目次
1 基礎知識のポイント
1.1 アンサンブル学習
アンサンブル学習は、機械学習の中心的な概念です。その主なアイデアは次のように要約されます。複数の弱学習器をトレーニングして強学習器の効果を達成することにより、組み合わせたパフォーマンスはどの弱学習器よりも優れています。機械学習のエラーは、次の 2 つのカテゴリに大別できます。1つは偏り誤差(bias error):予測値と実際の値の差を指し、もう1つは分散誤差(variance error):予測値の分散度を確率変数として指す、統合学習はこれらの問題を軽減することができます。複数の分類器の結果を組み合わせることで、特に一部の不安定な学習器のモデル予測の偏差を減らすことができるため、アンサンブル学習によって学習された学習器の安定性が高くなります。アンサンブル学習では、一般的な方法はバギングとブースティング、次にこれら 2 つの方法について簡単に説明します。
1.2 バギングとブースティング
バギングまたはブースティング手法を使用するには、基本学習器を選択する必要があります。たとえば、ツリーを分類することを選択すると、バギングとブースティングは一連のツリー学習器に結合され、統合された学習器になります. 次に、バギングとブースティングは、N 個の学習器を取得するためにどのようにトレーニングしますか?
-
初め:トレーニング データの選択
毎回、元のトレーニング データ セットから N 個の新しいトレーニング データ セットが生成され、N 個の学習器が個別にトレーニングされます。新しいトレーニング データ セットを生成するたびに、バギングはランダムにサンプルを選択します。これは、新しいトレーニング セットに各サンプルが出現する確率が同じであることを意味し、ブースティングはサンプルの重みに従って選択するため、一部のサンプルは新しいトレーニング セットで選択される可能性が高くなります。 -
2番目:トレーニングプロセス
バギングとブースティングの主な違いは、トレーニング プロセスです。このうち、Bagging はトレーニング フェーズで並列化され、各トレーナーは独立しているのに対し、Boosting はシーケンスに基づいて各トレーナーを構築します.新しいトレーナーの確立は前のトレーナーに依存するため、独立していません.、比較チャートは次のとおりです。
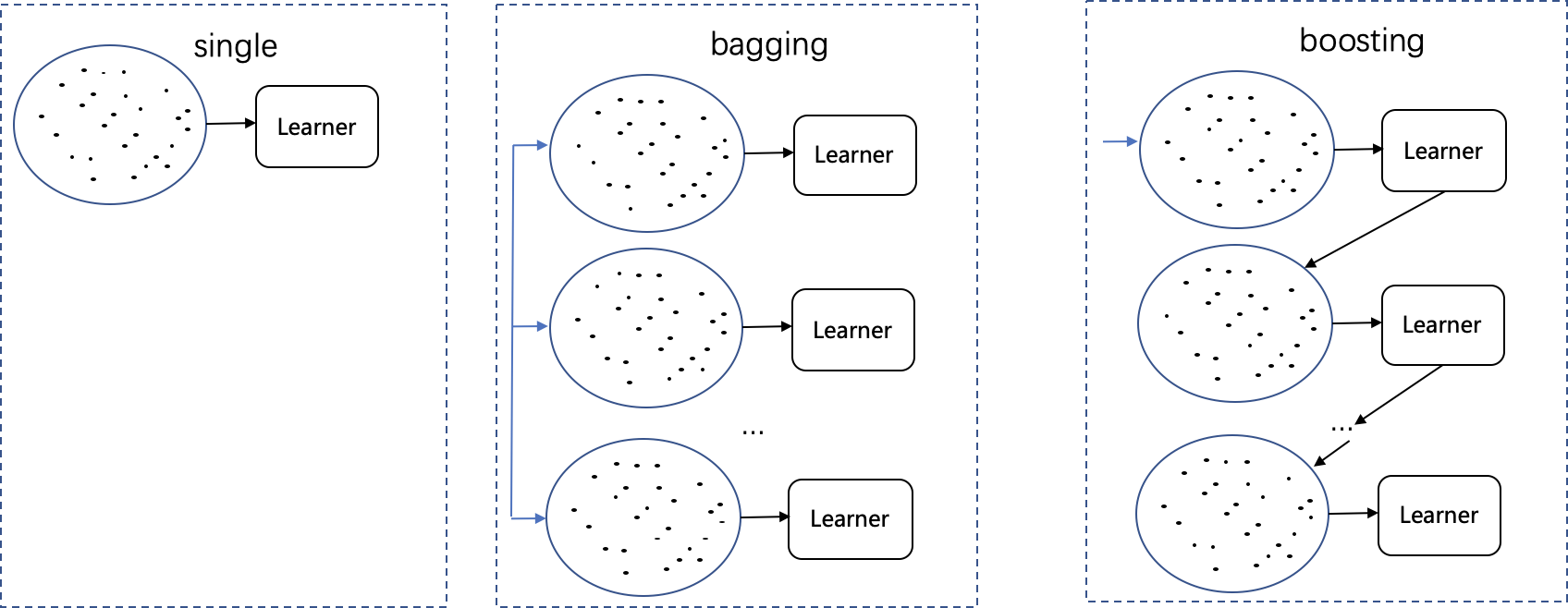
ブースティング アルゴリズムでは、各分類器のトレーニング データの選択は前の分類器の予測結果に依存するため、各トレーニング ステップでサンプルの重みが再調整され、誤って予測されたデータは重みを増加させ、トレーニングのために次の分類子に入る確率が高くなります。、これらの硬いサンプルの識別に焦点を当てています。
- 三番目:予測プロセス
N 人の学習者をトレーニングした後、バギングとブースティングでは予測結果に違いがあります.バギング戦略では、最終結果は N 人の学習者の結果の平均であり、ブースティングの予測結果は重み付けされた合計であり、次のように表されます
: = 1 N ∑ i = 1 N si \text{バギング} = \frac{1}{N} \sum_{i=1}^N s_i袋詰め=N1私は= 1∑Ns私
ブースティング = ∑ i = 1 N wisi \text{ブースティング} = \sum_{i=1}^N w_is_iブースティング=私は= 1∑Nw私s私
其中权重 w i w_i w私各分類子の予測のパフォーマンスに応じて割り当てられます。学習者の成績が良いほど、それに対応する重みが大きくなります。. ただし、Boosting が Bagging よりも優れている必要があるというわけではなく、特定のデータ セットや学習者など、複数の要因に応じて検討する必要があります。単一の学習器のパフォーマンスが悪い場合、バギングで強力な学習器を取得することは困難ですが、Boosting 最適化戦略は複数の学習器の効果を強化することができます。反対に、すべての学習者が過剰適合している場合は、バギングが最良の選択であり、ブースティングは過適合を回避するのに役立ちません。。
1.3 適応ブースティング
Adaptive Boosting (AdaBoost) は Boosting 手法の 1 つで、Boosting の核となる考え方は、前のモデルのエラーから学習することです。とAdaBoost 学習方法は、主に誤分類されたサンプルの重みを増加させるため、次のモデルは誤分類されたサンプルの認識効果により注意を払います。. トレーニングの基本的な手順は次のとおりです。
- ツリー モデルをトレーニングする
- このツリー モデル エラーのエラー率eeを計算しますe
- エラー率に基づいて、この決定木の重みを計算します。learning_rate * log((1-e) /e) であるため、エラー率 e が大きいほど、重みは小さくなります
- 各サンプルの重みを更新します。モデルによってペアになっているサンプルの場合、重みは変更されません。誤分類されたサンプルの場合、新しい重みは次のとおりです。old_weight * np.exp(この木の重み)、更新後、サンプルの重みが大きくなります、次のステップでは、そのような誤分類されたサンプルの識別が強化されます
- トレーニングされたツリーが最大値に達するまで、上記の手順を繰り返します
