論文ネットワークセグメンテーションのレビューを読む
自然および医療画像のディープセマンティックセグメンテーション:レビュー
概要
画像セマンティックセグメンテーションは、主にピクセルレベルの集中的な予測タスクを完了し、同じカテゴリに属するピクセル構成の例をシーン認識と画像コンテンツの理解に使用できます。医療画像分析の分野では、画像セグメンテーションを使用して医師の診断を支援することができます。この記事では、現在の主流のセグメンテーションネットワークと医療画像セグメンテーションネットワークを、構造最適化、損失関数最適化、シーケンスモデル、弱く監視されたモデル、およびマルチタスクモデルの側面からレビューし、さらなる研究と調査の方向性を示します。
#セクションIはじめ
に医療画像分析、特に医療画像(X線、MRI、PET、CT画像など)のセグメンテーションの分野への深層学習の適用が大きな注目を集めています。主流の研究の方向性には、深部ネットワークの勾配消失の問題の解決と圧縮の適用が含まれます。軽量ネットワークを構築し、損失関数を最適化してモデルのパフォーマンスを向上させるテクノロジーなど。
この論文の主な仕事は次のとおりです。
(1)2Dおよび3D画像をカバーする、既存の自然の顕著なセグメンテーションモデルおよび医療画像セグメンテーションモデルのレビュー。
(2)セグメンテーションフレームワークは、構造最適化、損失関数最適化、データ合成、弱監視モデル、シーケンスモデル、およびマルチタスクモデルの6つのカテゴリに要約されます。詳しくは図1をご覧ください。
(3)上記のまとめをもとに、次の研究・探求の方向性を示しています。

セクションII自然画像セグメンテーションネットワーク
このセクションでは、セグメンテーションネットワークの構造最適化を、最初に自然画像セグメンテーション、次に医療画像セグメンテーションの順に要約します。主に、ネットワークの深さ、幅、接続モードを最適化し、新しいネットワークレベルを導入します。
パートA完全畳み込みネットワーク(FCN)
2015年に提案された完全畳み込みネットワークは、セマンティックセグメンテーションモデルの創始者と言えます。従来のCNNの完全に接続されたレイヤーをアップサンプリング/転置畳み込みに置き換えることで、ネットワーク出力はなくなります。これは確率ですが、ヒートマップであり、ピクセルレベルでの高密度の予測が可能です。FCNモデルの入力を図に示します。FCNの空間情報をより適切に保持するために、浅い出力をアップサンプリングにマージして、より細かいピクセルレベルのセグメンテーションマップを取得します。

 パートIIエンコーダー-デコーダー
パートIIエンコーダー-デコーダー
別のタイプのセマンティックセグメンテーションネットワークは、SegNet、UNetなどで表されるエンコードおよびデコードネットワーク構造です。エンコードネットワークは特徴抽出に使用され、通常、各エンコーダーは多層畳み込み+ BNです。 + ReLu構造では、デコードネットワークの機能は、エンコーダネットワークによって出力された低解像度の機能を各レベルの入力画像解像度に復元して、ピクセルレベルの分類またはセグメンテーションを実行することです。
次の図は、それぞれSegNetとUNetのネットワーク構造を示しています。

アップサンプリングはSegNetの最大プーリングによって行われるのに対し、FCNでは転置された畳み込みによって行われることがわかります。
 また、コーデック構造に基づいているのは、後でMilletariによって提案されたVNet構造とDenseNet構造です。残りの接続がVNetに追加され、3Dセグメンテーションが実行されます;高密度に接続されたTiramisuネットワーク(TiramisuNet)がDenseNetのアイデアに基づいて追加されます;空間ピラミッドモデルと中空コンボリューションを使用して、さまざまなレベルのコンテキスト情報などの融合が完了します(空間ピラミッドモデルは、さまざまなスケールのフィルターとプールを介してさまざまなレベルの特徴の抽出を完了します。たとえば、後続のネットワークは、鋭いエッジをキャプチャして空間情報を復元するのが簡単ですが、穴の畳み込みは、さまざまな拡張率を介してさまざまなレベルの特徴の抽出を完了します)。
