Big Data: Spark-Kernel-Scheduling
2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开
测开的话,你就得学数据库,sql,oracle,尤其sql要学,当然,像很多金融企业、安全机构啥的,他们必须要用oracle数据库
这oracle比sql安全,强大多了,所以你需要学习,最重要的,你要是考网络警察公务员,这玩意你不会就别去报名了,耽误时间!
与此同时,既然要考网警之数据分析应用岗,那必然要考数据挖掘基础知识,今天开始咱们就对数据挖掘方面的东西好生讲讲 最最最重要的就是大数据,什么行测和面试都是小问题,最难最最重要的就是大数据技术相关的知识笔试
Big Data: Spark-Kernel-Scheduling

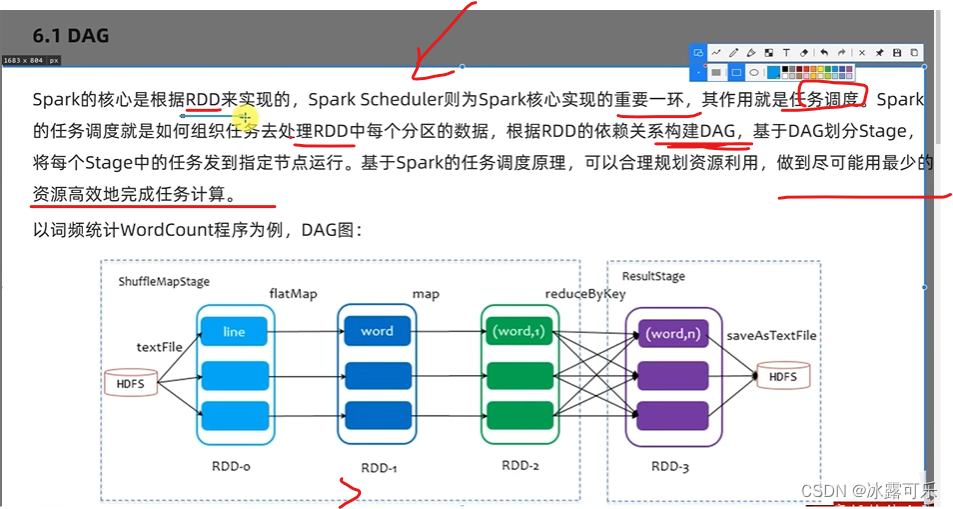
DAG, Richtungs-Ankreis-Azyklischer Graph Die Aktion
des DAG-gerichteten azyklischen Graphen
ist ein Ausführungsschalter
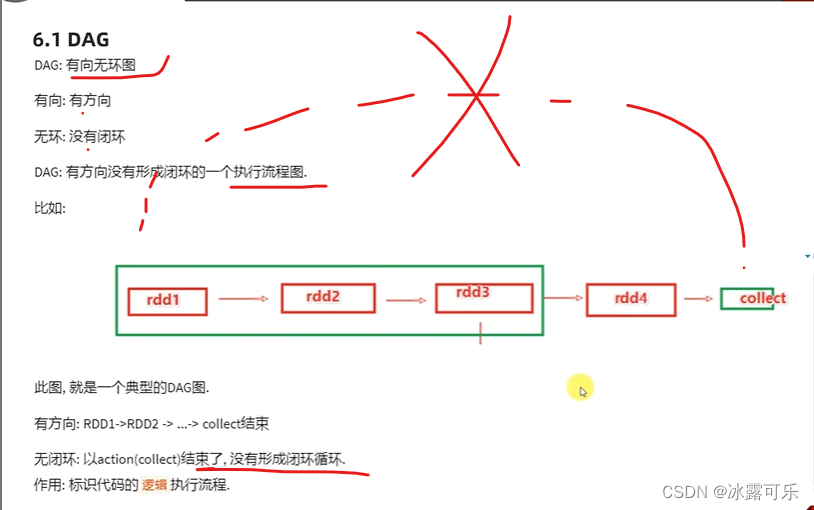
. Vor der Ausführung gibt es eine iterative Kette.
