下のカードをクリックして、「 CVer」パブリックアカウントをフォローしてください
AI / CVの重い乾物、できるだけ早く配達
Fengseは凹面の寺院からのものであり、次の
ものから複製されます:qubit(QbitAI)
NLPの分野における「新しい最愛の人」としての迅速な調整は、NLP事前トレーニングの新しいパラダイムとして学者からも称賛されました。
それで、それはCVフィールドから借りて、同じ結果を生み出すことができますか?
現在、コーネル大学やMeta AIなどの機関から、Promptを使用してTransformerベースのビジョンモデルを調整した結果、次のことがわかりました。
絶対に大丈夫!

ビジュアルプロンプトチューニング
論文:https://arxiv.org/abs/2203.12119
完全な微調整と比較して、Promptのパフォーマンスは大幅に向上しています。モデルのサイズとトレーニングデータに関係なく、24のケースのうち20が完全に勝ちます。
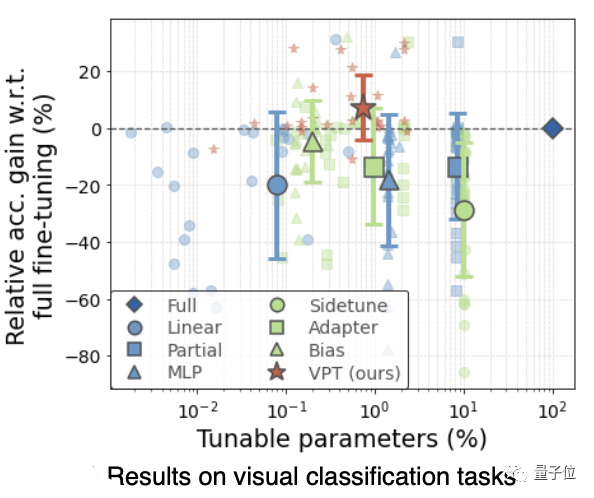
同時に、各タスクに必要なストレージコストを大幅に削減できます。

モデルパラメータの1%未満を使用します
誰もが常に使用している完全な微調整には、ダウンストリームタスクごとにバックボーンパラメータの個別のコピーを保存して展開する必要があります。特に、Transformerベースのモデルがどんどん大きくなり、それを超えているため、コストが高すぎます。 CNNアーキテクチャ。
いわゆるプロンプトは、元々、入力テキスト内の言語命令の事前プログラミングを指します。これにより、事前にトレーニングされた言語モデルは、さまざまなダウンストリームタスクを直接理解できます。
これにより、サンプルが少ないかゼロの場合でも、GPT-3は強力な一般化を示すことができます。
最近のいくつかの結果は、プロンプトが完全に微調整されたパフォーマンスに匹敵し、パラメーターストレージが1000分の1に削減されることを示しています。
NLPの高性能により、多くの人々がCVの分野でプロンプトの魔法を探求するようになりましたが、それらはクロスモーダルタスクでのテキストエンコーダーの入力に制限されています。
この論文では、著者は提案されたビジュアルプロンプトチューニング方法、または略してVPTを参照します。誰もがビジョンモデルのバックボーンにプロンプトを適用して結果を達成したのはこれが初めてです。
具体的には、完全な微調整と比較して、VPTは最新の大規模なNLPモデル調整方法に触発されており、特定のタスク用にトレーニングできる少数のパラメーター(モデルパラメーターの1%未満)のみを導入します。下流のタスクをトレーニングしている間、入力スペース。事前にトレーニングされたモデルのバックボーンをフリーズします。
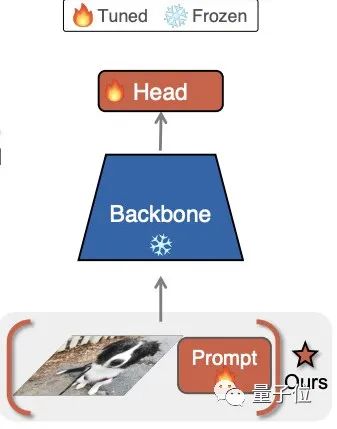
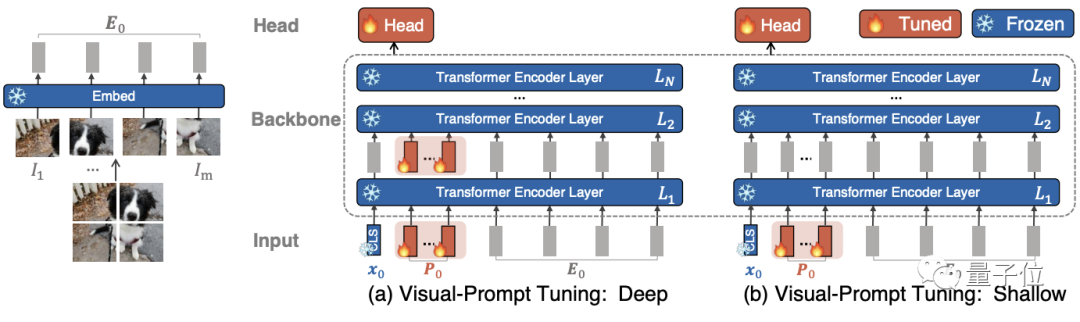
実際には、これらの追加パラメーターは、各Transformerレイヤーの入力シーケンスに事前に追加され、微調整中にリニアヘッドと一緒に学習されます。
合計で、彼らは2つのバリアントを調査しました。
VPT-Deepバリアントは、Transformerエンコーダーの各レイヤーの入力用に学習可能なパラメーターのセットを事前設定します。
VPT-Shallowバリアントは、最初のレイヤーの入力にヒントパラメーターのみを挿入します。
ダウンストリームタスクのトレーニング中は、タスク固有のキューとリニアヘッドのパラメーターのみが更新され、Transformerエンコーダー全体がフリーズします。
次に、ラバですか、それとも馬ですか?押し出す
20/24勝率
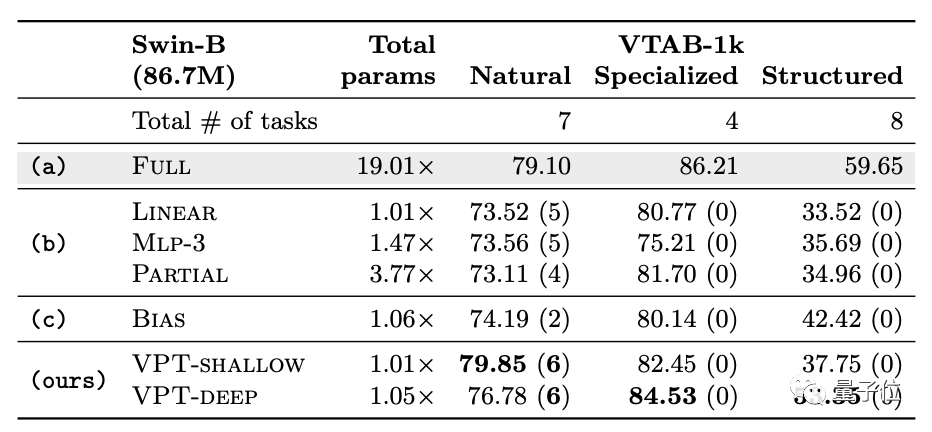
実験には、ImageNet-21kで事前トレーニングされた2つのバックボーンが含まれます。1つはVision Transformerからのもので、もう1つはSwinTransformerからのものです。
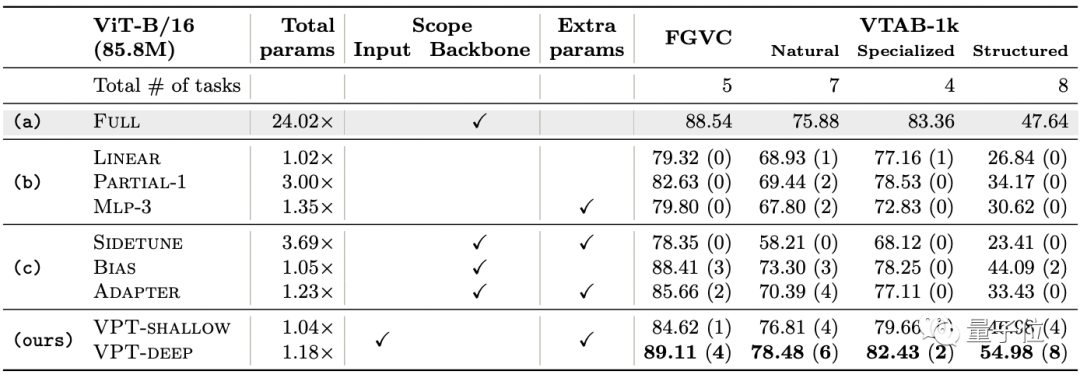
比較のための微調整方法は3種類あり、次の7種類があります。
(1)完全な微調整:すべてのバックボーンと分類ヘッドのパラメーターを更新します
(2)線形、部分k、Mlp-kを含む分類ヘッドに焦点を当てた微調整。
(3)バックボーンパラメータのサブセットを更新する方法、または微調整中にバックボーンに新しいトレーニング可能なパラメータを追加する方法。これらは、サイドチューン、バイアス、およびアダプタの3つのタイプに分けられます。

実験データセットには2つのセットがあり、次のような異なるドメインにわたる合計24のダウンストリーム認識タスクが含まれます。
(1)FGVCは、5つのベンチマークのきめ細かい視覚的分類タスクで構成されています。
(2)VTAB-1kは、19の異なる視覚分類のセットで構成され、標準カメラでキャプチャされた自然画像タスク(Natural)、特殊機器でキャプチャされた画像タスク(衛星画像など)(Specialized)、および幾何学的理解タスクを必要とするタスクに細分されます。 (構造化)、オブジェクトカウントなど。
各タスクの平均精度を測定した後の主な結果は次のとおりです。
VPT-Deepは、24のタスクのうち20で完全な微調整を上回りましたが、使用するモデルパラメーターの合計は大幅に少なくなりました(1.18倍対24.02倍)。
ご存知のとおり、NLP分野でPromptがどれほど強力であっても、そのパフォーマンスは完全な微調整を超えることはありません。これは、PromptがビジュアルTransformerモデルに非常に適していることを示しています。
他の微調整方法(グループbおよびc)と比較すると、VPT-Deepのパフォーマンスはすべて優れています。
さらに、テスト用にバックボーンパラメータースケールとモデルスケール(ViT-B、ViT-L、ViT-H)が異なるViTを選択すると、VPTメソッドは影響を受けず、基本的に最高のパフォーマンスを維持できることがわかりました。

Swin Transformerでは、包括的な微調整方法の平均精度は高くなりますが、パラメーターのコストも膨大になります。
他のすべての微調整方法はVPTより劣っています。
著者について
筆頭著者のJiaMenglinは、コーネル大学の情報科学の博士課程の学生であり、彼の主な研究の方向性は、視覚的およびテキスト的情報のきめ細かい認識です。これまでに、彼は4つのトップペーパーを発表しています。

一般的なTangLumingは、コーネル大学でコンピューターサイエンスの博士課程の学生でもあり、清華大学で数学と物理学を専攻して卒業しました。
彼の主な研究対象は、機械学習とコンピュータービジョンの交差点です。

VPT 论文下载
后台回复:VPT,即可下载上面论文ICCVおよびCVPR2021ペーパーおよびコードのダウンロード
舞台裏の返信:CVPR2021、 CVPR2021の論文とオープンソースの論文コレクションをダウンロードできます
背景の返信:ICCV2021、 ICCV2021の論文とオープンソースの論文コレクションをダウンロードできます
背景の返信:トランスフォーマーレビュー、最新の3つのトランスフォーマーレビューPDFをダウンロードできます
CVer-トランス交換グループを設立
以下のQRコードをスキャンするか、WeChat:CVer6666を追加します。CVerアシスタントWeChatを追加し、CVer- TransformerWeChat 交換グループへの参加を申し込むことができます。さらに、他の垂直方向もカバーされています:オブジェクト検出、画像セグメンテーション、オブジェクト追跡、顔検出と認識、OCR、ポーズ推定、超解像度、SLAM、医療画像、Re-ID、GAN、NAS、深度推定、自律運転、強化学習、レーンライン検出、モデルの剪定と圧縮、ノイズ除去、ヘイズ除去、排水、スタイル転送、リモートセンシング画像、行動認識、ビデオ理解、画像融合、画像取得、紙の寄稿と通信、PyTorch、TensorFlow、トランスフォーマー待機。
必ず注意してください:研究の方向性+場所+学校/会社+ニックネーム(トランスフォーマー+上海+引き継ぎ+カカなど)、フォーマットのコメントによると、それはより速く渡され、グループに招待されます

▲コードをスキャンするか、WeChat:CVer6666を追加して、交換グループに入ります
CVer Academic Exchange Group(Knowledge Planet)はこちらです!最新、最速、最高のCV / DL / MLペーパーエクスプレス、高品質のオープンソースプロジェクト、学習チュートリアル、実践的なトレーニング、その他の資料を知りたい場合は、以下のQRコードをスキャンして、CVer学術交流グループに参加してください。何千人もの人々を集めました!

▲コードをスキャンしてグループに入る
▲上のカードをクリックして、CVerの公式アカウントをフォローしてください
整理は簡単ではありませんので、気に入って見てください![]()