Swin Transformer の論文を集中的に読む
https://www.bilibili.com/video/BV13L4y1475U
Swin は、CV の下流タスク (下流タスクとは、分類、検出、セマンティック セグメンテーションなど、バックボーン ネットワークの背後にあるヘッドによって解決されるタスクを指します) をほぼカバーし、複数のデータ セットのリストを更新しました。
タイトル Swin Transformer: Shifted Windows を使用した Hierarchical Vision Transformer 意味: 移動ウィンドウを使用した Hierarchical Vision Transformer。Swin は、Transformer を畳み込みネットワークのようにいくつかのブロックに分割し、階層的な特徴抽出を実行できるようにして、抽出された特徴が階層的な概念を持つようにしたいと考えています。
概要
この論文では、コンピュータ ビジョンの一般的なバックボーンとして機能する、Swin Transformer と呼ばれる新しいビジョン トランスフォーマーを提案します。トランスフォーマーを言語から視覚に適用する際の課題は、視覚エンティティのスケールの大きな違い (同じオブジェクトが異なる写真では異なるサイズである可能性がある) や、画像のサイズが異なるという事実など、2 つの領域の違いから生じます。テキスト内の単語に変換、ピクセル高解像度。これらの不一致に対処するために、シフトされたウィンドウで表現が計算される階層型 Transformer を提案します。シフトされたウィンドウは効率を向上させます (セルフ アテンションはウィンドウ内で計算されるため、シーケンスの長さが大幅に短縮されます); セルフ アテンションは重複しないローカル ウィンドウに限定されますが、クロス ウィンドウ接続が可能になります (シフトすることで、隣接するウィンドウ間でしたがって、上位レイヤと下位レイヤの間でクロスウィンドウ接続を行うことができ、偽装したグローバル モデリング機能を実現できます。この階層構造の利点: ①、さまざまなスケールで情報を柔軟に提供する (モデリングの柔軟性)、②、画像サイズに対する線形の計算複雑さ (セルフ アテンションは小さなウィンドウで計算され、計算複雑度は画像サイズに比例して増加するが、画像サイズに応じて線形に増加する)二次関数的に)。Swin Transformer のこれらの特性により、画像分類 (ImageNet-1K で 87.3 のトップ 1 精度) や物体検出 (COCO testdev で 58.7 ボックス AP および 51.1 マスク AP) などの高密度予測タスクを含む、幅広いビジョン タスクと互換性があります。セマンティック セグメンテーション (ADE20K val で 53.5 mIoU)。そのパフォーマンスは、COCO の +2.7 ボックス AP および +2.6 マスク AP、ADE20K の +3.2 mIoU を大幅に上回り、ビジョン バックボーンとしての Transformer ベースのモデルの可能性を示しています。階層設計とシフト ウィンドウ アプローチも、すべての MLP アーキテクチャに有益であることが示されています。
序章
最初の 2 つの段落の意味: ビジョンの分野では、以前は畳み込みネットワークが主流でしたが、Transformer は NLP の分野でうまく機能し、Transformer はビジョンの分野にも適用できます。ViT はこれを実装しており、Swin の出発点は、Transformer がビジョン ドメインの一般的なバックボーン ネットワークとして使用できることを証明することです。
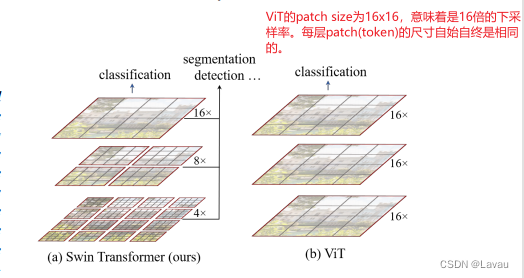
ViT はグローバルなセルフアテンション操作を通じてグローバル モデリングを実現できますが、マルチスケールの特徴の把握は弱くなります。検出やセグメンテーションなどの特定の視覚タスクでは、マルチスケール機能が特に重要です。ViT 処理の特徴は、単一の低解像度です。つまり、16 倍のダウンサンプリング レートが処理された後に処理された特徴です。したがって、ViT は集中的な予測タスクの処理には適さない可能性があります。一方、ViT のセルフアテンションは常に画像全体に対して行われます。これはグローバル モデルであり、複雑さは画像サイズに応じて二次関数的に増加します。
Swin は、畳み込みネットワークに関する多くの経験と予備知識を活用しています。たとえば、シーケンスの長さを短縮し、計算の複雑さを軽減するためです。Swin は、画像全体に対する ViT とは異なり、小さなウィンドウで自己注意を計算することを提案しました。ウィンドウ サイズが固定されている限り、計算量も固定され、画像全体の計算量は画像のサイズに比例して増加します。これは、畳み込みネットワークにおける局所性の帰納的バイアスを使用しているとみなすこともできます。同じオブジェクトの異なる部分、または同様のセマンティクスを持つ異なるオブジェクトが、接続された場所に出現する可能性が高くなります。
Swin はどのようにしてマルチサイズの特徴を生成するのでしょうか? 畳み込みネットワークでは、マルチサイズの特徴は主にプーリングによって生成されます。プーリング操作により、各コンボリューション カーネルが認識する受容野が増加するため、プールされた特徴がさまざまなサイズのオブジェクトをキャプチャできるようになります。これに対応して、Swin はプーリングのような操作、つまりパッチのマージを提案しました。隣接する小さなパッチを大きなパッチに結合します。上の図 (左) に示すように、大きなパッチは小さなパッチが以前に見たものを見ることができ、受容野が増加します。
(第 3 段落)
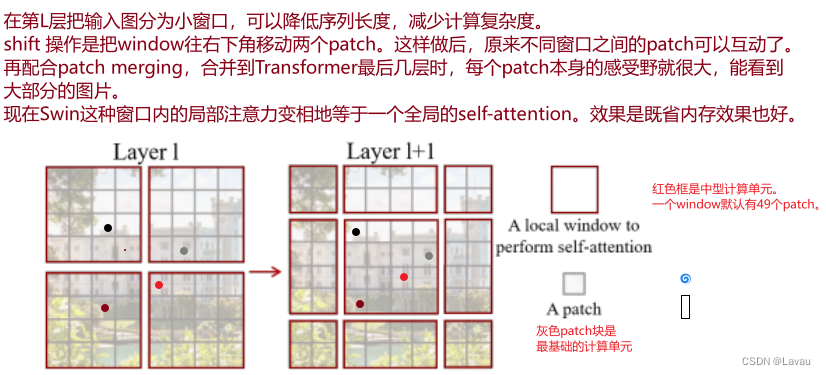
(第4段落。第4段落ではシフト動作を紹介します。ここでは図2と合わせて説明します。)
5 番目の段落では、Swin によって達成された結果が示されています。
第 6 パラグラフの著者の展望: CV と NLP の統一された枠組みは、2 つの分野の共通の発展を促進することができます。
(Swin はビジョンの事前知識をうまく活用し、ビジョンタスクで全方位を殺します。しかし、大統合では ViT の方が優れています。何も変更せず、事前情報を追加しないため、Transformer は 2 つの領域にあり、それらはすべてです)このようにして、モデルはパラメータを共有でき、複数のモダリティの出力も長い入力として結合でき、モダリティ間の違いに関係なく、直接 Transformer に渡されます。)
結論
Swin は、階層的な特徴表現を生成し、入力画像サイズに対して線形の計算量をもつ新しいビジュアル Transformer です。Swin は、COCO オブジェクト検出と ADE20K セマンティック セグメンテーションで最先端のパフォーマンスを達成し、これまでの最良の方法を大幅に上回りました。さまざまな視覚問題に対する Swin の強力なパフォーマンスにより、視覚信号と言語信号の統合モデリングが促進されることを期待しています。(第一段落)
著者は、Swin の最も重要な貢献はシフト ウィンドウ ベースの自己注意であると提案しています。これは、視覚の下流タスク、特に高密度予測タスクではより重要です。著者は、次の研究では、シフト ウィンドウ ベースの自己注意を NLP に適用できると提案しています。(第 2 段落)
関連作業
著者は最初に畳み込みニューラル ネットワークについて簡単に説明し、次にセルフ アテンションまたは Transformer が畳み込みニューラル ネットワークにどのように役立つかについて説明し、最後に視覚のバックボーン ネットワークとしての純粋な Transformer について説明します。
(Swin の関連作業は ViT の関連作業とほぼ同じであるため、ここでは繰り返しません)
方法
著者はこの章を 2 つの部分に分けています。 3.1 Swin の全体的なプロセスについて説明します。主に Swin の前方プロセスを説明し、パッチのマージ操作を実装する方法について説明します。3.2 Swin がシフトされたウィンドウベースのセルフアテンションを計算用の Transformer ブロックにどのように変換するかについて説明します。
全体的なアーキテクチャ
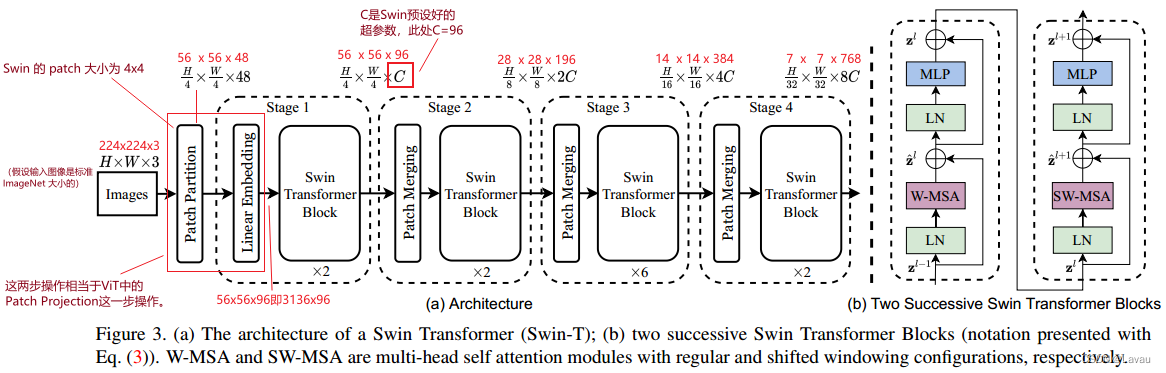
(21:06—29:00 モデル概要図3に従い、Swinの順計算処理を説明)
