記事ディレクトリ
YOLOv5+PyQt5+OpenCV を使用して小売キャビネットのスマートな製品認識をゼロから実現
データ収集からモデルの使用、最終プレゼンテーションまでの全プロセスのチュートリアル。ご質問やご提案がございましたら、コメント欄でお気軽にご相談ください。
最終的な効果を最初に置く
検知効果

スマートな小売キャビネットの製品識別。顧客が購入した製品を指定されたエリアに置くと、各製品を正確に識別できるため、完全な買い物リストを返し、顧客が支払う製品の実際の合計価格を計算できます。
1. データセットの準備
データのコピーを処理して、対応するデータセットを形成しました。データ総数は5422枚、全ての写真にマークが付けられており、商品カテゴリーは合計113品目となります。このデータ セットは、3796 のトレーニング セット、1084 の検証セット、542 のテスト セットを含むデータ セットに分割されています。
農福泉、コーラなどの一般的なものを含め、すべてのラベルは次のとおりです。
3+2-2
3jia2
aerbeisi
anmuxi
aoliao
asamu
baicha
baishikele
baishikele-2
baokuangli
binghongcha
bingqilinniunai
bingtangxueli
buding
chacui
chapai
chapai2
damaicha
daofandian1
daofandian2
daofandian3
daofandian4
dongpeng
dongpeng-b
fenda
gudasao
guolicheng
guolicheng2
haitai
haochidian
haoliyou
heweidao
heweidao2
heweidao3
hongniu
hongniu2
hongshaoniurou
jianjiao
jianlibao
jindian
kafei
kaomo_gali
kaomo_jiaoyan
kaomo_shaokao
kaomo_xiangcon
kebike
kele
kele-b
kele-b-2
laotansuancai
liaomian
libaojian
lingdukele
lingdukele-b
liziyuan
lujiaoxiang
lujikafei
luxiangniurou
maidong
mangguoxiaolao
meiniye
mengniu
mengniuzaocan
moliqingcha
nfc
niudufen
niunai
nongfushanquan
qingdaowangzi-1
qingdaowangzi-2
qinningshui
quchenshixiangcao
rancha-1
rancha-2
rousongbing
rusuanjunqishui
suanlafen
suanlaniurou
taipingshuda
tangdaren
tangdaren2
tangdaren3
ufo
ufo2
wanglaoji
wanglaoji-c
wangzainiunai
weic
weitanai
weitanai2
weitanaiditang
weitaningmeng
weitaningmeng-bottle
weiweidounai
wuhounaicha
wulongcha
xianglaniurou
xianguolao
xianxiayuban
xuebi
xuebi-b
xuebi2
yezhi
yibao
yida
yingyangkuaixian
yitengyuan
youlemei
yousuanru
youyanggudong
yuanqishui
zaocanmofang
zihaiguo
サンプル画像



独自のデータセットを作成するには、次の手順を参照してください。
1.1 データセットの収集
一部の写真はクローラーによってクロールされる可能性があります。
1.2 labelme を使用して画像にラベルを付ける
labelme は、Python で書かれ、グラフィカル インターフェイスに Qt を使用するグラフィカル画像注釈ツールです。端的に言えば、ソフトウェアのようなインターフェースを持っており、操作は可能ですが、コマンドラインで起動するため、ソフトウェアを使用するよりも少し面倒です。そのインターフェースは次のとおりです。
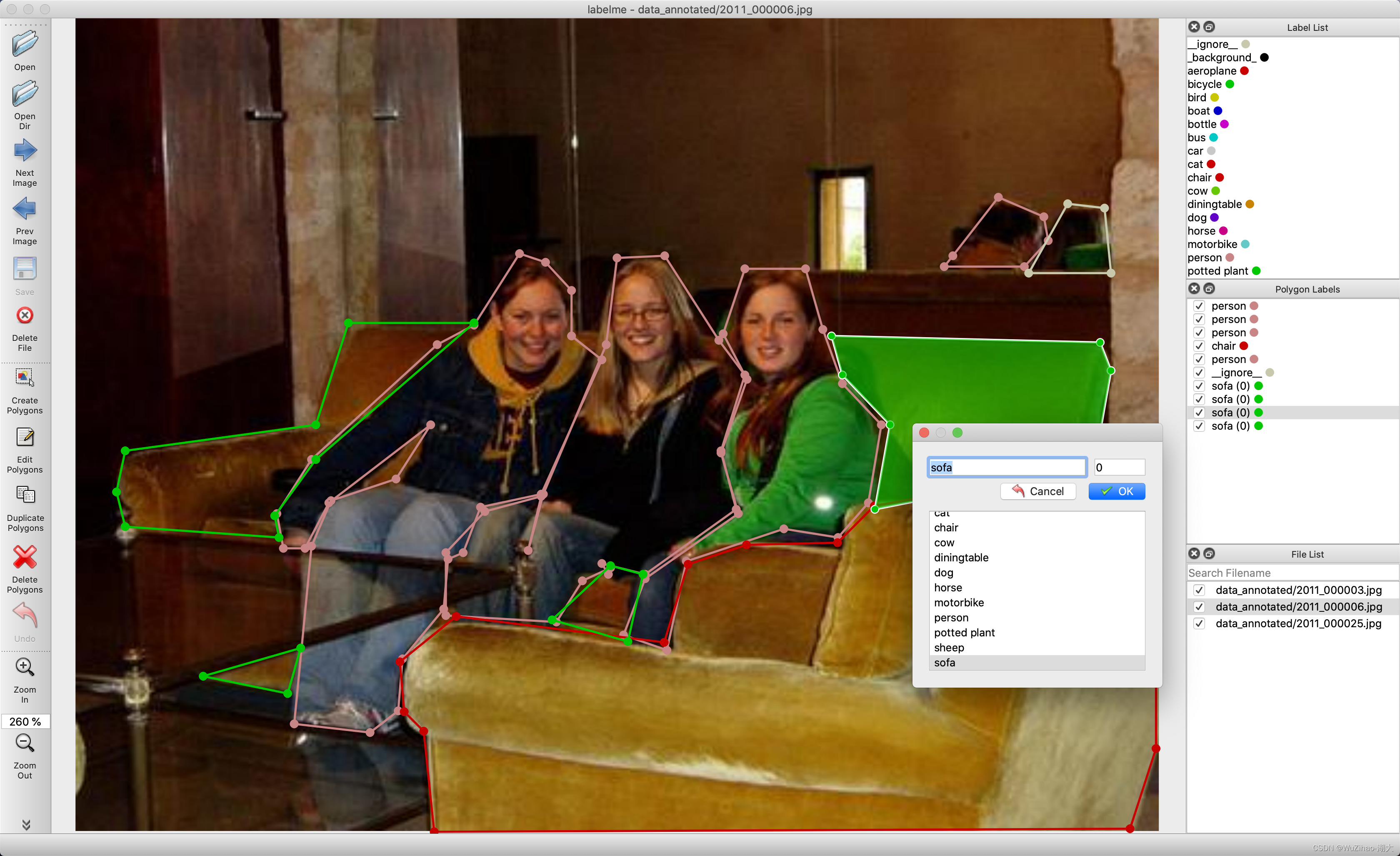
github リンク: labelme https://github.com/wkentaro/labelme
には、次のような多くの機能があります。
- 多角形、長方形、円、ポリライン、線分、点の形式で画像に注釈を付けます (ターゲットの検出、画像のセグメンテーションなどに使用できます)。
- フラグの形式で画像に注釈を付けます (画像の分類やクリーニングのタスクに使用できます)。
