ネットワーク全体のロジックとして、コントロール プレーンは、ルーターが送信元ホストから宛先ホストへのエンドツーエンド パスに沿ってデータグラムを転送する方法を制御するだけでなく、ネットワーク層のコンポーネントとサービスがどのように構成および管理されるかも制御します。
5.1 概要
転送テーブル(宛先ベースの転送の場合) とフロー テーブル(ユニバーサル転送の場合) は、ネットワーク層のデータ プレーンとコントロール プレーンをリンクする主要な要素です。
転送テーブルとフロー テーブルはどのように計算、維持、インストールされますか?
- ルーターごとの制御: 各ルーターには、他のルーターのルーティング コンポーネントと通信して転送テーブルの値を計算するルーティング コンポーネントがあります。
- 論理集中制御: 論理集中コントローラが各ルータで使用するフォワーディング テーブルを計算して配布します。
コントローラーは、明確に定義されたプロトコルを介して各ルーターのコントロール エージェント(CA) と対話し、ルーターの転送テーブルを構成および管理します。
5.2ルーティングアルゴリズム
目的:ルーター ネットワークを介して送信者から受信者までの適切なパスを決定すること(ルーティングに相当)。
- より良いパス:インデックスが小さいパス
- 指標: ステーション数、遅延、コスト、キューの長さなど、またはいくつかの単純な指標の加重平均
ルーティング アルゴリズム: ルーティング機能を完成させるネットワーク層ソフトウェアの一部
ネットワークのグラフ抽象化
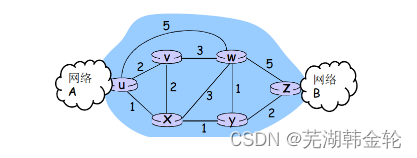
図: G = (N,E)
-
N = ルーターのセット = { u, v, w, x, y, z }
-
E = 链路集合 ={ (u,v), (u,x), (v,x), (v,w), (x,w), (x,y), (w,y), (w,z), (y,z) }
-
側面には価格があります
-
c(x,x') = リンクコスト(x,x')
-
(x, y) が E に属する場合、ノード y はノードxの隣接ノードとも呼ばれます
ルーティングの入力: トポロジー、エッジのコスト、ソースノード
ルートの出力: ソースノードのコレクションツリー
グラフ G = (N, E) のパス (パス) はノード (x 1 , x 2 , ... , x p )のシーケンスであり、コストはパスに沿ったすべてのエッジのコストの合計です。つまり、c(x 1 , x 2 )+c(x 2 , x 3 )+…+c(x p-1 , x p )、最小コストのパスは最短パスでもあり、つまり最小コストのパスです。送信元と宛先の間のリンクの数。
ルーティングアルゴリズムの原理
- 正しさ: アルゴリズムは正確かつ完全でなければなりません
- シンプルさ: アルゴリズムはコンピュータ上でシンプルであるべきです
- 堅牢性: アルゴリズムはトラフィックとネットワーク トポロジの変化に適応できる必要があります。
- 安定性: 生成されたルートがぐらつかないようにする必要があります。
- 公平性: どのサイトに対しても公平
- 最適性: 特定の指標の最適性
ルーティングアルゴリズムの分類
- 集中ルーティング アルゴリズム: 完全なグローバル ネットワーク知識を使用して、送信元から宛先までの最低コストのパスを計算します。このアルゴリズムは、すべてのノード間の接続性とすべてのリンクのコストを入力として受け取ります。グローバルな状態情報を持つアルゴリズムは、ネットワーク内の各リンクのコストを知っている必要があるため、リンク ステート(リンク ステート、LS ) アルゴリズムと呼ばれることがよくあります。
- 分散型ルーティング アルゴリズム: ルーターは、反復的かつ分散的な方法で最小コストのパスを計算します。各ノードは、直接接続されているリンクのコストのみを知って動作を開始します。Distance -Vector ( DV ) アルゴリズムは、各ノードがネットワーク内の他のすべてのノードまでのコスト (距離) 推定値のベクトルを維持する分散型ルーティング アルゴリズムです。
- 静的ルーティング アルゴリズム: ルーティングは時間の経過とともに非常にゆっくりと変化し、通常は手動で調整されます (リンク コストの手動編集など)。
- 動的ルーティング アルゴリズム: ネットワーク トラフィックの負荷やトポロジの変化に応じてルーティング パスを変更します。
- 負荷に敏感なアルゴリズム: リンクのオーバーヘッドは、基礎となるリンクの現在の輻輳レベルを反映して動的に変化します。
- 負荷が遅いアルゴリズム: リンクのコストが現在 (または最近) の輻輳レベルを明示的に反映していないため
5.2.1 リンクステートルーティングアルゴリズム
リンクステート アルゴリズムでは、ネットワーク トポロジとすべてのリンク コストが既知です。実際には、これは、各ノードがリンク状態パケットをネットワーク内の他のすべてのノードにブロードキャストすることによって行われます。各リンク状態パケットには、接続されているリンクの ID とコストが含まれており、多くの場合、これはリンク状態ブロードキャスト アルゴリズムによって完了されます。その結果、すべてのノードがネットワークの統合された完全なビューを得ることができます。
のリンクステート ルーティング アルゴリズムは、ダイクストラのアルゴリズムと呼ばれ、ノード (送信元ノード、u と呼びます) からネットワーク内の他のすべてのノードまでの最低コストのパスを計算します。k回の反復を通じて、k 個の宛先ノードへの最低コストのパスを知ることができます。次のトークンを定義します
- D(v): ソース ノードから宛先ノードまでのアルゴリズムのこの繰り返し。最小コストのパスのコスト
- p(v) ソースから v までの現在の最低コスト パスに沿った前のノード
- N': ノードのサブセット (ソースからの場合)。の最小コスト パスがわかっています (N の n)
LS アルゴリズムが終了すると、ノードごとに、ソース ノードから最低コストのパスに沿って前のノードが取得されます。前のノードごとに、その前のノードがあり、このようにして、ソース ノードからすべての宛先ノードまでの完全なパスを構築できます。
このアルゴリズムの計算の複雑さはどれくらいですか?
最初の反復ではすべての n 個のノードを検索する必要があり、2 回目の反復では n-1 個のノードをチェックする必要があり、3 回目の反復では n-2 個のノードをチェックする必要があります。これは、すべての反復で検索する必要があるノードです。合計 n(n+1)/2、リンクステート アルゴリズムの最悪の場合の複雑さは O(n 2 )
5.2.2 距離ベクトルルーティングアルゴリズム
距離ベクトル アルゴリズムは反復的で非同期の分散アルゴリズムであるのに対し、LS アルゴリズムはグローバル情報を使用するアルゴリズムです。
- 分散: 各ノードは、直接接続された 1 つ以上の隣接ノードから情報を受け取り、計算を実行し、その計算結果を隣接ノードに配布します。
- 反復: このプロセスは、近隣間で交換する情報がなくなるまで継続します。
- 非同期: すべてのノードが相互に同期して動作する必要はありません。
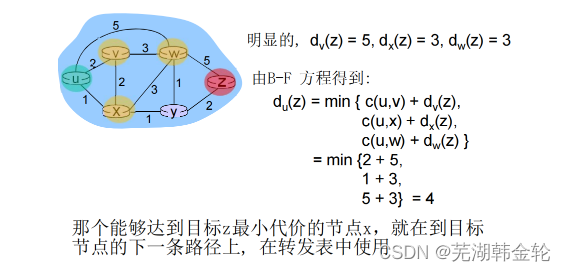
d x (y) をノード x からノード y までの最低コストのパスのコストとする。この場合、最小オーバーヘッドはよく知られている Bellman-Ford 方程式、つまり
dx ( y ) = minv { c ( x , y ) + dv ( y ) } d_x(y)= min_v\lbrace c(x,y) に関連します。 +d_v( y)\r中括弧d×( y )=分_v{
c ( x ,y )+dv( y )}