入力画像サイズが標準 ImageNet サイズ224 * 224 * 3 224*224*3であると仮定します。224∗224∗3.Swinのパッチサイズは4∗4 4*4なので4∗4なので、処理された画像ブロックは56 ∗ 56 ∗ 48 ( 56 = 224 4 ) ( 48 = 4 ∗ 4 ∗ 3 は各パッチ ベクトルの次元を表します) 56*56*48 (56=\frac{224}{ 4) }) (48=4*4*3\ は各 \ patch\ ベクトルの次元を表します)56∗56∗48 (56)=4224)(48=4∗4∗3 は各パッチベクトルの次元を表します) 。
Linear Embedding により、ベクトルの次元はプリセット サイズ(つまり、Transformer が受け入れることができるサイズ) に変更されます。Swin の論文では、このハイパーパラメータはCCに設定されています。C (図 3 に示す Swin-T の場合、C = 96 C=96)C=96)。線形埋め込みによって得られた結果のサイズは3136 ∗ 96 ( 3136 = 56 ∗ 56 ) 3136*96 (3136=56*56) となります。3136∗96 (3136)=56∗56 ) ; つまり、シーケンスの長さは3136 31363136、各トークン ベクトルの次元は96 9696。
Swin におけるパッチ パーティションとリニア エンベディングの 2 段階の操作は、ViT におけるパッチ プロジェクションの操作と同等です。Swin コードでは、作成者はワンステップの畳み込みを使用してこれを実行します。
このとき、Transformer に入るシーケンスの長さは3136 3136です。3136、Transformer に入る ViT のシーケンス長をはるかに超えています (シーケンス長は196 196196 ); Transformer はそのような長いシーケンスを受け入れることができません。Swin はセルフ アテンション ベースのシフト ウィンドウを導入しました。デフォルトでは、各ウィンドウには 49 個のパッチがあります。つまり、シーケンスの長さはわずか 49 です。Swin Transformer Block は、セルフ アテンション ベースのシフト ウィンドウによって計算されます。
次に、パッチのマージがどのように実装されるかを理解します。

Patch Merging の入力がH ∗ W ∗ CH*W*Cであることは明らかです。H∗W∗C、中央の Ⅰ、Ⅱ、Ⅲ、Ⅳの 4 つのステップ後の出力はH 2 ∗ W 2 ∗ 2 C \frac{H}{2}*\frac{W}{2}*2C2H∗2W∗2C._ _ _ つまり、パッチマージ後は「幅と高さが半分になり、チャンネルが2倍になる」という効果が実現されます。
- 最初のステップでは、指定されたイメージを 4 つのウィンドウに分割し、各ウィンドウには 4 つのパッチがあります。
- 2 番目のステップでは、各ウィンドウに対応するパッチをまとめて、「幅と高さを半分にする」効果を実現します。
- ステップⅢ 「幅と高さは半分、チャンネルは4倍」になるように積み上げます。
- ステップ IV では1 ∗ 1 1*1を使用します1∗1の畳み込みによりチャネルの寸法が削減され、「幅と高さが半分、チャネルが 2 倍」が実現します。
もう一度図 3 を見てください。
各ステージのパッチをマージするたびに、幅と高さは半分になり、チャンネルは 2 倍になります (これらの変更は図 3 でマークされています)。
ここまでで、Swin バックボーン ネットワークの順伝播 (計算) が完了しました。
Swin には 4 つのステージがあり、最後の 3 つのステージにはプーリングと同様のパッチ マージ操作があり、セルフ アテンションは小さなウィンドウ内で計算されます。
シフトウィンドウベースのセルフアテンション
シフト ウィンドウ ベースのセルフ アテンションを導入する理由は何ですか? グローバル セルフ アテンションは 2 次の複雑さにつながります。視覚の下流タスク、特に高密度の予測タスクを実行する場合、または画像サイズが大きい場合、グローバル セルフ アテンションの計算は非常に高価になります。そこで、著者はシフトウィンドウベースのセルフアテンションを提案します。(第一段落)
