
1条件付きGANの前提知識
条件付きGANは、GANによって生成されたデータを制御可能にし、モデルを実用的にすることもできます。
1.1実験の説明
条件付きGANモデルを構築して、モデルにラベルを入力する機能を実現し、ラベルカテゴリに対応するシミュレーションデータを生成し、WGAN-gpモデル変換に基づいて条件付きwGAN-gpモデルを実装します。
2サンプルコードの記述
条件付きGANは、条件付きオートエンコーダニューラルネットワークとほぼ同じように機能し、GANの上に入力された各モデルにラベルベクトルを追加します。
2.1コードコンバット:モジュールの導入とサンプルのロード----WGAN_cond_237.py(パート1)
import torch
import torchvision
from torchvision import transforms
from torch.utils.data import DataLoader
from torch import nn
import torch.autograd as autograd
import matplotlib.pyplot as plt
import numpy as np
import matplotlib
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
# 1.1 引入模块并载入样本:定义基本函数,加载FashionMNIST数据集
def to_img(x):
x = 0.5 * (x+1)
x = x.clamp(0,1)
x = x.view(x.size(0),1,28,28)
return x
def imshow(img,filename = None):
npimg = img.numpy()
plt.axis('off')
array = np.transpose(npimg,(1,2,0))
if filename != None:
matplotlib.image.imsave(filename,array)
else:
plt.imshow(array)
# plt.savefig(filename) # 保存图片 注释掉,因为会报错,暂时不知道什么原因 2022.3.26 15:20
plt.show()
img_transform = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize(mean=[0.5],std=[0.5])
]
)
data_dir = './fashion_mnist'
train_dataset = torchvision.datasets.FashionMNIST(data_dir,train=True,transform=img_transform,download=True)
train_loader = DataLoader(train_dataset,batch_size=1024,shuffle=True)
# 测试数据集
val_dataset = torchvision.datasets.FashionMNIST(data_dir,train=False,transform=img_transform)
test_loader = DataLoader(val_dataset,batch_size=10,shuffle=False)
# 指定设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)2.2コードコンバット:ジェネレーターとディスクリミネーターの実装----WGAN_cond_237.py(パート2)
# 1.2 实现生成器和判别器 :因为复杂部分都放在loss值的计算方面了,所以生成器和判别器就会简单一些。
# 生成器和判别器各自有两个卷积和两个全连接层。生成器最终输出与输入图片相同维度的数据作为模拟样本。
# 判别器的输出不需要有激活函数,并且输出维度为1的数值用来表示结果。
# 在GAN模型中,因判别器的输入则是具体的样本数据,要区分每个数据的分布特征,所以判别器使用实例归一化,
class WGAN_D(nn.Module): # 定义判别器类D :有两个卷积和两个全连接层
def __init__(self,inputch=1):
super(WGAN_D, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(inputch,64,4,2,1), # 输出形状为[batch,64,28,28]
nn.LeakyReLU(0.2,True),
nn.InstanceNorm2d(64,affine=True)
)
self.conv2 = nn.Sequential(
nn.Conv2d(64,128,4,2,1),# 输出形状为[batch,64,14,14]
nn.LeakyReLU(0.2,True),
nn.InstanceNorm2d(128,affine=True)
)
self.fc = nn.Sequential(
nn.Linear(128*7*7,1024),
nn.LeakyReLU(0.2,True)
)
self.fc2 = nn.Sequential(
nn.InstanceNorm1d(1,affine=True),
nn.Flatten(),
nn.Linear(1024,1)
)
def forward(self,x,*arg): # 正向传播
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0),-1)
x = self.fc(x)
x = x.reshape(x.size(0),1,-1)
x = self.fc2(x)
return x.view(-1,1).squeeze(1)
# 在GAN模型中,因生成器的初始输入是随机值,所以生成器使用批量归一化。
class WGAN_G(nn.Module): # 定义生成器类G:有两个卷积和两个全连接层
def __init__(self,input_size,input_n=1):
super(WGAN_G, self).__init__()
self.fc1 = nn.Sequential(
nn.Linear(input_size * input_n,1024),
nn.ReLU(True),
nn.BatchNorm1d(1024)
)
self.fc2 = nn.Sequential(
nn.Linear(1024,7*7*128),
nn.ReLU(True),
nn.BatchNorm1d(7*7*128)
)
self.upsample1 = nn.Sequential(
nn.ConvTranspose2d(128,64,4,2,padding=1,bias=False), # 输出形状为[batch,64,14,14]
nn.ReLU(True),
nn.BatchNorm2d(64)
)
self.upsample2 = nn.Sequential(
nn.ConvTranspose2d(64,1,4,2,padding=1,bias=False), # 输出形状为[batch,64,28,28]
nn.Tanh()
)
def forward(self,x,*arg): # 正向传播
x = self.fc1(x)
x = self.fc2(x)
x = x.view(x.size(0),128,7,7)
x = self.upsample1(x)
img = self.upsample2(x)
return img2.3コードコンバット:勾配ペナルティ項を完了する関数を定義します----WGAN_cond_237.py(パート3)
# 1.3 定义函数compute_gradient_penalty()完成梯度惩罚项
# 惩罚项的样本X_inter由一部分Pg分布和一部分Pr分布组成,同时对D(X_inter)求梯度,并计算梯度与1的平方差,最终得到gradient_penalties
lambda_gp = 10
# 计算梯度惩罚项
def compute_gradient_penalty(D,real_samples,fake_samples,y_one_hot):
# 获取一个随机数,作为真假样本的采样比例
eps = torch.FloatTensor(real_samples.size(0),1,1,1).uniform_(0,1).to(device)
# 按照eps比例生成真假样本采样值X_inter
X_inter = (eps * real_samples + ((1-eps)*fake_samples)).requires_grad_(True)
d_interpolates = D(X_inter,y_one_hot)
fake = torch.full((real_samples.size(0),),1,device=device) # 计算梯度输出的掩码,在本例中需要对所有梯度进行计算,故需要按照样本个数生成全为1的张量。
# 求梯度
gradients = autograd.grad(outputs=d_interpolates, # 输出值outputs,传入计算过的张量结果
inputs=X_inter,# 待求梯度的输入值inputs,传入可导的张量,即requires_grad=True
grad_outputs=fake, # 传出梯度的掩码grad_outputs,使用1和0组成的掩码,在计算梯度之后,会将求导结果与该掩码进行相乘得到最终结果。
create_graph=True,
retain_graph=True,
only_inputs=True
)[0]
gradients = gradients.view(gradients.size(0),-1)
gradient_penaltys = ((gradients.norm(2, dim=1) - 1) ** 2).mean() * lambda_gp
return gradient_penaltys2.4コードコンバット:モデルのトレーニング機能を定義する----WGAN_cond_237.py(パート4)
# 1.4 定义模型的训练函数
# 定义函数train(),实现模型的训练过程。
# 在函数train()中,按照对抗神经网络专题(一)中的式(8-24)实现模型的损失函数。
# 判别器的loss为D(fake_samples)-D(real_samples)再加上联合分布样本的梯度惩罚项gradient_penalties,其中fake_samples为生成的模拟数据,real_Samples为真实数据,
# 生成器的loss为-D(fake_samples)。
def train(D,G,outdir,z_dimension,num_epochs=30):
d_optimizer = torch.optim.Adam(D.parameters(),lr=0.001) # 定义优化器
g_optimizer = torch.optim.Adam(G.parameters(),lr=0.001)
os.makedirs(outdir,exist_ok=True) # 创建输出文件夹
# 在函数train()中,判别器和生成器是分开训练的。让判别器学习的次数多一些,判别器每训练5次,生成器优化1次。
# WGAN_gp不会因为判别器准确率太高而引起生成器梯度消失的问题,所以好的判别器会让生成器有更好的模拟效果。
for epoch in range(num_epochs):
for i,(img,lab) in enumerate(train_loader):
num_img = img.size(0)
# 训练判别器
real_img = img.to(device)
y_one_hot = torch.zeros(lab.shape[0],10).scatter_(1,lab.view(lab.shape[0],1),1).to(device)
for ii in range(5): # 循环训练5次
d_optimizer.zero_grad() # 梯度清零
# 对real_img进行判别
real_out = D(real_img,y_one_hot)
# 生成随机值
z = torch.randn(num_img,z_dimension).to(device)
fake_img = G(z,y_one_hot) # 生成fake_img
fake_out = D(fake_img,y_one_hot) # 对fake_img进行判别
# 计算梯度惩罚项
gradient_penalty = compute_gradient_penalty(D,real_img.data,fake_img.data,y_one_hot)
# 计算判别器的loss
d_loss = -torch.mean(real_out)+torch.mean(fake_out)+gradient_penalty
d_loss.backward()
d_optimizer.step()
# 训练生成器
for ii in range(1): # 训练一次
g_optimizer.zero_grad() # 梯度清0
z = torch.randn(num_img,z_dimension).to(device)
fake_img = G(z,y_one_hot)
fake_out = D(fake_img,y_one_hot)
g_loss = -torch.mean(fake_out)
g_loss.backward()
g_optimizer.step()
# 输出可视化结果,并将生成的结果以图片的形式存储在硬盘中
fake_images = to_img(fake_img.cpu().data)
real_images = to_img(real_img.cpu().data)
rel = torch.cat([to_img(real_images[:10]), fake_images[:10]], axis=0)
imshow(torchvision.utils.make_grid(rel, nrow=10),os.path.join(outdir, 'fake_images-{}.png'.format(epoch + 1)))
# 输出训练结果
print('Epoch [{}/{}], d_loss: {:.6f}, g_loss: {:.6f} ''D real: {:.6f}, D fake: {:.6f}'.format(epoch, num_epochs, d_loss.data, g_loss.data,real_out.data.mean(), fake_out.data.mean()))
# 保存训练模型
torch.save(G.state_dict(), os.path.join(outdir, 'generator.pth'))
torch.save(D.state_dict(), os.path.join(outdir, 'discriminator.pth'))2.5コードコンバット:モデルの結果が視覚化されるようになりました----WGAN_cond_237.py(パート5)
# 1.5 定义函数,实现可视化模型结果:获取一部分测试数据,显示由模型生成的模拟数据。
def displayAndTest(D,G,z_dimension): # 可视化结果
sample = iter(test_loader)
images, labels = sample.next()
y_one_hot = torch.zeros(labels.shape[0], 10).scatter_(1,labels.view(labels.shape[0], 1), 1).to(device)
num_img = images.size(0) # 获取样本个数
with torch.no_grad():
z = torch.randn(num_img, z_dimension).to(device) # 生成随机数
fake_img = G(z, y_one_hot)
fake_images = to_img(fake_img.cpu().data) # 生成模拟样本
rel = torch.cat([to_img(images[:10]), fake_images[:10]], axis=0)
imshow(torchvision.utils.make_grid(rel, nrow=10))
print(labels[:10])2.6ディスクリミネータークラスを定義するCondWGAN_D----WGAN_cond_237.py
(パート6)
# 1.6 定义判别器类CondWGAN_D
# 在判别器和生成器类的正向结构中,增加标签向量的输入,并使用全连接网络对标签向量的维度进行扩展,同时将其连接到输入数据。
class CondWGAN_D(WGAN_D): # 定义判别器类CondWGAN_D,使其继承自WGAN_D类。
def __init__(self, inputch=2):
super(CondWGAN_D, self).__init__(inputch)
self.labfc1 = nn.Linear(10, 28 * 28)
def forward(self, x, lab): # 添加输入标签,batch, width, height, channel=1
d_in = torch.cat((x.view(x.size(0), -1), self.labfc1(lab)), -1)
x = d_in.view(d_in.size(0), 2, 28, 28)
return super(CondWGAN_D, self).forward(x, lab)2.7ジェネレータークラスCondWGAN_G----WGAN_cond_237.pyを定義します(パート7)
# 1.7 定义生成器类CondWGAN_G
# 在判别器和生成器类的正向结构中,增加标签向量的输入,并使用全连接网络对标签向量的维度进行扩展,同时将其连接到输入数据。
class CondWGAN_G(WGAN_G): # 定义生成器类CondWGAN_G,使其继承自WGAN_G类。
def __init__(self, input_size, input_n=2):
super(CondWGAN_G, self).__init__(input_size, input_n)
self.labfc1 = nn.Linear(10, input_size)
def forward(self, x, lab): # 添加输入标签,batch, width, height, channel=1
d_in = torch.cat((x, self.labfc1(lab)), -1)
return super(CondWGAN_G, self).forward(d_in, lab)2.8関数を呼び出し、モデルをトレーニングします----WGAN_cond_237.py(パート6)
# 1.8 调用函数并训练模型:实例化判别器和生成器模型,并调用函数进行训练
if __name__ == '__main__':
z_dimension = 40 # 设置输入随机数的维度
D = CondWGAN_D().to(device) # 实例化判别器
G = CondWGAN_G(z_dimension).to(device) # 实例化生成器
train(D, G, './condw_img', z_dimension) # 训练模型
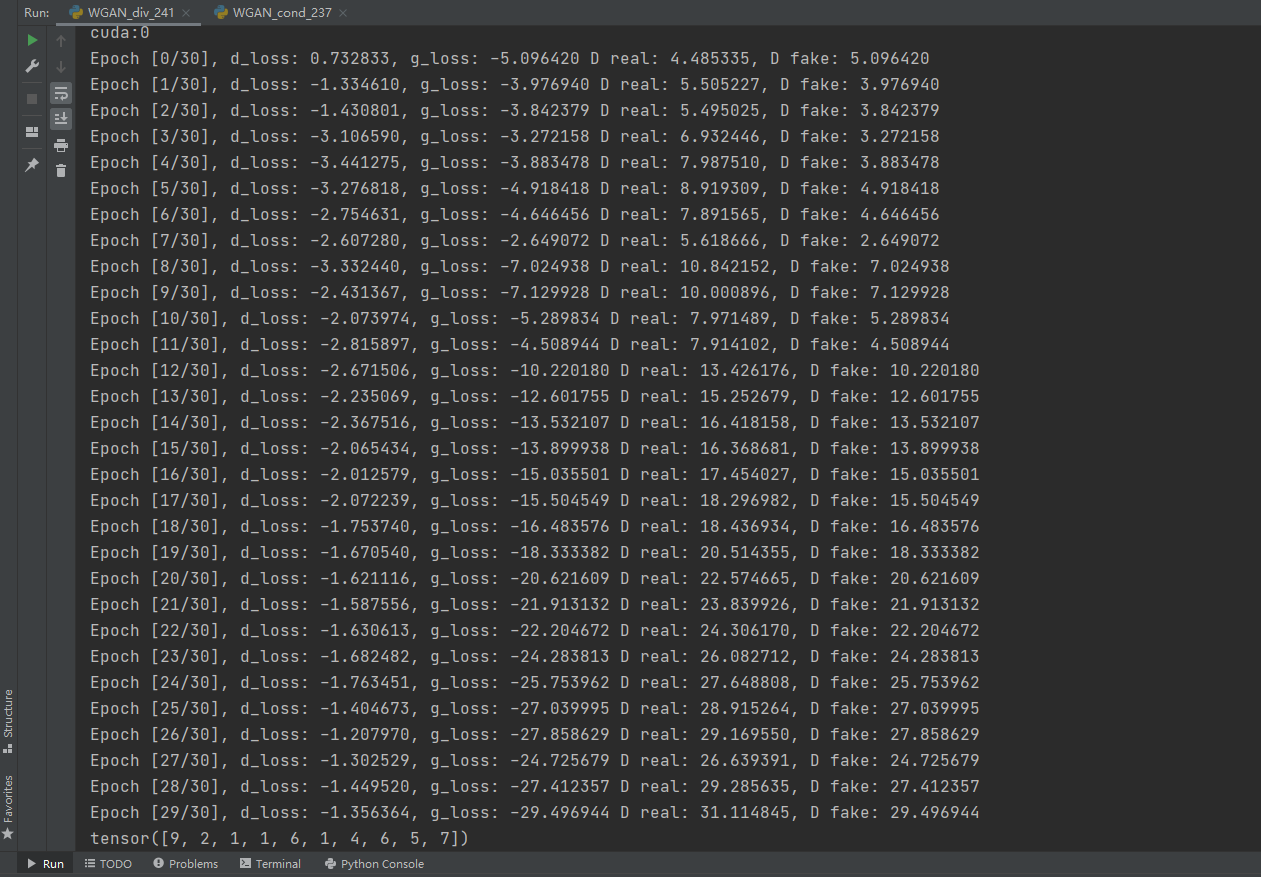
displayAndTest(D, G, z_dimension) # 输出可视化トレーニング後、モデルは視覚化の結果を出力します。図のように、行1は元のサンプルで、行2は出力されたシミュレートされたサンプルです。

同時に、プログラムは次のように、図8-20のサンプルに対応するクラスラベルも出力します。
tensor([9,2,1,1,6,1,4,6,5,7])
出力サンプルからわかるように、出力シミュレーションサンプルは元のサンプルと同じカテゴリであり、ジェネレータが指定されたラベルに従ってシミュレーションデータを生成できることを示しています。
3コードの概要(WGAN_cond_237.py)
import torch
import torchvision
from torchvision import transforms
from torch.utils.data import DataLoader
from torch import nn
import torch.autograd as autograd
import matplotlib.pyplot as plt
import numpy as np
import matplotlib
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
# 1.1 引入模块并载入样本:定义基本函数,加载FashionMNIST数据集
def to_img(x):
x = 0.5 * (x+1)
x = x.clamp(0,1)
x = x.view(x.size(0),1,28,28)
return x
def imshow(img,filename = None):
npimg = img.numpy()
plt.axis('off')
array = np.transpose(npimg,(1,2,0))
if filename != None:
matplotlib.image.imsave(filename,array)
else:
plt.imshow(array)
# plt.savefig(filename) # 保存图片 注释掉,因为会报错,暂时不知道什么原因 2022.3.26 15:20
plt.show()
