ダーティ読み取り(無効なデータ)
データが変更された後にトランザクションがコミットされなかった、トランザクションbがデータが変更された後にトランザクションを読み取る、トランザクションbがデータを読み取る、トランザクションaがデータを
ロールバックする、このダーティ読み取り
繰り返し不可の読み取り
トランザクションaはデータを読み取って使用し、トランザクションbはデータを直接変更して送信しただけで、トランザクションa
は以前に読み取られたデータが不正確であることがわかります。
ファントム読み取りの現象
は、繰り返し読み取ることができない特殊な現象です。たとえば
、テーブルに10個のデータがある場合、トランザクションは、変更
時に、IDが3より大きいすべてのデータ名をxxに変更します。bトランザクションが別のデータを挿入します。トランザクションaが変更された後、正常に変更されていないデータが1つ見つかります。
上記の現象は、並行性によって引き起こされるいくつかの問題です。mysqlの基礎となるメカニズムは、
これらの問題の解決に役立ちました。これらの問題を解決するために、データベースは、ロックメカニズム、トランザクション分離メカニズム、およびmvccマルチバージョンメカニズムを設計しました。
ロックすると、データのセキュリティが向上し、運用効率が低下します
按锁的粒度划分,可分为行级锁、表级锁、页级锁。(mysql支持)
行级锁
特点:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突概率最低,并发也最高
支持引擎:innodb
行级锁定分为行共享锁(共享锁)与独行写锁(排他锁)
表级锁
特点:开销小,枷锁快;不会出现死锁;锁粒度大,发出锁冲突的概率最高,并发度低
支持引擎:myisam,memory,innodb
分类:表级锁定分为表共享读锁(共享锁)与表独占写锁(排他锁)
页级锁
特点:开销和加锁时间界与表锁和行锁之间;会出现死锁,锁定粒度界于表锁和行锁之间,并发度一般
行レベルのロック
按锁级别划分,可分为共享锁、排他锁
行级锁之共享锁与排他锁
行级锁分为共享锁和排他锁两种。
排他锁又称为写锁,简称X锁,顾名思义,排他锁就是不能与其他所并存,如一个事务获取了一个数据行的排他锁,其他事务就不能再对该行加任何类型的其他他锁(共享锁和排他锁),但是获取排他锁的事务是可以对数据就行读取和修改。
共享锁又称为读锁,简称S锁,顾名思义,共享锁就是多个事务对于同一数据可以共享一把锁,获准共享锁的事务只能读数据,不能修改数据直到已释放所有共享锁,所以共享锁可以支持并发读(大家只能读不能改)。
与行处理相关的sql有:insert、update、delete、select,这四类sql在操作记录行时,可以为行加上锁,但需要知道的是:
对于insert、update、delete语句,InnoDB会自动给涉及的数据加锁,而且是排他锁(X);
代码演示:
开启两个cdm命令端(a端口,b端口)
a端口输入:
use test;
begin;
update blog set name = "666" where id = 1;
b端口输入:
use test;
update blog set name = "777" where id = 1;
a端口加了互斥锁,b端口就不能再加锁了,只有等a端口把锁释放了,b端口才能加锁
a端口输入命令后会直接卡住,当a端口输入commit或者rollback结束事务的后,
b端口的sql命令会直接运行并且会把id为1的name改成777
对于普通的select语句,InnoDB不会加任何锁,需要我们手动自己加,可以加两种类型的锁
1. 排他锁语法(X):select ... for update; -- 查出的记录行都会被锁住
代码演示:
开启两个cdm命令端(a端口,b端口)
a端口输入:
use test;
begin;
select * from blog where id = 3 for update; # 直接锁住id=3的字段
b端口输入:
use test;
begin;
select * from blog; # 查询blog表正常
update blog set name ="66" where id = 3;
