目次
3.3 残差構造において、入力次元と出力次元が一致しない場合の対処方法
3.4 Deep ResNet によるボトルネック構造の導入 ボトルネック
論文アドレス: https://arxiv.org/pdf/1512.03385.pdf
ビデオ:コンピューター ビジョンの半分をサポートする ResNet [論文集中読書]_哔哩哔哩_bilibili
ブログ投稿: Li Mu の論文の集中読書シリーズ: ResNet、Transformer、GAN、BERT_Shen Luohua のブログ-CSDN blog_transformer gan の論文
コード: 7.6. 残差ネットワーク (ResNet) — 実践的な深層学習 2.0.0 ドキュメント
1 概要
メインコンテンツ
ディープ ニューラル ネットワークはトレーニングが難しいため、残差 (残差構造) を使用して、ネットワークのトレーニングを以前よりもはるかに簡単にします。ImageNet では 152 層の ResNet が使用されており、VGG の 8 倍ですが、計算量は少なく、最終的に ImageNet2015 の分類タスクで 1 位を獲得しました。cifar-10 で 100 ~ 1000 層のネットワークをトレーニングします。以前のネットワークを残りのネットワークに置き換えるだけで、coco データセットでは 28% の改善が得られました。また、ImageNet ターゲット検出、ココ ターゲット検出、ココ セグメンテーションでも 1 位を獲得しました。
メインチャート
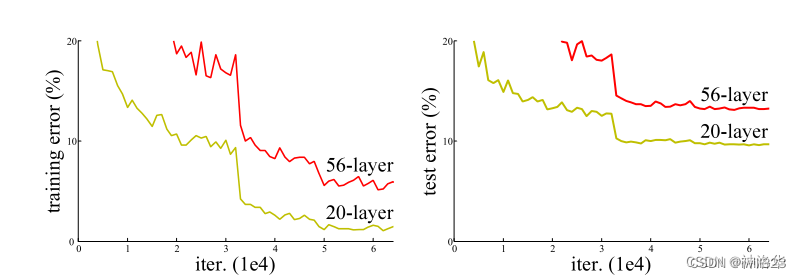
上の図は、残差構造を使用しない場合のネットワークのトレーニング誤差とテスト誤差を示しています。結果は、深い層のトレーニング誤差とテスト誤差が浅い層のものよりも高い、つまり、深いネットワークは実際にはトレーニングされていないことを示しています。下の図は、resnet 構造を使用したネットワーク効果の比較です。右側の残差構造を使用した後は、34 層ネットワークのトレーニングとテストのエラーが減少していることがわかります。

2 はじめに
2.1 残差構造を提案する理由
ディープ畳み込みニューラル ネットワークは、多くの層を積み重ねることができ、異なる層が異なるレベルの特徴を表現できるため、非常に効果的です。ただし、ネットワークが非常に深い場合、勾配の消失や勾配の爆発が発生しやすいため、最適化は困難です。解決策は、重みが大きすぎたり小さすぎたりしないように、適切なネットワークの重みを初期化することです。2 番目は、 BN などの正規化を追加して、各層間の出力、勾配の平均と分散をチェックして、一部の層が大きすぎたり小さすぎたりすることを回避し、より深いネットワークをトレーニングできるようにします (収束します)。しかし、別の問題があり、ディープネットワークのパフォーマンスは低下し、精度も低下します。
