モバイルインターネットの時代では、データは非常に豊富ですが、同時に、効果的な情報への人々のアクセス効率の低下、つまり情報過多にもつながります。レコメンデーションシステムは、ユーザーが関心のある情報を積極的かつパーソナライズしてプッシュし、情報過多の問題を大幅に軽減することができます。したがって、モバイルインターネット時代で最も急速に成長し、最も広く使用されているテクノロジーの1つになりました。
検索エンジンと比較して、ユーザーは推奨シナリオで積極的に表現する情報が少なく、意図が不明確です。ユーザーの多次元情報を組み合わせて、ユーザーの関心のあるポイントを効果的にモデル化する方法は、非常に困難で価値のある問題です。超大規模データシナリオでは、産業レコメンデーションシステムには、主に2つのコアフェーズ、リコールフェーズ(一致)とランキングフェーズ(ランク)が含まれます。リコールフェーズでは、超大規模な候補ライブラリからユーザーが関心を持つ可能性のある候補アイテムのセットをすばやく選択するため、数十ミリ秒以内に数億の候補アイテムから数千の関心のある候補セットを迅速に選択する必要があります。並べ替え段階では、リコール候補セットを正確にスコアリングし、ターゲットアイテムに対するユーザーのクリック率を正確に推定してから、ユーザーが最も関心を持っているコンテンツを提示します。
以下は、レコメンデーションシステムのリコールとランキングのコアリンクにおける最新の開発の紹介です。
リコールフェーズ
リコールフェーズはレコメンデーションシステムの中核部分であり、その目的は、レコメンデーションシステムの有効性を確保しながら、レコメンデーションアイテムの規模を非常に短い期間で数億から小さな範囲(数千)に縮小することです。可能な限り。そのため、リコール対象物の品質が、産業推薦の非常に重要な部分である推薦システム全体の効果の上限を直接決定し、近年、関連する研究も盛んになっています。
Mobius [1]は、サンプルからのリコールモデルを最適化する方法を調査しました。この論文の出発点は、それ自体は「良好」であるがシステムによってリコールされていないサンプルを見つけることができれば、これらのサンプルをモデルのトレーニングと修正に効果的に使用できるということです。しかし、リコールされていないサンプルから、どのサンプルがいわゆる「良い」サンプルであるかをどのように判断するかは簡単な問題ではありません。このため、この論文では、「近似評価」スキームを提案しています。参照としてのランキングモデル、つまり、CTRモデルのスコアが高いが、リコールされていないサンプルは、難しいサンプルと見なされます。オフライン段階では、元のリコール方法に基づいて相関は低いが推定CTRが高いサンプルが選択され、データ拡張と同じくらい難しいとマークされます。また、元の2クラスモデルも3クラス問題(正のサンプル/負のサンプル)にアップグレードされます。効果的なサンプル/難しいサンプル)クリック露出データがまばらで、ロングテールトレーニングが不十分であるという問題が軽減されます。この方法をオンラインシステムに直接適用すると、計算圧力が高くなるという問題が発生するため、オンラインフェーズでは、加速のためのANN近似最近傍検索アルゴリズムを紹介し、ベクトル圧縮を使用してオンラインメモリ要件を節約します。オンラインサービスのパフォーマンスの問題を効果的に軽減します。トレーニングデータの理解を続けると、EBR [2]モデルは、リコールフェーズでのネガティブサンプルスクリーニングが最も重要であることも示しています。並べ替えモードはコピーできず、露出されたクリックされていないデータのみをネガティブサンプルとして使用します。ただし、クリックされたデータに対してランダムサンプリングを実行してネガティブサンプルを生成し、クリックされたデータをポジティブサンプルとして使用する必要があります。同時に、cvフィールドでの難しいサンプルマイニング方法の助けを借りて、ネガティブサンプルは単純/困難に分けられ、別々に扱われます。これは、メビウスの考え方と似ています。EBRを次の図に示します。
先に述べたように、リコールシステムには時間のかかる計算に対する非常に厳しい要件があり、その結果、リコールシステムにディープモデルなどの優れたモデルが導入されています。その理由は、ディープモデルの複雑さが大きすぎるためです。 。、すべての候補セットに直接適用すると、計算が爆発的に増加します。このため、ツリーモデルの深度マッチングに基づくリコール技術TDMが提案され、複雑なモデルの完全なデータベース検索をに基づいて実現できます。ツリーの組織構造。近年、このフレームワークを中心に、TDM、JTM [3]からBSAT [4]まで、モデル構造、ツリー構築、検索プロセスの複数の次元からの一連の調査が次の図に示すように継続的に進歩しています。 :
画像ソース:https://flashgene.com/archives/145299.html
TDM作業の中心的な目標は、ベクトル検索モードの制限を打ち破ることができることです。これにより、複雑な深層学習モデルは、限られたリソースと時間枠内でデータベース全体のほぼ最適な検索を実現できます。TDMは、ライブラリ全体のツリー構造インデックスを構築するための最大関心ヒープの仮定に基づいており、複雑なディープニューラルネットワークモデルを使用して、ツリー内のユーザーとノードの関心の程度をモデル化します。オンラインサービスの過程で、ビーム検索は、迅速な検索を実現するために使用されます。
TDM作業では、モデルの最適化とツリー構造インデックスの学習の最適化目標が完全に同じではないため、2つの最適化が相互に抑制され、全体的な効果が最適化されない可能性があります。ツリー構造インデックスの品質は、全体的なリコール効果に決定的な影響を及ぼします。したがって、学習を通じて高品質のツリーインデックス構造を取得する方法が、JTMが解決したい主な問題です。
JTMは、TDMツリー構造インデックス+任意に複雑なモデルのシステムフレームワークに従い、共同最適化と階層的特徴モデリングを通じてTDMの欠点を解決します。JTMは、共通の損失関数の下で代替最適化を行うための共同トレーニングフレームワークを提案し、ツリーインデックス構造を学習して、2つの最適化目標に一貫性がなく、最適ではないソリューションにつながる状況を回避します。同時に、階層的なユーザーの関心の表現の概念が提案されます。ツリーインデックスの階層構造の助けを借りて、ユーザーの行動特性がさまざまなレベルの精度でモデル化され、粗いものから検索プロセスで問題ありません。BSATは、JTMに基づいて、検索プロセス(つまり、ビームサーチ)で共同学習を実行し、オフライントレーニングフェーズとオンラインサービスフェーズの間のノード分布の不一致の問題を軽減します。1)トレーニング中に、ポジティブサンプルアップトラッキング+ランダムネガティブによって生成されます。同じレイヤーでのサンプリング。ツリー上のノードとスパニングツリー上のノードは、オンラインサービス中にbeamsearchを介して取得されます。2)ツリー上のノードのラベルは、その子ノードのラベルによって決定され、避けられません。ビーム検索プロセスにエラーがないこと。
BSATは最初に、ビーム検索に最適なツリーモデルの理論的定義を示し、その存在を理論的に証明しました。最適なツリーモデルをトレーニングするために、この記事では損失関数とトレーニングアルゴリズムの定義を示します。トレーニングアルゴリズムの主な違いは次のとおりです。1)トレーニングに使用されるツリー上のノードはbeamsearchによって生成されます。2)ツリー上のノードのラベルは、サブツリー内でエッジ確率が最も高いアイテムのラベルと同じです。 、その子ノードだけでなく、ラベルの決定。上記の改善により、トレーニングとオンラインサービスの不一致の問題を効果的に解決できます。実験結果は、リコール指標においてBSATがJTMよりも優れた結果を達成したことを示しています。BSATを次の図に示します。
ツリー構造ベースのリコールは良好な結果を達成しましたが、まだ2つの欠点があります。1)ツリー構造自体を学習することは困難であり、リーフノードデータがまばらであるため、より細かいレベルで適切なツリー構造を学習することは困難です。検索効果を制限します。2)各候補アイテムは1つのリーフノードにのみ割り当てることができます。これにより、モデルが複数の角度から候補セットアイテムの表現を記述するように制限されます。DeepRetrieval [5]は、インデックス構造を変更し、アイテムインデックスとしてD x Kマトリックスを使用し、各ステップでK個の選択肢をDステップ予測することでK ^ Dパスを織り込むことで機能します。パスコードはEMアルゴリズムとモデルを一緒に使用してパスとアイテムを取得します。の多対多の関係を取得し、より複雑な観点からユーザーとアイテムの関係を学習します。実験により、DeepRetrievalはブルートフォースフルライブラリと同等の効果を達成できることが示されています。ほぼ線形の計算の複雑さでのマッチングアルゴリズム。DeepRetrievalを次の図に示します。
ソートフェーズ
排序阶段的核心问题是点击率 (CTR) 预估,也就是去衡量一个物品被特定用户点击的概率,最终推荐点击率靠前的结果。早期排序算法是以逻辑回归模型 (LR)+ 人工特征工程为主,模型简单易解释,但人工特征工程的成本比较高,不同任务间算法结论也难以复用,更重要的是对于稀疏数据很难抽取有效的人工特征。为了解决上面的问题,因子分解机 (FM) 提出了特征嵌入和二阶特征交叉来缓解数据稀疏和人工特征工程的问题。近些年,随着深度学习的快速发展,排序模型也不断演进,从经典 DNN 模型到结合浅层的 Wide&deep 模型再到结合二阶特征交叉的 DeepFM 模型,深度学习越来越广泛地应用在 CTR 预估问题上。其中 PNN、NFM、DCN、xdeepFM 等工作又进一步丰富了在深度 CTR 模型中进行有效高阶特征交叉的方式。进入 2020 年,特征交互依然是基于深度学习的 CTR 模型的研究热点之一,此外用户行为序列建模等也得到了极大的关注。
自从 Transformer 结构提出以来,推荐模型的特征交互开始进入 attention 时代。其中 AutoInt [6] 工作提出使用多头自注意力 (Multi-headSelf-attention) 机制将模型交互由低阶引向高阶,同时展示出 attention 机制在可解释性上的天然优势。而 FiBiNet [7] 工作借鉴 Squeeze-ExcitationNetwork(SENet) 中通道 attention 结构来学习动态特征的重要性并利用双线性函数来更好的建模交叉特征。
2020 年关于注意力机制在 CTR 预估中应用的研究依然没有停止。例如,自适应因子网络(AdaptiveFactorization Networks [8] )认为虽然 attention 可以建模高阶交互特征,但是同一种高阶交互并不一定适合所有的原始特征,为此论文提出了一种可以自适应调整交互阶数的网络来提升模型的性能。而 InterHAt [9] 则侧重于探究通过引入分层策略来改善 self-attention 的特征建模效果。除了特征本身之间的直接交互外,DRM [10] 则从特征映射空间中基的语义相关性来建模特征交互,也就是特征维度关系建模,论文认为特征空间的维度本身包含一些“隐”的语义,并且证明通过 attention 机制建模这种语义之间的相关性对模型 CTR 的预估有明显的正面作用,特别是当特征维度比较的大的时候,这种增益效果就越明显。AFN 如下图所示:
另一方面,用户行为序列建模也是 CTR 预估中一个热门话题,早期的 YouTube 工作直接把用户观看过的视频序列做平均池化 (mean pooling) 作为用户历史兴趣的表达。后来的 DIN 将 attention 的思想引入到行为序列建模中,使用目标物品对用户行为序列中的物品做 attention,得到 attention score, 然后基于这些 score 对用户行为特征加权求和来表征用户的兴趣。这种方式有效提升用户行为序列建模的效果,但是无法有效区分用户行为中兴趣的起始和终止,这个问题在之后 DIEN 中被深入讨论并处理。
DIEN 基于 RNN 去建模用户行为中兴趣的演化过程,但是 RNN 方式对用户行为序列进行串行计算,耗时相对还是比较高,线上使用压力较大,为此 BST[11] 提出可以使用 transformer 来建模用户的行为序列来缓解这个问题。另一方面,DSIN [12] 发现虽然用户在每个会话中的行为是相近的,但在不同会话中差别会比较大,因此论文提出要基于每个会话进行用户行为序列建模,也就是 session 建模。
对于 2020 年,序列建模的相关工作进展主要还是体现在如何建模更长的用户序列以及如何建模用户序列演进关系两部分。
建模更长的用户序列也就意味着对用户有着更全面的了解,但同时面对的噪声也就更多。对于这个问题,19 年 MIMN [13] 模型提出线上使用 UIC 模块(用户兴趣中心)专门用于更新用户最新兴趣表示,将耗时重头从实时计算部分拆分出来做异步更新,多通道用户兴趣记忆网络 MIMN 主要包括基于正则化修正的 NTU 模块和用来加强用户兴趣提取的能力的 MIU 单元,通过 UIC 的更新机制和 MIMN 的序列建模,首次将超长用户行为序列建模扩展到千级别长度。
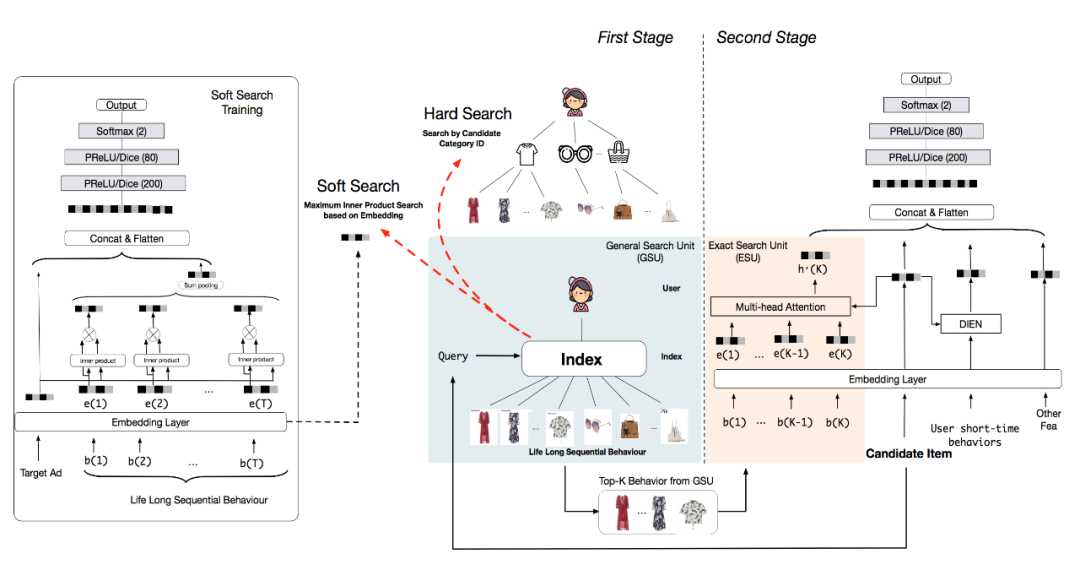
虽然 MIMN 模型将用户序列长度处理到千,但由于借用了经典 CTR 的 Embedding+MLP 模式,导致特征规模的扩增显著,同时将所有用户历史行为编码到一个固定大小的内存矩阵上会给内存单元带来很多噪音。延续这一方向,20 年的 SIM [14] 模型通过两阶段的方式来对用户终身行为序列进行建模,一阶段采用通用搜索单元(GSU)以次线性时间复杂度从原始长期行为序列中寻找 top-K 相关的子行为序列以减少噪声,包括 hard-search 同类目搜索和 soft-search 使用内积的近似最近邻两种实现方式;二阶段使用过滤后的较短行为子序列,用精准搜索单元(ESU)捕捉更精准的用户兴趣,包括 DIN/DIEN 等复杂模型;实现请求级别建模用户超长行为序列。SIM 如下图所示:
在用户序列演进关系建模方面,DTS[15] 通过在一个常微分方程中引入时间信息,使用神经网络根据用户历史行为连续建模用户的兴趣演变。但在电商场景中,临时促销活动中的爆品热销物品会成为用户的短期新兴趣,仅使用用户行为序列通常无法预测用户产生的新兴趣,而预测用户新的兴趣又严重依赖于物品的演化过程,因此基于时间感知的深度物品演化网络(DTAN [16] )提出基于时间 attention 的物品演化建模网络来解决这个问题。
上面的工作都是假设用户的每一个行为都是处于其真实意图的,但是实际电商场景中,有些用户行为可能是随机的,与真实用户意图无关的,如果基于这个无关的行为进行推荐可能会产生错误的推荐,同时反映用户真实意图的行为也可能有缺失。基于此,论文 [17] 提出基于卡尔曼滤波的注意力机制来克服这种观测上的误差和缺失。他们使用 transformer 来捕捉长期行为序列的关系和动态特征,但是在 Attention 里将用户历史行为作为用户隐藏兴趣的间接测量值,为用户的隐藏兴趣给出解析解。最终模型效果提升相对显著。
未来展望
随着互联网技术的发展,云技术、实时计算服务推动信息流推荐朝着实时化边缘化的方向发展,更好的满足用户多元化需求。这就需要对用户兴趣的实时追踪建模,对已有的深度学习推荐模型进一步升级优化,及时捕获用户兴趣就可以更迅速精准的为用户推荐感兴趣物品,提升用户体验。
随着智能产品的增多以及 5G 及物联网的发展,未来新场景下的交互方式的变化,能够让我们获得更多维度的用户信息,提升推荐模型的效果。信息流场景的爆发式增长,推荐系统的商业价值越来越重要,个性化推荐成为了标配,如何满足用户的使用体验以及如何提高商业价值,是工业、学术界专家学者在推荐系统上的深入探索的重要方向。