目次
1. はじめに
最も古典的な「おむつとビール」の話を例に挙げると、あるスーパーで過去の顧客の買い物リストを分析したところ、おむつを買いながらビールを買う客が多かったことが分かり、そのスーパーではビールとおむつが隣接して置かれていたという話です。これは奇妙な動きで、おむつやビールの売り上げが急増した。
おむつとビールの関係を直感的に見つけることは困難ですが、このようなデータマイニングと分析の後、カオスなデータからこの関係を見つけることができます。関係を見つけるプロセスは相関分析です。
相関分析は今日の電子商取引やショートビデオプラットフォームで広く使用されており、その主な応用シナリオは次のとおりです。
(1) 商品販売顧客が同時に異なる商品を購入する可能性を分析し、目標を絞った方法で商品マーケティング戦略を設計します。
(2) 行動分析インターネット上でのユーザーの行動に基づいて、ユーザーの潜在的な行動習慣や嗜好を分析します。
(3) 障害診断: 大規模で複雑なシステムの場合、過去の履歴データを参照することで、どの障害が関連しているかを分析することができます。
2. 基本的な考え方
(1) アイテムセット
I={i1,i2,...,id} をデータ内のすべての項目のセット、T={t1,t2,...,tn} をすべてのトランザクションのセットとします。各トランザクション ti に含まれる項目セットは、I のサブセットです。
関連分析では、0 個以上の項目を含むコレクションを項目セットと呼びます。アイテムセットに k 個のアイテムが含まれる場合、それは k アイテムセットと呼ばれます。0 個の項目のみを含む項目セットは空セットと呼ばれます。
(2) 協会規約
関連付けルールはX -> Yの形式で、X と Y は互いに素な項目セットです。
この相関ルールの重要性は、過去のデータに基づいて、X が出現し、同時に Y が出現する可能性が非常に高いということです。
(3) サポート
支持度は、関連関係のすべての項目がデータセット全体に出現する頻度を反映しており、関連関係の支持度が高い場合、相関ルールは普遍的である可能性があります。
項目 X のサポートは次のように定義されます。
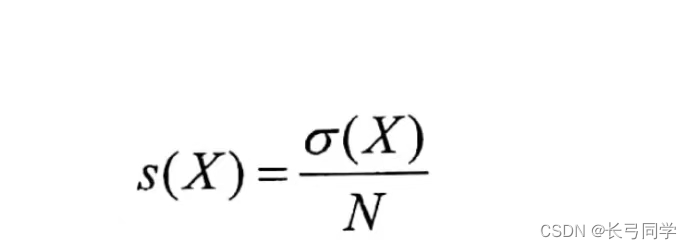
(この式では、N はトランザクション内のトランザクションの数、O(X) はトランザクション内に X が出現する回数です。)
X -> Y 形式の相関ルールの場合、そのサポートは次のように定義されます。

(この式中、O(XUY)はXとYが同時に出現する回数を意味します)
(4) 自信
