Python APIに基づくパドルライトの完全な展開プロジェクトはネットワーク全体でほとんど見つからないため、他の人のコードは非常に不完全で機能しないため、このブログは全体として最初であると言えます。 Python APIに基づいてPaddlePaddleをデプロイするネットワーク。モデルをカスタマイズし、ビデオストリームと単一の画像の完全な予測を実装するためのデモチュートリアル。
大物の助けを借りて、3日間のハードワークと苦労の末、同時に20年間のスマートカー人工知能グループのカーマーカー認識コードに基づいてインターネットから借りて、ついにpythonAPIベースを実行しましたモデル展開作業により、ビデオストリームと単一画像の予測機能を同時に実現しました。この記事は現在、Windows側でのみパドルライトのデプロイを実装していることに注意してください。私のシステムはラズビアンであるため、トレーニングしたモデルを実行すると、ラズベリーパイ側でメモリ不足のエラーが発生するため、まだ実装されていません。 ubuntuになります。デプロイしてさらに追加します。
ここ夜雨飘零で私を大いに助けてくれてありがとう。ハハハハ。トラフィックがなくなったためにラズベリーパイにデプロイできないという問題を解決するのに役立つことはできませんが、それは私に非常に重要なヒントと助けを与えてくれました。パドルライトの画像入力。モデルの前に、画像を正規化する必要があります。そうしないと、モデルを正常に処理できません。
最初に言わなければならないのは、Windows側とLinux側のPaddle Liteのデプロイメントコードには基本的に違いがないということです。違いは事前環境の構成のみであるため、全員が異なるシステムにデプロイします。 、コードを変更する必要はなく、独自のロジックコードを直接記述できます。
展開環境の準備
1.Windows展開環境の準備
pip install paddlelite
欠けているピップは何をしますか。
2.Linux展開環境の準備
私のブログを直接参照してください:
モデルファイルの準備
まず、画像分類/ターゲット検出用の分類モデルが必要です。図に示すように、一般的に2種類のモデルファイルがあります。
- モデル形式a:
__model__および__params__ファイル
 -モデルフォーマット2:単一
-モデルフォーマット2:単一.nbファイル

PythonAPI予測
これは、私が分割したPaddle Liteに基づく予測のコア機能であり、状況に応じて変更することもできます。注意が必要なのは次のとおりです。
- 画像の正規化部分は不可欠ですが、CVライブラリを使用してすべてを実行し、PILライブラリを破棄することもできます。
# 加载模型
def create_predictor(model_dir):
config = MobileConfig()
config.set_model_from_file(model_dir)
predictor = create_paddle_predictor(config)
return predictor
#图像归一化处理
def process_img(image, input_image_size):
origin = image
img = origin.resize(input_image_size, Image.BILINEAR)
resized_img = img.copy()
if img.mode != 'RGB':
img = img.convert('RGB')
img = np.array(img).astype('float32').transpose((2, 0, 1)) # HWC to CHW
img -= 127.5
img *= 0.007843
img = img[np.newaxis, :]
return origin,img
# 预测
def predict(image, predictor, input_image_size):
#输入数据处理
input_tensor = predictor.get_input(0)
input_tensor.resize([1, 3, input_image_size[0], input_image_size[1]])
image = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGRA2RGBA))
origin, img = process_img(image, input_image_size)
image_data = np.array(img).flatten().tolist()
input_tensor.set_float_data(image_data)
#执行预测
predictor.run()
#获取输出
output_tensor = predictor.get_output(0)
print("output_tensor.float_data()[:] : ", output_tensor.float_data()[:])
res = output_tensor.float_data()[:]
return res
コードの小さなヒント:
output_tensor.float_data()[:]モデルの予測出力です。分類問題の場合、出力は各カテゴリに対応する確率です。最終的な出力層はほぼ同じSoftmax函数であるため、高い確率で出力を直接選択できます。直接参照できます。私の単一画像予測コードに。- それがターゲット検出の問題である場合、一般的な状況はラベル+スコア+ボックス、通常は6つのパラメーターです。もちろん、これは単なるボックスです。複数のオブジェクトがある場合、出力はもちろん6 *オブジェクトの出力数です。次に、フレームをボックスに従って処理し、画像に表示できます。
単一画像予測
私は、廃棄物の分類PaddleClasに基づいてモデルを行うためにここにいるので、画像だけを入力する必要があり、出力ができ、導入目標検出モデルならば、我々はまた、出力に対処する必要があるのでlabel、score、pointそれは上にありますオリジナルフレーム缶。
from paddlelite.lite import *
import cv2
import numpy as np
import sys
import time
from PIL import Image
from PIL import ImageFont
from PIL import ImageDraw
# 加载模型
def create_predictor(model_dir):
config = MobileConfig()
config.set_model_from_file(model_dir)
predictor = create_paddle_predictor(config)
return predictor
#图像归一化处理
def process_img(image, input_image_size):
origin = image
img = origin.resize(input_image_size, Image.BILINEAR)
resized_img = img.copy()
if img.mode != 'RGB':
img = img.convert('RGB')
img = np.array(img).astype('float32').transpose((2, 0, 1)) # HWC to CHW
img -= 127.5
img *= 0.007843
img = img[np.newaxis, :]
return origin,img
# 预测
def predict(image, predictor, input_image_size):
#输入数据处理
input_tensor = predictor.get_input(0)
input_tensor.resize([1, 3, input_image_size[0], input_image_size[1]])
image = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGRA2RGBA))
origin, img = process_img(image, input_image_size)
image_data = np.array(img).flatten().tolist()
input_tensor.set_float_data(image_data)
#执行预测
predictor.run()
#获取输出
output_tensor = predictor.get_output(0)
print("output_tensor.float_data()[:] : ", output_tensor.float_data()[:])
res = output_tensor.float_data()[:]
return res
# 展示结果
def post_res(label_dict, res):
print(max(res))
target_index = res.index(max(res))
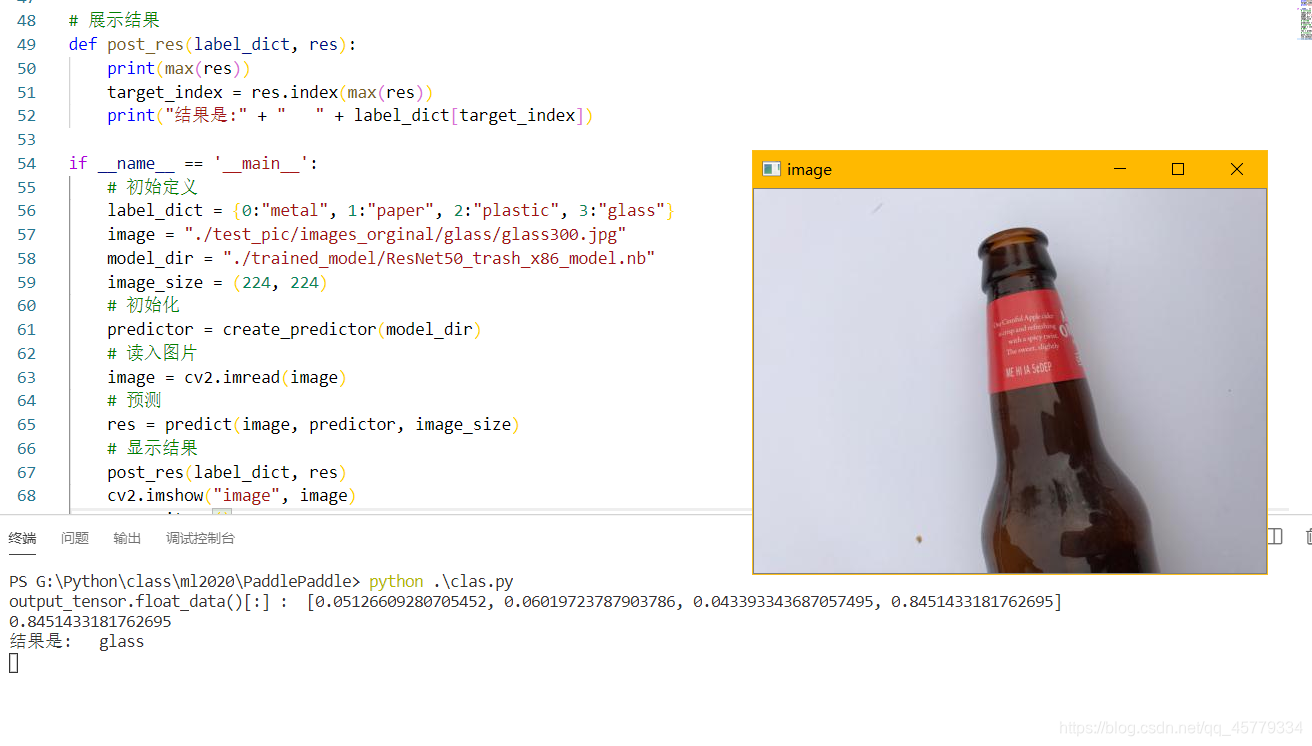
print("结果是:" + " " + label_dict[target_index])
if __name__ == '__main__':
# 初始定义
label_dict = {
0:"metal", 1:"paper", 2:"plastic", 3:"glass"}
image = "./test_pic/images_orginal/glass/glass300.jpg"
model_dir = "./trained_model/ResNet50_trash_x86_model.nb"
image_size = (224, 224)
# 初始化
predictor = create_predictor(model_dir)
# 读入图片
image = cv2.imread(image)
# 预测
res = predict(image, predictor, image_size)
# 显示结果
post_res(label_dict, res)
cv2.imshow("image", image)
cv2.waitKey()
- 結果を示す:
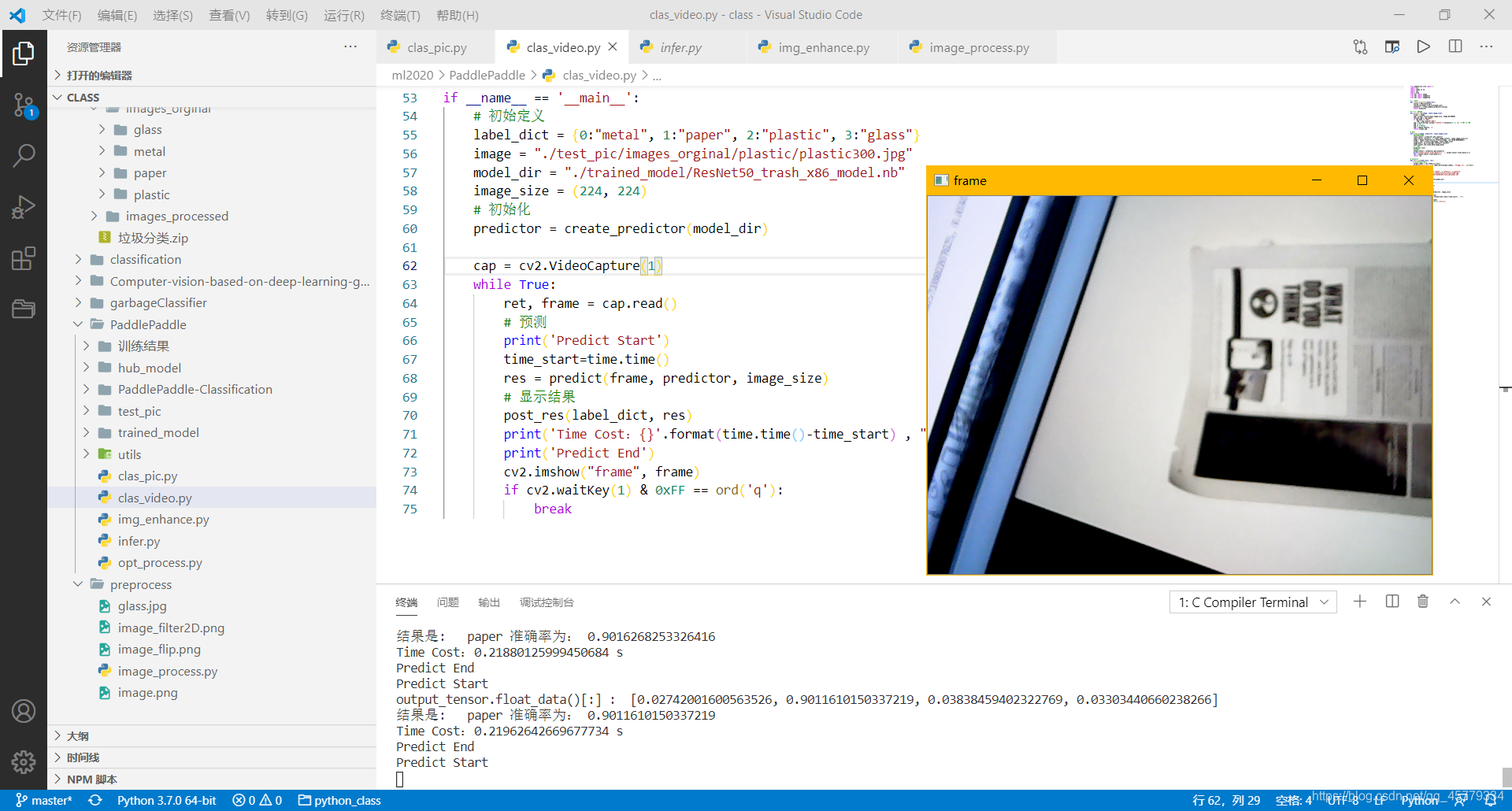
ビデオストリームの予測
from paddlelite.lite import *
import cv2
import numpy as np
import sys
import time
from PIL import Image
from PIL import ImageFont
from PIL import ImageDraw
# 加载模型
def create_predictor(model_dir):
config = MobileConfig()
config.set_model_from_file(model_dir)
predictor = create_paddle_predictor(config)
return predictor
#图像归一化处理
def process_img(image, input_image_size):
origin = image
img = origin.resize(input_image_size, Image.BILINEAR)
resized_img = img.copy()
if img.mode != 'RGB':
img = img.convert('RGB')
img = np.array(img).astype('float32').transpose((2, 0, 1)) # HWC to CHW
img -= 127.5
img *= 0.007843
img = img[np.newaxis, :]
return origin,img
# 预测
def predict(image, predictor, input_image_size):
#输入数据处理
input_tensor = predictor.get_input(0)
input_tensor.resize([1, 3, input_image_size[0], input_image_size[1]])
image = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGRA2RGBA))
origin, img = process_img(image, input_image_size)
image_data = np.array(img).flatten().tolist()
input_tensor.set_float_data(image_data)
#执行预测
predictor.run()
#获取输出
output_tensor = predictor.get_output(0)
print("output_tensor.float_data()[:] : ", output_tensor.float_data()[:])
res = output_tensor.float_data()[:]
return res
# 展示结果
def post_res(label_dict, res):
# print(max(res))
target_index = res.index(max(res))
print("结果是:" + " " + label_dict[target_index], "准确率为:", max(res))
if __name__ == '__main__':
# 初始定义
label_dict = {
0:"metal", 1:"paper", 2:"plastic", 3:"glass"}
model_dir = "./trained_model/ResNet50_trash_x86_model.nb"
image_size = (224, 224)
# 初始化
predictor = create_predictor(model_dir)
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
# 预测
print('Predict Start')
time_start=time.time()
res = predict(frame, predictor, image_size)
# 显示结果
post_res(label_dict, res)
print('Time Cost:{}'.format(time.time()-time_start) , "s")
print('Predict End')
cv2.imshow("frame", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
- 結果を示す: