
深層学習自然言語処理の原著
者 | Carina Lau
オープンソース言語ラージ モデル (LLM) が普及するにつれ、モデルのパフォーマンスと効率は製品のコストとサービス エクスペリエンスのバランスに関係します。では、大規模な言語モデルをより効率的かつ優れたものにする方法はあるのでしょうか?
オープンソースモデルの上限をさらに高めるために、清華大学の研究チームは答えを出しました。高品質のガイド付き対話データを拡張することで、モデルのパフォーマンスと効率が大幅に向上しました。以下の図に示すように、UltraLLaMA が LLM リストのトップになりました。
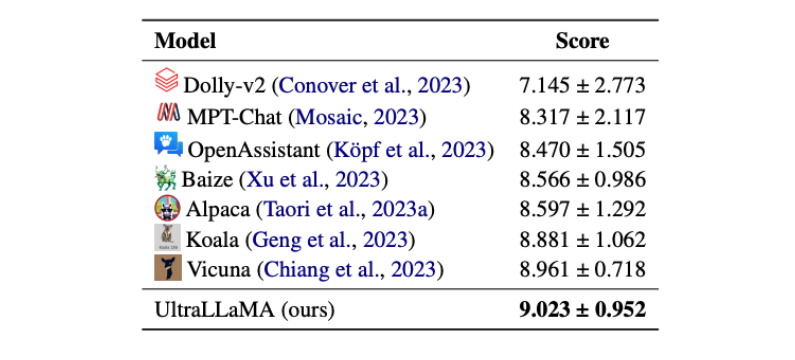
ネチズンのコメント: 150 万の高品質で多様なマルチターン会話を含む UltraChat は、SotA のオープンソース モデルである Vicuna よりも優れています。 論文を注意深く読んで、どのような啓発をもたらすことができるか見てみましょう~
論文を注意深く読んで、どのような啓発をもたらすことができるか見てみましょう~
論文: 高品質の教育的会話の拡張によるチャット言語モデルの強化
アドレス: https://arxiv.org/pdf/2305.14233.pdf
コード: https://github.com/thunlp/UltraChatNLP グループに入る —> NLP 交換グループに参加する
1 論文プロジェクトの概要
オープンソース モデルの上限をさらに高めるために、この論文では、新しいチャット言語モデル UltraLLaMA を提案します。UltraLLaMA は、UltraChat 上で LLaMA モデルを微調整することで得られ、多様で高品質なコマンド ダイアログ データ セットを提供します。し、チャット言語モデルのパフォーマンスを向上させることに成功しました。

2 UltraChat マルチモーダル データセットはどのように構築されますか?
デザインの構築: UltraChat の一般的な考え方は、別個の LLM を使用して開始行を生成し、ユーザーをシミュレートし、クエリに応答することです。UltraChat の 3 つのプラン: 世界に関する質問、執筆と作成、既存の資料への支援は、次の図に示すように、すべて特徴的なデザインになっています。
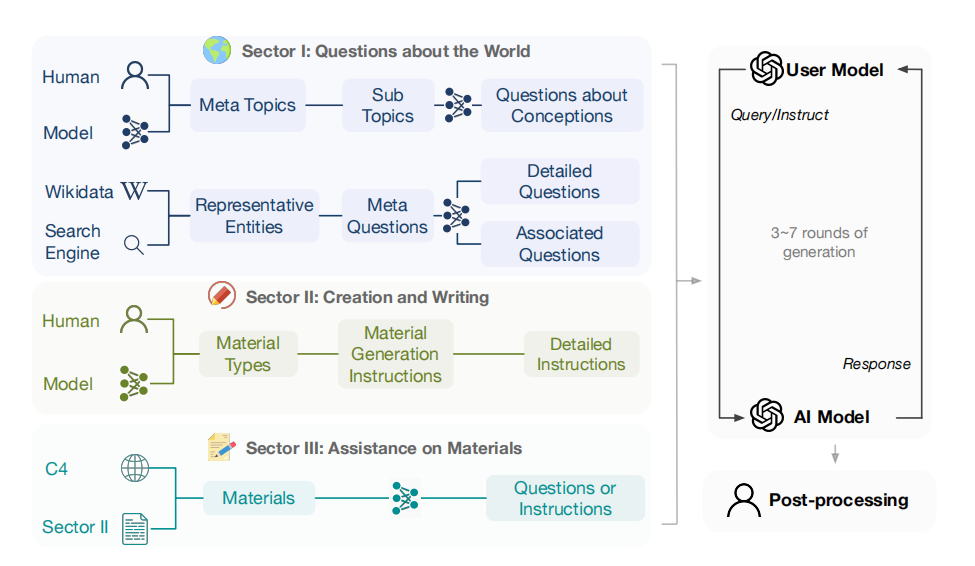
2.1 世界についての質問
データのこの部分は、現実世界に存在する概念、オブジェクト、エンティティに焦点を当てています。
データのこの部分を収集するアプローチには 2 つの角度があります。1 つはテーマとコンセプトに関するもの、もう 1 つは現実世界のエンティティに関するものです。
以下に示すように、日常生活のあらゆる側面をカバーする 30 の代表的で多様なメタテーマを生成するよう ChatGPT にリクエストします。

ビルドプロセス:
まず、これらのメタトピックに基づいて 1,100 を超えるサブトピックが生成され、同時に、人、場所、出来事など、最も一般的に使用される 10,000 の現実世界の名前付きエンティティが Wikidata から収集されます。
各サブトピックに対して最大 10 個の具体的な質問が設計され、エンティティごとに 5 つの基本的な質問、10 個の具体的な質問、および 20 個の拡張質問が設計されました。
次に、Turbo API を使用して、10 個の質問ごとに新しい関連質問を生成します。これらの質問を使って会話を生み出したいと考え、会話のきっかけとなる約 500,000 の質問の中からいくつかを選り分けてサンプリングしました。
手作りのプロンプトを使用して、さまざまな一般的な概念やオブジェクトをカバーするさまざまな質問を生成するようにモデルに指示し、会話履歴のコンテキストを考慮して、簡潔かつ有意義に答えるようモデルに求めます。
最後に、200,000 の特定の質問、250,000 の一般的な質問、および 50,000 のメタ質問がサンプリングされ、複数ラウンドの対話が繰り返し生成されます。
2.2 書き込みと作成
この部分の目的は、ユーザーの指示に従ってさまざまな種類のテキストを自動的に生成することです。
ChatGPT を使用して、ユーザーの指示に従って、物語、詩、エッセイなどの 20 種類の文章を生成します。

ビルドプロセス:
文章の種類ごとに、AI アシスタントがテキスト素材を生成できるように 200 の異なるプロンプトが生成され、指示の 80% がさらに拡張および洗練されています。
生成された指示は初期入力として使用され、それぞれ 2 ~ 4 ラウンドのダイアログが生成されます。
2.3 既存資料の支援
この部分の目的は、既存のテキスト資料に基づいて、書き直し、翻訳、要約などのさまざまな種類のタスクを生成することです。
テキストの断片とソース URL の多数のデータセットと、物語、詩、論文など 20 種類の異なる素材を含む C4 コーパスが使用されました。
ビルドプロセス:
約 10 種類の異なるマテリアルが C4 データセットから抽出されました。
種類ごとにいくつかのキーワードを考案し、テキストの断片をキーワードとURLごとに分類して資料を取得しました。
ChatGPT を使用して、マテリアルごとに最大 5 つの質問/メモを生成します。
AI アシスタントとの会話を開始するためのユーザーの最初の入力として、各質問/指示の資料を手動で設計された一連のテンプレートと組み合わせます。
500,000 のダイアログ オープニングが取得され、各ダイアログ オープニングにはテキストの断片とミッションの指示が含まれています。入力ごとに 2 ~ 4 ラウンドのダイアログが生成されます。