信頼度の高い相関ルールX->Yは、Xが出現するときにYが出現する可能性が高く、この相関ルールの信頼性が高いことを示している。
X->Y の信頼水準は次のように定義されます。

(5) アソシエーション分析の基本手順
1. 頻繁に使用されるアイテムセットを見つける
2. 相関ルールの生成
4. アプリオリ相関分析アルゴリズム
(1) 頻繁に使用されるアイテムセットを見つける
まず事前原理を与えます。
定理 1.アイテムセットが頻繁である場合、そのサブセットも頻繁である必要があります
定理 2.アイテムセットが頻度の低いアイテムセットである場合、そのスーパーセット (親セット) も頻度の低いアイテムセットでなければなりません
Apriori 関連分析アルゴリズムは、定理 2 を使用して非頻度アイテムセットを迅速に見つけ、非頻度アイテムセットを除外し、残りが頻繁に見つかるアイテムセットになります。
(2) 関連関係の生成
頻繁に使用されるアイテムセットの相関ルールの数は依然として非常に多いため、いくつかの信頼性の特性を使用して無効な関連関係を可能な限り削除し、それによって相関ルールの生成の困難さを軽減する必要があります。
定理 3.頻度の高い k 項目セット Y について、ルール X->YX の信頼度が信頼度しきい値よりも小さい場合、ルール X'->YX' の信頼度も信頼度しきい値よりも小さくなります。つまり、c(X->Y) < c0 の場合、 c(X'->Y) < c0 になります。
定理 3 を使用すると、無効な相関ルールを迅速に除外し、信頼しきい値を満たす相関ルールのみに焦点を当てることができます。
5. FP成長アルゴリズム
FP 成長 (頻度パターン成長) アルゴリズムは、トランザクション セットを FP ツリーのデータ構造にエンコードし、FP ツリーに基づいて頻度の高い項目セットを取得します。
(1) トランザクションをFPツリーにエンコードする
次の表は、複数の一般ユーザーが懸念する大きな V カテゴリの情報を収集すると想定されています。
(項目の出現数でソートされた一連のトランザクション)
| トランザクションID | アイテム |
| 1 | ニュース、金融、スポーツ |
| 2 | ニュース、健康 |
| 3 | 金融、有名人 |
| 4 | 体育 |
| 5 | ニュース、金融、健康 |
| 6 | ニュース、金融、スター |
| 7 | ニューススター |
| 8 | ニュース、金融、スポーツ |
1. トランザクション 1 を FP ツリーにプログラムします。ノード名の横の数字は、ノードを通過するトランザクションの数を示します。