例:
核となるアイデア:
- 各ノードは自身の距離ベクトル推定値を近隣ノードに送信し、タイミングや DV が変化した場合に相手側に計算させます。
- x が近隣から DV を受信すると、独自の計算を実行し、独自の距離ベクトルを更新します。
- D x (y) の推定値は、最終的に実際の最小コスト値 d x (y)に収束します。
各ノードが行うこと:
DVの特徴
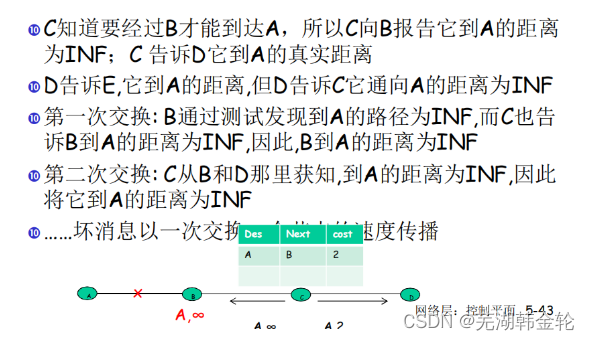
良いニュースは早く伝わり、悪いニュースはゆっくりと伝わります
良いニュース: 良いニュースは、交換サイクルごとに 1 つのルーターが進む速度で広まります (ルーターがアクセスしている、またはより短いパスを持っているなど)。
悪いニュースは非常にゆっくりと伝わります
例えば:

悪いニュースの伝達が遅い場合の解決策:スプリットホライズン アルゴリズム
ただし、スプリット ホライズンアルゴリズムは、いくつかのトポロジー形式では失敗します (ループがあります)。
LS アルゴリズムと DV アルゴリズムの比較
- メッセージの複雑さ(DV が有利)
- LS: n 個のノード、E 個のリンク、O(nE) 個のメッセージの送信、グローバルな伝播が存在します。
- DV:ご近所さんとの情報交換のみ、地域発信
- 収束時間(LS の勝利)
- LS: O(n 2 ) アルゴリズム、発振する可能性があります
- DV: コンバージェンスが遅い、ルーティング ループが発生する可能性があります
- 堅牢性: ルーターに障害が発生した場合に何が起こるか (LS が勝った場合)
- LS: ノードが誤ったリンク コストをアドバタイズします。各ノードは独自のルーティング テーブルのみを計算します。エラー メッセージの影響は少なく、局所的であり、ルーティングはより堅牢です。
- DV: DV ノードは、ネットワーク全体のすべてのノードに誤ったパス コストをアドバタイズする可能性があります。各ノードのルーティング テーブルは他のノードによって使用される可能性があります
5.3インターネットの自律システム内のルーティング: OSPF
自律システム(AS)
オープン最短パスファースト(OSPF):
- LSアルゴリズムを使用する
- LS パケットはネットワーク全体 (AS 内) に分散されます。
- グローバル ネットワーク トポロジとコストは各ノードで維持されます
- ダイクストラアルゴリズムを使用した配線計算
- OSPF アドバタイズメント情報は、各隣接ルータに 1 つのエントリを保持します。
- 通知情報は AS 全体に拡散します (フラッディングによって)。
特性:
- セキュリティ: すべての OSPF パケットは認証されます
- 同じコストの複数のパスが許可されます
- 各リンクには、異なる TOS に対応する複数のコスト マトリックスがあります。
- ユニキャストとマルチキャストの統合サポート
- 大規模ネットワークでの階層型OSPFサポート
5.4 ISP間のルーティング: BGP
階層型ルーティング: インターネットを AS (ルーター領域) に分割します。
ルーティングは次のようになります: 2 レベルのルーティング
- **AS 内部ルーティング: **同じ AS 内のルーターは同じルーティング プロトコルを実行します。
- AS間で AS 間ルーティング プロトコルを実行する
階層型ルーティングの利点
- スケールの問題を解決しました
- 経営上の問題は解決した
インターネットでは、すべての AS がボーダー ゲートウェイ プロトコル (Broder Gateway Protocol、BGP ) と呼ばれる同じ AS 間ルーティング プロトコルを実行し、インターネット内の何千もの ISP を結び付けます。BGP は分散型の非同期プロトコルです
5.4.1 BGP の役割
同じ AS 内にある宛先の場合、ルーターの転送テーブルのエントリはAS内部ルーティング プロトコルによって決定されます。AS の外側にある宛先はどうなるでしょうか? ここで BGP が登場します。
ルーターの転送テーブルには、(x,I) の形式のエントリが含まれます。ここで、x はプレフィックス(例: 138.16.68/22)、I はルーターのインターフェイスの 1 つのインターフェイス番号です。
-
隣接 AS からプレフィックスの到達可能性情報を取得します。BGP により、各サブネットがその存在をインターネットの他の部分にアドバタイズできるようになります。
-
そのプレフィックスへの「最適な」ルートを決定します。最適なルートを決定するために、ルーターは BGP ルート選択プロセスをローカルで実行します。
-
eBGP : 2 つの AS 間の BGP 接続にまたがる、隣接する AS からサブネット到達可能性情報を取得します。
-
iBGP : 取得したサブネット到達可能性情報を AS 内のすべてのルーター、および同じ AS 内の 2 つのルーター間の BGP セッションに分散します。
5.4.2 BGP経路情報のアドバタイズ
次のネットワークには 3 つの自律システム AS1、AS2、AS3 があります。
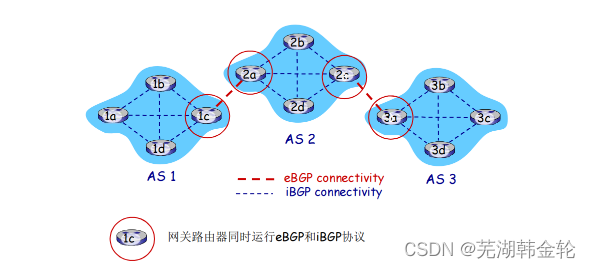
BGP セッション: BGP では、ルーターの各ペアが、ポート 179 を使用する半永続的な TCP 接続を介してルーティング情報を交換します。
iBGP および eBGP セッションを使用して到達可能性情報を伝達する
- ゲートウェイ ルータ 3a は、最初に eBGP メッセージ「AS3 x」をゲートウェイ ルータ 2c に送信します。
- 次に、ゲートウェイ ルーター 2c は、iBGP パケット「AS3 x」を AS2 内の他のすべてのルーター (ゲートウェイ ルーター 2a を含む) に送信します。
- 次に、ゲートウェイ ルータ 2a は、eBGP メッセージ「AS2 AS3 x」をゲートウェイ ルータ 1c に送信します。
- ゲートウェイ ルーター 1c は iBGP を使用して、AS1 のすべてのルーターにメッセージ「AS2 AS3 x」を送信します。
- このプロセスが完了すると、AS1 と AS2 の各ルーターは x が存在することを認識し、x への AS パスも認識します。

特定のルーターから特定の宛先までの異なるパスがいくつか存在し、それぞれが異なる AS のシーケンスを通過する場合があります。上記の場合、AS1 から x へのパスは 2 つあります: ルータ 1c を経由するパス「AS2 AS3 x」と、ルータ 1c を経由する新しいパス「AS3 x」です。
5.4.3 最適なルートの決定
ルーターが BGP 接続経由でプレフィックスをアドバタイズする場合、プレフィックスにいくつかのBGP 属性が含まれます。
プレフィックスとその属性はルートと呼ばれます。さらに 2 つの重要な属性はAS-PATHとNEXT HOP
- AS-PATH属性には、アドバタイズメントが通過した AS のリストが含まれます。BGP ルーターは、AS-PATH 属性を使用してアドバタイズメント ループを検出および防止します。ルーターは、ルート リストに自分の AS が含まれているのを確認すると、そのアドバタイズメントを拒否します。
- NEXT PATH属性は、AS 間ルーティング プロトコルと AS 内ルーティング プロトコル間の重要なリンクを提供します。NEXT HOP は、AS PATH が開始されるルーター インターフェイスの IP アドレスです。
1. ホットポテトルーティング
Hot Potato ルーティングに AS 発信プレフィックスを追加する手順。
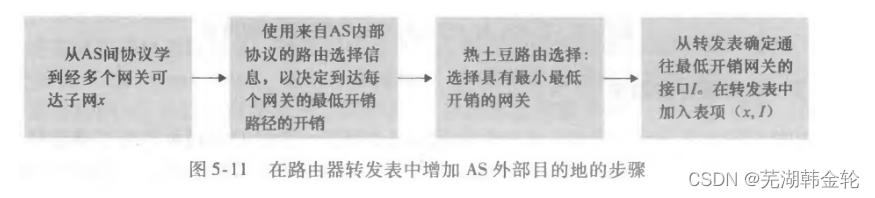