- ビデオアノテーション - VOC 形式でデータセットを生成します (セマンティック / インスタンスセグメンテーション用)
- COCO 形式でデータセットを生成します (セグメンテーションなど)。
2.YOLOv5
2.1 YOLO アルゴリズムの概要
YOLO フレームワーク (You Only Look Once) は、RCNN シリーズのアルゴリズムとは異なり、異なる方法でオブジェクト検出を処理します。画像全体をインスタンスに配置し、境界ボックスの座標とそれらのボックスのクラス確率を予測します。YOLO アルゴリズムを使用する最大の利点は、非常に高速で、1 秒あたり 45 フレームを処理でき、一般的なオブジェクト表現も理解できることです。
このセクションでは、YOLO が特定の画像内のオブジェクトを検出するために使用する処理手順について説明します。
まず、入力画像:

次に、YOLO は入力画像をグリッド形式 (例: 3 X 3) に分割します。

最後に、画像の分類と位置特定の処理が各グリッドに適用され、予測されたオブジェクトの境界ボックスとそれらに対応するクラス確率が取得されます。
全体のプロセスはあまり明確ではありませんが、以下に一つずつ詳しく紹介します。まず、ラベル付きデータをトレーニング用のモデルに渡す必要があります。画像がサイズ 3 X 3 のグリッドに分割されており、カテゴリが合計 3 つだけ、歩行者 (c1)、自動車 (c2)、およびオートバイ (c3) であると仮定します。したがって、各セルのラベル y は 8 次元ベクトルになります。

その中で:
pc はオブジェクトがグリッド内に存在するかどうか (存在確率) を定義し、
bx、by、bh、bw は境界ボックスを指定し、
c1、c2、c3 はカテゴリを表します。検出されたオブジェクトが車の場合、位置 c2 の値は 1、c1 と c3 の値は 0 になります。
上記の例から最初のグリッドが選択されていると仮定します。

このグリッドにはオブジェクトがないため、pc はゼロになり、このグリッドの y ラベルは次のようになります。

? グリッドにはオブジェクトがないため、他の値が何であるかは問題ではないことを意味します。車が含まれるグリッドの別の例 (c2=1) を次に示します。

このグリッドの y ラベルを記述する前に、実際のオブジェクトがグリッド内に存在するかどうかを YOLO がどのように判断するかを最初に理解することが重要です。全体像には 2 つのオブジェクト (2 台の車) があるため、YOLO はこれら 2 つのオブジェクトの中心点を取得し、これらのオブジェクトの中心を含むグリッドにオブジェクトが割り当てられます。中心点の左側にあるグリッドの Y ラベルは次のようになります。

このグリッドにはオブジェクトがあるため、pc は 1 に等しく、bx、by、bh、bw は処理される特定のグリッド セルを基準にして計算されます。検出物体は車なのでc2=1となり、c1、c3ともに0となります。9 つのグリッド内の各セルには、8 次元の出力ベクトルがあります。最終的な出力形状は 3X3X8 です。
上記の例 (入力画像: 100X100X3、出力: 3X3X8) を使用すると、モデルは次のようにトレーニングされます。

従来の CNN ネットワークを使用してモデルを構築し、モデルのトレーニングを実行します。テストフェーズでは、画像がモデルに渡され、前方パスの後に出力 y が取得されます。簡単にするために、これは 3X3 グリッドを使用して説明されていますが、実際のシーンでは通常、より大きなグリッド (19X19 など) が使用されます。
オブジェクトが複数のメッシュにまたがる場合でも、オブジェクトはその中点がある単一のメッシュにのみ割り当てられます。同じグリッド セルに複数のオブジェクトが表示される可能性は、グリッドを追加することで減らすことができます。
2.2 YOLOv5 の取得とデバッグ
2.2.1 yolov5 コードのダウンロード
git がある場合は git clone を使用します
git clone https://github.com/ultralytics/yolov5 # clone
git がない場合は、Dwonload ZIP を使用してコード プロジェクトをダウンロードできます。
yolov5 コード アドレス: yolov5
注: yolov5 コードは最新の v8.0 バージョンです。
バージョン 6.0 は、このリンク https://github.com/ultralytics/yolov5/tree/v6.0 からダウンロードできます。
2.2.2 yolov5 トレーニングに必要なサードパーティ ライブラリをインストールします。
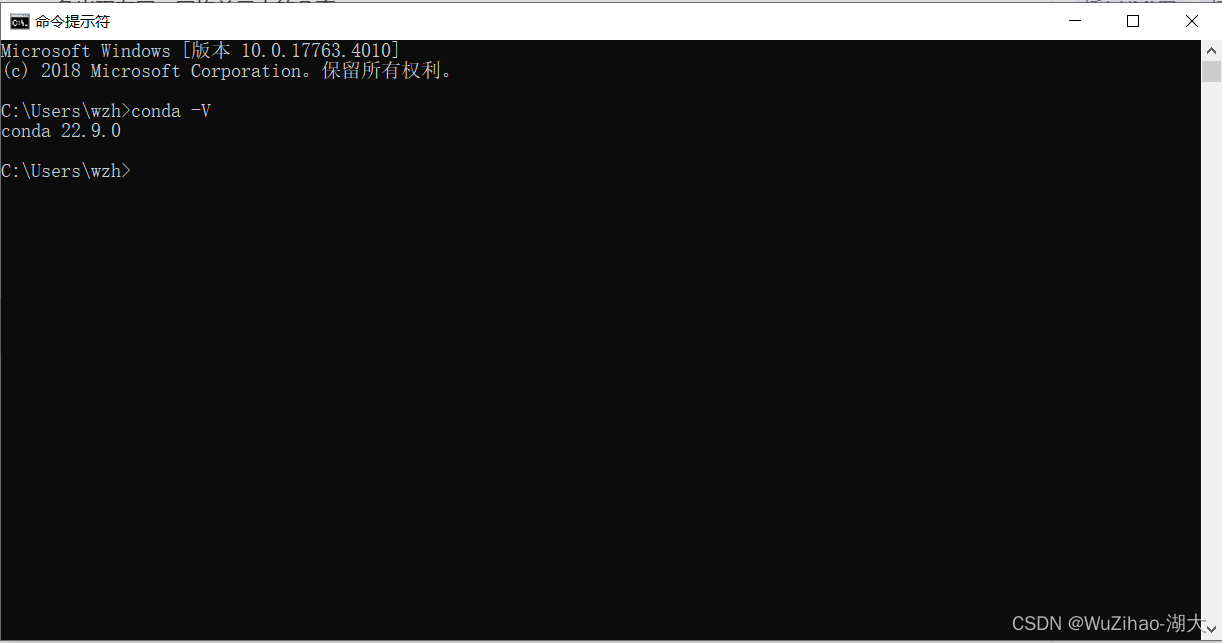
- anacondaが正しくインストールされているか確認してください。
