
1. Introduction aux activités de lancement de nouveaux produits
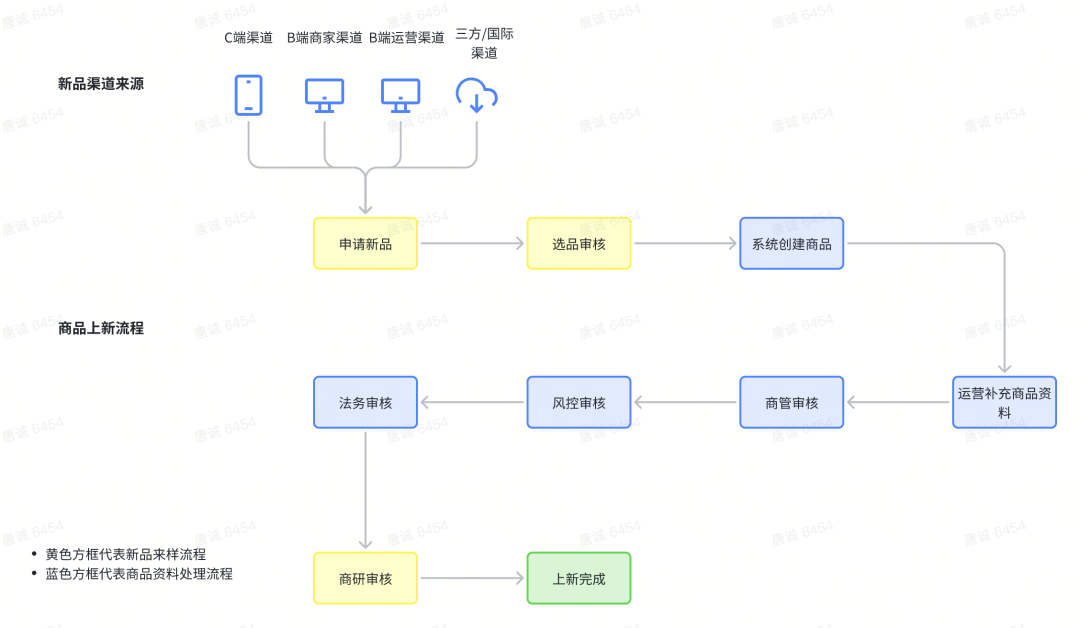
La liste de produits signifie mettre un nouveau produit sur la plate-forme Dewu. Un processus complet de liste de produits commence par la soumission de nouvelles demandes de produits à partir de diverses sources et canaux. Il doit passer par plusieurs cycles d'examen par différents rôles, notamment :
-
Examen de la sélection du produit : déterminer s'il répond aux exigences de conservation en fonction des informations soumises dans la demande de nouveau produit ;
-
Examen des données sur les produits : examen des données sur les produits pour en vérifier l'exactitude et l'exhaustivité, y compris plusieurs cycles de gestion commerciale, de contrôle des risques et d'examen juridique ;
-
Examen de la recherche commerciale : l'examen de la recherche commerciale est un jugement sur la capacité du produit à être identifié et pris en charge sur la plate-forme, ce qui est également une caractéristique de l'activité Dewu.
Dans ces cycles d'examen, l'examen de la sélection des produits et l'examen de la recherche commerciale appartiennent au processus d'échantillonnage des nouveaux produits. Ils n'apparaissent que dans la nouvelle activité du produit. Ils déterminent si le produit peut être vendu sur la plate-forme Dewu ; appartient au processus de traitement des données produit, il détermine si les informations produit actuelles répondent aux exigences d'affichage sur la face C.
Par conséquent, dans la mise en œuvre du système, le flux d'état du processus d'échantillon entrant de nouveau produit et le processus de traitement des données de produit doivent être impliqués. Le premier implique la table d'échantillons entrant de nouveau produit, et le second est principalement la table principale du produit SPU. se concentre sur le flux et la machine d'état du processus d'échantillonnage entrant des nouveaux produits. L'attribut du canal source du processus d'échantillonnage des nouveaux produits est très évident et il existe de grandes ou petites différences dans la logique commerciale et les processus des différents canaux.
2. Pourquoi envisager d'accéder à une machine à états ?
-
Il existe un grand nombre de valeurs d'énumération de statut et les conditions de leur transfert ne sont pas claires. Pour comprendre le processus métier, vous devez étudier attentivement le code, et le coût de démarrage et de maintenance est élevé.
-
Le transfert d’États est spécifié de manière totalement arbitraire par le code, et il existe des risques liés aux transferts arbitraires entre États.
-
Certains transferts d'État ne supportent pas l'idempotence et des opérations répétées peuvent entraîner des conséquences inattendues.
-
Le coût et le risque liés au transfert d'états nouveaux et modifiés sont élevés, la portée des modifications du code est incontrôlable et les tests nécessitent une régression de l'ensemble du processus.