a端口输入命令后会直接卡住,当a端口输入commit或者rollback结束事务的后,
b端口的sql命令会直接运行并且会把id为1的name改成666
select查询不受锁影响,如果我们只是为了锁住数据,不涉及增删改,那么就用select ... for update;来进行锁
注意:innodb锁如果有锁带索引的id字段,那么就锁命中的行
innodb锁如果没有带索引的id字段,那么就锁整个索引(没有命中索引,就相当于表锁)
2. 共享锁语法(S):select ... lock in share mode; -- 查出的记录行都会被锁住
代码演示:
开启两个cdm命令端(a端口,b端口)
a端口输入:
use test;
begin;
select * from blog where id = 4 lock in share mode; # 共享锁锁住id=4的字段
update blog set name = "yyy" where id = 4; # b端没有加共享锁的之前,可以直接在端口修改(可以加互斥锁)
update blog set name = "zzz" where id = 4; # b端加了共享锁之后,无法修改(无法加互斥锁)
b端口输入:
use test;
begin;
update blog set name = "xxx" where id = 4; # a端口加了共享锁之后,无法修改(无法加互斥锁)
select * from blog where id = 4 lock in share mode; # 共享锁锁住id=4的字段
a端口共享锁锁住id=4的字段,b端口对id=4的字段进行修改,直接卡住(update默认加互斥锁),
b端没有加共享锁的之前,a端口可以直接在端口修改name="yyy"。(事务a端口可以对数据加互斥锁)
当b端口加了共享锁之后,a端口将name修改成"zzz"直接卡住(b端口加了共享锁,a端口无法再加互斥锁)
デッドロック
代码演示:
开启两个cdm命令端(a端口,b端口)
a端口输入:
use test;
begin;
select * from blog where id = 4 lock in share mode; # 共享锁锁住id=4的字段(第一步)
update blog set name = "yyy" where id = 2; # b端口共享锁锁住id=2的字段,加互斥锁直接卡住(第三步)
b端口输入:
use test;
begin;
select * from blog where id = 2 lock in share mode; # 共享锁锁住id=2的字段(第二步)
update blog set name = "xxx" where id = 4; # a端口锁住id=4的字段,加互斥锁直接卡住(第四步)
a事务锁住了b事务,b事务锁住了a事务,出现该现象就是是死锁现象。
出现死锁现象,mysql会强制关闭一个事务,另一个事务会直接执行成功。
并发有也可能会造成死锁现象(如下图所示)
高い同時実行性でのデッドロック現象

データベースロックメカニズムの概要
1.一旦事务1对数据A加了排它锁
那么其他事务无法对数据A加任何锁
只有事务1可以操作数据A,而且可以读也可以写
2.一旦事务1对数据A加了共享锁
那么其他事务可以对数据A加锁,但只能加共享锁
一旦多个事务都给数据A加了共享锁,大家都只能读不能改
(特例,如果只有一把共享锁,持有共享锁的事务可以读也可以写)
Innodbストレージエンジン
InnoDB三大特点:事务,外键,行级锁
在Mysql中,行级锁并不是直接锁记录,而是锁索引。InnoDB 行锁是通过给索引项加锁实现的,而索引分为主键索引和非主键索引两种。
1、如果一条sql 语句操作了主键索引,Mysql 就会锁定这条语句命中的主键索引(或称聚集索引);
2、如果一条语句操作了非主键索引(或称辅助索引),MySQL会先锁定该非主键索引,再锁定相关的主键索引。
3、如果没有索引,InnoDB 会通过隐藏的聚集索引来对记录加锁。也就是说:如果不通过索引条件检索数据,那么InnoDB将对表中所有数据加锁,实际效果跟表级锁一样。
Innodbには3つの行ロックアルゴリズムがあります
レコードロックギャップロックネクストキー
1.レコードロック:単一行レコードのロック。
2.ギャップロック:ギャップロック、範囲をロックしますが、レコード自体は含まれません。GAPロックの目的は、同じトランザクションの2つの現在の読み取りがファントム読み取りから行われるのを防ぐことです。
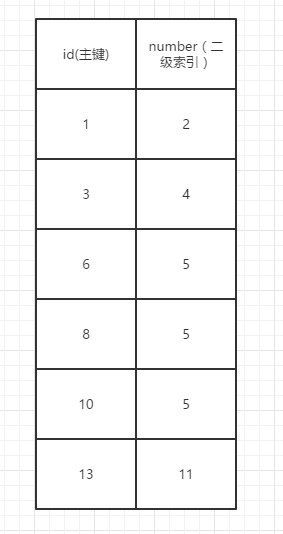
ギャップロック
現在number = 4をロックしていると仮定すると、ギャップロックは(2-4)、(4-5)
現在number = 13をロックしている場合、ギャップロックは(11)の後の番号です)
と仮定します。現在number = 2をロックしているので、ギャップロックは(2より前のnumber)、(2-4)です。
3. Next-Key Lock:GapLockと組み合わせたRecordLockと同じです。つまり、Next-KeyLockはレコード自体と範囲の両方をロックします。InnoDBストレージエンジンも次のキーに追加することに注意することが特に重要です。補助インデックスギャップロックの値
4つのレベルのトランザクション分離メカニズム(理解)
低から高まで、コミットされていない読み取り、コミットされた読み取り、繰り返し可能な読み取り、およびシリアル化可能です。これらの4つのレベルは、ダーティ読み取り、繰り返し不可能な読み取り、およびファントム読み取りの問題を1つずつ解決できます。
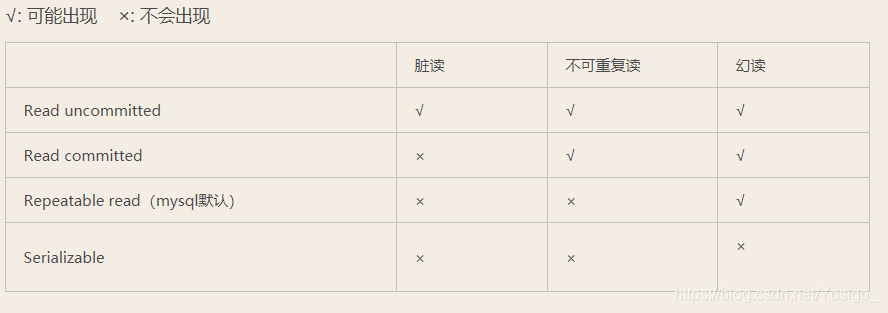
強調する必要があるのは、トランザクション分離レベルを上げることで、ダーティリード、繰り返し不可能なリード、ファントムリードの問題を実際に解決できることですが、同時に、トランザクション分離レベルが高いほど、同時実行性は低くなります。繰り返し可能な読み取りはmysqlのデフォルトの分離メカニズムであり、次のキーの行レベルのロックはファントム読み取りの問題を解決できます。
楽観的および悲観的なロック
ペシミスティックロックとオプティミスティックロックは、ロックの使用と同等です。
効率の問題を考慮して、オプティミスティックロックが主に使用されるようになりました。
ペシミスティックロック
ペシミスティックロックは、SQLステートメントを使用してコマンドを実行するときにミューテックスロックを直接使用することと同じです。ペシミスティックロックの長所:データセキュリティの確保;短所:データベース使用の効率の低下
楽観的ロック
データベースでは、楽観的ロックを実現する方法が2つあります。
1.バージョン番号を使用して
、データの各行にもう1つのフィールドバージョンがあり、データの各更新がバージョン番号+1に対応することを認識します。
原則:データを読み取り、バージョン番号を一緒に読み取り、次に更新します。バージョン番号+1、送信されたデータのバージョン番号がより大きいデータベースの現在のバージョン番号が更新されます。それ以外の場合は、期限切れのデータと見なされ、データが再度読み取られます。
2.タイムスタンプを使用して、データの
各行に対してもう1つのフィールド時間の
原則を実現します。データを読み取り、タイムスタンプを一緒に読み取ってから更新します。送信されたデータのタイムスタンプはデータベースの現在のタイムスタンプと等しくなり、更新されます。 、それ以外の場合は、期限切れのデータと見なされます。データの読み取り
楽観的ロックと悲観的ロックの選択では、主に2つのシナリオと適用可能なシナリオの違いに注目してください。
1.楽観的ロックは実際にはロックされておらず、効率が高い。ロックの粒度が十分に把握されていないと、更新が失敗する可能性が比較的高くなり、ビジネスの失敗が発生しやすくなります。
2.ペシミスティックロックはデータベースロックに依存しており、非効率的です。更新が失敗する可能性は比較的低いです。
mvccメカニズム
MVCC同時実行制御では、読み取り操作は、スナップショット読み取りと現在の読み取りの2つのカテゴリに分類できます。
スナップショット読み取り
は、ロックせずにレコードの表示バージョン(場合によっては履歴バージョン)を読み取ります。
現在の読み取り
はレコードの最新バージョンであり、現在の読み取りによって返されるレコードは、他のトランザクションがレコードを同時に変更しないようにロックされます。