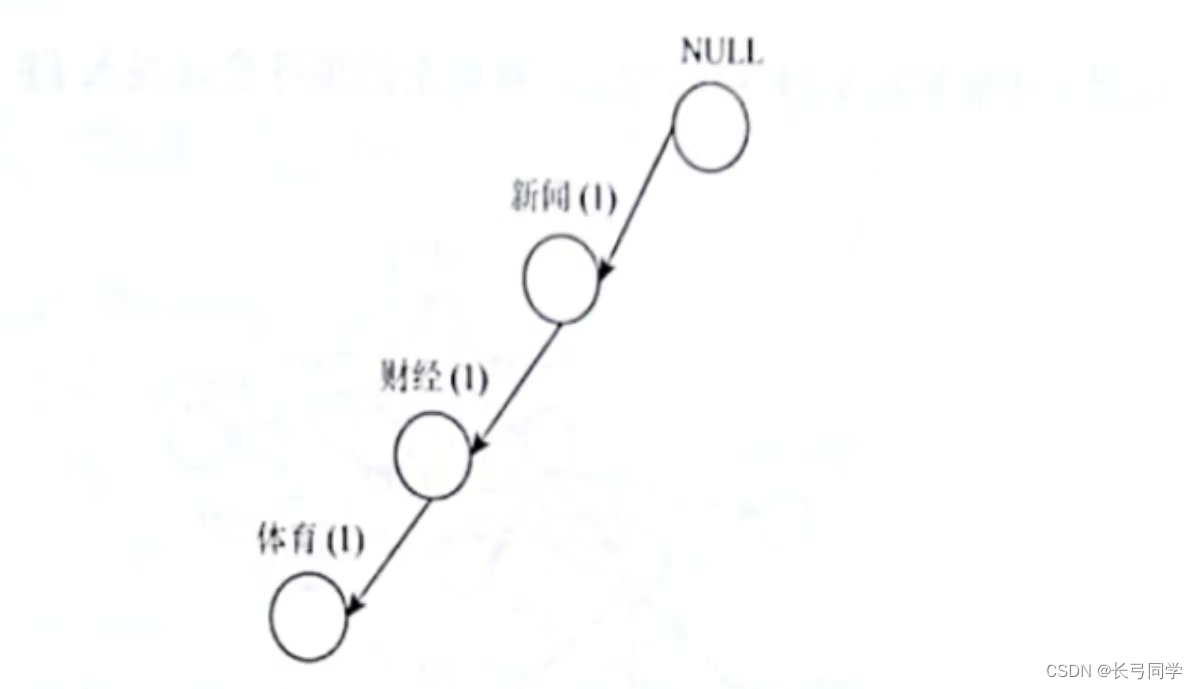
2. トランザクション 2 を FP ツリーにプログラムします。
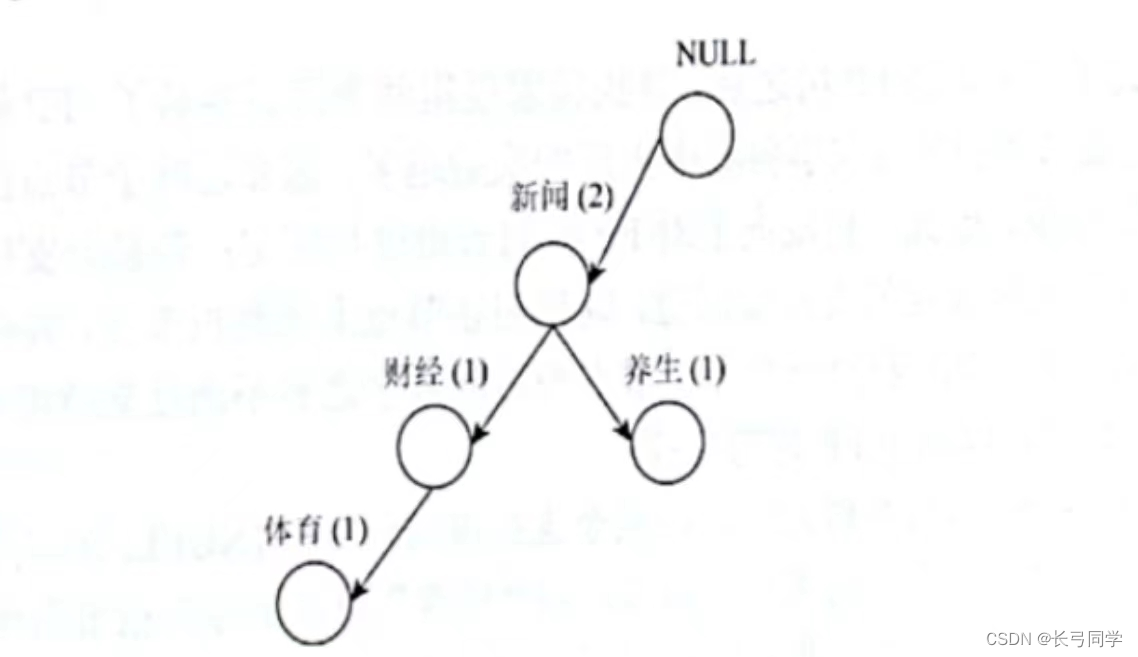
3. トランザクション 3 を FP ツリーに追加します。トランザクション 3 はトランザクション 1 と財務関係があるため、それらを点線で接続します。

4. 次の図に示すように、上記のルールに従って残りのトランザクションを FP ツリーにコンパイルします。

トランザクションセットのFPツリーがコンパイルされる
(2) 頻繁に使用されるアイテムセットを検索する
FP ツリー内のパスはいずれも、ルート ノードに近づくほどトランザクション セットに出現する回数が多くなり、リーフ ノードに近づくほどトランザクション セットに出現する回数が減ります。
したがって、FP ツリーのノードはボトムアップで判断されます。ブランチ内のノードの隣の数字が設定されたしきい値を満たす場合、それはノードがルート ノードまで遡ることを意味し、そのノードのいずれかのノードで構成されるアイテムセットは、よくあるアイテムのセットです。
上記で形成された FP ツリーでは、特定のサポートしきい値の下で、頻繁に使用されるアイテムセット: {ニュース、ファイナンス}、{スポーツ、ファイナンス}、{ニュース、スポーツ}、{ニュース、ファイナンス、スポーツ} を見つけることができます。
6. Python コードの実装
(アプリオリ関連解析コード)
from pandas as pd
from mlxtend.preprocessing import TranscactionEncoder
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
# 对数据集X进行编码,X为一个列表,表示整个事务合集:X列表中每个元素也是一个列表,表示每一个项集。
# 这里将数据集编码为二元形式
Encode_X=TranscactionEncoder.fit_transform(X)
X_df=pd.DataFrame(Encode_X)
# 对编码后的事务集X_df使用apriori算法生成频繁项集,support参数设置支持度阈值
frequent_itemsets=apriori(X_df,min_support=0.6)
# 从生成的频繁项集中寻找关联规则,min_threshold为置信度阈值
ass_rule=association_rules(frequent_itemsets,min_threshold=0.7)