1. 論文の簡単な紹介
1.筆頭著者: Hongbin Xu、Zhipeng Zhou
2.発行年: 2021年
3. 発行誌: AAAI
4. キーワード: MVS、自己監視、セグメンテーション、データ増強
5. 探索の動機:下の図 (a) からわかるように、画像再構成タスクをプロキシ タスクとして使用する自己教師あり MVS 手法はすべて、大まかな仮定、つまり、色の恒常性仮説に依存しています。複数のビュー間で一致する点は同じ色であるという前提があります。ただし、上の図 (b) からわかるように、実際のシナリオでは、多視点画像の色の値がさまざまな外的要因によって干渉される可能性があり、その結果、照明の変化、反射など、一致するポイントの色が異なります。 、ノイズ干渉など。したがって、色の一貫性の仮定に基づく自己監視信号は、これらの場合に誤った監視信号を導入する可能性が高く、代わりにモデルのパフォーマンスに干渉します。このタイプの問題を色の恒常性の曖昧さと呼びます。

6. 作業目標:自己教師あり MVS における色の一貫性のあいまいさの根本的な原因は、画像再構成のプロキシ タスクが色空間内の対応 (対応) のみを考慮することです。ただし、RGB ピクセル値の違いに基づくこのメトリックは、複数のビュー間の対応を表すのに十分な信頼性がなく、自己教師ありメソッドのパフォーマンスも制限します。次に、追加の事前知識を導入して、より堅牢なプロキシ タスクを自己教師あり信号として提供する方法を検討するのは自然なことです。これは、次の 2 点に分けられます。
- セマンティックの一貫性: 抽象的なセマンティック情報を導入して堅牢な対応を提供し、画像再構築タスクをセマンティック セグメンテーション マップ再構築タスクに置き換え、自己教師付き信号を構築します。
- データ拡張の一貫性: 自己教師ありトレーニングにデータ拡張を導入して、さまざまな色のバリエーションに対するネットワークの堅牢性を向上させます。
7. コア アイデア:ただし、自己監視型シグナルを構築する場合、無視できない問題がいくつかあります。
- セマンティック セグメンテーション マップの注釈を取得することは、セマンティックの一貫性を事前に確認するには非常にコストがかかります。また、トレーニング セットのシーンは動的に変化しており、自動運転タスクのようにすべてのシーンのすべての要素のセマンティック カテゴリを明確に定義することはできません。これが、以前の自己教師あり方法がセマンティック情報を使用して自己教師あり損失を構築しなかった理由です。この目的のために、多視点画像間で共有されるセマンティック情報をマイニングするために、多視点画像の教師なしコセグメンテーション (Co-Segmentation) によって自己教師あり損失が構築されます。
- 事前のデータ強調の一貫性については、データ強調自体が色分布の変化をもたらします。つまり、色の一貫性のあいまいさの問題を引き起こし、自己監視信号に干渉する可能性があります。この目的のために、単一ブランチの自己教師ありトレーニング フレームワークを 2 つのブランチに分割し、元のブランチの予測結果を疑似ラベルとして使用して、データ拡張ブランチの予測結果を監視します。
- 具体的な貢献は次のとおりです。
- セマンティックの一貫性とデータ拡張の一貫性の追加の事前確率が、色の恒常性のあいまいさを克服するための信頼できるガイダンスを提供できる、Joint Data-Augmentation and Co-Segmentation フレームワーク (JDACS) と呼ばれる統合された教師なし MVS パイプラインを提案します。
- 意味的一貫性に基づく新しい自己監督信号を提案します。これは、完全に教師なしの方法で、固定されていないシナリオで多視点画像から相互の意味的対応を発掘することができます。
- 色の変動に対する正則化を提供できる、教師なし MVS に大量のデータ拡張を組み込む新しい方法を提案します。
8. 実験結果:
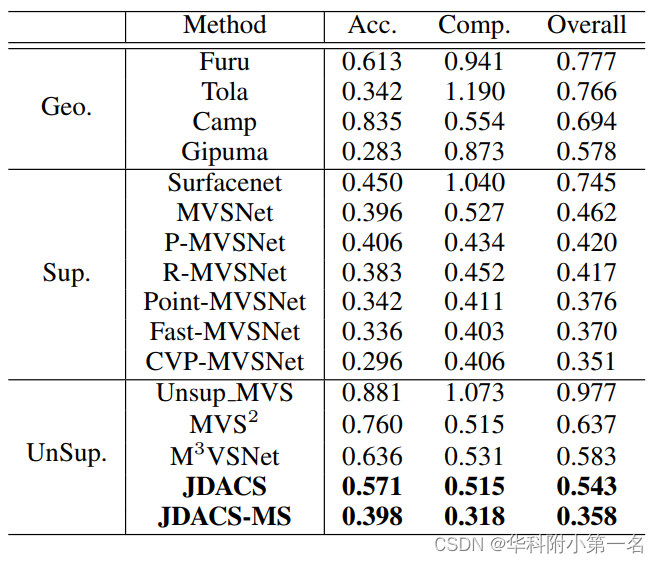
実験結果は、私たちの提案した方法が教師なしの方法の中で飛躍的なパフォーマンスをもたらし、いくつかのトップの教師ありの方法と同等に競争できることを示しています。