ディープネットワークのパフォーマンスの低下は、ネットワーク層の数が多くモデルの複雑さによる過学習によるものではありません。過学習とは、トレーニング誤差が低く、テスト誤差が高いことを意味し、ここでのトレーニング誤差も大きくなるからです。高い。では、なぜこのようなことが起こっているのでしょうか? 理論的に言えば、より深いネットワークを得るために浅いネットワークにいくつかの層を追加した場合、後者の精度は少なくとも悪くならないはずです。これは、後者では少なくとも、新しく追加された層がアイデンティティ マッピングを行うことができ、他の層は直接コピーされるためです。以前から。新しく追加されたレイヤーを少なくともアイデンティティ マッピングまでトレーニングできれば、新しいモデルは元のモデルと同じくらい効果的になります。同時に、新しいモデルはより複雑であるため、トレーニング データセットに適合するより良いソリューションを取得し、トレーニング エラーを減らすことができます。しかし実際には、SGD オプティマイザーはこれより良い解決策を見つけることができません。
したがって、作成者は明示的に恒等マッピングを構築し、一部の層の学習効果が良くない場合は、少なくとも恒等マッピングを実行して、後の層の学習に影響を与えないようにし、深層モデルの精度を向上させます。少なくとも悪化しないように。元の層にいくつかの新しい層を追加した後、学習されるマッピングは H(x) であるとします。ただし、新しい層は H(x) を直接学習するのではなく、H(x)−x を学習します。この部分では F( x) を意味します。つまり、新しく追加された層は残差関数 F(x) = H(x) - x を学習します。モデルの最終出力は F(x)+x です。この新しく追加された層は残ります。最適化の目標は F(x) になります。
構造は次の図 (右) に示されています。
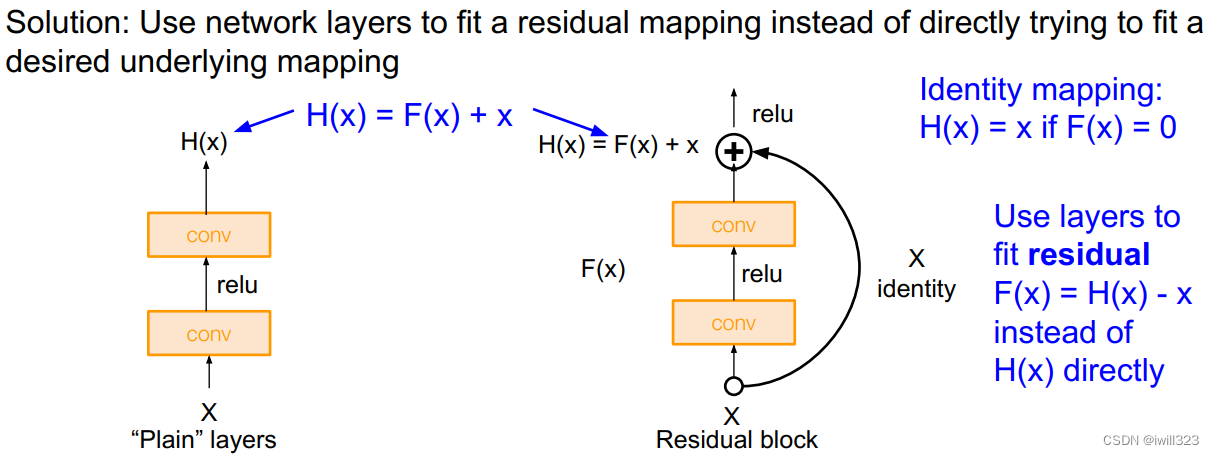
F(x)+x は数学における直接加算であり、ニューラル ネットワークのショートカット接続を通じて実現されます (ショートカットは 1 つ以上の層をスキップし、これらのスキップされた層の出力に入力を直接加算することです)。ショートカットは実際にアイデンティティ マッピング (アイデンティティ マッピング) を実行します。この操作ではパラメータを学習する必要がなく、モデルの複雑さも増加しません。追加が1つあるだけで計算量は増えず、ネットワーク構造も基本的には変わらず、普通に学習できます。
2.2 実験による検証
検証のために、imagenet 上で一連の実験が行われました。結果は、1) 残差ネットワークは最適化が容易であること、2) ネットワーク スタックが深いため残差ネットワークの精度が向上することを示しています。
3 実験部分
3.1 さまざまな構成の ResNet 構造

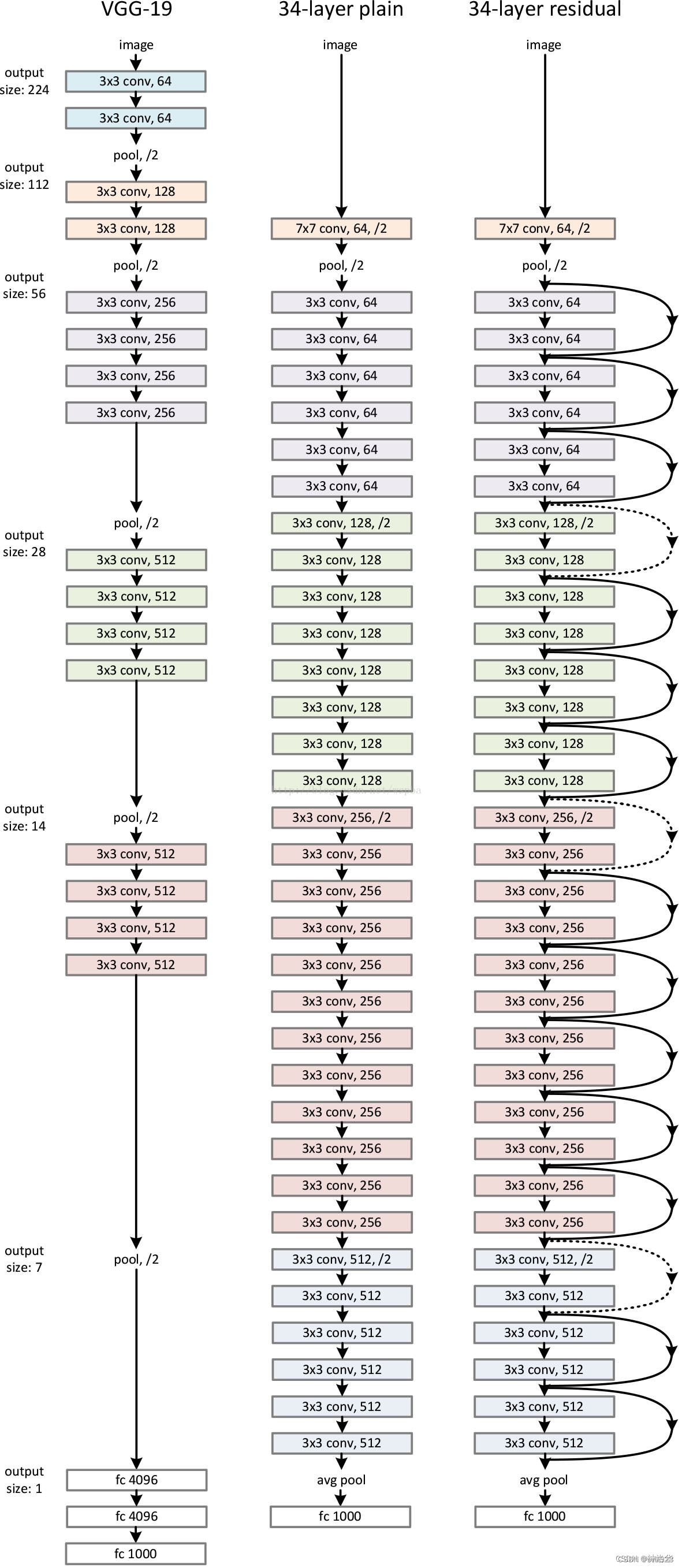
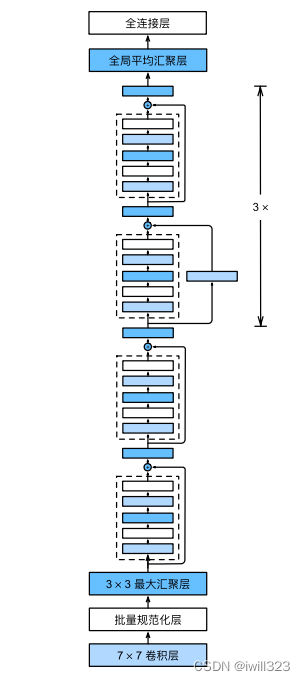
