Article directory
13. The principle of MapReduce framework
13.3Shuffle mechanism
13.3.2Partition partition
13.3.2.3 Custom Partitioner Steps
13.3.2.3.1 The custom class inherits Partitioner and overrides the getPartition() method
public class CustomPartitioner extends Partitioner<Text, FlowBean> {
@Override
public int getPartition(Text key, FlowBean value, int numPartitions) {
// 控制分区代码逻辑
… …
return partition;
}
}
13.3.2.3.2 In the Job driver, set a custom Partitioner
job.setPartitionerClass(CustomPartitioner.class);
13.3.2.3.3 After customizing the Partition, set the corresponding number of ReduceTasks according to the logic of the custom Partitioner
job.setNumReduceTasks(5);
13.3.2.4 Partition Summary
(1) If the number of ReduceTasks > the number of results of getPartition, several more empty output files part-r-000xx will be generated;
(2) If 1 < the number of ReduceTasks < the number of results of getPartition, some partition data will not be available. (3) If the number of ReduceTasks
= 1, no matter how many partition files are output from the MapTask side, the final result will be handed over to this ReduceTask, and only one result file part-r-00000 will be generated in the end;
(4) The partition number must start from zero and accumulate one by one.
13.3.2.5 Case Study
For example: Assuming that the number of custom partitions is 5,
(1) job.setNumReduceTasks(1); will run normally, but an output file will be generated
(2) job.setNumReduceTasks(2); will report an error
