制限のオフセットを使用する場合、たとえば、
offer = 30000から5個のデータを取得します
。select* from t where a = '11' limit 30000,5
データベースとテーブルのない財務フローテーブルがあります。現在のデータ量は9555695です。制限はページングクエリに使用されます。最適化前のクエリには16秒938ミリ秒(実行:16秒831ミリ秒、フェッチ:107ミリ秒)かかります。次のようにSQLを調整した後、347ミリ秒かかりました(実行:163ミリ秒、フェッチ:184ミリ秒)。
操作:クエリ条件をサブクエリに入れます。サブクエリは主キーIDのみをチェックし、サブクエリで決定された主キーを使用して他の属性フィールドをクエリします。
原則:バックテーブル操作を減らします。
これまで特定の原則について考えたことはありませんでしたが、今度はそれを追加します。サブクエリのselect id(インデックス)では、インデックスキーに対応する値がまさに主キーの値です(ここではデフォルトのIDが主キーです)。値)、したがって、テーブルに戻る必要はありません。つまり、IDに従ってテーブルを再度チェックする必要がないため、一部のデータはmysqlの基になるキャッシュに保存されます。
MySQLは通常、B + Treeのクラスター化インデックス構造です。主キー(通常はid)によると、必要なデータは、クエリするテーブルに戻らずに、リーフノードで直接見つけることができます。非常に高速です。
2つの組み合わせにより、実際には、インデックス値に対応する主キー値に基づいてテーブルクエリに戻るステップが回避されます。
–最適化前のSQL
SELECT 各种字段
FROM`table_name`
WHERE 各种条件
LIMIT 0,10;
-最適化されたSQL
SELECT 各种字段
FROM`table_name` main_tale
RIGHT JOIN
(
SELECT 子查询只查主键
FROM`table_name`
WHERE 各种条件
LIMIT 0,10;
) temp_table ON temp_table.主键 = main_table.主键
まず、MySQLのバージョンについて説明します。
mysql> selectversion();
+-----------+
| version() |
+-----------+
| 5.7.17 |
+-----------+
1 row in set (0.00 sec)
テーブル構造:
mysql> desc test;
+--------+---------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------+---------------------+------+-----+---------+----------------+
| id | bigint(20) unsigned | NO | PRI | NULL | auto_increment |
| val | int(10) unsigned | NO | MUL | 0 | |
| source | int(10) unsigned | NO | | 0 | |
+--------+---------------------+------+-----+---------+----------------+
3 rows in set (0.00 sec)
idは自動インクリメントの主キーであり、valは一意でないインデックスです。
合計500万の大量のデータを注入します。
mysql> selectcount(*) fromtest;
+----------+
| count(*) |
+----------+
| 5242882 |
+----------+
1 row in set (4.25 sec)
制限オフセット行のオフセットが非常に大きい場合、効率の問題が発生することがわかっています。
mysql> select * fromtestwhere val=4limit300000,5;
+---------+-----+--------+
| id | val | source |
+---------+-----+--------+
| 3327622 | 4 | 4 |
| 3327632 | 4 | 4 |
| 3327642 | 4 | 4 |
| 3327652 | 4 | 4 |
| 3327662 | 4 | 4 |
+---------+-----+--------+
5 rows in set (15.98 sec)
同じ目的を達成するために、通常、次のステートメントを書き直します。
mysql> select * fromtest a innerjoin (selectidfromtestwhere val=4limit300000,5) b on a.id=b.id;
+---------+-----+--------+---------+
| id | val | source | id |
+---------+-----+--------+---------+
| 3327622 | 4 | 4 | 3327622 |
| 3327632 | 4 | 4 | 3327632 |
| 3327642 | 4 | 4 | 3327642 |
| 3327652 | 4 | 4 | 3327652 |
| 3327662 | 4 | 4 | 3327662 |
+---------+-----+--------+---------+
5 rows in set (0.38 sec)
時間差は明らかです。
上記の結果が表示されるのはなぜですか?select * fromtestのクエリプロセスを見てみましょう。ここでval = 4 limit 300000,5;:
インデックスリーフノードデータをクエリします。リーフノードの主キー値に応じて、クラスター化インデックスでクエリする必要のあるすべてのフィールド値が使用されます。
下の写真のように:
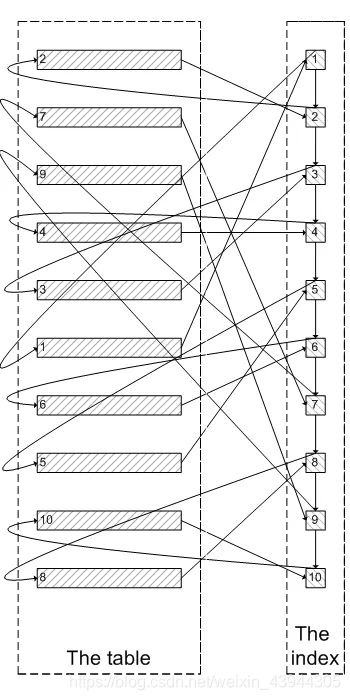
上記のように、300005インデックスノードをクエリし、300005クラスター化インデックスデータをクエリし、最後に最初の300,000アイテムから結果をフィルタリングし、最後の5アイテムを取り出す必要があります。MySQLは、クラスター化インデックスのデータをクエリするために大量のランダムI / Oを消費し、300,000のランダムI / Oクエリのデータは結果セットに表示されません。
インデックスは最初に使用されるので、最初にインデックスリーフノードに沿って最後に必要な5つのノードをクエリしてから、クラスター化インデックスの実際のデータをクエリしてみませんか。これには、次の図のプロセスと同様に、5つのランダムI / Oのみが必要です。
