要約: データ インテリジェンスの時代の到来により、マルチクラウドおよびマルチソース アーキテクチャの下でのデータ管理は企業にとって不可欠なインフラストラクチャであり、データ アクセス、データの統合と配布、データ セキュリティとデータ品質がその基盤であると考えています。これは、マルチクラウドとマルチソースへの方法でもあります。アーキテクチャの出発点です。このトピックでは、MySQL および ClickHouse に関連するデータ管理およびレプリケーション テクノロジに焦点を当てて、クラウド ネイティブのマルチクラウドおよびマルチソース データ管理 NineData を紹介します。
2023 年最初のクラウド データベース テクノロジー サロンの MySQL x ClickHouse 特別セッションが杭州海志センターで成功裏に開催されました。このサロンは、NineData、Caigen Development、Liangcang Taiyan の共同主催です。今回は、Jiuzhang Arithmetic Technology の副社長、Chen Changcheng (Tianyu) が「マルチクラウドおよびマルチソースにおけるデータ レプリケーション テクノロジーの公開 - NineData」の技術内容を共有しました。
この記事の内容は、音声録音とPPTに基づいて構成されています。

Jiuzhang Arithmetic Technology の副社長である Chen Changcheng (Tianyu) 氏は、Alibaba Cloud の元上級技術専門家であり、データベース分野で 15 年間働いており、Alibaba のデータベース インフラストラクチャの進化 (IOE から分散リモート マルチアクティブへ) を主導してきました。 、コンテナ化されたストレージとストレージの分離)とクラウドネイティブのデータベースツールシステム構築。
私の次の共有トピックは、「マルチクラウドおよびマルチソース-ナインデータの下でのデータ複製テクノロジーの秘密を明らかにする」であり、主に製品とテクノロジーの解釈が含まれており、誰にとっても理解しやすくなります。

こんにちは、みんな。私は九張算数チームのチェン・チャンチェンです。私たちのチームの使命は、すべての人にデータとクラウドを提供することです。私たちのチームの多くは、アリババ、ファーウェイ、IBMの上級技術専門家です。弊社 CEO の葉正生は、かつて Alibaba Cloud データベース部門の製品管理およびソリューション部門のゼネラルマネージャーを務めていました。私自身、アリで 10 年以上勤務し、主にインフラストラクチャ全体の PASS 層の進化とクラウドネイティブ データベース ツール システムの構築を担当しました。

次に、このセッションの共有アジェンダを紹介します。1 つ目は、マルチクラウドとデータの時代における企業のデジタル変革で遭遇する機会と課題について議論することです。次に、NineData の製品プラットフォームを紹介し、NineData のデータ レプリケーション テクノロジに焦点を当て、2 つの典型的な顧客事例を紹介します。