(3) job.setNumReduceTasks (6); greater than 5, the program will run normally, and an empty file will be generated
13.3.3 Partition Partition Case Practice
13.3.3.1 Requirements
Output the statistical results to different files (divisions) according to the different provinces where the mobile phone belongs
(1) Input data
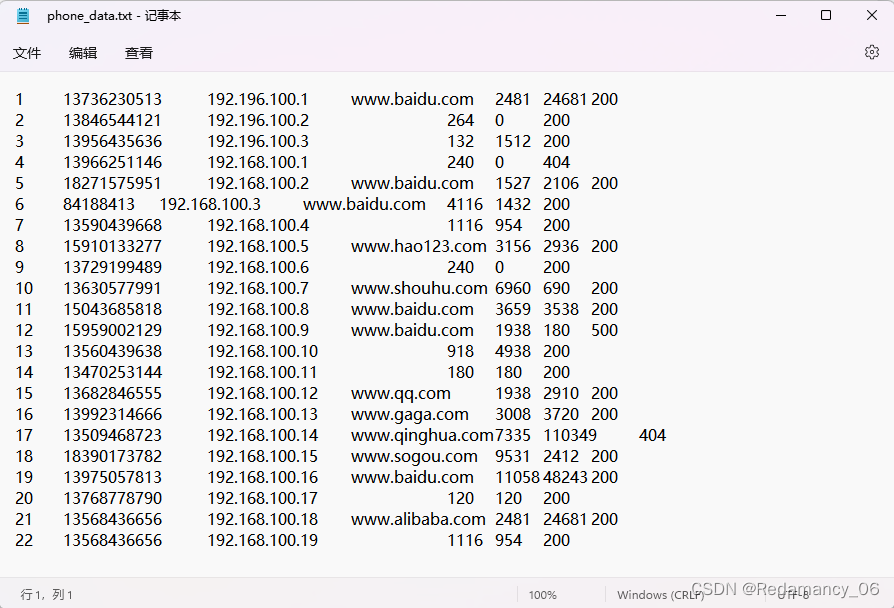
1 13736230513 192.196.100.1 www.baidu.com 2481 24681 200
2 13846544121 192.196.100.2 264 0 200
3 13956435636 192.196.100.3 132 1512 200
4 13966251146 192.168.100.1 240 0 404
5 18271575951 192.168.100.2 www.baidu.com 1527 2106 200
6 84188413 192.168.100.3 www.baidu.com 4116 1432 200
7 13590439668 192.168.100.4 1116 954 200
8 15910133277 192.168.100.5 www.hao123.com 3156 2936 200
