みなさん、こんにちは。私の名前はシャオミンです。
最近、多くのブロガーが、Markdownドキュメント内のディレクトリをすばやく抽出してxmindマインドマップに変換する必要があることを要求しています。当局は、Pythonを使用してxmindマインドマップを直接生成する方法を提供していると言われていますが、一部の人々は報告しています生成されたファイルを開くことができないこと。したがって、この状況に基づいて、Markdownをxmindにすばやく変換するのに役立つ効率的な支援を開発します。
ソフトウェアの使用法の紹介
最初にプログラムを開きます。インターフェースは次のとおりです。
最初に、ロードされたMarkdownドキュメントが配置されているフォルダーを選択できます。
次に、[ロード]ボタンをもう一度クリックします。
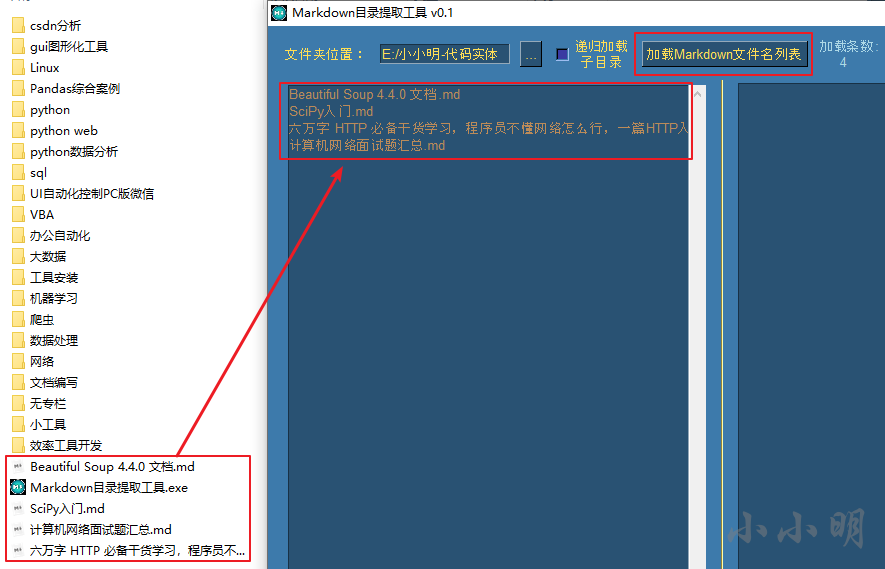
そのディレクトリ内のすべてのmdファイルがリストにロードされます。再帰的なチェックボックスをオンにしてロードすることもできます。
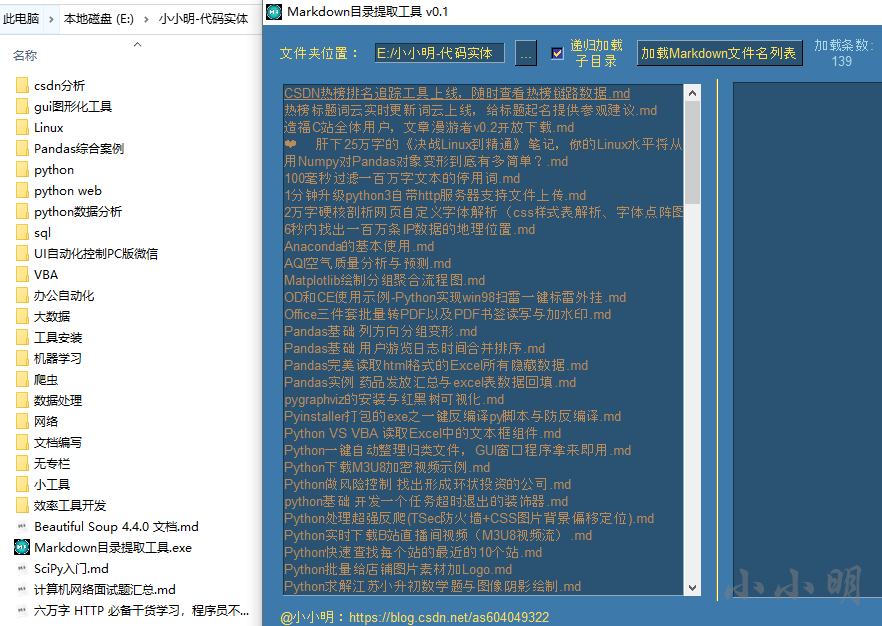
この時点で、含まれているサブファイルがすべてリストにロードされます。
指定されたMarkdownファイルに対応するディレクトリを取得するにはどうすればよいですか?