ホット ポテト ルーティングは、ルータ 1b が、ルータ 1b への残りの AS のコストを気にせずに、できるだけ早く (より具体的には、可能な限り低いコストで) AS からパケットを取得するという考えに基づいています。行き先。
2. ルーター選択アルゴリズム
同じプレフィックスへのルートが 2 つ以上ある場合、ルートが 1 つ残るまで、次の除外ルールが順番に呼び出されます。
- ルートには、その属性の 1 つとしてローカル プリファレンス値が割り当てられます ( AS PATH と NEXT-HOP を除く)。
- 残りのルート (すべて同じ最高のローカル優先値を持つルート) から、最短の AS PATH を持つルートが選択されます。
- 残りのルート (すべて同じ最高のローカル優先値と同じ AS-PATH 長を持つ) から、ホット ポテト ルーティングを使用します。つまり、最も近い NEXT-HOP ルーターを持つルートを選択します。
- まだ複数のルートが残っている場合、ルーターは BGP 識別子を使用してルートを選択します
5.4.4 IP エニーキャスト
BGP は、通常 DNS で使用されるIP エニーキャスト(エニーキャスト) サービスの実装にもよく使用されます。
-
CDN 会社は、複数のサーバーに同じ IP アドレスを割り当て、標準の BGP を使用してそれらの各サーバーからその IP アドレスをアドバタイズします。BGP ルーターは、その IP アドレスに対する複数のルート アドバタイズメントを受信すると、これらのアドバタイズメントを同じ物理的な場所への異なるパスを提供するものとして扱います。
-
ルーティング テーブルを設定するとき、各ルータはローカルで BGP ルーティング アルゴリズムを使用して、その IP アドレスへの「最適な」(たとえば、AS ホップ カウントによって決定される最も近い)ルートを選択します。
-
この最初の BGP アドレス アドバタイズメント フェーズの後、CDN はコンテンツを配布するという主なタスクを続行できます。
-
クライアントがその IP アドレスにリクエストを送信したい場合、インターネット ルーターは、BGP ルーティング アルゴリズムで定義されているように、リクエスト パケットを「最も近い」サーバーに転送します。
実際には、CDN は通常、IP エニーキャストを使用しないことを選択します。IP エニーキャストは、DNS リクエストを最も近いルート DNS サーバーに送信するために DNS システムで広く使用されています。
5.4.5 ルーティングポリシー
実際、ルート選択アルゴリズムでは、最初にローカル プリファレンス属性に従ってルートが選択され、ローカル プリファレンス値はローカル ASポリシーによって決定されます。
例:
![[外部リンク画像の転送に失敗しました。ソース サイトにはリーチ防止メカニズムがある可能性があります。画像を保存して直接アップロードすることをお勧めします (img-cw3TldXO-1679193844693) (C:\Users\86159\AppData\Roaming\Typora\) typora-user-images\ 1676111345769.png)]](https://img-blog.csdnimg.cn/026eb38e19d54a24b220833a0b812ee4.png)
W、X、および Y はアクセス ISP であり、A、B、および C はバックボーン プロバイダー ネットワークです。
ISP が顧客ネットワークとの間でトラフィックをルーティングすることだけを望んでいると仮定します(他の ISP 間でトラフィックを伝送したくない、つまり、顧客へも顧客からも広告を出さない)
-
A はパス Aw を B と C にアドバタイズします
-
B は、BAw を C にアナウンスしないことを選択します。
- C、A、w は B の顧客ではないため、B は CBAw のルートから収入を得ることができません。
