
Récemment, la conférence Kangaroo Cloud Spring sur le thème « Données + IA, construire une nouvelle productivité » s'est terminée avec succès. La conférence a présenté une série de produits numériques « +IA » et les dernières précipitations de l'industrie, visant à intégrer étroitement les données et. L'IA, qui repousse les limites traditionnelles de la productivité et permet aux entreprises d'atteindre un développement numérique de meilleure qualité et plus efficace. Lors de la réunion, Tou Tian, chef de produit de Kangaroo Cloud Data Stack, a présenté une nouvelle version de Data Stack V6.2 qui intègre des capacités d'IA . Il ne s'agit pas seulement d'une simple mise à niveau du produit, mais représente également la prédiction audacieuse de Kangaroo Cloud. avenir. .
Data Stack V6.2 : Maximiser la valeur des données
À l’ère des données, celles-ci sont devenues la bouée de sauvetage des entreprises. Comment gérer et utiliser efficacement ces données est une question que chaque entreprise explore. La sortie de Data Stack V6.2 vise précisément à résoudre ce défi et à aider les entreprises à surfer sur les vagues de l'océan des données.
Le concept central de la nouvelle Data Stack V6.2 est Data+AI . La nouvelle version fournit non seulement les fonctions de base de la plate-forme Big Data, mais fournit également aux entreprises une analyse de données et des applications intelligentes grâce à une intégration profonde avec la technologie d'IA . Cela signifie que les entreprises peuvent utiliser la plate-forme de pile de données pour réaliser l'intégration des systèmes de contenu de l'industrie, des informations flexibles et pratiques sur les données, des calculs de moteur d'analyse extrêmement rapides et une gestion et un contrôle complets de la sécurité des données. De plus, les solutions de produits Kangaroo Cloud couvrent également de nombreux aspects tels que la légèreté, la gouvernance des données et la création d'informations. Tout cela est conçu pour aider les entreprises à optimiser les coûts de stockage informatique, à améliorer la qualité des données, à promouvoir les normes et spécifications et, à terme, à maximiser la valeur des données.
1. Solution de centre de données légère, le traitement des données est plus efficace
En introduisant les moteurs informatiques efficaces Doris et StarRocks , une reconstruction révolutionnaire des performances de la plate-forme est réalisée. Cette initiative innovante améliore non seulement considérablement la vitesse de traitement des données, réduit les coûts de stockage ainsi que les coûts d'exploitation et de maintenance, mais optimise également l'efficacité des requêtes et apporte aux entreprises une expérience d'exploitation de données sans précédent. Les capacités de requêtes ad hoc et les capacités de traitement analytique hautes performances de Doris et StarRocks construisent conjointement une plateforme de traitement de données puissante et flexible. Les utilisateurs peuvent facilement faire face aux besoins d’analyse en temps réel de données massives et obtenir des informations instantanées sur les données et une aide à la décision. Dans ce processus, l'exactitude et la fiabilité des données sont entièrement garanties, fournissant un support de données solide pour les activités clés de l'entreprise telles que la prédiction des pannes, le marketing de précision et l'optimisation des processus.
et les capacités de traitement analytique hautes performances de Doris et StarRocks construisent conjointement une plateforme de traitement de données puissante et flexible. Les utilisateurs peuvent facilement faire face aux besoins d’analyse en temps réel de données massives et obtenir des informations instantanées sur les données et une aide à la décision. Dans ce processus, l'exactitude et la fiabilité des données sont entièrement garanties, fournissant un support de données solide pour les activités clés de l'entreprise telles que la prédiction des pannes, le marketing de précision et l'optimisation des processus.
2. Système complet de gouvernance des données pour maximiser la valeur de l'entreprise
Dans Data Stack V6.2, nous avons entièrement mis à niveau et redéfini la gouvernance des données pour répondre aux besoins croissants des entreprises en matière de gestion des données. Les cinq dimensions du centre de gouvernance des données : stockage, calcul, qualité, spécification et valeur, constituent un système complet de gouvernance des données pour garantir l'intégrité, l'exactitude et la disponibilité des données de l'entreprise.