- 最終的な予測を行う: 加重投票メカニズムを通じて各候補セットのサンプルを予測します
1.3 勾配ブースティング
Gradient Boosting も Boosting 手法の 1 つですが、前述したように、Boosting モデルの核心は過去の過ちから学ぶことです。そして、勾配ブースティングの各反復は、前のステップの残差 (出力値に対するターゲット損失関数の偏導関数) に直接適合するため、現在の t ステップの予測結果は、ターゲット損失の負の勾配方向に等しくなります。を前のステップ t-1 の予測値に関数化するため、各反復 ( ft ( xi ) = ft − 1 ( xi ) − ∂ L ( yi , ft − 1 ( xi ) ) ∂ ft − 1 ( xi ) f_t (x_i) = f_{t-1} (x_i)-\frac{\partial L(y_i,f_{t-1}(x_i))}{\partial f_{t-1}(x_i)}へt( ×私)=へt − 1( ×私)−∂f _t − 1( ×私)∂ L ( y私、ft − 1( ×私) )) 目標損失損失を継続的に削減する、アルゴリズムの流れは次のとおりです。
1. 初期化 : f 0 ( x ) = argmin γ ∑ i = 1 NL ( yi , γ ) 1. 初期化: f_0(x) = \text{argmin}_\gamma \sum_{i=1}^NL (y_i , \ガンマ)1. _を初期化する:へ0( × )=アルグミンc∑私は= 1NL ( y私、c )
2. for t = 1 to T : 2. \text{for} \text{ } t=1 \text{} \text{to} \text{ }T:2 . のために =1Tに :
( a ) 计算负段階度 : y ^ i = − ∂ L ( yi , ft − 1 ( xi ) ) ∂ ft − 1 ( xi ) , i = 1 , 2 , . . . N \text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }(a) 计算负梯度: \hat{y}_i =- \frac{\partial L (y_i,f_{t-1}(x_i))}{\partial f_{t-1}(x_i)}, i=1,2,...N ( a )負の勾配を計算する:y^私=−∂f _t − 1( ×私)∂ L ( y私、ft − 1( ×私) )、私=1 、2 、. . . N
(b) 二乗誤差 \text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }( b) 二乗誤差を最小化することにより、\hat{y}_i を基本学習器 h_t(x) に適合させます。 ( b )二乗誤差を最小化することにより、ベース学習器ht( × )適合y^私、
wt = argmin w ∑ i = 1 NL ( y ^ i − ht ( xi ; w ) ] 2 \text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ } \text{ }\text{ }\text{ } w_t = \text{argmin}_w \sum_{i=1}^NL(\hat{y}_i - h_t(x_i; w)]^2 wt=アルグミンw∑私は= 1NL (y^私−時間t( ×私;w ) ]2
(c) Linesearch を使用して、L を最小にするステップ サイズ ρ m を決定します\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }(c) Linesearch を使用しますL が最小になるように、ステップ サイズ \rho_m を決定します。 ( c )ラインサーチを使用してステップサイズρを決定します。_メートル、L が最小になるように、
ρ t = argmin ρ ∑ i = 1 NL ( yi , ft − 1 ( xi ) + ρ ht ( xi ; wt ) ) \text{ }\text{ }\text{ }\text{ }\text{ }\text { }\text{ }\text{ }\text{ }\text{ } \rho_t = \text{argmin}_{\rho} \sum_{i=1}^NL(y_i, f_{t-1}( x_i) + \rho h_t(x_i;w_t)) rt=アルグミンr∑私は= 1NL ( y私、へt − 1( ×私)+ρh _t( ×私;wt) )
( d ) ft ( x ) = ft − 1 ( x ) + ρ tht ( x ; wt ) \text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ } (d) f_t(x) = f_{t-1}(x)+\rho_th_t(x;w_t) (ニ)フt( × )=へt − 1( × )+rt時間t( x ;wt)
3. f M ( x ) を出力 3. f_M(x) を出力3.出力f _M( × )
2 GBDT アルゴリズム
2.1 原則
GBDT (Gradient Boosting Decision Tree) は勾配ブースティング木です. 次に、アルゴリズムの詳細を詳細に推測します.
1) GBDT 予測結果値式
K 個の木があるとします。k番目の木の予測値には、関数 fk ( x ) f_k(x)を使用します。へk( x )は、サンプルxi x_iバツ私、最終的な予測値は:
yi ^ = ∑ k = 1 K fk ( xi ) \hat{y_i}=\sum_{k=1}^Kf_k(x_i)y私^=k = 1∑Kへk( ×私)
2) 目標損失関数を定義する
損失関数は、モデルによって予測された値と実際のラベル値との差を測定するために使用されます. 同時に、モデルが複雑になりすぎないように、モデルの重みパラメーターを罰するために、通常、正則化項目が追加されます. ただし, , 最適化する重みパラメータがないため、ツリー モデル アルゴリズムに基づいています。したがって、モデルの複雑さにペナルティを課すには、他の方法が必要です。通常、ツリー モデルの場合、通常は正則化項目は、ツリーの深さ、ツリーの葉ノードの数、または葉ノードの重み値の L2 ノルムなどから因数分解されます。. 一般に、ツリーのリーフ ノードが多いほど、ツリーが深くなるほどオーバーフィットしやすくなり、リーフ ノードの重みスコアが高くなると、オーバーフィッティングにつながる可能性があります。これらの問題を組み合わせて、ツリー モデルの場合、ターゲット損失関数を次のように定義できます。
O bj = ∑ i = 1 nl ( this , this ^ ) + ∑ k = 1 K Ω ( fk ) Obj = \sum_{i=1}^nl(y_i, \hat{y_i}) + \sum_{k= 1}^K\オメガ(f_k)O b j=私は= 1∑nl ( y私、y私^)+k = 1∑Kああ( fk)
其中l ( yi , y ^ i ) l(y_i, \hat{y}_i)l ( y私、y^私)モデル予測と実際のラベルの差Ω ( fk ) \Omega(f_k)ああ( fk)は正則化項であり、モデルの複雑さを測定し、モデルのオーバーフィッティングを防ぎます。私たちの目標は、上記の目的損失関数を最小化することです。
3) 目標損失関数の変形
目的関数を使用して、モデルはどのように学習しますか? 訓練したいのはツリーベースの関数なのでft ( x ) f_t(x)へt( x )は数値ベクトルではなく、勾配降下法では解決できません。したがって、最適解を見つけるには、追加トレーニング (ブースティング) と呼ばれる別の方法が必要です。
初期値が 0 であると仮定すると、追加のツリーごとに、予測結果値の反復形式は次のようになります。
yi ^ ( 0 ) = 0 \hat{y_i}^{(0)} = 0y私^( 0 )=0
yi ^ ( 1 ) = f 1 ( xi ) = yi ^ ( 0 ) + f 1 ( xi ) \hat{y_i}^{(1)} = f_1(x_i) = \hat{y_i}^{(0 )} + f_1(x_i)y私^( 1 )=へ1( ×私)=y私^( 0 )+へ1( ×私)
yi ^ ( 2 ) = f 1 ( xi ) + f 2 ( xi ) = yi ^ ( 1 ) + f 2 ( xi ) \hat{y_i}^{(2)} = f_1(x_i) + f_2(x_i) ) = \hat{y_i}^{(1)} + f_2(x_i)y私^( 2 )=へ1( ×私)+へ2( ×私)=y私^( 1 )+へ2( ×私)
…
yi ^ ( t ) = ∑ k = 1 tfk ( xi ) = yi ^ ( t − 1 ) + ft ( xi ) \hat{y_i}^{(t)} =\sum_{k=1}^tf_k (x_i) = \hat{y_i}^{(t-1)} + f_t(x_i)y私^( t )=∑k = 1tへk( ×私)=y私^( t − 1 )+へt( ×私)
上記の式から、ステップ t での最終予測結果は、前の t-1 ステップのすべての結果と現在のツリーの結果の合計であることがわかります (ここでは、学習率係数を制御するために考慮しません)。各ツリーの重み) 値のスケーリング)。目的関数を次のように展開します。
O bj ( t ) = ∑ i = 1 nl ( yi , yi ^ ( t ) ) + ∑ i = 1 t Ω ( fi ) Obj^{(t)}=\sum_{i=1}^nl(y_i, \hat{y_i}^{(t)}) + \sum_{i=1}^t \Omega(f_i)O b j( t )=∑私は= 1nl ( y私、y私^( t ) )+∑私は= 1tああ( f私)
= ∑ i = 1 nl ( yi , yi ^ ( t − 1 ) + ft ( xi ) ) + Ω ( ft ) + const \text{ }\text{ }\text{ }\text{ }\text{ } \text{ }\text{ }\text{ }\text{ }\text{ }=\sum_{i=1}^nl(y_i, \hat{y_i}^{(t-1)} + f_t(x_i )) + \Omega(f_t) +const =∑私は= 1nl ( y私、y私^( t − 1 )+へt( ×私) )+ああ( ft)+定数_ _ _ _
目標損失関数が平均二乗誤差であると仮定すると、変換は次のようになります。
O bj ( t ) = ∑ i = 1 n ( yi − ( yi ^ ( t − 1 ) + ft ( xi ) ) ) 2 + Ω ( ft ) + const Obj^{(t)} = \sum_{i= 1}^n (y_i - (\hat{y_i}^{(t-1)} + f_t(x_i)))^2 + \Omega(f_t) + constO b j( t )=∑私は= 1n( _私−(y私^( t − 1 )+へt( ×私) ) )2+ああ( ft)+c o n s t