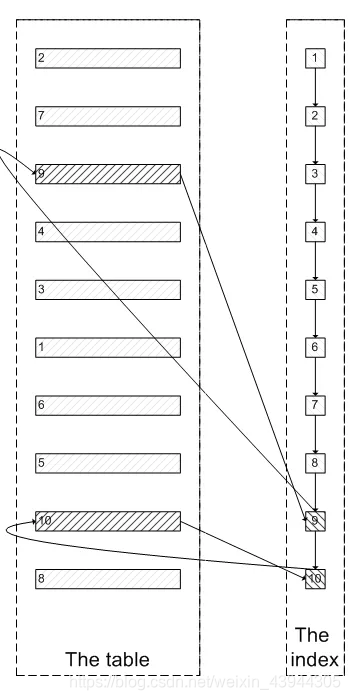
val = 4 limit 300000、5が300005インデックスノードと300005クラスター化インデックスデータノードをスキャンするテストから*を選択することを確認します
select * from test where val = 4 limit 300000,5 scans 300005 index node and 300005 clustered index data nodeを確認するには、MySQLにインデックスノードの頻度を介してSQLクエリのデータノードをカウントする方法があるかどうかを知る必要があります。最初にHandler_read_ *シリーズを試しましたが、残念ながら、どの変数も条件を満たすことができません。
間接的にしか確認できません:
InnoDBにはバッファープールがあります。データページやインデックスページなど、最近アクセスされたデータページがあります。したがって、2つのSQLを実行して、バッファープール内のデータページの数を比較する必要があります。予測結果は、select * from test内部結合を実行することです(select id from test where val = 4 limit 300000,5);その後、バッファープール内のデータページ数はselect * from test wherevalよりはるかに少なくなります。 = 4 limit 300000、5;前のSQLはデータページに5回しかアクセスせず、後者のSQLはデータページに300005回アクセスするため、対応する数。
select * fromtestwhere val=4limit300000,5
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like'%test%'groupby index_name;Empty set (0.04 sec)
現在、バッファプールにテストテーブルに関するデータページがないことがわかります。
mysql> select * fromtestwhere val=4limit300000,5;
+---------+-----+--------+
| id | val | source |
+---------+-----+--------+|
3327622 | 4 | 4 |
| 3327632 | 4 | 4 |
| 3327642 | 4 | 4 |
| 3327652 | 4 | 4 |
| 3327662 | 4 | 4 |
+---------+-----+--------+
5 rows in set (26.19 sec)
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like'%test%'groupby index_name;
+------------+----------+
| index_name | count(*) |
+------------+----------+
| PRIMARY | 4098 |
| val | 208 |
+------------+----------+2 rows in set (0.04 sec)
この時点で、バッファプール内のテストテーブルには4,098のデータページと208のインデックスページがあることがわかります。
select * from test内部結合(select id from test where val = 4 limit 300000,5);最後のテストの影響を防ぐために、バッファプールをクリアしてmysqlを再起動する必要があります。
mysqladmin shutdown
/ usr / local / bin / mysqld_safe&
mysql> select index_name、count(*)from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in( 'val'、 'primary')and TABLE_NAME like '%test%' groupby index_name;
SQLを実行するための空のセット(0.03秒):
mysql> select * fromtest a innerjoin (selectidfromtestwhere val=4limit300000,5) b on a.id=b.id;
+---------+-----+--------+---------+
| id | val | source | id |
+---------+-----+--------+---------+
| 3327622 | 4 | 4 | 3327622 |
| 3327632 | 4 | 4 | 3327632 |
| 3327642 | 4 | 4 | 3327642 |
| 3327652 | 4 | 4 | 3327652 |
| 3327662 | 4 | 4 | 3327662 |
+---------+-----+--------+---------+
5 rows in set (0.09 sec)
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like'%test%'groupby index_name;
+------------+----------+
| index_name | count(*) |
+------------+----------+
| PRIMARY | 5 |
| val | 390 |
+------------+----------+
2 rows in set (0.03 sec)
2つの明らかな違いがわかります。最初のSQLは4,098データページをバッファプールにロードしますが、2番目のSQLは5データページのみをバッファプールにロードします。私たちの予測に沿って。また、最初のSQLが遅い理由も証明されました。大量の役に立たないデータ行(300000)を読み取り、最終的にそれを破棄しました。そして、これは問題を引き起こします:バッファプールであまり熱くない多くのデータページをロードすると、バッファプールの汚染を引き起こし、バッファプールのスペースを占有します。発生した問題
バッファプールが再起動されるたびにクリアされるようにするには、innodb_buffer_pool_dump_at_shutdownとinnodb_buffer_pool_load_at_startupをオフにする必要があります。これら2つのオプションは、データベースがシャットダウンされたときのバッファプール内のデータと、データベースの電源がオンになったときにディスクにロードされるバックアップバッファプール。