以下の ResNet34 構造図を比較してください: (3+4+6+3)=16 個の残差モジュール、それぞれに 2 つの畳み込み層があります。最初の 7×7 畳み込み層と最後の完全結合層を加えて、合計 34 層になります。
3.2 残留構造効果の比較

3 つの主要な観察:
- 34層は18層よりも優れており、劣化の問題は解決されています
- 残差を使用すると、より高速な収束とより優れた収束結果が得られます。
- 18 層より、18 層のプレーン/残留ネットは比較的正確ですが、18 層の ResNet の方がより速く収束します。
3.3 残差構造において、入力次元と出力次元が一致しない場合の対処方法
A. 寸法を一致させるためにパッドは 0 で埋められます。
B. 次元が一致しない場合は、出力チャネルが入力の 2 倍になるように、CNN の完全接続または 1×1 畳み込みを使用するなど、統一された次元にマッピングします。resnet では、出力チャネルの数が 2 倍になると、入力の高さと幅は通常半分になるため、1×1 畳み込みストライド = 2 となります。
C. 入力次元と出力次元が一致しているかどうかに関係なく、投影マッピングが実行されます。
以下の著者は、これら 3 つの操作の効果を検証しています。以下の結果からわかるように、B と C は同様の効果を持ち、どちらも A よりも優れています。ただし、マッピングはかなり複雑になるため、ResNet では入力と出力の次元がほとんどの場合同じであること (モジュールが4 つだけ接続されている場合はチャネル数が変わります) を考慮して、最終的に著者は案 B を採用しました。

3.4 Deep ResNet によるボトルネック構造の導入 ボトルネック
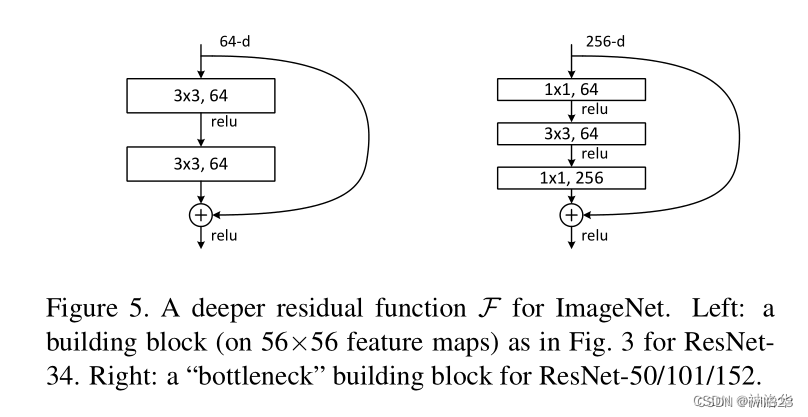
ResNet-50以降の構造ではモデルが深くなり、より多くのパターンを学習できるため、チャネル数も増加する必要があります。例えば、以前のモデル構成表では、ResNet-50/101/152の最初の残差モジュールの出力は256次元でしたが、64次元と比較して4倍に増加し、計算量は16倍に増加しました。 、価値がありません。
ボトルネック構造は効率を向上させるように設計されています。たとえば、最初のモジュールでは、1×1 畳み込みの後、入力が 256 次元から 64 次元に削減され、その後 3×3 畳み込みが実行され、1×1 畳み込み後に次元が 256 次元に戻ります。 。これを実行した後の複雑さは、左に示したものとほぼ同じになります。したがって、ResNet-50 の理論計算量は ResNet-34 とあまり変わりません。しかし実際には、1×1畳み込みの計算効率は他の畳み込みほど高くないため、ResNet-50の計算は依然として高価です。
4 コードの実装
4.1 残留ブロック
ResNet は、VGG の完全な 3×3 畳み込み層設計に従っています。
- 残差ブロックには、最初に同じ数の出力チャネルを持つ 2 つの 3x3 畳み込み層があり、各畳み込み層の後にバッチ正規化層と ReLU 活性化関数が続きます。