著者はどのようにして窓分割を実現したのでしょうか?(開始 20:45 -終了 30:54 ) (次の図は、ステージ 1 の入力を例としてウィンドウの分割を説明しています)

入力サイズは56 ∗ 56 ∗ 96 56*56*96です56∗56∗96.元の画像は重なり合うことなく均等にウィンドウに分割されます。これらのウィンドウは、上の図ではオレンジ色で示されています。これらのウィンドウは最小のコンピューティング ユニットではなく、最小のコンピューティング ユニットはパッチです。つまり、各ウィンドウにはm ∗ mm*m 個メートル∗mパッチ。スウィンの論文では、m = 7 m=7メートル=7.つまり、各ウィンドウには 49 個あります( 49 = 7 ∗ 7 ) 49 (49=7*7)49 (49)=7∗7 )パッチ。また、セルフ アテンションの計算はウィンドウ内で実行されるため、シーケンスの長さは常に49 4949.すると、上の図は 64 ( 56 7 ∗ 56 7 ) 64 (\frac{56}{7}*\frac{56}{7})に分割できます。64 (756∗756)ウィンドウ、それぞれこの64 6464 個のウィンドウが自己注意としてカウントされます。
Shifted Window based Self-Attention の複雑度の計算方法と、グローバル Self-Attention 複雑度との比較を説明します。(開始30:54 -終了34:41 )
(この部分のメモは省略しています。必要に応じて後で追加します)
作成者はシフト ウィンドウをどのように実装していますか? (開始 35:07 -終了 36:95 )
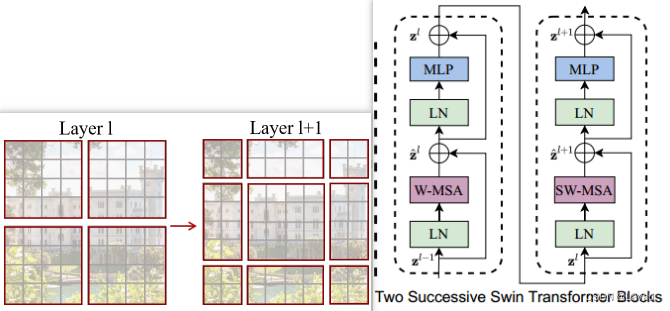
上図の左側では、ウィンドウ間通信の目的を達成するための移動プロセスが導入されています。Swin Transformer ブロック構造の配置も特殊です (左側の部分に示す移動プロセスと一致しています)。最初にウィンドウ ベースのマルチヘッド セルフ アテンションを毎回実行し、次にウィンドウ ベースのマルチヘッドを移動します。自己注意(上の図の右側に示すように)。
z ^ l = W _ MSA ( LN ( zl − 1 ) ) + zl − 1 \hat{\pmb{z}}^l = W\_MSA(LN(\pmb{z}^{l-1})) + \pmb{z}^{l-1}z^私=W_MSA ( LN ( z ) _ _ _l − 1 ))+zl − 1
zl = MLP ( LN ( z ^ l ) ) + z ^ l {\pmb{z}}^l = MLP(LN(\hat{\pmb{z}}^l)) + \hat{\ pmb{z}}^lz私=M L P ( L N (z^l ))+z^l
z ^ l + 1 = SW _ MSA ( LN ( zl ) ) + zl \hat{\pmb{z}}^{l+1} = SW\_MSA(LN(\pmb{z}^{l}) ) + \pmb{z}^{l}z^l + 1=SW_MSA ( LN ( z ) _ _ _ _l ))+zl
zl + 1 = MLP ( LN ( z ^ l + 1 ) ) + z ^ l + 1 {\pmb{z}}^{l+1} = MLP(LN(\hat{\pmb{z}}^) {l+1})) + \hat{\pmb{z}}^{l+1}zl + 1=M L P ( L N (z^l + 1 ))+z^l + 1
Swin がマスクを使用して移動ウィンドウの計算効率を向上させる方法を説明します。(開始37:04~終了51:00 )
(この部分のメモは省略しています。必要に応じて後で追加します)
アーキテクチャのバリエーション
このセクションでは、著者は Swin の 4 つの亜種、Swin-T、Swin-S、Swin-B、Swin-L を提案します。目的は、Resnet と公平に比較することです。4 つのバリアント間の違いは 2 つのハイパーパラメータに反映されています: ①、ベクトル次元サイズCCC、②、各段が所有するトランスブロックの数。(これは Resnet の構造に似ています。Resnet も 4 つのステージに分かれており、各ステージには異なる数の残差ブロックがあります)