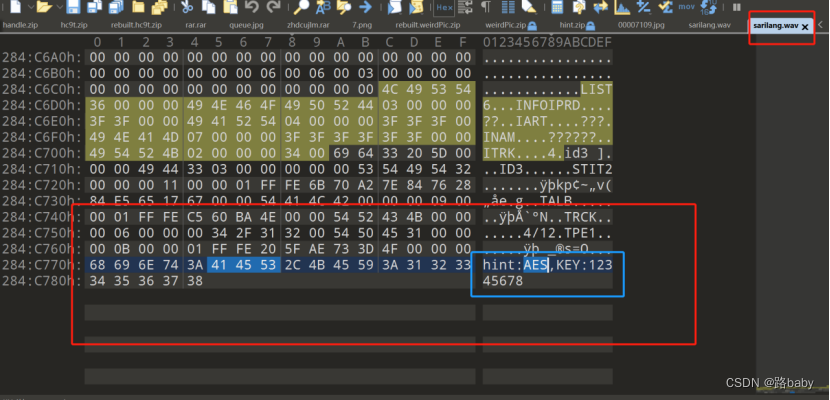
ファイルの最後に明らかなヒントが 見つかりました
AES暗号化パスワードは12345678です
しかし、これはオフラインで接続されていません
AESで暗号化されているステガノグラフィーソフトウェアについて考えてみましょう
Silent Eye (silenteye)どうやって知っているかは聞かないでください (コンピューター上のツールを使って試行錯誤するだけです) でもこのツールはかなり不人気です
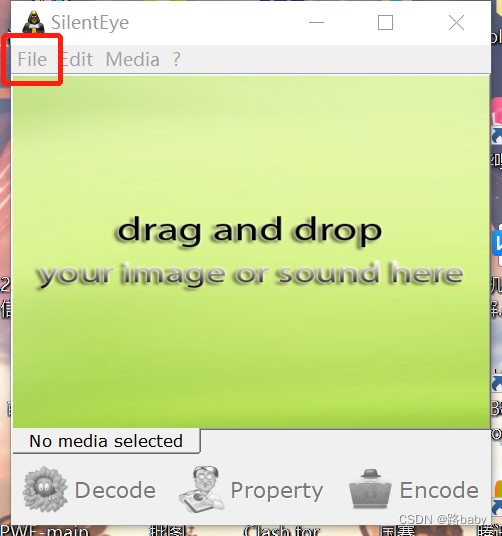
ファイルを選択し、復号化することを選択します


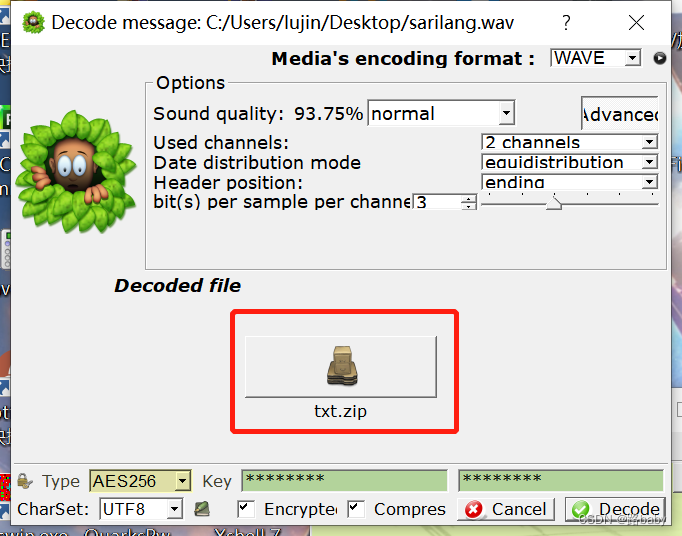
実行してtxtファイル(解凍されたもの)を取得します
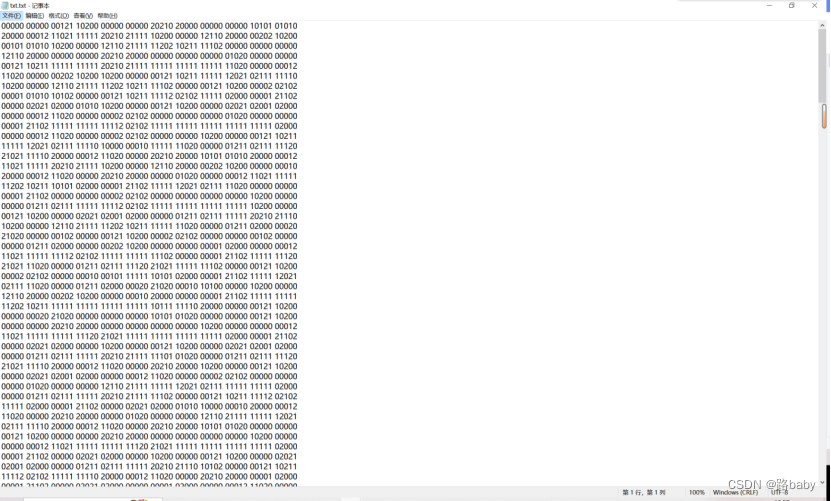
内部には012で構成される密なコードがあります
ああ、これが一番迷惑なことだ
わかった、わかった、それでは考えてみましょう
3文字で構成されるコードは何ですか
現時点ではいくつか思い出せません。
ただし、文字を変換する必要があるかどうかは注意深く観察しています。
0 は最も頻繁に変更されるわけではありません。
そして、長い考えが1つありました!
この2はあれですか?
次に、直接置き換えます