3. Statut impliqué dans le processus de lancement d'un nouveau produit
Énumération du statut des échantillons de nouveaux produits
Le champ d'état correspondant à la table d'échantillons de nouveaux produits contient les valeurs d'énumération suivantes (modérément simplifiées pour faciliter l'explication) :
public enum NewProductShowEnum {
DRAFT(0, "草稿"),
CHECKING(1, "选品中"),
UNPUT_ON_SALE_UNPASS(2, "选品不通过"),
UNPUT_ON_SALE_PASSED(3, "商研审核中"),
UNPUT_ON_SALE_PASSED_UNSEND(4, "商品资料待审核"),
UNPUT_ON_SALE_PASSED_UNSEND_NOT_PUT(5, "鉴别不通过"),
UNPUT_ON_SALE_PASSED_SEND(6, "请寄样"),
SEND_PRODUCT(7, "商品已寄样"),
SEND_PASS(8, "寄样鉴别通过"),
SEND_REJECT(9, "寄样鉴别不通过"),
GONDOR_INVALID(10, "作废"),
FINSH_SPU(11, "新品资料审核通过"),
}
Énumération du statut du SPU
Le champ d'état correspondant à la table principale du produit SPU contient les valeurs d'énumération suivantes (modérément simplifiées pour faciliter l'explication) :
public enum SpuStatusEnum {
OFF_SHELF(0, "下架"),
ON_SHELF(1, "上架"),
TO_APPROVE(2, "待审核"),
APPROVED(3, "审核通过"),
REJECT(4, "审核不通过"),
TO_RISK_APPROVE(8, "待风控审核"),
TO_LEGAL_APPROVE(9, "待法务审核"),
}
La partie transfert de statut du SPU impliquée dans le processus métier de lancement du nouveau produit est soumise au transfert de statut du produit. Le transfert de statut du produit est également connecté à la machine d'état (mais ce n'est pas le contenu abordé dans cet article). L'article discutera principalement de l'état du transfert de statut du nouveau produit.
4. Tous les événements concernant les échantillons de nouveaux produits
-
Enregistrer le brouillon du nouveau produit
-
Soumettre une demande de nouveau produit
-
Sélection de produits réussie
-
Échec de la sélection du produit
-
Soumettre à nouveau après le rejet de la sélection de produits
-
Lancer un examen de la recherche commerciale
-
Revue de recherche commerciale-identification de support
-
L'identification et l'évaluation des recherches commerciales ne sont pas prises en charge
-
Examen de la recherche commerciale : les informations sur le produit sont incorrectes
-
Examen SPU rejeté pendant plus de X jours
-
Lancer l'envoi d'échantillons
-
Mise à jour de la progression de la livraison des échantillons
12 au total.
5. Transfert de statut d'échantillon de nouveau produit
Comme mentionné ci-dessus, différents canaux sources de produits ont des processus de lancement de nouveaux produits différents, ce qui signifie que le flux de statut des différents canaux est également différent. Voici une illustration des canaux de vente côté B :
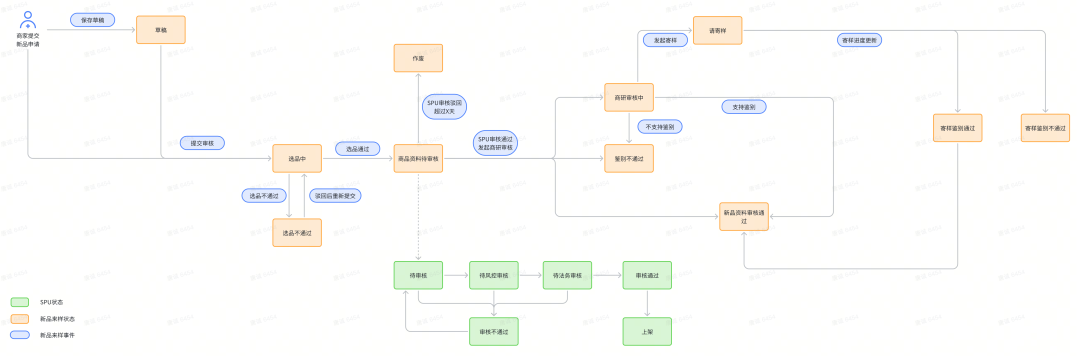
Dans la figure, la case orange représente l'état des échantillons entrants de nouveaux produits, la case verte représente l'état du SPU, la case bleue arrondie représente l'événement qui déclenche le changement d'état et les endroits reliés par des flèches représentent le flux depuis l'état actuel. à l'état suivant.
Notez que lorsque certains événements sont déclenchés, l'état cible vers lequel doit être transféré n'est pas fixe. Une série de jugements logiques est nécessaire pour déterminer l'état cible vers lequel l'événement finira par se dérouler.
6. Sélection de la technologie des machines à états
Choisissez Spring StateMachine comme cadre de machine d'état réel Pour des processus et des détails spécifiques, veuillez vous référer à cet article https://mp.weixin.qq.com/s/TqXMtS44D4w6d1-KLxcoiQ .
7. Difficultés rencontrées par l'accès aux machines d'état
À l'heure actuelle, le code des échantillons de nouveaux produits est toujours confronté au problème du couplage de code entre différents canaux, qui doit être résolu ensemble dans cet accès, sinon le coût d'accès à la machine d'état sera très élevé et la qualité sera difficile à garantir. , et la maintenance ultérieure sera plus difficile. Même si les modifications de la machine à états mentionnées ci-dessus sont effectuées dans des conditions idéales, sans autres modifications, il y aura toujours deux problèmes :
-
Couplage de la logique de jugement de l'état cible ;
-
Le couplage qui exécute réellement l'action.
On peut simplement comprendre qu'il existe une très grande interface dans la mise en œuvre de la garde de la machine à états (pour déterminer si les conditions préalables à l'exécution sont remplies) et de l'action (l'exécution réelle de l'action), qui contient différentes méthodes pour déterminer la cible. statut et exécution de différentes actions sur tous les canaux, il est très difficile de lire pour comprendre ce que fait spécifiquement un certain canal.
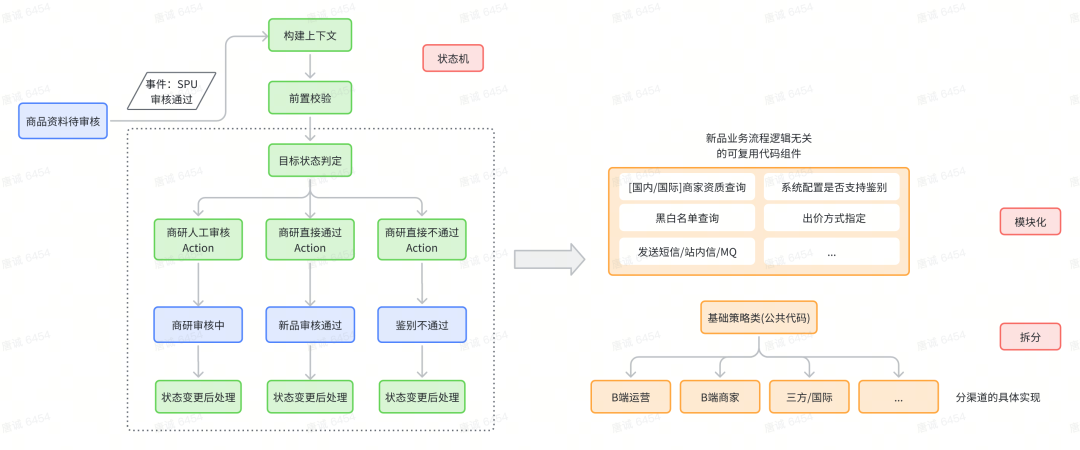
Le problème est concentré dans le code de l'interface d'examen de la sélection des produits et d'examen de la recherche commerciale pour les échantillons entrants de nouveaux produits (cette partie est également la partie avec la logique métier la plus complexe pour les échantillons entrants de nouveaux produits). La logique réussite-échec, la sélection des produits et la logique de la recherche commerciale sont toutes mélangées. Le code est long et illisible. Il y a également des problèmes avec les transactions volumineuses (plusieurs appels RPC dans la transaction). tandis que la machine d’état est connectée et les fusions, notamment :
-
Les codes des différentes chaînes sont divisés à l'aide du mode stratégie ;
-
Différents états et différentes logiques de traitement d'événements d'opération sont résumés dans les classes de garde et d'action de différents états et événements de la machine à états ;
-
La même logique de traitement de code dans différents canaux est encapsulée dans des modules de code individuels et appelée dans chaque canal.
La méthode globale de transformation est présentée dans la figure ci-dessous :
8. Revenu attendu
Comme on peut le comprendre de ce qui précède, bien qu'il s'agisse d'un accès à une machine d'état, il faut en fait compléter deux aspects de la transformation. L'un consiste à achever le découplage du code métier divisé en canaux et en opérations dans l'ensemble de cette partie. la transformation, ont pu :
-
Résoudre les problèmes de transaction majeurs dans le lien de demande de nouveau produit précédent, tels que : la soumission de l'enregistrement et l'examen du nouveau produit ;
-
L'isolement commercial entre les canaux sources des produits rend la portée des modifications de code plus contrôlable et plus propice aux tests ;
-
Améliorez l'évolutivité du code, abaissez le seuil de compréhension du code et améliorez l'efficacité du développement itératif pour les besoins quotidiens.
Le deuxième est l'accès à la machine d'état, qui peut résoudre le problème de flux d'état dans le processus d'échantillonnage de nouveaux produits, notamment :
-
Gestion unifiée et centralisée des règles de changement de statut pour faciliter l'apprentissage et la maintenance ultérieure ;
-
Éviter les transferts de statut illégaux et répétés ;
-
Il devient plus facile d’ajuster l’ordre entre les nouveaux états et processus d’état, et les modifications de code sont plus contrôlables.
9. Conception détaillée
La justification de la répartition par canal
Le lancement de nouveaux échantillons de produits à partir de différents canaux sources de produits est un processus dans lequel différents rôles soumettent de nouveaux produits via différents terminaux. La combinaison de rôles et de terminaux est fixe et ne peut pas être combinée à volonté. En regardant les rôles ou les terminaux seuls, ils n'ont pas d'importance. une entreprise commune Caractéristiques, ce n'est que lorsque des rôles spécifiques sont déterminés qu'un processus commercial complet peut être déterminé.
La possibilité de postuler pour de nouveaux produits dans chaque canal est également différente. Par exemple, les commerçants ont la compréhension la plus complète des informations sur les produits, ils peuvent donc remplir des informations complètes sur les produits lorsqu'ils postulent pour de nouveaux produits, et il y a plus de processus commerciaux que d'autres. En comparaison, seule une petite quantité d'informations sur le produit peut être renseignée du côté de l'application. Une fois la demande rejetée, elle ne peut pas être modifiée et soumise. Par conséquent, les différences entre les différentes chaînes sont naturelles et peuvent continuer à exister en fonction des chaînes elles-mêmes.
Par conséquent, il est raisonnable et nécessaire de répartir les flux selon les canaux pour certaines opérations.
Les opérations commerciales sont découplées par canal
Interface commune pour les opérations commerciales
Les enregistrements uniques de nombreux nœuds importants dans les échantillons de nouveaux produits (les opérations par lots seront également converties en traitement unique) les opérations commerciales (telles que la soumission de nouvelles demandes de produits, l'examen de la sélection de produits, l'examen de la recherche commerciale) peuvent être résumés dans " prétraitement des demandes -> vérification des opérations " -> Exécuter la logique métier -> Opérations de persistance -> Actions de post-traitement associées ", donc une classe d'interface commune est conçue pour transporter le processus d'exécution de différentes opérations commerciales pour les nouveaux produits et échantillons provenant de différents canaux :
public interface NspOperate<C> {
/**
* 支持的商品来源渠道
* @return
*/
Integer supportApplyType();
/**
* 支持的操作类型
* @return
*/
String operateCode();
/**
* 请求预处理
* @param context
*/
void preProcessRequest(C context);
/**
* 校验
* @param context
*/
void verify(C context);
/**
* 执行业务逻辑
* @param context
*/
void process(C context);
/**
* 执行持久化
* @param context
*/
void persistent(C context);
/**
* 后处理
* @param context
*/
void post(C context);
}
Quelques notes:
-
Chaque événement de la machine à états suivante correspond au type de fonctionnement de l'interface un à un. De plus, d'autres types d'opérations peuvent également être définis pour des scénarios qui n'impliquent pas de transfert d'état (par exemple : modification de nouvelles applications de produit, création de SPU basées sur de nouvelles applications de produit).
-
La définition de la méthode de processus est relativement large.Dans différentes opérations commerciales, le contenu réel de l'exécution peut être très différent, par exemple, lors de la soumission d'une évaluation d'un nouveau produit, vous ne pouvez effectuer que certaines actions d'assemblage de données, alors que dans une étude de recherche commerciale, vous devez analyser les objectifs après cette opération. Jugement de statut. Par conséquent, les sous-classes peuvent se diviser davantage et définir de nouvelles méthodes à mettre en œuvre en fonction de leurs propres besoins métier.
-
La méthode de persistance persistante est définie séparément pour prendre en charge l'ajout de transactions uniquement à cette méthode. Le code système actuel a en fait une conception similaire, mais la transaction est trop large, incluant l'ensemble du processus d'exécution tel que la vérification et le traitement métier. Elle peut inclure divers RPC. Les appels, ce qui est également l'une des raisons importantes des transactions volumineuses, il est donc clair ici que l'implémentation de cette méthode lit et écrit uniquement les opérations de base de données et ne contient aucune logique métier.
-
Chaque implémentation de cette interface utilise "canal source du produit + type d'opération" pour former une clé unique pour la gestion de Spring Bean. En même temps, afin de tenir compte du fait que certaines opérations ne distinguent pas la source du produit, il est permis de définir. un applyType spécial (tel que -1) pour représenter l'implémentation actuelle prend en charge tous les canaux. Lors de l'obtention de l'implémentation, optimisez pour obtenir l'implémentation du canal actuel. S'il n'est pas trouvé, essayez de trouver l'implémentation de tous les canaux :
public NspOperate getNspOperate(Integer applyType, String operateCode) {
String key = buildKey(applyType, operateCode);
NspOperate nspOperate = operateMap.get(key);
if (Objects.isNull(nspOperate)) {
String generalKey = buildKey(-1, operateCode);
nspOperate = operateMap.get(generalKey);
}
AssertUtils.throwIf(Objects.isNull(nspOperate), "NspOperate not found! key = " + key);
return nspOperate;
}
Cours de mise en œuvre d'opérations commerciales
Selon le scénario commercial actuel, afin de faciliter la réutilisation de certains codes, la mise en œuvre des opérations commerciales comporte jusqu'à trois niveaux de relations d'héritage :
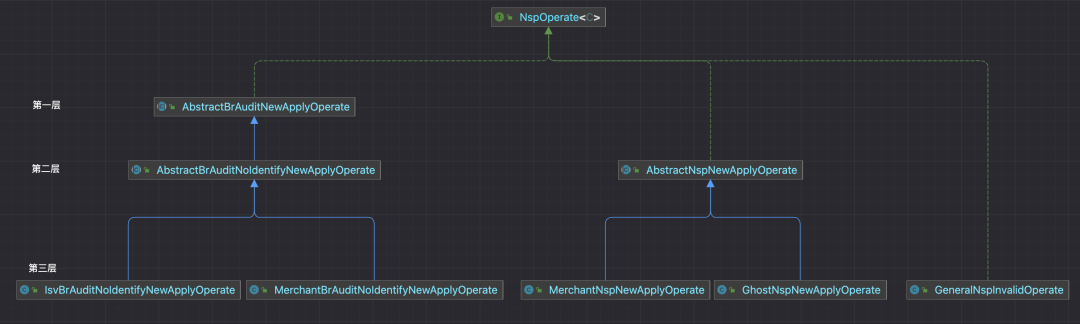
-
Le premier niveau : dimensions pour l'agrégation des types d'opérations (événements commerciaux), tels que l'examen de la recherche commerciale, où vous pouvez définir des codes communs et des méthodes personnalisées dans l'examen de la recherche commerciale, telles que : vérification générale des paramètres d'entrée pour l'examen de la recherche commerciale, les champs ne sont pas vides. etc.
-
Deuxième niveau : spécifique à la dimension du type d'opération (événements commerciaux), telle que la revue de recherche commerciale - prend en charge l'identification, la revue de recherche commerciale - ne prend pas en charge l'identification, etc. Ici, vous pouvez définir les codes communs de tous les canaux sources de produits sous le type d'opération. dimension. Par exemple : la raison est requise lorsque l'identification n'est pas prise en charge et que l'examen de la recherche commerciale appelle une série de logiques de jugement provenant de plusieurs systèmes.
-
La troisième couche : Implémentation spécifique au niveau du canal source du produit, vous pouvez réutiliser le code dans la classe parent.
Toutes les opérations commerciales ne nécessitent pas ces trois niveaux de mise en œuvre. En utilisation réelle, trois situations se produiront, telles que :
-
Il n'y a qu'une seule couche : les échantillons de nouveaux produits sont invalidés, quel que soit le canal source du produit. Tous les canaux utilisent la même logique, et une seule classe d'implémentation suffit.
-
Il n'y a que deux niveaux : soumettre une nouvelle demande de produit et faire la distinction entre les différents canaux de source de produits.
-
Il existe trois niveaux : l'examen de la recherche commerciale sur les nouveaux produits est également divisé en plusieurs types d'opérations (événements commerciaux), tels que : l'examen de la recherche commerciale - prend en charge l'identification, l'examen de la recherche commerciale - ne prend pas en charge l'identification, l'examen de la recherche commerciale - initie. envoi d'échantillons, etc., chaque canal source de produits a sa propre implémentation sous chaque type d'opération.
Accès à la machine à états
Définition de la machine à états
À en juger par le diagramme de flux d'état ci-dessus, le flux d'état des nouveaux produits et échantillons est relativement clair, mais en fait, il y aura quelques différences mineures dans le processus d'état de chaque canal. Afin d'éviter une division incomplète des canaux sources, des considérations globales sont nécessaires. également pris en compte. Le coût de configuration de la machine à états n'est pas élevé, il est donc décidé que chaque canal construit sa propre configuration de machine à états.
En prenant le canal côté C comme exemple, la configuration de la machine à états est la suivante :
@Configuration
@Slf4j
@EnableStateMachineFactory(name = "newSpuApplyStateMachineFactory")
public class NewSpuApplyStateMachineConfig extends EnumStateMachineConfigurerAdapter<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum> {
public final static String DEFAULT_MACHINEID = "spring/machine/commodity/newspuapply";
@Resource
private NewSpuApplyStateMachinePersist newSpuApplyStateMachinePersist;
@Resource
private NspNewApplyAction nspNewApplyAction;
@Resource
private NspNewApplyGuard nspNewApplyGuard;
@Bean
public StateMachinePersister<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum, NewSpuApplySendEventContext> newSpuApplyMachinePersister() {
return new DefaultStateMachinePersister<>(newSpuApplyStateMachinePersist);
}
@Override
public void configure(StateMachineConfigurationConfigurer<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum> config) throws Exception {
config.withConfiguration().machineId(DEFAULT_MACHINEID);
}
@Override
public void configure(StateMachineStateConfigurer<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum> config) throws Exception {
config.withStates()
.initial(NewProductShowEnum.STM_INITIAL)
.state(NewProductShowEnum.CHECKING)
.state(NewProductShowEnum.UNPUT_ON_SALE_UNPASS)
.state(NewProductShowEnum.UNPUT_ON_SALE_PASSED_UNSEND)
.state(NewProductShowEnum.UNPUT_ON_SALE_PASSED)
.choice(NewProductShowEnum.STM_UNPUT_ON_SALE_PASSED_UNSEND)
.choice(NewProductShowEnum.STM_UNPUT_ON_SALE_PASSED)
.state(NewProductShowEnum.UNPUT_ON_SALE_PASSED_UNSEND_NOT_PUT)
.state(NewProductShowEnum.OTHER_UNPASS_FOR_SPU_STUDYER)
.state(NewProductShowEnum.FINSH_SPU)
.state(NewProductShowEnum.GONDOR_INVALID)
.states(EnumSet.allOf(NewProductShowEnum.class));
}
@Override
public void configure(StateMachineTransitionConfigurer<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum> transitions) throws Exception {