= ∑ i = 1 n [ 2 ( yi ^ ( t − 1 ) − yi ) ft ( xi ) + ft ( xi ) 2 ] + Ω ( ft ) + const \text{ }\text{ } \text{ }\text{ }\text{ }= \sum_{i=1}^n[2(\hat{y_i}^{(t-1)} - y_i)f_t(x_i) + f_t(x_i) ^2] + \Omega(f_t) + const =∑私は= 1n[ 2 (y私^( t − 1 )−y私) ft( ×私)+へt( ×私)2 ]+ああ( ft)+定数_ _ _ _
関数ft ( xi ) f_t(x_i)へt( ×私)与yi ^ ( t − 1 ) \hat{y_i}^{(t-1)}y私^( t − 1 )は関係ありません. 上記の目的関数の 2 番目のステップの変更では、式は個別のyi ^ ( t − 1 ) \hat{y_i}^{(t-1)} をy私^( t − 1 )項。以下は、テイラーの公式の原理に基づく GBDT 最適化のソリューションです。
4) テイラーの公式
テイラーの公式は、複雑な関数の性質を研究するためによく使用される近似法の 1 つであり、関数微分法の重要な応用内容でもあります。関数が特定の条件を満たす場合、テイラーの式は、関数を近似する多項式を構築するための係数として、特定の点での関数の微分値を使用できます。式の展開は次のとおりです
。 f(x) + f^{'}(x)\Delta x + \frac{1}{2}f^{''}(x)\Delta x^2f ( x+Δ x )≒f ( x )+へ' (x)Δx+21へ' ' (x)Δx2
5) 目的関数はテイラー展開で表される
次に目的関数をテイラー展開し、その解法は次のようになります。
O bj ( t ) = ∑ i = 1 nl ( yi , yi ^ ( t − 1 ) + ft ( xi ) ) + Ω ( ft ) + const Obj^{(t)} = \sum_{i=1}^nl(y_i,\hat{y_i}^{(t-1)} + f_t(x_i)) + \Omega(f_t) +定数O b j( t )=私は= 1∑nl ( y私、y私^( t − 1 )+へt( ×私) )+ああ( ft)+c o n s t
我们令:
gi = ∂ yi ^ ( t − 1 ) l ( yi , y ^ ( t − 1 ) ) g_i = \partial_{\hat{y_i}^{(t-1)}}l (y_i, \hat{y}^{(t-1)})g私=∂y私^( t − 1 )l ( y私、y^( t − 1 ) )
hi = ∂ yi ^ ( t − 1 ) 2 l ( yi , yi ^ ( t − 1 ) ) h_i = \partial_{\hat{y_i}^{(t-1)}}^2l (y_i, \hat{y_i}^{(t-1)})時間私=∂y私^( t − 1 )2l ( y私、y私^(t−1))
其中 g i g_i g私和 h i h_i 時間私目的関数を表すl ( yi , yi ^ ( t − 1 ) ) l(y_i, \hat{y_i}^{(t-1)})l ( y私、y私^( t − 1 ) )対y ^ ( t − 1 ) \hat{y}^{(t-1)}y^( t − 1 )の 1 次導関数と 2 次導関数したがって、目的関数のテイラー展開式は
次のようになります。 ft ) + const Obj^{(t)} \approx \sum_{i=1}^n[l(y_i, \hat{y_i}^{(t-1)}) + g_if_t(x_i) + \frac { 1}{2}h_if^2_t(x_i)] + \Omega(f_t) + constO b j( t )≒私は= 1∑n[ l ( y私、y私^( t − 1 ) )+g私へt( ×私)+21時間私へt2( ×私) ]+ああ( ft)+c o n s t
ターゲット損失関数が平均二乗誤差であると見なされる場合、gi g_ig私和 h i h_i 時間私计計算の結果:
gi = ∂ yi ^ ( t − 1 ) ( yi ^ ( t − 1 ) − yi ) 2 = 2 ( yi ^ ( t − 1 ) − yi ) g_i = \partial_{\hat{y_i}^ {(t-1)}}(\hat{y_i}^{(t-1)}-y_i)^2=2(\hat{y_i}^{(t-1)}-y_i)g私=∂y私^( t − 1 )(y私^( t − 1 )−y私)2=2 (y私^( t − 1 )−y私)
hi = ∂ yi ^ ( t − 1 ) 2 ( yi ^ ( t − 1 ) − yi ) 2 = 2 h_i = \partial_{\hat{y_i}^{(t-1)}}^2(\hat {y_i}^{(t-1)}-y_i)^2=2時間私=∂y私^( t − 1 )2(y私^( t − 1 )−y私)2=2したがって
、目的関数を
次のように解決します。 ) + const Obj^{(t)} \approx \sum_{i=1}^n[l(y_i, \hat{y_i}^{(t-1)}) + g_if_t(x_i) + \frac{ 1 }{2}h_if^2_t(x_i)] + \Omega(f_t) + constO b j( t )≒私は= 1∑n[ l ( y私、y私^( t − 1 ) )+g私へt( ×私)+21時間私へt2( ×私) ]+ああ( ft)+c o n s t
= ∑ i = 1 n [ 2 ( yi ^ ( t − 1 ) − yi ) ft ( xi ) + ft ( xi ) 2 ] + Ω ( ft ) + const = \sum_{i=1} ^n[2(\hat{y_i}^{(t-1)}-y_i)f_t(x_i) + f_t(x_i)^2]+ \Omega(f_t) + const=私は= 1∑n[ 2 (y私^( t − 1 )−y私) ft( ×私)+へt( ×私)2 ]+ああ( ft)+c o n s t
定数は目的関数の最適化に影響を与えないため、定数部分は削除され、次のようにさらに解決されます。 =
∑ i = 1 n [ gift ( xi ) + 1 2 shift 2 ( xi ) ] + Ω ( ft ) = \ sum_{i=1}^n[g_if_t(x_i) + \frac{1}{2}h_if^2_t(x_i)] + \Omega(f_t)=私は= 1∑n[ g私へt( ×私)+21時間私へt2( ×私) ]+ああ( ft)
其中 g i g_i g私和 h i h_i 時間私目的関数を表すl ( yi , yi ^ ( t − 1 ) ) l(y_i, \hat{y_i}^{(t-1)})l ( y私、y私^( t − 1 ) )対y ^ ( t − 1 ) \hat{y}^{(t-1)}y^( t − 1 )の 1 次導関数と 2 次導関数
6) 正規化項Ω ( ft ) \Omega(f_t)ああ( ft)
次に、目的関数の正則化項Ω ( ft ) \Omega(f_t)ああ( ft)はどのように表現するのですか? 最初に明確にする必要があるのは、正則化項の目的はモデルのオーバーフィッティングを防ぐことであるため、モデルが複雑になりすぎないようにする必要があるということです.ツリーモデル構造に基づいて、正則化式を定義できます.次のように: Ω ( ff ) = γ T + 1 2
λ ∑ j = 1 T wj 2 \Omega(f_f) = \gamma T + \frac{1}{2}\lambda \sum_{j=1}^Tw_j ^2ああ( ff)=γT _+21lj = 1∑Twj2
ここでTTT は葉ノードの数を表し、wj w_jwじjj番目を示しますjリーフ ノードのスコアは、正則化式の式から、正則化項により、ツリーにリーフ ノードが多くなりすぎず、リーフ ノードの値が大きくなりすぎないことがわかります。以下に示すように:
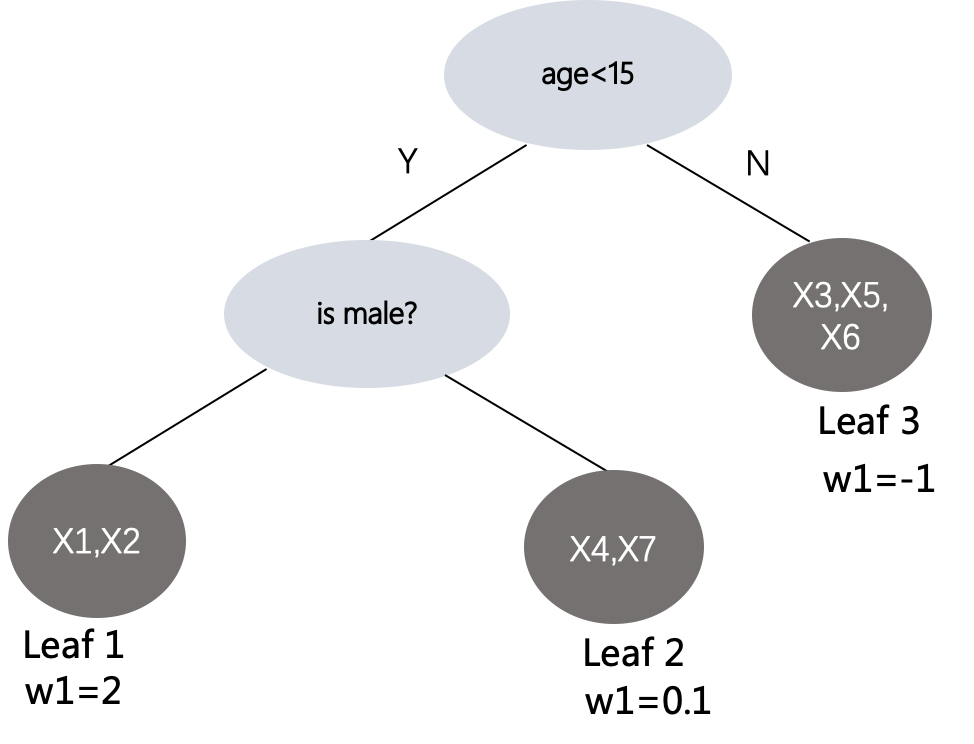
则 Ω \Omega Ωの計算結果γ 3 + 1 2 λ ( 4 + 0.01 + 1 ) \gamma^3 + \frac{1}{2}\lambda(4+0.01+1)c3+21l ( 4+0 . 0 1+1 )、前のターゲット損失関数では、ft ( x ) f_t(x)へt( x )はモデル結果の予測スコアです。次に、設定したツリー モデル構造に対して:
ft ( x ) = wq ( x ) f_t(x) = w_{q(x)}へt( × )=wq ( x )
其中w ∈ RT w \in \text{R}^TwεRTは T 次元のベクトルで、要素の各値は各リーフ ノードのスコアを表します。q ( x ) q(x)q ( x )は、サンプル x のマッピング関数であり、ツリー構造の特定のリーフ ノードがマッピングされます。正則化項とツリー モデル構造表現を上記の目的関数に組み込むと、
次のようになります。 ( t)} \approx \sum_{i=1}^n[g_if_t(x_i) + \frac{1}{2}h_if^2_t(x_i)] + \Omega(f_t)O b j( t )≒私は= 1∑n[ g私へt( ×私)+21時間私へt2( ×私) ]+ああ( ft)
= ∑ i = 1 n [ ギフト ( xi ) + 1 2 hift 2 ( xi ) ] + γ T + 1 2 λ ∑ j = 1 T wj 2 =\sum_{i=1}^n[g_if_t(x_i) + \frac{1}{2}h_if^2_t(x_i)] + \gamma T + \frac{1}{2}\lambda \sum_{j=1}^Tw_j^2=私は= 1∑n[ g私へt( ×私)+21時間私へt2( ×私) ]+γT _+21lj = 1∑Twj2
= ∑ j = 1 T [ ( ∑ i ∈ I jgi ) wj + 1 2 ( ∑ i ∈ I jhi + λ ) wj 2 ] + γ T = \sum_{j=1}^T[(\sum_{i \ in I_j}g_i)w_j+\frac{1}{2}(\sum_{i \in I_j}h_i + \lambda)w_j^2] + \gamma T=j = 1∑T[ (i ∈ Iじ∑g私) wじ+21(i ∈ Iじ∑時間私+l ) wj2]+γT _
定義:
G j = ∑ i ∈ I jgi G_j = \sum_{i \in I_j} g_iGじ=i ∈ Iじ∑g私
H j = ∑ i ∈ I jhi H_j = \sum_{i \in I_j} h_iHじ=i ∈ Iじ∑時間私
次に、上記の目的関数をさらに分解して取得します。
O bj ( t ) = ∑ j = 1 T [ ( ∑ i ∈ I jgi ) wj + 1 2 ( ∑ i ∈ I jhi + λ ) wj 2 ] + γ T Obj ^ {(t)}= \sum_{j=1}^T[(\sum_{i \in I_j}g_i)w_j+\frac{1}{2}(\sum_{i \in I_j}h_i + \lambda ) w_j^2] + \gamma TO b j( t )=j = 1∑T[ (i ∈ Iじ∑g私) wじ+21(i ∈ Iじ∑時間私+l ) wj2]+γ T
= ∑ j = 1 T [ G jwj + 1 2 ( H j + λ ) wj 2 ] + γ T =\sum_{j=1}^T[G_jw_j+\frac{1}{2}(H_j+\lambda )w_j^2]+\ガンマ T=j = 1∑T[ Gじwじ+21( Hじ+l ) wj2]+γT _
其中 w j w_j wじ上記の目標損失関数を最小化するために最適化したい値、つまりツリー構造の葉ノードの値です。 wj w_jwじ導関数を取り、結果を 0 に設定します:
∑ j = 1 T [ G j + ( H j + λ ) wj ] = 0 \sum_{j=1}^T[G_j+(H_j+\lambda)w_j]=0j = 1∑T[ Gじ+( Hじ+l ) wじ]=0
、次の値を取得できます:
wj ∗ = − G j H j + λ w_j^* = -\frac{G_j}{H_j+\lambda}wj∗=−Hじ+lGじな
wj ∗ w_j^*wj∗O bj ( t ) = − 1 2 ∑ j = 1 TG j 2 H j + λ + γ T Obj^{(t)} = -\ frac
{ 1}{2}\sum_{j=1}^T \frac{G_j^2}{H_j+\lambda} + \gamma TO b j( t )=−21j = 1∑THじ+lGj2な+γT _
最終的なターゲット損失関数式を取得します。解決したいのはgi g_iですg私和 h i h_i 時間私,どこでGj G_jGじおよびH j H_jHじ葉ノードjj をそれぞれ表すjのすべてのサンプルの一次導関数ggg分数と二次導関数hhhの分数の和. したがって、次の図に示すように、どのような種類の構造ツリーでも、サンプルが到着するリーフ ノードのターゲット損失関数値を計算できます。
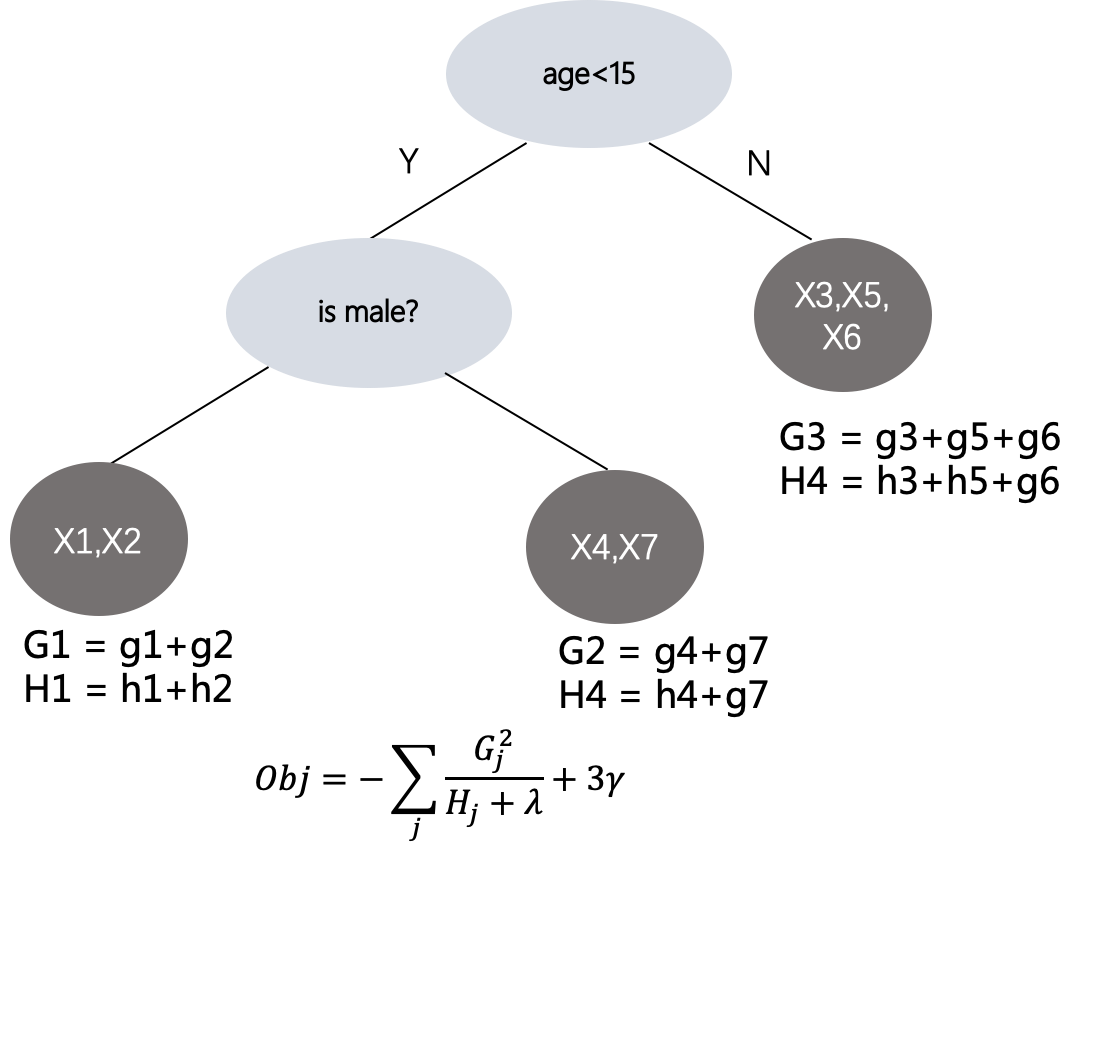
7) 木の最適分割構造の解き方
Obj を最小化するには、結合されたすべての分割ツリーを計算し、上記の式に従って各ツリーの目標損失値を計算し、最後に最小の損失値を持つツリー構造を選択する必要があります。これは可能ですか?すべてのツリー構造を網羅的に列挙すると、複雑さが高すぎるため、実現不可能です。では、ツリーの各レベルで必要ですか分割後の目標損失値が分割前の損失値よりも小さいかどうかに応じて、ノードを左ノードと右ノードに分割します、および分割する特徴点、分割しきい値に応じて、最大ゲインを選択し (ターゲット損失損失値は、新しく選択されたカット ポイントの後に最も低くなります)、分割ゲイン ゲインは次のように計算されます (切断前の損失 - 切断後の損失)。切断):
ゲイン = 1 2 [ GL 2 HL + λ + GR 2 HR − λ − ( GL + GR ) 2 HL + HR + λ ] − γ ゲイン = \frac{1}{2}[\frac{G_L^ 2}{H_L + \lambda} + \frac{G_R^2}{H_R - \lambda} - \frac{(G_L+G_R)^2}{H_L+H_R+\lambda}]-\ガンマガイン_ _ _=21[HL+lGL2な+HR−lGR2な−HL+HR+l( GL+GR)2]−γでは
、葉ノードを分割するかどうかは、上記の式により、利益収入が 0 より大きい場合は、引き続き分割できます。切り方については、gg を使用できます。gとhhhしてソートし、左から右にスキャンして最適なカット ポイントを選択します。
2.2 トレーニング
GBDT の原理に慣れたら、GBDT モデルがどのようにトレーニングされ、トレーニング後にどのようなモデル構造が得られるかを見てみましょう。
トレーニングステップ
平均二乗誤差損失関数を使用していると仮定すると、gbdt モデルのトレーニング手順は次のように要約されます。
- 最初のステップ (初期値の決定): 各サンプルの初期値モデル予測スコアは、すべてのサンプルの平均値です: f 0 ( xi ) = 1 n ∑ i = 1 nyi f_0(x_i)=\frac{1}{ n}\sum_{i=1}^n y_iへ0( ×私)=n1∑私は= 1ny私
- 2 番目のステップ (最初のツリーの構築): 各サンプルについて、前の予測結果に従ってyi ^ 0 = f 0 ( xi ) \hat{y_i}^0=f_0(x_i)y私^0=へ0( ×私)値と対応するラベル値yi y_iy私、前のステップでのモデルの予測値に対する目的関数を取得します一阶导数gi = 2 ( yi ^ 0 − yi ) g_i=2(\hat{y_i}^0-y_i)g私=2 (y私^0−y私)と二次導関数hi = 2 h_i=2時間私=2, そして、すべての機能タイプをトラバースし、各機能に対応する機能値の範囲. 分割後、分割前後のゲイン成長を計算し、最大の成長を持つ分割ポイントを選択し、ノードまで分割を続けます分割前と分割後 差が設定されたしきい値よりも小さいか、モデルの深さ、葉ノードの数などが設定されたしきい値を超えています。やっと、リーフ ノードの w 値は、上記の式に従って計算されます。: w = − G j H j + λ w= -\frac{G_j}{H_j+\lambda}w=−Hじ+ lGじな、ここでG j 、H j G_j、H_jGじ,ひじは、このリーフ ノードに分類されるすべてのサンプルの 1 次導関数の合計と 2 次導関数の合計です。これにより、サンプルを計算し、規則に従って分割し、どのリーフ ノードに分類するかを決定できます。関数f 1 ( xi ) f_1(x_i)へ1( ×私)。
- 3 番目のステップ (2 番目のツリーの構築): すべてのサンプルについて、前のすべてのツリーを通じて、セグメンテーション条件に従って、各ツリーのリーフ ノードに分類されるスコアの累積和が、現在のサンプルの予測スコアになります: yi ^ 1 = f 0 (xi) + f 1 (xi) \hat{y_i}^1=f_0(x_i)+f_1(x_i)y私^1=へ0( ×私)+へ1( ×私)、最初のツリー構築ルール プロセスに従って、2 番目のツリーの構築のために、各リーフ ノードのスコアf 2 ( xi ) f_2(x_i)へ2( ×私)