対応するリストアイテムをクリックするだけです。
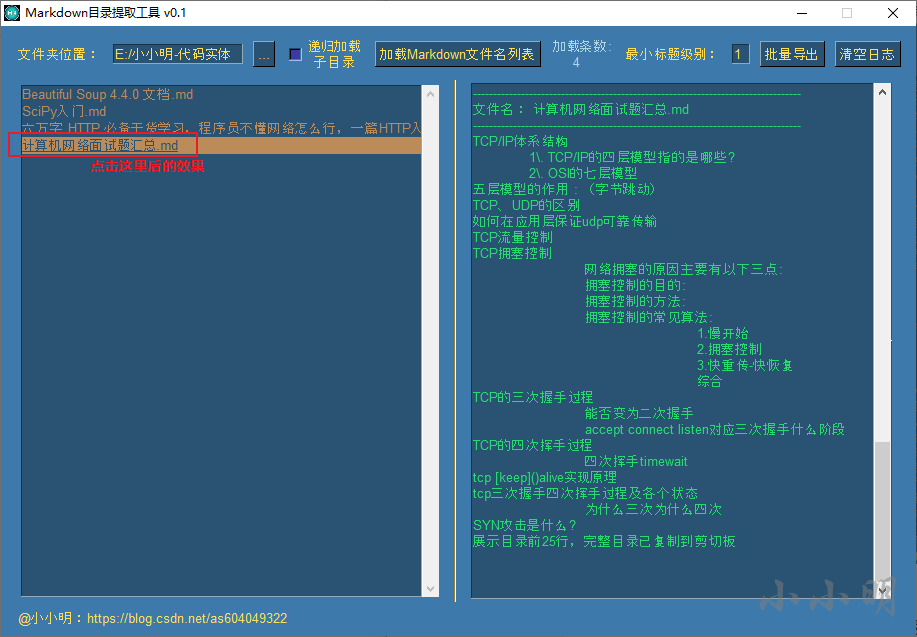
この時点で、Markdownディレクトリがカットバージョンにコピーされ、xmindソフトウェアに貼り付けることができます。xmindソフトウェアを開いた後、冗長ノードを削除し、中央ノードを選択して、以下を貼り付けます。
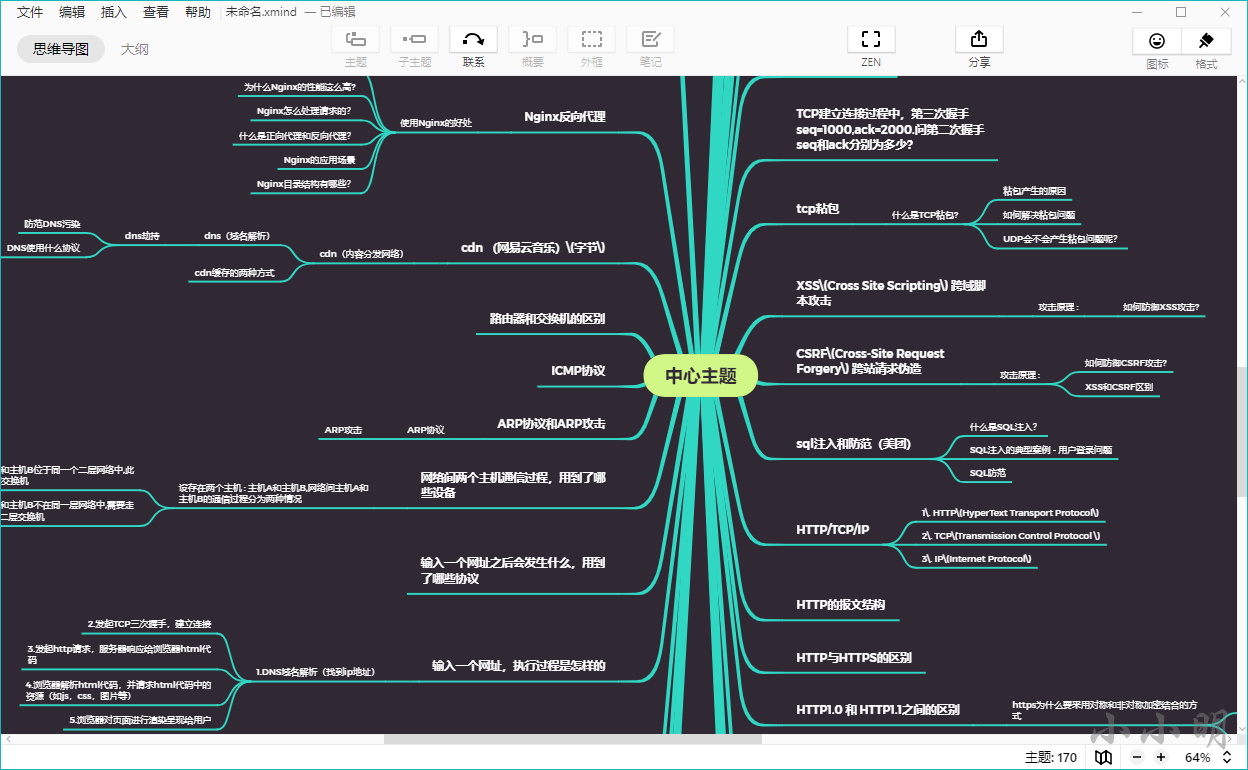
結果が完璧なマインドマップになっていることがわかります。現時点では、中央ノードの名前を変更して保存するだけです。
もちろん、次のような一部のMarkdownドキュメントは特別です。
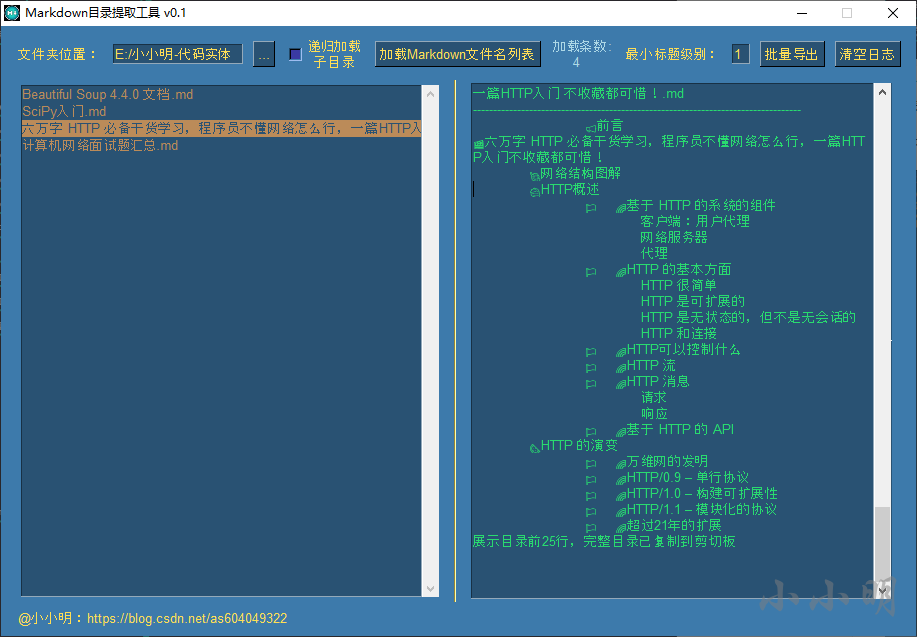
第1レベルのタイトルを削除し、他のレベルのタイトルを1レベル上げます。最小タイトルレベルを2に変更してから、記事をクリックします。
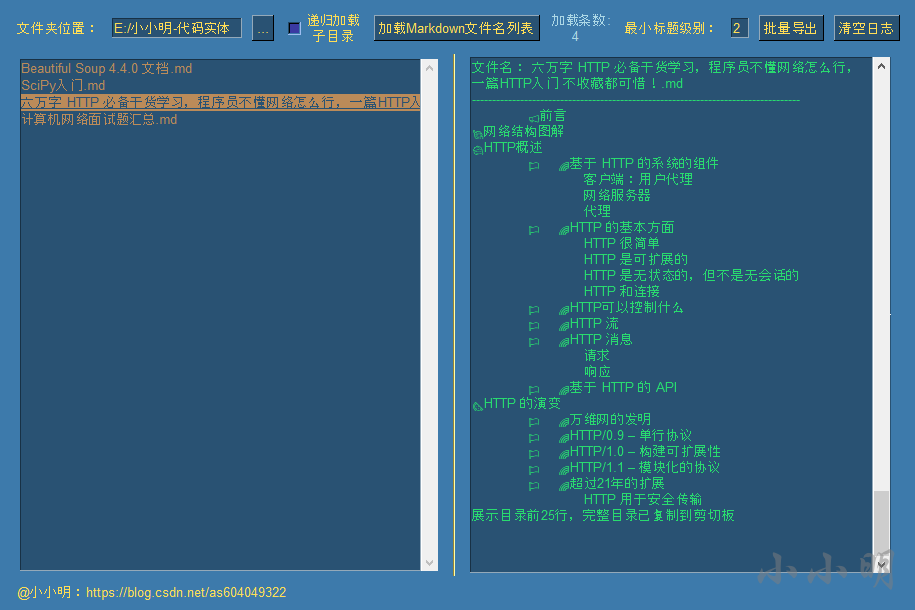
この時点で、xmindに移動して貼り付け、目的の効果を取得します。