何をすればいいのか分からない、これはブレインファックコーディングのバリアントコードではありません
切断にはスクリプトを使用するか、オフライン ツールボックスを使用できます。幸いなことに、私は両方を持っています。私は確かに雑多な人間です。
python2 ook.py -o 2.txt

メモ帳に保存する
再実行
python2 ook.py -b 3.txt

フラグを立てろ、おい、このトピックの話題は不人気だ
補充する
ここに知識を追加します
Ook! Ook! はオランウータンの言語を模倣して表現された暗号です。Brainfuck から派生したバリアント エンコーディングです。Ook! Ook! は、「Ook.」、「Ook?」、「Ook!」の 3 つの文字で構成されています。
それぞれの「OK!」は指示を表します。対応内容は以下の通りです。
- 「Ook. Ook?」: Brainfuck の「<」に相当
- 「Ook? Ook.」: Brainfuck の「>」に相当
- 「Ook. Ook.」: Brainfuck の「+」に相当
- 「Ook! Ook!」: Brainfuck の「-」に相当
- 「Ook! Ook.」: Brainfuck の「.」に相当
- 「Ook. Ook!」: Brainfuck の「,」に相当
- 「Ook! Ook?」: Brainfuck の「[」に相当
- 「Ook? Ook!」: Brainfuck の「]」に相当
Ook! Ook! コードは、使用法と意味が Brainfuck に似ていますが、別の言語で説明されているだけです
Brainfuck は 8 文字で構成されるエンコードです。このエンコーディングは、「>」、「<」、「+」、「-」、「.」、「,」、「[」、「]」を含む 8 つの命令記号で構成される最小限のプログラミング言語です。
悪いイメージ
名前を見てください、おそらく壊れた鏡を意味します
この質問を盲目的に推測するというアイデアは、内部のファイルまたはデータを復元することです。
しかし、この質問には予想外の解決策があり、 オンラインであれば追加点が得られます。

私はただ彼を猫にしているだけです(笑)