Diese Kette ist ein DAG-gerichteter azyklischer Graph
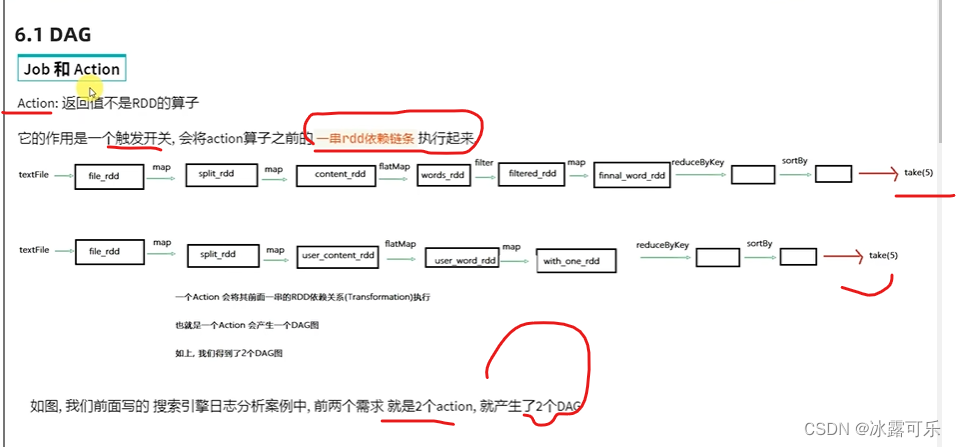
Es dient dazu, das Flussdiagramm auszuführen. Sie müssen es nicht ausführen. Sie können anhand des Codes erkennen, wie Sie es ausführen möchten.
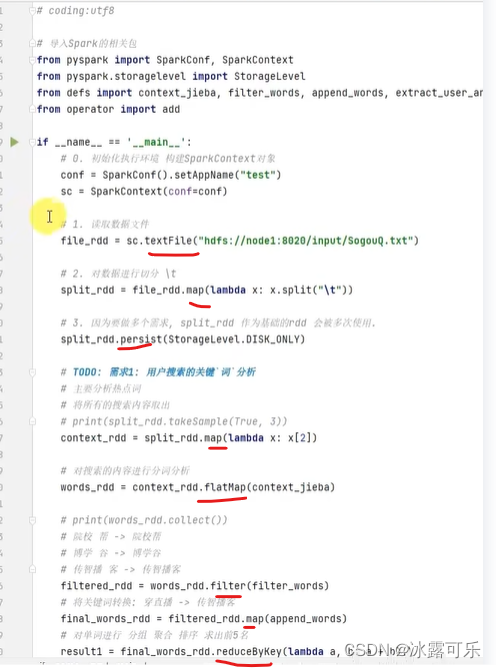
Erstellen Sie Schritt für Schritt ein DAG-Diagramm

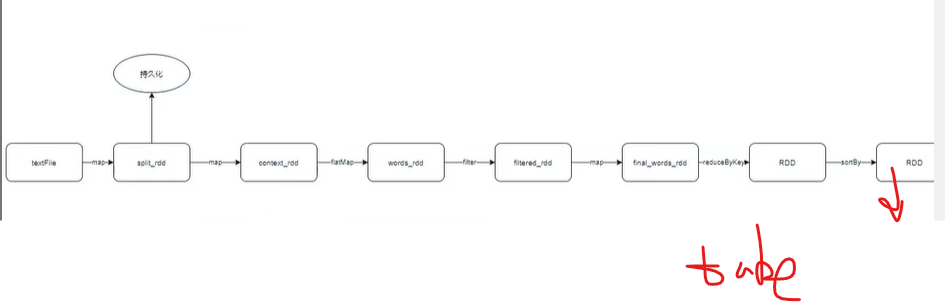
, erstellen Sie ein DAG,
und alle Aufgaben können erledigt werden, da der Vorgang beginnt
