Fengse は凹形の non-si qubit から送信されます
| パブリック アカウント QbitAI
最後に、清華大学のTang Jie のチームも動きました。
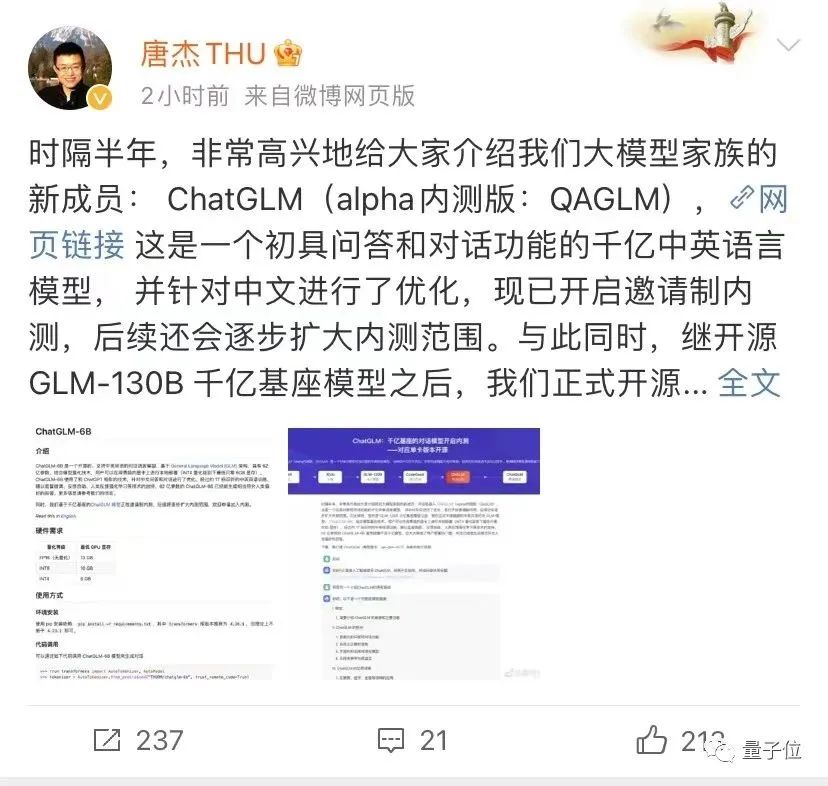
GPT4 がリリースされた同じ日に、Tang 教授は Weibo で次のように発表しました。
数千億のパラメーターを持つ大規模モデルに基づく対話ロボットである ChatGLM は、現在、招待による内部テスト用に公開されています。
報告によると、ChatGLMは特に中国人向けに最適化されており、中国人に優しいと言えます〜
ブログのアウトラインを書いたり、スクリプトを作成したり、数学の問題を解いたり、コードを書いたり、 Gao Leng Yujie の役を演じたりすることも得意なようです。
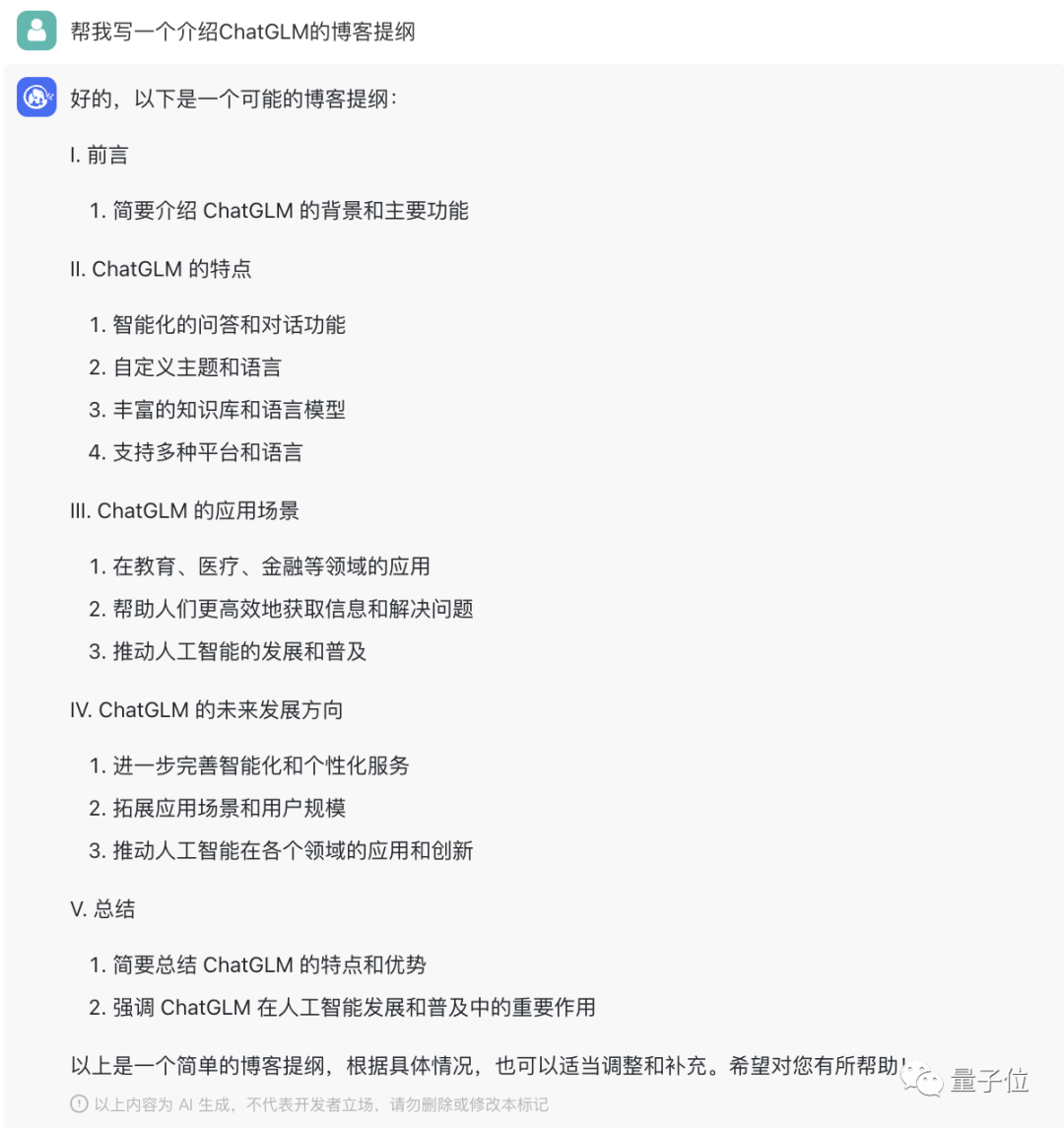
△ChatGLMを紹介するブログ概要を書く

△ガオ・レン・ユジエとしてのコスプレチャット
Qubit は幸運にも内部テスト クォータを取得でき、後で実際のテストの波を実施します。
そんな中、次の発表がありました。
コミュニティと共に大規模モデル技術の開発を促進するために、Tang Jie のチームは、62 億のパラメーターを含むバイリンガルのChatGLM-6Bモデルもオープンソース化しました。
その最大の特徴は、 2080Tiさえあれば普通のパソコンに展開できることです。
見てみましょう。
古典的な中国語でスピーチを書くことはできますが、何玉明の最新ニュースを知っていますが...
最初に ChatGLM を見てみましょう。半年後に誕生した Tang Jie の大規模なモデル ファミリーの新しいメンバーです。
アルファ版は QAGLM (フルネーム qa-glm-v0.7) と呼ばれます。

効果をお試しください。
まず、ChatGPT との違いについて説明しましょう。

独自の研究開発機関や、中国語が得意な特徴を指摘。
次に、古典的な中国語で感謝の言葉を書きましょう。

なんと言うか、余分な「ゆ」と訳の分からない繁体字があるものの、それでも読み応えがあり、対訳文が使われていることで勢いが増している。
そして、数日前のシリコンバレーのThunderの記事の冒頭部分を流用して、タイトルをつけました。
かなり良い感じです。少なくともいくつかの重要な情報が取得されました。

残念ながら、論文の課題は合格しませんでした。トピックを簡単に要約するために GLM-130B へのリンクを投げたとき、それはこれをまったく言っていませんでした.
ChatGPT Hu Zouさんのリファレンス(手動犬頭)の動作とほぼ同じです。

次に、その数学的能力をテストします。
この小学校の単語問題は問題ありません。

でもニワトリとウサギは同じ檻にいるから難しくて、結局負の数まで計算してしまう==

プログラミングに関しては、単純なアルゴリズムの問題も解決できます。
情報を要約する能力はどうですか?英語で要件を提示しましたが、難しくありません。
結果は正しいです:

現在、ChatGLM は各ラウンドで最大 5 ラウンドの対話しか実行できず、各ラウンドで最大 1,000 語を入力できることに注意してください。
新しい情報をよく把握しており、現在の Twitter の CEO が Musk であること、そして He Yuming が 3 月 10 日に学界に戻ったことも知っていますが、GPT-4 がリリースされたことはまだ発見されていません。

そして、現在の応答速度は依然として非常に速く、何の問題であっても、正解か不正解かを問わず、数秒以内に答えを出すことができます。
最後に、Qubit にはコスプレをさせて、ガールフレンドをなだめるのがどれほど良いかを確認します。

ええと、私は少し直立していましたが、この一節を聞いた後、「私」は本当に怒りを失いました。
では、上記は私たちのテスト結果ですが、どう思いますか?
1,300 億のパラメータを持つ基本モデルに基づく
公式イントロダクションによると、ChatGLMはChatGPTの設計思想を参考に、 1000億のベースモデルGLM-130Bにコードプレトレーニングを注入し、教師あり微調整などの技術(つまり、機械の答えを人間の価値観、人間の期待に適合させる)。
このGLM-130Bの背景は語る価値があります。
これは、清華大学の知識工学研究所 (KEG) と Zhipu AI によって共同開発された大規模な中国語と英語の事前トレーニング言語モデルであり、1,300 億のパラメーターを持ち、昨年 8 月に正式にリリースされました。
BERT、GPT-3、および T5 のアーキテクチャとは異なり、GLM-130B は、複数の目的関数を含む自己回帰事前トレーニング モデルです。
その利点は次のとおりです。