9. 論文とコードのダウンロード:
https://arxiv.org/pdf/2104.05374v1.pdf
https://github.com/ToughStoneX/Self-Supervised-MVS
2. 実施プロセス
1. JDACSの概要
フレームワーク全体は、次の 3 つのブランチに分かれています。
- 深度推定ブランチ: 参照ビュー (Reference View) とソース ビュー画像 (Source View) をネットワークに入力し、予測された深度マップとソース ビュー画像を使用して参照ビュー画像を再構築します。再構成された画像と元の画像の違いを参照透視図で比較し、Photometric Consistency Loss (Photometric Consistency) を構築します。
- コセグメンテーション ブランチ: 入力マルチビューを事前トレーニング済みの VGG ネットワークにフィードし、その特徴マップに対して非負行列分解 (NMF) を実行します。NMF の直交性の制約により、そのプロセスは、複数のビュー間で共有されるセマンティクスをクラスタリングし、コセグメンテーション マップを出力するものと見なすことができます。次に、セグメント化された画像再構成タスク、つまりセマンティックの一貫性の喪失が、予測された深度マップとマルチビュー コセグメンテーション マップから構築されます。
- データ強化ブランチ: 元のマルチビューに対してランダムなデータ強化を実行し、ネットワークに送信します。深度推定ブランチによって予測された深度マップは、データ拡張ブランチの予測結果を監視するための疑似ラベルとして使用され、データ拡張一貫性損失が構築されます。
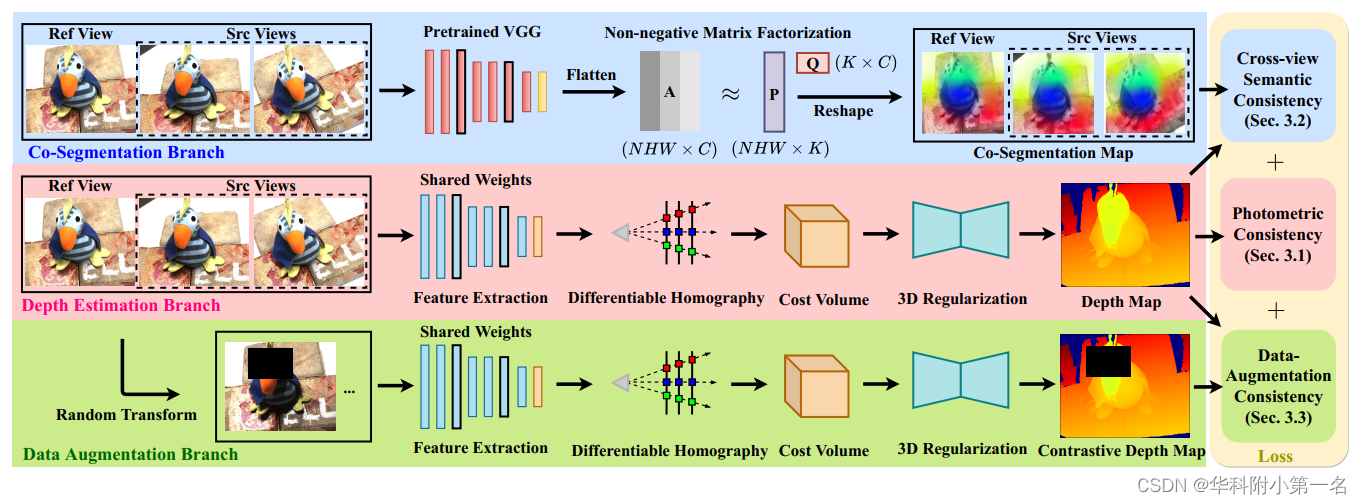
2.深度推定ブランチ
MVSNet、CVP-MVSNet、およびその他のバックボーン ネットワークを使用して深度マップを予測します。