Weiter mit Anforderung 2
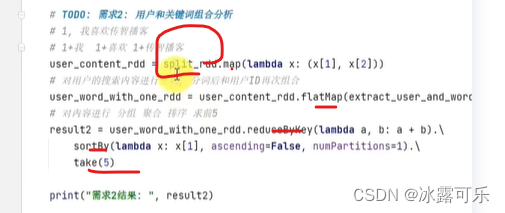
: Der Take, der mit split_rdd abgespielt wurde,
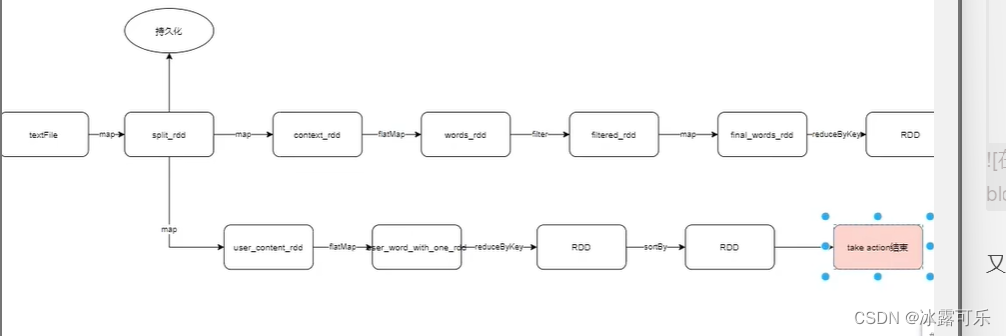
ist der Auslöseschalter.
Der persistente Cache kann direkt verwendet werden

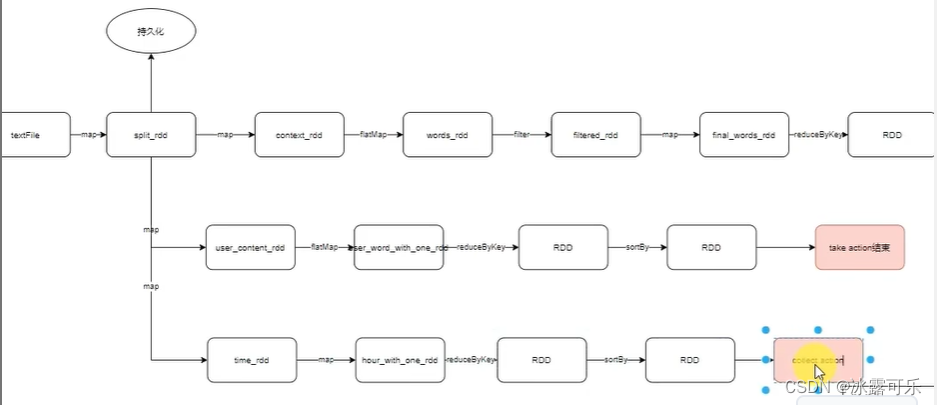
Jede Aktion hat ihre eigene Kette
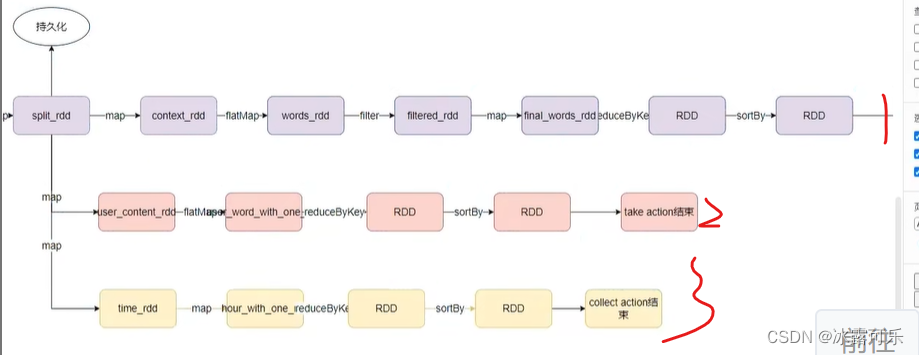
Eine Aktion löst eine Jobanwendungsunteraufgabe Job
Job
Eine Kette ist ein Job