もちろん、リスト内のファイルについては、ディレクトリファイルをバッチでエクスポートすることもできます。[バッチエクスポート]をクリックします。バッチエクスポートをクリックした後、最初に保存場所を選択してから、エクスポートを開始します。

保存フォルダをクリックして選択を解除すると、エクスポートタスクの実行が終了します。
コードを開発する
まず、Markdownディレクトリを抽出する関数を開発します。
import cchardet
def load_md(filename, min_level=1):
with open(filename, "rb") as f:
md_bytes = f.read()
encoding = cchardet.detect(md_bytes)['encoding']
if encoding is None:
encoding = "u8"
md = md_bytes.decode(encoding)
code_area = False
result = []
for line in md.splitlines():
if line.startswith("```"):
code_area = not code_area
if code_area or not line.startswith("#") or line.find(" ") == -1:
continue
num_sign, title = line.split(maxsplit=1)
if not title:
continue
tab_num = len(num_sign) - min_level
if tab_num < 0:
continue
result.append("\t" * tab_num + title)
return result
ここでは、エンコーディング認識にcchardetを使用しています。これを使用していないリーダーは、次のものをインストールする必要があります。
pip install cchardet
上記のコードの原則は、Markdownテキストを1行ずつ読み取ることです。#で始まり、スペースを含むテキストは、タイトル付きの行と見なされ、コード領域に#がある場合は除外されます。
その他のコードについては、興味のある子供靴を自分で勉強することができます。完全なコードとパッケージ化されたツールをcodeChinaからダウンロードしてください。
ツールとオープンソースコードのダウンロードアドレス: