関連するブログ、ムークラス参照列この一連のJavaソースコードとシステムメーカーは簡潔Zhentiインタビュアー
この列の下には、GitHubのアドレスです:
ソースは解決:https://github.com/luanqiu/java8
記事デモ:HTTPS:// GitHubの。 com / luanqiu / java8_demo
クラスメートは必要に応じてそれを見ることができます)
Javaソースコードの分析とインタビューの質問-推論:他のJavaソースコードでのキューのアプリケーション
開発者が使用するAPIを提供することに加えて、紹介キューは、スレッドプールやロックなど、Javaの他のAPIと密接に統合されます。スレッドプールはキューAPIを直接使用します。ロックはキューの概念を借用し、キューとスレッドを再実装します。プールとロックは、私たちが仕事でよく使用するAPIであり、インタビュアーからも頻繁に尋ねられます。キューは両方の実現に重要な役割を果たします。一緒に見てみましょう。
1キューとスレッドプールの組み合わせ
1.1スレッドプールでのキューの役割
誰もがスレッドプールを使用している必要があります。たとえば、固定サイズのスレッドプールを作成して、実行中のスレッドに文を出力させたい場合は、次のようなコードを記述します。
ExecutorService executorService = Executors.newFixedThreadPool(10);
// submit 是提交任务的意思
// Thread.currentThread() 得到当前线程
executorService.submit(() -> System.out.println(Thread.currentThread().getName() + " is run"));
// 打印结果(我们打印出了当前线程的名字):
pool-1-thread-1 is run
コード内のエグゼキューターは、主にスレッドプールをより便利に構築するのに役立つ並行ツールクラスです。newFixedThreadPoolメソッドは、固定サイズのスレッドプールが構築されることを示します。指定する入力パラメーターは10で、最大スレッドプールを構築できます。 10スレッド出てきます。
実際の作業では、フローのサイズを制御することはできません。ここでは、最大10スレッドを設定していますが、100のリクエストが一度に来る場合、10スレッドがビジーである必要があります。残りの90リクエストはどうですか?
このとき、キューを消す必要があります。スレッドが消化できないデータをキューに入れ、データをキューに入れ、スレッドが消費するのを待って、キューから取り出してゆっくり消費します。
