前文
以下の例は、ミュンヘン大学での機械学習の入門講義の一部です。このプロジェクトの目標は、探索的分析を行い、結果を詳しく説明しながら、目前の問題について1つまたは複数の機械学習パイプラインを作成して比較することです。
準備
mlr3の詳細なガイドについては、以下を参照してください。
mlr3本(https://mlr3book.mlr-org.com/index.html)
## 安装与加载所需包
install.packages('mlr3verse')
install.packages('DataExplorer')
install.packages('gridExtra')
library(mlr3verse)
library(dplyr)
library(tidyr)
library(DataExplorer)
library(ggplot2)
library(gridExtra)固定シードを使用して乱数ジェネレーターを初期化し、再現性を保証し、ロガーの冗長性を減らして出力をクリーンに保ちます。
set.seed(7832)
lgr::get_logger("mlr3")$set_threshold("warn")
lgr::get_logger("bbotk")$set_threshold("warn")この例では、著者は、機械学習アルゴリズムの特定のアプリケーションと肝疾患検出のための学習者を調査します。したがって、タスクは二元分类、いくつかの一般的な診断手段に基づいて、患者が肝疾患を患っているかどうかを予測することです。
受け取るサンプルデータとコード:いいね、この記事を読んで、友達の輪に共有し、いいねを10個集めて、30分間保存します。スクリーンショットを撮り、WeChat ID:mzbj0002を送信するか、以下のQRコードをスキャンします。2022年のVIP会員は無料で受け取ります。
カヌーノート2022VIPプロジェクト
権利と利益:
2022年のカヌーノートのすべてのツイートのサンプルデータとコード(2021年のほとんどを含む)。
カヌーノート科学研究交流グループ。
半額購入
跟着Cell学作图系列合集(無料のチュートリアル+コードコレクション)|セルをフォローして、シリーズのコレクションを描く方法を学びましょう。
通行料金:
99円/人。WeChatを追加することができます:mzbj0002送金するか、記事の最後に直接報酬を与えることができます。

インドの肝疾患データ
# Importing data
data("ilpd", package = "mlr3data")これには、インドのアーンドラプラデーシュ州北東部の583患者について収集されたデータが含まれています。観察結果は、患者が肝疾患を患っているかどうかに基づいて2つのカテゴリーに分けられました。ターゲット変数に加えて、主に数値の10個の機能が提供されています。これらの機能をより詳細に説明するために、次の表にデータセット内の変数を示します。
| 変数 | 説明 |
|---|---|
| 年 | 患者の年齢(89歳を超えるすべての患者は90と表示されます |
| 性別 | 患者の性別(1 =女性、0 =男性) |
| total_bilirubin | 総血清ビリルビン(mg / dL) |
| direct_bilirubin | 直接ビリルビンレベル(mg / dL) |
| アルカリホスファターゼ | 血清アルカリホスファターゼレベル(U / L) |
| アラニンアミノ基転移 | 血清アラニントランスアミナーゼレベル(U / L) |
| aspartate_transaminase | 血清アスパラギン酸トランスアミナーゼレベル(U / L) |
| total_protein | 総血清タンパク質(g / dL) |
| アルブミン | 血清アルブミンレベル(g / dL) |
| albumin_globulin_ratio | アルブミンとグロブリンの比率 |
| 病気にかかった | ターゲット変数(1 =肝疾患、0 =肝疾患なし) |
明らかに、いくつかの測定値は他の変数の一部です。たとえば、総血清ビリルビンは直接的および間接的なビリルビンレベルの合計ですが、アルブミンの量は総血清タンパク質の値とアルブミン-グロブリン比を計算するために使用されます。したがって、いくつかの機能は相互に高い相関関係があり、以下で扱います。
データ前処理
単変量分布
次に、各変数の単変量分布を調べます。ターゲット変数と唯一の個別の特徴である性別から始めます。これらは両方ともバイナリ変数です。
## 所有离散变量的频率分布
plot_bar(ilpd,ggtheme = theme_bw())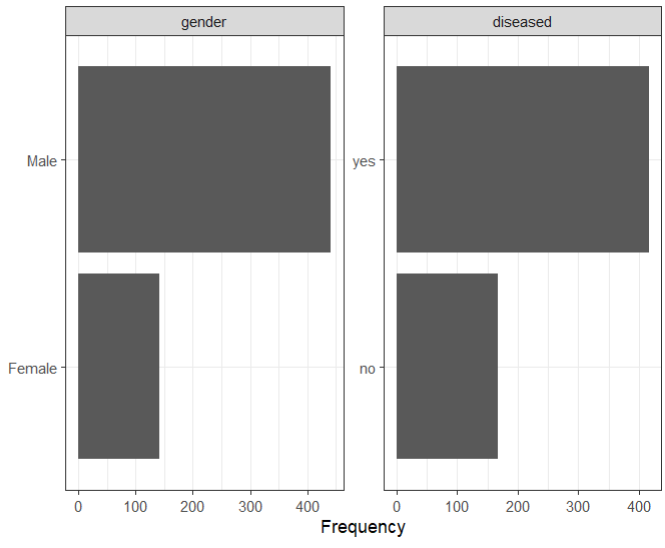
ヒストグラムに示されているように、ターゲット変数(つまり、肝疾患のある患者とない患者)の分布は非常に不均衡であることがわかります。肝疾患のある患者とない患者の数は、それぞれ416と167です。クラスの表現が不足していると、MLモデルのパフォーマンスが低下する可能性があります。この質問を調査するために、著者は、少数派クラスがランダムにオーバーサンプリングされたデータセットにモデルを適合させ、完全にバランスの取れたデータセットを作成しました。さらに、層化サンプリングを適用して、交差検定プロセス中にクラスの比率が維持されるようにしました。唯一の個別の機能genderもかなり不均衡です。
## 查看所有连续变量的频率分布直方图
plot_histogram(ilpd,ggtheme = theme_mlr3())
一部のインジケーター機能は非常に右に歪んでおり、いくつかの極端な値が含まれていることがわかります。外れ値の影響を減らすために、また一部のモデルは特徴の正規性を想定しているため、logこれらの変数を変換しました。
機能のグループ化
目标との間の特征関係を描くために、分析された类别分布に従います特征。まず、個別の機能の性別を調べました。
plot_bar(ilpd,by = 'diseased',ggtheme = theme_mlr3())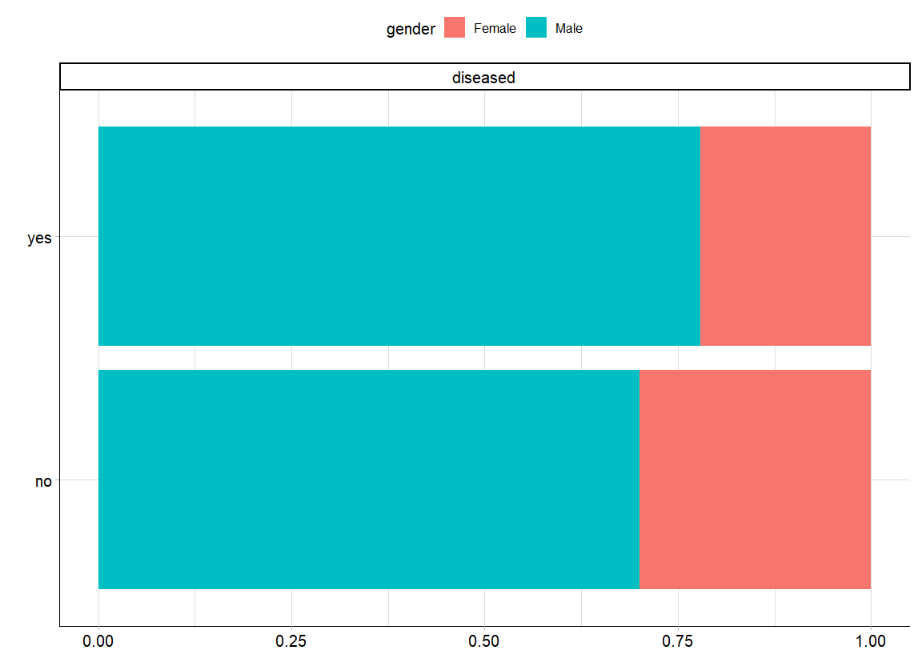
「病気」のカテゴリーでは、男性の割合がわずかに高かったが、全体として、その差は有意ではなかった。これに加えて、前述したように、両方のカテゴリーでジェンダーの不均衡が見られます。
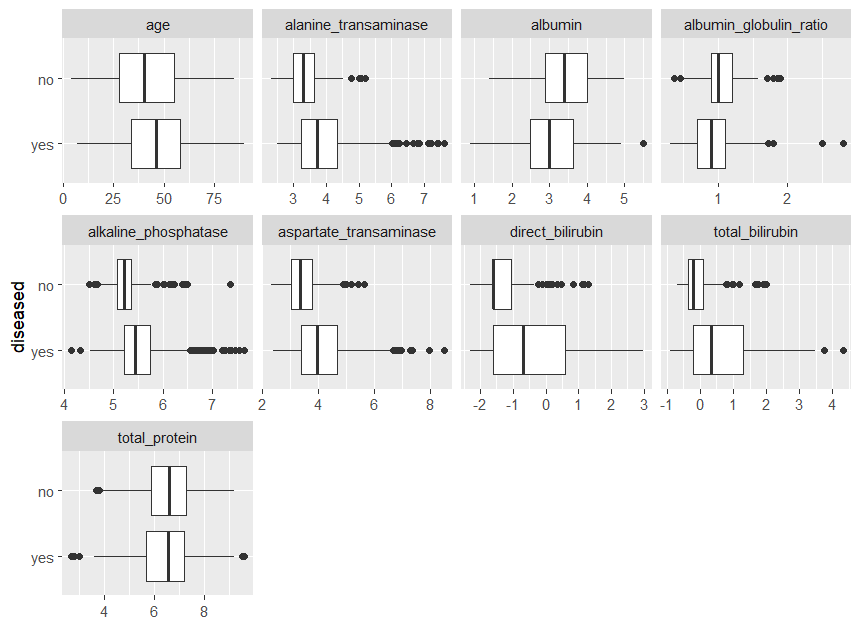
連続特徴の違いを確認するためboxplotsに、右バイアスの特徴が対数変換されていない以下を比較しました。
## View bivariate continuous distribution based on `diseased`
plot_boxplot(ilpd,by = 'diseased')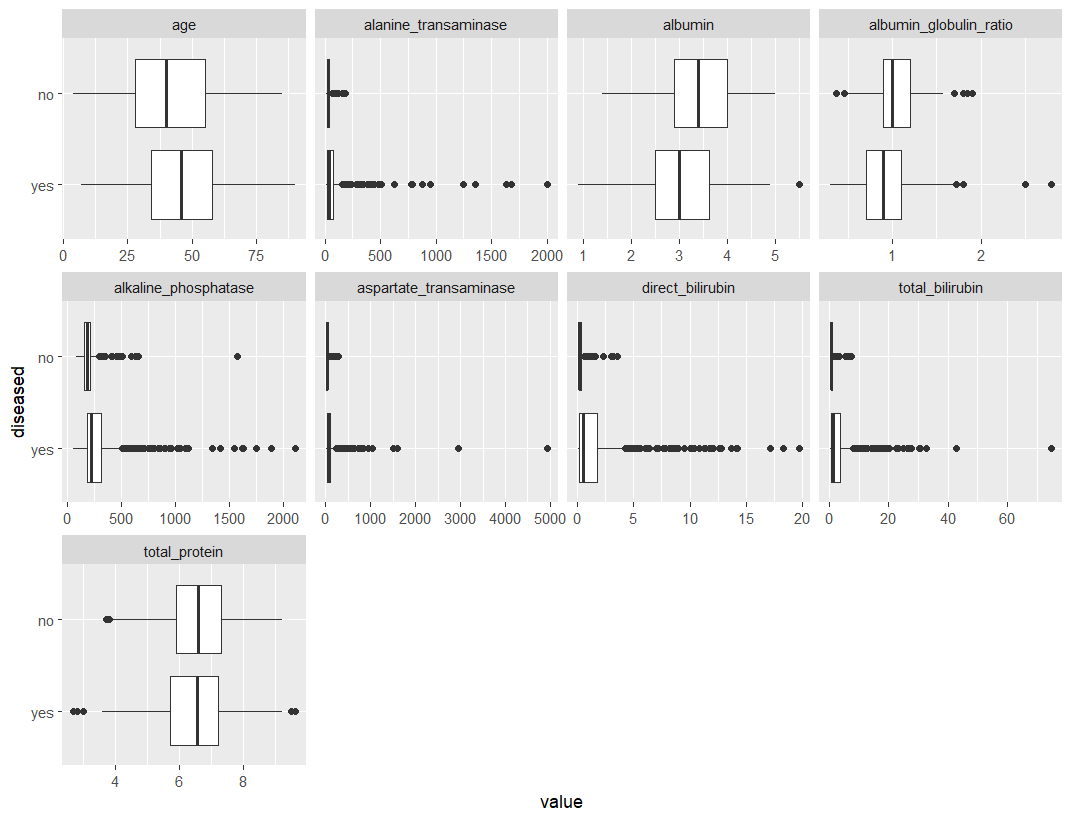
を除いてtotal_protein、各機能について、2つのクラスの中央値の差が得られることがわかります。強く右にバイアスされた機能の中で、「病気」クラスには「病気なし」クラスよりもはるかに極端な値が含まれていることは注目に値します。おそらくその規模が大きいためです。
下のグラフからわかるように、この効果は対数変換後に減衰します。さらに、これらの機能は、箱ひげ図の長さで示されるように、「病気」クラスでより広がります。全体として、これらの機能はターゲットに関連しているように見えるため、このタスクにこれらの機能を使用して、ターゲットとの関係をモデル化することは理にかなっています。
一部の機能の対数変換
ilpd_log = ilpd %>%
mutate(
# Log for features with skewed distributions
alanine_transaminase = log(alanine_transaminase),
total_bilirubin =log(total_bilirubin),
alkaline_phosphatase = log(alkaline_phosphatase),
