
Auteur|Invisible (Xing Ying), ingénieur principal du noyau de base de données chez NetEase
Édition et finition|Équipe technique SelectDB
Introduction : En tant que secteurs d'activité importants de NetEase, Lingxi Office et Yunxin ont respectivement construit la plate-forme de surveillance Lingxi Eagle et la plate-forme de données Yunxin pour relever les défis du traitement et de l'analyse des données de journaux/séries chronologiques à grande échelle. Cet article se concentrera sur l'application d' Apache Doris dans les journaux NetEase et les scénarios de séries chronologiques, et sur la façon d'utiliser Apache Doris pour remplacer Elasticsearch et InfluxDB, obtenant ainsi des ressources de serveur inférieures et une expérience de performances de requête plus élevée. Par rapport à Elasticsearch, la vitesse de requête d'Apache Doris est. au moins Amélioré de 11 fois, économisant les ressources de stockage jusqu'à 70 %.
Avec le développement rapide des technologies de l’information, la quantité de données d’entreprise a explosé. Pour une grande entreprise Internet comme NetEase, une grande quantité de journaux et de données de séries chronologiques est générée chaque jour, qu'il s'agisse de systèmes de bureau internes ou de services fournis en externe. Ces données sont devenues une pierre angulaire importante pour le dépannage, le diagnostic des problèmes, la surveillance de la sécurité, l'alerte sur les risques, l'analyse du comportement des utilisateurs et l'optimisation de l'expérience. Exploiter pleinement la valeur de ces données contribuera à améliorer la fiabilité, les performances, la sécurité et la satisfaction des utilisateurs des produits.
En tant que secteurs d'activité importants de NetEase, Lingxi Office et Yunxin ont respectivement construit la plate-forme de surveillance Lingxi Eagle et la plate-forme de données Yunxin pour faire face aux défis posés par le traitement et l'analyse des données de journaux/séries chronologiques à grande échelle. À mesure que l'entreprise continue de se développer, les données de journaux/séries chronologiques ont également augmenté de façon exponentielle, ce qui a entraîné des problèmes tels qu'une augmentation des coûts de stockage, des temps de requête prolongés et une détérioration de la stabilité du système. La première plate-forme n'était pas viable, ce qui a incité NetEase à rechercher de meilleures solutions.
Cet article se concentrera sur la mise en œuvre d'Apache Doris dans les scénarios de journaux et de séries chronologiques NetEase, présentera la pratique de mise à niveau de l'architecture d'Apache Doris dans NetEase Lingxi Office et NetEase Cloud Letter, et partagera l'expérience de la création, de l'importation, de la requête, etc. basé sur des scénarios réels.
Architecture précoce et points faibles
01 Plateforme de surveillance Lingxi-Eagle
NetEase Lingxi Office est une nouvelle génération de plateforme bureautique collaborative de messagerie. Intégrez des modules tels que la messagerie électronique, le calendrier, les documents cloud, la messagerie instantanée et la gestion client. La plate-forme de surveillance Eagle est un système APM à liaison complète qui peut fournir une analyse des performances multidimensionnelle et à différentes granularités pour NetEase Lingxi Office.
La plate-forme de surveillance Eagle stocke et analyse principalement les données des journaux d'entreprise telles que Lingxi Office, Enterprise Email, Youdao Cloud Notes et Lingxi Documents. Les données des journaux sont d'abord collectées et traitées via Logstash, puis stockées dans Elasticsearch, qui effectue un journal en temps réel. Il fournit également des services de recherche de journaux et de requête de journaux par lien complet pour Lingxi Office.

Au fur et à mesure que le temps passe et que les données de log augmentent, certains problèmes apparaissent progressivement lors du processus d'utilisation d'Elasticsearch :
- Latence de requête élevée : dans les requêtes quotidiennes, la latence de réponse moyenne d'Elasticsearch est élevée, ce qui affecte l'expérience utilisateur. Ceci est principalement limité par des facteurs tels que la taille des données, la rationalité de la conception de l'index et les ressources matérielles.
- Coûts de stockage élevés : dans un contexte de réduction des coûts et d’amélioration de l’efficacité, les entreprises ont un besoin de plus en plus urgent de réduire leurs coûts de stockage. Cependant, étant donné qu'Elasticsearch dispose de plusieurs magasins de données tels que le stockage en ligne directe, en ligne inversée et en colonne, le degré de redondance des données est élevé, ce qui pose certains défis en matière de réduction des coûts et d'amélioration de l'efficacité.
02 Plateforme de données Yunxin
NetEase Yunxin est un expert en communications convergées et en services PaaS cloud natifs, construit sur les 26 années d'expérience de NetEase. Il fournit des communications convergées et des produits et solutions de base cloud natifs, notamment la messagerie instantanée de messagerie instantanée, le cloud vidéo, les SMS, les microservices de Qingzhou et le middleware PaaS. . attendez.
La plateforme de données Yunxin analyse principalement les données de séries chronologiques générées par la messagerie instantanée, le RTC, les SMS et d'autres services. La première architecture de données était principalement construite sur la base de données de séries chronologiques InfluxDB. La source de données était d'abord signalée via la file d'attente de messages Kafka, après analyse et nettoyage des champs, elle était stockée dans la base de données de séries chronologiques InfluxDB pour fournir des requêtes en ligne et hors ligne. Le côté hors ligne prend en charge l'analyse des données T+1 hors ligne, et le côté en temps réel doit fournir la génération en temps réel de rapports et de factures de surveillance des indicateurs.
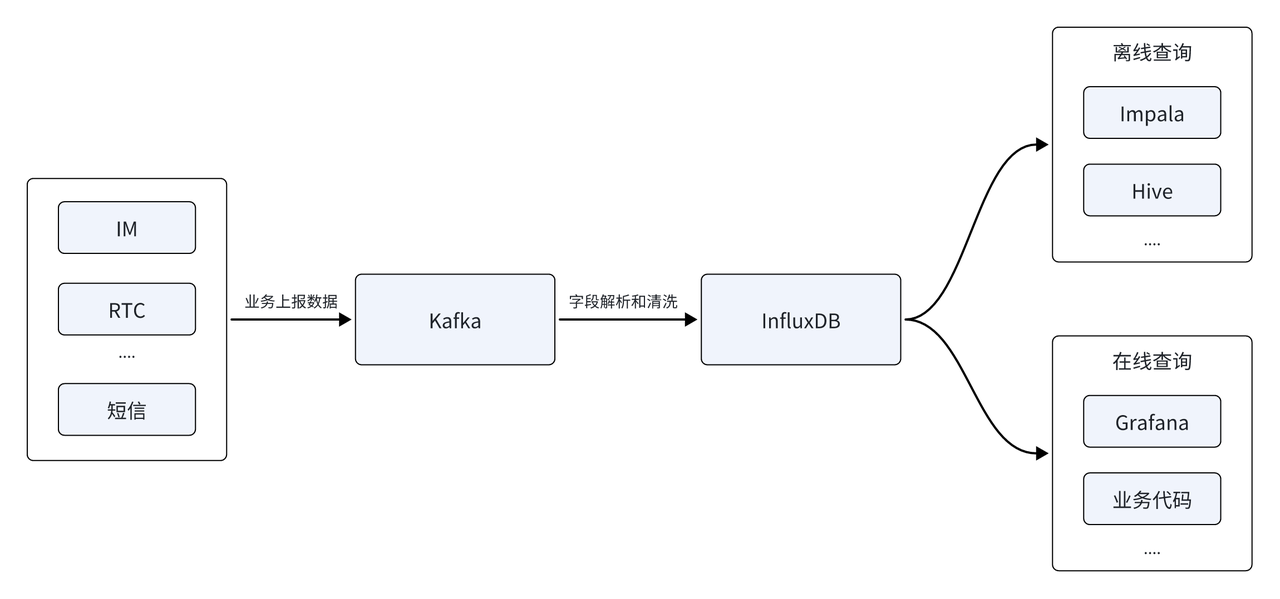
Avec la couverture rapide de l'échelle des clients, le nombre de sources de données signalées continue d'augmenter et InfluxDB est également confronté à une série de nouveaux défis :
- MOO de dépassement de mémoire : à mesure que le nombre de sources de données augmente, l'analyse hors ligne doit être effectuée sur la base de plusieurs sources de données et la difficulté de l'analyse augmente. Limitée par les capacités de requête d'InfluxDB, l'architecture actuelle peut provoquer un manque de mémoire (MOO) face à des requêtes complexes provenant de plusieurs sources de données, ce qui pose un énorme défi en termes de disponibilité commerciale et de stabilité du système.
- Coûts de stockage élevés : le développement de l'activité a également entraîné une croissance continue du volume de données du cluster, et une grande partie des données du cluster sont des données froides. Les données chaudes et froides sont stockées de la même manière, ce qui entraîne des coûts de stockage élevés. Ceci est incompatible avec la réduction des coûts et accroît les conflits avec les objectifs efficaces de l'entreprise.
Sélection du moteur de base
Pour cette raison, NetEase a commencé à rechercher de nouvelles solutions de bases de données, dans le but de résoudre les défis rencontrés par les deux grandes entreprises ci-dessus dans les scénarios de synchronisation des journaux. Dans le même temps, NetEase espère utiliser une seule base de données pour s'adapter au système commercial et à l'architecture technique des deux principaux scénarios d'application, répondant ainsi aux besoins de mise à niveau d'une extrême facilité d'utilisation et d'un faible investissement. À cet égard, Apache Doris répond à nos exigences de sélection, notamment sur les aspects suivants :
- Optimisation des coûts de stockage : Apache Doris a procédé à de nombreuses optimisations dans la structure de stockage pour réduire le stockage redondant. Il a un taux de compression plus élevé et prend en charge le stockage à chaud et à froid basé sur S3 et NOS (Netease Object Storage), ce qui peut réduire efficacement les coûts de stockage et améliorer l'efficacité du stockage des données.
- Haut débit et hautes performances : Apache Doris prend en charge l'écriture sur disque hautes performances du stockage en colonnes, le compactage séquentiel et l'importation en streaming efficace de Stream Load, et peut prendre en charge des dizaines de Go d'écriture de données par seconde. Cela garantit non seulement l’écriture à grande échelle des données de journal, mais offre également une visibilité des requêtes à faible latence.
- Récupération de journaux en temps réel : Apache Doris prend non seulement en charge la récupération en texte intégral des textes de journaux, mais permet également de répondre aux requêtes en temps réel. Doris prend en charge l'ajout d'un index inversé en interne, qui peut satisfaire la récupération de texte intégral des types de chaînes et la récupération équivalente et par plage des types numériques/dates ordinaires. En même temps, il peut optimiser davantage les performances de requête de l'index inversé et le rendre plus. adapté à l’analyse des données de journal.
- Prise en charge de l'isolation des locataires à grande échelle : Doris peut héberger des milliers de bases de données et des dizaines de milliers de tables de données, et peut permettre à un locataire d'utiliser une base de données de manière indépendante, répondant ainsi aux besoins d'isolation des données multi-tenants et garantissant la confidentialité et la sécurité des données.
De plus, au cours de l'année écoulée, Apache Doris a continué à approfondir le scénario de journalisation et a lancé une série de fonctionnalités de base, telles qu'un index inversé efficace, un type de données Variant flexible, etc., pour fournir un meilleur traitement et une meilleure analyse du journal/temps. données de série. Des solutions efficaces et flexibles . Sur la base des avantages ci-dessus, NetEase a finalement décidé d'introduire Apache Doris comme moteur principal de la nouvelle architecture.
Plateforme unifiée de stockage et d'analyse des journaux basée sur Apache Doris
01 Plateforme de surveillance Lingxi-Eagle

Premièrement, dans la plate-forme de surveillance Lingxi Office-Eagle, NetEase a mis à niveau avec succès Elasticsearch vers Apache Doris, créant ainsi une plate-forme unifiée de stockage et d'analyse des journaux. Cette mise à niveau architecturale améliore non seulement considérablement les performances et la stabilité de la plateforme, mais lui fournit également un service de récupération de journaux puissant et efficace. Les avantages spécifiques se reflètent dans :
- Les ressources de stockage sont économisées de 70 % : grâce au taux de compression élevé du stockage en colonnes Doris et de ZSTD, Elasticsearch nécessite 100 T d'espace de stockage pour stocker les mêmes données de journal, mais seulement 30 T d'espace de stockage sont nécessaires pour les stocker dans Doris, soit une économie de 70 T. % des ressources de stockage . En raison de l'économie significative d'espace de stockage, le SSD peut être utilisé pour stocker des données chaudes au lieu du disque dur au même coût, ce qui apportera également une plus grande amélioration des performances des requêtes.