img_transform = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize(mean=[0.5],std=[0.5])
]
)
data_dir = './fashion_mnist'
train_dataset = torchvision.datasets.FashionMNIST(data_dir,train=True,transform=img_transform,download=True)
train_loader = DataLoader(train_dataset,batch_size=1024,shuffle=True)
# 测试数据集
val_dataset = torchvision.datasets.FashionMNIST(data_dir,train=False,transform=img_transform)
test_loader = DataLoader(val_dataset,batch_size=10,shuffle=False)
# 指定设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
# 1.2 实现生成器和判别器 :因为复杂部分都放在loss值的计算方面了,所以生成器和判别器就会简单一些。
# 生成器和判别器各自有两个卷积和两个全连接层。生成器最终输出与输入图片相同维度的数据作为模拟样本。
# 判别器的输出不需要有激活函数,并且输出维度为1的数值用来表示结果。
# 在GAN模型中,因判别器的输入则是具体的样本数据,要区分每个数据的分布特征,所以判别器使用实例归一化,
class WGAN_D(nn.Module): # 定义判别器类D :有两个卷积和两个全连接层
def __init__(self,inputch=1):
super(WGAN_D, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(inputch,64,4,2,1), # 输出形状为[batch,64,28,28]
nn.LeakyReLU(0.2,True),
nn.InstanceNorm2d(64,affine=True)
)
self.conv2 = nn.Sequential(
nn.Conv2d(64,128,4,2,1),# 输出形状为[batch,64,14,14]
nn.LeakyReLU(0.2,True),
nn.InstanceNorm2d(128,affine=True)
)
self.fc = nn.Sequential(
nn.Linear(128*7*7,1024),
nn.LeakyReLU(0.2,True)
)
self.fc2 = nn.Sequential(
nn.InstanceNorm1d(1,affine=True),
nn.Flatten(),
nn.Linear(1024,1)
)
def forward(self,x,*arg): # 正向传播
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0),-1)
x = self.fc(x)
x = x.reshape(x.size(0),1,-1)
x = self.fc2(x)
return x.view(-1,1).squeeze(1)
# 在GAN模型中,因生成器的初始输入是随机值,所以生成器使用批量归一化。
class WGAN_G(nn.Module): # 定义生成器类G:有两个卷积和两个全连接层
def __init__(self,input_size,input_n=1):
super(WGAN_G, self).__init__()
self.fc1 = nn.Sequential(
nn.Linear(input_size * input_n,1024),
nn.ReLU(True),
nn.BatchNorm1d(1024)
)
self.fc2 = nn.Sequential(
nn.Linear(1024,7*7*128),
nn.ReLU(True),
nn.BatchNorm1d(7*7*128)
)
self.upsample1 = nn.Sequential(
nn.ConvTranspose2d(128,64,4,2,padding=1,bias=False), # 输出形状为[batch,64,14,14]
nn.ReLU(True),
nn.BatchNorm2d(64)
)
self.upsample2 = nn.Sequential(
nn.ConvTranspose2d(64,1,4,2,padding=1,bias=False), # 输出形状为[batch,64,28,28]
nn.Tanh()
)
def forward(self,x,*arg): # 正向传播
x = self.fc1(x)
x = self.fc2(x)
x = x.view(x.size(0),128,7,7)
x = self.upsample1(x)
img = self.upsample2(x)
return img
# 1.3 定义函数compute_gradient_penalty()完成梯度惩罚项
# 惩罚项的样本X_inter由一部分Pg分布和一部分Pr分布组成,同时对D(X_inter)求梯度,并计算梯度与1的平方差,最终得到gradient_penalties
lambda_gp = 10