transitions.withExternal()
//提交新的新品申请
.source(NewProductShowEnum.STM_INITIAL)
.target(NewProductShowEnum.CHECKING)
.event(NewSpuApplyStateMachineEventsEnum.NEW_APPLY)
.guard(nspNewApplyGuard)
.action(nspNewApplyAction)
//选品不通过
.and().withExternal()
.source(NewProductShowEnum.CHECKING)
.target(NewProductShowEnum.UNPUT_ON_SALE_UNPASS)
.event(NewSpuApplyStateMachineEventsEnum.OM_PICK_REJECT)
.guard(nspOmRejectGuard)
.action(nspOmRejectAction)
//选品通过
.and().withExternal()
.source(NewProductShowEnum.CHECKING)
.target(NewProductShowEnum.UNPUT_ON_SALE_PASSED_UNSEND)
.event(NewSpuApplyStateMachineEventsEnum.OM_PICK_PASS)
.guard(nspOmPassGuard)
.action(nspOmPassAction)
//发起商研审核
.and().withExternal()
.source(NewProductShowEnum.UNPUT_ON_SALE_PASSED_UNSEND)
.target(NewProductShowEnum.STM_UNPUT_ON_SALE_PASSED_UNSEND)
.event(NewSpuApplyStateMachineEventsEnum.START_BR_AUDIT)
.and().withChoice()
.source(NewProductShowEnum.STM_UNPUT_ON_SALE_PASSED_UNSEND)
.first(NewProductShowEnum.UNPUT_ON_SALE_PASSED, nspStartBrAuditWaitAuditStatusDecide, nspStartBrAuditWaitAuditChoiceAction)
.then(NewProductShowEnum.UNPUT_ON_SALE_PASSED_UNSEND_NOT_PUT, nspStartBrAuditRejctStatusDecide, nspStartBrAuditRejctChoiceAction)
.last(NewProductShowEnum.FINSH_SPU, nspStartBrAuditFinishChoiceAction)
//商研审核-支持鉴别
.and().withExternal()
.source(NewProductShowEnum.UNPUT_ON_SALE_PASSED)
.target(NewProductShowEnum.FINSH_SPU)
.event(NewSpuApplyStateMachineEventsEnum.BR_HUMAN_AUDIT_SUPPORT_ALL)
.guard(nspBrAuditSupportAllGuard)
.action(nspBrAuditSupportAllAction)
//商研审核-商品信息有误
.and().withExternal()
.source(NewProductShowEnum.UNPUT_ON_SALE_PASSED)
.target(NewProductShowEnum.OTHER_UNPASS_FOR_SPU_STUDYER)
.event(NewSpuApplyStateMachineEventsEnum.BR_HUMAN_AUDIT_WRONG_INFO)
.guard(nspBrAuditWrongInfoGuard)
.action(nspBrAuditWrongInfoAction)
//商研审核-不支持鉴别
.and().withExternal()
.source(NewProductShowEnum.UNPUT_ON_SALE_PASSED)
.target(NewProductShowEnum.UNPUT_ON_SALE_PASSED_UNSEND_NOT_PUT)
.event(NewSpuApplyStateMachineEventsEnum.BR_HUMAN_AUDIT_SUPPORT_NONE)
.guard(nspBrAuditRejectGuard)
.action(nspBrAuditRejectAction)
;
}
}
L'état de la machine à états est entièrement mappé avec le champ d'état dans la table de base de données d'exemple de nouveau produit, et les événements de la machine à états correspondent complètement aux événements de la figure ci-dessus. Dans les nouveaux exemples de produits, certains scénarios nécessitent une série de jugements logiques pour arriver à l'état cible après avoir reçu un événement. Ici, l'état de choix de la machine à états sera utilisé pour terminer le jugement et le transfert de l'état cible. .
Précisons quels éléments liés à la machine à états sont séparés indépendamment et lesquels sont partagés :

On peut voir que seule la classe de configuration de la machine à états est différente pour chaque canal, donc le coût n'est pas élevé. La manière dont les classes d’implémentation de garde et d’action sont partagées par tous les canaux sera expliquée ci-dessous.
Mise en œuvre de la garde et de l'action
Comme le montre la configuration spécifique de la machine à états ci-dessus, deux types de flux d'état sont impliqués dans le processus d'échantillonnage de nouveaux produits :
-
Le statut cible après le déclenchement de l'événement est fixe. Par exemple, si l'événement d'échec de sélection de produit est déclenché pendant la révision de la sélection de produit, le statut cible de la nouvelle demande de produit sera déterminé comme étant un échec de sélection de produit ;
-
L'état cible après le déclenchement de l'événement doit être jugé par la logique du code. Pour cette raison, l'état de choix est introduit dans la configuration de la machine d'état. Par exemple, en cas de lancement d'une étude de recherche commerciale, l'état cible d'un nouveau produit. l'application peut être que l'identification n'est pas prise en charge directement, ou que l'application du nouveau produit peut être directement transmise, elle peut également nécessiter un examen manuel.
Dans la conception de la machine à états Spring, les responsabilités de ces deux types de flux d'état, gurad et action seront différentes :
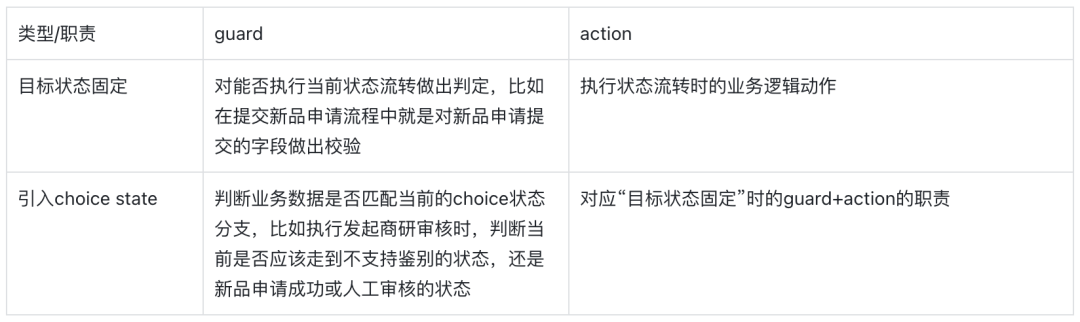
La logique de mise en œuvre de ces deux types de garde et d’action sera donc différente.
Cependant, pour la garde et l'action sous le même état d'événement/choix, différents canaux source de produit peuvent être partagés, car la répartition du code métier en fonction du canal source de produit a été implémentée et doit uniquement être acheminée vers le NspOperate spécifique dans le La classe d'implémentation métier est suffisante. Des exemples sont donnés ci-dessous :
Garde avec état cible fixe :
@Component
public class NspNewApplyGuard extends AbstractGuard<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum, NewSpuApplySendEventContext> {
@Resource
private NewSpuApplyOperateHelper newSpuApplyOperateHelper;
@Override
protected boolean process(StateContext<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum> context) {
final CatetorySendEventContextRequest<NewSpuApplyContext> request = getSendEventContext(context).getRequest();
NewSpuApplyContext ctx = request.getParams();
Integer applyType = ctx.getApplyType(); //从业务数据中取出商品来源
NspOperate<NewSpuApplyContext> nspOperate = newSpuApplyOperateHelper.getNspOperate(applyType, NewSpuApplyStateMachineEventsEnum.NEW_APPLY.getCode()); //固定的事件code
//做请求的预处理
nspOperate.preProcessRequest(ctx);
//对业务数据做校验,校验不通过即抛出异常
nspOperate.verify(ctx);
//正常执行完上述2个方法,代表是可以执行的
return Boolean.TRUE;
}
}
En garde, il vous suffit d'obtenir la classe d'implémentation de NspOperate basée sur la source du produit et le code d'événement fixe, et d'appeler les méthodes preProcessRequest et verify de NspOperate pour terminer la vérification.
Action avec état cible fixe :
@Component
public class NspNewApplyAction extends AbstractSuccessAction<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum, CategorySendEventContext> {
@Resource
private NewSpuApplyOperateHelper newSpuApplyOperateHelper;
@Override
protected void process(StateContext<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum> context) {
final CatetorySendEventContextRequest<NewSpuApplyContext> request = getSendEventContext(context).getRequest();
NewSpuApplyContext ctx = request.getParams();
Integer applyType = ctx.getApplyType(); //从业务数据中取出商品来源
NspOperate<NewSpuApplyContext> nspOperate = newSpuApplyOperateHelper.getNspOperate(applyType, NewSpuApplyStateMachineEventsEnum.NEW_APPLY.getCode()); //固定的事件code
//执行业务逻辑
nspOperate.process(ctx);
//持久化
nspOperate.persistent(ctx);
//后处理
nspOperate.post(ctx);
}
}
Dans l'action, la classe d'implémentation de NspOperate est également obtenue sur la base de la source du produit et du code d'événement fixe, et les dernières méthodes de NspOperate sont appelées pour terminer l'opération commerciale.
Garde dans l'état Choix :
Guard doit déterminer l'état de la cible en fonction des canaux et des événements actuels. Ici, une interface distincte est abstraite pour que guard puisse implémenter les appels. Si une logique similaire est nécessaire dans NspOperate, cette interface distincte peut également être référencée, il n'y aura donc pas de code. reproduction:
public interface NspStatusDecider<C, R> {
/**
* 支持的商品来源渠道
* @return
*/
Integer supportApplyType();
/**
* 支持的操作类型
* @return
*/
String operateCode();
/**
* 判定目标状态
* @param context
*/
R decideStatus(C context);
}
@Component
public class NspBrAuditNoIdentifyGuard extends AbstractGuard<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum, NewSpuApplySendEventContext> {
@Resource
private NewSpuApplyOperateHelper newSpuApplyOperateHelper;
@Override
protected boolean process(StateContext<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum> context) {
final CatetorySendEventContextRequest<NewSpuApplyContext> request = getSendEventContext(context).getRequest();
NewSpuApplyContext ctx = request.getParams();
Integer applyType = ctx.getApplyType(); //从业务数据中取出商品来源
NspStatusDecider<NewSpuApplyContext, Result> nspStatusDecider = newSpuApplyOperateHelper.getNspStatusDecider(applyType, NewSpuApplyStateMachineEventsEnum.BR_HUMAN_AUDIT_SUPPORT_NONE.getCode()); //固定的事件code
//判定目标状态
Result result = nspStatusDecider.decideStatus(ctx);
ctx.setResult(result); //将判定结果放入上下文,其他的guard可以引用结果,避免重复判断
return Result.isSuccess(result); //根据判定结果决定是否匹配当前guard对应的目标状态
}
}
Action dans l'état Choix :
@Component
public class NspBrAuditNoIdentifyAction extends AbstractSuccessAction<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum, CategorySendEventContext> {
@Resource
private NewSpuApplyOperateHelper newSpuApplyOperateHelper;
@Override
protected void process(StateContext<NewProductShowEnum, NewSpuApplyStateMachineEventsEnum> context) {
final CatetorySendEventContextRequest<NewSpuApplyContext> request = getSendEventContext(context).getRequest();
NewSpuApplyContext ctx = request.getParams();
Integer applyType = ctx.getApplyType(); //从业务数据中取出商品来源
NspOperate<NewSpuApplyContext> nspOperate = newSpuApplyOperateHelper.getNspOperate(applyType, NewSpuApplyStateMachineEventsEnum.BR_HUMAN_AUDIT_SUPPORT_NONE.getCode()); //固定的事件code
//做请求的预处理
nspOperate.preProcessRequest(ctx);
//对业务数据做校验
nspOperate.verify(ctx);
//执行业务逻辑
nspOperate.process(ctx);
//持久化
nspOperate.persistent(ctx);
//后处理
nspOperate.post(ctx);
}
}
La seule différence avec l'action avec un état cible fixe est que les méthodes preProcessRequest et verify de NspOperate sont exécutées.
Au lieu d'utiliser différentes implémentations de garde et d'action entre différents canaux, utilisez des classes de stratégie distinctes pour diviser les différentes implémentations de canal pour les deux considérations suivantes :
-
Il est possible de remplacer l'implémentation de la machine à états, de sorte que le code lié à l'implémentation de la machine à états ne devrait pas être couplé au code de logique métier ;
-
Dans les scénarios qui n'impliquent pas de machines à états, il est également nécessaire de diviser la logique par canal, comme l'édition d'une nouvelle application de produit, etc.
Lien avec le flux d'état du SPU pendant le processus de lancement du produit
Lorsque le nouvel échantillon de produit entre dans le statut « Informations sur le produit en attente d'examen », le processus de la machine d'état SPU prendra en charge le flux de statut SPU suivant. Lorsque le statut SPU atteint « Audit réussi », le statut du nouvel échantillon de produit sera transmis à la recherche commerciale. et l'étape de révision. Pendant cette période, chaque changement d'information et de statut du SPU doit être notifié des échantillons entrants de nouveaux produits (via MQ ou un événement dans l'application), puis le traitement commercial correspondant est effectué sur les enregistrements d'échantillons entrants de nouveaux produits.
Analyse étendue ultérieure
Pour les changements futurs qui pourraient être impliqués dans le processus d’application d’un nouveau produit, évaluez l’évolutivité de cette transformation.
Ajouter de nouveaux canaux de sources de produits
Configurez simplement une nouvelle machine à états pour mettre en œuvre diverses opérations et événements commerciaux pour le nouveau canal sans affecter les canaux existants.
Ajout d'un nœud d'état pour les nouveaux échantillons de produits
Modifiez simplement la configuration de la machine à états et ajoutez de nouveaux événements et les classes d'implémentation correspondantes.
Ajuster l'ordre entre les états pour les échantillons entrants de nouveaux produits
Modifiez la configuration de la machine d'état et évaluez la modification des classes d'implémentation des opérations commerciales impliquées. La portée de la modification est claire et contrôlable.
10. Résumé
Nous utilisons le modèle stratégique pour découpler la logique métier des différents canaux de source de produits, conserver les points communs et mettre en œuvre leur propre logique différenciée pour fournir une évolutivité pour les changements futurs des exigences commerciales grâce à l'introduction de machines à états, nous clarifions et standardisons le statut du ; nouveau processus de produit. Flow garantit que le statut est transféré correctement et légalement, tout en établissant une base solide pour les futurs changements de processus commerciaux.
D'une part, cette transformation résout les problèmes persistants de la mise en œuvre actuelle et réduit la difficulté de démarrer avec le code existant. D'autre part, elle prend également en compte l'efficacité du développement à l'avenir, qu'il s'agisse de l'ajout de nouvelles sources. canaux ou en modifiant les processus métier, la portée des modifications du code peut être garantie. Elle est contrôlable et mesurable sans ajouter de charge de travail supplémentaire, et peut soutenir l'entreprise de manière plus efficace, sûre et stable.
* Texte/Orange douce
Cet article est original de Dewu Technology. Pour des articles plus intéressants, veuillez consulter : Site officiel de Dewu Technology.
La réimpression sans l'autorisation de Dewu Technology est strictement interdite, sinon la responsabilité légale sera engagée conformément à la loi !
Les lycéens créent leur propre langage de programmation open source en guise de cérémonie de passage à l'âge adulte - commentaires acerbes des internautes : S'appuyant sur la défense, Apple a publié la puce M4 RustDesk. Les services nationaux ont été suspendus en raison d'une fraude généralisée. À l'avenir, il envisage de produire un jeu indépendant sur la plateforme Windows Taobao (taobao.com) Redémarrer le travail d'optimisation de la version Web, destination des programmeurs, Visual Studio Code 1.89 publie Java 17, la version Java LTS la plus couramment utilisée, Windows 10 a un part de marché de 70 %, Windows 11 continue de décliner Open Source Daily | Google soutient Hongmeng pour prendre le relais ; l'anxiété et les ambitions de Microsoft ont fermé la plate-forme ouverte ;