下のカードをクリックして、「CVer」公式アカウントをフォローしてください
AI/CV 重乾物、初回配送
クリックして入力 —>【画像セグメンテーション】WeChat Technology Exchange Group
転載元: Heart of the Machine
ChatGPT は大規模な言語モデルの熱狂を引き起こしました.AI のもう 1 つの主要な分野であるビジョンの GPT の瞬間はいつ来るのでしょうか?
2 日前、マシンの心臓部は Meta の最新の研究成果である Segment Anything Model (SAM)を導入しました。この研究は、AI コミュニティで広範な議論を巻き起こしました。
私たちが知る限り、ほぼ同時に、Zhiyuan Research Institute のビジョン チームは、一般的なセグメンテーション モデル SegGPT (Segment Everything In Context) も開始しました。これは、視覚プロンプトを使用して任意のセグメンテーション タスクを完了する一般的なビジョン モデルです。

SegGPT: コンテキスト内ですべてをセグメント化する
論文アドレス: https://arxiv.org/abs/2304.03284
コードアドレス: https://github.com/baaivision/Painter
デモ:https://huggingface.co/spaces/BAAI/SegGPT
SegGPT と、Meta AI 画像セグメンテーションの基本モデルである SAM が同時にリリースされました. 両者の違いは次のとおりです。
SegGPT の「万能型」: 1 つまたは複数のサンプル画像とインテント マスクが与えられると、モデルはユーザーのインテントを取得し、「サンプルから学習」して同様のセグメンテーション タスクを完了することができます。ユーザーは、画面上のオブジェクトのクラスをマークして認識し、現在の画面または他の画面またはビデオ環境にあるかどうかにかかわらず、同様のオブジェクトをバッチで識別してセグメント化できます。
SAM「ワンタッチ」: ポイントまたはバウンディング ボックスを介して、予測する画像にインタラクティブなプロンプトが表示され、分割画面上の指定されたオブジェクトが認識されます。
「ワンタッチ」でも「ワンストップ」でも、ビジュアルモデルがイメージ構造を「理解」したということです。SAM の細かいラベリング機能と SegGPT の一般的なセグメンテーションおよびラベリング機能を組み合わせることで、ピクセル配列から視覚的な構造単位に画像を解析し、生物の視覚のようにあらゆるシーンを理解できます. 一般的な視覚 GPT の夜明けが近づいています.
SegGPT は、Zhiyuan の一般的な視覚モデル Painter (CVPR 2023) の派生モデルであり、すべてのオブジェクトをセグメント化するという目標のために最適化されています。SegGPT トレーニングが完了したら、微調整の必要はありません. 例を提供するだけで、画像や動画のインスタンス、カテゴリ、パーツ、輪郭、テキスト、顔などを含む、対応するセグメンテーション タスクを自動的に推論して完了することができます.
このモデルには、次の有利な機能があります。
1. 一般的な機能: SegGPT にはコンテキスト推論機能があり、モデルは提供されたセグメンテーションの例 (プロンプト) に従って予測を適応的に調整し、インスタンス、カテゴリ、パーツ、輪郭、テキスト、人間の顔など、「すべて」のセグメンテーションを実現できます。 、医用画像、リモートセンシング画像など
2. 柔軟な推論能力: 任意の数のプロンプトをサポートします; 特定のシナリオに合わせて調整されたプロンプトをサポートします; 異なる色のマスクを使用して異なるターゲットを表し、並列セグメンテーション推論を実現できます.
3. 自動ビデオ セグメンテーションおよび追跡機能:最初のフレーム画像と対応するオブジェクト マスクをコンテキストの例として取り上げると、SegGPT は後続のビデオ フレームを自動的にセグメント化し、マスクの色をオブジェクト ID として使用して自動追跡を実現できます。
ケースプレゼンテーション
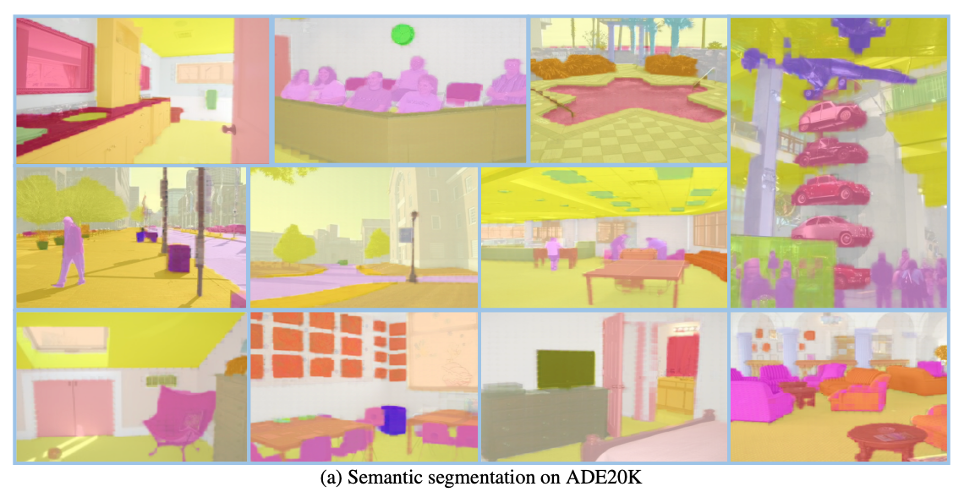
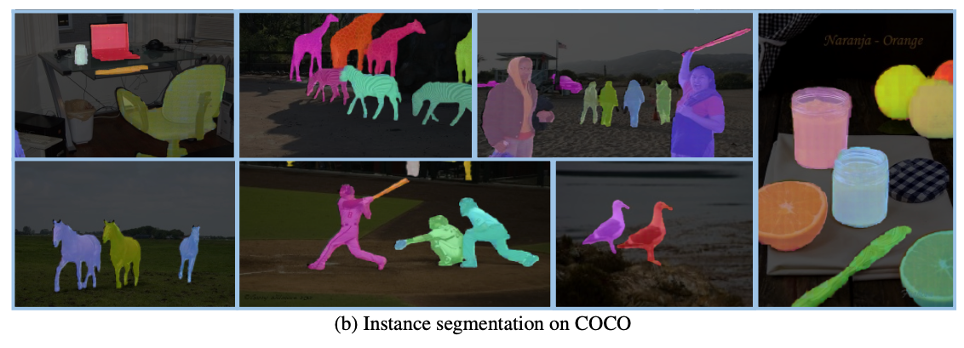
1. 著者は、少数ショット セマンティック セグメンテーション、ビデオ オブジェクト セグメンテーション、セマンティック セグメンテーション、パノラマ セグメンテーションなど、幅広いタスクで SegGPT を評価します。以下の図は、インスタンス、カテゴリ、パーツ、輪郭、テキスト、および任意の形状のオブジェクトに対する SegGPT のセグメンテーション結果を具体的に示しています。