また、コーデック構造に基づいているのは、後でMilletariによって提案されたVNet構造とDenseNet構造です。残りの接続がVNetに追加され、3Dセグメンテーションが実行されます;高密度に接続されたTiramisuネットワーク(TiramisuNet)がDenseNetのアイデアに基づいて追加されます;空間ピラミッドモデルと中空コンボリューションを使用して、さまざまなレベルのコンテキスト情報などの融合が完了します(空間ピラミッドモデルは、さまざまなスケールのフィルターとプールを介してさまざまなレベルの特徴の抽出を完了します。たとえば、後続のネットワークは、鋭いエッジをキャプチャして空間情報を復元するのが簡単ですが、穴の畳み込みは、さまざまな拡張率を介してさまざまなレベルの特徴の抽出を完了します)。

次の図は、コーデックネットワークの接続モードの最適化を比較できます。たとえば、エンコードネットワーク情報はUNetのスキップ接続(緑色の矢印)を介してデコードネットワークに送信され、VNetは各ブロックに残りの接続を導入し、TitanisuNetは各ブロックにあります。ブロック内の前面と背面の畳み込み層に密な接続が導入されます。
 **パートCネットワークの簡素化**
**パートCネットワークの簡素化**
アイデア3は、テンソルスケッチ、チャネル/ネットワークプルーニング、スパース接続などを使用してネットワークを簡素化し、計算の複雑さを軽減することです。
**パートDアテンションネットワーク**
は、さまざまなレイヤーによって作成された一連の出力または機能マップから最も識別力のあるパートを選択することにより、アテンションの適用を完了することができます。たとえば、グローバル平均プールを介して重要な機能マップを選択し、ResNetにアテンションモジュールを追加し、空間機能とチャネル機能に同時に焦点を当てるDualAtteentionネットワークを追加します。
**パートEジェネレーティブ
アドバーサリネットワーク** GoodFellowによって提案されたGANのアイデアは、セグメンテーションネットワークに転送することもできます。GTとセグメンテーションネットワークの出力結果を入力することにより、トレーニングネットワークの出力は実際のセグメンテーションマップに近くなります。
セクションIII医療画像セグメンテーションネットワーク
医療画像セグメンテーションネットワークは、セグメント化された画像タイプに応じて2Dと3Dに分けることができます。
パートAモデルの圧縮
セグメンテーションネットワークは、医療分野、特にリアルタイムのパフォーマンスが必然的に要求される診療所で使用され、処理される画像は非常に高解像度であることが多いため、ネットワークの圧縮が非常に必要です。現在、モデルの圧縮は、NAS、グループの正規化、穴の畳み込み、重み付け、およびその他のスキームを介して実行されます。
パートBコーデック構造に基づく医療画像セグメンテーションモデルの最適化スキーム
コーデック構造は、画像セグメンテーションの分野で優れたパフォーマンスを示していますが、医療画像セグメンテーションには、自然画像と比較してまだ多くの制限があります。たとえば、に基づいて医療画像を収集することは困難です。大規模なデータセットを使用したトレーニングは、ネットワークの過剰適合や不十分な一般化などの問題を簡単に引き起こす可能性があります。
セクションIIによると、次の最適化のアイデアがあります。
アテンションメカニズム:
主な試みは、マルチレベルのアテンションを使用して腹部MRI画像のセグメンテーション品質を改善し、キャビティコンボリューションモジュールを使用して3D画像セグメンテーションの詳細情報を保持することです。医療画像セグメンテーションGANの
敵対ネットワーク
を生成します。膵臓CT画像、網膜血管セグメンテーション、脳腫瘍CT画像の研究に使用されています。
サイクリックニューラルネットワーク
リカレントのアイデアは、多くの医療スキャン画像が時系列であるため、主にLSTMおよびその他の処理シーケンスモデルを使用します。別のアイデアは、リカレント再帰を使用して、詳細情報の抽出と、UNetのセグメンテーションの改善など、長期的な依存関係の送信を増やすことです。パフォーマンス、以前はいくつかの派手なUNetの測定値がありました。