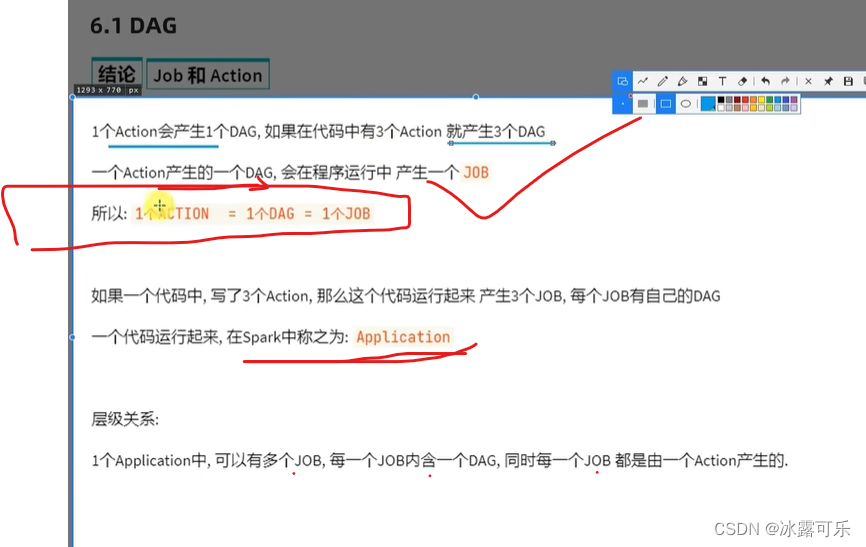
Verstehen Sie, dass es so viele Aktionen gibt, dass es auch so viele Dags gibt.
Eine Anwendung enthält mehrere Aktionen, also mehrere Jobs
verstanden
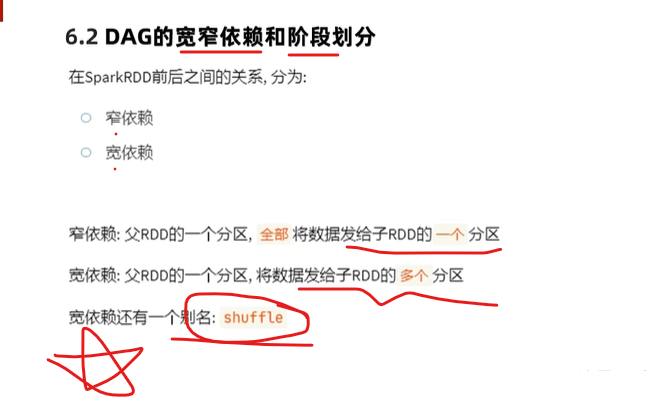
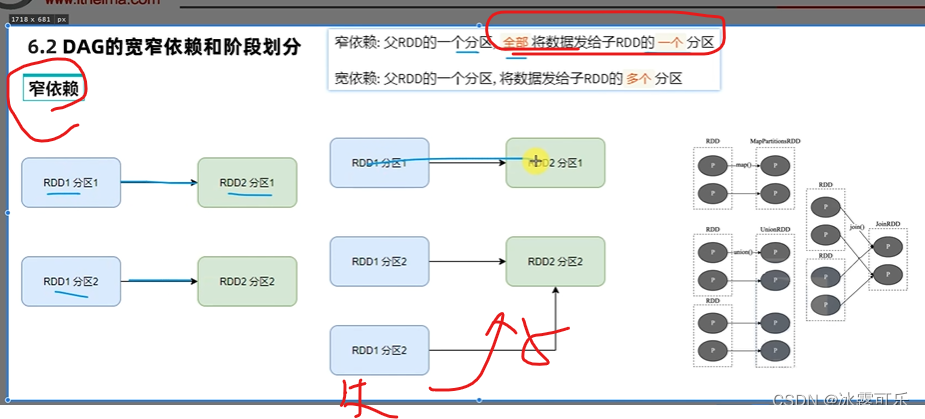
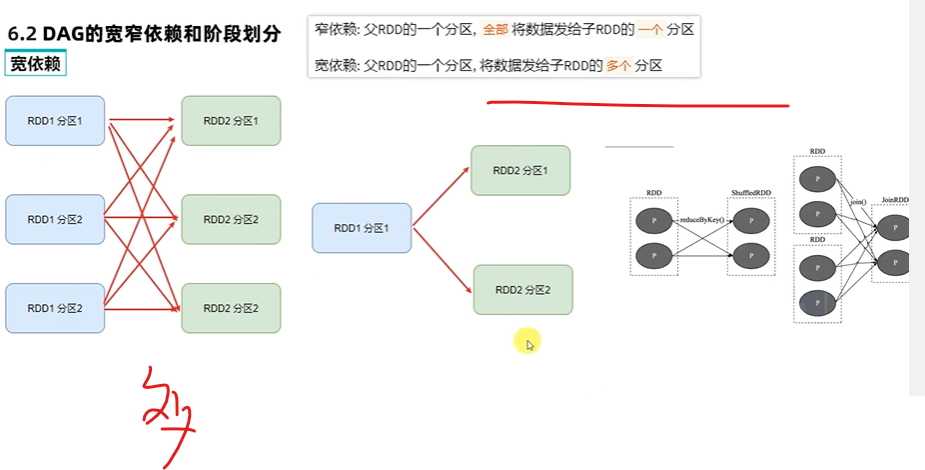
Gabel
Eine enge Abhängigkeit ist schmeichelhaft.
Threads werden zwischen verschiedenen Executoren ausgeführt
, sodass die Übertragung von Daten dazu führen kann, dass die Netzwerk-E/A-Leistung voll ist.
Wie soll ich es sagen?
Die Stufen enger Abhängigkeiten werden also alle im selben Speicher berechnet ? Ist es nicht notwendig, io zu übertragen?
Kann es im selben Thread verarbeitet werden?
Sehr gut.
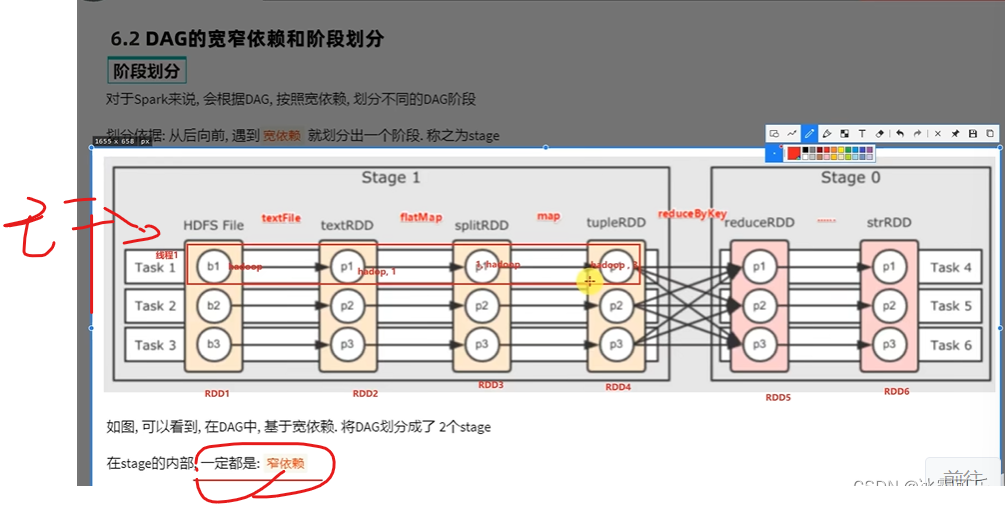
Thread 1 führt eine Zeile aus, eine Pipe für In-Memory-Berechnungen. Dies wird als Speicher-Computing-Pipeline bezeichnet , die als Pipeline bezeichnet wird.
