Pythonクローラーセレクション03エピソード(簡単な言語で説明されている再定期的な解析モジュール)
記事のディレクトリ
夢を追いかけるには情熱と理想が必要であり、夢を実現するには闘争と献身が必要です
1。正規表現(基本的な紹介)
-
目的
1.テキストデータの処理
2.テキストコンテンツの検索、検索、抽出は論理的に複雑なタスクです
3.上記の問題を迅速かつ便利に解決するために、正規表現テクノロジが作成されます。 -
正規定義
は、テキストの高度なマッチングモードであり、その本質は、一連の文字と特殊記号で構成される文字列です。この文字列は正規表現です。 -
原則
文字列は、通常の文字と特定の意味を持つ文字で構成され、繰り返し、位置などの特定の文字列ルールを記述して、特定のタイプの特定の文字列を表現し、一致させます。 -
目的
- 正規表現のメタ文字に精通している
- 一般的な正規表現を読み、簡単な正規表現を編集できる
- reモジュールを使用して正規表現を操作できる
re模块官方文档:
https ://docs.python.org/zh-cn/3.8/library/re.htmlre模块库源码:
https ://github.com/python/cpython/blob/3.8/Lib/re.py
2.メタ文字の使用:
以下案例若需要在python或pycharm中执行需要引入re模块
テンプレートの例:
import re
print(re.findall('ab',"abcdefabcd"))
# ['ab', 'ab']
2.1普通のキャラクター:
匹配规则:每个普通字符匹配其对应的字符
例子:re.findall('ab',"abcdefabcd")
# ['ab', 'ab']
注意事项:正则表达式在python中也可以匹配中文
2.2メタ文字:|(または関係)
匹配规则:匹配 | 两侧任意的正则表达式即可
例子:re.findall('com|cn',"www.baidu.com/www.jingdong.cn")
#['com', 'cn']
2.3メタ文字:。(単一のメタ文字と一致します)
匹配规则:匹配除换行外的任意一个字符
例子:re.findall('钱天.',"钱天二,钱天三,钱天四")
# ['钱天二', '钱天三', '钱天四']
2.4メタ文字:[文字セット]
匹配规则: 匹配字符集中的任意一个字符
表达形式:
[abc#!好] 表示 [] 中的任意一个字符
[0-9],[a-z],[A-Z] 表示区间内的任意一个字符
[_#?0-9a-z] 混合书写,一般区间表达写在后面
例子:re.findall('[aeiou]',"How are you!")
# ['o', 'a', 'e', 'o', 'u']
2.5メタ文字:[^文字セット](反文字セットと一致)
匹配规则:匹配除了字符集以外的任意一个字符
例子:re.findall('[^0-9]',"Use 007 port")
#['U', 's', 'e', ' ', ' ', 'p', 'o', 'r', 't']
2.6メタ文字:^ \ A
匹配规则:匹配字符串开始位置
例子:re.findall('^Jame',"Jame,hello")
#['Jame']
2.7メタ文字:$ \ Z
匹配规则:匹配目标字符串的结尾位置
例子:re.findall('Jame$',"Hi,Jame")
#['Jame']
规则技巧: ^ 和 $必然出现在正则表达式的开头和结尾处。如果两者同时出现,则中间的部分必须匹配整个目标字符串的全部内容。
2.8メタ文字:*
匹配规则:匹配前面的字符出现0次或多次
例子:re.findall('ha*',"haaaaaa~~~~h!")
#['haaaaaa', 'h']
2.9メタ文字:+
匹配规则:匹配前面的字符出现1次或多次
例子:re.findall('[A-Z][a-z]+',"Hello World")
#['Hello', 'World']
2.10メタ文字:?
匹配规则:匹配前面的字符出现0次或1次
例子:匹配手机号 re.findall('-?[0-9]+',"Jame,age:18, -26")
#['18', '-26']
2.11メタ文字:{n}
匹配规则:匹配前面的字符出现n次
例子:re.findall('1[0-9]{10}',"Jame:13886495728")
#['13886495728']
2.12メタ文字:{m、n}
匹配规则: 匹配前面的字符出现m-n次
例子:匹配QQ号 re.findall('[1-9][0-9]{5,10}',"QQ:1259296994")
#['1259296994']
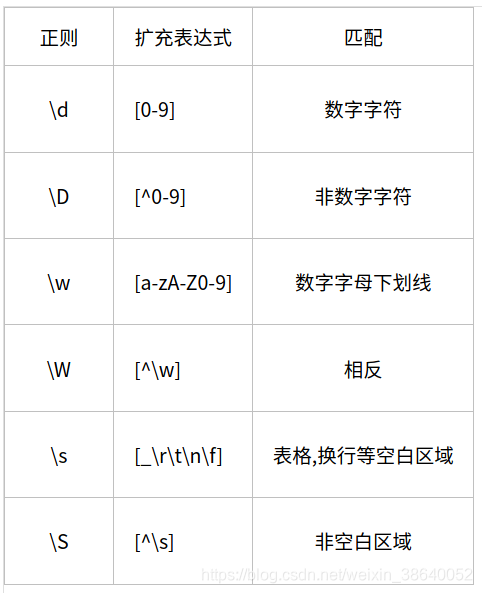
2.13メタ文字:\ d \ D
匹配规则:\d 匹配任意数字字符,\D 匹配任意非数字字符
例子:匹配端口 re.findall('\d{1,5}',"Mysql: 3306, http:80")
#['3306', '80']
2.14メタ文字:\ w \ W
匹配规则:\w 匹配普通字符,\W 匹配非普通字符
说明: 普通字符指数字,字母,下划线,汉字。
例子: re.findall('\w+',"server_port = 8888")
#['server_port', '8888']
2.15メタ文字:\ s \ S
匹配规则:\s 匹配空字符,\S 匹配非空字符
说明:空字符指 空格 \r \n \t \v \f 字符
例子: re.findall('\w+\s+\w+',"hello world")
#['hello world']
2.16メタ文字:\ s \ S
匹配规则:\s 匹配空字符,\S 匹配非空字符
说明:空字符指 空格 \r \n \t \v \f 字符
例子: re.findall('\w+\s+\w+',"hello world")
#['hello world']
2.17メタ文字:\ b \ B
匹配规则:\b 表示单词边界,\B 表示非单词边界
说明:单词边界指数字字母(汉字)下划线与其他字符的交界位置。
例子:re.findall(r'\bis\b',"This is a test.")