# 计算梯度惩罚项
def compute_gradient_penalty(D,real_samples,fake_samples,y_one_hot):
# 获取一个随机数,作为真假样本的采样比例
eps = torch.FloatTensor(real_samples.size(0),1,1,1).uniform_(0,1).to(device)
# 按照eps比例生成真假样本采样值X_inter
X_inter = (eps * real_samples + ((1-eps)*fake_samples)).requires_grad_(True)
d_interpolates = D(X_inter,y_one_hot)
fake = torch.full((real_samples.size(0),),1,device=device) # 计算梯度输出的掩码,在本例中需要对所有梯度进行计算,故需要按照样本个数生成全为1的张量。
# 求梯度
gradients = autograd.grad(outputs=d_interpolates, # 输出值outputs,传入计算过的张量结果
inputs=X_inter,# 待求梯度的输入值inputs,传入可导的张量,即requires_grad=True
grad_outputs=fake, # 传出梯度的掩码grad_outputs,使用1和0组成的掩码,在计算梯度之后,会将求导结果与该掩码进行相乘得到最终结果。
create_graph=True,
retain_graph=True,
only_inputs=True
)[0]
gradients = gradients.view(gradients.size(0),-1)
gradient_penaltys = ((gradients.norm(2, dim=1) - 1) ** 2).mean() * lambda_gp
return gradient_penaltys
# 1.4 定义模型的训练函数
# 定义函数train(),实现模型的训练过程。
# 在函数train()中,按照对抗神经网络专题(一)中的式(8-24)实现模型的损失函数。
# 判别器的loss为D(fake_samples)-D(real_samples)再加上联合分布样本的梯度惩罚项gradient_penalties,其中fake_samples为生成的模拟数据,real_Samples为真实数据,
# 生成器的loss为-D(fake_samples)。
def train(D,G,outdir,z_dimension,num_epochs=30):
d_optimizer = torch.optim.Adam(D.parameters(),lr=0.001) # 定义优化器
g_optimizer = torch.optim.Adam(G.parameters(),lr=0.001)
os.makedirs(outdir,exist_ok=True) # 创建输出文件夹
# 在函数train()中,判别器和生成器是分开训练的。让判别器学习的次数多一些,判别器每训练5次,生成器优化1次。
# WGAN_gp不会因为判别器准确率太高而引起生成器梯度消失的问题,所以好的判别器会让生成器有更好的模拟效果。
for epoch in range(num_epochs):
for i,(img,lab) in enumerate(train_loader):
num_img = img.size(0)
# 训练判别器
real_img = img.to(device)
y_one_hot = torch.zeros(lab.shape[0],10).scatter_(1,lab.view(lab.shape[0],1),1).to(device)
for ii in range(5): # 循环训练5次
d_optimizer.zero_grad() # 梯度清零
# 对real_img进行判别
real_out = D(real_img,y_one_hot)
# 生成随机值
z = torch.randn(num_img,z_dimension).to(device)
fake_img = G(z,y_one_hot) # 生成fake_img
fake_out = D(fake_img,y_one_hot) # 对fake_img进行判别
# 计算梯度惩罚项
gradient_penalty = compute_gradient_penalty(D,real_img.data,fake_img.data,y_one_hot)
# 计算判别器的loss
d_loss = -torch.mean(real_out)+torch.mean(fake_out)+gradient_penalty
d_loss.backward()
d_optimizer.step()
# 训练生成器
for ii in range(1): # 训练一次
g_optimizer.zero_grad() # 梯度清0
z = torch.randn(num_img,z_dimension).to(device)
fake_img = G(z,y_one_hot)
fake_out = D(fake_img,y_one_hot)
g_loss = -torch.mean(fake_out)
g_loss.backward()
g_optimizer.step()
# 输出可视化结果,并将生成的结果以图片的形式存储在硬盘中
fake_images = to_img(fake_img.cpu().data)
real_images = to_img(real_img.cpu().data)
rel = torch.cat([to_img(real_images[:10]), fake_images[:10]], axis=0)
imshow(torchvision.utils.make_grid(rel, nrow=10),os.path.join(outdir, 'fake_images-{}.png'.format(epoch + 1)))
# 输出训练结果
print('Epoch [{}/{}], d_loss: {:.6f}, g_loss: {:.6f} ''D real: {:.6f}, D fake: {:.6f}'.format(epoch, num_epochs, d_loss.data, g_loss.data,real_out.data.mean(), fake_out.data.mean()))
# 保存训练模型
torch.save(G.state_dict(), os.path.join(outdir, 'cond_generator.pth'))
torch.save(D.state_dict(), os.path.join(outdir, 'cond_discriminator.pth'))
# 1.5 定义函数,实现可视化模型结果:获取一部分测试数据,显示由模型生成的模拟数据。
def displayAndTest(D,G,z_dimension): # 可视化结果
sample = iter(test_loader)
images, labels = sample.next()
y_one_hot = torch.zeros(labels.shape[0], 10).scatter_(1,labels.view(labels.shape[0], 1), 1).to(device)
num_img = images.size(0) # 获取样本个数
with torch.no_grad():
z = torch.randn(num_img, z_dimension).to(device) # 生成随机数
fake_img = G(z, y_one_hot)
fake_images = to_img(fake_img.cpu().data) # 生成模拟样本
rel = torch.cat([to_img(images[:10]), fake_images[:10]], axis=0)
imshow(torchvision.utils.make_grid(rel, nrow=10))
print(labels[:10])
# 1.6 定义判别器类CondWGAN_D
# 在判别器和生成器类的正向结构中,增加标签向量的输入,并使用全连接网络对标签向量的维度进行扩展,同时将其连接到输入数据。
class CondWGAN_D(WGAN_D): # 定义判别器类CondWGAN_D,使其继承自WGAN_D类。
def __init__(self, inputch=2):
super(CondWGAN_D, self).__init__(inputch)
self.labfc1 = nn.Linear(10, 28 * 28)
def forward(self, x, lab): # 添加输入标签,batch, width, height, channel=1
d_in = torch.cat((x.view(x.size(0), -1), self.labfc1(lab)), -1)
x = d_in.view(d_in.size(0), 2, 28, 28)
return super(CondWGAN_D, self).forward(x, lab)
# 1.7 定义生成器类CondWGAN_G
# 在判别器和生成器类的正向结构中,增加标签向量的输入,并使用全连接网络对标签向量的维度进行扩展,同时将其连接到输入数据。
class CondWGAN_G(WGAN_G): # 定义生成器类CondWGAN_G,使其继承自WGAN_G类。
def __init__(self, input_size, input_n=2):
super(CondWGAN_G, self).__init__(input_size, input_n)
self.labfc1 = nn.Linear(10, input_size)
def forward(self, x, lab): # 添加输入标签,batch, width, height, channel=1
d_in = torch.cat((x, self.labfc1(lab)), -1)
return super(CondWGAN_G, self).forward(d_in, lab)
# 1.8 调用函数并训练模型:实例化判别器和生成器模型,并调用函数进行训练
if __name__ == '__main__':
z_dimension = 40 # 设置输入随机数的维度
D = CondWGAN_D().to(device) # 实例化判别器
G = CondWGAN_G(z_dimension).to(device) # 实例化生成器
train(D, G, './condw_img', z_dimension) # 训练模型
displayAndTest(D, G, z_dimension) # 输出可视化