- 4 番目のステップ (3 番目のツリーの構築): すべてのサンプルは、以前に構築されたツリーを通過し、条件に従ってリーフ ノードに到達します。このときのサンプルの予測結果値は次のとおりです。 yi ^ 2 = f 0 ( xi ) + f 1 ( xi ) + f 2 ( xi ) \hat{y_i}^2 = f_0(x_i) + f_1(x_i) + f_2(x_i)y私^2=へ0( ×私)+へ1( ×私)+へ2( ×私),根据最新结果,然后计算每个样本的 g i , h i g_i,h_i gi,hi,选择增益最大的gain作为切分点。
- …
- 直到建树数量满足设置的阈值
模型结构
训练完后,就得到了N棵树,每一棵树的结构本质上是一连串的分段规则组成,根据输入样本的特征满足情况走树的不同分支,最后落入到树的某个叶子节点,其中落入到叶子节点的权重值就是这个样本在当前这课树的预测分值。
2.3 预测
当训练好了模型以后,预测的过程就简单了,假设有T棵树,则最终的模型预测结果为这个样本落入到每棵树的叶子节点分值之和,用公式表达如下:
y i ^ = ∑ j = 0 T f j ( x i ) \hat{y_i} = \sum_{j=0}^Tf_j(x_i) yi^=j=0∑Tfj(xi)
3 训练框架
接下来介绍优化Gradient Boosting算法的几种分布式训练框架,这些框架支持分布式训练,树的调优,缺失值处理,正则化等避免过拟合问题。
3.1 XGBoost
XGBoost: A Scalable Tree Boosting System 是由2014年5月,由DMLC开发出来的,目前是比较受欢迎,高效分布式训练Gradient Boosted Trees算法框架,包含的详细资料可以参考官方文档: 官网文档。
3.2 LightGBM
LightGBM: 非常に効率的な勾配ブースティング決定木2017 年 1 月の Microsoft TeamsXGBoost フレームワークに存在するいくつかの問題を目指して、より効率的な学習フレームワークが設計されています。勾配片側サンプリング GOSS ((Gradient Based One Side Sampling) および EFB をマージする相互に排他的な機能(専用機能バンドル) モデルの学習効率を高速化します. 詳細については、公式ドキュメント 公式サイトの. 以下は、lightgbm に基づくランク ソートの簡単なコードです。
import lightgbm as lgb
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
import seaborn as sns
import matplotlib.pyplot as plt
import seaborn as sns
import shap
import graphviz
#读取数据,显示前面20行
df = pd.read_csv('train.csv')
df.head(20)
#显示数据列名称
df.columns
#抽取x,y对应的字段
X = df.drop(['label','query','term'], axis=1)
y = df.label
group=np.loadtxt('./group.txt')
#训练数据
train_data = lgb.Dataset(X, label=y, group=group,free_raw_data=False)
#参数定义
params = {
'task' : 'train',
'boosting_type': 'gbdt',
'objective': 'lambdarank',
'num_iterations': 200,
'learning_rate':0.1,
'num_leaves': 31,
'tree_learner': 'serial',
'max_depth': 6,
'metric': 'ndcg',
'metric_freq': 10,
'train_metric':True,
'ndcg_at':[2],
'max_bin':255,
'max_position': 20,
'verbose':0
}
#指明类别特征
categorical_feature=[0,1]
#训练
gbm=lgb.train(params,
train_data,
valid_sets=train_data,
categorical_feature=categorical_feature)
#模型保存
gbm.save_model('model_large.md')
#预测
bst = lgb.Booster(model_file='model_large.md')
df_test = pd.read_csv('test.csv')
y_pred = bst.predict(test)
#feature重要度
fea_imp = pd.DataFrame({
'imp': bst.feature_importance(importance_type='split'), 'col': X.columns})
fea_imp = fea_imp.sort_values(['imp', 'col'], ascending=[True, False]).iloc[-30:]
fea_imp.plot(kind='barh', x='col', y='imp', figsize=(10, 7), legend=None)
plt.title('Feature Importance')
plt.ylabel('Features')
plt.xlabel('Importance');
# 基于shap特征分析
explainer = shap.TreeExplainer(bst)
shap_values = explainer.shap_values(X)
shap.summary_plot(shap_values, X, plot_type="bar")
shap.summary_plot(shap_values, X)