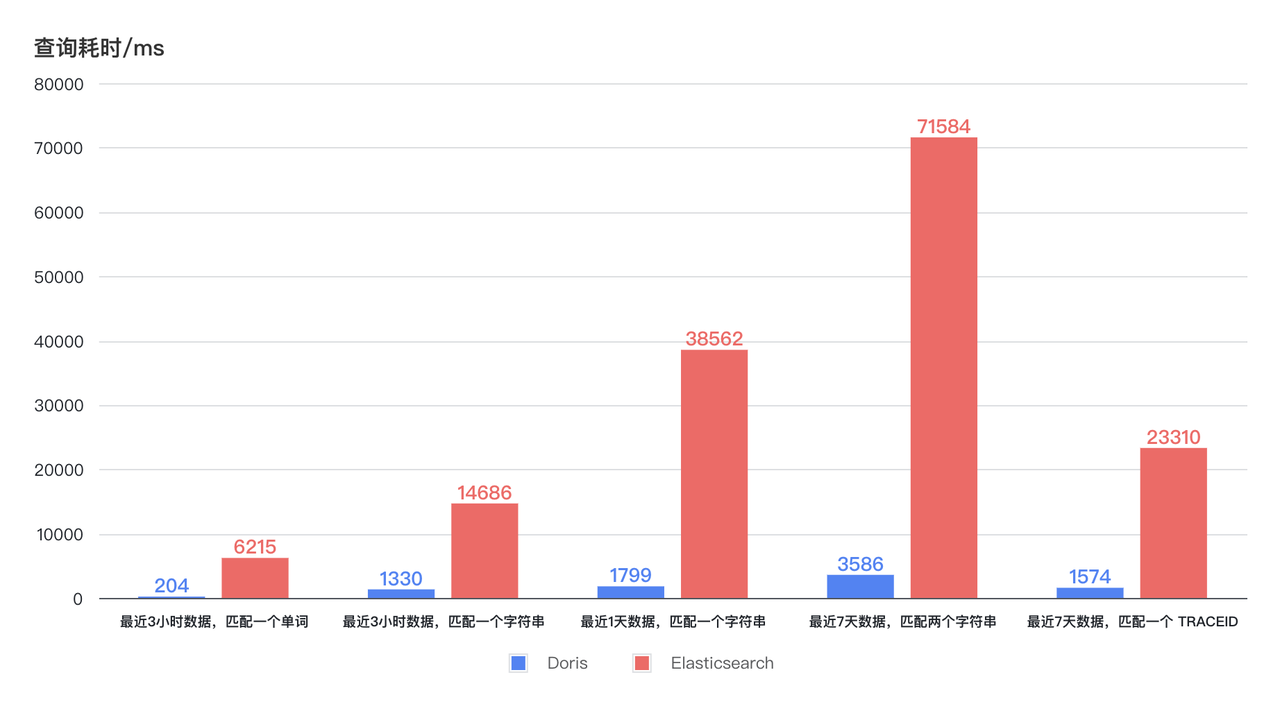
- La vitesse des requêtes est 11 fois supérieure : la nouvelle architecture améliore des dizaines de fois l'efficacité des requêtes avec une consommation de ressources CPU réduite. Comme le montre le diagramme ci-dessous, le temps de requête Doris pour la récupération des journaux au cours des 3 dernières heures, 1 jour et 7 jours reste stable et inférieur à 4 secondes, et la réponse la plus rapide peut être inférieure à 1 seconde. Le temps de requête d'Elasticsearch présente de grandes fluctuations, le temps le plus long prenant jusqu'à 75 secondes, et même le temps le plus court prenant 6 à 7 secondes. Avec une utilisation moindre des ressources, l'efficacité des requêtes de Doris est au moins 11 fois supérieure à celle d'Elasticsearch .
02 Plateforme de données Yunxin
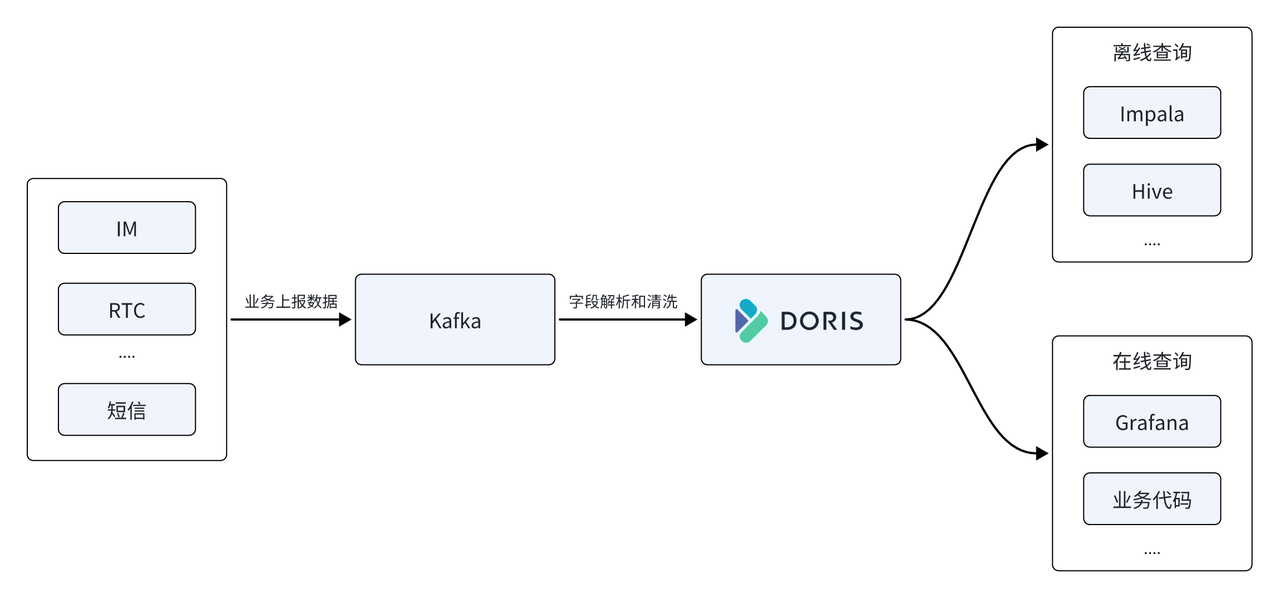
Dans la plate-forme de données Yunxin, NetEase utilise également Apache Doris pour remplacer la base de données de séries chronologiques InfluxDB dans la première architecture, en l'utilisant comme moteur de stockage et de calcul de base de la plate-forme de données, et Apache Doris fournit des services de requête unifiés hors ligne et en temps réel.