9 13729199489 192.168.100.6 240 0 200
10 13630577991 192.168.100.7 www.shouhu.com 6960 690 200
11 15043685818 192.168.100.8 www.baidu.com 3659 3538 200
12 15959002129 192.168.100.9 www.baidu.com 1938 180 500
13 13560439638 192.168.100.10 918 4938 200
14 13470253144 192.168.100.11 180 180 200
15 13682846555 192.168.100.12 www.qq.com 1938 2910 200
16 13992314666 192.168.100.13 www.gaga.com 3008 3720 200
17 13509468723 192.168.100.14 www.qinghua.com 7335 110349 404
18 18390173782 192.168.100.15 www.sogou.com 9531 2412 200
19 13975057813 192.168.100.16 www.baidu.com 11058 48243 200
20 13768778790 192.168.100.17 120 120 200
21 13568436656 192.168.100.18 www.alibaba.com 2481 24681 200
22 13568436656 192.168.100.19 1116 954 200
(2) Expected output data
Mobile phone numbers 136, 137, 138, 139 are placed in a separate 4 files at the beginning, and other beginnings are placed in one file
13.3.3.2 Requirements Analysis
1. Demand: output the statistical results to different files (partitions) according to the different provinces where the mobile phone belongs.
2. Data input
13630577991 6960 690
13736230513 2481 24681
13846544121 264 0
13956435636 132 1512
13560439638 918 4938
3. Expected data output
file 1
file 2
file 3
file 4
file 5
4. Add a ProvincePartitioner partition
136 partition 0
137 partition 1
138 partition 2
139 partition 3
other partition 4
5. Driver driver class
//Specify the custom data partition
job.setPartitionerClass (ProvincePartitioner.class);
//Specify the corresponding number of reduceTasks at the same time
job.setNumReduceTasks (5);
13.3.3.3 Partition Partition Case Demonstration
 Create a partitioner2 folder and copy the 4 java codes in the writable to partitioner2 at the same time
Create a partitioner2 folder and copy the 4 java codes in the writable to partitioner2 at the same time
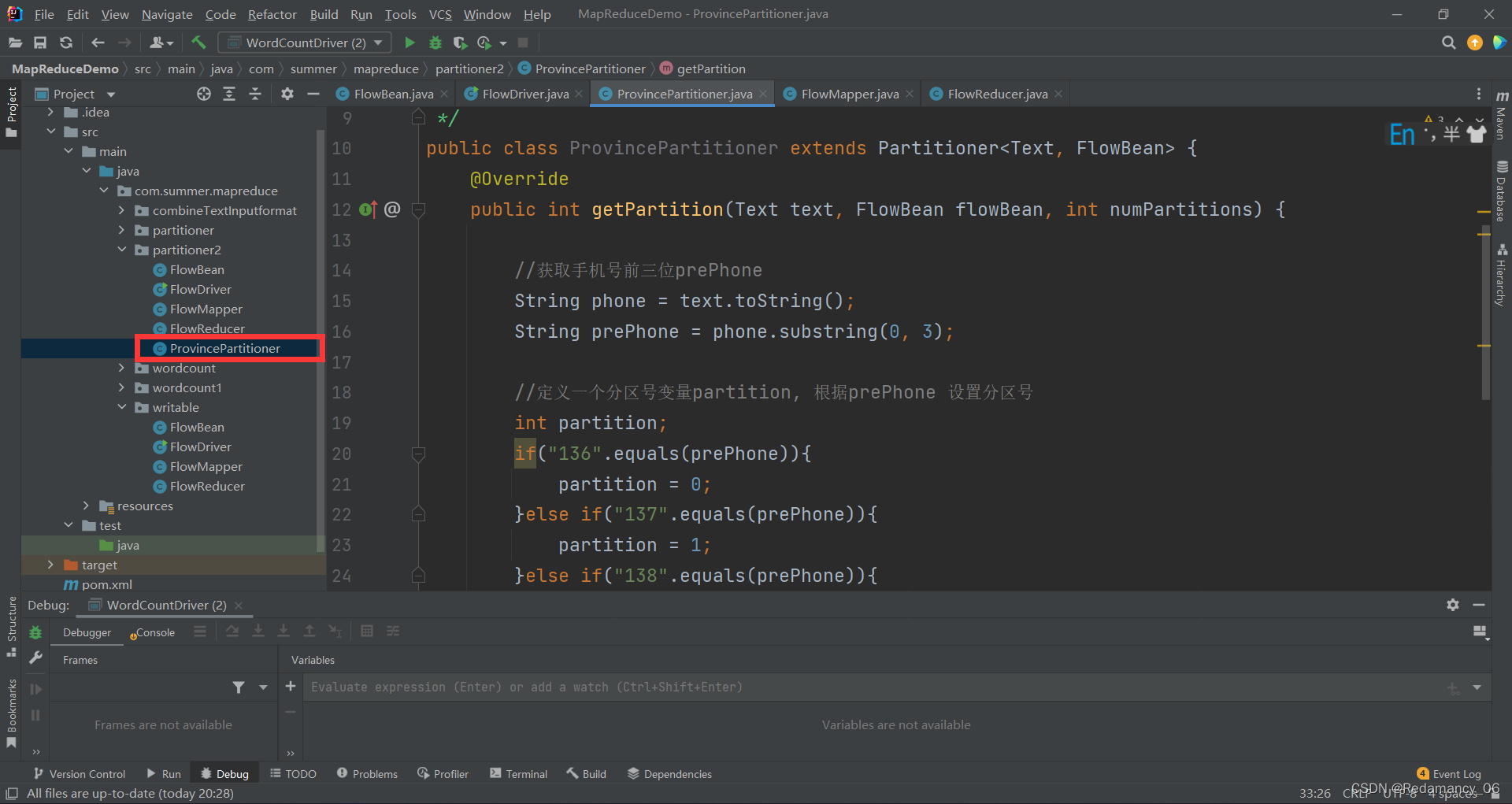
On the basis of the case writable, add a partition class
package com.summer.mapreduce.partitioner;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class ProvincePartitioner extends Partitioner<Text, FlowBean> {
@Override
public int getPartition(Text text, FlowBean flowBean, int numPartitions) {
//获取手机号前三位prePhone
String phone = text.toString();
String prePhone = phone.substring(0, 3);
//定义一个分区号变量partition,根据prePhone设置分区号
int partition;
if("136".equals(prePhone)){
partition = 0;
}else if("137".equals(prePhone)){
partition = 1;
}else if("138".equals(prePhone)){
partition = 2;
}else if("139".equals(prePhone)){
partition = 3;
}else {
partition = 4;
}
//最后返回分区号partition
return partition;
}
}

Add custom data partition settings and ReduceTask settings in the driver function
package com.summer.mapreduce.partitioner;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FlowDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1 获取job对象
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2 关联本Driver类
job.setJarByClass(FlowDriver.class);
//3 关联Mapper和Reducer
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReducer.class);
//4 设置Map端输出数据的KV类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
//5 设置程序最终输出的KV类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
//8 指定自定义分区器
job.setPartitionerClass(ProvincePartitioner.class);
//9 同时指定相应数量的ReduceTask
job.setNumReduceTasks(5);
//6 设置输入输出路径
FileInputFormat.setInputPaths(job, new Path("D:\\inputflow"));
FileOutputFormat.setOutputPath(job, new Path("D\\partitionout"));
//7 提交Job
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
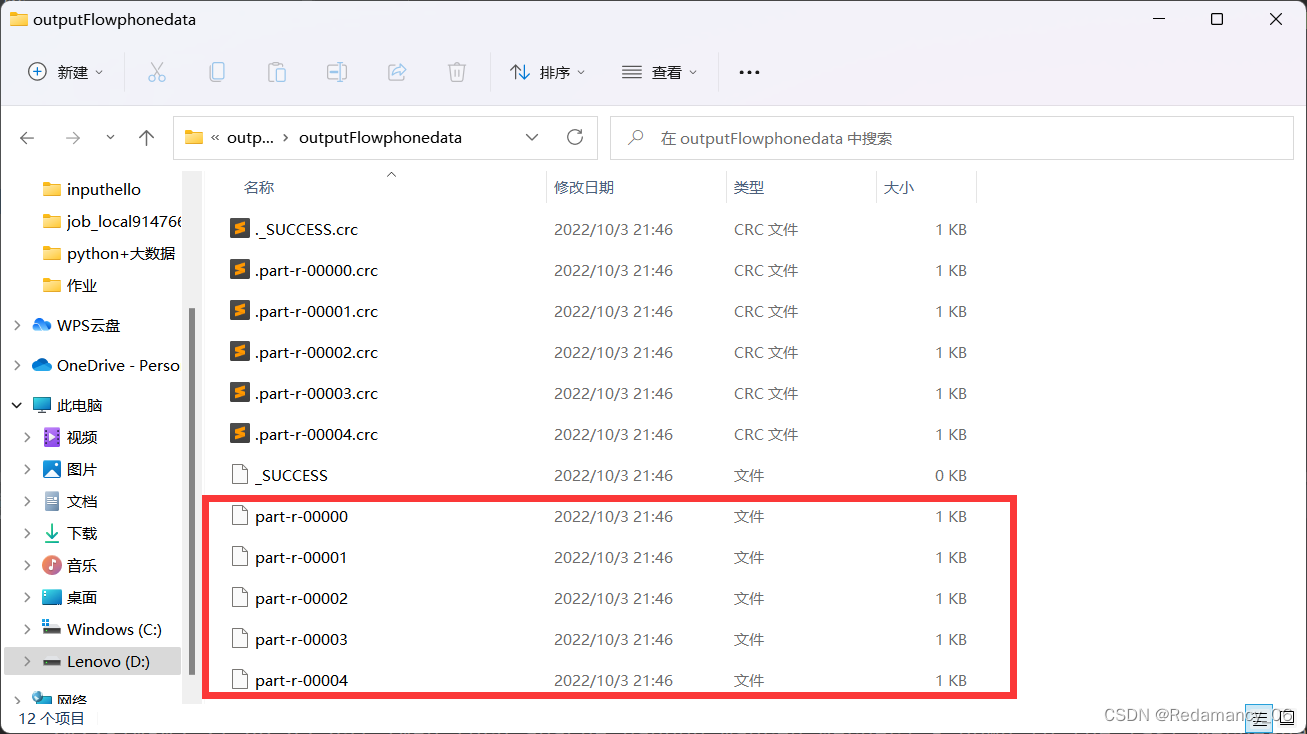
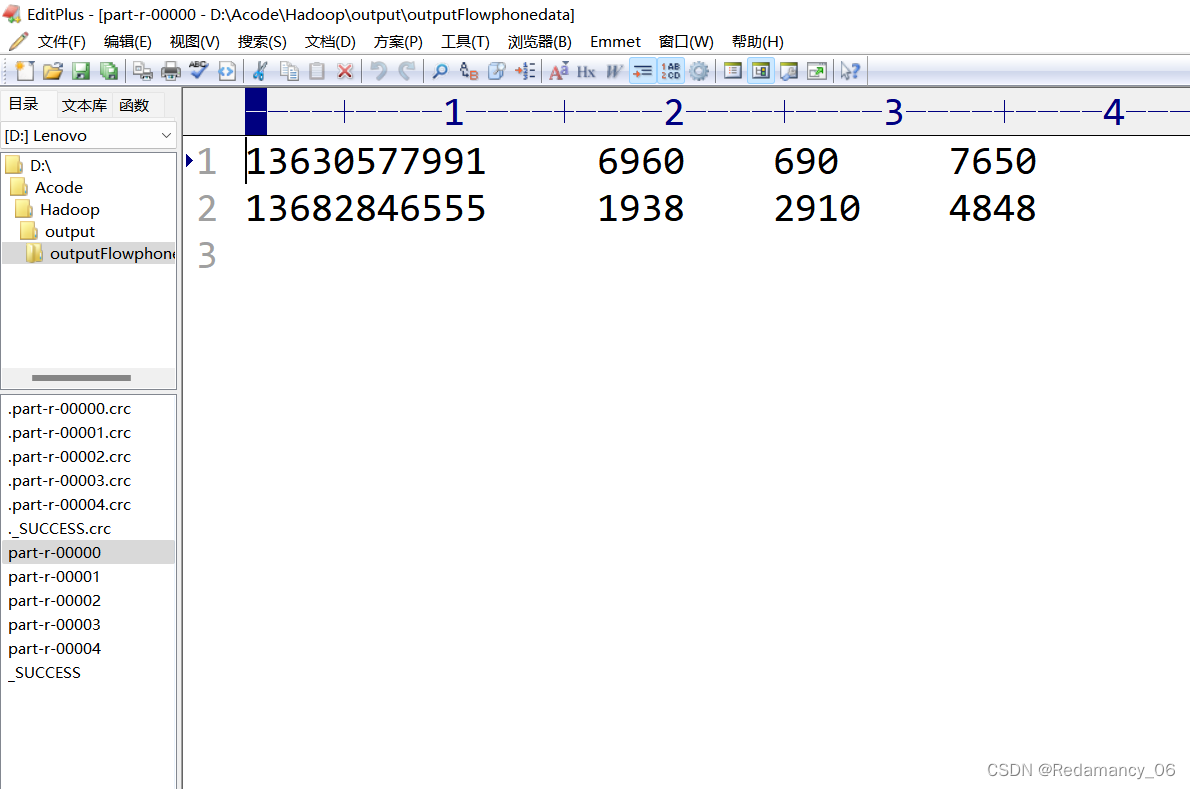
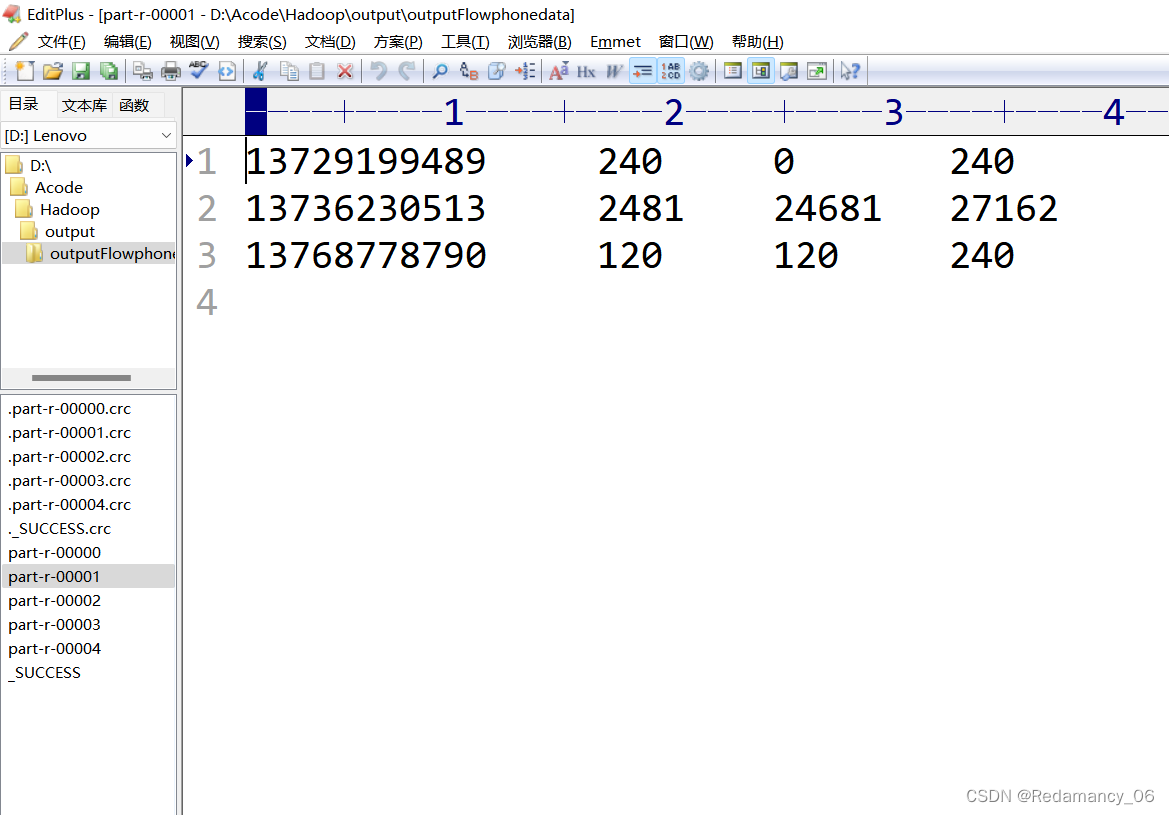
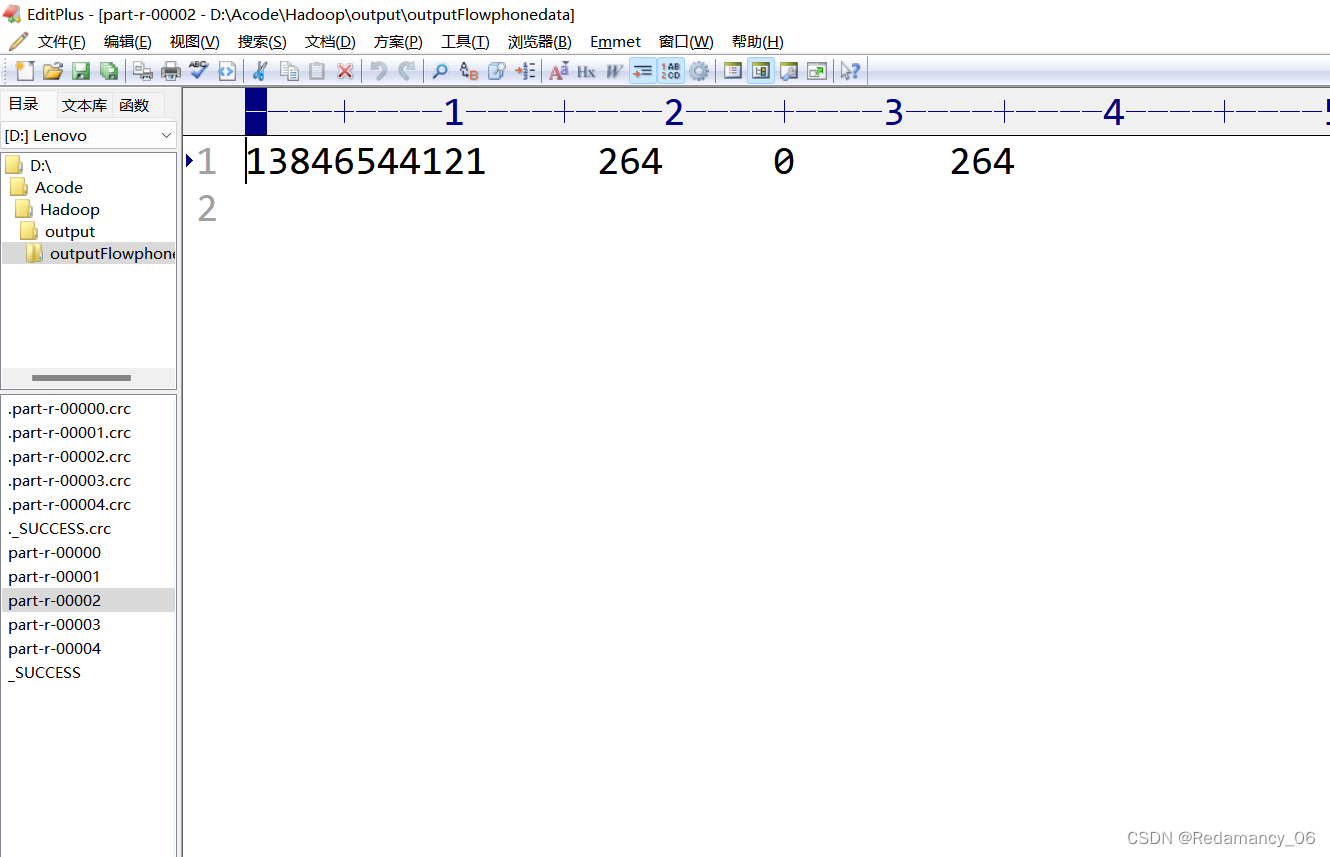
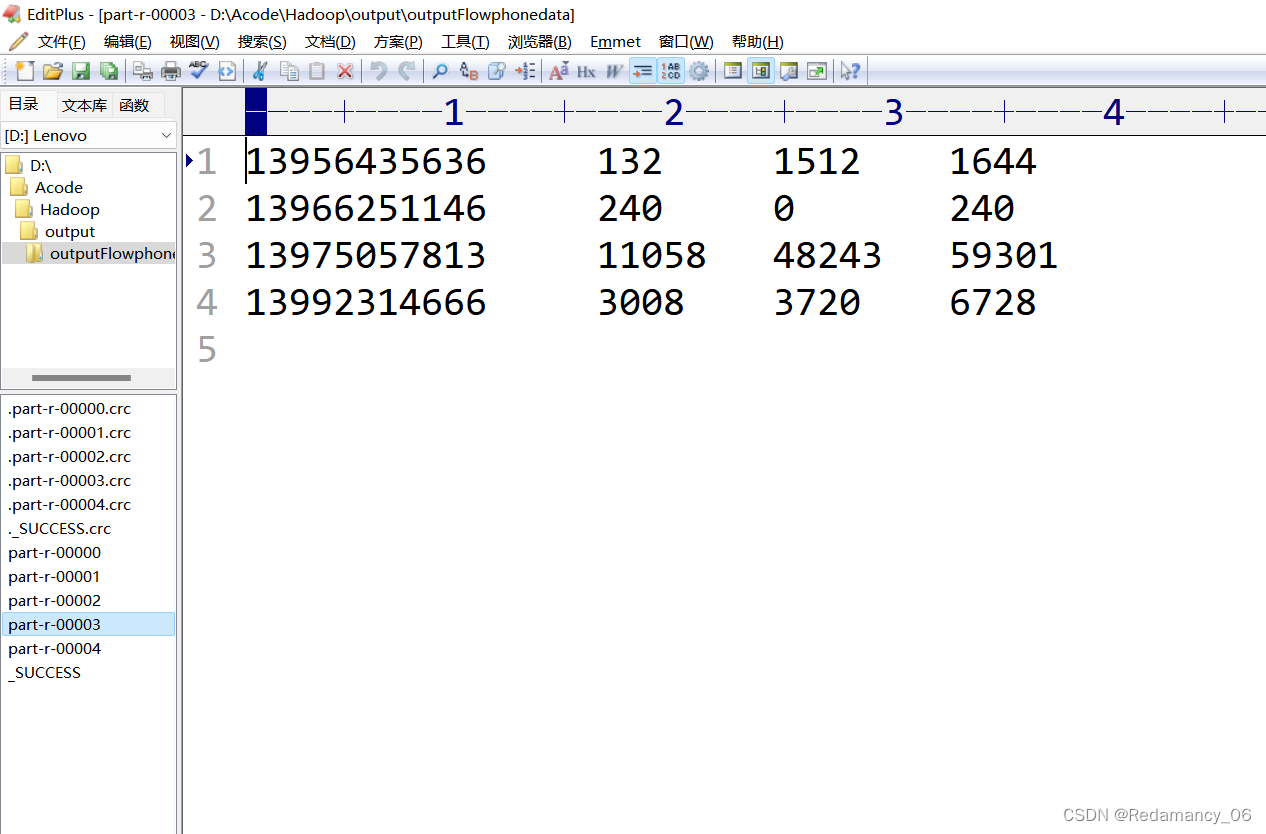
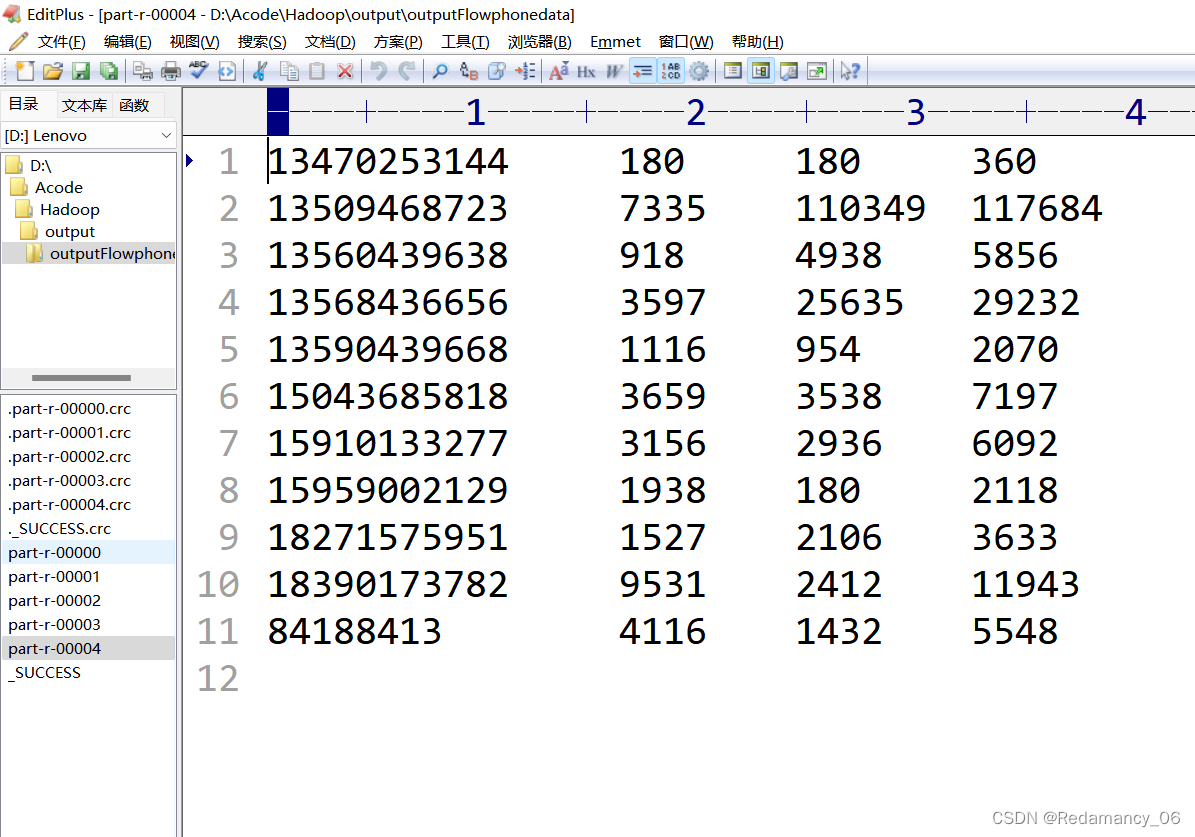
After running, there are five partitions, as expected, over!