shap.dependence_plot('entropy', shap_values, X, interaction_index=None, show=True)
3.3 キャットブースト
CatBoost: カテゴリ機能を使用した偏りのないブースティング2017 年 4 月、ロシアの検索大手 Yandex がxgboostを最適化するためのフレームワークを開発.このフレームワークの最大の利点は,カテゴリ特徴量を扱えることである.LightGBMと比較して,カテゴリ特徴量のラベルエンコーディングが不要であり,ユーザーが迅速に操作するのに便利である. 詳細な公式ウェブサイト:公式ウェブサイト, 以下は 3 つの詳細な比較表です:
トレーニング ロスの比較:
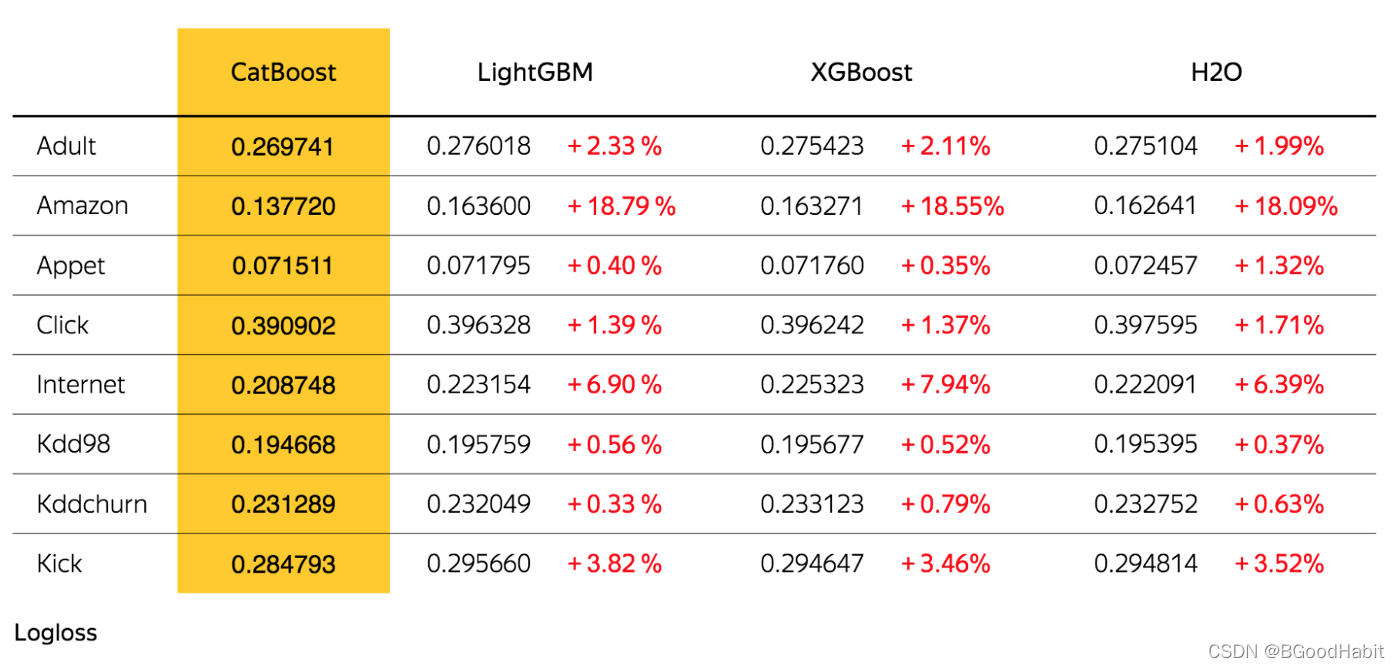
モデルのパフォーマンスの比較: 左が CPU マシン、右が GPU マシンです
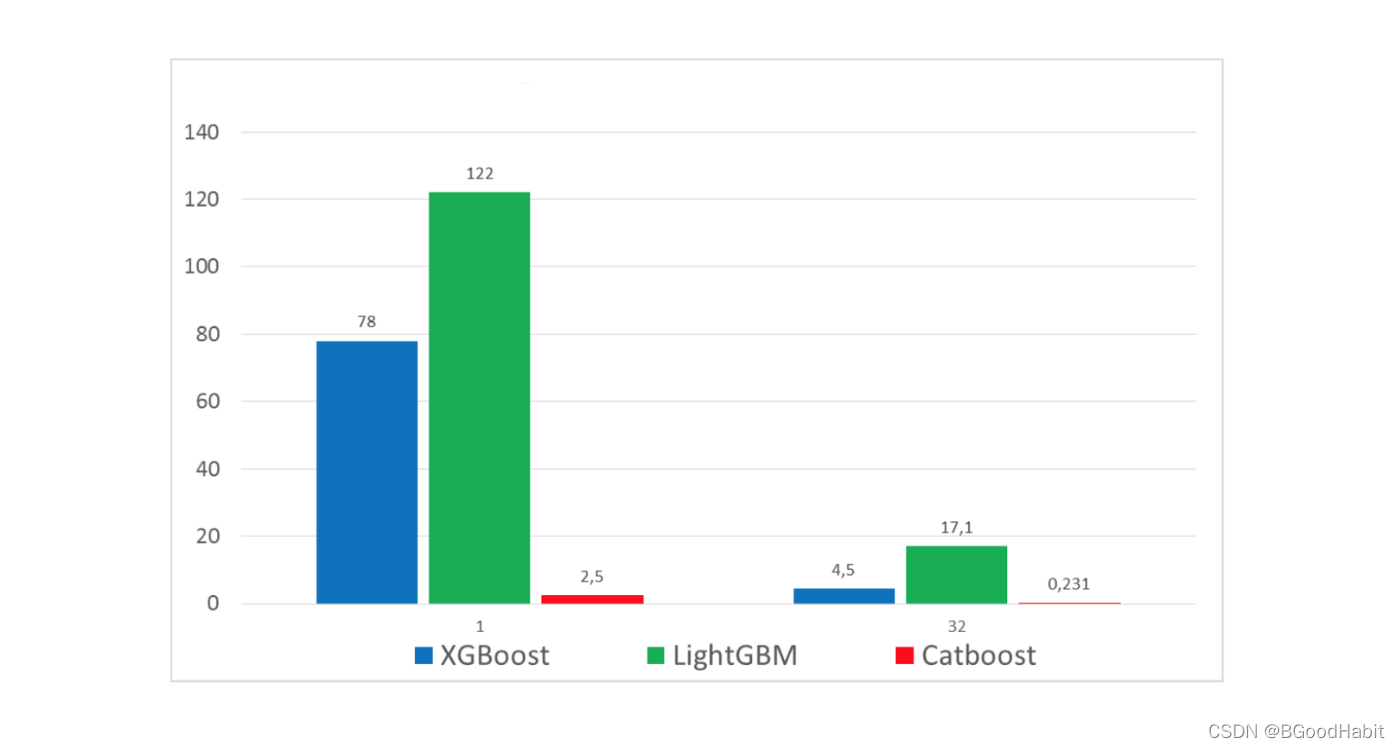
。 XGBoost や LightGBM と比較して、指数収束効果が確実に向上 の条件下で、モデルのパフォーマンスが大幅に向上しました。以下は、Catboost に基づくトレーニングの簡単なコード例です。
import numpy as np
import pandas as pd
import os
from sklearn.metrics import mean_squared_error
from sklearn import feature_selection
from catboost import CatBoostClassifier
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
import seaborn as sns
import matplotlib.pyplot as plt
#读取数据
df = pd.read_csv('data.csv')
df.head()
#显示特征名
df.columns
#显示某个特征名的数据情况
pd.set_option('display.float_format', '{:.2f}'.format)
df.f_ctf.describe()
#特征分布显示
plt.figure(figsize = (10, 4))
plt.scatter(range(df.shape[0]), np.sort(df['f_ctf'].values))
plt.xlabel('index')
plt.ylabel('f_ctf')
plt.title("f_ctf Distribution")
plt.show();
#训练样本划分
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.20, random_state=42)
#指明categorical特征
categorical_features_indices=[1,2,3]
#模型训练
model = CatBoostClassifier(iterations=700,
learning_rate=0.01,
depth=15,
eval_metric='AUC',
random_seed = 42,
bagging_temperature = 0.2,
od_type='Iter',
metric_period = 75,
loss_function='Logloss',
od_wait=100)
model.fit(X_train, y_train,
eval_set=(X_valid, y_valid),
cat_features=categorical_features_indices,
use_best_model=True,
plot=True)
#特征重要度显示
fea_imp = pd.DataFrame({
'imp': model.feature_importances_, 'col': X.columns})
fea_imp = fea_imp.sort_values(['imp', 'col'], ascending=[True,False]).iloc[-30:]
fea_imp.plot(kind='barh', x='col', y='imp', figsize=(10, 7), legend=None)
plt.title('CatBoost - Feature Importance')
plt.ylabel('Features')
plt.xlabel('Importance');
3.4 NGブースト
NGBoost: 確率的予測のための自然勾配ブースティングは、比較的新しいトレーニング勾配ブースティング アルゴリズム フレームワークです。で2019 年 10 月、スタンフォード大学の Andrew Ng のチームによる公開。github コードは次の場所に記録されています: NGBoost Github、コア ポイントは確率的予測のためのモジュラー ブースティング アルゴリズムである自然勾配ブースティングを使用します。. アルゴリズムは、基本学習器、パラメータ確率分布、およびスコアリング ルールで構成されます。
4 ツリーモデルと深度モデルの組み合わせ
ツリー モデルは解釈可能性と安定性に優れていますが、意味的な特徴がなく、汎化能力が十分でないという欠点があるため、実際のシナリオでは、ツリー モデルをディープ ラーニング モデルと組み合わせることができます。単純平均は改善する必要がある. これは効果を比較するための簡単な実験である. bertモデルはgbdtモデルと比較して感情分類タスクに一定の改善があります. ただし, bertとgbdtの結果を組み合わせて単純に計算する.平均値が最も効果的です. 詳細は誰かが作成したものを参照してください. 単純な比較テスト: bert vs catboost