L'atelier de gouvernance fournit une interface de fonctionnement intuitive, ce qui rend simple et efficace le lancement, l'enregistrement, l'attribution et le traitement des tâches de gouvernance des données. Grâce à cette plate-forme, les entreprises peuvent afficher l'état de la gouvernance des données d'un point de vue personnel, d'une perspective de projet à une perspective panoramique, garantissant ainsi que la qualité des données de chaque lien est efficacement surveillée et gérée. La fonction d'inspection du code standardise le code SQL via des règles d'inspection SQL pour prévenir à l'avance d'éventuels problèmes de gestion. La gestion des petits fichiers vise à résoudre le problème des petits fichiers dans les clusters Hadoop, en optimisant les performances et l'évolutivité du cluster grâce à une fusion ponctuelle ou régulière et en améliorant l'efficacité du traitement des données .
La gouvernance des données de DataStack V6.2 ne constitue pas seulement une mise à niveau de la technologie, mais également un façonnement de la culture des données de l'entreprise. Grâce à un tel système de gouvernance, les entreprises peuvent établir un cadre complet de gouvernance des données , promouvoir la normalisation et la standardisation des données et, en fin de compte, maximiser la valeur des actifs de données.
3. L'adaptation Xinchuang à lien complet prend en charge une localisation complète
À l’ère de l’information et de l’innovation de l’information, nous sommes bien conscients des besoins des entreprises en matière de sécurité des données et de contrôlabilité indépendante. Par conséquent, notre plate-forme atteint non seulement une couverture complète de l'innovation en matière d'informations en termes de serveurs, de systèmes d'exploitation, de puces, de middleware, de bases de données de métadonnées, de moteurs informatiques, etc., mais apporte également des adaptations profondes dans la protection de sécurité complète des processus.etle déploiement privatisé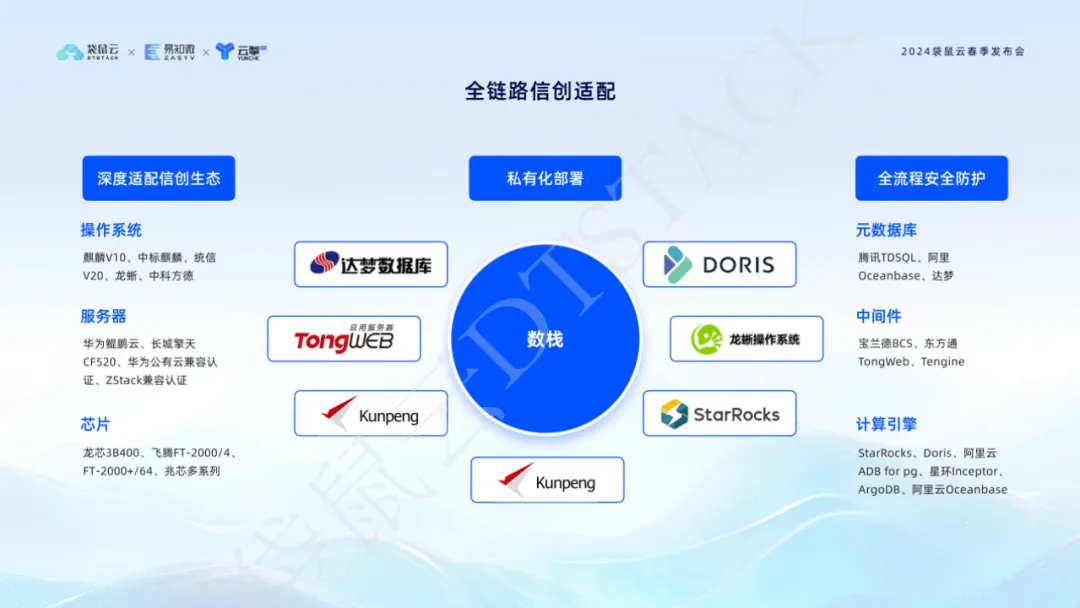
4. Innover et percer les capacités du lac de données Paimon pour réaliser un modèle de traitement de données intégré par lots
Dans le modèle de traitement de données traditionnel, les entreprises sont souvent confrontées au dilemme consistant à développer et à maintenir deux ensembles de logiques de code : l'un pour le traitement par lots et l'autre pour le traitement de flux en temps réel. Cela signifie non seulement doubler la charge de travail de développement et de maintenance, mais nécessite également de traiter la logique de fusion des données entre les deux pour garantir que les deux systèmes soient mis en ligne simultanément. Un tel modèle augmente non seulement la consommation de ressources, mais peut également conduire à une ambiguïté des données, rendant difficile la garantie de l'exactitude des données et réduisant la confiance du personnel commercial dans les résultats des données.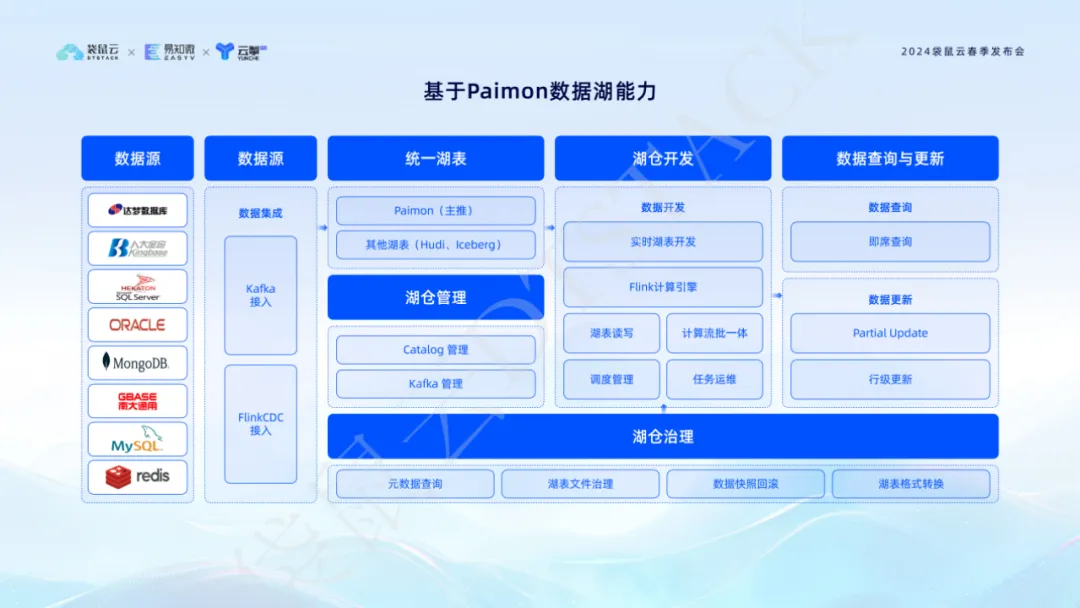
La percée innovante de la pile de données réalise le modèle de traitement de données intégré par lots grâce aux capacités de Paimon Data Lake , résolvant efficacement les problèmes ci-dessus. La plate-forme fournit un développement de tables Lake en temps réel et des fonctions de requête ad hoc , permettant aux développeurs de données de traiter simultanément des données en temps réel et par lots sur une seule plate-forme sans avoir besoin d'investissements en ressources supplémentaires ni de processus complexes de synchronisation des données. Une telle solution intégrée réduit non seulement l'utilisation des ressources informatiques et de stockage, mais garantit également la cohérence et l'exactitude des données, améliorant ainsi la reconnaissance par le personnel de l'entreprise des résultats de l'analyse des données. Cette innovation apportera un soutien solide à la transformation numérique et à la mise à niveau intelligente des entreprises.
5. Les quatre fonctions principales d'EasyMR sont profondément optimisées pour débloquer une nouvelle expérience de traitement et de calcul du Big Data.
