下のカードをクリックして、「 CVer」パブリックアカウントをフォローしてください
AI / CVの重い乾物、できるだけ早く配達
転載元:Heart of the Machine
最近、コンピュータービジョンのトップ会議であるCVPR 2022が会議の入会結果を発表し、美図秀秀研究所(MTラボ)と北漢大学コーララボ(CoLab)が共同で発表した論文が受理されました。この論文は、挑戦的な複数人の3D人間の姿勢推定問題を解決するための分散認識シングルステージモデルを画期的に提案します。この方法は、ネットワーク前向き推論を介して3D空間内の人体位置情報と対応するキーポイント情報を同時に取得することにより、予測プロセスを簡素化し、効率を向上させます。さらに、このメソッドは人間のキーポイントの真の分布を効果的に学習します。これにより、回帰ベースのフレームワークの精度が向上します。
マルチパーソン3Dポーズ推定は、現在注目されている研究テーマであり、幅広い応用の可能性もあります。コンピュータビジョンでは、単一のRGB画像に基づく複数人の3D人物ポーズ推定の問題は、通常、トップダウンまたはボトムアップの2段階法によって解決されますが、2段階法には多くの冗長性があります。計算と複雑後処理の効率が低いことが批判されています。また、既存の手法は人間の姿勢データの分布に関する知識が不足しているため、2D画像から3D位置までの不適切な問題を正確に解決することはできません。上記の2つの点は、実際のシナリオでの既存の手法の適用を制限します。
Meitu Imaging Research Institute(MT Lab)とBeihangUniversityのColaLab(CoLab)がCVPR 2022で発表した論文は、分散型の単一ステージモデルを提案し、このモデルを使用して単一のRGB画像から複数のレベルを推定します。 3Dカメラ空間の個人。
この方法では、3D人体ポーズを2.5D人体中心点と3Dキーポイントオフセットとして表現し、画像空間の深度推定に適応させます。同時に、この表現は人体位置情報と対応するキーポイント情報により、単段多人3Dポーズ推定が可能になります。

紙のアドレス:https://arxiv.org/abs/2203.07697
さらに、このメソッドは、モデル最適化プロセス中に人間のキーポイントの分布を学習します。これにより、キーポイントの位置の回帰予測に重要なガイダンス情報が提供され、回帰ベースのフレームワークの精度が向上します。この分布学習モジュールは、トレーニングプロセス中の最尤推定を通じてポーズ推定モジュールと一緒に学習でき、モデル推論の計算負荷を増やすことなく、テストプロセス中にモジュールを削除します。人間のキーポイントの分布を学習することの難しさを減らすために、この方法は、ターゲット分布に徐々に近づくための反復更新戦略を革新的に提案します。
モデルは完全に畳み込み方式で実装され、エンドツーエンドでトレーニングおよびテストできます。このようにして、アルゴリズムは、2段階法に近い精度を達成しながら、速度を大幅に向上させながら、複数人の3D人物ポーズ推定問題を効果的かつ正確に解決できます。
バックグラウンド
複数人の3D人間のポーズ推定は、コンピュータービジョンの典型的な問題であり、AR / VR、ゲーム、モーション分析、仮想フィッティングなどで広く使用されています。近年、メタバースの概念が台頭し、この技術が注目を集めています。現在、この問題を解決するために、通常、2段階の方法が使用されます。トップダウン法、つまり、画像内の複数の人体の位置が最初に検出され、次に1人の3Dポーズ推定モデルが使用されます。検出された各人物がそのポーズを予測するために;上向きの方法は、最初に画像内のすべての人物の3Dキーポイントを検出し、次にこれらのキーポイントを相関によって対応する人体に割り当てることです。
2段階方式は精度は高いものの、冗長な計算と複雑な後処理により人体位置情報と要点位置情報を順次取得する必要があるため、実際のシナリオの展開要件を満たすことは通常困難であり、多くの場合人間の3Dポーズ推定のアルゴリズムプロセスを単純化する必要があります。
一方、データ分布に関する事前の知識がない場合に、単一のRGB画像から3Dキーポイントの位置、特に深度情報を推定することは、悪条件の問題です。このため、2Dシーンに適用される従来の1ステージモデルを3Dシーンに直接拡張することはできません。したがって、3Dキーポイントのデータ分布を学習して取得することが、高精度の複数人の3D人間ポーズ推定の鍵となります。
上記の問題を克服するために、本論文は、単一の画像に基づく複数人の3D人間の姿勢推定の不適切な問題を解決するために、分布を意識した単一ステージモデル(DAS)を提案する。DASモデルは、3D人間のポーズを2.5D人間の中心点および3D人間のキーポイントオフセットとして表します。これは、RGB画像ドメインに基づく深度情報予測を効果的に適応させます。同時に、人体位置情報と要点位置情報を統合し、単眼画像から単段多人3Dポーズを推定することができます。
さらに、DASモデルは、最適化プロセス中に3Dキーポイントの分布を学習します。これにより、3Dキーポイントの回帰に関する貴重なガイダンス情報が提供され、予測精度が効果的に向上します。さらに、キーポイントの分布を推定することの難しさを軽減するために、DASモデルは反復更新戦略を採用して実際の分布ターゲットに徐々に近づきます。このようにして、DASモデルは単眼RGBから複数のデータを効率的かつ正確に取得できます。一度に画像。個々の3D人間のポーズ推定結果。
単段多人3Dポーズ推定モデル
実装に関しては、DASモデルは回帰予測フレームワークに基づいて構築されます。DASモデルは、特定の画像について、前方予測を通じて画像に含まれる人物の3D人間のポーズを出力します。DASモデルは、図1(a)および(b)に示すように、人体の中心点を中心点信頼マップおよび中心点座標マップとして表します。
その中で、DASモデルは、中心点信頼マップを使用して2D画像座標系での人体投影中心点の位置を特定し、中心点座標マップを使用して、 3Dカメラ座標系。DASモデルは、図1(c)に示すように、人体のキーポイントをキーポイントオフセットマップとしてモデル化します。
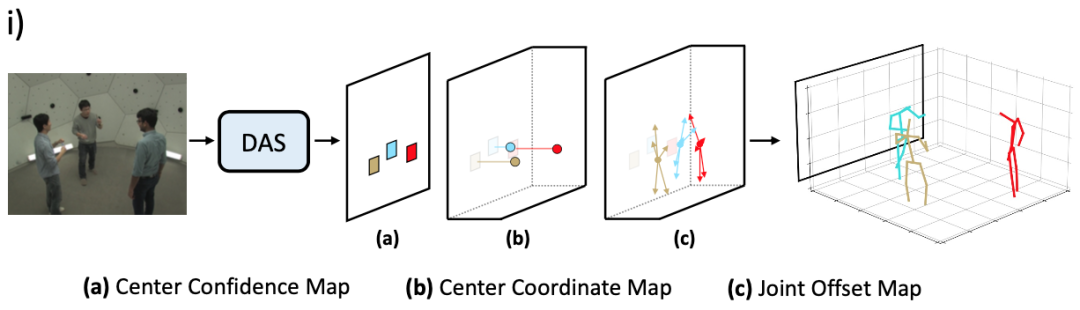
図1:複数人の3D人間のポーズ推定のための分散認識シングルステージモデルのフローチャート。
DASモデルは、中心点の信頼マップをバイナリマップとしてモデル化し、マップ内の各ピクセルは、人体の中心点がその位置に表示されるかどうかを示します。表示される場合は1、それ以外の場合は0です。DASモデルは、中心点座標マップを密なマップとしてモデル化します。マップ内の各ピクセルは、その位置に表示される文字の中心のx、y、およびz座標をエンコードします。キーポイントオフセットマップは、中心点座標マップと同様の方法でモデル化されます。マップ内の各ピクセルは、x、y、z方向の人体中心点に対するその位置での人体キーポイントのオフセットをエンコードします。DASモデルは、ネットワーク転送プロセスで上記の3つの情報グラフを並行して出力できるため、冗長な計算を回避できます。
さらに、DASモデルは、これら3つの情報マップを使用して複数の人物の3Dポーズを簡単に再構築でき、複雑な後処理手順を回避できます。2ステージ方式と比較して、このようなコンパクトでシンプルな1ステージモデルは、より多くのことを実現できます。優れた効率。
分布を意識した学習モデル
回帰予測フレームワークの最適化のために、既存の作業は主に従来のL1またはL2損失関数を使用しますが、この種の教師ありトレーニングは、実際には人体の要点のデータ分布の仮定に基づいていることがわかりました。ラプラス分布またはガウス分布を満たします。モデルの最適化を実行しました[12]。ただし、実際のシナリオでは、人間のキーポイントの実際の分布は非常に複雑であり、上記の単純な仮定は実際の分布からはほど遠いものです。
既存の方法とは異なり、DASモデルは、最適化プロセス中に3D人体キーポイント分布の真の分布を学習し、キーポイント回帰予測のプロセスをガイドします。図2に示すように、実際の分布が追跡できないという問題を考慮して、DASモデルは正規化フローを使用してモデル予測結果の確率推定の目標を達成し、モデル出力に適した分布を生成します。
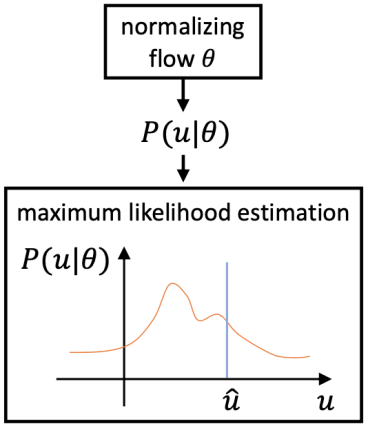
図2:正規化されたフロー。
分布認識モジュールは、トレーニングプロセス中に最尤推定法を介してキーポイント予測モジュールと一緒に学習できます。学習が完了すると、分布認識モジュールは予測プロセスで削除されます。このような分布認識モジュールは、アルゴリズムは、余分な計算を追加することなく、回帰予測モデルの精度を向上させることができます。
