コースのリソース:
7.モデルの検証と学習過程の可視化【小学生向けPytorch】【ソースコード提供】_哔哩哔哩_bilibili
前項の注意点を参考に食べるのがオススメです〜:
pytorch の高度な学習 (5): ナニー レベルのニューラル ネットワーク移行学習アプリケーションの詳細な紹介、トレーニング済みモデルを必要なモデルに置き換える方法 - プログラマー募集
- トレーニングとテストのデータセット: データ (5 クラス)
- 検証セット: テストデータ (データセットからランダムに 20 枚以上の写真を抽出)
- 事前トレーニング済みのネットワークと重みファイル: resnet34 事前トレーニング済みの重みファイルを使用します。ダウンロード アドレスは次のとおりです。
https://download.pytorch.org/models/resnet34-333f7ec4.pth
目次
1. データセット CreateDataset.py を生成します
2.事前トレーニングモデル PreTrainedModel.py
1. トレーニング済みのウェイト ファイルをダウンロードする
2. 転移学習法を使用して resnet34 ニューラル ネットワーク フレームワークを変更し、事前トレーニング済みの重みを読み込みます
1. データセット CreateDataset.py を生成します
トレーニング セットとテスト セットを生成し、それぞれ tes.txt、train.txt、および eval.txt ファイルに保存します (モデルの入力に相当)。後でデータローダ dataload を実行するときは、そこからデータを読み取ります。
- test.txt、train.txt: テスト セットとトレーニング セットの画像パスとラベルを保存します
- eval.txt: 検証セットの画像データを保存するパス
1. コード
'''
生成训练集和测试集,保存在txt文件中
'''
##相当于模型的输入。后面做数据加载器dataload的时候从里面读他的数据
import os
import random#打乱数据用的
def CreateTrainingSet():
# 百分之80用来当训练集
train_ratio = 0.8
# 用来当测试集
test_ratio = 1-train_ratio
rootdata = r"data"#数据的根目录
train_list, test_list = [],[]#读取里面每一类的类别
data_list = []
#生产train.txt和test.txt
class_flag = -1
for a,b,c in os.walk(rootdata):
print(a)
for i in range(len(c)):
data_list.append(os.path.join(a,c[i]))
for i in range(0,int(len(c)*train_ratio)):
train_data = os.path.join(a, c[i])+'\t'+str(class_flag)+'\n'
train_list.append(train_data)
for i in range(int(len(c) * train_ratio),len(c)):
test_data = os.path.join(a, c[i]) + '\t' + str(class_flag)+'\n'
test_list.append(test_data)
class_flag += 1
print(train_list)
random.shuffle(train_list)#打乱次序
random.shuffle(test_list)
with open('train.txt','w',encoding='UTF-8') as f:
for train_img in train_list:
f.write(str(train_img))
with open('test.txt','w',encoding='UTF-8') as f:
for test_img in test_list:
f.write(test_img)
def CreateEvalData():
data_list = []
test_root = r"testdata"
for a, b, c in os.walk(test_root):
for i in range(len(c)):
data_list.append(os.path.join(a, c[i]))
print(data_list)
with open('eval.txt', 'w', encoding='UTF-8') as f:
for test_img in data_list:
f.write(test_img + '\t' + "0" + '\n')
if __name__ == "__main__":
CreateEvalData()
CreateTrainingSet()
2. 走行結果
3 つの TXT ファイルが生成されていることがわかります。
eval.txt ファイルの各行は、画像のパスと 0 で構成されます。画像の後に 0 を追加することで、train.txt と test.txt の形式を前にパス、後ろにラベルで統一します。 TXT の情報は後で均一に抽出できます。
2.事前トレーニングモデル PreTrainedModel.py
1. トレーニング済みのウェイト ファイルをダウンロードする
対応する URL から resnet34 事前トレーニング パラメーターをダウンロードし、ファイルを resnet34_pretrain.pth に変更して、プロジェクト ファイルに保存します。

2. 転移学習法を使用して resnet34 ニューラル ネットワーク フレームワークを変更し、事前トレーニング済みの重みを読み込みます
- 使用するデータセットは 5 カテゴリで、全結合層の FC 層の出力は 5 である必要があり、自作した resnet ニューラル ネットワークの FC 層の出力は 1000 です (1000 カテゴリのデータセットを使用してトレーニング)、そのため、fc レイヤーの出力を 5 に変更する必要があります。
- resnet34 トレーニング前の重みファイルの fc レイヤー パラメーターを削除します。
- 自分で構築したネットワークに重みパラメーターを読み込み、ネットワーク内の重みを更新します。
- fc レイヤー以外のすべてのレイヤーをフリーズして、fc レイヤー パラメーターの個別のトレーニングの準備をします。
- 損失関数と勾配降下アルゴリズムを使用して、fc レイヤーのパラメーターをトレーニングします。
詳細については、メモを参照してください。
3. モデルの最適化
3.1 モデルプロセスデータの保存と出力
トレーニング中に epoch=50 を設定します。
- エポックの各ラウンドで、トレーニング プロセス中の損失値と、テスト プロセス中の精度と平均損失が保存され、記録は mobilenet_36_traindata.txt という名前のファイルに保存されます。
- 10 エポックごとに、重みパラメータが resnet_epoch_xx_acc_xx.pth ファイルに保存され、対応するエポック番号と精度がファイル名に保存されます。50 エポックがあるため、 resnet_epoch_10_acc_xx.pth、resnet_epoch_20_acc_xx.pth などの 5 つのファイルが保存されます。
- エポックの acc が以前のものよりも高い場合は、BEST_resnet_epoch_xx_acc_xx.pth ファイルを保存して、現在の最大精度を記録します。
# 一共训练50次
epochs = 50
best = 0.0
for t in range(epochs):
print(f"Epoch {t + 1}\n-------------------------------")
train_loss = train(train_dataloader, model, loss_fn, optimizer)
accuracy, avg_loss = test(test_dataloader, model)
# 记录训练过程值,写入mobilenet_36_traindata.txt文件进行保存
write_result("mobilenet_36_traindata.txt", t+1, train_loss, avg_loss, accuracy)
#10个 epoch保存一次resnet_epoch_xx_acc_xx.pth文件
if (t+1) % 10 == 0:
torch.save(model.state_dict(), "resnet_epoch_"+str(t+1)+"_acc_"+str(accuracy)+".pth")
# 如果一个epoch的acc比上一个要高,就保存一个BEST_resnet_epoch_xx_acc_xx.pth文件,记录当前最高的准确率
if float(accuracy) > best:
best = float(accuracy)
torch.save(model.state_dict(), "BEST_resnet_epoch_" + str(t+1) + "_acc_" + str(accuracy) + ".pth")3.2 トレーニングプロセス
train メソッドでは、バッチサイズのデータのバッチの平均損失を返します。
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
avg_total = 0.0
# 从数据加载器中读取batch(一次读取多少张,即批次数),X(图片数据),y(图片真实标签)。
for batch, (X, y) in enumerate(dataloader):
# 将数据存到显卡
X, y = X.cuda(), y.cuda()
# 得到预测的结果pred
pred = model(X)
# 计算预测的误差
loss = loss_fn(pred, y)
avg_total = avg_total+loss.item()
# 反向传播,更新模型参数
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每训练10次,输出一次当前信息
if batch % 10 == 0:
loss, current = loss.item(), batch * len(X)
#这行代码的作用是在训练模型时输出当前的loss值和训练进度。
#其中,loss值会被格式化为浮点数,current表示当前已经训练的样本数,size表示总的样本数。
#输出的格式为"loss:(loss值][[current/{size]”。其中,“>“表示右对齐,数字表示输出的最小宽度。
print(f"loss: {loss:>5f} [{current:>5d}/{size:>5d}]")
# 定义平均损失
avg_loss = f"{(avg_total % batch_size):>5f}"
return avg_loss3.3 テストプロセス
テスト関数は、テスト セット データの精度と損失の値を返します
def test(dataloader, model):
size = len(dataloader.dataset)
# 将模型转为验证模式
model.eval()
# 初始化test_loss 和 correct, 用来统计每次的误差
test_loss, correct = 0, 0
# 测试时模型参数不用更新,所以no_gard()
# 非训练, 推理期用到
with torch.no_grad():
# 加载数据加载器,得到里面的X(图片数据)和y(真实标签)
for X, y in dataloader:
# 将数据转到GPU
X, y = X.cuda(), y.cuda()
# 将图片传入到模型当中就,得到预测的值pred
pred = model(X)
# 计算预测值pred和真实值y的差距
test_loss += loss_fn(pred, y).item()
# 统计预测正确的个数
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= size
correct /= size
accuracy = f"{(100*correct):>0.1f}"
avg_loss = f"{test_loss:>8f}"
print(f"correct = {correct}, Test Error: \n Accuracy: {accuracy}%, Avg loss: {avg_loss} \n")
# 增加数据写入功能
return accuracy, avg_loss3.4 実行結果
- epoch=50 の場合、トレーニングが終了するまでしばらく辛抱強く待つ必要があります。BESTの冒頭のパラメータファイルが生成され、ラウンドごとにaccが増加していることが分かります.最も精度の高いエポックのグループは50番目のグループでacc=87.1%であることが分かります.パラメータのグループは、後でニューラル ネットワークとして選択できます モデルを検証するための重み.
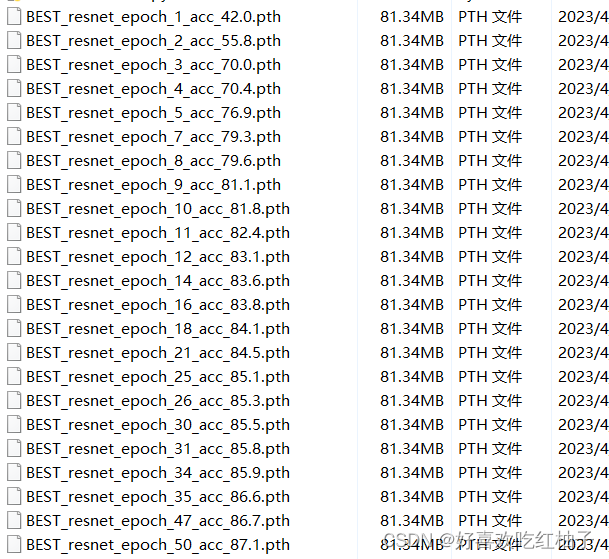
- 10/20/30/40/50 の生成されたエポック ウェイト ファイル

- Mobilenet_36_traindata.txt が生成され、トレーニング プロセス中に各エポックのトレーニング情報が保存されます。
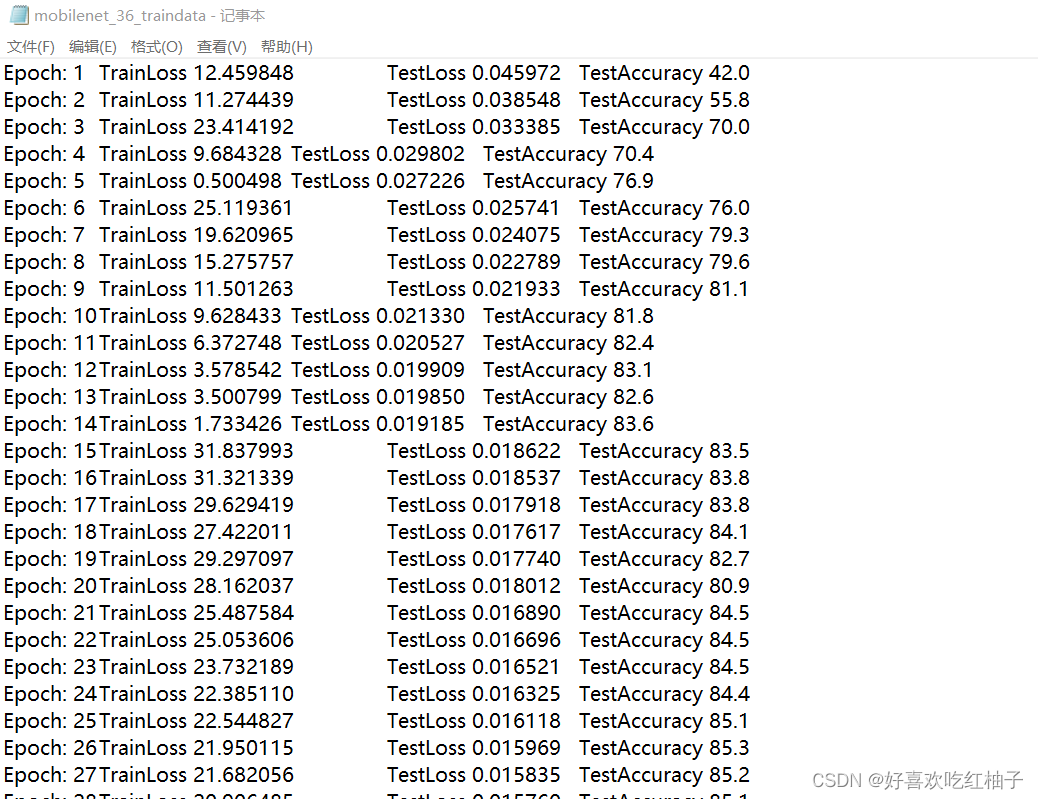
4. コード
'''
纪录训练信息,包括:
1. train loss
2. test loss
3. test accuracy
'''
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision.models import resnet34
from utils import LoadData, write_result
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
avg_total = 0.0
# 从数据加载器中读取batch(一次读取多少张,即批次数),X(图片数据),y(图片真实标签)。
for batch, (X, y) in enumerate(dataloader):
# 将数据存到显卡
X, y = X.cuda(), y.cuda()
# 得到预测的结果pred
pred = model(X)
# 计算预测的误差
loss = loss_fn(pred, y)
avg_total = avg_total+loss.item()
# 反向传播,更新模型参数
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每训练10次,输出一次当前信息
if batch % 10 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>5f} [{current:>5d}/{size:>5d}]")
# 定义平均损失
avg_loss = f"{(avg_total % batch_size):>5f}"
return avg_loss
def test(dataloader, model):
size = len(dataloader.dataset)
# 将模型转为验证模式
model.eval()
# 初始化test_loss 和 correct, 用来统计每次的误差
test_loss, correct = 0, 0
# 测试时模型参数不用更新,所以no_gard()
# 非训练, 推理期用到
with torch.no_grad():
# 加载数据加载器,得到里面的X(图片数据)和y(真实标签)
for X, y in dataloader:
# 将数据转到GPU
X, y = X.cuda(), y.cuda()
# 将图片传入到模型当中就,得到预测的值pred
pred = model(X)
# 计算预测值pred和真实值y的差距
test_loss += loss_fn(pred, y).item()
# 统计预测正确的个数
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= size
correct /= size
accuracy = f"{(100*correct):>0.1f}"
avg_loss = f"{test_loss:>8f}"
print(f"correct = {correct}, Test Error: \n Accuracy: {accuracy}%, Avg loss: {avg_loss} \n")
# 增加数据写入功能
return accuracy, avg_loss
if __name__ == '__main__':
batch_size = 32
# # 给训练集和测试集分别创建一个数据集加载器
train_data = LoadData("train.txt", True)
valid_data = LoadData("test.txt", False)
train_dataloader = DataLoader(dataset=train_data, num_workers=4, pin_memory=True, batch_size=batch_size, shuffle=True)
test_dataloader = DataLoader(dataset=valid_data, num_workers=4, pin_memory=True, batch_size=batch_size)
# 如果显卡可用,则用显卡进行训练
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
'''
修改ResNet34模型的最后一层
'''
pretrain_model = resnet34(pretrained=False)
num_ftrs = pretrain_model.fc.in_features # 获取全连接层的输入
pretrain_model.fc = nn.Linear(num_ftrs, 5) # 全连接层改为不同的输出
# 预先训练好的参数, 'https://download.pytorch.org/models/resnet34-333f7ec4.pth'
pretrained_dict = torch.load('./resnet34_pretrain.pth')
# # 弹出fc层的参数
pretrained_dict.pop('fc.weight')
pretrained_dict.pop('fc.bias')
# # 自己的模型参数变量,在开始时里面参数处于初始状态,所以很多0和1
model_dict = pretrain_model.state_dict()
# # 去除一些不需要的参数
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}
# # 模型参数列表进行参数更新,加载参数
model_dict.update(pretrained_dict)
# 改进过的预训练模型结构,加载刚刚的模型参数列表
pretrain_model.load_state_dict(model_dict)
'''
冻结部分层
'''
# 将满足条件的参数的 requires_grad 属性设置为False
for name, value in pretrain_model.named_parameters():
if (name != 'fc.weight') and (name != 'fc.bias'):
value.requires_grad = False
#
# filter 函数将模型中属性 requires_grad = True 的参数选出来
params_conv = filter(lambda p: p.requires_grad, pretrain_model.parameters()) # 要更新的参数在parms_conv当中
model = pretrain_model.to(device)
# 定义损失函数,计算相差多少,交叉熵,
loss_fn = nn.CrossEntropyLoss()
''' 控制优化器只更新需要更新的层 '''
optimizer = torch.optim.SGD(params_conv, lr=1e-3) # 初始学习率
#
# 一共训练50次
epochs = 50
best = 0.0
for t in range(epochs):
print(f"Epoch {t + 1}\n-------------------------------")
train_loss = train(train_dataloader, model, loss_fn, optimizer)
accuracy, avg_loss = test(test_dataloader, model)
# 记录训练过程值,写入mobilenet_36_traindata.txt文件进行保存
write_result("mobilenet_36_traindata.txt", t+1, train_loss, avg_loss, accuracy)
#10个 epoch保存一次resnet_epoch_xx_acc_xx.pth文件
if (t+1) % 10 == 0:
torch.save(model.state_dict(), "resnet_epoch_"+str(t+1)+"_acc_"+str(accuracy)+".pth")
# 如果一个epoch的acc比上一个要高,就保存一个BEST_resnet_epoch_xx_acc_xx.pth文件,记录当前最高的准确率
if float(accuracy) > best:
best = float(accuracy)
torch.save(model.state_dict(), "BEST_resnet_epoch_" + str(t+1) + "_acc_" + str(accuracy) + ".pth")
print("Train PyTorch Model Success!")3. モデルの検証
トレーニング済みのニューラル ネットワークを使用して、検証セット内の画像に対してデータ検証を実行します。
1. モデル構造のインポート
fc 層の出力を変更した resnet34 ネットワークを定義します。
'''
1. 导入模型结构
'''
# 设置自己的模型
model = resnet34(pretrained=False)
num_ftrs = model.fc.in_features # 获取全连接层的输入
model.fc = nn.Linear(num_ftrs, 5) # 全连接层改为不同的输出
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")2. モデル パラメータの読み込み
最高のトレーニング精度を持つパラメーター セットの重みファイルを使用します。私の名前は「./BEST_resnet_epoch_50_acc_87.1.pth」です。パラメーターをニューラル ネットワークに読み込み、モデルを cuda に変換します。
'''
2. 加载模型参数
'''
# 调用最好的acc的一组参数权重
model_loc = "./BEST_resnet_epoch_50_acc_87.1.pth"
model_dict = torch.load(model_loc)
model.load_state_dict(model_dict)
# 把模型转换到cuda中
model = model.to(device)3. 画像を読み込む
LoadData と DataLoader を使用して、検証セットに画像を読み込みます。
'''
3. 加载图片
'''
# 加载验证集中的图片
valid_data = LoadData("eval.txt", train_flag=False)
test_dataloader = DataLoader(dataset=valid_data, num_workers=2, pin_memory=True, batch_size=1)
4. 検証プロセス
検証データセットの各画像の予測ラベルと確率を、label_list と尤度_list の 2 つのリストに格納します。
def eval(dataloader, model):
label_list = []
likelihood_list = []
model.eval()
with torch.no_grad():
# 加载数据加载器,得到里面的X(图片数据)和y(真实标签)
for X, y in dataloader:
# 将数据转到GPU
X = X.cuda()
# 将图片传入到模型当中就,得到预测的值pred
pred = model(X)
# 获取可能性最大的标签
label = torch.softmax(pred,1).cpu().numpy().argmax()
label_list.append(label)
# 获取可能性最大的值(即概率)
likelihood = torch.softmax(pred,1).cpu().numpy().max()
likelihood_list.append(likelihood)
return label_list,likelihood_list
5. 結果を取得する
ラベル リストのラベル番号を対応するカテゴリ テキストに変換し、pandas を使用してリストを描画し、各画像のカテゴリと確率を出力し、表を csv ファイルに保存します。
'''
4. 获取结果
'''
#
label_list, likelihood_list = eval(test_dataloader, model)
label_names = ["daisy", "dandelion","rose","sunflower","tulip"]
result_names = [label_names[i] for i in label_list]
list = [result_names, likelihood_list]
df = pd.DataFrame(data=list)
df2 = pd.DataFrame(df.values.T, columns=["label", "likelihood"])
print(df2)
# 使用pandas把预测结果保存
df2.to_csv('testdata.csv', encoding='gbk')pycharm コンソール出力の結果:

testdata.csv ファイルに保存された予測テーブル:
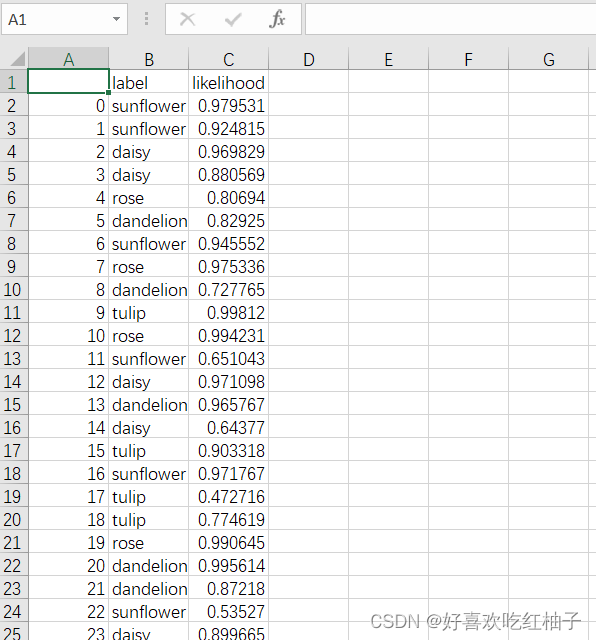
6. 完全なコード
'''
1.单幅图片验证
2.多幅图片验证
'''
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision.models import resnet34
from utils import LoadData, write_result
import pandas as pd
def eval(dataloader, model):
label_list = []
likelihood_list = []
model.eval()
with torch.no_grad():
# 加载数据加载器,得到里面的X(图片数据)和y(真实标签)
for X, y in dataloader:
# 将数据转到GPU
X = X.cuda()
# 将图片传入到模型当中就,得到预测的值pred
pred = model(X)
# 获取可能性最大的标签
label = torch.softmax(pred,1).cpu().numpy().argmax()
label_list.append(label)
# 获取可能性最大的值(即概率)
likelihood = torch.softmax(pred,1).cpu().numpy().max()
likelihood_list.append(likelihood)
return label_list,likelihood_list
if __name__ == "__main__":
'''
1. 导入模型结构
'''
# 设置自己的模型
model = resnet34(pretrained=False)
num_ftrs = model.fc.in_features # 获取全连接层的输入
model.fc = nn.Linear(num_ftrs, 5) # 全连接层改为不同的输出
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
'''
2. 加载模型参数
'''
# 调用最好的acc的一组参数权重
model_loc = "./BEST_resnet_epoch_50_acc_87.1.pth"
model_dict = torch.load(model_loc)
model.load_state_dict(model_dict)
# 把模型转换到cuda中
model = model.to(device)
'''
3. 加载图片
'''
# 加载验证集中的图片
valid_data = LoadData("eval.txt", train_flag=False)
test_dataloader = DataLoader(dataset=valid_data, num_workers=2, pin_memory=True, batch_size=1)
'''
4. 获取结果
'''
#
label_list, likelihood_list = eval(test_dataloader, model)
label_names = ["daisy", "dandelion","rose","sunflower","tulip"]
result_names = [label_names[i] for i in label_list]
list = [result_names, likelihood_list]
df = pd.DataFrame(data=list)
df2 = pd.DataFrame(df.values.T, columns=["label", "likelihood"])
print(df2)
# 使用pandas把预测结果保存
df2.to_csv('testdata.csv', encoding='gbk')4.可視化