- 2 つの畳み込み層の出力が入力と同じ形状である場合、入力は層間データ パスを通じて最終的な ReLU 活性化関数に直接追加されます。
- チャネル数を変更したい場合は、追加の 1×1 畳み込み層を導入して入力を必要な形状に変換し、加算演算を実行する必要があります。
class Residual(nn.Module):
def __init__(self, input_channels, num_channels, use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)このコードは 2 種類の残差ブロックを生成します: (use_1x1conv=True/False)
- ストライドは 2 になり、高さと幅が半分になり、チャネルの数が増加します。そこで、ショートカット接続部分に1×1畳み込み層を追加してチャンネル数を変更します。
blk = Residual(3,6, use_1x1conv=True, strides=2)
blk(X).shapeトーチ。サイズ([ 4 , 6 , 3 , 3 ])
- ストライドが 1、高さと幅が一定の場合、入力は出力に加算されます (ReLU 非線形性を適用する前)。
blk = Residual(3,3)
X = torch.rand(4, 3, 6, 6)
Y = blk(X)
Y.shapeトーチ。サイズ([ 4 , 3 , 6 , 6 ])
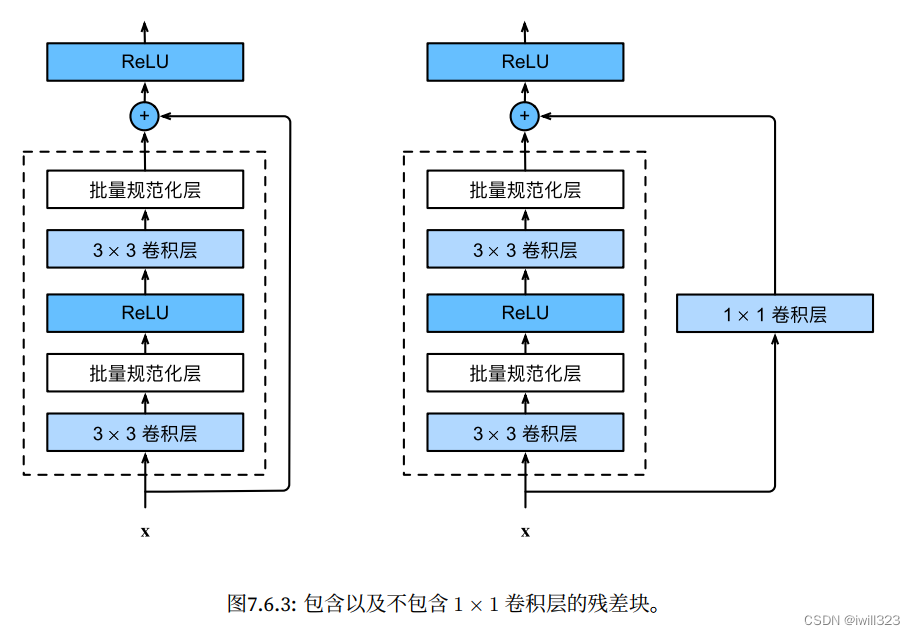
上記の実装は pytorch とは少し異なります。pytorch が実装されたとき、use_1x1conv の後にバスノルムも実行されました。
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
1X1 畳み込みは次のように使用されます。
def conv1x1(in_planes: int, out_planes: int, stride: int = 1) -> nn.Conv2d:
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)4.2 ResNet モデル
完全な ResNet アーキテクチャ:
- 残りのブロックをスタックする
- すべての残差ブロックには 2 つの 3x3 conv レイヤーがあります
- 定期的にフィルターを 2 倍にし、ストライド 2 (各次元で /2) を使用して空間的にダウンサンプリングします。
- 先頭に追加の conv レイヤー (ステム)
- 最後に FC 層なし (出力クラスへの FC 1000 のみ)
- 理論的には、可変サイズの入力画像を使用して ResNet をトレーニングできます
- 最後のコンバージョン層の後のグローバル平均プーリング層