測光の一貫性:測光の一貫性の重要な考え方は、同じ視野角での合成画像と元の画像の違いを最小限に抑えることです。最初のビューが参照ビューであり、残りの N-1 ビューが i (2≤i≤N) インデックスのソース ビューであることを示します。関連する内因性および外因性パラメーター (K、T) を持つ特定の画像 (I1、Ii) のペアの場合、ソース ビュー内の対応する位置 p`j は、その参照ビュー座標 pj に基づいて計算できます。

ここで、j (1≤j≤HW) はピクセル ポイントのインデックスで、D は予測深度マップです。次に、微分可能バイリニア サンプリングを使用して、変形画像 Ii' を取得します。

変形により、一部のピクセルが画像の外側領域に投影される可能性があるため、新しいビューで有効なピクセルを示すバイナリ有効性マスク Mi が同時に生成されます。MVS では、測光整合性の損失は、すべての N-1 ソース ビューを参照ビューに投影することによって計算されます。

ここで、∇ は勾配演算子を表し、o は内積です。色空間とグラデーション空間の両方で L1 損失を計算します。
3. 共同分割支店
教師なしコセグメンテーションによるマルチビュー画像からの暗黙的な共通セグメンテーションのマイニング。コセグメンテーションの目的は、特定の画像コレクション内の共通オブジェクトの前景ピクセルを見つけることです。非負行列分解 (NMF) には固有のクラスタリング プロパティがあります。従来のコセグメンテーション パイプラインを介して事前トレーニング済みの CNN レイヤーのアクティベーションに NMF を適用すると、画像間のセマンティックな対応を検出できます。

1. N 個の画像が入力として使用され、[N, C, h, w] の特徴マップは、ImageNet によって事前にトレーニングされた Vgg モデルを通じて取得されます。(ここで h と w は、元の画像のサイズではなく、特徴マップのサイズです)。
2. N 個の特徴マップの次元を [Nhw, C] に変換し、非負行列分解によって P 行列: [Nhw, K] と Q 行列: [K, C] を取得し、その次元を変換します。 P 行列を [N, h, w, K] に変換します。ここで、K はカテゴリのプリセット数です。目的は、特徴マップ内のピクセルを K カテゴリにクラスタ化することです。