- Prend en charge l'écriture à haut débit : trafic d'écriture en ligne moyen de 500 M/s, pic de 1 Go/s, InfluxDB utilise 22 serveurs et l'utilisation des ressources CPU est d'environ 50 %, tandis que Doris n'utilise que 11 machines et l'utilisation du CPU est d'environ 50 % , la consommation globale des ressources n'est que de la moitié de la précédente .
- Ressources de stockage économisées 67 % : 11 machines physiques Doris ont été utilisées pour remplacer 22 InfluxDB. Pour stocker la même échelle de données, InfluxDB nécessite 150 T d'espace de stockage, tandis que son stockage dans Doris ne nécessite que 50 T d'espace de stockage, ce qui permet d'économiser 67 % de ressources de stockage .
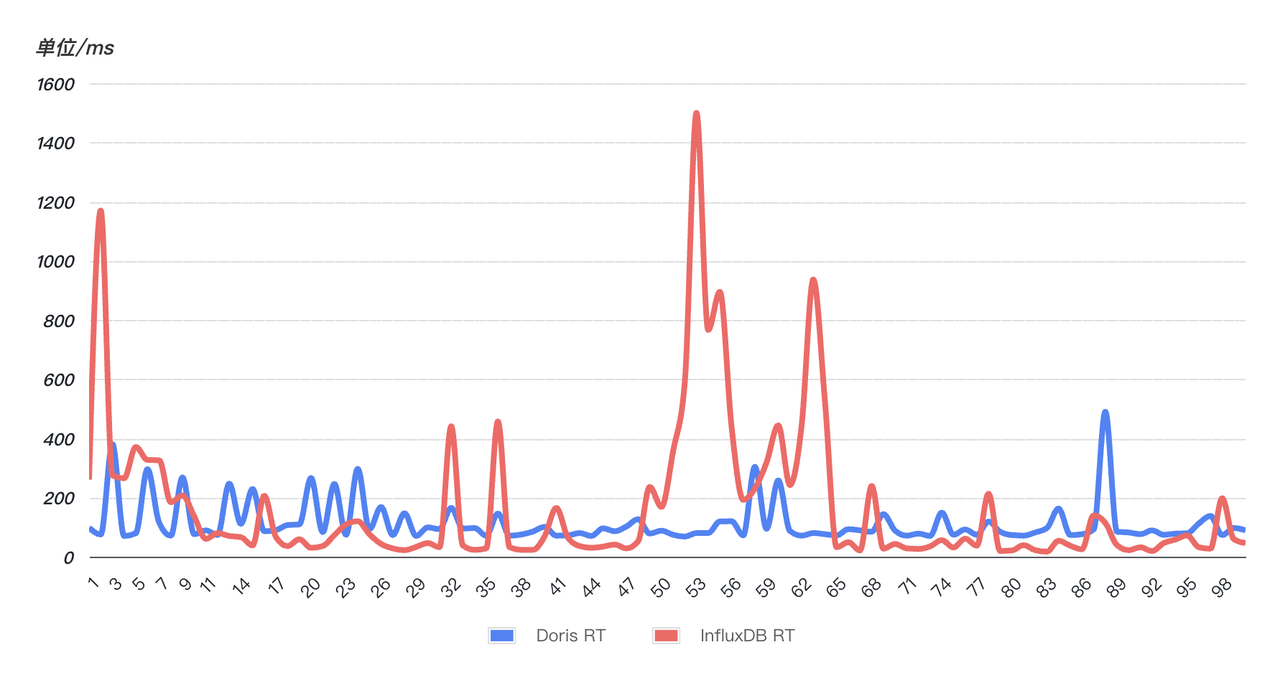
- La réponse aux requêtes est rapide et plus stable : afin de vérifier la vitesse de réponse aux requêtes, un SQL en ligne a été sélectionné au hasard (correspondant à une chaîne au cours des 10 dernières minutes) et le SQL a été interrogé 99 fois en continu. Comme le montre la figure ci-dessous, les performances des requêtes de Doris (bleu) sont plus stables que celles d'InfluxDB (rouge). 99 requêtes sont relativement stables et n'ont pas de fluctuations évidentes . Cependant, InfluxD a connu de multiples fluctuations anormales. le temps de requête a grimpé en flèche et la stabilité des requêtes a été affectée.
Pratique et réglage
Au cours du processus de mise en œuvre commerciale, NetEase a également rencontré certains problèmes et défis. J'aimerais profiter de cette opportunité pour compiler et partager ces précieuses expériences d'optimisation, dans l'espoir de fournir des conseils et une aide pour l'utilisation de chacun.
01 Optimisation de la création de tables
La conception du schéma de base de données est essentielle aux performances, et cela ne fait pas exception lorsqu'il s'agit de données de journaux et de séries chronologiques. Apache Doris fournit des options d'optimisation spécialisées pour ces deux scénarios. Il est donc essentiel d'activer ces options d'optimisation lors de la création de la table. Voici les options d’optimisation spécifiques que nous utilisons dans la pratique :
- Lorsque vous utilisez un champ horaire de type DATETIME comme clé primaire, la vitesse d'interrogation des n derniers journaux sera considérablement améliorée.
- Utilisez le partitionnement RANGE basé sur des champs temporels et permettez à Partiiton dynamique de gérer automatiquement les partitions au quotidien, améliorant ainsi la flexibilité de la requête et de la gestion des données.
- En ce qui concerne la stratégie de regroupement, vous pouvez utiliser RANDOM pour le regroupement aléatoire, et le nombre de compartiments est approximativement fixé à 3 fois le nombre total de disques du cluster.
- Pour les champs fréquemment interrogés, il est recommandé de créer des index pour améliorer l'efficacité des requêtes ; et pour les champs qui nécessitent une récupération de texte intégral, un analyseur de paramètres de segmentation de mots approprié doit être spécifié pour garantir l'exactitude et l'efficacité de la récupération.
- Pour les scénarios de journaux et de séries chronologiques, une stratégie de compactage de séries chronologiques spécialement optimisée est utilisée.
- L'utilisation de la compression ZSTD peut obtenir de meilleurs effets de compression et économiser de l'espace de stockage.
CREATE TABLE log
(
ts DATETIME,
host VARCHAR(20),
msg TEXT,
status INT,
size INT,
INDEX idx_size (size) USING INVERTED,
INDEX idx_status (status) USING INVERTED,
INDEX idx_host (host) USING INVERTED,
INDEX idx_msg (msg) USING INVERTED PROPERTIES("parser" = "unicode")
)
ENGINE = OLAP
DUPLICATE KEY(ts)
PARTITION BY RANGE(ts) ()
DISTRIBUTED BY RANDOM BUCKETS 250
PROPERTIES (
"compression"="zstd",
"compaction_policy" = "time_series",
"dynamic_partition.enable" = "true",
"dynamic_partition.create_history_partition" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-7",
"dynamic_partition.end" = "3",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "250"
);
02 Optimisation de la configuration du cluster
Configuration EF
# 开启单副本导入提升导入性能
enable_single_replica_load = true
# 更加均衡的tablet分配和balance测量
enable_round_robin_create_tablet = true
tablet_rebalancer_type = partition
# 频繁导入相关的内存优化
max_running_txn_num_per_db = 10000
streaming_label_keep_max_second = 300
label_clean_interval_second = 300
Configuration BE
write_buffer_size=1073741824
max_tablet_version_num = 20000
max_cumu_compaction_threads = 10(cpu的一半)
enable_write_index_searcher_cache = false
disable_storage_page_cache = true
enable_single_replica_load = true
streaming_load_json_max_mb=250
03 Réglage de l'importation de Stream Load
Pendant les périodes de pointe, la plate-forme de données Yunxin est confrontée à plus d'un million de TPS en écriture et à un trafic d'écriture de 1 Go/s, ce qui impose sans aucun doute des exigences extrêmement élevées en matière de performances du système. Cependant, comme il existe de nombreuses petites tables simultanées du côté commercial et que le côté requête a des exigences en temps réel extrêmement élevées en matière de données, il est impossible d'accumuler le traitement par lots dans un lot suffisamment grand en peu de temps. Après avoir mené conjointement une série d'optimisations avec des parties commerciales, Stream Load n'est toujours pas en mesure de consommer rapidement les données dans Kafka, ce qui entraîne un retard de données de plus en plus important dans Kafka.
Après une analyse approfondie, il a été constaté que pendant la période de pointe de l'activité, le programme d'importation de données du côté commercial avait souffert de goulots d'étranglement en termes de performances, principalement reflétés dans l'occupation excessive des ressources CPU et mémoire. Cependant, les performances du côté de Doris n'ont pas encore connu de goulot d'étranglement significatif, mais le temps de réponse de Stream Load a une nette tendance à la hausse.
Étant donné que le programme métier appelle Stream Load de manière synchrone, cela signifie que la vitesse de réponse de Stream Load affecte directement l'efficacité globale du traitement des données. Par conséquent, si le temps de réponse d’un seul Stream Load peut être réduit efficacement, le débit de l’ensemble du système sera considérablement amélioré.