まずはGartnerのレポートを見てみましょう。このレポートによると、80% 以上の企業がマルチクラウドまたはハイブリッド クラウドを選択するとのことです。Percona のレポートによると、70% 以上の企業がマルチソース データを処理するために複数のデータベースを使用することを選択するとのことです。業界分析レポートでは、企業がマルチソースインフラストラクチャと新しいデータアーキテクチャを効果的に使用できれば、イノベーション能力と全体的な収益性が大幅に向上することがわかりました。しかし、この新しいマルチクラウドとデータの時代において、企業は依然として、データサイロ、マルチソースデータ管理の複雑さ、開発効率など、早急に解決する必要があるいくつかの問題に直面しています。
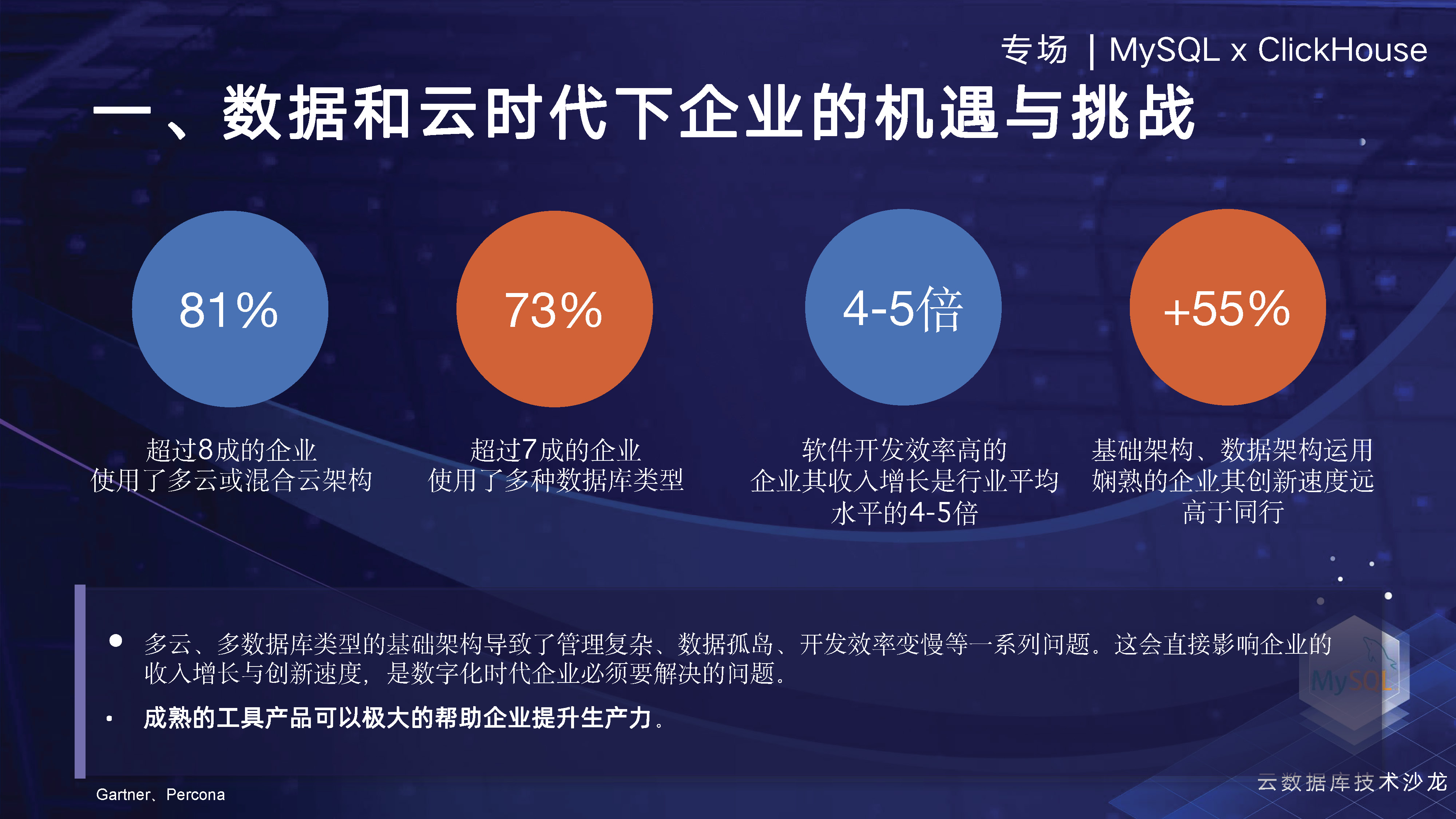
今日の企業のデータ ガバナンスとデータ管理全体を見ると、あらゆる側面に多くの問題が関係しています。NineDataの観点から、これらの問題をどのように解決するかを考えるべきです。
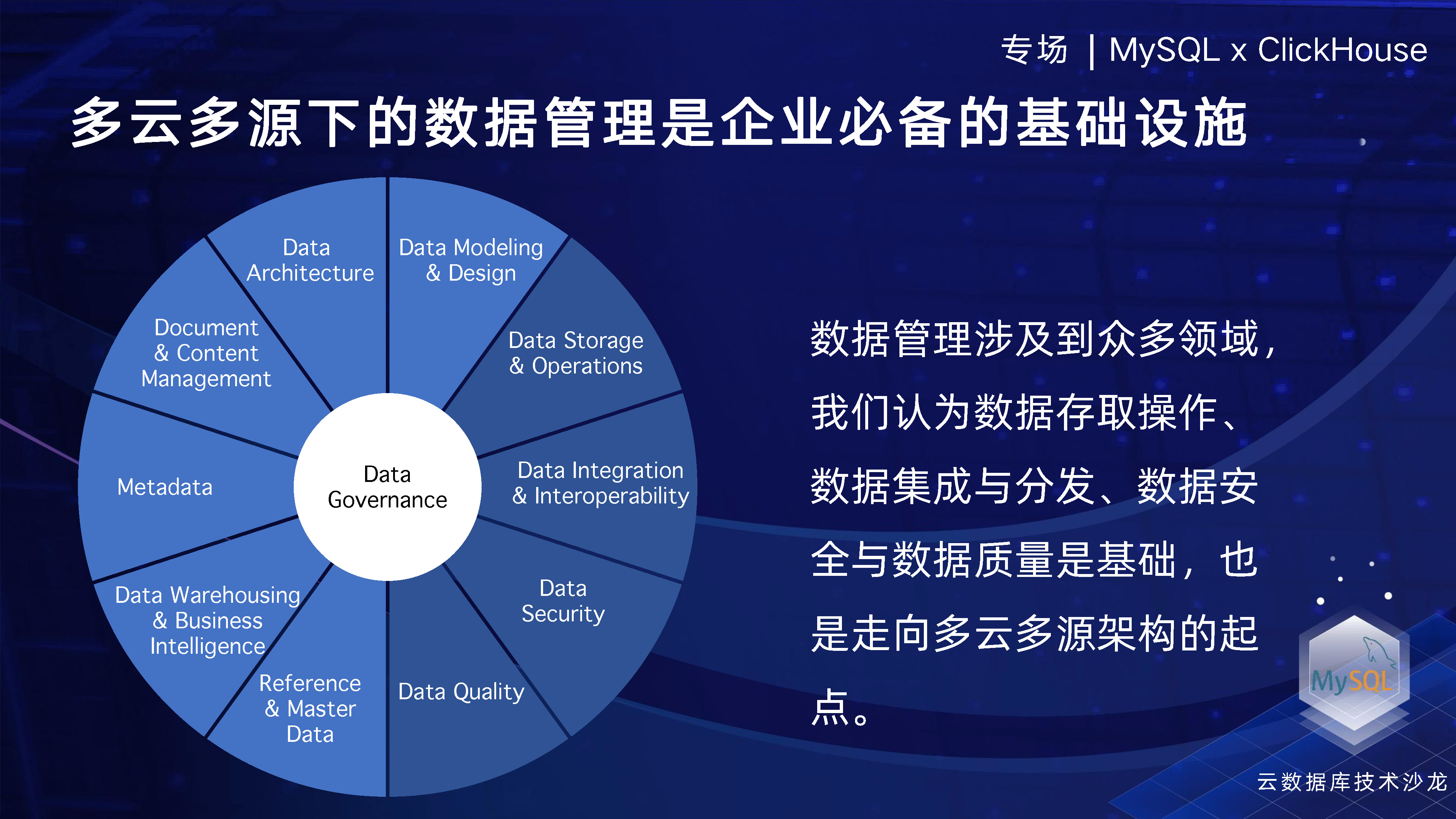
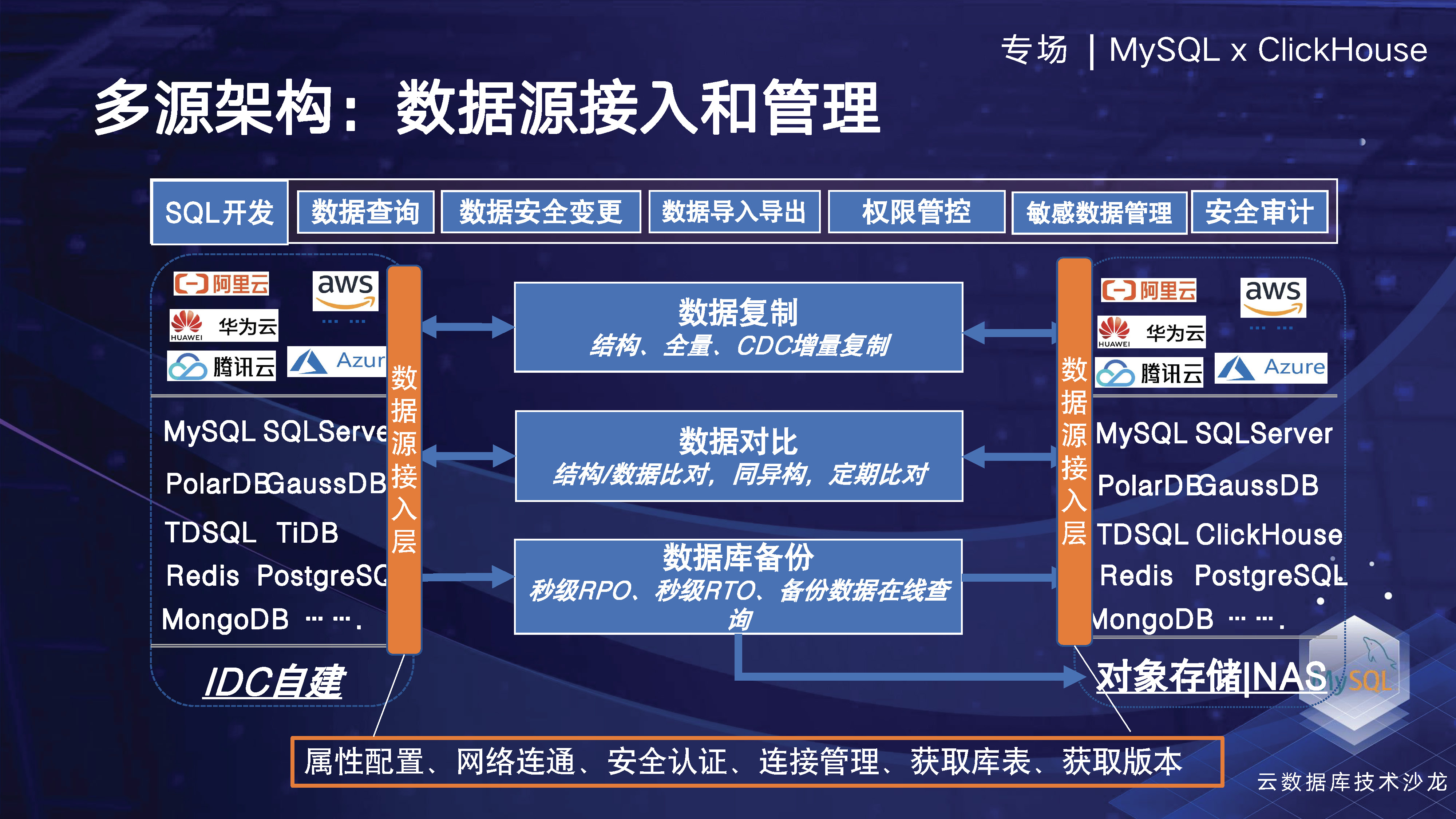
私たちは、エンタープライズ データ管理のプロセス全体で、組み込みのセキュリティ機能を使用して、企業の開発効率とセキュリティを向上させます。これには、エンタープライズ データベースの設計、開発、変更、リリースのライフサイクル全体にわたるセキュリティの実装が含まれます。同時に、マルチソース データ レプリケーション テクノロジーを使用してデータ フローを促進し、データ バックアップ テクノロジーとオンライン クエリ テクノロジーを使用して企業データ資産を保護し、コールド データのデータ価値を向上させます。革新的なテクノロジー手法を使用してデータ資産を保護し、データを増加します。値です。さらに、構造比較、データ比較、複数環境データ比較などの技術的手段を通じて企業のデータ品質を向上させることができます。
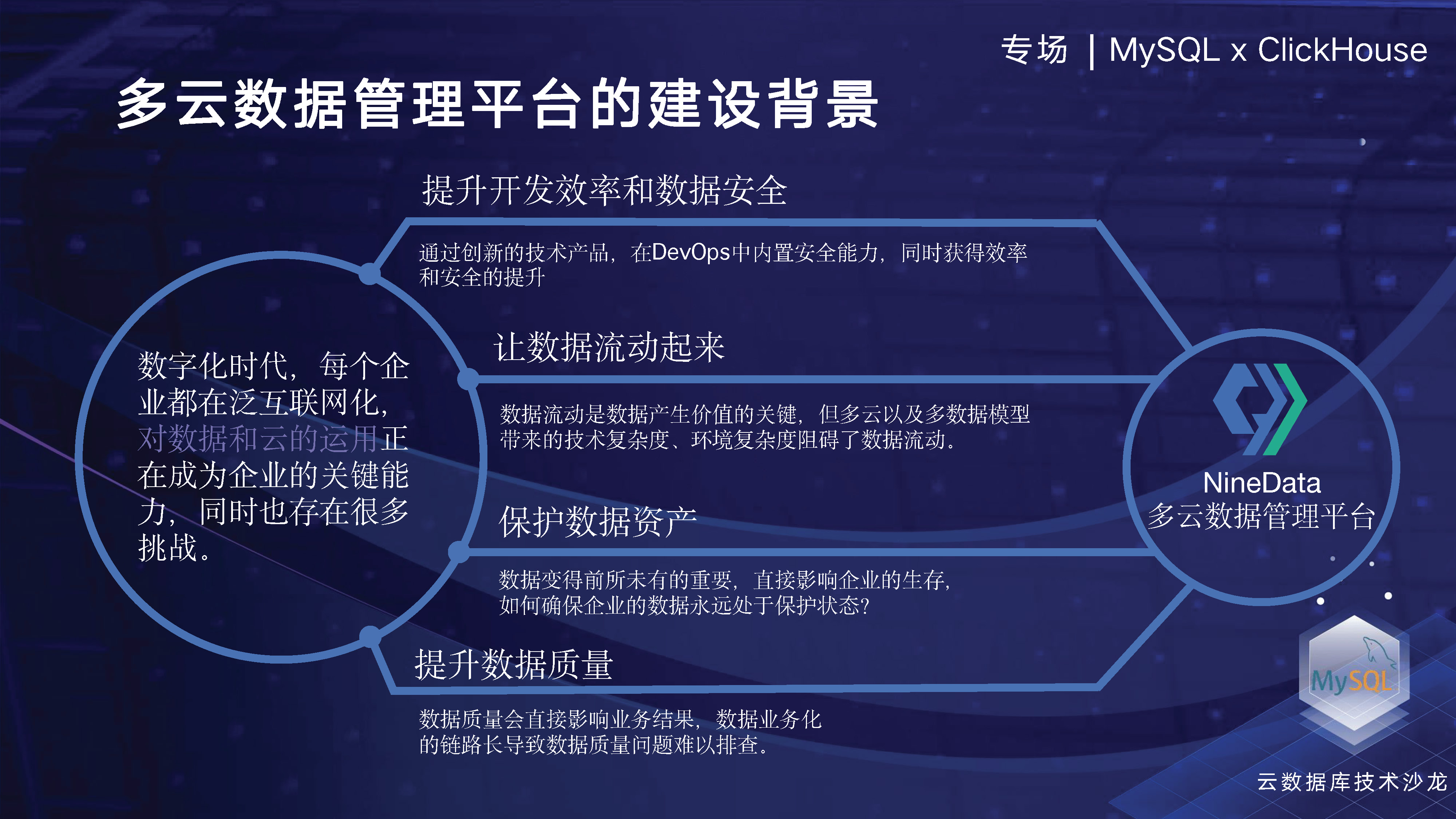
以下の 2 番目のトピックでは、NineData データ管理プラットフォーム全体の主要なアーキテクチャについて説明します。最下層はマルチクラウド、マルチソースをベースとしたインフラ設計であり、バックアップ、レプリケーション、比較、SQL開発といったコアとなる4つの機能モジュールは以前にも紹介しました。次に、マルチソース、マルチクラウドの観点からプラットフォーム全体を紹介します。