最後はフラグを見つけてそのまま終了
通常の解決策は最初に述べたことです
興味があれば試してみてください
後で時間があればアップロードします
クリオト
合唱団4

ソースファイルとスクリプトは1 つだけ
これを見てそのアイデアを推測する必要がありました。
フラグはtask.pyを実行して暗号を取得します
必要なのは、解析スクリプト内の暗号を逆にしてフラグを取得することだけです
以下は task.py です。 まずは分析してみましょう
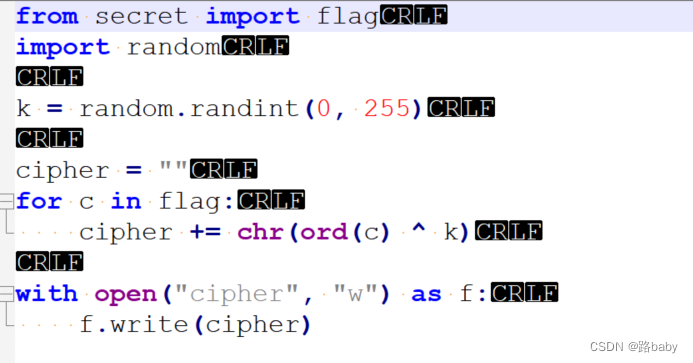
脚本解析
もちろん、このスクリプトの各部分を詳しく分析します。
シークレットインポート フラグから
このコード行は、 「secret」という名前のモジュールから変数フラグをインポートします。コード スニペットによって提供される情報に基づいて、flag はシークレット フラグを含む文字列であると想定できます。
ランダムにインポート
このコード行は、乱数を生成する関数を提供するPython の組み込みモジュール randomをインポートします。
k = ランダム.randint( 0 , 255 )
このコード行は、random.randint()関数を使用して [0, 255] (両端を含む) の範囲でランダムな整数を生成し、それを変数 k に割り当てます。このランダムな整数は、 XOR演算のキーとして使用されます。
暗号 = ""
フラグの cの場合 :
暗号 += chr ( ord (c) ^ k)
コードのこの部分では、ループを使用してフラグ文字列内の各文字を反復処理し、次の処理を実行します。
- ord(c) 文字 cの ASCII 値を取得します 。
- ASCII 値とキー k の XOR : ord(c) ^ k。
- chr() 関数は、結果を対応する文字に変換します。
- 最後に、結果の文字が暗号 文字列に追加されます。
このようにして、フラグ文字列全体が走査され、 XOR 演算後の暗号文文字列cipherが生成されるまでループが実行されます。
open ( "cipher" , "w" )を fとして使用:
f.write(暗号)
コードのこの部分では、 open() 関数を使用して「cipher」という名前のファイルを作成し、それを書き込みモードで開きます。次に、write()メソッドを使用して 暗号文文字列 cipherを ファイルに書き込みます。最後に、 with ステートメントを使用して、ファイル操作が適切に閉じられていることを確認します。
スクリプトの目的は、ランダムに生成されたキーとのXOR演算を使用してシークレット トークンを暗号化し、結果の暗号文を"cipher"というファイルに保存することです 。
フラグ内の各文字は、暗号化のために同じ番号 k と XOR 演算されます。
平文内のすべての文字は、同じキー k で XOR 演算されます。
したがって、考えられるkを256個列挙してXOR復号を試みるだけでよく、復号された文字列に「フラグ」が含まれていれば復号は成功したことになります。
上脚本
with open("cipher", "r") as f:
cipher = f.read()
#打开名为 "cipher" 的文件,并以只读模式打开它
for k in range(0, 256):
msg = ""
#外层循环使用 range(0, 256) 遍历从 0 到 255 的所有可能的密钥
for c in cipher:
#内层循环遍历 cipher 字符串中的每个字符
msg += chr(ord(c) ^ k)
#chr() 函数将结果转换回相应的字符。
- #最后,将得到的字符追加到 msg 字符串中,以构建解密后的消息
if "flag" in msg:
print(msg)
break
#解密后的消息中包含字符串 "flag",则输出该消息并跳出循环
旗を取りに走る
フラグ{c30dd6b0-38a3-5f88-830c-52ed3b67c81f}
安全でない公開鍵