ResNet の最初の 2 つの層は GoogLeNet の層と同じです。64 個の出力チャネルとストライド 2 を持つ 7×7 畳み込み層の後に、ストライド 2 の 3×3 最大プーリング層が続きます。違いは、ResNet が各畳み込み層の後にバッチ正規化層を追加することです。
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))以下では、ResNet は残差ブロックで構成される 4 つのモジュールを使用し、各モジュールは同じ数の出力チャネルを持つ複数の残差ブロックを使用します。
- 最初のモジュールの場合: 出力チャネルの数は入力チャネルの数と同じであるため、1x1conv を使用する必要はありません。ストライド 2 の最大プーリング層が以前に使用されているため、1x1conv を使用する必要はありません。高さと幅。
- 後続の各モジュール: 最初の残差ブロックでは、出力チャンネルの数が入力チャンネルの数と一致しないため、1x1conv が使用されます。最初の残差ブロックは前のモジュールのチャンネル数を 2 倍にし、高さと幅がカットされます。半分に。
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(input_channels, num_channels,
use_1x1conv=True, strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
グローバル平均プーリング層と完全接続層の出力
net = nn.Sequential(b1, b2, b3, b4, b5,
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(), nn.Linear(512, 10))ResNet のさまざまなモジュールの入力形状がどのように変化するかを観察します。
X = torch.rand(size=(1, 1, 224, 224))
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t', X.shape)
シーケンシャル出力形状: torch.Size([1, 64, 56, 56])
シーケンシャル出力形状: torch.Size([1, 128, 28, 28])
シーケンシャル出力形状: torch.Size([1, 256, 14, 14])
シーケンシャル出力形状: torch.Size([1, 512, 7] 、7])
AdaptiveAvgPool2d 出力形状: torch.Size([1, 512, 1, 1])
平坦化出力形状: torch.Size([1, 512])
線形出力形状: torch.Size([1, 10])
各モジュールには 4 つの畳み込み層があります (恒等マップの 1×1 畳み込み層は含まれません)。最初の 7×7 畳み込み層と最後の全結合層を追加すると、合計 18 層になります。したがって、このモデルは ResNet-18 と呼ばれることがよくあります。152 層のより深い ResNet-152 など、モジュール内のさまざまな数のチャネルと残差ブロックを構成することで、さまざまな ResNet モデルを取得できます。ResNet の主なアーキテクチャは GoogLeNet に似ていますが、ResNet アーキテクチャの方がシンプルで、変更が容易です。これらの要因により、ResNet が急速かつ広範囲に使用されるようになりました。
完全なコード:
class Residual_Block(nn.Module):
def __init__(self, ic, oc, stride=1):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(ic, oc, kernel_size=3, padding=1, stride=stride),
nn.BatchNorm2d(oc),
nn.ReLU(inplace=True)
)
self.conv2 = nn.Sequential(
nn.Conv2d(oc, oc, kernel_size=3, padding=1),
nn.BatchNorm2d(oc)
)
self.relu = nn.ReLU(inplace=True)
if stride != 1 or (ic != oc): # 对于resnet18,or的两个条件一直,因为改变通道的时候,同时stride == 2
self.conv3 = nn.Sequential(
nn.Conv2d(ic, oc, kernel_size=1, stride=stride),
nn.BatchNorm2d(oc)
)
else:
self.conv3 = None
def forward(self, X):
Y = self.conv1(X)
Y = self.conv2(Y)
if self.conv3:
X = self.conv3(X)
Y += X
return self.relu(Y)
class ResNet(nn.Module):
def __init__(self, block = Residual_Block, num_layers = [2,2,2,2], num_classes=11):
super().__init__()
self.preconv = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
self.layer0 = self.make_residual(block, 64, 64, num_layers[0])
self.layer1 = self.make_residual(block, 64, 128, num_layers[1], stride=2)
self.layer2 = self.make_residual(block, 128, 256, num_layers[2], stride=2)