マルチクラウド アーキテクチャの観点から見ると、NineData の主な目的は、企業がマルチクラウドまたはハイブリッド クラウドに分散されたさまざまなデータ ソースを管理できるようにすることです。この目的のために、企業がさまざまなクラウド ベンダーに分散したデータ ソースをオフラインで管理できるように、柔軟なクラウド ネイティブ アーキテクチャ、エラスティック アーキテクチャ、ネットワーク構造などを設計しました。同時に、企業が排他的クラスターのテクノロジーを通じて独自のリソースを独占的に享受できるようになります。これには、企業のワーカー ノードをローカルまたは VPC 内に配置して、データの内部閉ループを実現し、企業データのセキュリティとワーカー実行の効率を向上できることが含まれます。
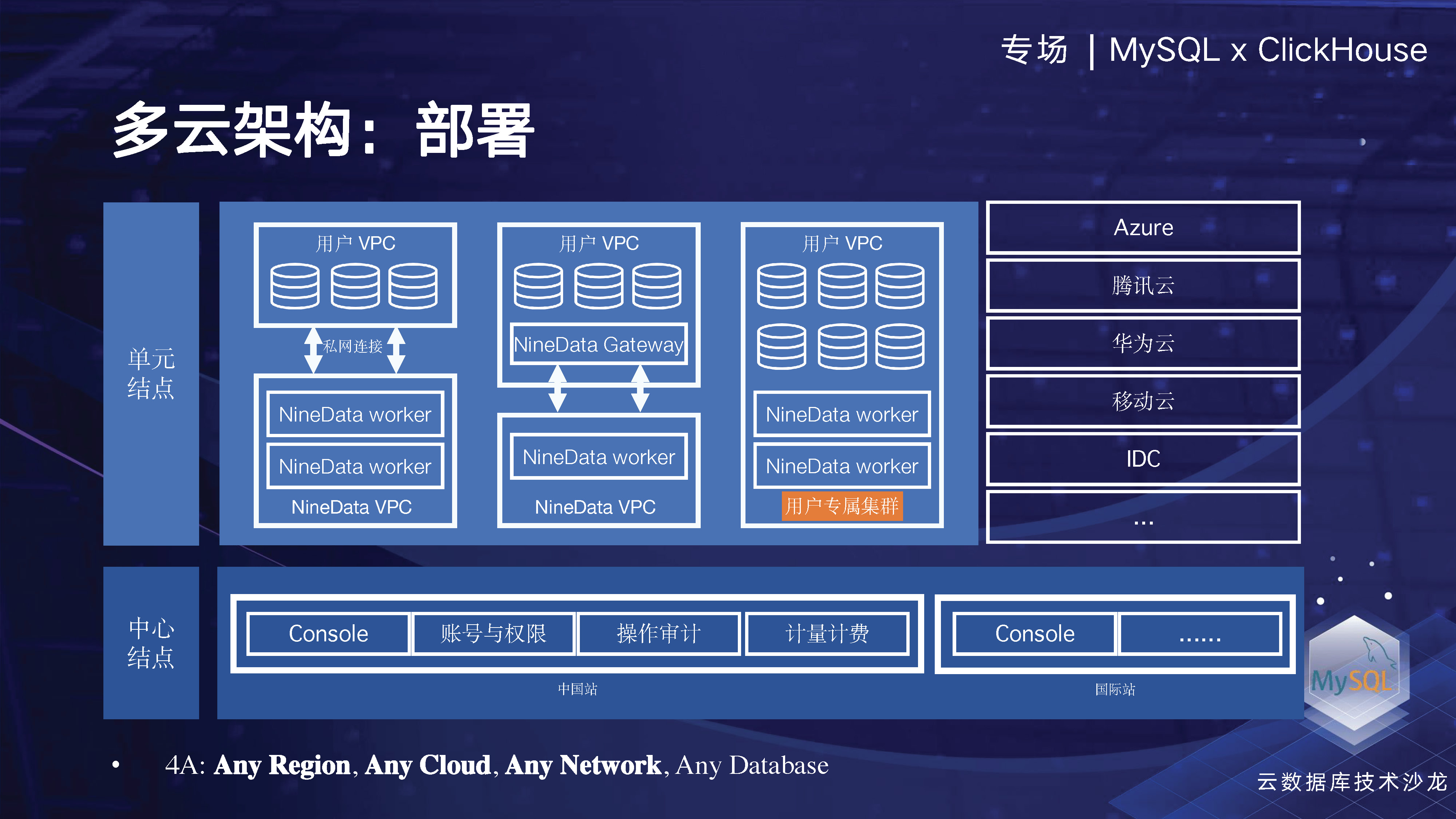
NineData は、クラウドネイティブの SAAS 製品として、オンデマンド展開と柔軟なスケーリングの最も基本的な機能を備えていることがわかります。