aspartate_transaminase = log(aspartate_transaminase),
direct_bilirubin = log(direct_bilirubin)
)
plot_histogram(ilpd_log,ggtheme = theme_mlr3(),ncol = 3)
plot_boxplot(ilpd_log,by = 'diseased')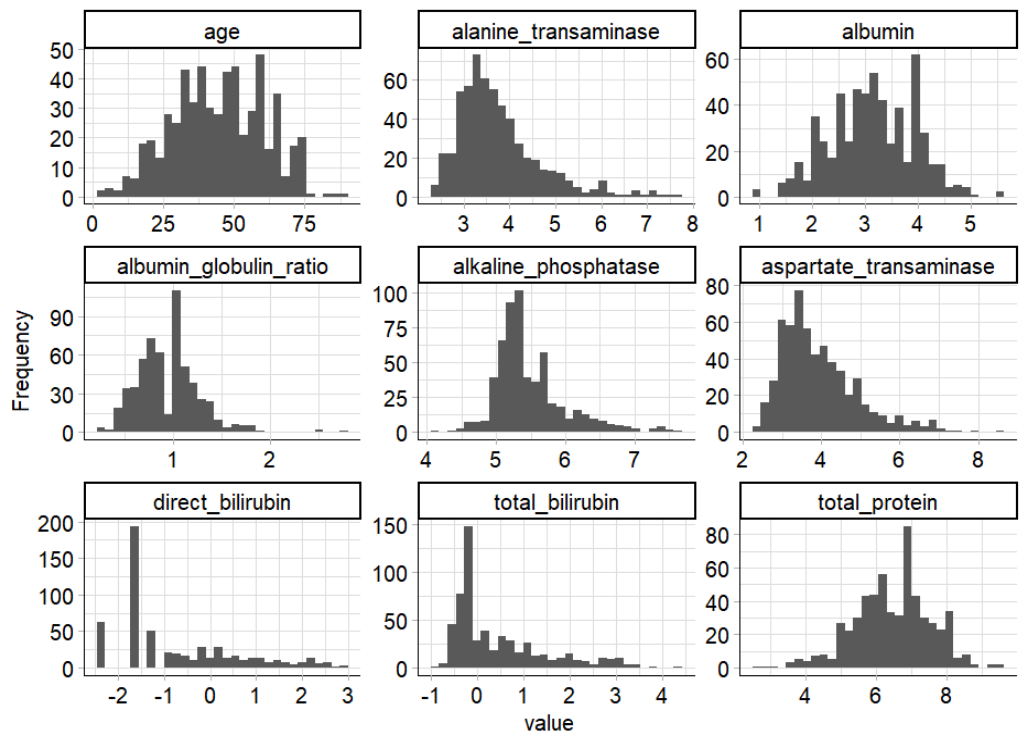
log変換されたデータ分布が大幅に改善されていることがわかります。
関連する分析
データの説明で述べたように、一部の機能は別の機能によって間接的に測定されます。これは、それらが高度に相関していることを示しています。比較したいモデルの仮定のいくつかは、独立機能である多重共线性か、問題があります。したがって、機能間の相関関係を調べました。
plot_correlation(ilpd)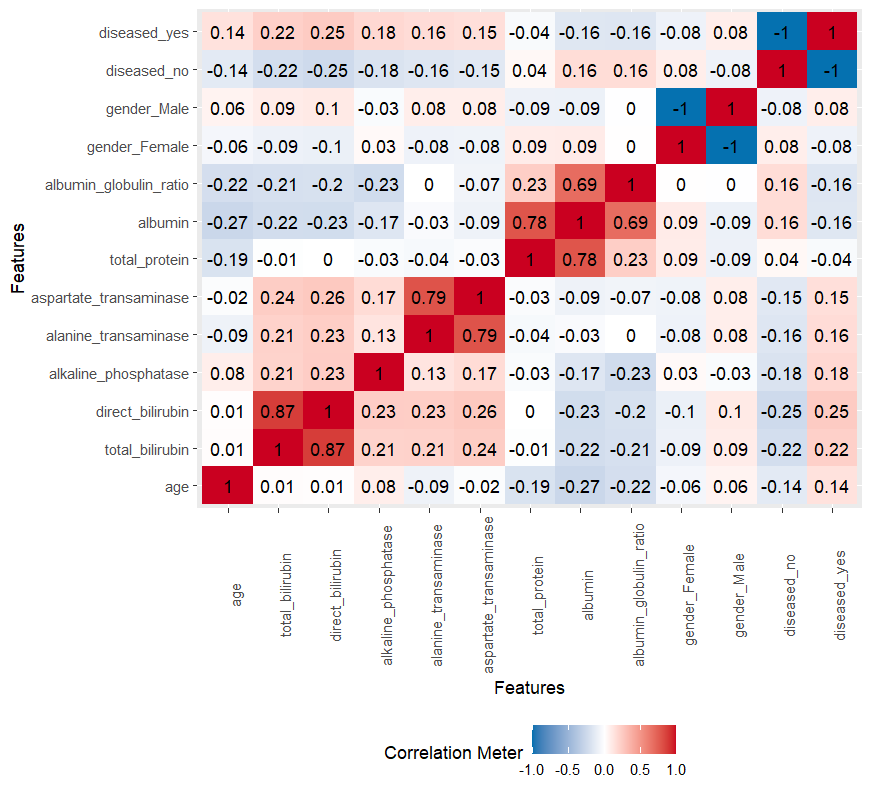
見てわかるように、4つのペアは非常に高い相関係数を持っています。これらの機能を見ると、それらが相互に作用していることは明らかです。モデルの複雑さを最小限に抑える必要があるため、また多重共線性を考慮して、機能の各ペアの1つだけを使用することにしました。どの機能を維持するかを決定する際に、より具体的で肝疾患に関連する機能を選択しました。したがって、アルブミンとグロブリンの比率やタンパク質の総量ではなく、アルブミンを選択しました。同じ点は、総ビリルビンの代わりに直接ビリルビンの量を使用することにも当てはまります。アスパラギン酸アミノトランスフェラーゼとアラニンアミノトランスフェラーゼについては、これら2つの特性のデータに根本的な違いは見られなかったため、アスパラギン酸アミノトランスフェラーゼを任意に選択しました。
最終データセット
## Reducing, transforming and scaling dataset
ilpd = ilpd %>%
select(-total_bilirubin, -alanine_transaminase, -total_protein,
-albumin_globulin_ratio) %>%
mutate(
# Recode gender
gender = as.numeric(ifelse(gender == "Female", 1, 0)),
# Remove labels for class
diseased = factor(ifelse(diseased == "yes", 1, 0)),
# Log for features with skewed distributions
alkaline_phosphatase = log(alkaline_phosphatase),
aspartate_transaminase = log(aspartate_transaminase),
direct_bilirubin = log(direct_bilirubin)
)
## 标准化
po_scale = po("scale")
po_scale$param_set$values$affect_columns =
selector_name(c("age", "direct_bilirubin", "alkaline_phosphatase",
"aspartate_transaminase", "albumin"))
task_liver = as_task_classif(ilpd_m, target = "diseased", positive = "1")