En tant que module produit important dans la pile de données, EasyMR représente notre compréhension approfondie et notre innovation continue de l'écosystème du Big Data. Il est basé sur Hadoop open source et itère de manière synchrone avec la communauté open source. Il est développé indépendamment par notre équipe de moteurs informatiques et possède des fonctionnalités optimisées et améliorées de composants de base tels que Spark, Flink et Paimon. Ces optimisations améliorent non seulement les performances et la stabilité du traitement des données, mais redonnent également à la communauté et favorisent la construction conjointe de l'écosystème Hadoop.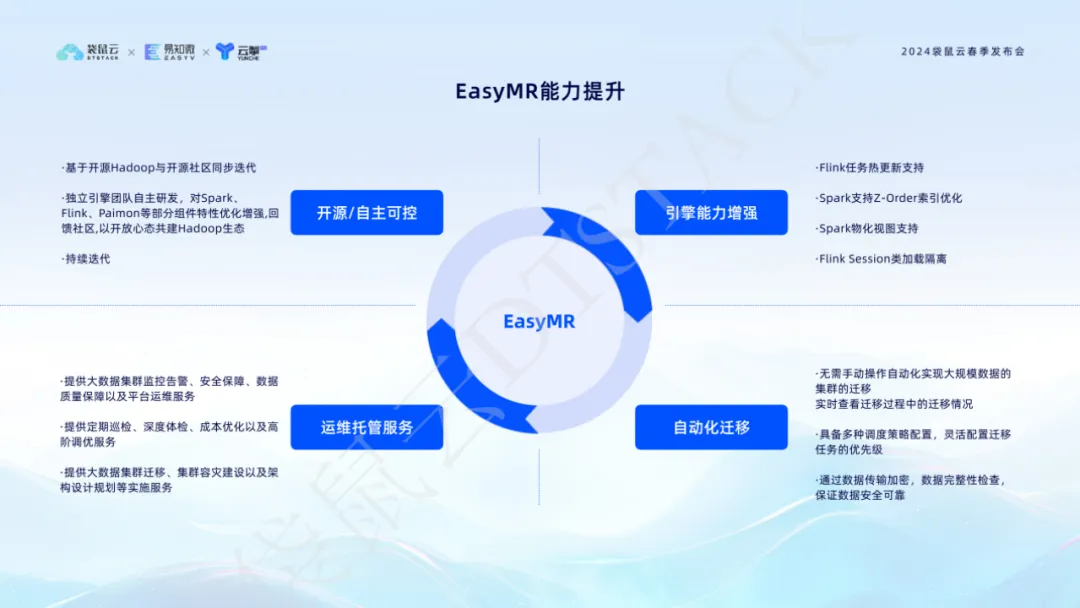
Les capacités améliorées d'EasyMR se reflètent dans de nombreux aspects : il prend en charge les mises à jour à chaud des tâches Flink , garantissant la continuité des activités et la flexibilité ; l'optimisation de l'index Z-Order de Spark et la prise en charge des vues matérialisées améliorent l'efficacité du traitement des données et la vitesse de réponse. L'isolation de chargement des classes de session de Flink garantit la sécurité et la vitesse de réponse ; fiabilité de l’environnement d’exploitation. De plus, la fonction de migration automatisée d'EasyMR rend la migration de clusters de données à grande échelle facile et simple et surveille l'état pendant le processus de migration en temps réel pour garantir la sécurité et la fiabilité des données. Grâce à ces innovations et optimisations, EasyMR offre aux utilisateurs une plateforme Big Data efficace, intelligente et facile à entretenir, aidant les entreprises à réaliser un saut qualitatif en matière de gestion et d'analyse des données.
Les capacités Data+IA rendent le développement de données plus intelligent
La technologie de l’IA est devenue le principal moteur de l’innovation et de l’amélioration de l’efficacité des entreprises. En intégrant la technologie d'IA générative , DataStack V6.2 a réalisé six fonctions principales : développement intelligent, réglage intelligent, diagnostic intelligent, récupération intelligente, analyse intelligente et vérification intelligente, ce qui améliore considérablement l'efficacité et la qualité du traitement des données.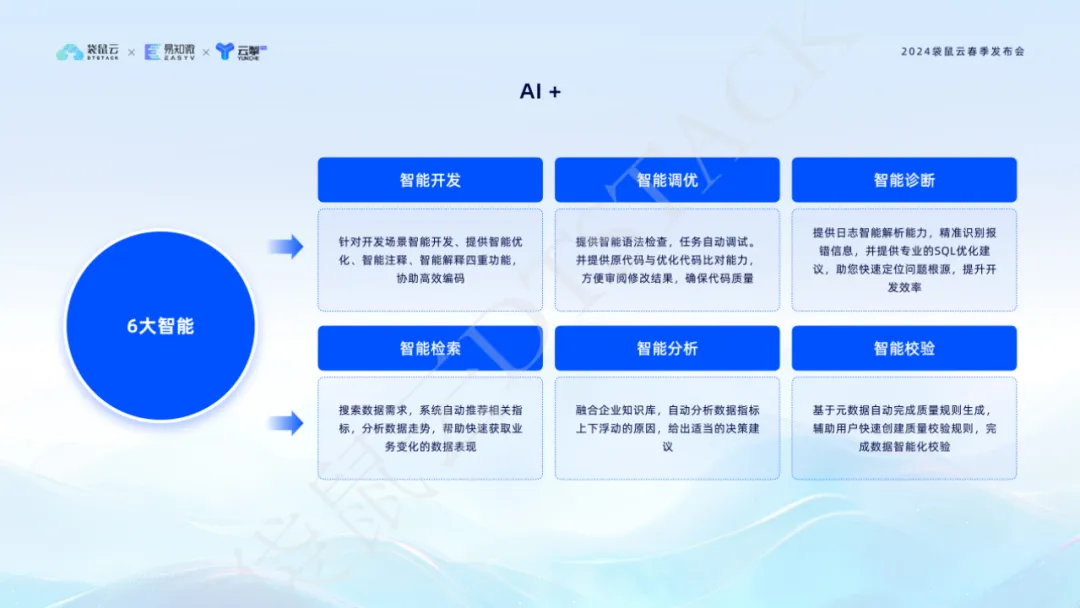
Le réglage intelligent peut optimiser automatiquement le code SQL et améliorer les performances d'exécution ; le diagnostic intelligent utilise l'IA pour analyser les journaux afin de localiser rapidement les problèmes et fournir des suggestions d'optimisation professionnelles permettant de comprendre en profondeur les tendances des données et de fournir un soutien solide à la prise de décision. Ces fonctions améliorent non seulement l'efficacité du développement, mais garantissent également la qualité du code et atteignent les objectifs commerciaux avec plus de précision, en s'appuyant sur les données. L’introduction de l’IA+ marque que nous entrons dans une nouvelle ère de gestion des données plus intelligente et plus efficace.
La fonction de réglage intelligent AI + peut fournir des suggestions d'optimisation intelligentes lorsque les développeurs écrivent du code dans l'éditeur, permettant aux étudiants en développement de données de l'examiner et de le comparer. Cela améliore l'efficacité et la qualité du codage, permettant aux étudiants en développement de données de se concentrer davantage sur la mise en œuvre de la logique métier.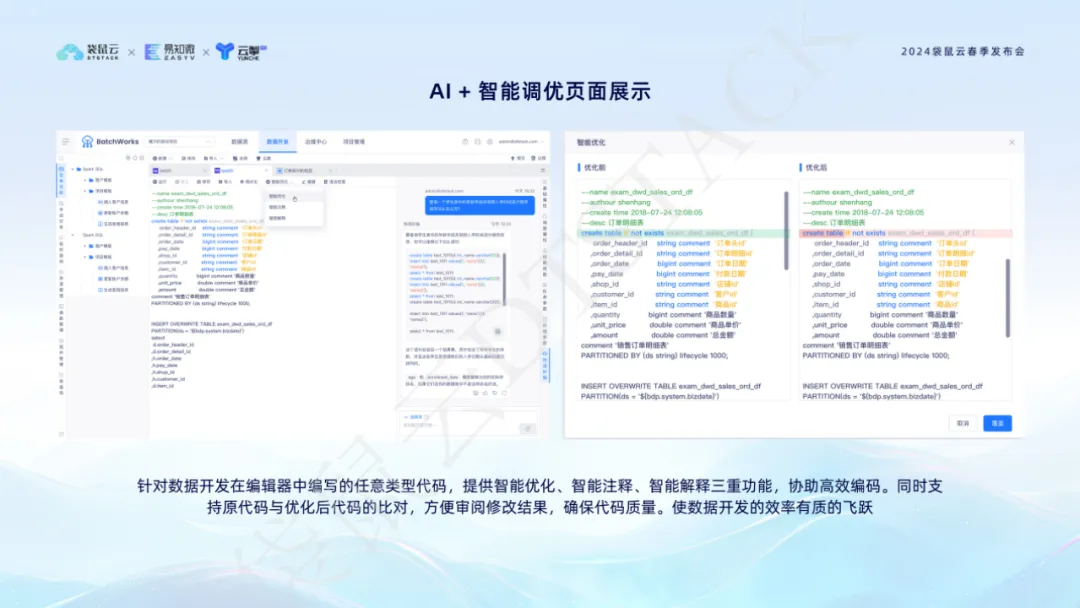
La fonction de diagnostic intelligent AI + utilise la technologie IA pour analyser intelligemment Spark SQL, Flink SQL et d'autres journaux de tâches, identifier les messages d'erreur et fournir des suggestions d'optimisation SQL professionnelles pour aider à localiser rapidement la cause première du problème et améliorer l'efficacité du développement du code. 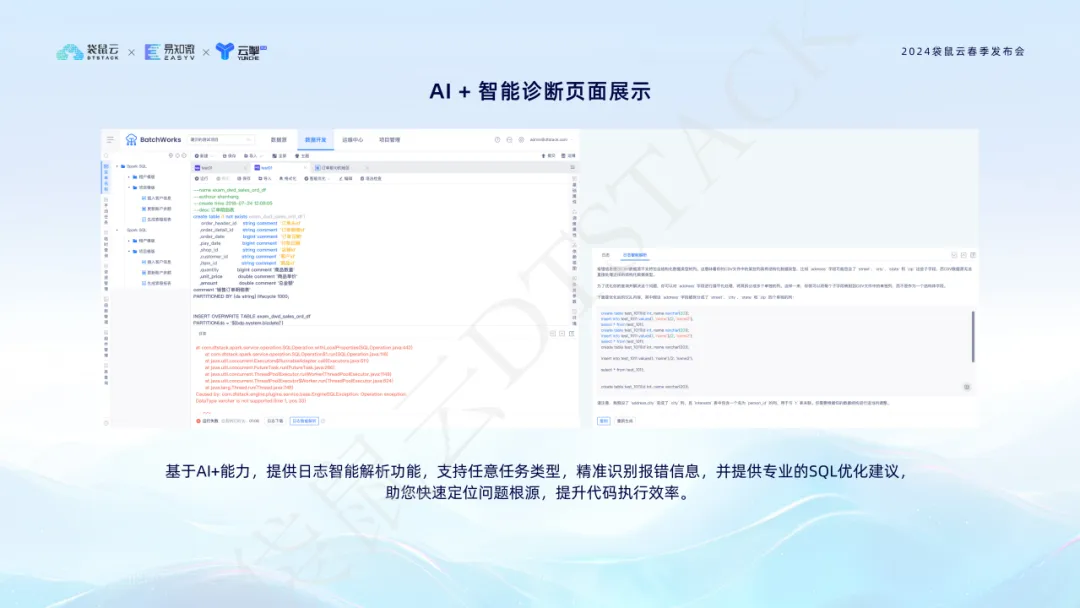 Grâce à l'intégration avec AI+, la pile de données simplifie non seulement le processus de développement des données, mais améliore également la précision et la fiabilité du traitement des données, fournissant ainsi un support technique solide à la prise de décision basée sur les données des entreprises.
Grâce à l'intégration avec AI+, la pile de données simplifie non seulement le processus de développement des données, mais améliore également la précision et la fiabilité du traitement des données, fournissant ainsi un support technique solide à la prise de décision basée sur les données des entreprises.
Produits + services, une nouvelle mise à niveau de la stratégie de commercialisation des produits de la pile de données
Lors de ce lancement de produit, nous avons redéfini notre stratégie de commercialisation de produits, visant à fournir des solutions de services flexibles et diversifiées aux entreprises ayant des besoins différents.  La série de produits comprend l'édition standard, l'édition professionnelle et l'édition ultime, et offre des options de déploiement d'applications cloud pour répondre aux besoins de traitement des données des entreprises de différentes tailles. En outre, nous fournissons également des services à valeur ajoutée tels que l'adaptation de Xinchuang et l'entrepôt du lac en temps réel, ainsi que des versions avancées et supérieures de services d'exploitation et de maintenance systématiques, garantissant que les clients peuvent bénéficier d'une assistance complète, de base à avancée.
La série de produits comprend l'édition standard, l'édition professionnelle et l'édition ultime, et offre des options de déploiement d'applications cloud pour répondre aux besoins de traitement des données des entreprises de différentes tailles. En outre, nous fournissons également des services à valeur ajoutée tels que l'adaptation de Xinchuang et l'entrepôt du lac en temps réel, ainsi que des versions avancées et supérieures de services d'exploitation et de maintenance systématiques, garantissant que les clients peuvent bénéficier d'une assistance complète, de base à avancée.
La stratégie de commercialisation des produits de Datastack se concentre non seulement sur la vente de produits, mais également sur l'optimisation et la mise à niveau continues des services. En proposant deux voies de mise à niveau du produit et de mise à niveau de version, il aide les entreprises à garantir l'adaptabilité continue et la nature tournée vers l'avenir de la plate-forme de données. Une telle stratégie améliore non seulement l'expérience client, mais établit également une base solide pour le développement à long terme des produits de pile de données.
Trois cas pratiques de produits majeurs pour aider la transformation numérique des entreprises
1. Une banque : mise en œuvre d’une évaluation des performances basée sur l’IA
Sur la base des indicateurs d'évaluation des performances accumulés, combinés à la propre base de connaissances de l'entreprise, la banque utilise les capacités intelligentes d'analyse et de traitement des données de l'IA pour améliorer considérablement l'efficacité de la gestion et le niveau de gouvernance de l'évaluation des performances.
Notre solution a aidé la banque à réaliser la transformation des rapports d'indicateurs en tableaux de bord d'indicateurs, puis en BI conversationnelle d'indicateurs, ce qui a considérablement réduit le coût pour les employés d'obtenir et d'utiliser les données, a rendu les normes d'évaluation plus scientifiques et rigoureuses et le contenu de l'évaluation plus complet. , garantissant que la banque Il existe un lien étroit entre la performance globale et la performance individuelle des employés. Grâce à l'attribution intelligente de l'IA et aux suggestions intelligentes, les banques peuvent suivre les résultats de performance des employés en temps réel, identifier les problèmes en temps opportun et procéder à des ajustements, favorisant ainsi la cohérence des employés et des objectifs organisationnels et l'amélioration continue des performances. Cette transformation optimise non seulement la gestion des ressources humaines de la banque, mais apporte également une efficacité opérationnelle et des résultats commerciaux plus élevés à l'ensemble de l'organisation.
2. Une marque d’alcool chinoise : un data center léger
Grâce à Data Stack, la marque a établi une plate-forme marketing unifiée, aidant les entreprises à réaliser des capacités d'analyse multidimensionnelles telles que le partage de données , les balises intelligentes et la gestion des indicateurs, et fournissant un solide support de données pour le marketing de précision des entreprises, l'optimisation des processus, etc.  La plateforme adopte une solution de données légères de milieu de gamme et la combine avec les capacités de calcul haute performance de StarRocks pour permettre aux sociétés de boissons alcoolisées de réaliser une gestion efficace des données et une analyse instantanée. Les fonctionnalités de requête à faible latence et de chargement rapide des données de StarRocks permettent aux entreprises de réagir rapidement aux changements du marché et de réaliser des prévisions de défaillance et un marketing de précision. Par rapport à l'écosystème Hadoop traditionnel, une solution de données de milieu de gamme aussi légère offre d'excellentes performances de requête, un traitement des données en temps réel, une simultanéité élevée et une maintenance facile dans les scénarios où le volume de données est faible, ce qui en fait une solution idéale pour une utilisation rapide. analyse des données, il favorise la transformation numérique des sociétés d’alcool.
La plateforme adopte une solution de données légères de milieu de gamme et la combine avec les capacités de calcul haute performance de StarRocks pour permettre aux sociétés de boissons alcoolisées de réaliser une gestion efficace des données et une analyse instantanée. Les fonctionnalités de requête à faible latence et de chargement rapide des données de StarRocks permettent aux entreprises de réagir rapidement aux changements du marché et de réaliser des prévisions de défaillance et un marketing de précision. Par rapport à l'écosystème Hadoop traditionnel, une solution de données de milieu de gamme aussi légère offre d'excellentes performances de requête, un traitement des données en temps réel, une simultanéité élevée et une maintenance facile dans les scénarios où le volume de données est faible, ce qui en fait une solution idéale pour une utilisation rapide. analyse des données, il favorise la transformation numérique des sociétés d’alcool.