Après avoir communiqué avec les étudiants de la communauté Apache Doris, j'ai appris que Doris avait lancé deux optimisations importantes des performances d'importation pour les scénarios de journalisation et de synchronisation :
- Importation d'une seule copie : écrivez d'abord sur une copie, et les autres copies extraient les données de la première copie. Cette méthode peut éviter la surcharge causée par le tri répété et la création d'index de plusieurs copies.
- Importation sur une seule tablette : par rapport à la méthode d'écriture consistant à disperser les données sur plusieurs tablettes en mode normal, une stratégie consistant à écrire uniquement sur une seule tablette à la fois peut être adoptée. Cette optimisation réduit le nombre de petits fichiers et la surcharge d'E/S générée lors de l'écriture, améliorant ainsi l'efficacité globale de l'importation. Cette fonctionnalité peut être activée en définissant
load_to_single_tabletle paramètre sur lors de l'importation .true
Après optimisation à l'aide des méthodes ci-dessus, les performances d'importation ont été considérablement améliorées :
- La vitesse de consommation de Kafka est multipliée par plus de 2
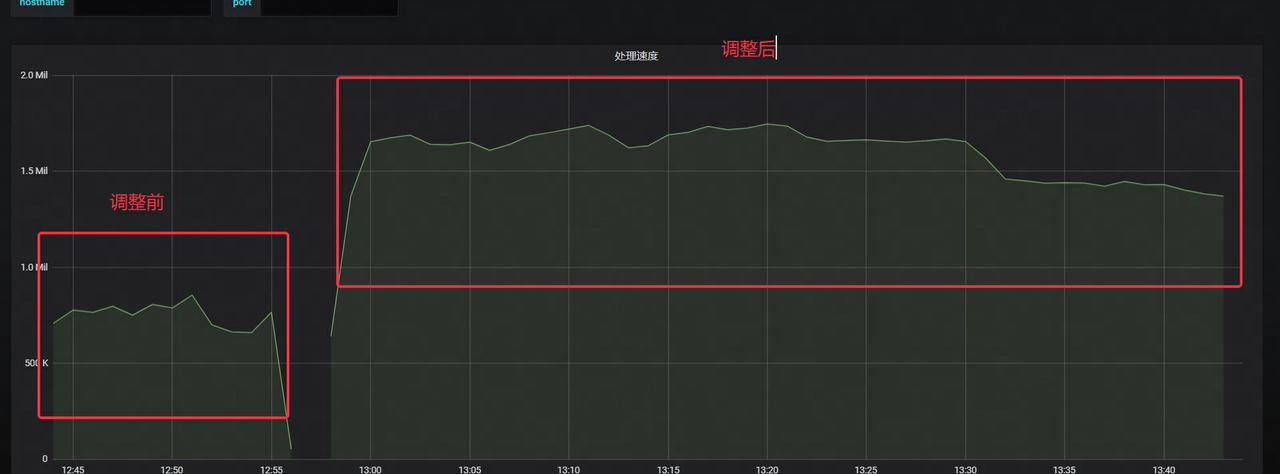
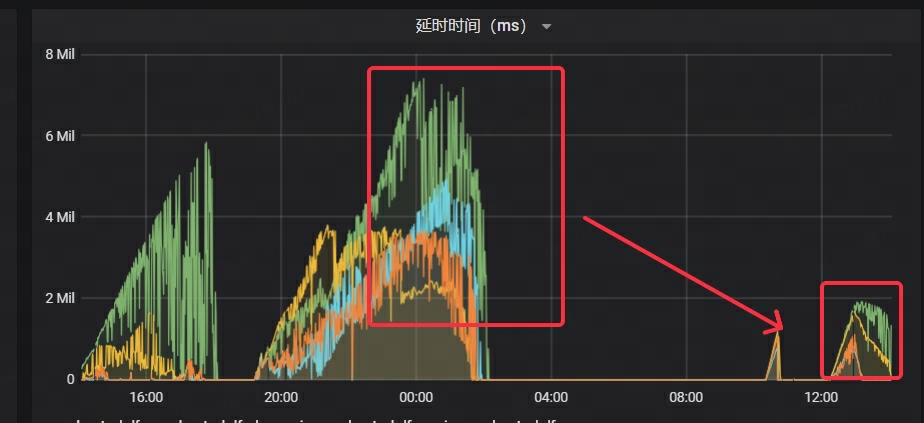
- La latence de Kafka a considérablement diminué, à seulement 1/4 du temps d'origine
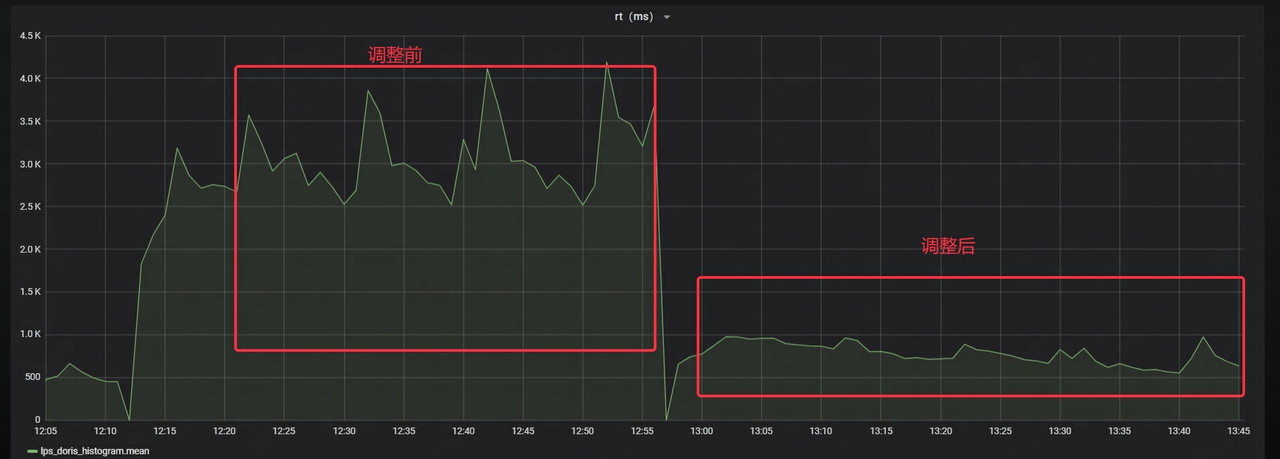
- Le RT de Stream Load est réduit d’environ 70 %
NetEase a également effectué des tests de résistance approfondis et des essais en niveaux de gris avant le lancement officiel. Après un travail d'optimisation continu, il a finalement assuré que le système pouvait fonctionner de manière stable en ligne dans des scénarios à grande échelle, offrant ainsi un soutien solide à l'entreprise.
1. Délai d'expiration du chargement du flux :
Au début du test de résistance, il y avait un problème de délais d'attente fréquents et de rapports d'erreurs lors de l'importation de données, et lorsque le processus et l'état du cluster étaient normaux, la surveillance ne pouvait pas collecter normalement les données métriques de BE.
Obtenez la pile de Doris BE via Pstack et utilisez PT-PMT pour analyser la pile. Il a été constaté que la raison principale était que lorsque le client lançait une requête, ni le codage HTTP Chunked ni la longueur du contenu n'étaient définis, ce qui faisait croire à tort à Doris que la transmission des données n'était pas encore terminée et restait donc en attente. État. Après avoir ajouté le paramètre d’encodage Chunked sur le client, l’importation des données est revenue à la normale.
2. La quantité de données importées en une seule fois par Stream Load dépasse le seuil :
Le problème est résolu en augmentant streaming_load_json_max_mble paramètre à 250M (100M par défaut).
3. Copies insuffisantes et erreur d’écriture : alive replica num 0 < quorum replica num 1
Il show backendss'avère qu'un BE a un statut anormal et est affiché comme HORS LIGNE. Vérifiez le be_customfichier de configuration correspondant et trouvez qu'il existe broken_storage_path. Une inspection plus approfondie du journal de BE a révélé que le message d'erreur indiquait « trop de fichiers ouverts », ce qui signifie que le nombre de descripteurs de fichiers ouverts par le processus BE a dépassé le maximum défini par le système, provoquant l'échec de l'opération d'E/S.
Lorsque le système Doris détecte cette anomalie, il marque le disque comme inutilisable. Étant donné que la table est configurée avec une stratégie de copie unique, lorsqu'il y a un problème avec le disque sur lequel se trouve la seule copie, l'écriture des données ne peut pas continuer car le nombre de copies est insuffisant.
Par conséquent, la limite d'ouverture maximale du processus FD a été ajustée à 1 million, be_custom.confle fichier de configuration a été supprimé, le nœud BE a été redémarré et le service a finalement repris son fonctionnement normal.
4. Gigue de la mémoire FE
Lors du test en niveaux de gris professionnels, le problème est survenu : il ne pouvait pas se connecter à FE. En vérifiant les données de surveillance, il a été constaté que la mémoire JVM 32G était épuisée et que le répertoire de fichiers bdb dans le méta-répertoire FE s'était anormalement étendu à 50G.
Étant donné que l'entreprise a effectué des opérations d'importation de données Stream Load hautement simultanées et que FE enregistrera les informations de chargement pertinentes pendant le processus d'importation, les informations de mémoire générées par chaque importation sont d'environ 200 Ko. Le temps de nettoyage de ces informations de mémoire streaming_label_keep_max_secondest contrôlé par des paramètres. La valeur par défaut est de 12 heures. Après l'avoir ajustée à 5 minutes, la mémoire FE ne sera pas épuisée. Cependant, après une période de fonctionnement, il s'avère que la mémoire est épuisée. instabilité selon le cycle d'une heure et l'utilisation maximale de la mémoire. Le taux atteint 80 %. Après avoir analysé le code, nous avons constaté que le thread qui nettoie les étiquettes label_clean_interval_seconds'exécute une fois sur deux. La valeur par défaut est de 1 heure. Après l'avoir ajustée à 5 minutes, la mémoire FE est très stable.
04 Réglage des requêtes
Lorsque la plateforme de surveillance Lingxi-Eagle effectuait des tests de requêtes, on soupçonnait qu'elle lisait des résultats qui ne remplissaient pas les conditions de correspondance. Ce phénomène ne respectait évidemment pas la logique de récupération attendue. Comme le montre le premier enregistrement ci-dessous :
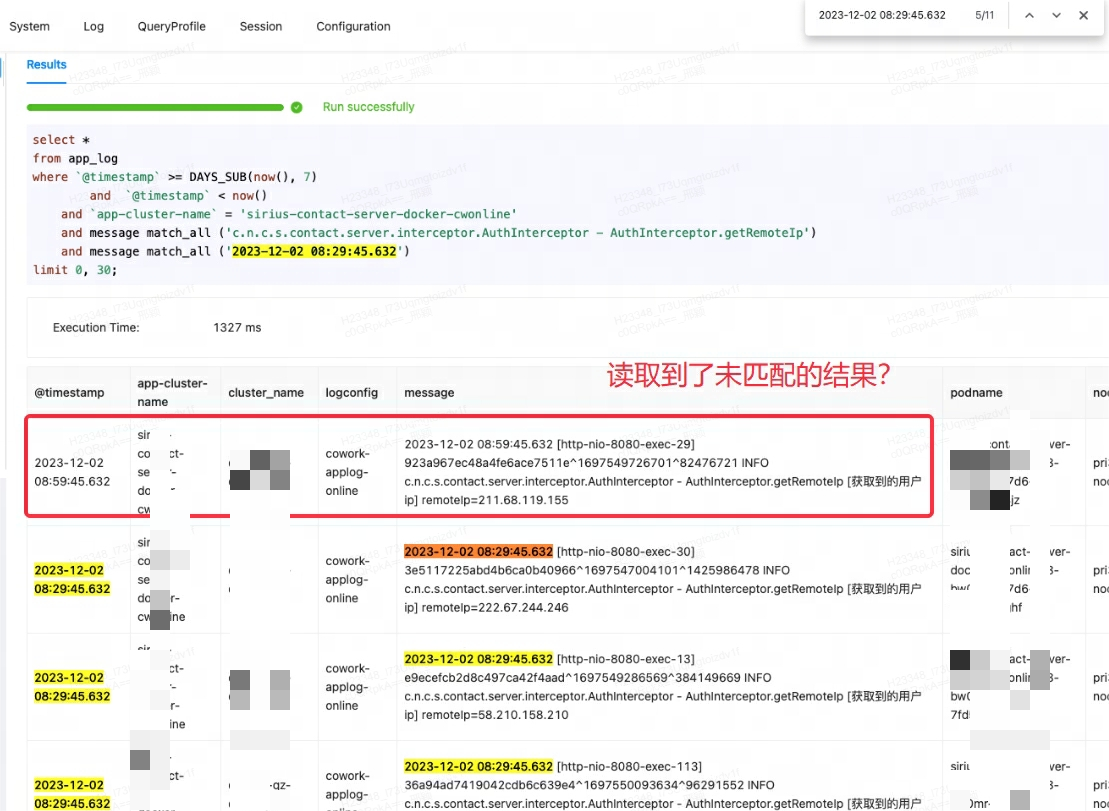
Au début, je pensais à tort qu'il s'agissait d'un bug de Doris, alors j'ai essayé de rechercher des problèmes et des solutions similaires. Cependant, après avoir consulté les membres de la communauté et examiné attentivement les documents officiels, il a été découvert que l'origine du problème résidait dans match_allune mauvaise compréhension du scénario d'utilisation.
match_allLe principe de fonctionnement de est que la correspondance peut être effectuée tant qu'une segmentation des mots existe et que la segmentation des mots est basée sur des espaces ou des signes de ponctuation . Dans ce cas, match_allle « 29 » correspond au « 29 » dans le contenu suivant du premier enregistrement, produisant ainsi des résultats inattendus.
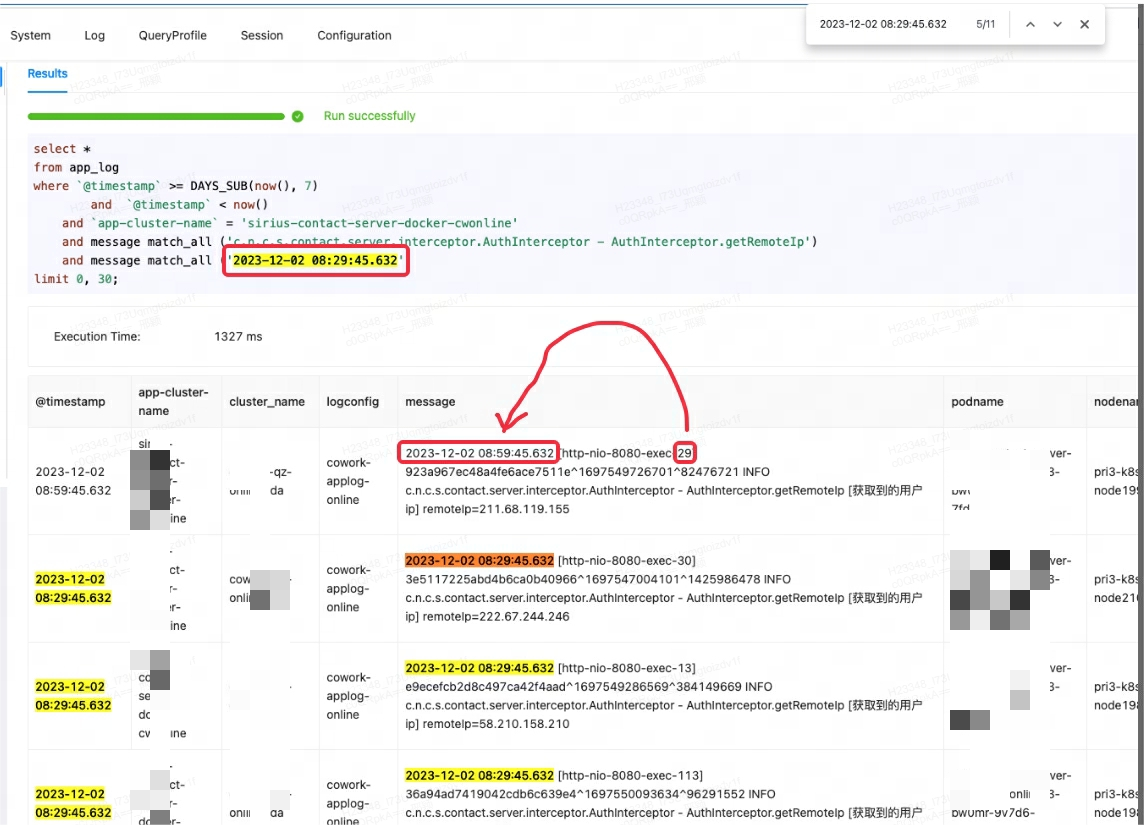
Dans ce cas, la méthode correcte consiste à utiliser MATCH_PHRASEune correspondance MATCH_PHRASEqui peut répondre aux exigences d'ordre dans le texte.
-- 1.4 logmsg中同时包含keyword1和keyword2的行,并且按照keyword1在前,keyword2在后的顺序
SELECT * FROM table_name WHERE logmsg MATCH_PHRASE 'keyword1 keyword2';
Lorsque vous utilisez MATCH_PHRASEla correspondance, vous devez le spécifier lors de la construction de l'index support_phrase, sinon le système effectuera une analyse complète de la table et effectuera une correspondance stricte, ce qui entraînera une mauvaise efficacité des requêtes.
INDEX idx_name4(column_name4) USING INVERTED PROPERTIES("parser" = "english|unicode|chinese", "support_phrase" = "true")
Pour les tables qui ont déjà écrit des données, si vous souhaitez l'activer support_phrase, vous pouvez DROP INDEXsupprimer l'ancien index puis ADD INDEXajouter un nouvel index. Ce processus est effectué de manière incrémentielle sur la table existante sans réécrire les données de la table entière, garantissant ainsi l'efficacité de l'opération.
Par rapport à Elasticsearch, la méthode de gestion des index de Doris est plus flexible et peut rapidement ajouter ou supprimer des index en fonction des besoins de l'entreprise, offrant ainsi plus de commodité et de flexibilité.
Conclusion
L'introduction d'Apache Doris répond efficacement aux besoins de NetEase en matière de journaux et de scénarios de synchronisation, et résout efficacement les problèmes de coûts de stockage élevés et de faible efficacité des requêtes de NetEase Lingxi Office et des premières plates-formes de traitement et d'analyse des journaux de NetEase Cloud Letter.
Dans les applications réelles, Apache Doris a transporté un trafic d'écriture en ligne moyen de 500 Mo/s et une valeur maximale de plus de 1 Go/s avec des ressources de serveur inférieures. Dans le même temps, la réponse aux requêtes a également été considérablement améliorée. Par rapport à Elasticsearch, l'efficacité des requêtes a été multipliée par au moins 11. De plus, Doris a un taux de compression plus élevé et peut économiser 70 % des ressources de stockage par rapport à avant.
Enfin, un merci tout spécial à l'équipe technique de SelectDB pour son soutien continu. À l'avenir, NetEase continuera à promouvoir Apache Doris et à l'appliquer en profondeur dans d'autres scénarios Big Data de NetEase. Dans le même temps, nous sommes également impatients d'avoir des échanges approfondis avec davantage d'équipes commerciales intéressées par Doris afin de promouvoir conjointement le développement d'Apache Doris.
Contributions open source
Au cours du processus de mise en œuvre commerciale et de dépannage, les étudiants de NetEase ont activement pratiqué l'esprit open source et ont contribué à une série de relations publiques précieuses à la communauté Apache Doris pour promouvoir le développement et le progrès de la communauté :
- Correction d'un bug de chargement de flux
- Optimisation du code de chargement de flux
- Stratification chaude et froide pour trouver une optimisation Rowset appropriée
- La stratification chaude et froide réduit les traversées invalides
- Optimisation des intervalles de verrouillage à chaud et à froid
- Optimisation du filtrage des données stratifiées chaudes et froides
- Optimisation du jugement de capacité de stratification chaude et froide
- Optimisation du tri hiérarchique à chaud et à froid
- Standardisation des rapports d'erreurs FE
- Nouvelle
array_aggfonction - Fonction d'agrégation Correction d'un bug
- Correction d'un bug du plan d'exécution
- Optimisation de TaskGroupManager
- Réparation d'accident BE
- Modification de documents :
- https://github.com/apache/doris/pull/26958
- https://github.com/apache/doris/pull/26410
- https://github.com/apache/doris/pull/25082
- https://github.com/apache/doris/pull/25075
- https://github.com/apache/doris/pull/31882
- https://github.com/apache/doris/pull/30654
- https://github.com/apache/doris/pull/30304
- https://github.com/apache/doris/pull/29268