
Avec les progrès rapides de la technologie de l’intelligence artificielle, OpenAI est devenu l’un des leaders dans le domaine. Il fonctionne bien sur une variété de tâches de traitement linguistique, notamment la traduction automatique, la classification de texte et la génération de texte. Avec l'essor d'OpenAI, de nombreux autres modèles de langages open source de haute qualité ont vu le jour, tels que Llama, ChatGLM, Qwen, etc. Ces excellents modèles open source peuvent également aider les équipes à créer rapidement une excellente application LLM.
Mais face à tant de choix, comment utiliser les interfaces OpenAI de manière uniforme tout en réduisant les coûts de développement ? Comment surveiller efficacement et en continu les performances d'exécution des applications LLM sans ajouter de complexité de développement supplémentaire ? GreptimeAI et Xinference apportent des solutions pratiques à ces problèmes.
Qu'est-ce que GreptimeAI
GreptimeAI est construit sur la base de données de séries chronologiques open source GreptimeDB. Il s'agit d'un ensemble de solutions d'observabilité pour les applications de grands modèles de langage (LLM). Il prend actuellement en charge les écosystèmes LangChain et OpenAI. GreptimeAI vous permet d'acquérir une compréhension complète des coûts, des performances, du trafic et de la sécurité en temps réel, aidant ainsi les équipes à améliorer la fiabilité des applications LLM.
Qu'est-ce que la Xinférence ?
Xinference est une plateforme d'inférence de modèles open source conçue pour les grands modèles de langage (LLM), les modèles de reconnaissance vocale et les modèles multimodaux, et prend en charge le déploiement privatisé. Xinference fournit une API RESTful compatible avec l'API OpenAI et intègre des outils de développement tiers tels que LangChain, LlamaIndex et Dify.AI pour faciliter l'intégration et le développement de modèles. Xinference intègre plusieurs moteurs d'inférence LLM (tels que Transformers, vLLM et GGML), convient à différents environnements matériels et prend en charge le déploiement multi-machine distribué. Il peut répartir efficacement les tâches d'inférence de modèle entre plusieurs appareils ou machines pour répondre aux besoins de plusieurs machines. modèle et calcul à grande vitesse disponibles.
GreptimeAI + Xinference déployer/surveiller les applications LLM
Ensuite, nous prendrons le modèle Qwen-14B comme exemple pour présenter en détail comment utiliser Xinference pour déployer et exécuter le modèle localement. Un exemple sera présenté ici, qui utilise une méthode similaire à l'appel de fonction OpenAI (Function Calling) pour effectuer des requêtes météorologiques, et montre comment utiliser GreptimeAI pour surveiller l'utilisation des applications LLM.
Inscrivez-vous et obtenez les informations de configuration de GreptimeAI
Visitez https://console.greptime.cloud pour enregistrer le service et créer le service AI. Après avoir accédé au tableau de bord AI, cliquez sur la page de configuration pour obtenir les informations de configuration OpenAI.
Démarrez le service de modèle Xinference
Il est très simple de démarrer le service de modèle Xinference localement. Il vous suffit de saisir la commande suivante :
xinference-local -H 0.0.0.0
Xinference démarrera le service localement par défaut et le port par défaut est 9997. Le processus d'installation locale de Xinference est omis ici. Vous pouvez vous référer à cet article pour l'installation.
Démarrage du modèle via l'interface utilisateur Web
Une fois Xinference démarré, saisissez http://localhost:9997 dans le navigateur pour accéder à l'interface utilisateur Web.

Démarrez le modèle à partir de la ligne de commande
Nous pouvons également utiliser l'outil de ligne de commande de Xinference pour démarrer le modèle. L'UID du modèle par défaut est qwen-chat (le modèle sera accessible via cet ID ultérieurement).
xinference launch -n qwen-chat -s 14 -f pytorch
Obtenez des informations météorologiques via l'interface de style OpenAI
Supposons que nous ayons la possibilité get_current_weatherd'obtenir des informations météorologiques pour une ville spécifiée en appelant la fonction, avec les paramètres locationet format.
Configurer OpenAI et l'interface d'appel
Accédez au port local Xinference via le SDK Python d'OpenAI, utilisez GreptimeAI pour collecter des données, utilisez chat.completionsl'interface pour créer une conversation et utilisez-la pour toolsspécifier la liste de fonctions que nous venons de définir.
from greptimeai import openai_patcher
from openai improt OpenAI
client = OpenAI(
base_url="http://127.0.0.1:9997/v1",
)
openai_patcher.setup(client=client)
messages = [
{"role": "system", "content": "你是一个有用的助手。不要对要函数调用的值做出假设。"},
{"role": "user", "content": "上海现在的天气怎么样?"}
]
chat_completion = client.chat.completions.create(
model="qwen-chat",
messages=messages,
tools=tools,
temperature=0.7
)
print('func_name', chat_completion.choices[0].message.tool_calls[0].function.name)
print('func_args', chat_completion.choices[0].message.tool_calls[0].function.arguments)
détails des outils
Appel de fonction La liste des fonctions (outils) est définie ci-dessous, avec les champs obligatoires spécifiés.
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "获取当前天气",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市,例如北京",
},
"format": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "使用的温度单位。从所在的城市进行推断。",
},
},
"required": ["location", "format"],
},
},
}
]
Le résultat est le suivant, vous pouvez voir que nous chat_completionavons obtenu l'appel de fonction généré par le modèle Qwen via :
func_name: get_current_weather
func_args: {"location": "上海", "format": "celsius"}
Obtenez le résultat de l'appel de fonction et appelez à nouveau l'interface
On suppose ici que nous avons appelé la fonction avec les paramètres donnés get_current_weatheret obtenu le résultat, et renvoyé le résultat et le contexte au modèle Qwen :
messages.append(chat_completion.choices[0].message.model_dump())
messages.append({
"role": "tool",
"tool_call_id": messages[-1]["tool_calls"][0]["id"],
"name": messages[-1]["tool_calls"][0]["function"]["name"],
"content": str({"temperature": "10", "temperature_unit": "celsius"})
})
chat_completion = client.chat.completions.create(
model="qwen-chat",
messages=messages,
tools=tools,
temperature=0.7
)
print(chat_completion.choices[0].message.content)
Résultats finaux
Le modèle Qwen finira par générer une réponse comme celle-ci :
上海现在的温度是 10 摄氏度。
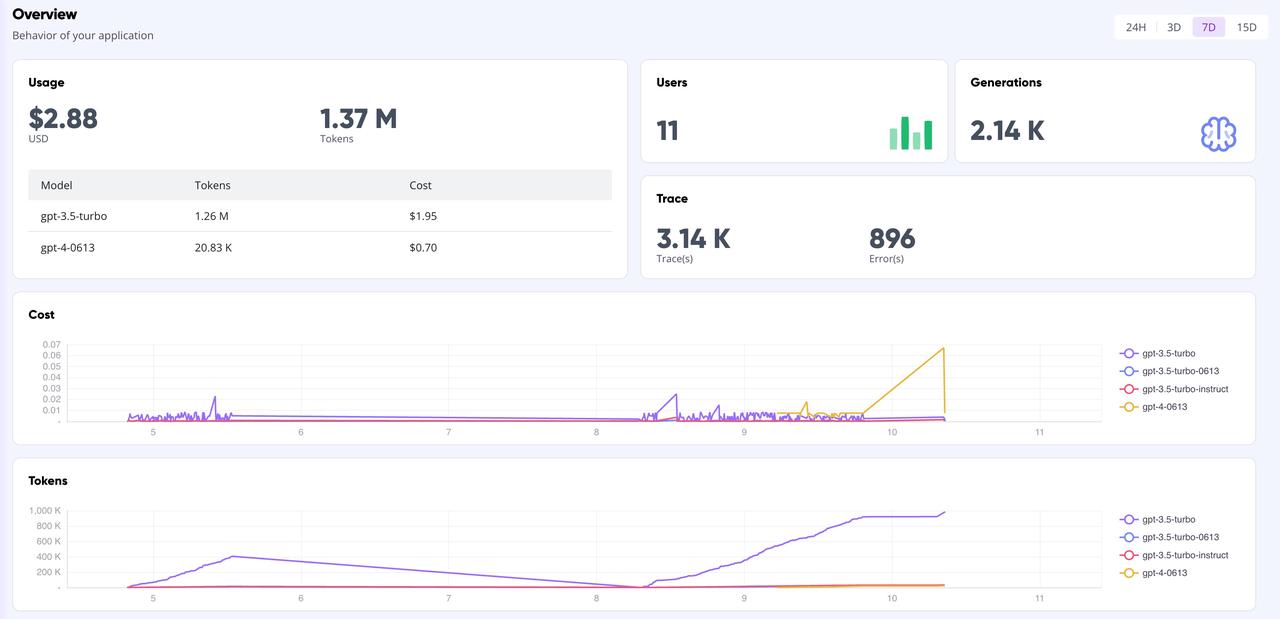
Panneau d'affichage GreptimeAI
Sur la page GreptimeAI Dashboard, vous pouvez surveiller de manière complète et en temps réel toutes les données d'appel basées sur l'interface OpenAI, y compris des indicateurs clés tels que le jeton, le coût, la latence, la trace, etc. Vous trouverez ci-dessous la page de présentation du tableau de bord.
Résumer
Si vous utilisez des modèles open source pour créer des applications LLM et que vous souhaitez utiliser le style OpenAI pour effectuer des appels d'API, alors utiliser Xinference pour gérer le modèle d'inférence et utiliser GreptimeAI pour surveiller le fonctionnement du modèle est un bon choix. Que vous effectuiez des analyses de données complexes ou de simples requêtes quotidiennes, Xinference peut fournir des fonctionnalités de gestion de modèles puissantes et flexibles. Dans le même temps, combiné à la fonction de surveillance de GreptimeAI, vous pouvez comprendre et optimiser plus efficacement les performances et la consommation de ressources du modèle.
Nous attendons avec impatience vos tentatives et apprécions le partage d'expériences et d'idées utilisant GreptimeAI et Xinference. Explorons ensemble les possibilités infinies de l’intelligence artificielle !
Peu de connaissances sur Greptime :
Greptime Greptime Technology a été fondée en 2022 et améliore et développe actuellement trois produits : la base de données de séries chronologiques GreptimeDB, GreptimeCloud et l'outil d'observabilité GreptimeAI.
GreptimeDB est une base de données de séries chronologiques écrite en langage Rust. Elle est distribuée, open source, native du cloud et hautement compatible. Elle aide les entreprises à lire, écrire, traiter et analyser des données de séries chronologiques en temps réel tout en réduisant les coûts de stockage à long terme. fournir aux utilisateurs un service DBaaS entièrement géré qui peut être hautement intégré à l'observabilité, à l'Internet des objets et à d'autres domaines ; GreptimeAI est conçu sur mesure pour LLM, offrant une surveillance complète des coûts, des performances et des processus de génération.
GreptimeCloud et GreptimeAI ont été officiellement testés. Bienvenue pour suivre le compte officiel ou le site officiel pour les derniers développements !

Site officiel : https://greptime.cn/
GitHub : https://github.com/GreptimeTeam/greptimedb
Documentation : https://docs.greptime.cn/
Twitter : https://twitter.com/Greptime
Slack : https://greptime.com/slack
LinkedIn : https://www.linkedin.com/company/greptime/
Un programmeur né dans les années 1990 a développé un logiciel de portage vidéo et en a réalisé plus de 7 millions en moins d'un an. La fin a été très éprouvante ! Des lycéens créent leur propre langage de programmation open source en guise de cérémonie de passage à l'âge adulte - commentaires acerbes des internautes : s'appuyant sur RustDesk en raison d'une fraude généralisée, le service domestique Taobao (taobao.com) a suspendu ses services domestiques et repris le travail d'optimisation de la version Web Java 17 est la version Java LTS la plus utilisée Part de marché de Windows 10 Atteignant 70 %, Windows 11 continue de décliner Open Source Daily | Google soutient Hongmeng pour prendre le relais des téléphones Android open source pris en charge par Docker ; Electric ferme la plate-forme ouverte Apple lance la puce M4 Google supprime le noyau universel Android (ACK) Prise en charge de l'architecture RISC-V Yunfeng a démissionné d'Alibaba et prévoit de produire des jeux indépendants pour les plates-formes Windows à l'avenir