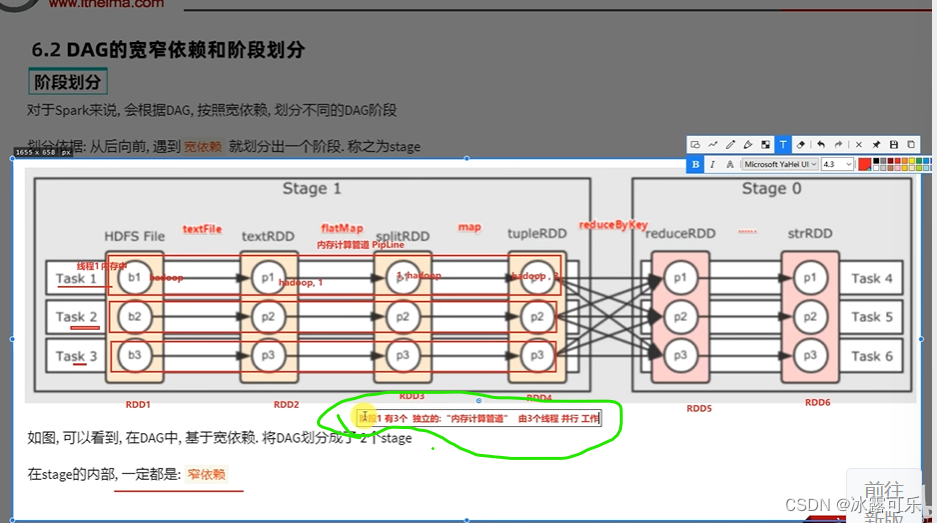
Das Gleiche, das Gleiche rechts
Dann muss die große Abhängigkeit zum Netzwerk io
oder allen zum gleichen Executor gehen, was auch im Speicher berechnet wird [schwierig]
Wenn Sie Netzwerk-IO verwenden müssen, müssen Sie es übertragen. Wie auch immer, das Innere der Computerpipeline ist einfach schmeichelhaft.
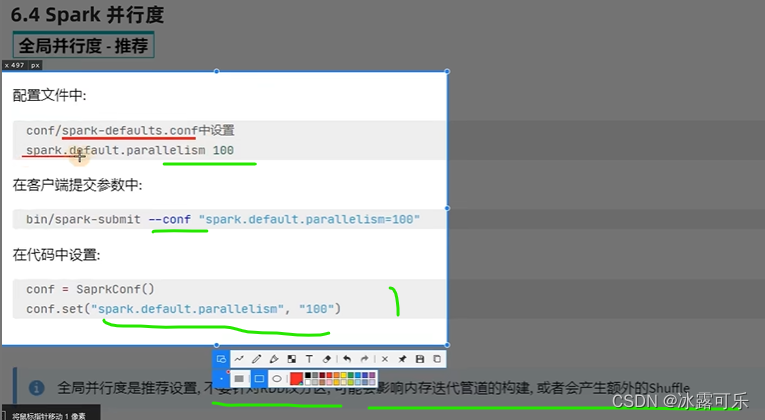
Die Priorität der Spark-Parallelität liegt natürlich darin, dass die
Berechnung des Kernspeichers zweitrangig ist
Sie möchten vollen Speicher, lokalen Wissensmodus, auf keinen Fall den Garnmodus
Big Data kann nicht im vollen Speicher berechnet werden
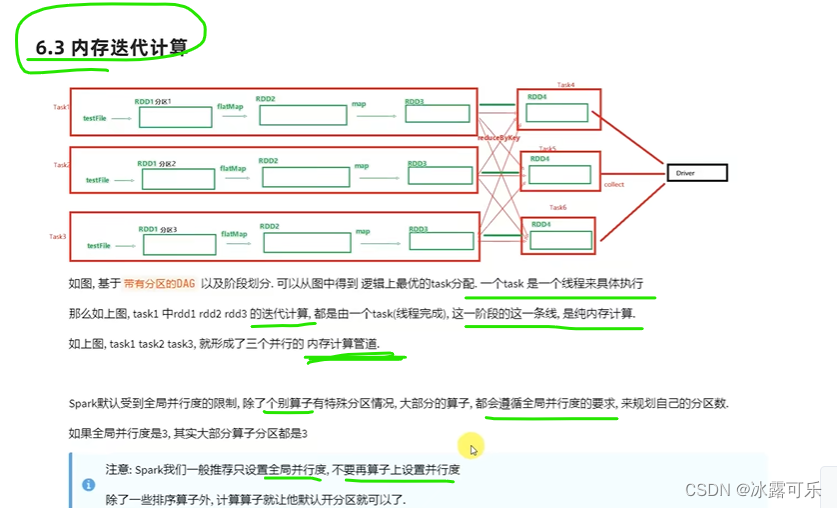
Ändern Sie den Grad der Parallelität nicht, wenn nichts falsch ist
, damit die Leistung garantiert werden kann. Verstehen Sie
?