エンタープライズ ネットワークの場合、多くの顧客がデータベースのパブリック ネットワーク ポート、特に重要なデータを公開することを望まない、または公開したくないためです。そこで、データベースゲートウェイを設計し、ユーザーはデータベースゲートウェイをインストールするだけで中央管理ノードに接続でき、社内一元管理を含むさまざまな場所に散在するデータを統合できるリバースアクセスチャネルを確立できます。データソースの数。さらに、NineData ワーカーをユーザーのローカル エリアに配置してデータ リンクの内部閉ループを実現することもできます。また、管理リンクは中央コンソールを通じてインスタンス レベルのタスクを管理でき、データ チャネル全体がユーザーのローカル エリア内にあります。地域一元管理を実現します。
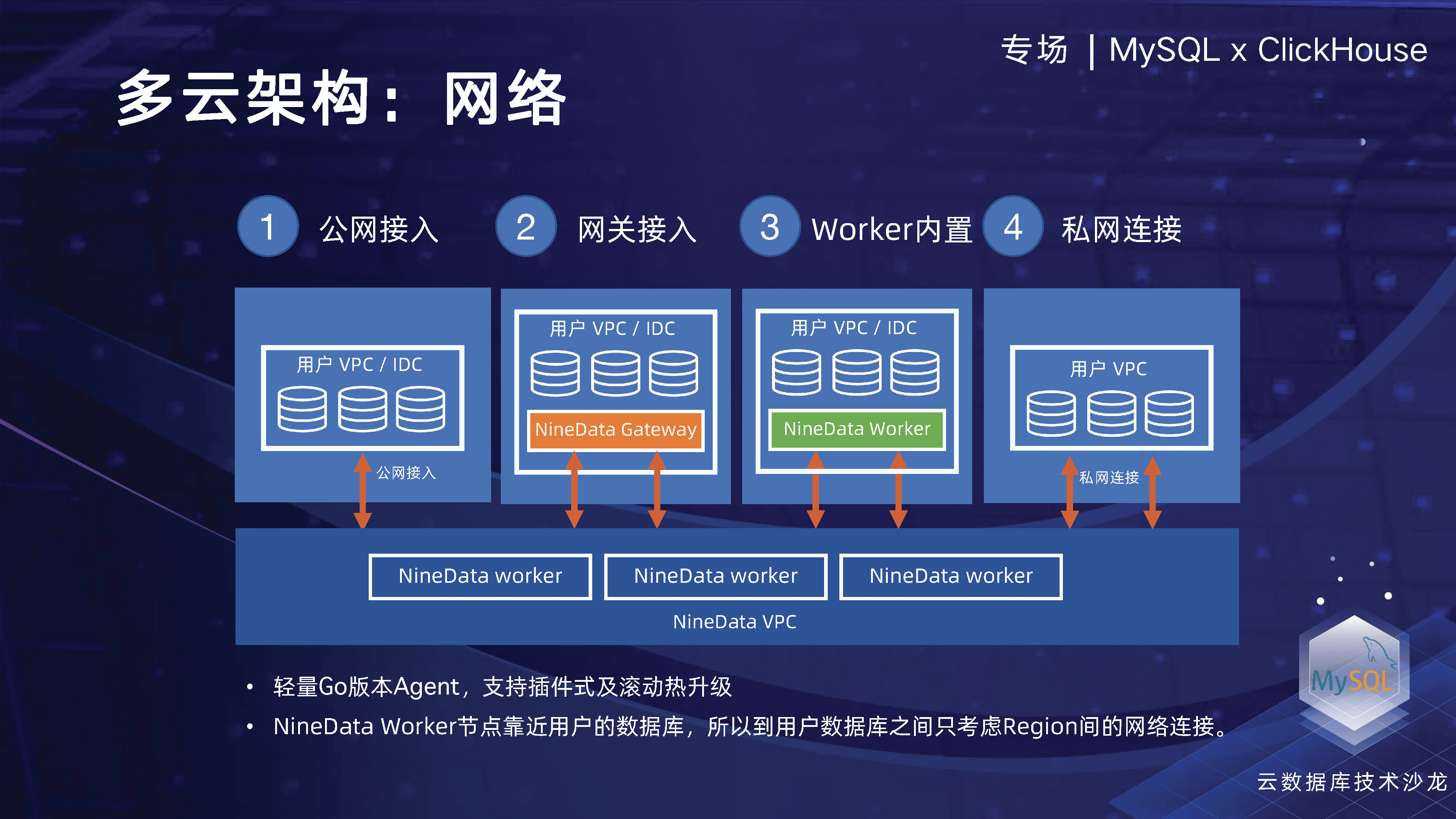
複数のソースに関して、私たちは主にデータ用の統合アクセス層を設計しました。多くのデータソースにアクセスするために、データソース全体を抽象化し、その属性構成の接続管理、接続チェック、セキュリティ認証も含めて統一的に抽象化しました。このように、すべてのデータ ソースを均一に接続でき、上記 4 つの主要な機能モジュールに基づいて、同じデータ ソースを使用してアクセスするため、1 回のアクセスですべての機能を使用できます。ユーザーにとって、すべてのデータソースを登録した後、一元管理できることが最も重要です。
そこで、次にSQL開発に関連する内容を紹介していきます。NineDataは、当社の製品を使用して企業オンライン データの管理とクエリを実行し、データ開発から変更リリースまでのライフ サイクル全体の統合管理を実行できるようにしたいと考えています。したがって、NineData Personal Edition は MySQL Workbench や Navicat などのクライアント ツールに似ていますが、私たちの機能は SAAS バージョンです。将来的にはクライアント版もリリースする予定です。エンタープライズ バージョンでは、実稼働プロセス全体を通じてセキュリティと権限機能を構築しながら、データベースの設計、開発、変更リリースのためのビジュアル インターフェイスを通じて企業の効率を向上させたいと考えています。

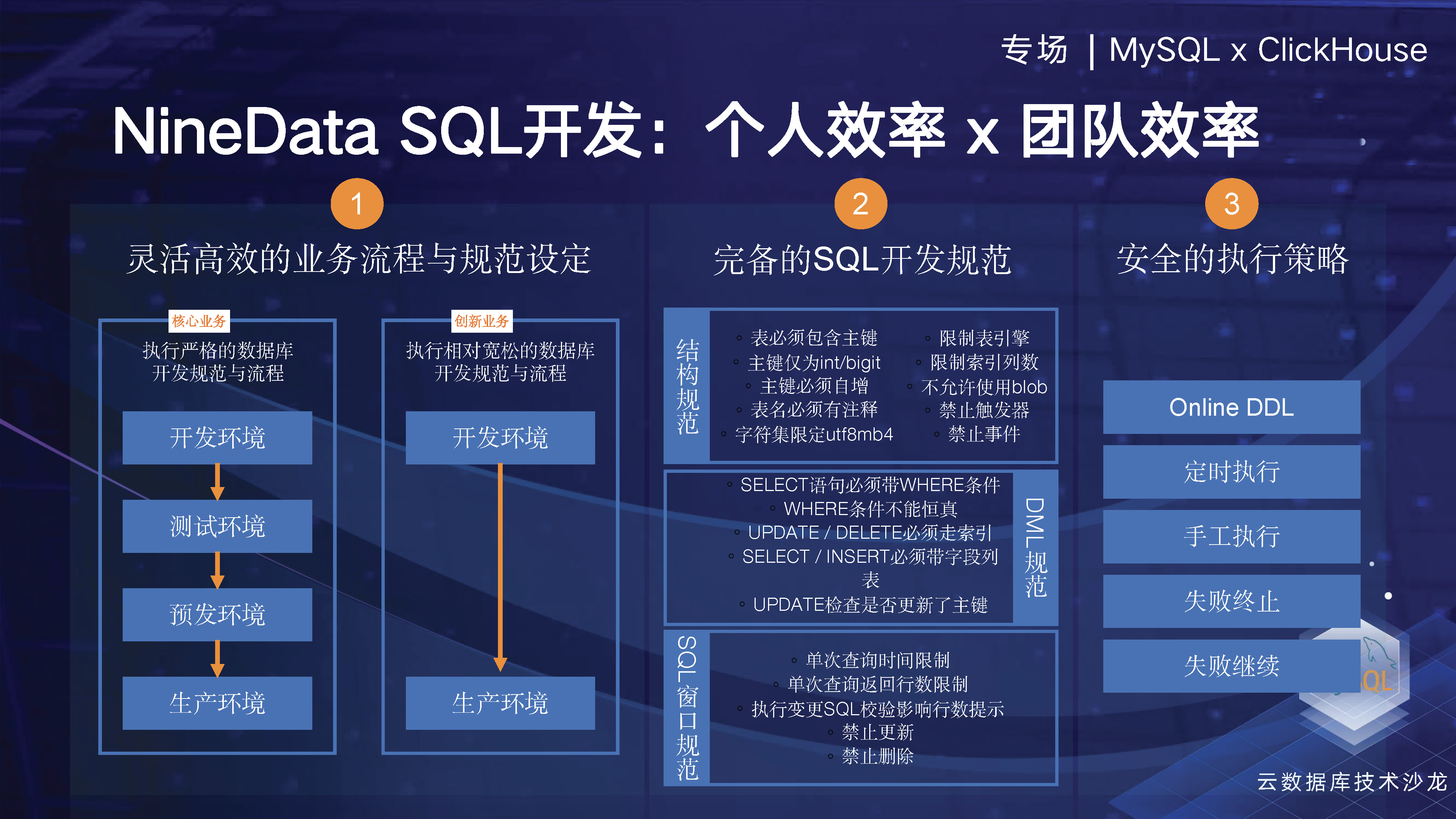
個人やチームの効率を向上させるにはどうすればよいでしょうか? 実際、企業内には構造の同期などを実行できるようにしたい環境が複数あります。異なる環境間では、異なるレベルの要件が存在する可能性があります。たとえば、機敏なビジネスでは、管理を削減して、より迅速にイノベーションを実現できるようにする必要があるかもしれません。一部の中核ビジネスでは、安定性と権限管理にさらに注意を払うことになります。
この点、NineDataでは、大規模なデータ変更が本番データベースの安定性に影響を与えるかどうかの判断や隔離・ブロック、テーブル構造の変更についてはどのように判断するかなど、さまざまな状況をカバーするSQL開発仕様を多数策定しています。オンラインDDLの有無 大きな負荷などが追加されます。さらに、ユーザーによるセキュリティ実行ポリシーの定義をサポートし、ユーザーまたはカスタム メソッドによるテンプレートの使用をサポートする 90 を超える開発仕様テンプレートを提供します。
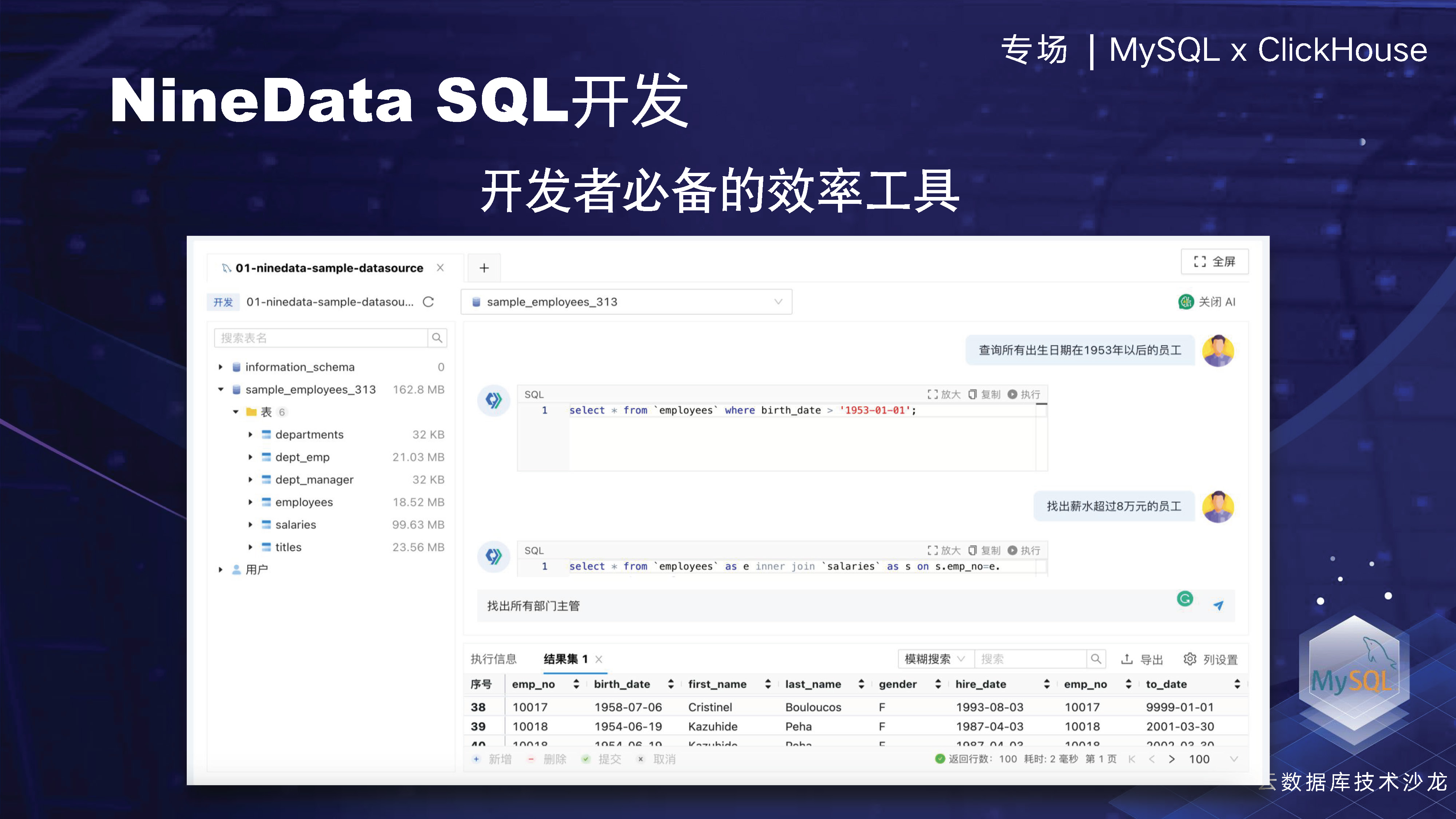
NineData SQL の開発は、ユーザーの効率性の向上に注力してきました。現在、業界で非常に普及しているChatGPTなどのインテリジェンスですが、この大規模モデル技術をベースにして、NineDataの製品全体の機能を強化し、ユーザー指向の効率を向上させています。これは主に、ユーザーが 1 つのデータ ソースに基づいたリアルタイムの対話を通じて、必要なデータを迅速にクエリするだけで済むという事実に反映されています。たとえば、給与が一定額を超える従業員を簡単に見つけることができます。同時に、データベースの学生向けに、NineData は SQL ステートメントとテーブル構造の最適化もサポートしています。誰もがそれを体験することを歓迎しますが、それでも非常に嬉しい驚きを感じるでしょう。
次に、データ レプリケーションにおける NineData のいくつかのテクノロジーに焦点を当てます。マルチソース マルチクラウド データ レプリケーションの主な課題は、データベースの種類が多く、各データベースの背後にあるデータ型とデータ構造も独立して設計されていることです。したがって、データ間の連携をどのように実現し、自由に流通させるかが大きな課題となります。同時に、多くのクラウド ベンダーが豊富なデータ ソースを提供していますが、それらの間には微妙な違いや大きな違いがあります。顧客のビジネス開発の過程で、多くの企業のデータセンターや国際ビジネスには、長距離にわたるデータ トポロジが必要になる場合があります。

以下の図に示すように、これは典型的なデータ レプリケーション リンク トポロジであり、ソースとターゲットを構成した後、NineData によってリンク全体の実行が開始されます。最初に、ネットワーク接続、アカウントのパスワードなどが正しいかどうかを確認するための事前チェックが行われます。次に、移行構造が実行され、全量のデータと増分データがフェッチされて書き込まれます。当社の製品設計コンセプトは、マルチソースおよび複数のデータソースへのアクセスをサポートし、優れたスケーラビリティを備えていることを期待することです。新しいデータ ソースが追加されたときに簡単にアクセスできるようになります。ここまでさまざまなデータ ソースを取り上げてきましたが、それらの間にはいくつかの小さな違いがあります。したがって、同期リンク全体の長期安定した動作を保証するために、その可観測性と介入の構築にも重点を置いています。
伝送カーネル モジュール全体において、最も基本的な機能は一貫性を確保することであり、これが私たちの最終目標でもあります。さらに、高スループットと低遅延の機能も必要です。次に、これらの点を中心に以下の共有も行っていきます。

NineData のモジュール全体のアーキテクチャについては、簡単に説明しました。業界の他の製品と比較して、当社はパフォーマンスの収集、例外処理、データの一貫性に多額の投資を行っていきます。

まず、スループット能力を見てみましょう。完全なパフォーマンスを例として、ソースで処理するデータがあり、それらの間には多数のテーブルがあり、それらのデータ量が異なるとします。処理のために 3 つの同時スレッドを同時に開始した場合、少量のデータを含む一部のテーブルは処理された可能性がありますが、大量のデータを含む一部のテーブルはまだ 1 つのスレッドの処理を待機しています。テーブル レベルが同時実行の場合も、同様の問題が発生します。したがって、全体の効率を向上させるには、テーブルの同時実行機能を強化する必要があります。具体的には、テーブルが均等にスライスされているかどうかを考慮する必要があります。このため、デフォルトのコンポーネントはワンキー分割をサポートし、主キー、NULL 以外の一意キー、NULL 許容一意キー、共通キーなどの順序で分割をサポートするという戦略を策定しました。可能な限り最もバランスの取れた方法で同時処理を実現します。
次に、ソースのクローリング パフォーマンスが良好で、線形に拡張できる場合、スループットのボトルネックはチャネルではなく、ターゲット ライブラリの書き込みにある可能性があります。したがって、ターゲットライブラリでの執筆姿勢は非常に重要です。すべての SQL をターゲット側で解析する必要がある場合、パフォーマンスは確実に低下します。したがって、何らかの方法で一括送信する必要があります。同時に、圧縮スイッチを扱う場合は、CPU の数に注意する必要があります。CPU 数が少ない場合、圧縮を有効にするとパフォーマンスに大きな影響を与える可能性があります。私たちのテストでは、CPU の数が 4 コアを超える可能性がある場合、圧縮を有効にしないことによる影響は比較的小さくなります。
使用中に、いくつかの問題が発生する可能性があります。たとえば、通常の同時書き込みでは、ソース側で 100G のデータを書き込むと、ターゲット側では 150G になる可能性があります。これは、単一のテーブルが順不同で送信されると、データ ホールが発生する可能性があるためです。この目的を達成するために、NineData はスライス サイズと同時順序に関していくつかの最適化を行いました。
フル コピー全体がシングルエンドであり、ターゲットに迅速に流れるため、このデータは削除されます。したがって、JVM 全体のパラメータに対してターゲットを絞った最適化を行うことは、完全なデータ レプリケーション モデル自体がこの機能を備えているという事実にも基づいています。

2 番目の部分は低遅延です。では、低遅延を構築するにはどうすればよいでしょうか? 私たちはこれを 2 つの観点から検討します。1つは、バッチ データ マージやホット データ マージなどを含むチャネル全体のパフォーマンスの観点です。ホットスポット データのマージでは、レコードが A1 から A2 に変更され、次に A3 に変更される場合、一般的な同期モデルはフルトラック変更ですが、ホットスポット機能が有効になった後は、A3 に直接マップされ、A1 が挿入されない場合があります。または A2 を更新します。この機能により、データが最終状態に直接書き込まれ、キューがメモリに直接マージされます。パフォーマンス レベルでは、技術的な応用もいくつかあります。たとえば、 redis のレプリケーション リンク内のキューのシリアル化コストを削減できるため、キュー全体の消費を最小限に抑えることができます。
管理レベル全体において、低遅延システム全体にとっても非常に重要であり、これは私たちの長年の実践から得られた経験です。例を 2 つ挙げると、1 つはデータベースが遅延しているが、データ サーバー上のログはクリアされているということですが、クラウドネイティブ製品としてはどうすればよいでしょうか? ユーザー インターフェイスをプルして、OSS または他のオブジェクト ストレージにアップロードされたログがあるかどうかを確認します。存在する場合は、全額の再取得を回避し、遅延を減らすために、前のレコードを自動的に取得して継続します。
さらに、セキュリティポジションも文書化します。ターゲット ライブラリに対して 16 の同時書き込みがあり、それぞれが異なるライブラリ テーブルとレコードを同時に送信すると仮定します。ポイントを記録するときは、データの損失を避けるために、これら 16 個のポイントのうち最も遅いものを記録する必要があります。つまり、他の 15 個は同時により高速に実行されます。異常なダウンタイムが発生して再起動すると、高速に実行されている複数のスレッドが実行したデータを再生するという問題が発生します。これにより、ユーザーはこれがデータのロールバックであると感じます。
これで 2 つの最適化が完了しました。1 つ目はテーブル レベルのサイトで、各テーブルには独自の最新サイトがあります。このテーブルの位置が再生中に使用されている場合は、位置のロールバックを避けるためにそれを破棄します。2 番目の最適化は、通常の操作およびメンテナンス操作用であり、16 個のスレッドが一貫した位置に到達するように、キュー内のすべてのデータを送信して完了し、プロセスを閉じます。この機能により、クリーンなクリーンダウンが達成され、ユーザーは再起動後にデータを再生する必要がなくなります。これは最もエレガントな方法の 1 つです。