#['is']
注意: 当元字符符号与Python字符串中转义字符冲突的情况则需要使用r将正则表达式字符串声明为原始字符串,如果不确定那些是Python字符串的转义字符,则可以在所有正则表达式前加r。
3.マッチングルール
3.1特殊文字のマッチング
-
目的:一致したターゲット文字列に正規表現の特殊文字が含まれている場合、それ自体の意味を表現するときに、式のメタ文字を処理する必要があります。
特殊字符: . * + ? ^ $ [] () {} | \ -
操作方法:正規表現メタ文字の前に\を追加します。メタ文字は、その特殊な意味、つまり文字を削除することです。
e.g. 匹配特殊字符 . 时使用 \. 表示本身含义
In : re.findall('-?\d+\.?\d*',"123,-123,1.23,-1.23")
Out: ['123', '-123', '1.23', '-1.23']
3.2欲張りモードと非欲張りモード
- 定義
贪婪模式: 默认情况下,匹配重复的元字符总是尽可能多的向后匹配内容。比如: * + ? {m,n}
非贪婪模式(懒惰模式): 让匹配重复的元字符尽可能少的向后匹配内容。
- 欲張りモードは非欲張りモードに変換されます
- 貪欲モード[マッチリピート]デフォルトの最大値
- 非欲張りモードの最小値、[マッチリピート]の後に追加しますか?
対応する一致する繰り返しメタ文字の後に「?」記号を追加します
* -> *?
+ -> +?
? -> ??
{
m,n} -> {
m,n}?
e.g.
In : re.findall(r'\(.+?\)',"(abcd)efgh(higk)")
Out: ['(abcd)', '(higk)']
デモ
import re
# 贪婪匹配 ['《java入门到放弃》,派神:《python入门到放弃》,前端:《Html直接放弃,are you ok》']
print(re.findall('《.+》', "抓娃:《java入门到放弃》,派神:《python入门到放弃》,前端:《Html直接放弃,are you ok》"))
# 非贪婪匹配 ['《java入门到放弃》', '《python入门到放弃》', '《Html直接放弃,are you ok》']
print(re.findall('《.+?》', "抓娃:《java入门到放弃》,派神:《python入门到放弃》,前端:《Html直接放弃,are you ok》"))
3.3正規表現のグループ化
-
定義:
正規表現では、()を使用して正規表現の内部グループを確立します。サブグループは正規表現の一部であり、内部の全体的な操作オブジェクトとして使用できます。
-
効果:
(1)メタ文字の操作対象を操作全体で変更することができます。
#(1)改变 +号 重复的对象
re.search(r'(ab)+',"ababababab").group()
#'ababababab'
#(2)改变 |号 操作对象
re.search(r'(王|李)\w{1,3}',"王者荣耀").group()
#'王者荣耀'
(2)付随するコンテンツのサブグループに対応するコンテンツ部分は、プログラミング言語のいくつかの言い訳によって取得できます。
#获取url协议类型
re.search(r'(https|http|ftp|file)://\S+',"https://www.baidu.com").group(1)
- キャプチャグループ:
正規表現のサブグループに名前を付けて、サブグループの意味を表すことができます。この名前付きサブグループはキャプチャグループです
形式: "(?Ppattern)"
#给子组命名为 "pig"
re.search(r'(?P<pig>ab)+',"ababababab").group('pig')
#'ab'
注意事项
- 正規表現には複数のサブグループを含めることができます
- サブグループはネストできますが、重複しないか、ネスト構造が複雑です
- サブグループのシリアル番号は、通常、外側から内側、および左から右にカウントされます。

4.まとめ
4.1正規表現の原則
-
正しさ、ターゲット文字列に正しく一致させることができます。
-
ターゲット文字列が予期せず他のコンテンツとできるだけ一致しないことを除いて、排他性。
-
ターゲット文字列のすべての条件を可能な限り考慮し、省略せずに包括性。
4.2普通字符集的替换
4.3计数符

4.4巩固提升
- 正規表現を使用して特殊文字を照合する場合は、エスケープを示すために\を追加する必要があります。
- 特殊文字:。* +?^ $ []()()| \
- 特殊文字を照合するときに使用します。それ自体の意味を意味します。
例1:
import re
print(re.findall('-?\d+\.?\d*',"123,-123,1.23,-1.23"))
#['123', '-123', '1.23', '-1.23']
例子2:
import re
s="1992年5月2日出生于中国,中国内地影视女演员-12,12.34,1/0,40%,-1.6"
r=re.findall('-?\d+\.?/?\d*%?',s)
print(r)
#['1992', '5', '2', '-12', '12.34', '1/0', '40%', '-1.6']
2.プログラミング言語では、複数のエスケープの問題を回避するために、正規表現はネイティブ文字列を使用して記述されることがよくあります。
python字符串 --> 正则 --> 目标字符串
"\\$\\d+" 解析为 \$\d+ 匹配 "$100"
"\\$\\d+" 等同于 r"\$\d+"