ilpd_f = po_scale$train(list(task_liver))[[1]]$data()最後に、すべての連続変数機能に対して実行しました标准化。これは、k-NNモデルにとって特に重要です。次の表は、最終的なデータセットと適用した変換を示しています。注:対数変換やその他の変換とは異なり、スケーリングはデータ自体に依存します。分割する前にデータをスケーリングすると、トレーニングとテストセットの情報が共有されるため、データ漏洩につながる可能性があります(Nature Reviews Genetics |ゲノミクスに機械学習を適用する際の一般的な落とし穴を参照)。データ漏洩はパフォーマンスの向上につながる可能性があるため、MLワークフローによって引き起こされる各データ分割に常に個別にスケーリングを適用する必要があります。したがって、この場合は使用することを強くお勧めしPipeOpScaleます。
学習者とチューニング
まず、task最終的なデータセットといくつかのメタ情報を含む1つを定義する必要があります。また、パッケージはデフォルトで最初のポジティブクラスをポジティブクラスにするため、ポジティブクラスを指定する必要があります。ポジティブクラスの割り当ては、その後の評価に影響を及ぼします。
## Task definition
task_liver = as_task_classif(ilpd_f, target = "diseased", positive = "1")以下ではlogistic regression、、linear discriminant analysis(LDA)、quadratic discriminant analysis(QDA)、、naive Bayes(k-nearest neighbourk-NN)、classification trees(CART)、およびrandom forestの二項分類の目的を評価します。
# detect overfitting
install.packages('e1071')
install.packages('kknn')
learners = list(
learner_logreg = lrn("classif.log_reg", predict_type = "prob",
predict_sets = c("train", "test")),
learner_lda = lrn("classif.lda", predict_type = "prob",
predict_sets = c("train", "test")),
learner_qda = lrn("classif.qda", predict_type = "prob",
predict_sets = c("train", "test")),
learner_nb = lrn("classif.naive_bayes", predict_type = "prob",
predict_sets = c("train", "test")),
learner_knn = lrn("classif.kknn", scale = FALSE,
predict_type = "prob"),
learner_rpart = lrn("classif.rpart",
predict_type = "prob"),
learner_rf = lrn("classif.ranger", num.trees = 1000,
predict_type = "prob")
)パラメータチューニング
最適なハイパーパラメータを見つけるために、ランダム検索を使用してハイパーパラメータ空間をより適切にカバーします。調整するハイパーパラメータを定義します。k-NN他の方法には強い仮定があり、ベースラインとして機能するため、、、、CARTおよびの随机森林ハイパーパラメータのみを調整します。
については、下限(ネイバーの数)k-NNとして3を選択し、上限として50を選択します。kkが小さすぎると、過剰適合につながる可能性があります。Manhattan distanceまた、さまざまな距離測度( 1、2 Euclidean distance)とカーネルを試しました。については、ハイパーパラメーター(複雑さパラメーター)と(分割を試みるために、ノード内の観測値の最小数)CARTを調整しました。制御されたサイズ:小さい値は過剰適合につながり、大きい値は過適合につながります。また、ターミナルノードの最小サイズのパラメーターと、各分割でランダムにサンプリングされた候補変数の数(1から特徴の数まで)を調整します。cpminsplitcptree随机森林的
tune_ps_knn = ps(
k = p_int(lower = 3, upper = 50), # Number of neighbors considered
distance = p_dbl(lower = 1, upper = 3),
kernel = p_fct(levels = c("rectangular", "gaussian", "rank", "optimal"))
)
tune_ps_rpart = ps(
# Minimum number of observations that must exist in a node in order for a
# split to be attempted
minsplit = p_int(lower = 10, upper = 40),
cp = p_dbl(lower = 0.001, upper = 0.1) # Complexity parameter
)
tune_ps_rf = ps(
# Minimum size of terminal nodes
min.node.size = p_int(lower = 10, upper = 50),
# Number of variables randomly sampled as candidates at each split
mtry = p_int(lower = 1, upper = 6)
)次のステップは、をmlr3tuningインスタンス化AutoTunerすることです。ネストされたリサンプリングには内部ループを採用しました5-fold交叉验证法。評価回数は停止基準として100回とした。AUC評価指標として使用します。
前述のように、ターゲットクラスのバランスが取れていないため、完全にバランスの取れたクラスを選択します。を使用mlr3pipelinesすることで、後でベンチマーク関数を適用できます。
# Oversampling minority class to get perfectly balanced classes
po_over = po("classbalancing", id = "oversample", adjust = "minor",
reference = "minor", shuffle = FALSE, ratio = 416/167)
table(po_over$train(list(task_liver))$output$truth()) # Check class balance
# Learners with balanced/oversampled data
learners_bal = lapply(learners, function(x) {
GraphLearner$new(po_scale %>>% po_over %>>% x)
})
lapply(learners_bal, function(x) x$predict_sets = c("train", "test"))モデルのフィッティングとベンチマーク
学習器を定義し、ネストされたリサンプリングの内部メソッドを選択し、アジャスターを設定した後、外部のリサンプリング方法の選択を開始します。オーバーサンプリングのないターゲット変数の分布を維持するために、層化5分割交差検定法を選択しました。ただし、層化なしの通常の交差検定でも、非常に類似した結果が得られることがわかります。
# 5-fold cross-validation
resampling_outer = rsmp(id = "cv", .key = "cv", folds = 5L)
# Stratification
task_liver$col_roles$stratum = task_liver$target_namesさまざまな学習者をランク付けし、最終的に、目前のタスクに最適な学習者を決定するために、ベンチマークを使用します。以下のコードブロックは、すべての学習者に対してベンチマークを実行します。
design = benchmark_grid(
tasks = task_liver,
learners = c(learners, learners_bal),
resamplings = resampling_outer
)
bmr = benchmark(design, store_models = FALSE) ## 耗时较长上記のように、層化5分割交差検定法を選択しました。これは、パフォーマンスがtrain-test-split80%と20%での5つのモデル評価の平均として決定されることを意味します。さらに、パフォーマンスメトリックの選択は、さまざまな学習者をランク付けするために重要です。それぞれに固有のユースケースがありAUCますが、感度と特異性の両方を考慮したパフォーマンスメトリックを選択しました。これは、ハイパーパラメータの調整にも使用されます。
まず、AUCオーバーサンプリングの有無にかかわらず、すべての学習者を比較し、トレーニングとテストのデータを比較します。
measures = list(
msr("classif.auc", predict_sets = "train", id = "auc_train"),
msr("classif.auc", id = "auc_test")
)
tab = bmr2$aggregate(measures)
tab_1 = tab[,c('learner_id','auc_train','auc_test')]
print(tab_1)> print(tab_1)
learner_id auc_train auc_test
1: classif.log_reg 0.7548382 0.7485372
2: classif.lda 0.7546522 0.7487159
3: classif.qda 0.7683438 0.7441634
4: classif.naive_bayes 0.7539374 0.7498427
5: classif.kknn.tuned 0.8652143 0.7150679
6: classif.rpart.tuned 0.7988561 0.6847818
7: classif.ranger.tuned 0.9871615 0.7426650
8: scale.oversample.classif.log_reg 0.7540066 0.7497002
9: scale.oversample.classif.lda 0.7537952 0.7489675
10: scale.oversample.classif.qda 0.7679012 0.7481963
11: scale.oversample.classif.naive_bayes 0.7536208 0.7503436
12: scale.oversample.classif.kknn.tuned 0.9982251 0.6870297
13: scale.oversample.classif.rpart.tuned 0.8903927 0.6231100
14: scale.oversample.classif.ranger.tuned 1.0000000 0.7409655上記の結果から、ロジスティック回帰、LDA、QDA、およびNBは、オーバーサンプリングが適用されているかどうかに関係なく、トレーニングデータとテストデータで非常によく似ていることがわかります。一方、k-NN、CART、およびランダムフォレストは、トレーニングデータではるかに優れた予測を行い、過剰適合を示唆しています。
さらに、オーバーサンプリングではAUC、すべての学習者のパフォーマンスにほとんど変化がありません。
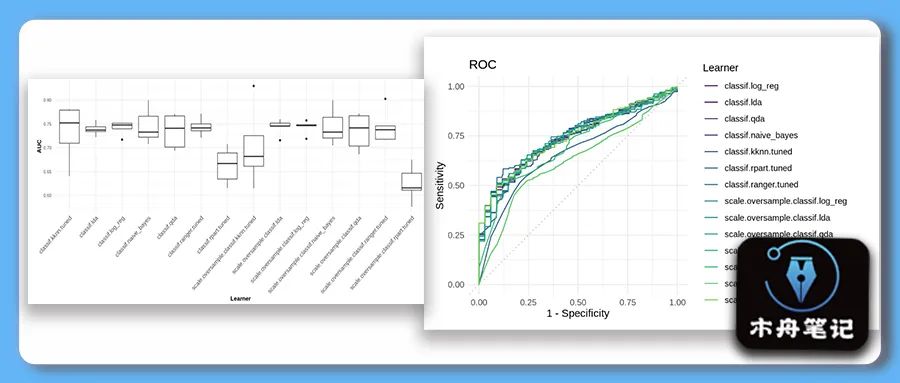
AUC以下の箱ひげ図は、すべての学習者の5分割交差検定のパフォーマンスを示しています。
# boxplot of AUC values across the 5 folds
autoplot(bmr2, measure = msr("classif.auc"))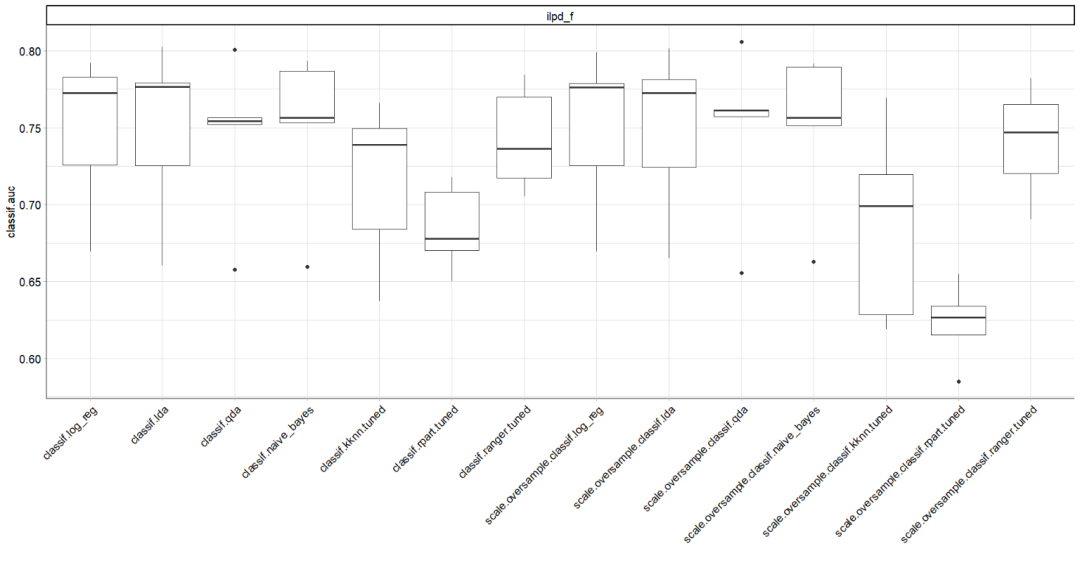
autoplot(bmr2,type = "roc")+
scale_color_discrete() +
theme_bw()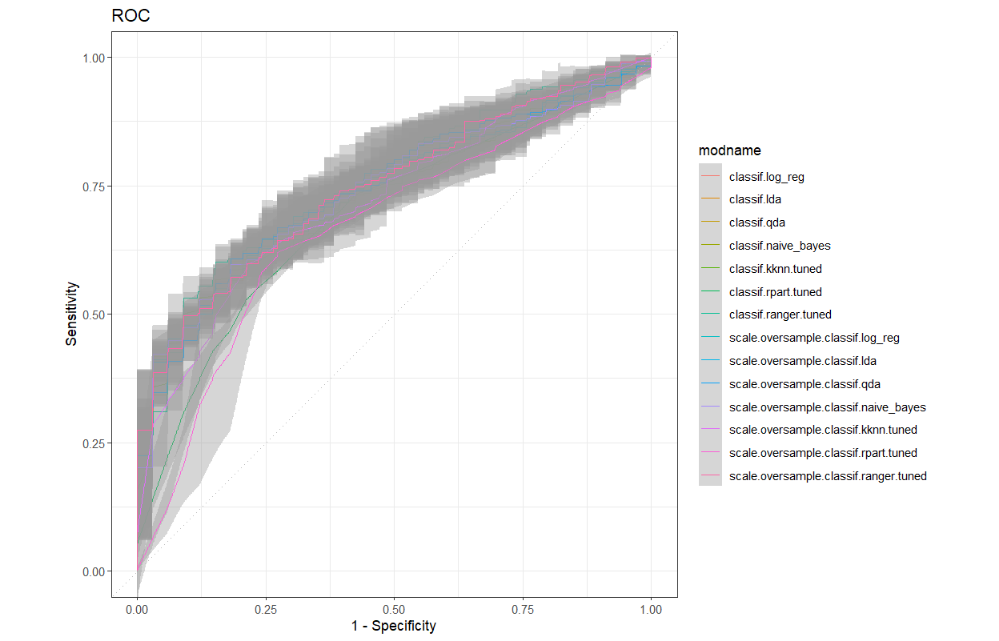
続いて、各学習者の感度、特異度、偽陰性率(FNR)、偽陽性率(FPR)が出力されます。
tab2 = bmr2$aggregate(msrs(c('classif.auc', 'classif.sensitivity','classif.specificity',
'classif.fnr', 'classif.fpr')))
tab2 = tab2[,c('learner_id','classif.auc','classif.sensitivity','classif.specificity',
'classif.fnr', 'classif.fpr')]
print(tab2)> print(tab2)
learner_id classif.auc classif.sensitivity
1: classif.log_reg 0.7485372 0.8917097
2: classif.lda 0.7487159 0.9037005
3: classif.qda 0.7441634 0.6779116
4: classif.naive_bayes 0.7498427 0.6250430
5: classif.kknn.tuned 0.7180074 0.8509180
6: classif.rpart.tuned 0.6987046 0.8679289
7: classif.ranger.tuned 0.7506405 0.9447504
8: scale.oversample.classif.log_reg 0.7475678 0.6008893
9: scale.oversample.classif.lda 0.7489090 0.5841652
10: scale.oversample.classif.qda 0.7431096 0.5529547
11: scale.oversample.classif.naive_bayes 0.7494055 0.5505164
12: scale.oversample.classif.kknn.tuned 0.6924480 0.6948078
13: scale.oversample.classif.rpart.tuned 0.6753005 0.7090075
14: scale.oversample.classif.ranger.tuned 0.7393948 0.7427424
classif.specificity classif.fnr classif.fpr
1: 0.2516934 0.10829030 0.7483066
2: 0.1855615 0.09629948 0.8144385
3: 0.6946524 0.32208835 0.3053476
4: 0.7488414 0.37495697 0.2511586
5: 0.2581105 0.14908204 0.7418895
6: 0.3108734 0.13207114 0.6891266
7: 0.1554367 0.05524957 0.8445633
8: 0.7663102 0.39911073 0.2336898
9: 0.8023173 0.41583477 0.1976827
10: 0.8139037 0.44704532 0.1860963
11: 0.8381462 0.44948365 0.1618538
12: 0.5811052 0.30519220 0.4188948
13: 0.5449198 0.29099254 0.4550802
14: 0.5509804 0.25725760 0.4490196オーバーサンプリングなしでは、ロジスティック回帰、LDA、k-NN、CART、およびランダムフォレストは感度が高く、特異性が非常に低いことがわかります。一方、QDAと単純ベイズスターリングは特異性で比較的高いスコアを示しましたが、感度が高い。定義上、高い感度(特異性)は低い偽陰性(陽性)率に由来し、これもデータに反映されます。
単一のモデルを抽出する
## 提取随机森林模型
bmr_rf = bmr2$clone(deep = TRUE)$filter(learner_ids = 'classif.ranger.tuned')
## ROC
autoplot(bmr_rf,type = "roc")+
scale_color_discrete() +
theme_bw()
## PRC
autoplot(bmr_rf, type = "prc")+
scale_color_discrete() +
theme_bw()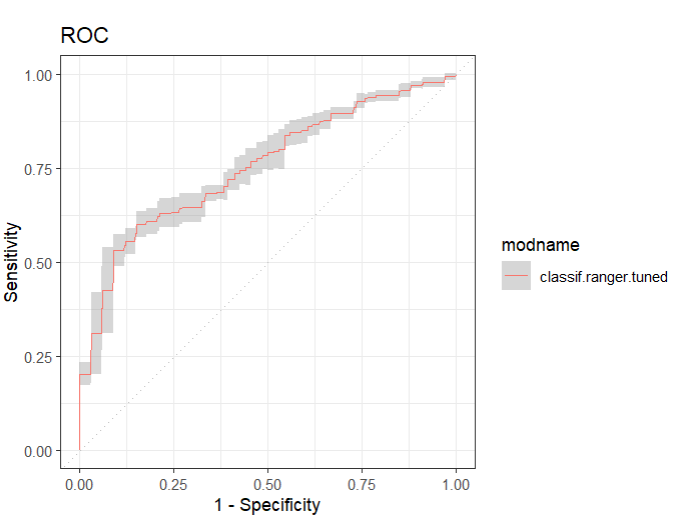
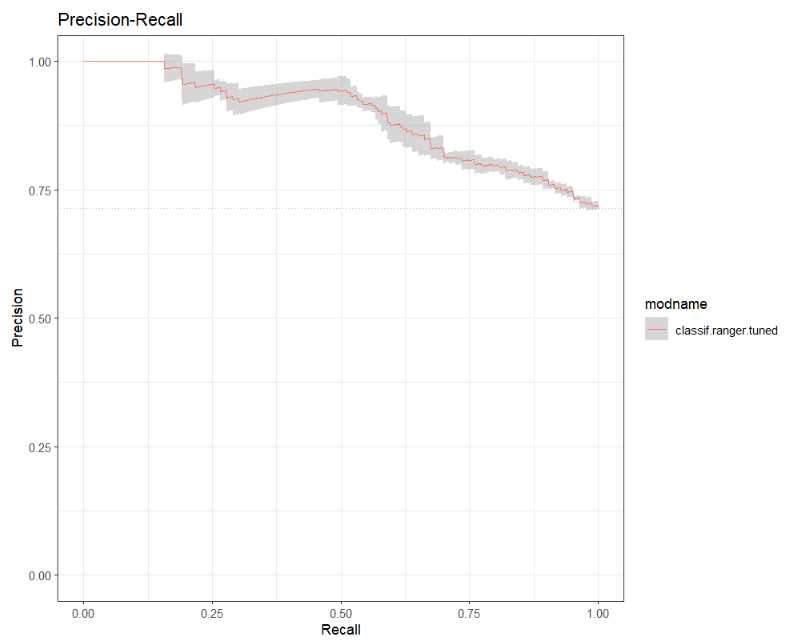
オーバーサンプリングを使用する必要があるかどうかなど、どの学習者が最も効果的に機能するかについては、感度と特異性の実際的な影響に大きく依存します。実用上の重要性に関しては、2つのうちの1つが他の2つを何倍も上回る可能性があります。典型的なHIV迅速診断検査の例を考えてみましょう。高感度で低特異性を犠牲にして(不必要な)ショックを引き起こす可能性がありますが、それ以外の場合は危険ではありませんが、低感度は非常に危険です。よくあることですが、白黒の「ベストモデル」はありません。要約すると、オーバーサンプリングを行っても、感度と特異性の点でどのモデルもうまく機能しませんでした。私たちの場合、私たちは考える必要があります:低感度を犠牲にして高い特異性の結果は何ですか?つまり、肝臓病の多くの患者に健康であることを伝えることを意味します;そして低特異性を犠牲にして高感度の結果は何ですか、これは多くの健康な患者に彼らが肝疾患を持っていることを伝えることを意味します。トピック固有の情報がさらにない場合は、選択した特定のパフォーマンスメトリックで最高のパフォーマンスを発揮する学習者のみを述べることができます。前述のように、ランダムフォレストに基づくAUCランダムフォレストが最高のパフォーマンスを発揮します。また、ランダムフォレストは最高(最低)の感度スコアを持つ学習者であり、FNRナイーブベイズはFPR最高(最低)の特異度スコアを持つ学習者です。
しかし、私たちの分析は決して網羅的なものではありません。機能レベルでは、分析の機械学習と統計分析の側面にほぼ専念してきましたが、実際のトピック(肝疾患)をより深く掘り下げて、変数と基礎となる相関関係および相互作用をさらに理解しようとすることも可能です。徹底的にセックス。これは、削除された変数が再度考慮されることを意味する場合もあります。さらに、主成分分析を使用するなど、データセットに対して特徴エンジニアリングとデータ前処理を実行できます。ハイパーパラメータの調整に関しては、より大きなハイパーパラメータスペースを使用し、さまざまなハイパーパラメータの数を評価することを検討してください。さらに、調整は、ベースライン学習者としてラベル付けされている一部の学習者にも適用できます。最後に、さらに多くの分類器があります。特に、勾配ブースティングとサポートベクターマシンは、このタスクに追加で適用でき、より良い結果をもたらす可能性があります。
参考
(mlr3gallery:診断手段に基づく肝臓患者の分類)(https://mlr3gallery.mlr-org.com/posts/2020-09-11-liver-patient-classification/)