self.layer3 = self.make_residual(block, 256, 512, num_layers[3], stride=2)
self.postliner = nn.Sequential(
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(),
nn.Linear(512, num_classes)
)
def make_residual(self, block, ic, oc, num_layer, stride=1):
layers = []
layers.append(block(ic, oc, stride))
for i in range(1, num_layer):
layers.append(block(oc, oc))
return nn.Sequential(*layers)
def forward(self, x):
out = self.preconv(x)
out = self.layer0(out) # [64, 32, 32]
out = self.layer1(out) # [128, 16, 16]
out = self.layer2(out) # [256, 8, 8]
out = self.layer3(out) # [512, 4, 4]
out = self.postliner(out)
return out 5 トレーニングとテスト
トレーニング方法
- 画像処理:
- 画像は [256 , 480]でランダムにサンプリングされた短辺でサイズ変更されます。
- 224 × 224 のクロップは、画像またはその水平方向の反転からランダムにサンプリングされ、ピクセルごとの平均が減算されます。
- 標準の色拡張が使用されます。
- 各 CONV レイヤー後およびアクティブ化前のバッチ正規化
- He らによる Xavier 初期化。
- SGD + 運動量 (0.9) + 1e-5 の重量減衰
- 学習率: 0.1 から始まり、検証エラーがプラトーになったときに 10 で割ります。
現在は手動調整は必要ありません。リー先生は、たとえ精度の変化が横ばいになったとしても、あまり早く急上昇すべきではないと考えています。そうしないと、後の段階での収束が弱くなるでしょう。表面的には何もしていないように見えますが、モデルは微調整されていますが、マクロデータからは見えません。
- ミニバッチサイズ 256
- ドロップアウトは使用されていません
テスト
標準の 10 クロップ テスト: テスト画像が与えられた場合、ランダムまたは特定のルールに従って 10 枚の画像をサンプリングし、各サブ画像について予測を行い、結果を評価します。また、1 つの解像度ではなく、さまざまな解像度で {224, 256, 384, 480, 640} をサンプリングします。
6 CIFAR-10 実験
なぜ cifar-10 (32*32 の 5 ワットの画像) のような小さなデータセットで 1202 層のネットワークをトレーニングするのかというと、過剰学習はそれほど強力ではありません。変圧器モデルの数千億のパラメータがオーバーフィットしないのはなぜですか? Li Mu 氏は、残差接続を追加すると、モデルの本質的な複雑さが大幅に軽減されると考えています。理論的には、モデルにいくつかのレイヤーが追加された場合、モデルは少なくとも次のレイヤーを学習してアイデンティティ マップを作成できるため、精度が低下することはありません。つまり、データに適合するように単純なモデルをトレーニングする方が簡単です。残りの接続を追加すると、モデルの複雑さが軽減されるのと同じです
7 残留ネットワークが機能する理由
ResNet は CNN バックボーンに残りの接続を追加するため、新しく追加したレイヤーのトレーニング効果が良くない場合でも、少なくとも単純なモデルにフォールバックできるため、精度が低下することはありません。
著者らは、残差 f(x) = H(x) - x をフィッティングする方が簡単であると推測しています。理想写像 f(x) が恒等写像に非常に近い場合、残差写像は恒等写像の微妙な変動を捉えやすくなります。実際には、この層が前の層と比較して大きな変化があるかどうかに依存します。差動アンプの役割に相当します。
元の参照されていないマッピングを最適化するよりも、残差マッピングを最適化する方が簡単であるという仮説を立てます。
最適な関数がゼロ マッピングよりも恒等マッピングに近い場合、ソルバーは関数を新しい関数として学習するよりも、恒等マッピングを参照して摂動を見つける方が簡単です。
今見ると、勾配がより適切に維持されるため、ResNetトレーニングが高速になっています。以下の g(x) は元のレイヤー、f() は新しく追加されたレイヤーです。乗数が追加されると、勾配は一般に小さい (0 ~ 1 ガウス分布) ため、新しく追加されたレイヤーによって勾配が簡単に消失します。残りの接続が追加され、勾配には前のレイヤー (青いプラス記号の右側の項目) の勾配が含まれるため、どれだけ深く追加しても勾配は比較的大きくなり、トレーニング結果はすぐに「平らになる」ことはありません (トレーニングは動きません)。SGD を実行すればするほど、トレーニングはより効果的になります。SGD の本質は、勾配が比較的大きい限り、トレーニングを続けることができるということです。いずれにせよ、ノイズがあり、常にゆっくりと収束し、最終的な効果はより良く。また、勾配には以前に学習した項目が含まれているため、残差ネットワークは迅速に学習します。

論文の推奨事項
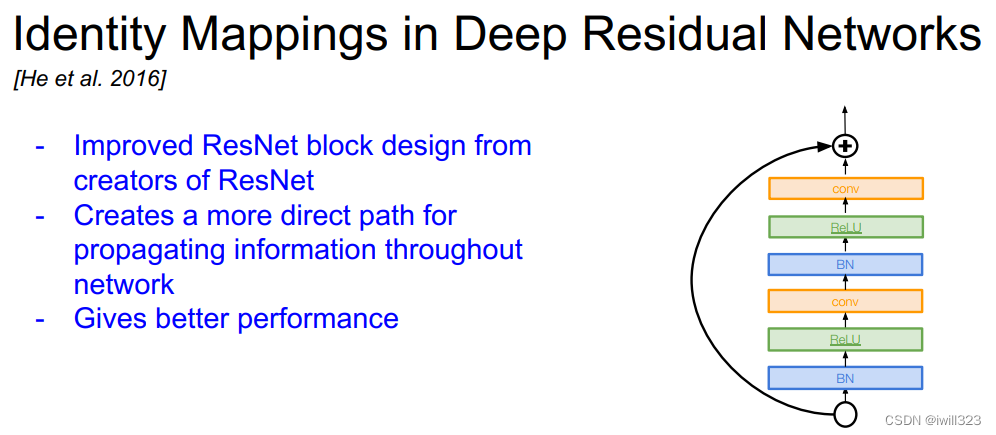
1、深層残留ネットワークにおけるアイデンティティマッピング
多くの ResidualBlock デザインが論文に記載されています。自分でいくつかの効果を達成してみることができます。

2、 密接に接続された畳み込みネットワーク
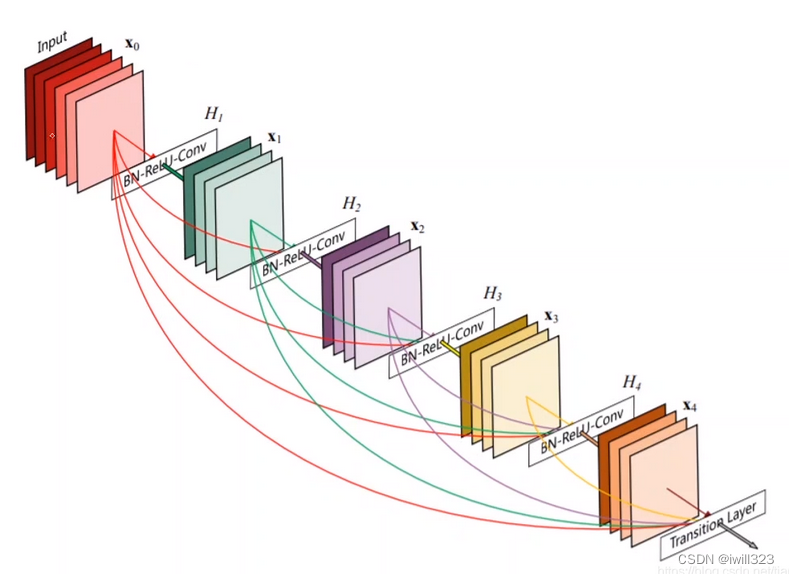
これも検討する価値のある実装方法です。