Windows + R を押して cmd を開き、「conda -V」と入力します。バージョン番号が表示されれば、インストールは成功しています。
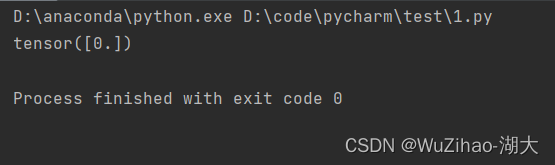
- pytorchが正しくインストールされているかどうかを確認する
import torch
if __name__ == '__main__':
print(torch.zeros(1))
- 次の図に示すように、サードパーティ ライブラリをインストールするには、yolov5 フォルダー ディレクトリを入力し、
cd [path_to_yolov5] を入力してサードパーティ ライブラリをインストールします。
pip install -r requirement.txt
以下の図に示すように、インストールが完了するまで待ちます
2.2.3 事前トレーニングされた重みファイルをダウンロードする
データセットの数が少ない場合でも良好な検出精度を達成できるように、事前トレーニングされた重みファイルをダウンロードし、これに基づいてトレーニングを調整する必要があります。
オプションは、yolov5s、yolov5m、yolov5l、yolov5x です。モデルのサイズが徐々に大きくなり、学習時間が長くなり、正解率が向上します。
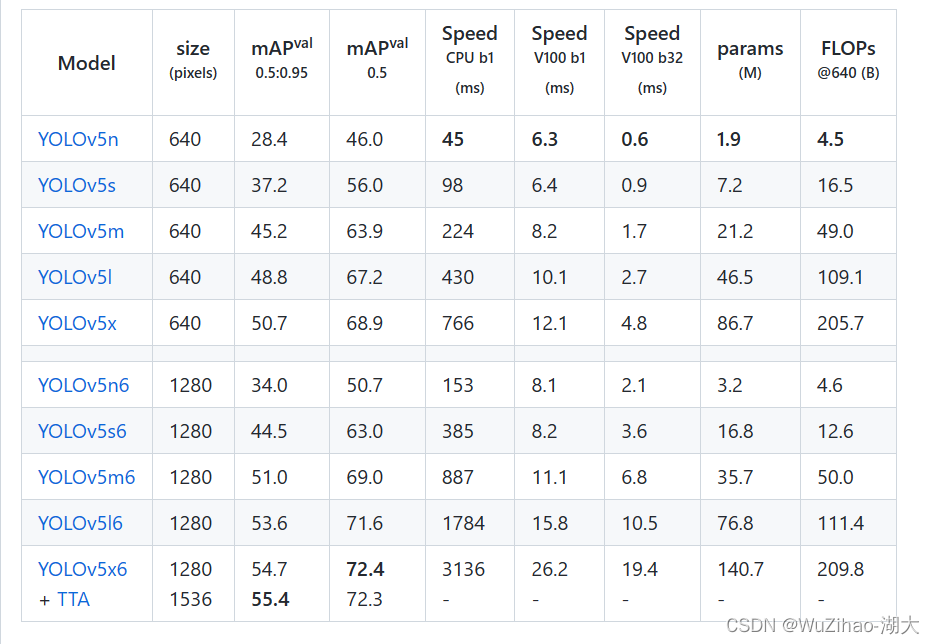
ここでは、トレーニングの例として yolov5s を取り上げます。ダウンロード アドレスはyolov5s.pt で、
すべての重みのダウンロード アドレスは https://github.com/ultralytics/yolov5/releases/tag/v6.0 にあります。
2.2.4 独自の yaml ファイルを構成する
models/yolov5s_mask.yaml を構成するには、yolov5s.yaml ファイルを直接コピーし、 nc、つまりカテゴリで変更することができます。検出された製品の数は 113 です。アンカー パラメータは、データ セットに対して knn クラスタリングを実行することで取得できるアンカー ボックスのサイズを示します。ここでのデフォルトは、COCO データ セットのクラスタリングの結果です。

マスク.yamlを設定します。ここで、 train は、トレーニング データ セットの場所、val テスト データ セットの場所、nc カテゴリの数、および名前カテゴリの名前を指定します (順序に注意してください)。

2.2.5 トレーニングを開始する
python3 train.py --img 640 --batch 8 --epochs 50 --data my.yaml --cfg yolov5s_my.yaml --weights "yolov5s.pt"

グラフィックス カードのスペースが不十分な場合は、-bath パラメータを減らすことができます。
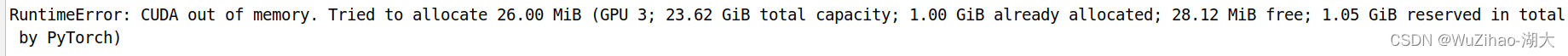
最終的な重みファイルは /runs/train/exp/weights/best.pt の下に生成されます。後で使用するために、
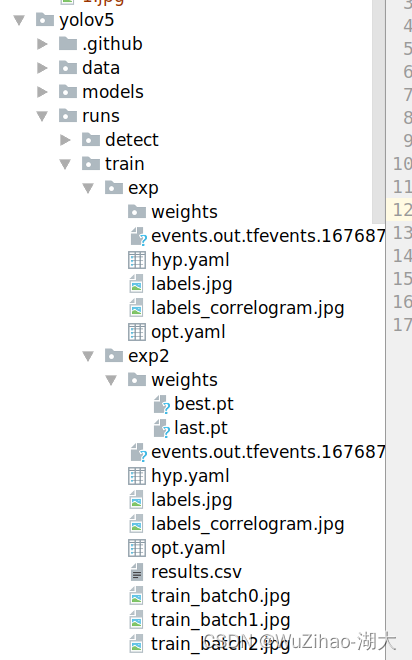
このファイルを yolov5 ディレクトリにコピーします。
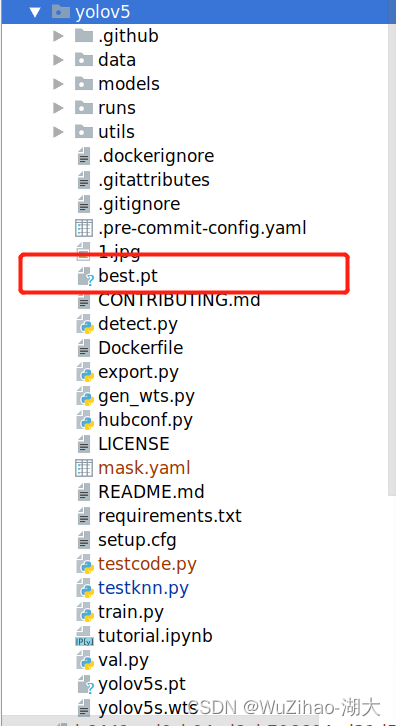
2.2.5 後続の検出呼び出しのための検出メソッドを作成する
今後画像またはビデオの検出を実行する場合は、YOLOv5 モデルと画像を渡すだけで、検出後の画像が返されます。
import os
import sys
from pathlib import Path
import numpy as np
import torch
FILE = Path(__file__).resolve()
ROOT = FILE.parents[0] # YOLOv5 root directory
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
from models.experimental import attempt_load
from utils.general import apply_classifier, check_img_size, check_imshow, check_requirements, check_suffix, colorstr, \
increment_path, non_max_suppression, print_args, save_one_box, scale_coords, strip_optimizer, xyxy2xywh, LOGGER
from utils.plots import Annotator, colors
from utils.torch_utils import load_classifier, select_device, time_sync