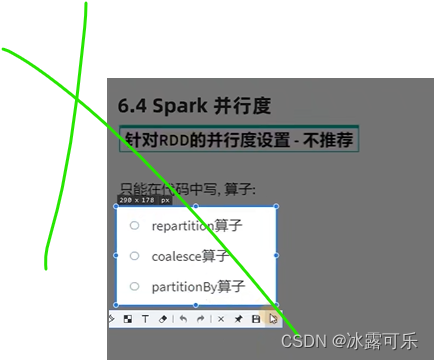
Ändern Sie nicht die Anzahl der Partitionen
Enge Abhängigkeiten führen die Speicheriteration direkt durch, dh Speicherberechnungspipelines, und eine Aufgabe wird
ohne Netzwerk-IO-Übertragung ausgeführt, was die Leistung verbessert
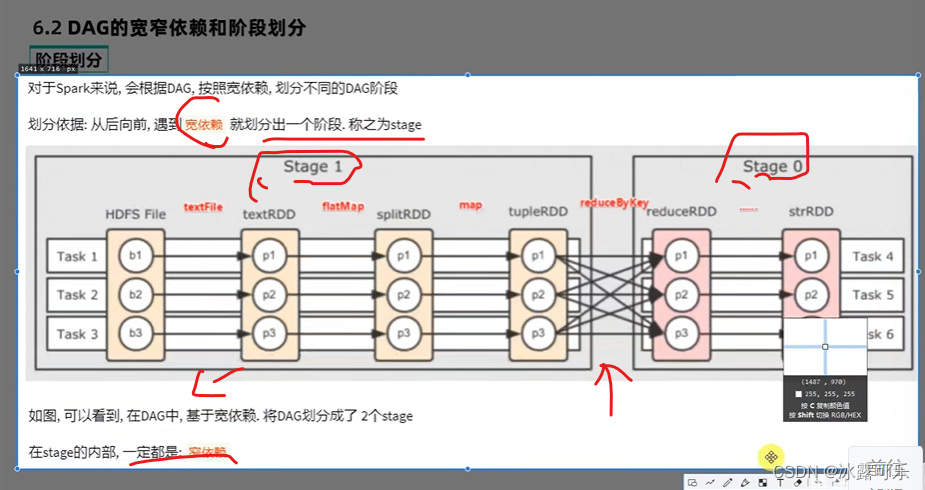
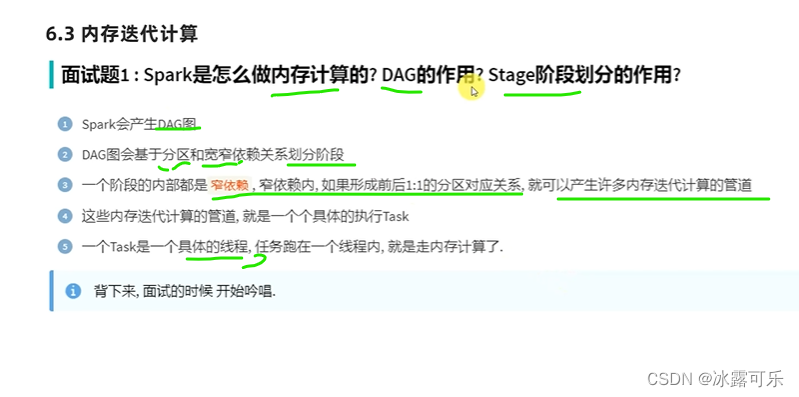
Spark erstellt die DAG
DAG wird rückwärts übertragen, um eine Wide-Narrow-Abhängigkeit zu bilden
Enge Abhängigkeiten sind Pipeline-Berechnungsiterationen
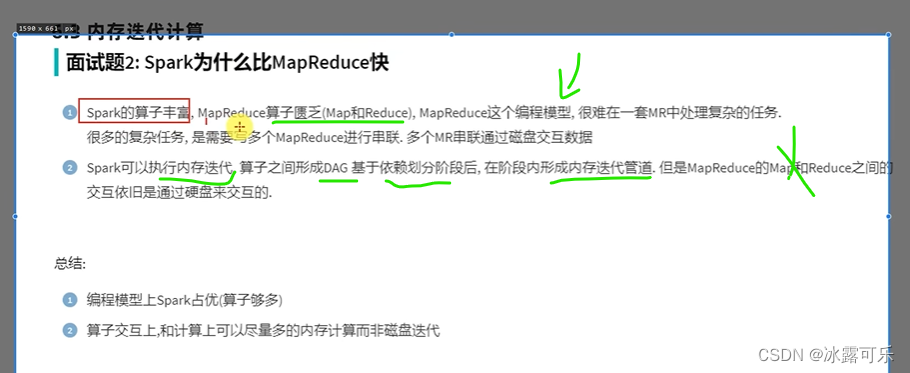
Der Vorteil von Spark gegenüber MapReduce besteht darin, dass es mehr
Operatoren hat und Spark über eine Speicheriterationspipeline verfügt, wodurch viele IO-Netzwerkübertragungen reduziert werden und die Leistung plötzlich hoch ist.
Dies ist das Thema des Interviews. Die Prüfung sollte den