3. Société du groupe municipal d'État de Pékin : Full Link Xinchuang
Afin de résoudre les problèmes de transformation numérique de l'entreprise et les exigences en matière d'innovation de l'information, ce client a créé une « plate-forme Big Data d'innovation de l'information à lien complet ».  La plate-forme est profondément adaptée à l'écosystème de Xinchuang et réalise une protection de sécurité complète et un déploiement privatisé à partir de serveurs, de systèmes d'exploitation, de puces, de bases de données de métadonnées d'application, de middleware et de moteurs informatiques. Grâce à une telle adaptation de l'innovation de l'information à lien complet , le groupe a non seulement résolu le problème des îlots de données, mais a également répondu aux exigences strictes du pays en matière d'innovation de l'information et a assuré la sécurité et la contrôlabilité des données. Cette initiative a considérablement amélioré les capacités de gouvernance des données du groupe, jeté une base de données solide pour le développement à long terme de l'entreprise et a également fourni à d'autres entreprises publiques une expérience pratique précieuse en matière d'innovation de l'information.
La plate-forme est profondément adaptée à l'écosystème de Xinchuang et réalise une protection de sécurité complète et un déploiement privatisé à partir de serveurs, de systèmes d'exploitation, de puces, de bases de données de métadonnées d'application, de middleware et de moteurs informatiques. Grâce à une telle adaptation de l'innovation de l'information à lien complet , le groupe a non seulement résolu le problème des îlots de données, mais a également répondu aux exigences strictes du pays en matière d'innovation de l'information et a assuré la sécurité et la contrôlabilité des données. Cette initiative a considérablement amélioré les capacités de gouvernance des données du groupe, jeté une base de données solide pour le développement à long terme de l'entreprise et a également fourni à d'autres entreprises publiques une expérience pratique précieuse en matière d'innovation de l'information.
Ce qui précède est l'introduction à la version DataStack V6.2. Il ne s'agit pas seulement d'un produit, mais également d'un résumé de notre compréhension approfondie et de notre pratique de la gouvernance du Big Data et de l'analyse intelligente. Nous pensons que Data Stack V6.2 peut aider davantage d'entreprises à maximiser la valeur des données et à promouvoir leur transformation numérique.
Adresse de téléchargement du « Livre blanc sur le système d'indicateurs industriels » : https://www.dtstack.com/resources/1057?src=szsm
Adresse de téléchargement du « Livre blanc sur les produits Dutstack » : https://www.dtstack.com/resources/1004?src=szsm
Adresse de téléchargement du « Livre blanc sur les pratiques de l'industrie de la gouvernance des données » : https://www.dtstack.com/resources/1001?src=szsm
Pour ceux qui souhaitent en savoir ou en savoir plus sur les produits Big Data, les solutions industrielles et les cas clients, visitez le site officiel de Kangaroo Cloud : https://www.dtstack.com/?src=szkyzg
Linus a pris sur lui d'empêcher les développeurs du noyau de remplacer les tabulations par des espaces. Son père est l'un des rares dirigeants capables d'écrire du code, son deuxième fils est directeur du département de technologie open source et son plus jeune fils est un noyau open source. contributeur. Robin Li : Le langage naturel deviendra un nouveau langage de programmation universel. Le modèle open source prendra de plus en plus de retard sur Huawei : il faudra 1 an pour migrer complètement 5 000 applications mobiles couramment utilisées vers Java, qui est le langage le plus enclin . vulnérabilités tierces. L'éditeur de texte riche Quill 2.0 a été publié avec des fonctionnalités, une fiabilité et des développeurs. L'expérience a été grandement améliorée. Bien que l'ouverture soit terminée, Meta Llama 3 a été officiellement publié. la source de Laoxiangji n'est pas le code, les raisons derrière cela sont très réconfortantes. Google a annoncé une restructuration à grande échelle.