前のトレーニング プロセスで保存した mobilenet_36_traindata.txt ファイルを使用します。このファイルには、トレーニング プロセス中の各エポックの精度 acc および損失関数 TrainLoss、TestLoss、および TestAccuracy が保存されます。
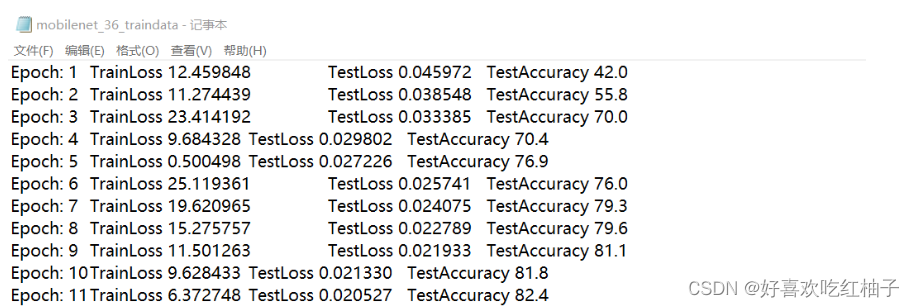
1. コード
import matplotlib.pyplot as plt
import numpy as np
# 画图表
def getdata(data_loc):
epoch_list = []
train_loss_list = []
test_loss_list = []
acc_list = []
with open(data_loc, "r") as f:
for i in f.readlines():
data_i = i.split("\t")
epoch_i = float(data_i[0][7:])
train_loss_i = float(data_i[1][10:])
test_loss_i = float(data_i[2][9:])
acc_i = float(data_i[3][13:])
epoch_list.append(epoch_i)
train_loss_list.append(train_loss_i)
test_loss_list.append(test_loss_i)
acc_list.append(acc_i)
print(len(epoch_list), len(train_loss_list))
return epoch_list, train_loss_list, test_loss_list, acc_list
if __name__ == "__main__":
data_loc = r"mobilenet_36_traindata.txt"
epoch_list, train_loss_list, test_loss_list, acc_list = getdata(data_loc)
# #train_loss
# plt.plot(epoch_list, train_loss_list)
#
# plt.legend(["model"])
# plt.xticks(np.arange(0, 50, 5)) # 横坐标的值和步长
# plt.yticks(np.arange(0, 100, 10)) # 横坐标的值和步长
# plt.xlabel("Epoch")
# plt.ylabel("train_loss")
# plt.title("Train Loss")
# plt.show()
# 准确率曲线
# plt.plot(epoch_list, acc_list)
#
# plt.legend(["model"])
# plt.xticks(np.arange(0, 50, 5)) # 横坐标的值和步长
# plt.yticks(np.arange(0, 100, 10)) # 横坐标的值和步长
# plt.xlabel("Epoch")
# plt.ylabel("Accurancy(100%)")
# plt.title("Model Accuracy")
# plt.show()
# test_loss
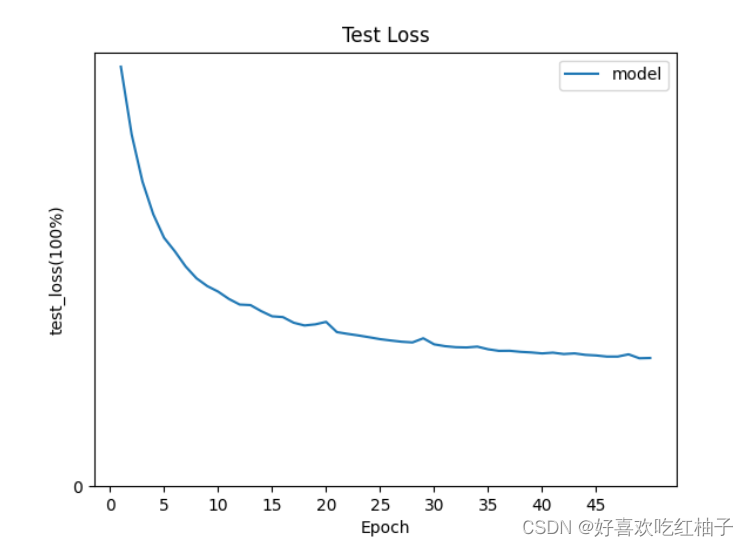
plt.plot(epoch_list, test_loss_list)
plt.legend(["model"])
plt.xticks(np.arange(0, 50, 5)) # 横坐标的值和步长
plt.yticks(np.arange(0, 1, 10)) # 横坐标的值和步长
plt.xlabel("Epoch")
plt.ylabel("test_loss(100%)")
plt.title("Test Loss")
plt.show()2. グラフィックを描く
- 描画された精度率 acc 曲線:
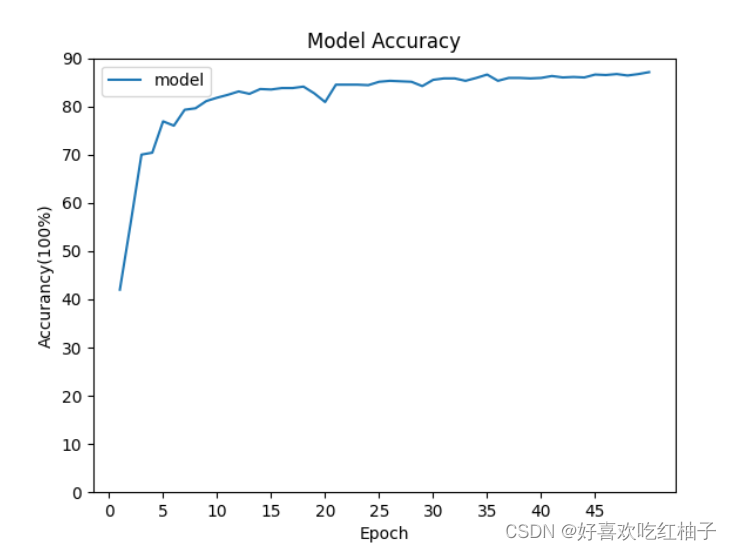
- 描かれた列車損失曲線:
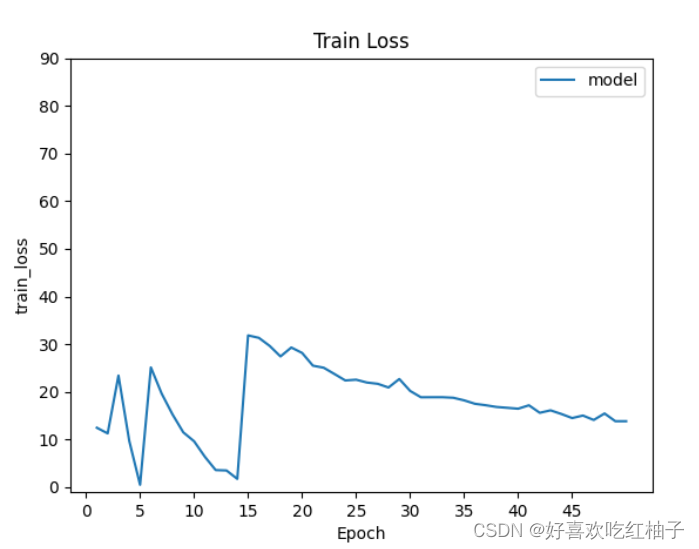
- 描かれたテスト損失曲線: (縦軸は 0 から 1 です)