1 つの公開鍵 1 つの暗号文
明らかにRSA復号化
pem 公開キー ファイルはn と eを抽出できます。
n がある場合、rsa 復号化のためにp と qを取得するにはフェルマー分解が必要です
もちろん、Feng Erxiのツールは、私の知る限り、オフライン RSA ソリューションにとって最も便利なツールであるはずです。
ただし、スクリプトにはまだ必要があります
# -*- coding: utf-8 -*-
from Crypto.PublicKey import RSA
from gmpy2 import *
def Pollard_rho_func_2(a,n):
return (pow(a,n-1,n)+3)%n
with open('pub.pem', 'r') as f:
key = RSA.importKey(f)
print('n:'+str(key.n))
print('e:'+str(key.e))
n = key.n
e = key.e
# 费get p,q
ori=2
a=Pollard_rho_func_2(ori,n)
b=Pollard_rho_func_2(a,n)
p=1
i=1
while (a!=b):
if (gcd(abs(a-b),n)>1):
p=gcd(abs(a-b),n)
break
else:
a = Pollard_rho_func_2(a,n)
b = Pollard_rho_func_2(b,n)
b = Pollard_rho_func_2(b,n)
i+=1
if (i%100==0):
print(i)
if (p!=1):
print('p:'+str(p))
q = n/p
print('q:'+str(q))
# p= 189749484366449861630736482622030204229600074936733397229668738586605895979811823994029500725448581332746860468289540041125768726148614579255062994177531727784605194094836998282676712435286273497842956368997116036170165393912022560935791934662695453870846024312915604049805219410140420469163797779129644454583
# q= 177993461816075408240866752227210319316825574291000376727523991315086097605063837563342286560819823849610146713383370383386260295565108973920944593141677024612114517119831676665456754235233172344362610684938542774386956894066675103840244633202469661725050948177995671009070311486253646420435061175078660441183
d = invert(e,(p-1)*(q-1))
print('d:'+str(d))
#c = 0xc1bb8cbb9581abf710cab1908a04772f6cc972756e161a5a0615eaf1505d6928e545e626a508abd8c008d43c4eab5ee751c2b5e297891784dc851d8ba887907278142bc70649b503fdec092b143f3afc4508e1671f503c8e38d624befdeeea2bfd3e947289000568a2e409d0f955e19ebb9dccb798543c6435247a8d6b05facddb7f270fce1cecf92994beb7f3119d7f09caa4cff46c9e8db119e41726d0a0ce02ab2b5ae42c3e64c17746a29a32bd642a6045d73078ae8bd1f54a869760474b395c493ffc69cd8020647dcb0610779296a7c18aa984c5b74414e45bdf5d44000888765e457fb84e1ba3b6f60f7ab4f3b9047614f36adf49eac5d662c5916fb8
c = 0x2093fdefa37b3b4ef0d45f42e32f98aa3f1495f06ef6a24250
origin = pow(c,d,n)
print('*'*20)
print(hex(origin)[2:].decode('hex'))get gkce~ow]dDyYsg|]{<}jtcsq
ブラケットが2つあるのでシーザーかフェンスのように見えます
使用できるツールはありますが、スクリプトの作成についてはまだ知る必要があります。
a = "gkce~ow]dDyYsg|]{<}jtcsq"
b = ''
# 遍历字符串 'a' 中的每个字符for i in range(len(a)):
j = i / 2 + 1
# 如果索引 'i' 是偶数,则从字符的 ASCII 值中减去 'j'
if i % 2 == 0:
b += chr(ord(a[i]) - j)
else:
# 如果索引 'i' 是奇数,则将 'j' 添加到字符的 ASCII 值中
b += chr(ord(a[i]) + j)
# 打印转换后的字符串 'b'print(b)このコードでは、ループを使用して文字列 a の各文字を調べ、算術演算を実行して文字を暗号化または復号化します。
具体的には、暗号化中に、文字の ASCII コードからインデックスを引いて、2 で割って 1 を加算することで、暗号化された文字を取得します。復号化時には、文字の ASCII コードとインデックスを 2 で割って、元の文字を取得します。
指定した文字列「a」に基づいて、
フラグ{we_l0v3_encrYpti0n}
1文字だけ
ファイルを開いた瞬間
これは 1 文字ですか、これは複数の文字ですか
とても腹立たしい
しかし、これを見たときに、今年オンラインの ISCC で出題されたAL の大質問、その他の質問を突然思い出しました。
その質問の最後に、上記のようなテキストが表示されましたが、エンコードとデコードを行った後、該当するのは 1 行だけです。
他の回線にはノイズ情報が詰まっています
終わった気がして、この質問を続けましょう
すべてのテキストは16 進数で表示されます
すべての文字をASCIIに変換して内容を表示できます
しかし、変換後の出力が文字化けしていることがわかりました
トピック名は 1 文字のみです
以前の経験とオンラインでの同様の質問を組み合わせて、 XOR 暗号化であると推測し 、正解は特定の文字 XOR を使用した 1 行の結果です
本来はこうなるはずなのですが、本当に一つ一つ解決していこうとすると、オフラインの時間では足りなくなってしまうのではないかと思います。
秘密キーが可視文字であるかどうかはわからないため、0、255 ループを使用してすべてのコンテンツを復号化できます。

ファイルは合計 500 行あるため、各行は 255 行を使用して復号化され、最終的な出力結果は 500 *255=127500 行になります。たとえ正しい結果がその中にあったとしても、1 行ずつ表示するのは困難です。私たちの目で。
最終フラグは読み取り可能な ASCII コードである必要があるため、すべての結果から数字、文字、スペースの組み合わせの結果を除外します。
これは一般的な考え方です
スクリプトの詳しい説明は後ほど
#coding:utf-8
import binascii
# 将16进制转换为ASCII
def hex2char(data):
output = binascii.unhexlify(data)
return output
# 异或解密函数,tips为加密字符串,key为秘钥,长度可变
def xor_encrypt(tips, key):
lkey = len(key)
secret = []
num = 0
for each in tips:
if num >= lkey:
num = num % lkey
# 将每个字符与秘钥进行异或运算,并将结果转换为ASCII字符
secret.append(chr(ord(each) ^ ord(key[num])))
num += 1
# 将解密后的字符列表连接成字符串并返回
return "".join(secret)
# 打开文件并读取所有行的内容
txt = open('enc.txt', 'r').readlines()
# 遍历文件中的每一行
for line in txt:
# 尝试使用0到255之间的不同整数作为秘钥进行解密操作
for i in range(0, 255):
a = 1
result = xor_encrypt(hex2char(line.strip('\n')), chr(i))
# 筛选出只包含数字、字母和空格的解密结果
for j in result.strip('\n'):
k = ord(j)
# 如果字符不是数字、字母或空格,则将标志a设置为0
if k < ord('z') + 1 and k > ord('0') - 1:
pass
elif k == 32:
pass
else:
a = 0
break
# 如果解密结果只包含数字、字母和空格,则打印该结果
if a == 1:
print(result)
# python2コードの説明
このコードを実行すると、「enc.txt」という入力ファイル内のすべての行を復号化しようとします。
まず、コードでは 2 つの関数が定義されています。
1. hex2char(data)関数は、binasciiモジュールを使用して 16 進データを ASCII 文字列に変換します。
- 変換する 16 進データを表すパラメータ データを受け取ります。
- この関数は内部で binascii.unhexlify() 関数を呼び出して変換操作を実行します。
- 最後に、変換された ASCII 文字列が結果として返されます。2.
2. xor_encrypt(tips, key)関数は、XOR 暗号化および復号化操作を実行します。
- これは 2 つのパラメータを受け入れます。tips は暗号化または復号化する文字列を示し、key はキーを示します。
- いくつかの変数は関数内で定義されています。lkey はキーの長さを示し、secret は暗号化または復号化の結果を保存するために使用され、num はキー内の文字位置を追跡するために使用されます。
- この関数は、キーと入力文字列を 1 文字ずつ XOR 演算することによって暗号化または復号化します。キーの長さが十分でない場合は、キー内の文字が再利用されます。
- XOR 演算は、文字を ASCII コードに変換し、XOR 演算を実行して、結果を文字形式に変換することによって機能します。
- 最後に、関数は結果のすべての文字を文字列に連結して返します。
次に、メインコードのロジックを分析してみましょう。
- txt = open('enc.txt', 'r').readlines(): 'enc.txt' という名前のファイルを開き、すべての行を読み取り、各行を文字列として txt リストに保存します。
- for line in txt:: txt リストの各行 (つまり、ファイル内の各行) を走査します。
- for i in range(0, 255): 考えられるキー文字を表す 0 ~ 254 (ASCII コード範囲) の整数値をループします。
- a = 1: 復号結果がフィルタリング条件を満たすかどうかをマークするために使用される変数 a を 1 に初期化します。
- result = xor_encrypt(hex2char(line.strip('\n')), chr(i)): 現在の行の内容から改行文字を削除し、ASCII 文字列に変換します。次に、現在のループでキー文字を使用して xor_encrypt() 関数を呼び出し、現在の行の内容を復号化し、復号化された結果を result 変数に格納します。
- 次に、次の手順で復号結果をフィルタリングします。
- for j in result.strip('\n'):: 復号化結果の各文字をループします。
- k = ord(j): 文字 j の ASCII コードを取得し、変数 k に格納します。
- 文字の ASCII コードが次の条件を満たすかどうかを確認します。
- if k < ord('z') + 1 and k > ord('0') - 1: pass: 文字は数字または文字の間の ASCII コード範囲であり、ループは継続します。
- elif k==32: pass: 文字はスペースの ASCII コードであり、ループが継続します。
- else: a = 0; Break: 文字が数字でも文字でもスペースでもない場合は、変数 a を 0 に設定し、内側のループから抜け出します。
7.if a == 1: print(result): 内側のループが完了したら、変数 a の値が 1 であるかどうかを確認します。「はい」の場合、復号結果がフィルタリング条件を満たしていることを意味し、出力されます。\

できれば Python2 環境で実行してフラグを取得します
フラグ{leKwFMfjcEitrqoTmdkIZSPRVLYxWsQU}