クラスメートの皆さん、今日は、CNN畳み込みニューラルネットワークでの注意メカニズムの適用について、3つの注意メカニズムとそのコード再現に焦点を当てて共有します。
ニューラルネットワークのコラムの以前の記事でも注意メカニズムを使用しました。たとえば、SE注意メカニズムはMobileNetV3およびEfficientNetネットワークで使用されています。興味がある場合は、 https://blogを参照してください。 csdn.net/dgvv4/category_11517910.html。それで、今日は注意のメカニズムについてお話します。
1はじめに
注意メカニズムは、人間の視覚の研究に由来します。認知科学では、情報処理のボトルネックにより、人間は他の目に見える情報を無視しながら、すべての情報の一部に選択的に焦点を合わせます。限られた視覚情報処理資源を合理的に利用するためには、人間は視覚野の特定の部分を選択し、それに集中する必要があります。
従来の局所画像特徴抽出、スライディングウィンドウ法などの注意メカニズムの厳密な数学的定義はなく、注意メカニズムと見なすことができます。ニューラルネットワークでは、注意メカニズムは通常、入力の特定の部分をハード選択したり、入力のさまざまな部分にさまざまな重みを割り当てたりできる追加のニューラルネットワークです。アテンションメカニズムは、大量の情報から重要な情報を除外できます。
ニューラルネットワークに注意メカニズムを導入する方法はたくさんあります。畳み込みニューラルネットワークを例にとると、注意メカニズムを空間次元に導入でき、注意メカニズム(SE)をチャネル次元に追加することもできます。もちろん、また、混合次元(CBAM)。)、つまり、空間次元とチャネル次元は注意メカニズムを増加させます。
2.SENetアテンションメカニズム
2.1メソッドの紹介
SEアテンションメカニズム(Squeeze-and-Excitation Networks)は、チャネル次元のアテンションメカニズムを強化し、主要な操作はスクイーズと励起です。
自動学習、つまり別の新しいニューラルネットワークを使用して、特徴マップの各チャネルの重要度を取得し、この重要度を使用して各特徴に重み値を割り当て、ニューラルネットワークが特定の特徴に焦点を合わせることができるようにします。チャネル。現在のタスクに役立つ機能マップのチャネルをブーストし、現在のタスクに役立たない機能チャネルを抑制します。
下の図に示すように、SEアテンションメカニズム(左側の白い画像C2)に入る前は、特徴マップの各チャネルの重要性は同じです。SENet(右側のカラー画像C2)を通過した後、異なる色異なる表現重みは各特徴チャネルの重要性を異なるものにするため、ニューラルネットワークは大きな重み値を持つ特定のチャネルに焦点を合わせます。
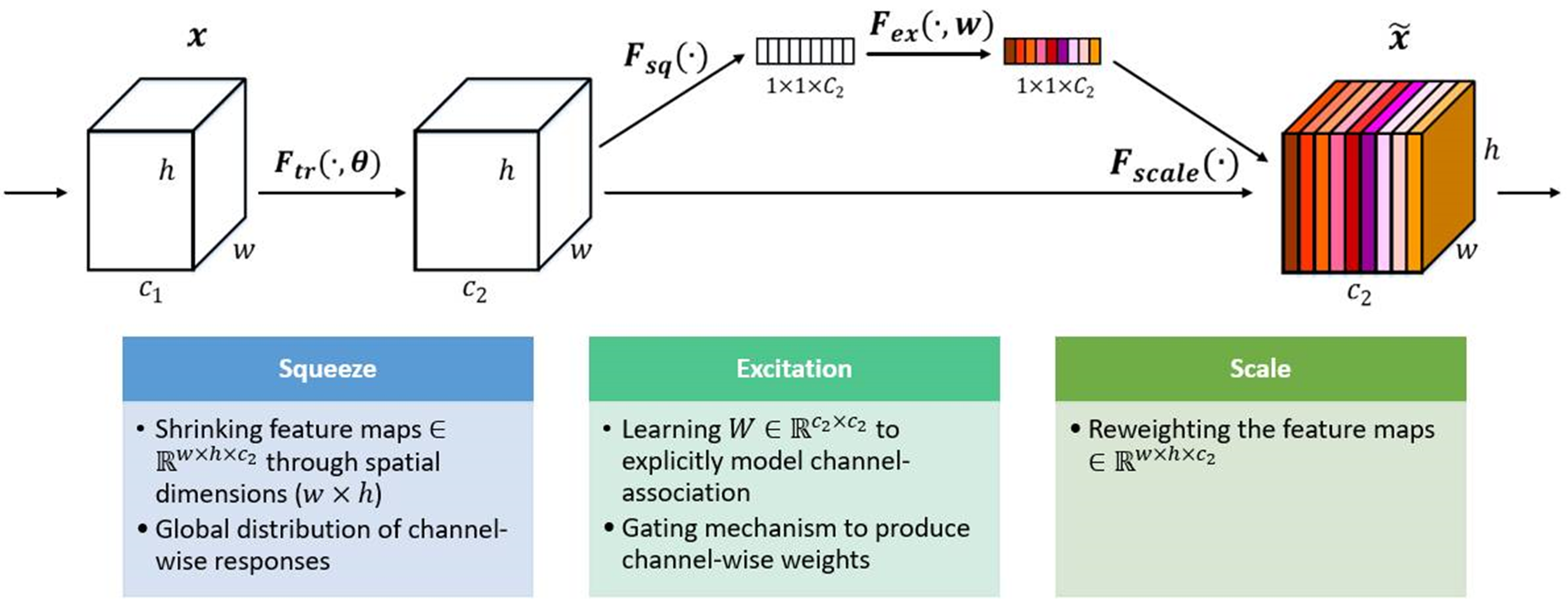
2.2実装プロセス:
(1)スクイーズ(Fsq):グローバル平均プーリングにより、各チャネルの2次元特徴(H * W)が1つの実数に圧縮され、特徴マップが[h、w、c]==>から変更されます。 [1、1、c]
(2)励起(Fex):各特徴チャネルの重み値を生成します。この論文では、チャネル間の相関は、完全に接続された2つのレイヤーを介して構築されます。出力重み値の数は、入力特徴マップ。[1,1、c] ==> [1,1、c]
(3)スケール(Fscale) :以前に取得した正規化された重みを各チャネルの特徴に重み付けします。この論文では乗算が使用されており、重み係数はチャネルごとに乗算されます。[h、w、c] * [1,1、c] ==> [h、w、c]
以下では、EfficientNetのSEアテンションメカニズムを使用して、このプロセスを説明します。
スクイーズ操作:特徴マップはグローバル平均プーリングの対象となり、特徴マップは特徴ベクトル[1,1、c]に圧縮されます。
励起操作: FC1層+スウィッシュ活性化+FC2層+シグモイド活性化。完全に接続されたレイヤー(FC1)を介して、特徴マップベクトルのチャネル次元が元の1 / r、つまり[1,1、c * 1 / r]に縮小され、次にSwishアクティベーション関数を介して、次にを介して完全に接続された層(FC2)の場合、特徴マップベクトルの特徴マップは元の[1,1、c]に戻され、シグモイド関数を介して0-1の間の正規化された重みベクトルに変換されます。
スケール操作:正規化された重みと元の入力特徴マップチャネルをチャネルごとに乗算して、重み付き特徴マップを生成します。
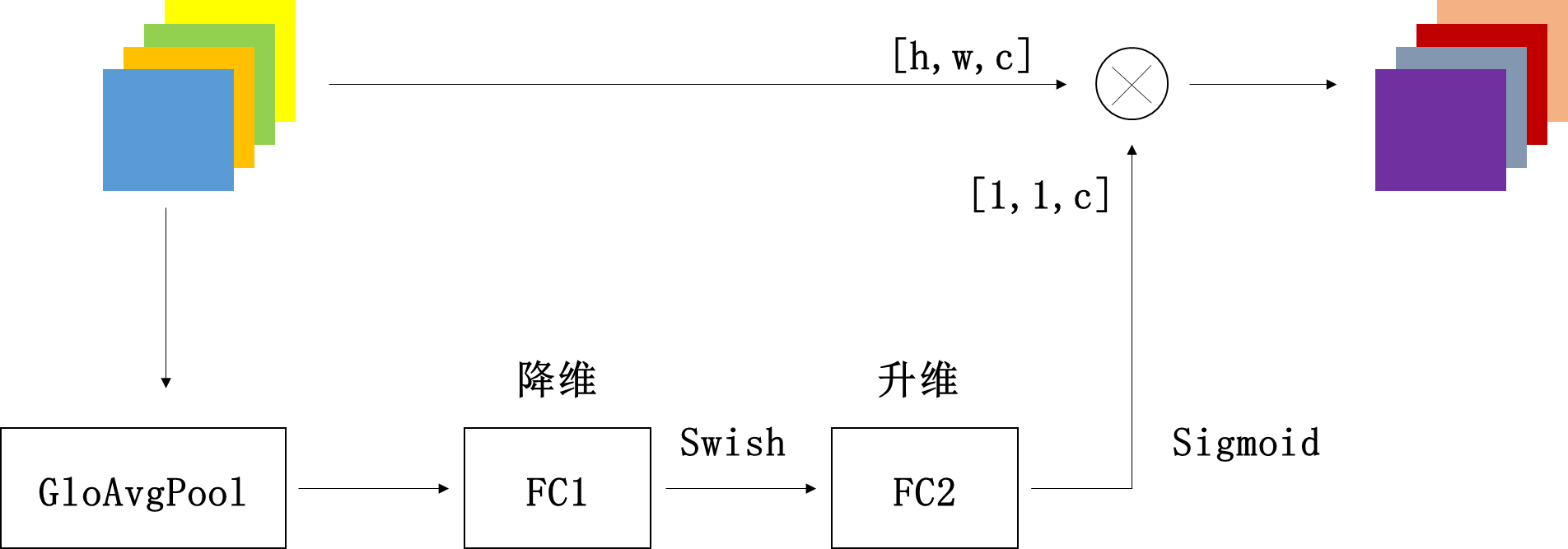
セクション:
(1)SENetのコアアイデアは、機能チャネルの数値分布に従って直接判断するのではなく、完全に接続されたネットワークを介して損失損失に応じて機能の重みを自動的に学習することです。これにより、有効な機能の重みがチャネルが大きい。もちろん、SEアテンションメカニズムは必然的にいくつかのパラメータと計算量を増やしますが、コストパフォーマンスは依然としてかなり高いです。
(2)この論文は、励起操作で2つの完全に接続された層を使用する利点は、1つの完全に接続された層を直接使用する場合と比較して、非線形性が高く、チャネル間の複雑な相関をより適切に適合できることであると考えています。
2.3コードの複製
import tensorflow as tf
from tensorflow.keras import layers, Model, Input
# se注意力机制
def se_block(inputs, ratio=4): # ratio代表第一个全连接层下降通道数的系数
# 获取输入特征图的通道数
in_channel = inputs.shape[-1]
# 全局平均池化[h,w,c]==>[None,c]
x = layers.GlobalAveragePooling2D()(inputs)
# [None,c]==>[1,1,c]
x = layers.Reshape(target_shape=(1,1,in_channel))(x)
# [1,1,c]==>[1,1,c/4]
x = layers.Dense(in_channel//ratio)(x) # 全连接下降通道数
# relu激活
x = tf.nn.relu(x)
# [1,1,c/4]==>[1,1,c]
x = layers.Dense(in_channel)(x) # 全连接上升通道数
# sigmoid激活,权重归一化
x = tf.nn.sigmoid(x)
# [h,w,c]*[1,1,c]==>[h,w,c]
outputs = layers.multiply([inputs, x]) # 归一化权重和原输入特征图逐通道相乘
return outputs
# 测试SE注意力机制
if __name__ == '__main__':
# 构建输入
inputs = Input([56,56,24])
x = se_block(inputs) # 接收SE返回值
model = Model(inputs, x) # 构建网络模型
print(x.shape) # (None, 56, 56, 24)
model.summary() # 输出SE模块的结构SEモジュールの構造フレームワークを表示する
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 56, 56, 24)] 0
__________________________________________________________________________________________________
global_average_pooling2d (Globa (None, 24) 0 input_1[0][0]
__________________________________________________________________________________________________
reshape (Reshape) (None, 1, 1, 24) 0 global_average_pooling2d[0][0]
__________________________________________________________________________________________________
dense (Dense) (None, 1, 1, 6) 150 reshape[0][0]
__________________________________________________________________________________________________
tf.nn.relu (TFOpLambda) (None, 1, 1, 6) 0 dense[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 1, 1, 24) 168 tf.nn.relu[0][0]
__________________________________________________________________________________________________
tf.math.sigmoid (TFOpLambda) (None, 1, 1, 24) 0 dense_1[0][0]
__________________________________________________________________________________________________
multiply (Multiply) (None, 56, 56, 24) 0 input_1[0][0]
tf.math.sigmoid[0][0]
==================================================================================================
Total params: 318
Trainable params: 318
Non-trainable params: 0
__________________________________________________________________________________________________3.ECANetアテンションメカニズム
3.1メソッドの紹介
ECANetはチャネルアテンションメカニズムの実装であり、ECANetはSENetの改良版と見なすことができます。
著者は、SENetの次元削減がチャネル注意メカニズムに副作用をもたらすこと、およびすべてのチャネル間の依存関係をキャプチャすることは非効率的で不必要であることを示しています。
ECAアテンションメカニズムモジュールは、グローバル平均プーリング層の直後に1x1畳み込み層を使用し、完全に接続された層を削除します。このモジュールは、次元削減を回避し、チャネル間の相互作用を効果的にキャプチャします。また、ECAには、良好な結果を達成するためのいくつかのパラメーターのみが含まれます。
ECANetは、 1次元の畳み込みレイヤーを介してクロスチャネル情報の相互作用を完了します。Conv1D。畳み込みカーネルのサイズは、関数を介して適応的に変更されるため、チャネル数が多いレイヤーは、より多くのクロスチャネル相互作用を実行できます。適応関数は次のとおりです。 、ここで

3.2実装プロセス
(1)入力された特徴マップはグローバル平均プーリングの対象となり、特徴マップは[h、w、c]の行列から[1,1、c]のベクトルに変化します。
(2)適応型1次元畳み込みカーネルサイズkernel_sizeを計算します
(3)1次元畳み込みでkernel_sizeを使用して、特徴マップの各チャネルの重みを取得します
(4)正規化された重みと元の入力特徴マップチャネルをチャネルごとに乗算して、重み付き特徴マップを生成します
3.3コードの実装
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import Model, layers
import math
def eca_block(inputs, b=1, gama=2):
# 输入特征图的通道数
in_channel = inputs.shape[-1]
# 根据公式计算自适应卷积核大小
kernel_size = int(abs((math.log(in_channel, 2) + b) / gama))
# 如果卷积核大小是偶数,就使用它
if kernel_size % 2:
kernel_size = kernel_size
# 如果卷积核大小是奇数就变成偶数
else:
kernel_size = kernel_size + 1
# [h,w,c]==>[None,c] 全局平均池化
x = layers.GlobalAveragePooling2D()(inputs)
# [None,c]==>[c,1]
x = layers.Reshape(target_shape=(in_channel, 1))(x)
# [c,1]==>[c,1]
x = layers.Conv1D(filters=1, kernel_size=kernel_size, padding='same', use_bias=False)(x)
# sigmoid激活
x = tf.nn.sigmoid(x)
# [c,1]==>[1,1,c]
x = layers.Reshape((1,1,in_channel))(x)
# 结果和输入相乘
outputs = layers.multiply([inputs, x])
return outputs
# 验证ECA注意力机制
if __name__ == '__main__':
# 构造输入层
inputs = keras.Input(shape=[26,26,512])
x = eca_block(inputs) # 接收ECA输出结果
model = Model(inputs, x) # 构造模型
model.summary() # 查看网络架构ECAモジュールを見ると、パラメーターの量はSENetと比較して大幅に削減されており、パラメーターの量は1次元畳み込みのkernel_sizeのサイズと同じです。
Model: "model_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_2 (InputLayer) [(None, 26, 26, 512) 0
__________________________________________________________________________________________________
global_average_pooling2d_1 (Glo (None, 512) 0 input_2[0][0]
__________________________________________________________________________________________________
reshape_1 (Reshape) (None, 512, 1) 0 global_average_pooling2d_1[0][0]
__________________________________________________________________________________________________
conv1d (Conv1D) (None, 512, 1) 5 reshape_1[0][0]
__________________________________________________________________________________________________
tf.math.sigmoid_1 (TFOpLambda) (None, 512, 1) 0 conv1d[0][0]
__________________________________________________________________________________________________
reshape_2 (Reshape) (None, 1, 1, 512) 0 tf.math.sigmoid_1[0][0]
__________________________________________________________________________________________________
multiply_1 (Multiply) (None, 26, 26, 512) 0 input_2[0][0]
reshape_2[0][0]
==================================================================================================
Total params: 5
Trainable params: 5
Non-trainable params: 0
__________________________________________________________________________________________________