セクションIV損失関数の最適化
損失関数はネットワーク更新の推進力であるため、セグメンテーションモデルの最適化のアイデアは損失関数を最適化することです。
クロスエントロピー損失関数(クロスエントロピー)
は、ピクセルレベルの分類で最も一般的に使用されるクロスエントロピー損失関数です。これは、予測値と真の値をピクセルごとに計算することによって取得されます。式は次のとおりです。

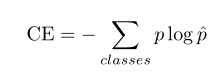 最適化1:加重クロスエントロピー損失関数(WCE)
最適化1:加重クロスエントロピー損失関数(WCE)
医療画像セグメンテーションの非常に重要な特徴は、異なるカテゴリのサンプルの比率がまったく異なることです。たとえば、網膜血管セグメンテーション中の元の画像の前景血管の比率は非常に小さく、ほとんどが黒い背景です。この非常に不均一なサンプルに基づく訓練された分類器の性能を想像することができます。したがって、モデルのパフォーマンスに対するサンプルの不均衡の影響を減らすために、さまざまなカテゴリにさまざまな重みを与える加重クロスエントロピー損失関数を考えるのは自然なことです。
 最適化2:フォーカルロス
最適化2:フォーカルロス
フォーカルロスは、正と負のサンプル間の不均衡の問題を解決することでもあります。クロスエントロピーでさらに変更されています。以前のCEと比較して、もう1つの項目が見つかりました。
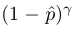 したがって、
したがって、
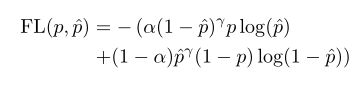 アルファスケール係数を使用して正のバランスを取ります。ネガティブサンプルの割合。
アルファスケール係数を使用して正のバランスを取ります。ネガティブサンプルの割合。
焦点損失の理解については、以下を参照してください。焦点損失
オーバーラップ
に基づく評価指標には、主にダイス係数(F1スコア)、トベルスキー損失、指数対数損失、Lovasz-Softmax損失、境界損失、保守的損失などが含まれます。
ダイス係数は非常によく知られており、その計算はIoUクロスコンビネーション比に似ています。その他の損失は十分に理解されていないため、さらに補足して調査する必要があります。
ダイスロス/ IoU / F1スコア

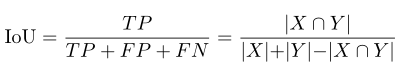
前述のように、医療画像のセグメンテーションは、前景が小さな割合を占め、背景が大きな割合を占める状況に直面することがあります。したがって、前任者はこの問題に対して一連の最適化を行いました。
最適化3:正規化項を使用したクロスエントロピー損失
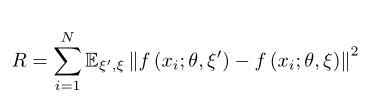
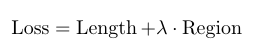
セクションV医療画像の生成
CNNモデルのパフォーマンスはトレーニングデータの量に大きく依存することはよく知られていますが、大規模な医療画像データセットを取得することの難しさを考慮すると、幾何学的変換による限られたトレーニングデータのデータ増幅を実行することは避けられません。GANの導入以来、画像生成を考えるのは当然です。トレーニングデータを拡張する方法。現在、既存の試みには
、CGANを介して脳室MR画像とCT画像を生成してデータを拡張する、
EssNetではMR画像をCT画像で合成し、最終的にCT画像のセグメンテーションに使用する
、X線画像を使用して複数の臓器を合成するなどがあります。待つ。
セクションVI弱い監視モデル
ピクセルレベルのラベリング情報の取得は、時間と手間がかかります。ラベリングされていない画像または部分的にラベリングされた画像に基づいて、監視されていない/監視されていない学習を実行できる場合、それは実際のニーズにより一致しています。現在の試みは次のとおりです。
損失関数の弱く監視されたデータに区別項目を追加することにより、セグメンテーションの精度を維持しながら計算の複雑さを軽減できます。
トレーニングにはバウンディングボックスレベルの監視情報
のみを使用します。画像のみを使用します。レベルの情報出力セグメンテーション結果マスク
。ADMM、教師と学生のモデルなどの助けを借りて、ドメインの移行は、弱く監視された学習の効果を達成できます。
セクションVIIマルチタスクモデル
複数のタスクを同時に学習し、各タスクが特定の精度を維持するマルチタスク学習は、実際のアプリケーションとより一致しています。現在の研究の進歩には、さまざまな損失を組み合わせて建物と空中のセグメンテーションを同時に完了すること、VGG16 +グローバル平均プーリング+ FCNを使用して、患者の検出と皮膚のセグメンテーションのタスクを同時に完了すること、改良されたUNetモデルが胸部CTのセグメンテーションと分類のタスクを同時に完了することが含まれます。 Mask R-CNNは、Faster R-CNNに基づいており、画像ラベルとbboxを使用してマスク予測を完了します。医療画像セグメンテーションのマルチタスクは、主にマルチカテゴリセグメンテーションタスクを完了し、さまざまな組織や臓器にラベルを付けます。
概要
表1は、一般的なセグメンテーションネットワークとその最適化をまとめたものです。主なテストデータセットはPASCAL VOC 2012であり、評価インデックスはIoUです。
 上記のレビューを通じて、医療画像のセグメンテーションにいくつかの制限や問題があることもわかります。
上記のレビューを通じて、医療画像のセグメンテーションにいくつかの制限や問題があることもわかります。
(1)ほとんどの医療画像は高次元であり、GPUに直接接続するのには適していません。通常、スライスやパッチなどの操作が必要であり、効果がありません。空間情報を使用する;
(2)医療画像システムの独自性により、自然画像とは異なるノイズが発生することが多く、処理が面倒で、除去が難しいものもあります;
(3)医療画像の大規模なデータセットを取得するのが難しいため、半監視および弱監視ネットワークは、より多くの臨床応用価値があります。
(4)事前の知識を備えた補助セグメンテーションは、医療画像セグメンテーションにより適しています。
考えられる方向
医療画像セグメンテーションの分野におけるUNetアーキテクチャの主流のセグメンテーションモデルは、スキップ接続と組み合わせたコーデック構造に基づくUNetシリーズフレームワークです。スキップ接続は、勾配の消失と最前層の情報送信の問題を効果的に解決できます。空間ピラミッド、中空コンボリューションなどと組み合わせて、さらに制御できます。フロントレベル情報の転送特性。
シーケンスモデル
医療画像のセグメンテーションには多数の3D画像が含まれるため、時系列モデルを使用して処理を支援することは避けられませんが、スライスプロセスでは空間的な幾何学的特徴が失われることは避けられません。将来的には、ボリュームメトリックデータのシーケンス方法をさらに調査する必要があります。
損失関数
従来の損失には、オーバーラップベースと距離ベースの損失関数があります。解決する必要があるのは、ディープネットワークでの勾配消失の問題を排除する方法と、
NASのような最適な損失関数を自動的に検索する方法です。
その他の方向性は次のとおりです。
非医療事前トレーニングモデルマルチモーダルセグメンテーションモデル。MRI、PET、CT、X線など多くの種類の医療画像があり、それぞれを取得するのは簡単ではないため、効果的な1対1のセグメンテーションモデルを見つけるのは難しいため、非医療画像を使用できるかどうかを検討してください。事前にトレーニングされたモデルは、医療セグメンテーションモデルの学習を支援します。
大規模なオープンソースデータセット。より大規模な2D / 3D医療画像セグメンテーションデータセットをオープンソース化するために努力している医療データセットは本当に貴重です。
強化学習は、条件付きランダムフィールド(CRF)などの医療画像セグメンテーションに強化学習を適用します。これは、少量のラベル付きデータと多数のラベルなしの弱く監視されたモデルを使用します。
FP Analysisは、一部のモデルが誤検知の分類に失敗する理由を分析します。
上記。