また、人体のキーポイント予測に使用する特徴は、人体の中心点で抽出されます。この特徴は、中心点から遠く離れた人体のキーポイントの表現能力が弱く、ターゲットの空間的不整合が原因となります。予測に大きな誤差があります。この問題を軽減するために、アルゴリズムは反復更新戦略を提案します。これは、図3に示すように、履歴更新結果を開始点として使用し、中間結果の近くの予測値を統合して、最終目標に徐々に近づきます。
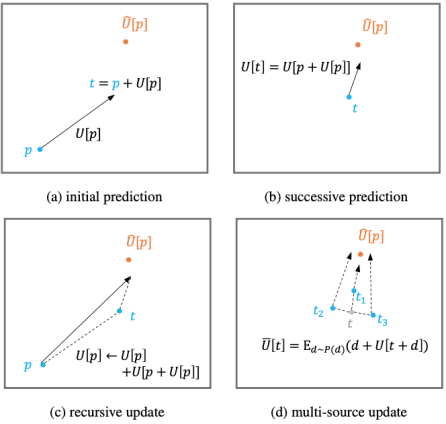
図3:反復最適化戦略。
アルゴリズムモデルは完全畳み込みネットワーク(FCN)によって実装され、図4に示すように、トレーニングとテストの両方のプロセスをエンドツーエンドで実行できます。
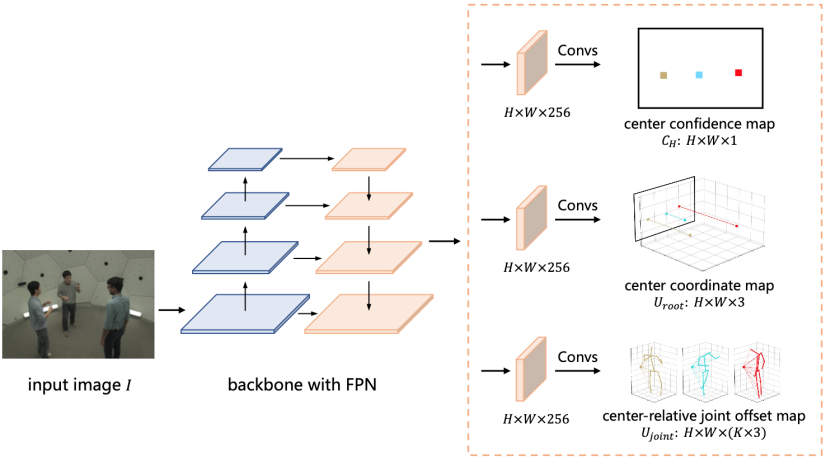
図4:分散対応のシングルステージマルチパーソン3D人間ポーズ推定ネットワーク構造。
実験結果によると、図5に示すように、既存の最先端の2ステージ方式と比較して、シングルステージアルゴリズムは、ほぼまたはそれ以上の精度を達成でき、速度を大幅に向上させることができます。それが多くの問題を解決できることを証明します。人間の3D人間の姿勢推定の問題における優位性。
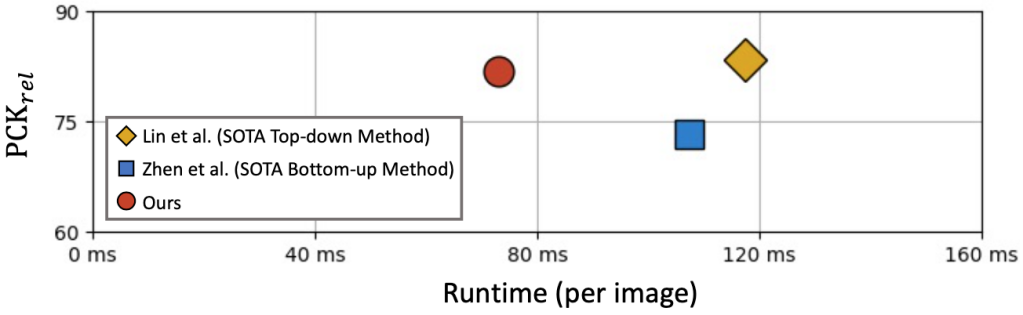
図5:既存のSOTA2ステージアルゴリズムとの比較結果。
詳細な実験結果は表1および2に記載されています。
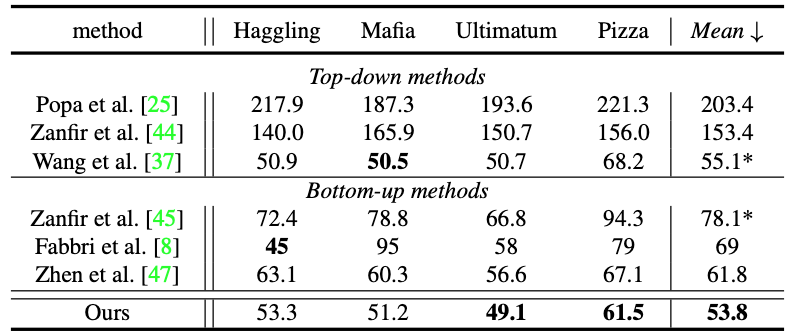
表1:CMUPanopticStudioデータセットの結果の比較。
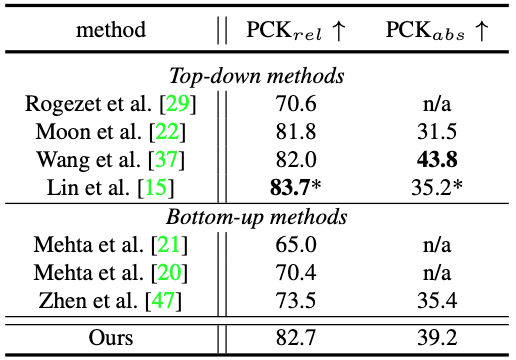
表2:MuPoTS-3Dデータセットの結果の比較。
図6に示すように、シングルステージアルゴリズムの視覚化結果によると、アルゴリズムは、ポーズの変更、人体の切り捨て、背景の乱雑さなどのさまざまなシナリオに適応して、正確な予測結果を生成できます。これにより、堅牢性がさらに示されます。アルゴリズムの。
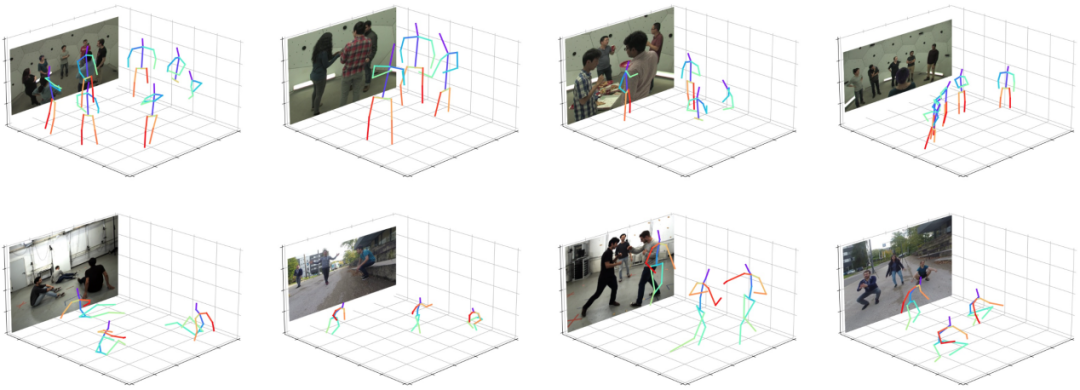
図6:結果の視覚化。
要約する
この論文では、MeituとBeihang大学の研究者が、困難な複数人の3D人間の姿勢推定問題を解決するために、分散型対応の単一ステージモデルを革新的に提案します。既存のトップダウンおよびボトムアップの2ステージモデルと比較して、このモデルは、1つのネットワーク前向き推論を通じて人体位置情報と対応する人体要点位置情報を同時に取得できるため、予測プロセスを効果的に簡素化できます。高い計算コストと高いモデルの複雑さという点で、既存の方法の欠点を克服します。
さらに、この方法は、標準化されたフローを複数人の3D人間ポーズ推定タスクにうまく導入して、トレーニングプロセス中に人間のキーポイント分布を学習し、分布学習の難しさを緩和して徐々に目標に近づくための反復回帰戦略を提案します。 。このようにして、アルゴリズムはデータの真の分布を取得して、モデルの回帰予測の精度を効果的に向上させることができます。
研究チーム
この論文は、Meitu Imaging Research Institute(MT Lab)とBeijing University of Aeronautics and Astronautics(CoLab)の研究者によって共同で提案されています。Meitu Imaging Research Institute(MT Lab)は、コンピュータービジョン、機械学習、拡張現実、クラウドコンピューティングなどの分野でのアルゴリズム研究、エンジニアリング開発、製品化を専門とするMeituのチームであり、コアアルゴリズムのサポートを提供し、切断を通じてMeitu製品の開発を促進します。 -エッジテクノロジー。「Meituテクノロジーセンター」として知られています。CVPR、ICCV、ECCVなどのトップ国際コンピュータービジョン会議に何度も参加し、10回以上の1位と2位の賞を受賞しています。
引用:
[1] JP Agnelli、M Cadeiras、Esteban G Tabak、Cristina Vilma Turner、およびEricVanden-Eijnden。特徴空間の流れを正規化することによるクラスタリングと分類。マルチスケールモデリングとシミュレーション、2010年。
[12] Jiefeng Li、Siyuan Bian、Ailing Zeng、Can Wang、Bo Pang、Wentao Liu、Cewu Lu。残差対数尤度推定による人間のポーズ回帰。ICCV、2021年。
[15]JiahaoLinとGimHeeLee。Hdnet:複数人のカメラ空間の位置特定のための人間の深度推定。ECCVでは、2020年。
[47] Jianan Zhen、Qi Fang、Jiaming Sun、Wentao Liu、Wei Jiang、Hujun Bao、Xiaowei Zhou。Smap:単発の複数人の絶対3Dポーズ推定。ECCV、2020年。
[48] Xingyi Zhou、Dequan Wang、PhilippKrähenbühl。ポイントとしてのオブジェクト。arXiv preprint arXiv:1904.07850、2019。
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-人体姿态估计交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-人体姿态估计 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如人体姿态估计+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看