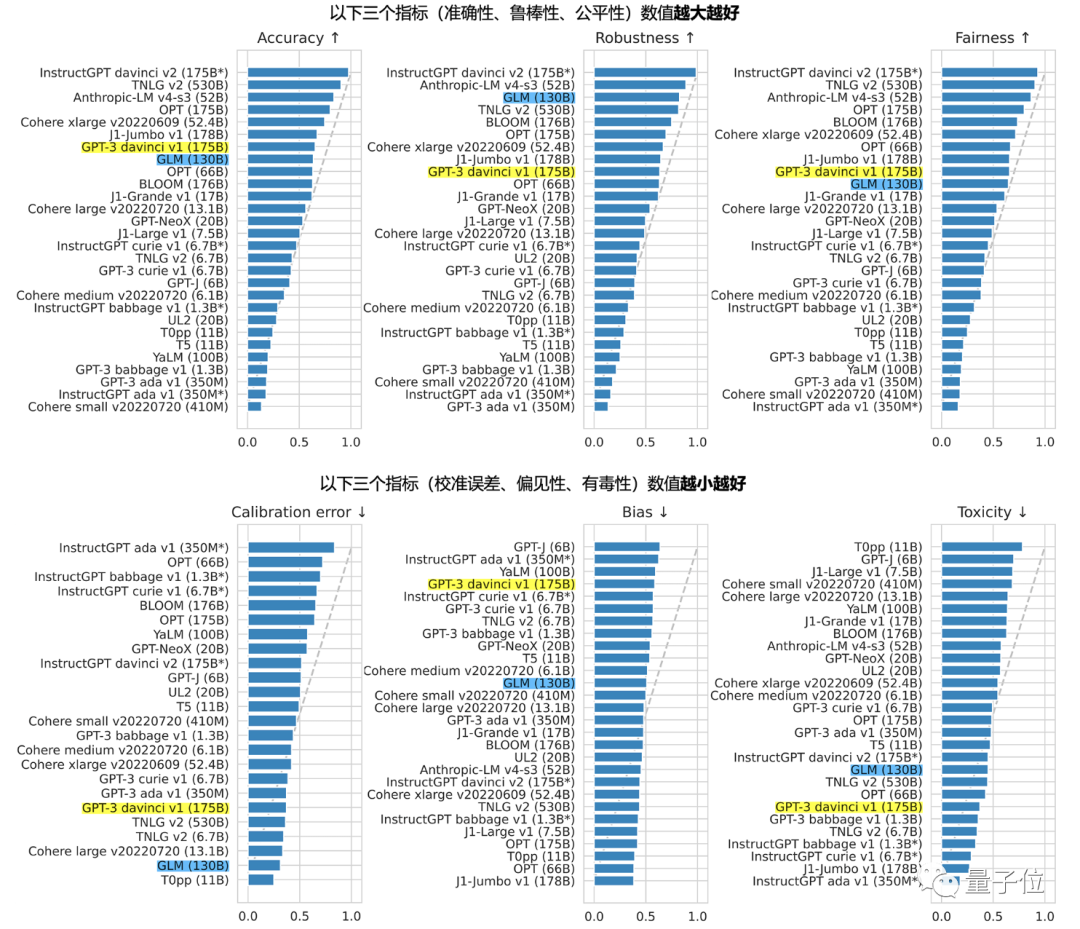
スタンフォードが報告した30の世界主流の大規模モデル評価の中で、GLM-130Bはアジアで唯一選ばれたモデルにもなりました。
そして良い結果を得ました:
たとえば、精度と悪意の指標の点で GPT-3 175B (davinci) に近いか同等であり、堅牢性とキャリブレーション エラーは、1000 億規模のすべての台座モデルで (公正な比較として、罰金のみ) -指示プロンプトのないチューニングモデルを比較)それも顕著です。
また、CCF の最近の会議で、聴衆は次のように尋ねました。ChatGPT はなぜ中国で生まれなかったのですか? この問題に注意を払わなかったということですか?
ゲストはGLM-130Bを動かしました(ICLR'23にも選ばれました)。
いよいよGLM-130Bが「大活躍」することになりました。
内部テストに関して、Tang Jie のチームは、範囲は将来的に徐々に拡大され、興味のある友人はしばらく待つことができると述べました。
60億個のパラメータの縮小版もオープンソース
このチャット ロボット ChatGLM に加えて、Tang Jie のチームは今回、GLM-130B の「縮小版」 ChatGLM-6Bもオープンソース化しました。
△ GitHub は 2,000 個近くの星を獲得しました
ChatGLM-6B は、ChatGLM と同じ技術を使用しており、中国語の質疑応答と対話機能を備えています。
機能は次のとおりです。

もちろんデメリットとしては、容量が60億しかないこと、モデル記憶力や語学力が弱いこと、論理的な問題(数学、プログラミングなど)が苦手なこと、対話を何度も繰り返すと文脈の喪失や誤解が生じる可能性があることです。
しかし、その主な機能は、単一の 2080Ti での推論に使用できる低いしきい値であり、ハードウェア要件は高くありません。
したがって、興味がある限り、研究用と(非商用の)アプリケーション開発用の両方で、ダウンロードして試してみることができます。
ポータル:
https://chatglm.cn/
https://github.com/THUDM/ChatGLM-6B
参照リンク:
[1]https://weibo.com/2126427211/MxlsQ6w4A#repost
[2]https://chatglm.cn/blog?continueFlag=d70d7590143c950d12ac7283214d879d
—終わり— _ _