説明のために絵を描きましょう:
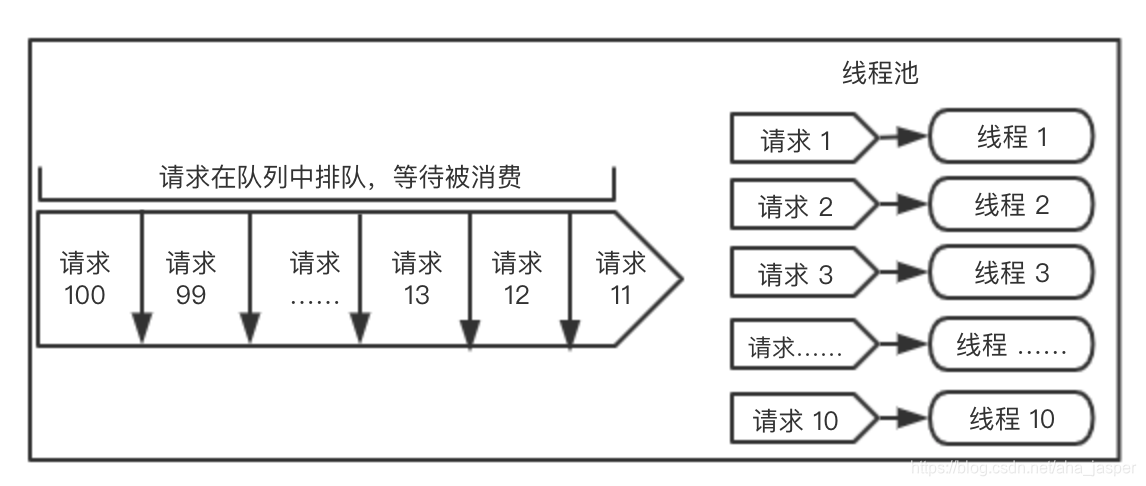
上の図の右側は、10個のスレッドがフルストレングスでリクエストを消費していることを示し、左側は、残りのリクエストがキューにキューイングされて消費を待機していることを示しています。
キューがスレッドプール内で非常に重要な位置を占めていることがわかります。スレッドプール内のスレッドがビジーでない場合、リクエストはキューで待機され、ゆっくりと消費されます。
次に、スレッドプールで使用されるキューのタイプと、それらが果たす役割を見てみましょう。
1.2スレッドプールで使用されるキューのタイプ
1.2.1 LinkedBlockingQueueキュー
先ほど言ったnewFixedThreadPool newFixedThreadPool
は固定サイズのスレッドプールです。つまり、スレッドプールが初期化されても、スレッドプールのスレッドサイズは変更されません(スレッドプールのデフォルト設定では、コアスレッドの数はリサイクルされません)。 newFixedThreadPoolのソースコードを見てみましょう。
// ThreadPoolExecutor 初始化时,第一个参数表示 coreSize,第二个参数是 maxSize,coreSize == maxSize,
// 表示线程池初始化时,线程大小已固定,所以叫做固定(Fixed)线程池。
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
ソースコードでは、ThreadPoolExecutorが初期化されていることがわかります。ThreadPoolExecutorはスレッドプールのAPIです。スレッドプールの章で詳しく説明します。5番目の構築パラメーターはキューです。スレッドプールは、シーンに応じて異なるキューを選択します。 LinkedBlockingQueueはQueueのデフォルトパラメータです。つまり、このブロッキングキューの最大容量はIntegerの最大値です。つまり、スレッドプールの処理容量が制限されている場合、最大数のタスクをブロッキングキューに格納できます。
ただし、実際の作業では、newFixedThreadPoolを直接使用することはお勧めできません。主に、LinkedBlockingQueueのデフォルトコンストラクターを使用しているため、キューの容量が大きすぎ、リアルタイムの応答を必要とするリクエストでは、キューの容量が大きすぎて有害になることが多いためです。 。
たとえば、上記のスレッドプールを使用する場合、スレッドは10個あり、キューはIntegerの最大値です。1w/ qpsリクエストなどの同時トラフィックが大きい場合、10個のスレッドがまったく消費されず、リクエストが多くなります。キューでブロックされています。10個のスレッドが引き続き継続的に消費していますが、キュー内のすべてのデータを消費するのに時間がかかります。すべてのデータを消費するのに3秒かかり、これらのリアルタイムリクエストにはすべてタイムアウトがあるとします。デフォルトのタイムアウトは2秒です。時間が2秒に達すると、リクエストがタイムアウトしてエラーが返されます。このとき、キュー内の多くのタスクが消費を待機しています。消費が後で完了しても、呼び出し元に返すことはできません。 。
上記の状況では、タイムアウト後にインターフェイスがエラーを返したことが発信者に表示されますが、サーバータスクは実行待ちの状態です。3秒後、サーバータスクは正常に実行される可能性がありますが、発信者は認識できず、パーティーが再び電話をかけると、要求が成功したことがわかります。
発信者がページから発信した場合、エクスペリエンスは低下します。ページの最初の呼び出しでエラーが発生します。ユーザーがページを更新すると、ページに前のリクエストが成功したことが表示されます。これは非常に悪いエクスペリエンスです。
したがって、キューのサイズはそれほど大きくなく、実際の消費状況に応じてキューのサイズを設定できるようにして、インターフェイスがタイムアウトする前にキューに入れられたリクエストを確実に実行できるようにします。
シーンはもっと複雑ですが、理解を容易にするために、絵を描いて全体のプロセスを説明しました:
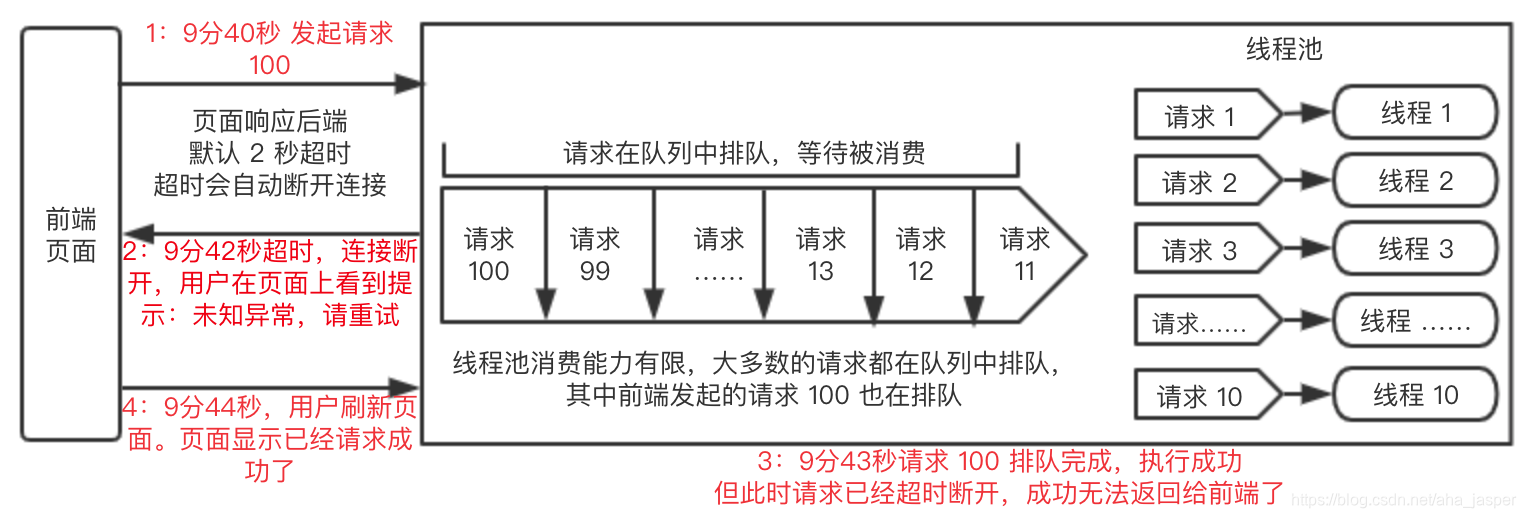
この種の問題は、実際の作業ではすでに非常に深刻な生産事故であり、使用には注意が必要です。
newSingleThreadExecutor
とnewFixedThreadPoolは同じで、newSingleThreadExecutorメソッドの下部もLinkedBlockingQueueです。newSingleThreadExecutorスレッドプールの下部スレッドには1つしかありません。つまり、このスレッドプールは一度に1つの要求しか処理できず、残りの要求はキュー内の実行キューに入れられますnewSingleThreadExecutorのソースコード実装を見てください。
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
// 前两个参数规定了这个线程池一次只能消费一个线程
// 第五个参数使用的是 LinkedBlockingQueue,说明当请求超过单线程消费能力时,就会排队
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
最下層がLinkedBlockingQueueのデフォルトパラメータを使用していることがわかります。これは、キューの最大値がIntegerの最大値であることを意味します。
1.2.2 SynchronousQueue
newFixedThreadPoolメソッドに加えて、スレッドプールの作成時に異なるキューに対応するメソッドがいくつかあります。newCachedThreadPoolを見てみましょう。newCachedThreadPoolの最下層はSynchronousQueueキューに対応しています。ソースコードは次のとおりです。
public static ExecutorService newCachedThreadPool() {
// 第五个参数是 SynchronousQueue
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
SynchronousQueueキューにはサイズの制限がなく、リクエストの数はキューに耐えることができます。これは彼の利点であると言えます。欠点は、データがキューに入れられるたびにすぐに戻ることができず、スレッドがデータを取得するのを待つ必要があることです。正常に戻るためには、リクエストの量が多く、消費容量が少ない場合、ホドラーが大量のリクエストを保留することになります。スローな消費が完了してから解放する必要があるため、通常の作業には注意が必要です。
1.2.3 DelayedWorkQueueキュー
newScheduledThreadPoolは、スケジュールされたタスクのスレッドプールを表します。基になるソースコードは次のとおりです。
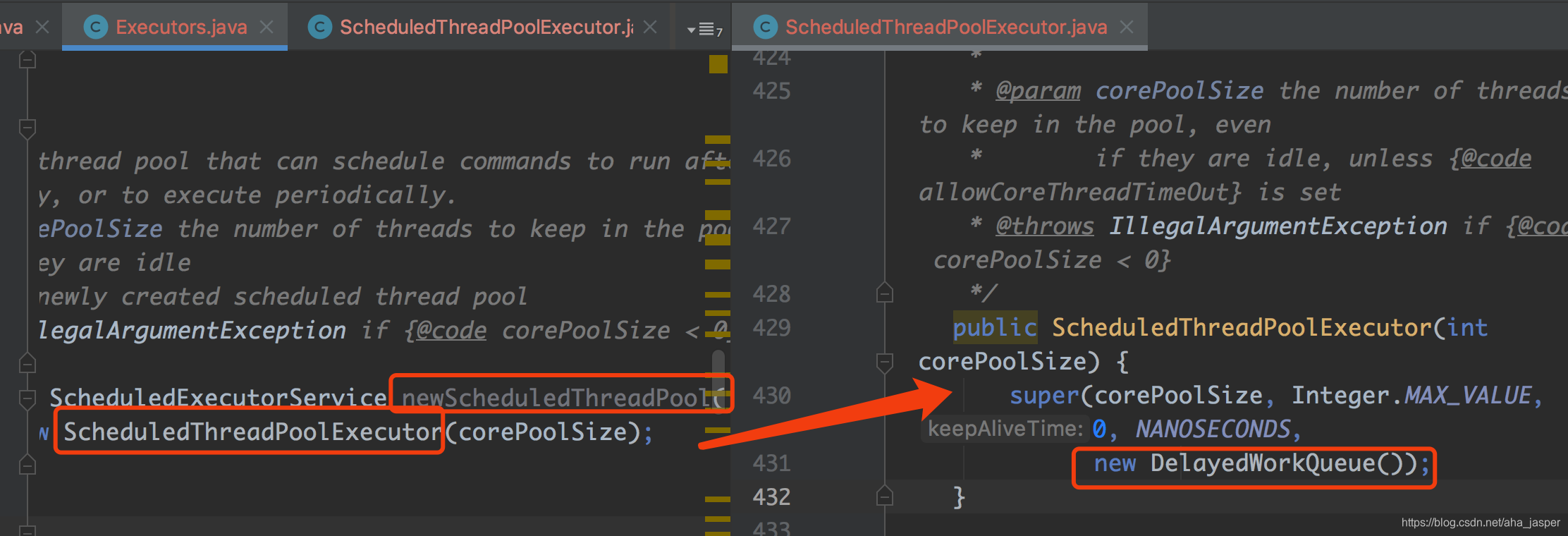
スクリーンショットの左から右に、下部のキューがDelayedWorkQueue遅延キューを使用していることを確認できます。これは、スレッドプールの下部の遅延の関数がDelayedWorkQueueキューによって提供され、新しい遅延リクエストがすべて最初であることを示しています。キューに対して、遅延時間が経過すると、スレッドプールはキューからスレッドを自然に取り出して実行できます。
newSingleThreadScheduledExecutorメソッドもnewScheduledThreadPoolと同じで、DelayedWorkQueueのdelay関数を使用しますが、前者は単一のスレッドによって実行されます。
1.3まとめ
スレッドプールのソースコードから、次のことがわかります。
- スレッドプールの設計では、キューがデータのバッファリングとデータの実行の遅延の役割を果たします。スレッドプールの消費容量が制限されている場合、リクエストをキューに入れて、スレッドプールの消費をゆっくりと行うことができます。
- さまざまなシナリオによると、スレッドプールは、DelayedWorkQueue、SynchronousQueue、LinkedBlockingQueueなどのさまざまなキューを使用して、通常の実行用のスレッドプールを実装するためのDelayedWorkQueueのDelay関数を使用するなど、独自のさまざまな機能を実装することを選択します。
2キューとロックの組み合わせ
通常、ロックコードを記述するときにこれを記述します。
ReentrantLock lock = new ReentrantLock();
try{
lock.lock();
// do something
}catch(Exception e){
//throw Exception;
}finally {
lock.unlock();
}
ロックの初期化->ロック->ビジネスロジックの実行->ロックの解放、これは通常のプロセスですが、ロックを取得するために一度に1つのスレッドしか存在できないことがわかっています。え?
待機中、ロックを取得できない他のスレッドは待機キューで待機します。ロックが解放されると、それらのスレッドがロックを獲得します。スケマティックダイアグラムを描画します。
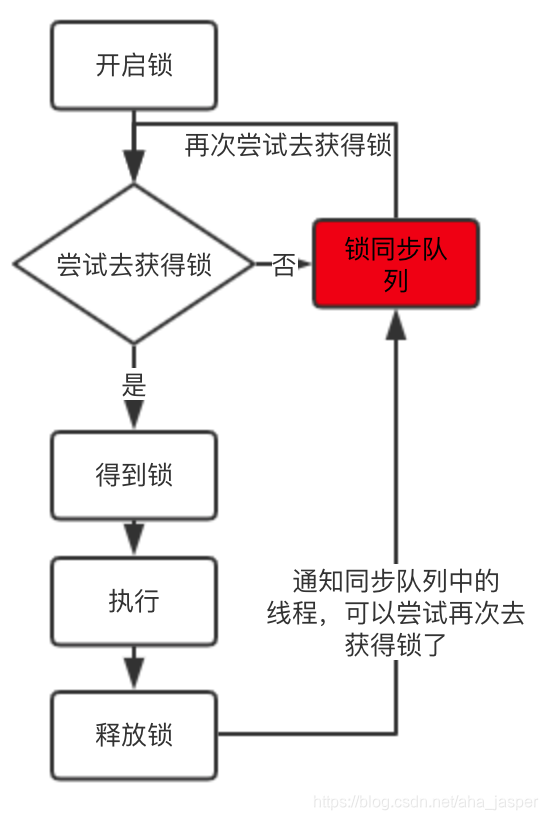
図の赤いマークは同期キューです。ロックを取得できないスレッドは同期キューにキューイングされます。ロックが解放されると、同期キュー内のスレッドがロックを獲得し始めます。
ロック内のキューの機能の1つは、ロックを取得できないスレッドの管理を支援し、これらのスレッドが辛抱強く待機できるようにすることです。
同期キューは既存のキューAPIを使用して実装されていませんが、基礎となる構造とアイデアは現在のキューと一致しているため、キューの章をよく理解しており、ロック同期キューを理解するのに非常に役立ちます。
3まとめ
キューのデータ構造は非常に重要です。これは、スレッドプールとロックの2つのヘビーウェイトAPIで非常に重要な役割を果たします。キューの下部にある一般的なデータ構造について非常に明確にし、データがエンキューおよびデキューされる方法を理解する必要がありますはい、キューの章も比較的複雑です。たくさんデバッグすることをお勧めします。また、githubでデバッグデモも提供しています。デバッグを試すことができます。