Grad der Parallelität unterscheiden, nicht die Partition.
Die beste Partition ähnelt dem Grad der Parallelität.

Beim Mischen werden die Karten gemischt.
Es ist am besten, das Netzwerk-IO nicht zu mischen oder zu viele Mischvorgänge durchzuführen.
Dies ist schwierig.
Rechenkomplexität
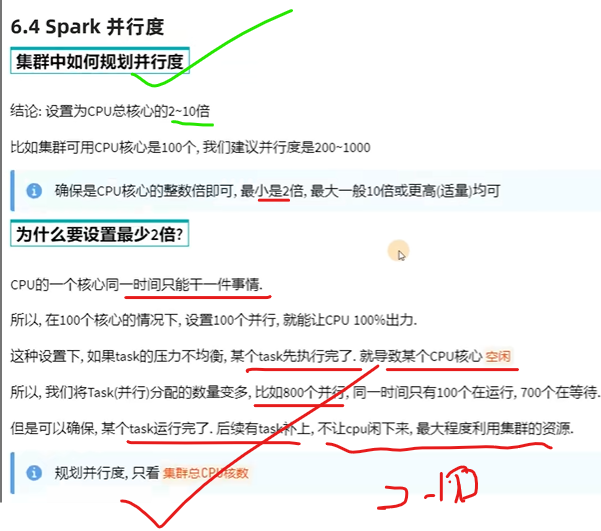
Parallelität beträgt das Zwei- bis Zehnfache der Anzahl der CPUs
Zusammenfassen
提示:重要经验:
1)
2) Orakel gut lernen, auch wenn die Wirtschaft kalt ist, ist das gesamte Testangebot definitiv kein Problem! Gleichzeitig ist es für Sie auch die einzige Möglichkeit, die öffentliche Internetpolizei zu testen.
3) Bei der Suche nach AC im schriftlichen Test darf die Raumkomplexität nicht berücksichtigt werden, aber das Interview muss sowohl die optimale Zeitkomplexität als auch die optimale Raumkomplexität berücksichtigen.