- したがって、C は CBAw パスの存在を知ることができません。各 ISP によって認識されるネットワークは実際のネットワークと一致しません。
-
C は最終的に (B を使用する代わりに) CAw 経由で w にルーティングする可能性があります。
-
X は、2 つのネットワークに接続されたデュアル アクセス、マルチホーム スタブ ネットワークです。
-
ポリシーは X を強制します。X はパケットを B から X を経由して C にルーティングしたくないため、X は実際に C にルーティングできることを B にアドバタイズしません。
5.5 SDNコントロール プレーン
従来の方法: ルーターごと (ルーターごと) のコントロール プレーン
各ルーターの個別のルーター アルゴリズム要素、コントロール プレーンで相互作用
SDN アプローチ: 論理的に集中化されたコントロール プレーン
別の (通常はリモート) コントローラーがローカルのコントロール エージェント (CA) と対話します。
SDN アーキテクチャには 4 つの重要な特徴があります
- フローベースの転送。SDN によって制御されるスイッチのパケット転送作業は、トランスポート層、ネットワーク層、またはリンク層ヘッダーの任意の数のヘッダー フィールド値に基づいて実行できます。
- データ プレーンはコントロール プレーンから分離されています。データ プレーンはネットワーク スイッチで構成されます。ネットワーク スイッチは、フロー テーブルで「一致プラスアクション」ルールを強制する比較的単純な (しかし高速な) デバイスです。コントロール プレーンは、サーバーと、スイッチのフロー テーブルを決定および管理するソフトウェアで構成されます。
- ネットワーク制御機能: データ プレーン スイッチの外部にあります。
- プログラム可能なネットワーク。ネットワークは、コントロール プレーンで実行されるネットワーク制御アプリケーションを通じてプログラム可能です。
5.5.1 SDN コントロール プレーン: SDN コントローラーおよび SDN ネットワーク コントロール アプリケーション
SDN コントロール プレーンは、SDN コントローラーとSDN ネットワーク制御アプリケーションの2 つの部分に大別されます。
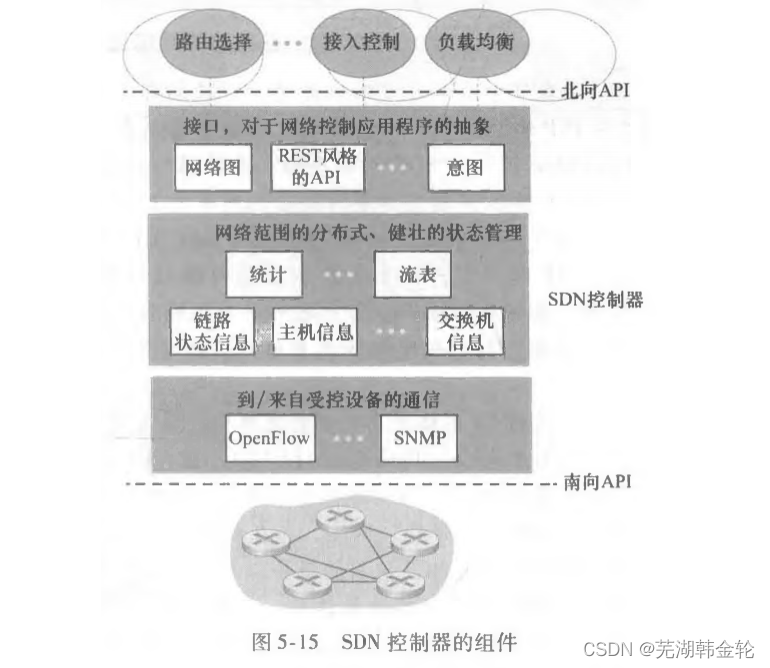
コントローラーの機能は大きく3つのレベルに分類できます
- 通信層: SDN コントローラーと制御対象のネットワーク デバイス間の通信。
- ネットワーク全体の状態管理層
- ネットワーク制御アプリケーション層へのインターフェース。コントローラーは、「ノースバウンド」インターフェイスを通じてネットワーク制御アプリケーションと対話します。
5.5.2 OpenFlowプロトコル
OpenFlow プロトコルは、SDN コントローラーと SDN 制御スイッチ、または OpenFlow API を実装する他のデバイス間で実行されます。このプロトコルは、デフォルトのポート番号6653を使用して、TCP上で実行されます。
コントローラから制御対象スイッチに流れる重要なメッセージは次のとおりです。
- 構成: このメッセージにより、コントローラーはスイッチの構成パラメーターを照会および設定できます。
- Modify state : このメッセージは、スイッチ フロー テーブルのエントリを追加/削除または変更し、スイッチ ポート特性を設定するためにコントローラによって使用されます。
- Read Status : このメッセージは、スイッチのフロー テーブルとポートから統計情報とカウンタ値を収集するためにコントローラによって使用されます。
- パケットの送信: このメッセージは、制御対象スイッチの特定のポートから特定のメッセージを送信するためにコントローラーによって使用されます。
制御対象のスイッチからコントローラに流れる重要なメッセージは次のとおりです。
- Packet In : パケット (およびその制御) をコントローラーに渡します。コントローラーからのパケットアウト メッセージを参照してください。
- フローの削除: スイッチ上のフロー エントリを削除します。
- ポートステータス: ポートの変更をコントローラに通知します。
ネットワーク管理者は、フロー テーブルを作成/送信してスイッチを直接プログラムする必要はありませんが、コントローラ上のアプリを使用して自動的に計算および設定します。
5.5.3 データプレーンとコントロールプレーンの相互作用の例
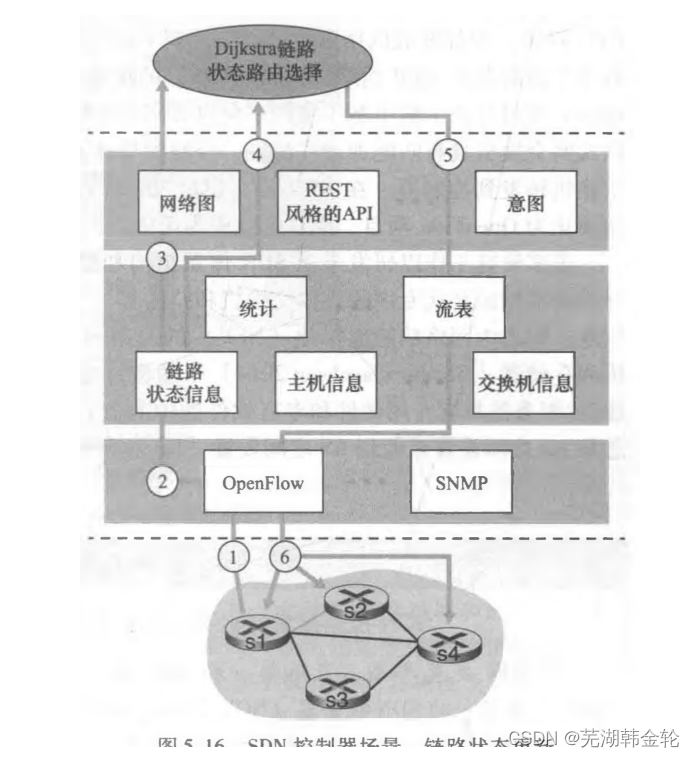
- S1、リンク障害が発生し、OpenFlow メッセージを使用してコントローラーに通知: ポート ステータス メッセージ
- SDN コントローラーは OpenFlow メッセージを受信し、リンク状態情報を更新します。
- ダイクストラ ルーティング アルゴリズム アプリケーションが呼び出されます (このステータス変更メッセージは以前に登録されています)
- ダイクストラ ルーティング アルゴリズムはコントローラ内のネットワーク トポロジ情報にアクセスし、リンク状態情報により新しいルートを計算します。
- リンク ステート ルーティング アプリは、SDN コントローラーのフロー テーブル計算要素と対話して、新しい必要なフロー テーブルを計算します。
- コントローラは OpenFlow を使用して、更新する必要がある新しいフロー テーブルをスイッチにインストールします。
5.6 ICMP: インターネット制御メッセージプロトコル
インターネット制御メッセージ プロトコル (ICMP)。ホストとルーターがネットワーク層で相互に通信するために使用されます。
ICMP は通常、 IP の一部とみなされますが、ICMP メッセージは IP パケットで伝送されるため、アーキテクチャの観点からは IP の上位にあります。
ICMP メッセージは IP ペイロードとして伝送されます
ICMP メッセージには、タイプ フィールドとエンコーディング フィールドがあり、ヘッダーと、ICMP メッセージを初めて生成する原因となった IP データグラムの最初の8 バイトが含まれます(送信者は、エラーの原因となったデータグラムを特定できます) )

トレースルートプログラム
このプログラムを使用すると、1 つのホストから世界中の任意のホストまでのルートを追跡できます。Traceroute は ICMP パケットを使用して実装されます
送信元と宛先の間のすべてのルーターの名前とアドレスを決定するために、送信元ホストの Traceroute は一連の通常の IP データグラムを宛先ホストに送信します。
これらの各データグラムには、到達不能な UDP ポート番号を持つ UDP セグメントが含まれています。
- 1 つ目: TTL=1
- 2 番目: TTL=2 など。
- ソースホストもデータグラムごとにタイマーを開始します
n 番目のデータグラムが n 番目のルーターに到着すると、n 番目のルーターはデータグラムの TTL がちょうど期限切れになったことを観察します。
- ルーターはデータグラムを破棄します
- 次に、ICMP メッセージ (タイプ 11、コード 0) を送信元に送信します。
- メッセージにはルーターの名前とIPアドレスが含まれます
ICMP メッセージが到着すると、送信元は RTT を計算します。
停止の基準:
- UDP セグメントは最終的に宛先ホストに到達します
- ターゲットが ICMP「ポート到達不能」メッセージ (タイプ 3、コード 3) をソース ホストに返します。
- 送信元ホストがこのメッセージを受信したら、停止します。
5.7ネットワーク管理とSNMP
ネットワーク管理とは何ですか?
ネットワーク管理には、ネットワークおよびネットワーク要素リソースを監視、テスト、ポーリング、構成、分析、評価、制御するためのハードウェア、ソフトウェア、人的要素のセットアップ、統合、調整が含まれ、妥当なコストでリアルタイムの運用パフォーマンスとサービス要件を満たすことができます。品質要件
5.7.1 ネットワーク管理フレームワーク
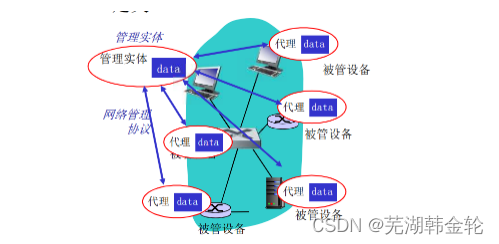
- 管理サーバーは、ネットワーク オペレーション センター (NOC) の集中ネットワーク管理ワークステーション上で実行される、通常は人間の参加によるアプリケーションです。
- 管理対象デバイスは、管理対象ネットワーク上に存在するネットワーク機器 (そのソフトウェアを含む) です。管理対象デバイスには、いわゆる管理対象オブジェクトがいくつかあります。
- 管理対象デバイス内の各管理対象オブジェクトに関連付けられた情報は **管理情報ベース (MIB)** に収集され、管理サーバーで利用できるこの情報の値がわかります。
- 各管理対象デバイスには、管理対象デバイス内で実行されるプロセスであるネットワーク管理エージェントも常駐し、管理サーバーと通信し、管理サーバーのコマンドと制御の下で管理対象デバイス内でローカル アクションを実行します。
- ネットワーク管理フレームワークの最後のコンポーネントは、ネットワーク管理プロトコルです。このプロトコルは管理サーバーと管理対象デバイスの間で実行され、管理サーバーが管理対象デバイスのステータスを照会し、エージェントを通じて間接的にこれらのデバイスに対してアクションを実行できるようにします。
5.7.2 簡易ネットワーク管理プロトコル
シンプル ネットワーク管理プロトコルは、管理サーバーと管理サーバーの代わりに実行するエージェントの間でネットワーク管理制御および情報メッセージを渡すために使用されるアプリケーション層プロトコルです。
SNMP の最も一般的な使用法は、SNMP 管理サーバーが SNMP エージェントに要求を送信する要求/応答モードです。要求を受信した後、エージェントはいくつかのアクションを実行し、要求に対する応答を送信します。
2 番目によく使用される SNMP は、エージェントによって管理サーバーに送信される非要求メッセージであり、トラップ メッセージ(トラップ メッセージ)と呼ばれます。
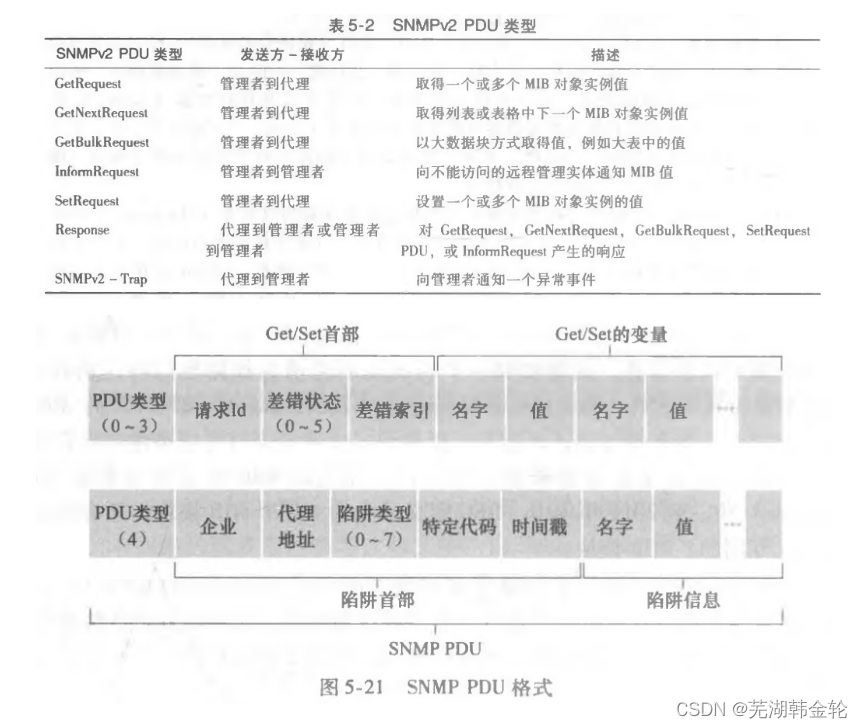
SNMPv2で定義される7種類のメッセージ
これにより、管理サーバーは管理対象デバイスのステータスを照会し、プロキシを通じて間接的にそれらのデバイスに対してアクションを実行できるようになります。