3. ワンホット グラフに再形成し、ソフトマックスを通じてセマンティック グラフを構築する
4. コセグメンテーション ロスを計算する

4.データ拡張ブランチ
対照学習に関する最近の研究では、自己教師あり学習におけるデータ拡張の利点が示されています。直観的に、データ拡張は困難なサンプルをもたらし、教師なし損失の信頼性を壊し、変更に対するロバスト性を提供します。簡単に言えば、任意の拡張 τθ をパラメータ化するためにランダム ベクトル θ を定義します: 画像 I→I¯。τθ ただし、拡張画像の自然な色の変動は、色の不変性に関する自己教師付き制約に干渉する可能性があるため、データ拡張が自己教師付き方法に適用されることはめったにありません。したがって、ビュー合成の本来の目的を最適化する代わりに、元のデータと増強されたサンプルの出力を正則化することによって、教師なしデータ増強の一貫性が強化されます。
具体的には、N個のピクチャのデータを強化し、深度推定ブランチの共有CVP_MVSNETを介してピラミッドの各層の深度マップを取得し、損失を計算する。

Data Augmentation Consistency Loss :深度推定ブランチの元の画像 I の通常のフォワード パス予測は D として示され、強化された画像 I¯τθ の予測は D¯τθ として示されます。対照的に、データ拡張の一貫性は、D と D¯τθ の差を最小限に抑えることで保証されます。

ここで、Mτθ は、変換 τ の下での遮蔽されていないマスク τθ を示します。異なるビュー間のエピポーラ制約により、このフレームワークに統合された拡張メソッドは、ピクセルの空間位置を変更しません。データの拡張方法は次のとおりです。
- クロスビュー マスク:マルチビューの状況でオクルージョン イリュージョンをシミュレートするために、バイナリ クロッピング マスク 1-Mτθ1 がランダムに生成され、参照ビューの一部の領域がオクルードされます。次に、オクルージョン マスクが他のビューに投影され、イメージ内の対応する領域がオクルージョンされます。残りの領域 Mτθ1 が変換の影響を受けないと仮定すると、元のサンプルと拡張されたサンプルの結果の間の有効な領域を比較できます。
- ガンマ補正:ガンマ補正は、画像の明るさを調整するために使用される非線形操作です。さまざまなイルミネーションをシミュレートするために、積分確率ガンマ補正 τθ2 は θ2 をパラメータ化して、教師なし損失に挑戦します。
- 色のディザリングとぼかし:ランダムな色のディザリング、ランダムなぼかし、ランダムなノイズなど、多くの変換で画像に色の変動を加えることができます。測光損失はビュー間で一定の色を必要とするため、色の変動により、MVS の教師なし損失が信頼できなくなります。代わりに、τθ3 で表されるこれらの変換は、挑戦的なシーンを作成し、自己監視における色の変動に対するロバスト性を調整することができます。
全体の変換 τθ は、上記の拡張機能の組み合わせとして表現できます: τθ = τθ3◦τθ2◦τθ1、ここで、◦ は特徴の組み合わせを示します。
5. 全体損失
測光整合性に基づく基本的な自己教師あり信号 LPC に加えて、2 つの自己教師あり信号、セマンティック整合性 LSC データ強化整合性 LDA が追加されています。上記の損失に加えて、構造的類似性 LSSIM や深度平滑性 LSmooth など、いくつかの一般的な正則化用語も深度推定に使用されます。最終的な損失は次のとおりです。

重みは経験的に次のように設定されます: λ1 = 0.8、λ2 = 0.1、λ3 = 0.1、λ4 = 0.2、λ5 = 0.0067。
6.実験
先端技術との比較

7. 制限事項
解決すべき問題がいくつかあります: 第一に、すべての背景ピクセルの色とセマンティクスさえも同じであるため、黒/白の背景などの非テクスチャ領域には有効な自己監視信号がありません; 第二に、共同セグメンテーション ImageNet 分類タスクに基づいて事前トレーニングされた VGG モデルは、詳細なセマンティクスに注意を払う必要があるセグメンテーション タスクには適していないため、この方法では比較的大まかなセマンティック情報しか発掘されませんでした。