2.4 データセットの評価
UltraChat データセットは大規模なマルチモーダル対話データセットであり、100 万を超える対話が含まれており、各対話には平均 8 ラウンドの対話が含まれています。テキスト情報だけでなく、音声、ビデオ、画面共有データも含まれます。
UltraChat の統計分析と他のいくつかのコマンド データセットとの比較の結果を以下の表に示します。
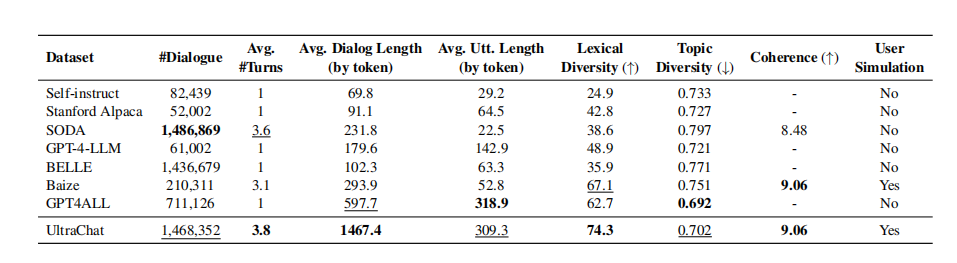
UltraChat は、規模、平均ラウンド数、インスタンスあたりの最長平均長、語彙の多様性の点で他のデータセットよりも優れており、最大規模のオープンソース データセットの 1 つです。
UltraChat のトピックの多様性は GPT4ALL よりわずかに低いですが、それでも他のデータセットよりは高いです。これは、UltraChat の各会話にはより多くのトークンが含まれているのに対し、GPT4ALL の会話は 1 つの会話につき 1 ターンしかないためである可能性があります。
データセットの一貫性を評価すると、UltraChat と Baize のデータが一貫性の点で最も高いランクにあることがわかりました。
3 UltraLLaMA 対話モデルはどのくらい強力ですか?
モデルの基本的な状況:
対話のコンテキストをよりよく理解するために LLaMA-13B モデルを改良した UltraLLaMA。
モデルが会話の初期部分の情報を活用して、より適切で一貫した応答を生成できるようにするために、研究者らは会話を最大 2048 トークンの短いシーケンスに分割し、モデルの応答に対してのみ損失関数を最適化しました。
このモデルは、クロス エントロピー損失と 128A100gpu を使用し、合計バッチ サイズ 512 を使用して微調整されています。
評価データセットを作成する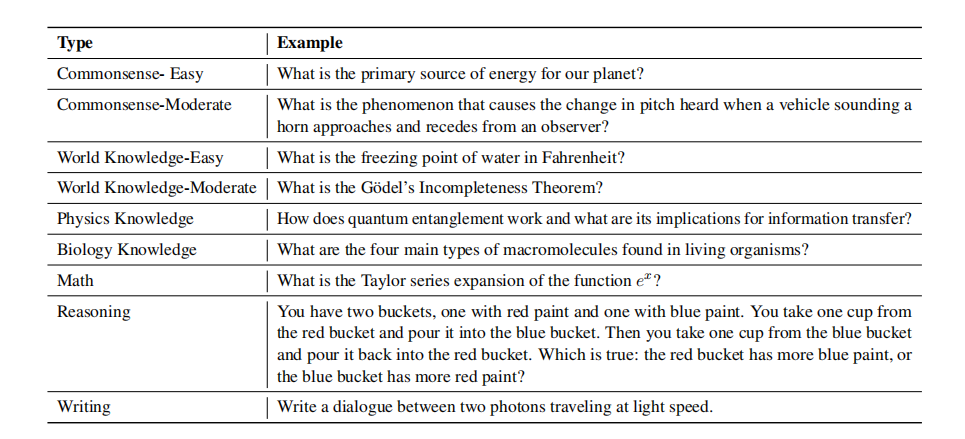
評価セットは、上の表に示すように、Vicuna ベンチマークと GPT-4 によって複数のトピックと難易度にわたって生成された 300 の質問/指示で構成されています。
TruthfulQA ベンチマークを使用して、モデルとベースラインに関する世界の知識を評価し、それらが真実のステートメントを識別できるかどうかを検出し、誤った情報の生成または伝播を回避できるかどうかを検出します。
TruthfulQA ベンチマークは、38 のカテゴリと 2 つの評価タスク (複数選択と生成) を備えた難しいテストです。
3.1 モデルの評価
ベースライン評価
ChatGPT は、各質問に対する UltraLLaMA および他のベースライン モデルの応答を評価するために使用されます。

ChatGPT に質問と 2 つのモデルの応答をフィードし、各応答を理由とともに 1 から 10 で評価します。
プロンプトは、正確さを主な基準として評価されます。
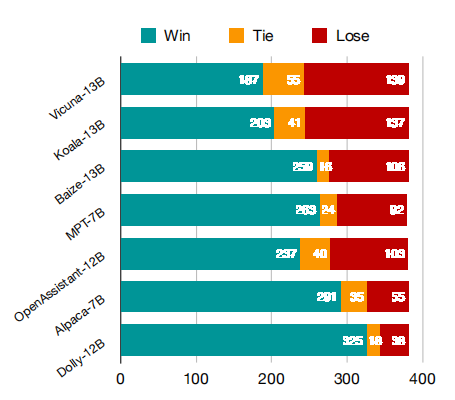
上の図に示すように、UltraLLaMA と評価セットの他のベースライン モデルの勝/同/敗時間が比較されます。
UltraLLaMA は、評価セットで他のオープンソース モデルをはるかに上回り、勝率は 85% です。
UltraLLaMA は Vicuna よりも 13% 高い勝率を持っています。
独立した評価

UltraLLaMA モデルとベースライン モデルの応答は、ChatGPT を使用して個別にスコア付けされました。1 ~ 10 の応答ベースの品質スコア。太字は最高のスコアを示し、2 番目に良いスコアには下線が付けられています。
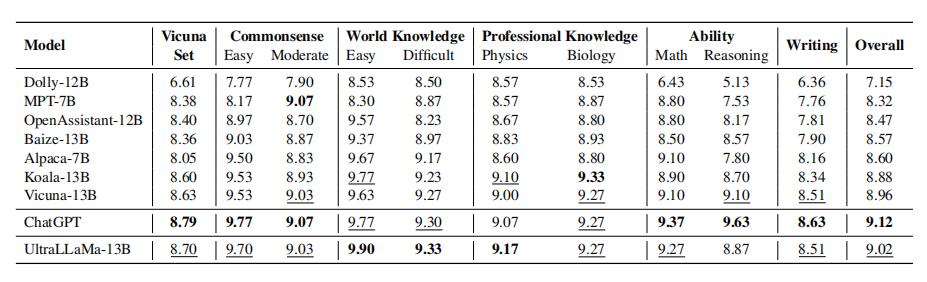
上の表は、UltraLLaMA とベースライン モデルのスコアの比較を示しています。UltraLLaMA は、合計スコアと評価セットの大部分の両方で他のオープンソース モデルよりも優れており、その強力な機能を示しています。
この内訳は、さまざまな種類の問題や指示に対する各モデルのパフォーマンスも反映しています。一般に、すべてのモデルは、単純な常識や世界の知識に関連した質問ではより良いパフォーマンスを示しましたが、推論や創造的な文章を含むより複雑なタスクではより悪いパフォーマンスを示しました。興味深いことに、LLaMA はパラメータが少ないにも関わらず、常識や世界の知識に関連した問題に関しては大規模なモデルに匹敵しますが、より要求の厳しいタスクに関しては遅れをとっています。さらに、Dolly および OpenAssistant Pythia ベースのモデルは、サイズが小さいにもかかわらず、LLaMA ベースのモデルよりもパフォーマンスが低いことにも気づきました。これは、基礎となる言語モデルの重要性を示しています。
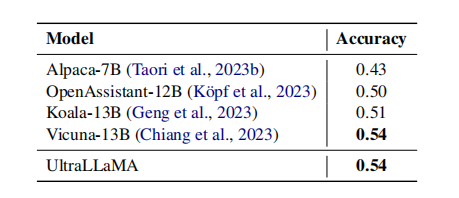
Q&Aの精度
UltraLLaMA およびその他のベースライン モデルは、実際の QA マルチエコー タスクでテストされます。モデルに各候補の回答が真か偽かを判断させます。
各機種の判定精度は下表のとおりです。真の判断を発見することは、既存のモデルにとって依然として困難な課題です。
UltraLLaMA は、このタスクにおいて Vicuna よりも優れたパフォーマンスを発揮し、他のベースラインよりも優れたパフォーマンスを発揮します。
システムプロンプトの影響
さまざまな役割や応答スタイルをガイドするために、システム プロンプトがよく使用されます。
システム ヒントは、モデルによって生成される出力の品質に影響を与えることが判明しました。モデルが「有用で詳細な」応答を提供するよう求められると、より関連性の高い有益な応答が生成されます。
このようなヒントは、必ずしも決定的な質問の精度を向上させるわけではありませんが、より多くの追加情報が含まれるため、回答の全体的な品質が向上します。
以下の表に例を示します。どちらの応答も正解でしたが、システムはプロンプトに基づいたモデルを通じてより詳細な応答を生成しました。

4 まとめ
この論文の研究結果は、チャット言語モデルの開発にとって非常に重要です。まず、UltraChat データセットの作成により、チャット言語モデルのトレーニング用の豊富なリソースが提供されます。次に、LLaMA モデルを微調整することで、研究者らは優れたパフォーマンスを備えた対話モデル UltraLLaMA を作成することに成功しました。これは、チャット言語モデルをさらに最適化するための強力な参考資料となります。
NLP グループに入る —> NLP 交換グループに参加する