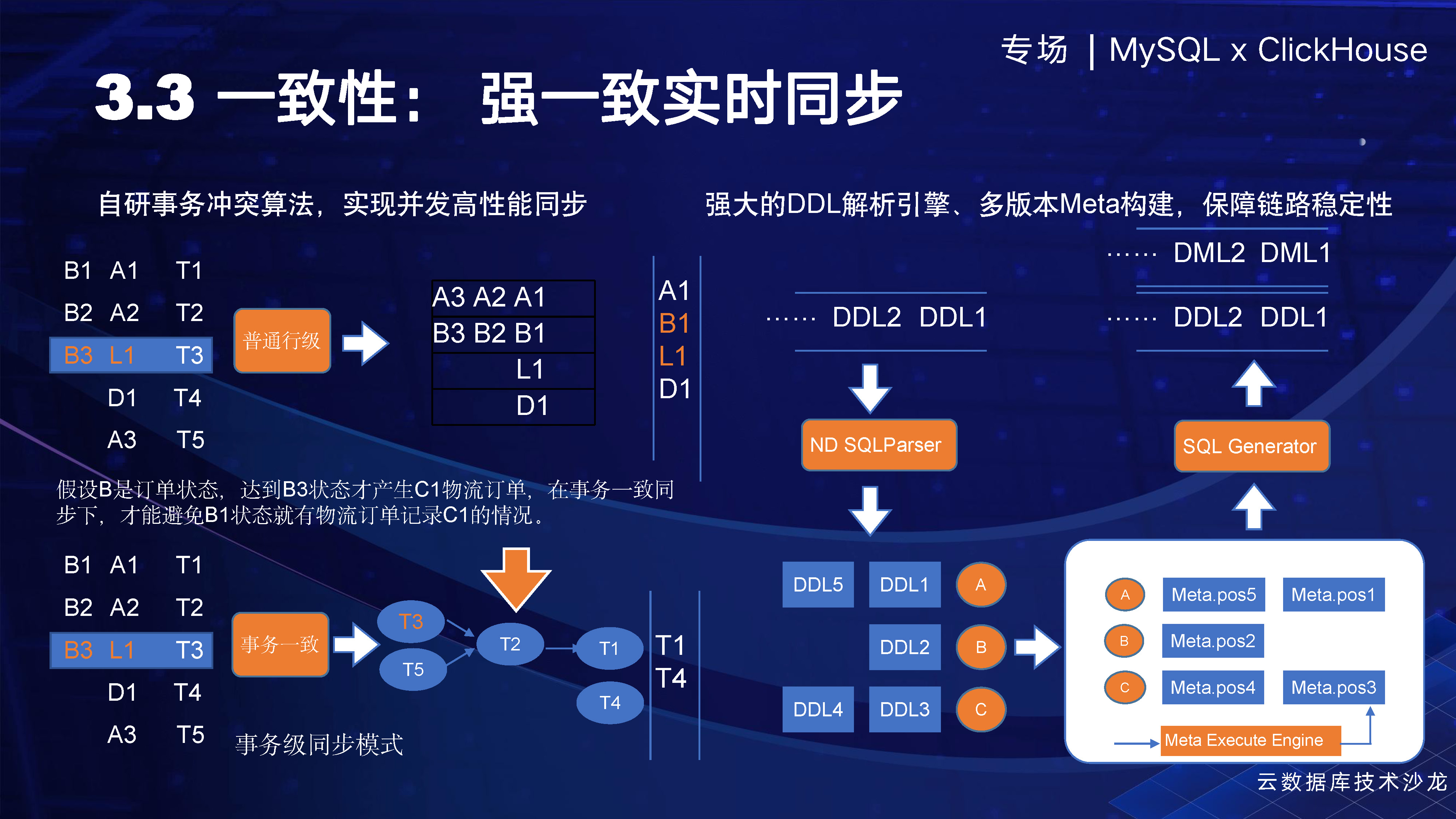
一貫性を確保することがより重要であり、考慮すべき重要な点が 2 つあります。1 つ目は、データ自体の一貫性です。たとえば、T1 から T5 までの 5 つのトランザクションがあるとします。B1 が注文ステータスで、注文は B1 から作成され、ユーザーの支払いは B3 に行われる可能性があり、この時点で物流注文 L が生成されます。通常の行レベルの同期方法を使用する場合、注文と物流注文は別のテーブル、つまり別のキューに保存されます。ただし、行レベルの同時実行性のため、その順序は保証できません。したがって、B1 と L はターゲット ライブラリに同時に表示される可能性があります。つまり、注文が作成されると、物流注文も作成されます。オンライン ビジネスにとって、これは明らかにビジネス ロジックに反しており、オンライン ビジネスの通常の運営をサポートできません。
したがって、トランザクション整合性機能を構築し、ユーザーはトランザクション機能を有効にすることができます。ユーザーがトランザクション機能を有効にすると、T3 トランザクションの各レコードが以前のすべてのトランザクションと依存関係があるかどうかがチェックされます。存在する場合、T3 はデータの整合性を確保するために、他のトランザクションが送信されるのを待ってから送信します。したがって、最初の送信は T1 から T4 のみを送信し、T3 は T2 が送信されるのを待ってから送信します。これは、データの一貫性を保証する同期メカニズムです。
2 番目の問題は、リーダーの解析エンドの一貫性に関するものです。具体的には、テーブル構造を例に挙げると、テーブル構造に変更があった場合、一般的な解決策はソースでテーブル構造を確認することです。ただし、ほとんどのデータ ログにはデータとテーブル名のみが含まれており、構造や型などの情報が欠如しているため、データ ソースをチェックして構造情報を取得し、最終結果をつなぎ合わせる必要があります。ただし、レビュー中にソースで 2 番目の DDL がすでに発生している可能性が非常に高く、取得されるのは再度変更された DDL であり、その結果、結合されたデータに不整合やエラーが発生します。
したがって、DDL 解析機能を開発しました。つまり、DDL 解析が完了した後、同期スレッド解析スレッドで再生が直接実行されます。同時に、各変更のバージョンを記録し、再生中に新しいバージョンを生成します。古いバージョンは削除されません。この方法では、他の業界の慣例のように最初からメタ構造を再生する必要がなく、いつでもどのテーブルでもメタ構造を確認できますが、この方法は問題の診断が非常に難しく、最新または最新のメタを取得することはできません。 . ステータス。
データ比較に関して、 NineData はデータ比較が全体的なデータ品質に与える影響が非常に重要であると考えているため、これを重要な製品機能として示しています。したがって、構造比較、データ比較、修正された SQL 生成の点で非常に包括的な機能を実行しました。次に、ユーザーのソース データベースとターゲット データベース間のデータ比較によってもたらされる負荷を考慮します。これらの負荷は、多くの生産担当者にとって非常に重要です。そのため、矛盾したデータのみを再チェックする、同時実行性と電流制限を制御する、サンプリング比と条件フィルタリングを設定する、特定の範囲内のデータのみを比較するなど、多くの戦略を策定しました。同時に、パフォーマンスの面でもいくつかの作業を行いました。ソースとターゲットからすべてのデータを引き出すと大量のコンピューティング リソースと帯域幅が消費されるため、よりエレガントに計算されたプッシュダウンを実行する必要があるからです。

スケーラビリティの観点から、 NineData で高速な新しいデータ ソースをサポートするにはどうすればよいでしょうか? つまり、構造とデータ型の変換を迅速にサポートし、チャネルを迅速に製品化する必要があり、これらが現在の重要な考慮事項です。私たちの全体的な設計思想は、さまざまな元のソースからターゲットまでの N 倍 M のトポロジー手法が、N に M を追加することで実現できるということです。
最初にデータ型について話しましょう。データ型は最終的な一貫性をより重視する可能性があり、業界では多くの中間型が定義されているためです。現在、NineData ではいくつかの中間型も定義しています。これは、中間型の抽象化が優れているほど、中間型の型が少なくなり、新しいデータ ソース用の変換を開発する作業が少なくて済むためです。したがって、より少ないサンプル セットに適切に抽象化する方法は、全体的により適切な抽象化方法です。
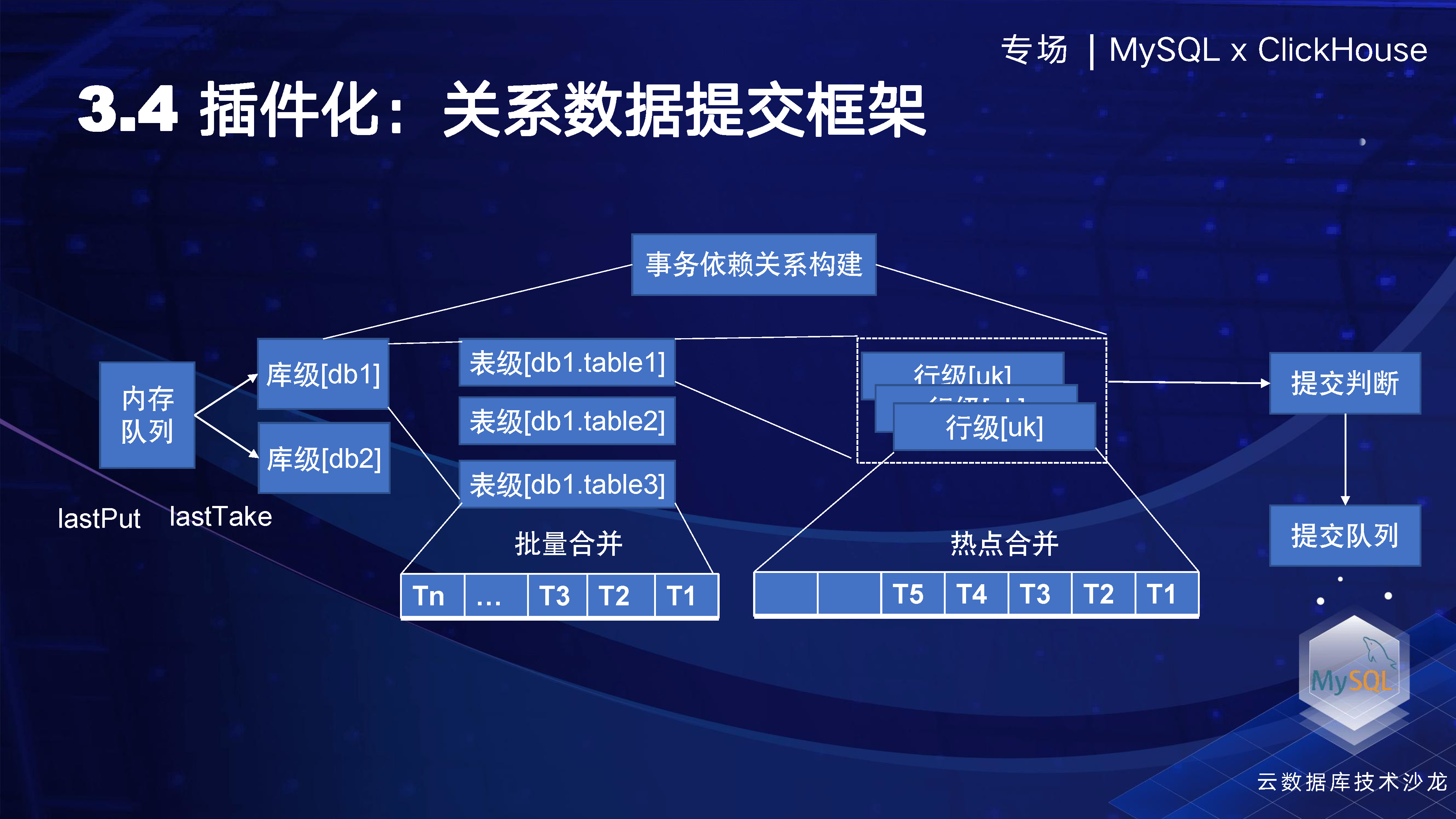
2 番目のプラグインは、リレーショナル データ送信と呼ばれるフレームワークを提供することです。十分なプラグインを実現するには、全体的な再利用性を向上させるために、最下層のさまざまな場所にいくつかのフレームワークを提供する必要があることを意味します。たとえば、すべてのデータがライターに入力されると、送信時に DDL と DML の両方が待機する必要があります。テーブル構造が変更され、サポートされていることを確認してから、後続の DML を配置します。さらに、ロックの競合をソートするために、ライブラリ レベルとテーブル レベルでいくつかの DDL メモリ構造が存在します。実際、テーブル レベルは同じテーブルに配置される DML です。つまり、バッチを保存して SQL を最適化し、書き込みを減らすことができます。行レベルの操作では、同じ UK であれば、前述したようにホットスポット マージを実行できます。このようなフレームワーク抽象化機能により、後でアクセスするデータ ソースがこれらの機能を自然に保持できるようになります。同時に、データ フローのプロセスで、トランザクションに依存するトポロジ関係を構築して、データを送信できるかどうか、および以前のデータが完了したかどうかを判断することもできます。
今日は MySQL と ClickHouse テクノロジーのセッションで、これら 2 つの分野についても多くの練習を行いました。MySQL と ClickHouse はデータ型の点で大きく異なるため、ClickHouse は多くのエンジン タイプもサポートしています。まずエンジンの選択について見てみましょう。また、MaterializeMySQL や Airbyte などの業界の実装も調査しました。ReplacingMergeTree は実装可能ですが、これは MaterializeMySQL によって内部的に使用されるエンジンでもあると考えています。MaterializeMySQL はクエリに関してある程度のカプセル化を行っていますが、クエリのカプセル化が十分でない場合、さまざまなベンダーの中間同期ツールにはバージョンと違いがあります。これにより、最終的にユーザーのクエリ結果が異なるものになります。
この CollapsingMergeTree の符号は、-1 または 1 です。追加、削除、変更、クエリ操作については、増分レプリケーションを自然にマップできます。そこで、この CollapsingMergeTree を初めて実装しました。これにより、データを目的のターゲットに同期できます。実際には、一部の顧客が依然として ReplacingMergeTree を使用していることが判明したため、それもサポートし、両方の方法を提供しました。
ClickHouse には比較的多くのデータ型があり、MySQL のようなクラウドネイティブ型よりも多い可能性があります。したがって、タイプマッピングに関しては多くの選択肢があり、多くのデフォルトも存在します。「NA」と指定しない場合、初期値が表示される場合があります。たとえば、「ポイント」タイプの場合は「00」になる場合があります。これらの動作により、ユーザーがソース データとターゲット データを比較するときにデータの不一致を見つける可能性があります。
送信プロセスでは、チャネルのパフォーマンスの観点から、Airbyte のアプローチと同様に、すべての増分データが 1 つのファイルに結合されます。これは、ClickHouse エンジンでの多くの追加、削除、変更が直接追加されるため、この方法は比較的単純です。しかし、この方法では大幅な遅れが生じます。そのため、実装プロセスではSQLを使用して送信することを検討しており、アイテムが何件来たかをすぐにバッチ送信に転送し、1000秒以上または0.5秒など動的に制御でき、数百ミリ秒で送信できます。また、ClickHouse の Jdbc は各ステートメントを解析する際のパフォーマンスが低いため、いくつかの最適化を行い、バッチ送信を採用してパフォーマンスを向上させました。

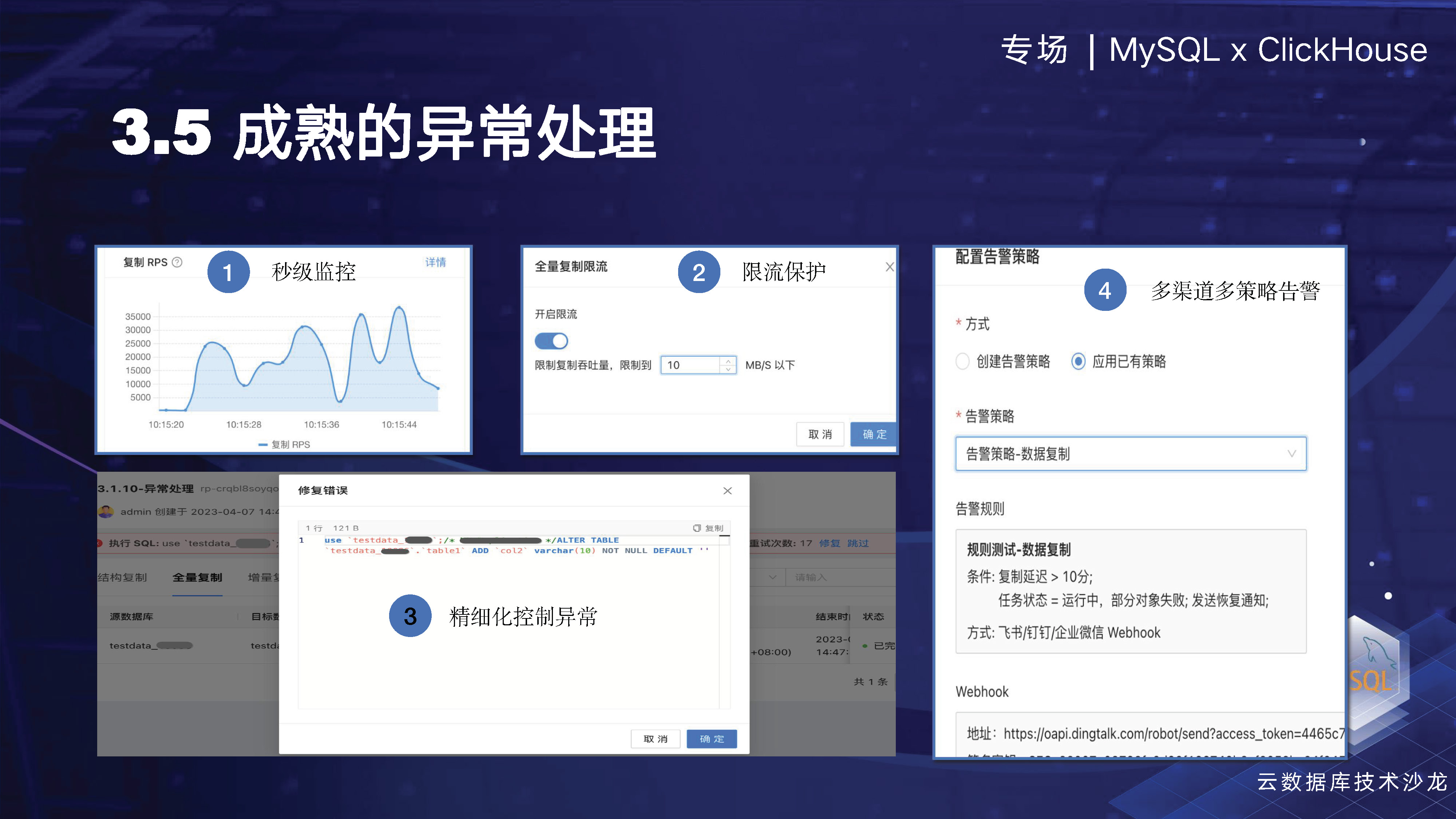
次に「観察力」と「介入力」の2つの側面について紹介します。タイプの数が多いため、たとえば同期プロセス中に、ターゲット側や新規書き込みで何らかの問題が発生し、双方の間でデータの競合が発生する可能性があります。したがって、可観測性の観点から、基本的な状態をユーザーに完全に開示するだけでなく、各スレッドによって送信されたステートメントも提供します。たとえば、16 個のスレッドが実行されている場合、これらの 16 個のスレッドがどの SQL を実行しているか、タスクが DDL によってスタックしているかどうかなどが表示されます。MySQL Processlist と同様の方法で、各スレッドが実行している操作、実行時間、その他の情報を表示できます。
「介入能力」の点では、同期プロセス中にユーザーが同期リンクに新しいオブジェクトを追加したり、異常な状況に遭遇して介入が必要になったりする可能性があるため、構築にも重点を置いています。または、操作を書き直してサブミットする必要があるなど、この種の問題はよく発生します。

たとえば、下の図では、きめの細かい制御の例外が例として示されています。ターゲットに言及するステートメントがあり、実行中に構造上の競合が発生した場合、システムはステートメントをポップアップ表示し、ユーザーはダイアログ ボックスで SQL ステートメントを直接変更して実行できるため、新しい SQL を作成できます。実行されました。テーブル構造を変更するプロセスでは、この種の問題が頻繁に発生しますが、ユーザーはこれらの問題をスキップまたは無視して次の操作を続行することを選択することもできます。
マルチクラウドおよびマルチソースのNineDataデータレプリケーション機能に関しては、市場競争における高い競争力を確保するために、製品の機能の完全性、構造、事前検査、およびパフォーマンスについて多くの作業を行ってきました。現時点では製品が完成しており、クラウド上でご利用・体験していただけます。

以下に 2 つの簡単なケースを示します。一つ目は大手不動産会社の事例です。この企業には大規模なデータベースがありますが、その開発プロセスには ISV やサードパーティ ソフトウェア開発プロバイダーなどの多くのパートナーが関与しています。したがって、データ ソースのアクセス制御をこれらのパートナーに委任する必要があります。従来の手作業による管理プロセスでは、権限管理が非常に複雑で煩雑であり、統一的に管理することが困難でした。この目的を達成するために、NineData はデータ ソースを統合管理するためのソリューションを提供します。このソリューションにより、企業内のすべてのデータソースが統合管理され、開発者のアカウント初期化、権限の申請、データ開発プロセスの可視化がすべて最適化され、開発効率とコラボレーション効率が大幅に向上します。

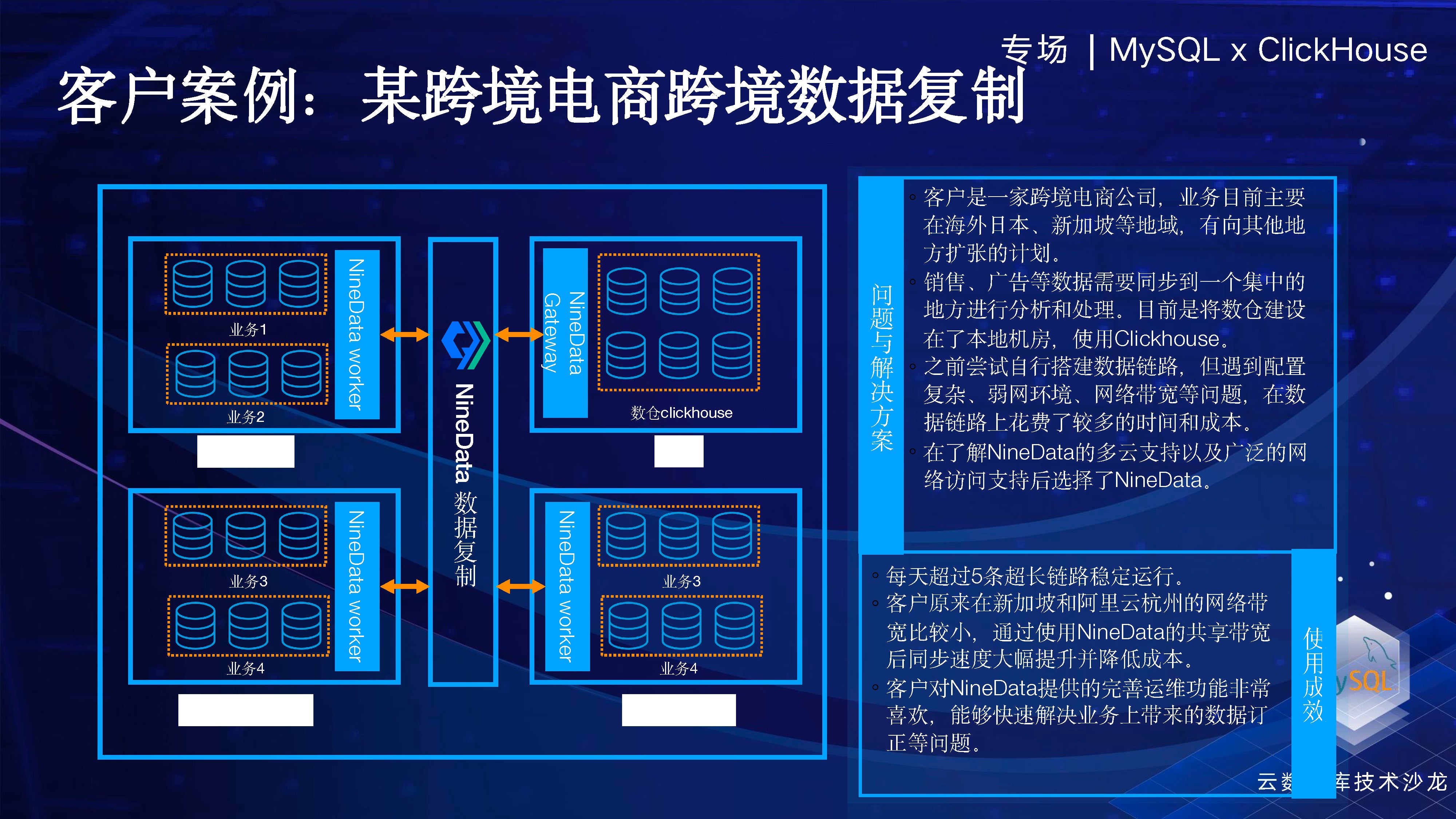
2 番目のケースは、分析と運用アクティビティが ClickHouse に基づいている、越境電子商取引シナリオです。彼の MySQL プロダクションは日本、韓国など世界中に点在しており、各地のオンライン データを国内の ClickHouse に集約して一元的な分析と運用上の意思決定を行っています。このプロセスでは、NineData レプリケーション製品を使用しました。NineData には、リージョン間のレプリケーションにおいていくつかの利点があります。解析モジュール、読み取りモジュール、書き込みモジュールはさまざまな場所に展開でき、解析モジュールはユーザーのソース側に近く、書き込み側はユーザーの宛先側に近いことができるため、より最適化された全体的なパフォーマンスを実現できます。
OK、私からの共有はこれですべてです。はい、皆さんありがとうございました。
「テクノロジーの進化、データをよりスマートにする」をテーマとしたこのカンファレンスには、ByteDance、Alibaba Cloud、Jiuzhang Math、Huawei Cloud、Tencent Cloud、Baidu からデータベース分野の専門家 6 名が集まり、テクノロジーのトレンドとエンタープライズレベルの現実を組み合わせました。現場のランディングケース、大多数のテクノロジー愛好家とのコミュニケーションと共有