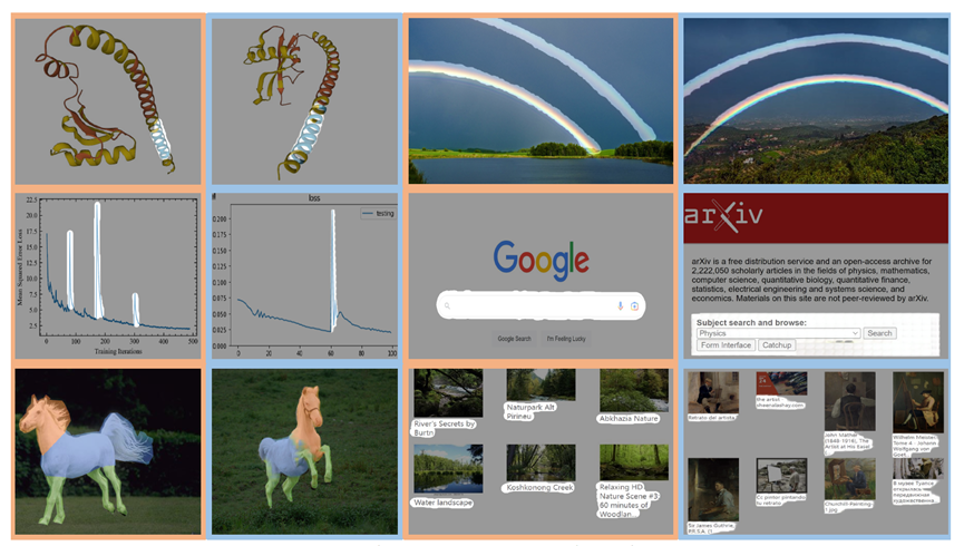
2. 1 つの画像 (上の画像) で虹をマークし、他の画像 (下の画像) で虹をバッチ分割できます。

3. ブラシを使用して惑星リング ベルトを大まかに一周し (上図)、予測マップのターゲット イメージ (下図) に正確に惑星リング ベルトを出力します。


4. SegGPT は、ユーザーから提供された宇宙飛行士のヘルメット マスク (左の図) のコンテキストに基づいて、新しい画像で対応する宇宙飛行士のヘルメット エリア (右の図) を予測できます。

トレーニング方法
SegGPT は、さまざまなセグメンテーション タスクを一般的な文脈学習フレームワークに統合し、さまざまなセグメンテーション データを同じ形式の画像に変換することで、さまざまなデータ形式を統合します。
具体的には、SegGPT のトレーニングは、データ サンプルごとにランダムなカラー マップを使用したコンテキスト カラーリング問題として定式化されます。目標は、特定の色に依存するのではなく、コンテキストに従ってさまざまなタスクを実行することです。トレーニング後、SegGPT は、コンテキスト推論を通じて、インスタンス、カテゴリ、パーツ、輪郭、テキストなどの画像またはビデオで任意のセグメンテーション タスクを実行できます。

テスト時のテクニック
試練の技で様々な能力を解き放つ方法が一般モデルの見どころです。SegGPT の論文では、下図に示すさまざまなコンテキスト アンサンブル手法など、さまざまなセグメンテーション機能のロックを解除して強化するための複数のテクノロジが提案されています。提案された Feature Ensemble メソッドは、豊富で倹約的な推論効果を達成するために、任意の数の迅速な例をサポートできます。

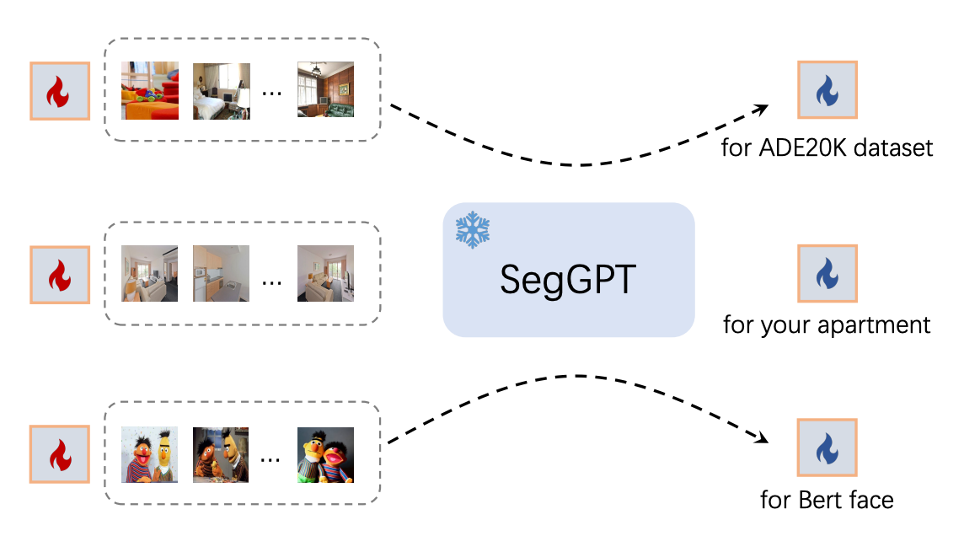
さらに、SegGPT は、特定のシナリオを最適化するための特別なプロンプトもサポートしています。対象を絞った使用シナリオの場合、SegGPT は、特定のシナリオに適用するためにモデル パラメーターを更新することなく、プロンプト チューニングを通じて対応するプロンプトを取得できます。たとえば、特定のデータ セットに対応するプロンプトを自動的に作成したり、ルーム専用のプロンプトを作成したりします。以下に示すように:
結果表示
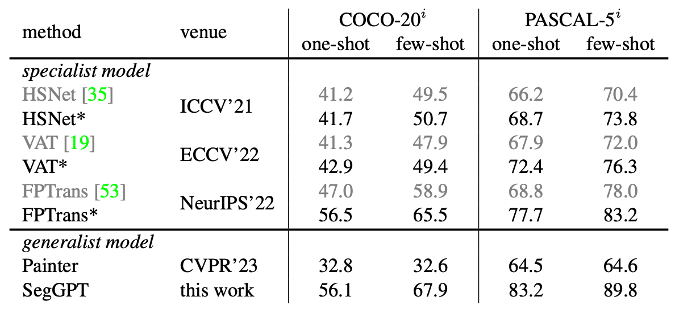
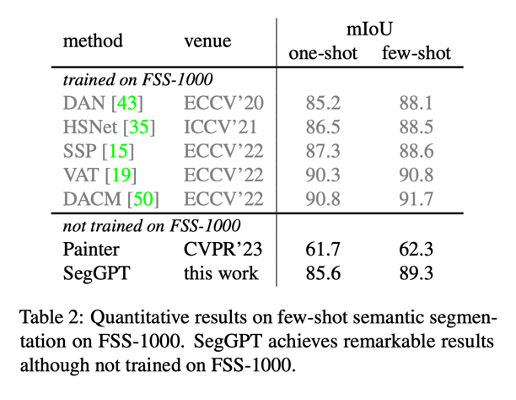
このモデルは、いくつかの迅速な例のみを必要とし、COCO および PASCAL データセットで最先端のパフォーマンスを実現します。SegGPT は、少数ショット セマンティック セグメンテーション テスト セット FSS-1000 でのトレーニングなしで最先端のパフォーマンスを達成するなど、強力なゼロ ショット シーン転送機能を示しています。
ビデオ トレーニング データがなくても、SegGPT はビデオ オブジェクトのセグメンテーションを直接実行し、ビデオ オブジェクトのセグメンテーション用に最適化されたモデルと同等のパフォーマンスを実現できます。
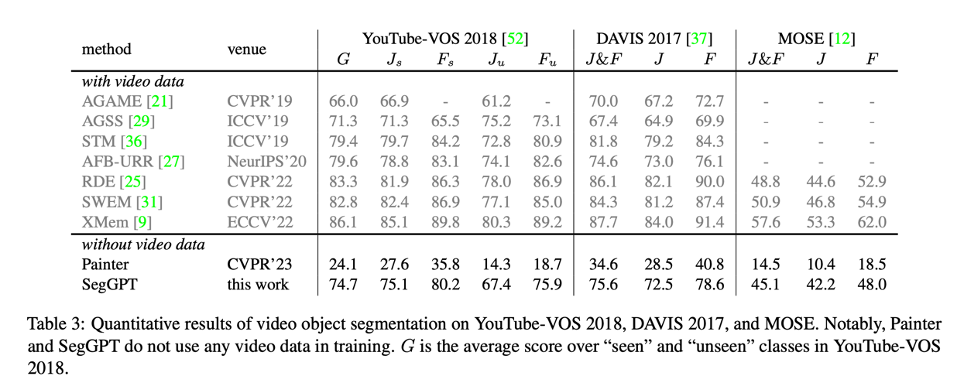
以下は、セマンティック セグメンテーションおよびインスタンス セグメンテーション タスクでの調整されたプロンプトのパフォーマンスに基づいています。
クリックして入力 —>【画像セグメンテーション】WeChat Technology Exchange Group
最新の CVPP 2023 論文とコードのダウンロード
背景の返信: CVPR2023。CVPR 2023 の論文とコード オープン ソースの論文のコレクションをダウンロードできます。
バックグラウンドでの返信: Transformer レビュー、最新の 3 つの Transformer レビュー PDF をダウンロードできます
图像分割和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-图像分割或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如图像分割或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看