from utils.augmentations import Albumentations, augment_hsv, copy_paste, letterbox, mixup, random_perspective
@torch.no_grad()
def detection(model,input_img):
imgsz = 640 # inference size (pixels)
conf_thres = 0.25 # confidence threshold
iou_thres = 0.45 # NMS IOU threshold
max_det = 1000 # maximum detections per image
device = '0' # cuda device, i.e. 0 or 0,1,2,3 or cpu
view_img = False # show results
save_txt = False # save results to *.txt
save_conf = False # save confidences in --save-txt labels
save_crop = False # save cropped prediction boxes
nosave = False # do not save images/videos
classes = None # filter by class: --class 0, or --class 0 2 3
agnostic_nms = False # class-agnostic NMS
augment = False # augmented inference
project = ROOT / 'runs/detect', # save results to project/name
name = 'exp' # save results to project/name
exist_ok = False, # existing project/name ok, do not increment
line_thickness = 3 # bounding box thickness (pixels)
hide_labels = False # hide labels
hide_conf = False # hide confidences
half = False # use FP16 half-precision inference
# Directories
# Initialize
device = select_device(device)
weights = 'best.pt'
# # Load model
w = str(weights[0] if isinstance(weights, list) else weights)
classify, suffix, suffixes = False, Path(w).suffix.lower(), ['.pt', '.onnx', '.tflite', '.pb', '']
check_suffix(w, suffixes) # check weights have acceptable suffix
pt, onnx, tflite, pb, saved_model = (suffix == x for x in suffixes) # backend booleans
stride = int(model.stride.max())
names = model.module.names if hasattr(model, 'module') else model.names # get class names
imgsz = check_img_size(imgsz, s=stride) # check image size
img0 = input_img # BGR
im0s=img0
# Padded resize
img = letterbox(img0, imgsz, stride=32, auto=pt)[0]
# Convert
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img = np.ascontiguousarray(img)
bs = 1 # batch_size
dt, seen = [0.0, 0.0, 0.0], 0
t1 = time_sync()
img = torch.from_numpy(img).to(device)
img = img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if len(img.shape) == 3:
img = img[None] # expand for batch dim
t2 = time_sync()
dt[0] += t2 - t1
# Inference
if pt:
pred = model(img, augment=augment)[0]
t3 = time_sync()
dt[1] += t3 - t2
# NMS
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
dt[2] += time_sync() - t3
# Process predictions
for i, det in enumerate(pred): # per image
seen += 1
im0=im0s.copy()
annotator = Annotator(im0, line_width=line_thickness, example=str(names))
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
# Write results
for *xyxy, conf, cls in reversed(det):
# Add bbox to image
c = int(cls) # integer class
label = None if hide_labels else (names[c] if hide_conf else f'{
names[c]} {
conf:.2f}')
annotator.box_label(xyxy, label, color=colors(c, True))
# Stream results
im0 = annotator.result()
return im0
3.Pyqt5
pyqtを使用して表示インターフェイスを作成します
3.1 はじめに
PyQt5 は Digia の Qt5 アプリケーション フレームワークと Python を組み合わせたもので、python2.x と python3.x の両方をサポートします。
ここではPython 3.xを使用します。Qt ライブラリは Riverbank Computing によって開発され、最も強力な GUI ライブラリの 1 つです。
PyQt5 は一連の Python モジュールで構成されています。620 を超えるクラス、6000 の関数とメソッド。Unix、Windows、Mac OS などの主要なオペレーティング システムで動作します。PyQt5 には、GPL と商用の 2 つのライセンスがあります。
3.2 Windows プラットフォームのインストール
PyQt5 をインストールするには 2 つの方法があり、1 つは公式 Web サイトからソースコードをダウンロードする方法、もう 1 つは pip を使用してインストールする方法です。
ここでは pip インストールを使用することをお勧めします。Python のバージョンに応じて適切な PyQt5 バージョンが自動的に選択されるため、手動でソース コードをダウンロードしてインストールすると、間違いが発生します。より安全なインストール方法を使用することをお勧めします。
pip3 install PyQt5
さらに、外部ネットワークへのネットワーク アクセスがあまり良好でない場合は、Douban ミラーを使用してダウンロードすることをお勧めします。そうしないと、速度が非常に遅くなったり、インストールが直接失敗したりします。
pip install PyQt5 -i https://pypi.douban.com/simple
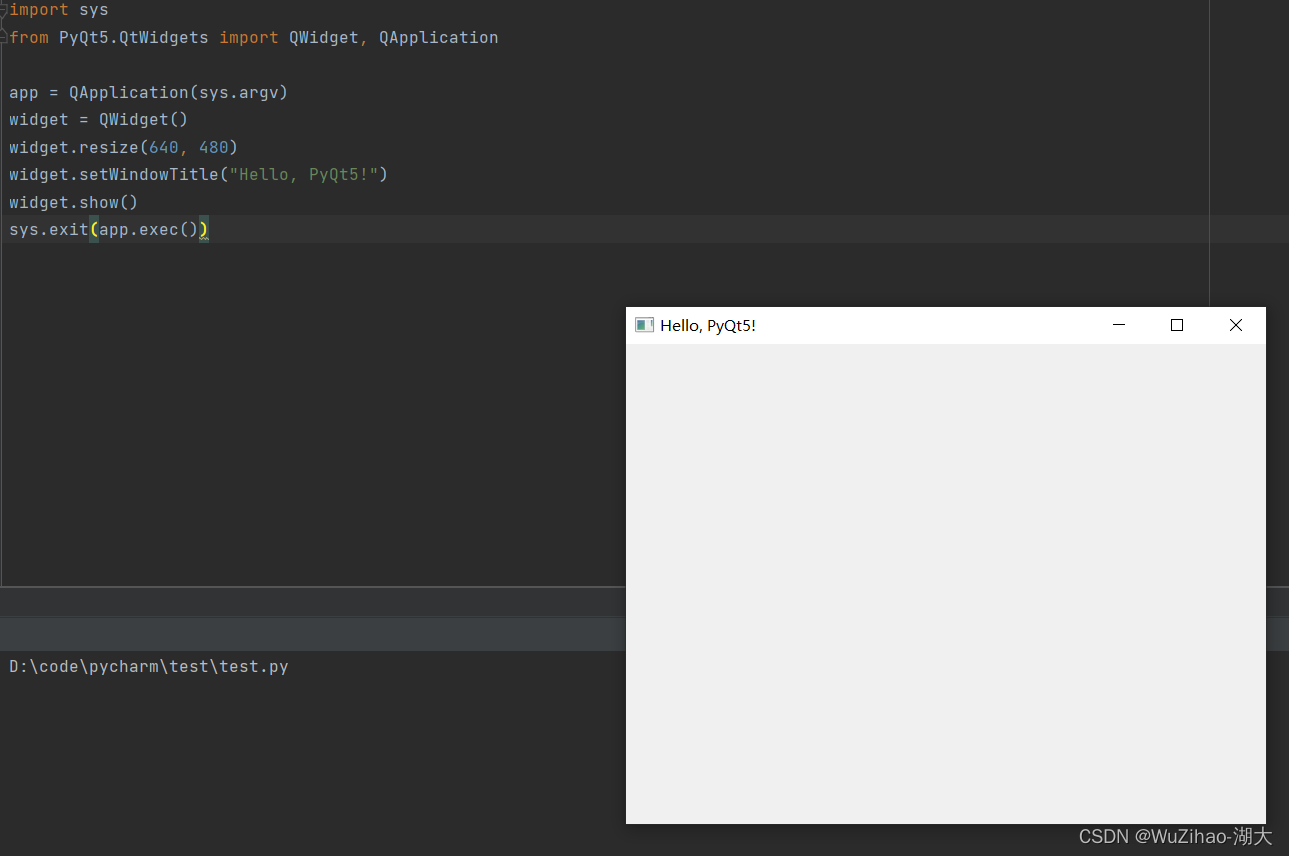
次のコードを実行します。
import sys
from PyQt5.QtWidgets import QWidget, QApplication
app = QApplication(sys.argv)
widget = QWidget()
widget.resize(640, 480)
widget.setWindowTitle("Hello, PyQt5!")
widget.show()
sys.exit(app.exec())
エラーが報告されず、「Hello, PyQt5!」というタイトルのウィンドウが表示されれば、インストールは成功です。
pip が pyqt5 をインストールする場合、エラー エラー: Microsoft Visual C++ 14.0 以降が必要です。「Microsoft C++ Build Tools」で入手してください: https://visualstudio.microsoft.com/visual-cpp-build-tools/
error: Microsoft Visual C++ 14.0 or greater is required. Get it with "Microsoft C++ Build Tools": https://visualstudio.microsoft.com/visual-cpp-build-tools/
私の他の記事を参照してください。解決されました
(pip は pyqt5 をインストールし、エラーを報告します) エラー: Microsoft Visual C++ 14.0 以降が必要です。「Microsoft はプロジェクトを実行するためにこれを行うことができます。pyqt に興味がある場合」で入手してください。 、グラフィカル インターフェイス開発ツール Qt Designer などについては、記事 https://zhuanlan.zhihu.com/p/162866700 を参照してください。
4.OpenCV
OpenCV (オープン ソース コンピューター ビジョン ライブラリ) は BSD ライセンスに基づいているため、学術目的および商業目的での使用は無料です。C++、C、Python、Java インターフェイスを提供し、Windows、Linux、Mac OS、iOS、Android をサポートします。
画像を Yolov5 モデルで必要な入力に変換するために、OpenCV を使用して画像とビデオを処理します。
インストール
まず、opencv の依存ライブラリである別のサードパーティ ライブラリ numpy をインストールする必要があり、これがないと python-opencv 開発を実行できません。
numpy をインストールします: pip install numpy
opencv-python をインストールします: pip install opencv-python
5. 画像検出
5.1 インターフェースのレイアウト
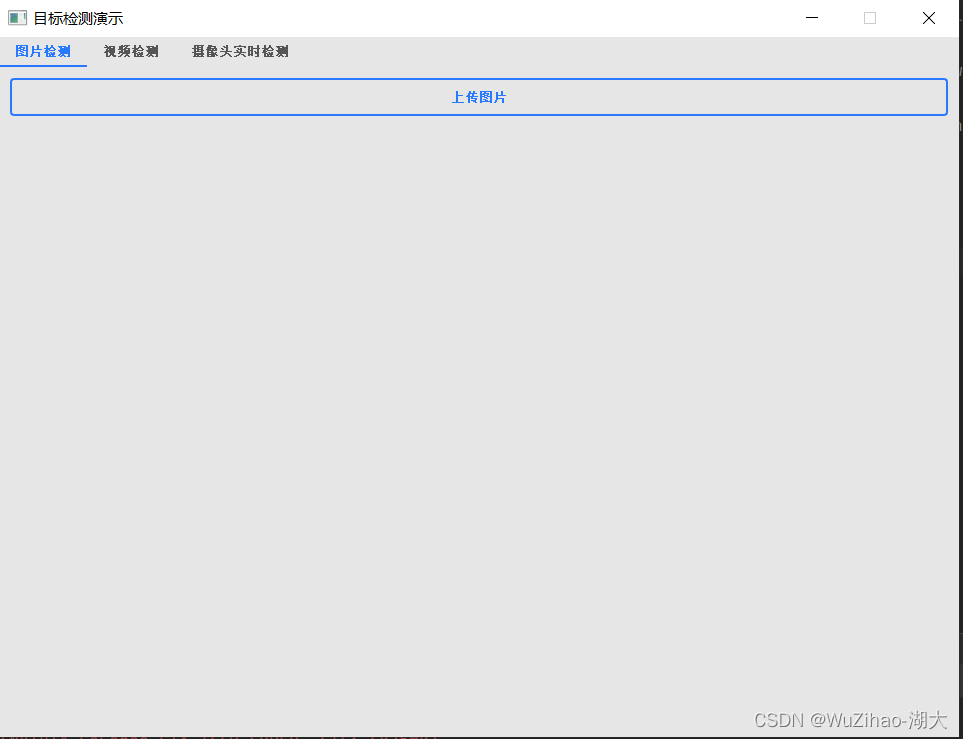
まず、pyqt を使用してインターフェイスのレイアウトを設計します。これは主に画像をアップロードするためのボタンと 2 つの表示ボードであり、1 つは元の画像を表示し、もう 1 つはモデルのテスト後の画像を表示します。ここでの主な用途はグリッド レイアウト QGridLayout() です。
class Qdetection1(QWidget):
def __init__(self,model):
super(Qdetection1, self).__init__()
self.initUI()
self.model=model
def initUI(self):
self.main_layout = QGridLayout() # 创建主部件的网格布局
self.setLayout(self.main_layout) # 设置窗口主部件布局为网格布局
self.button1 = QPushButton('上传图片')
self.button1.clicked.connect(self.loadImage)
self.main_layout.addWidget(self.button1)
self.imageLabel1 = QLabel()
self.main_layout.addWidget(self.imageLabel1)
self.imageLabel2 = QLabel()
self.main_layout.addWidget(self.imageLabel2)
self.main_layout.addWidget(self.button1, 0, 0, 1, 2)
self.main_layout.addWidget(self.imageLabel1, 2, 0, 1, 1)
self.main_layout.addWidget(self.imageLabel2, 2, 1, 1, 1)
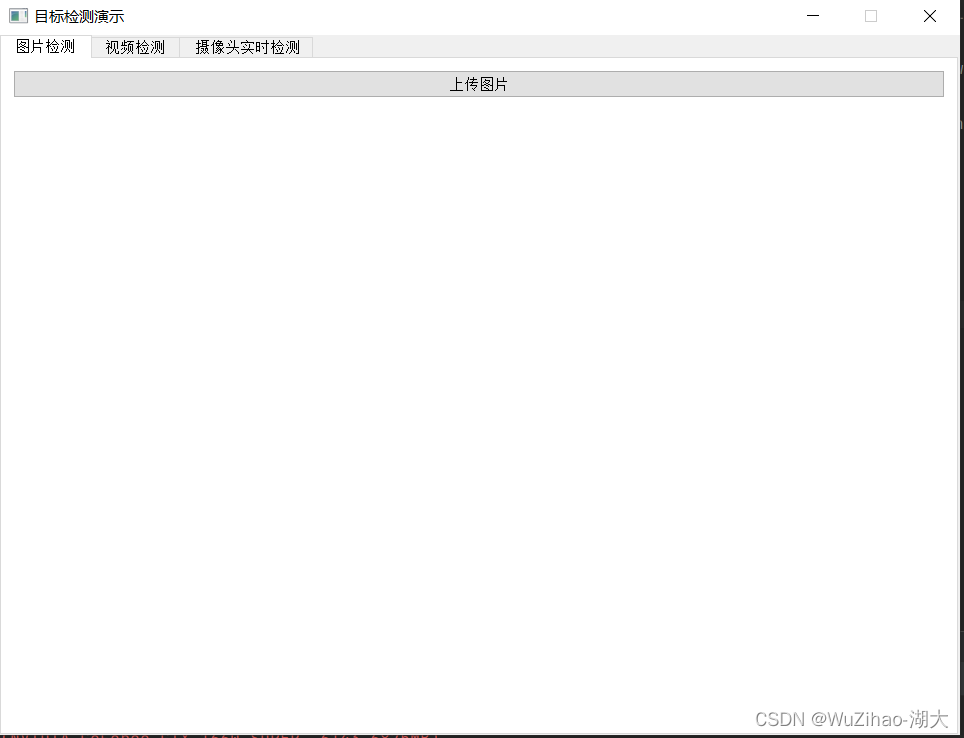
後続でビデオ検出とカメラのリアルタイム検出があるため、同じインターフェイスに統合するには、QTabWidget() を使用できます。
my_tabwidget=QTabWidget()
tab1_widget=Qdetection1(model)
tab2_widget = Qdetection2(model)
tab3_widget = Qdetection3(model)
my_tabwidget.setWindowTitle('目标检测演示 ')
my_tabwidget.addTab(tab1_widget, '图片检测')
my_tabwidget.addTab(tab2_widget, '视频检测')
my_tabwidget.addTab(tab3_widget, '摄像头实时检测')
my_tabwidget.show()
pyqt が提供する元のコンポーネントは美しくありませんが、qt_material を使用してコンポーネントを美しくすることができます。インストールと使用は比較的簡単です。
インストール
pip install qt_material
使用
import sys
from PyQt5 import QtWidgets
from qt_material import apply_stylesheet
# create the application and the main window
app = QtWidgets.QApplication(sys.argv)
window = QtWidgets.QMainWindow()
# setup stylesheet
apply_stylesheet(app, theme='dark_teal.xml')
# run
window.show()
app.exec_()
コントラスト効果
5.2 モデルのロード
使用するにはトレーニング済みモデルを読み取ってロードする必要があります。応答速度を向上させ、各関数が繰り返しロードされるのを防ぐために、ウィンドウの起動時にロードするために使用されます。
if __name__ == '__main__':
device = select_device('0')
# Load model
weights = 'best.pt'
w = str(weights[0] if isinstance(weights, list) else weights)
classify, suffix, suffixes = False, Path(w).suffix.lower(), ['.pt', '.onnx', '.tflite', '.pb', '']
check_suffix(w, suffixes) # check weights have acceptable suffix
pt, onnx, tflite, pb, saved_model = (suffix == x for x in suffixes) # backend booleans
stride, names = 64, [f'class{
i}' for i in range(1000)] # assign defaults
if pt:
model = torch.jit.load(w) if 'torchscript' in w else attempt_load(weights, map_location=device)
stride = int(model.stride.max()) # model stride
names = model.module.names if hasattr(model, 'module') else model.names # get class names
5.3 アップロード ボタン イベントをクリックしてディスプレイ バインディングを検出する
アップロード ボタンをクリックすると、cv2 を通じてファイルが読み取られ、検出メソッドによって画像が検出されます。次に、結果を対応する表示ボードに一時的に置きます。
def loadImage(self):
fname, _ = QFileDialog.getOpenFileName(self, '打开文件', '.', '图像文件(*.jpg *.png)')
if fname is None or fname=="":
print("未选择图片")
else:
img = cv2.imread(fname)
np_img=detection(self.model,img)
np_img = cv2.cvtColor(np_img, cv2.COLOR_BGR2RGB)
img=cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
self.imageLabel1.setPixmap(QPixmap(QImage(img.data, img.shape[1], img.shape[0], img.shape[1]*3, QImage.Format_RGB888)))
self.imageLabel2.setPixmap(QPixmap(QImage(np_img.data, np_img.shape[1], np_img.shape[0], np_img.shape[1]*3, QImage.Format_RGB888)))
5.4 完全なコード
import torch
from utils.general import check_suffix
from utils.torch_utils import select_device
from pathlib import Path
import sys
from PyQt5.QtCore import *
from PyQt5.QtGui import *
from PyQt5.QtWidgets import *
import time
import cv2
from mydetection import detection
from yolov5.models.experimental import attempt_load
class Qdetection1(QWidget):
def __init__(self,model):
super(Qdetection1, self).__init__()
self.initUI()
self.model=model
def initUI(self):
self.main_layout = QGridLayout() # 创建主部件的网格布局
self.setLayout(self.main_layout) # 设置窗口主部件布局为网格布局
self.button1 = QPushButton('上传图片')
self.button1.clicked.connect(self.loadImage)
self.main_layout.addWidget(self.button1)
self.imageLabel1 = QLabel()
self.main_layout.addWidget(self.imageLabel1)
self.imageLabel2 = QLabel()
self.main_layout.addWidget(self.imageLabel2)
self.main_layout.addWidget(self.button1, 0, 0, 1, 2)
self.main_layout.addWidget(self.imageLabel1, 2, 0, 1, 1)
self.main_layout.addWidget(self.imageLabel2, 2, 1, 1, 1)
def loadImage(self):
fname, _ = QFileDialog.getOpenFileName(self, '打开文件', '.', '图像文件(*.jpg *.png)')
if fname is None or fname=="":
print("未选择图片")
else:
img = cv2.imread(fname)
np_img=detection(self.model,img)
np_img = cv2.cvtColor(np_img, cv2.COLOR_BGR2RGB)
img=cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
self.imageLabel1.setPixmap(QPixmap(QImage(img.data, img.shape[1], img.shape[0], img.shape[1]*3, QImage.Format_RGB888)))
self.imageLabel2.setPixmap(QPixmap(QImage(np_img.data, np_img.shape[1], np_img.shape[0], np_img.shape[1]*3, QImage.Format_RGB888)))
if __name__ == '__main__':
app = QApplication(sys.argv)
device = select_device('0')
# Load model
weights = 'best.pt'
w = str(weights[0] if isinstance(weights, list) else weights)
classify, suffix, suffixes = False, Path(w).suffix.lower(), ['.pt', '.onnx', '.tflite', '.pb', '']
check_suffix(w, suffixes) # check weights have acceptable suffix
pt, onnx, tflite, pb, saved_model = (suffix == x for x in suffixes) # backend booleans
stride, names = 64, [f'class{
i}' for i in range(1000)] # assign defaults
if pt:
model = torch.jit.load(w) if 'torchscript' in w else attempt_load(weights, map_location=device)
stride = int(model.stride.max()) # model stride
names = model.module.names if hasattr(model, 'module') else model.names # get class names
my_tabwidget=QTabWidget()
tab1_widget=Qdetection1(model)
my_tabwidget.setWindowTitle('目标检测演示 ')
my_tabwidget.addTab(tab1_widget, '图片检测')
my_tabwidget.show()
apply_stylesheet(app, theme='light_blue.xml')
sys.exit(app.exec_())
最終効果