Dans le développement moderne du deep learning, nous nous appuyons généralement sur d'autres modules pour créer des systèmes logiciels complexes tels que des blocs de construction. Ce processus est souvent rapide et efficace. Cependant, la manière de localiser et de résoudre rapidement les problèmes rencontrés a toujours troublé les concepteurs et les responsables de systèmes d'apprentissage profond en raison de la complexité et du couplage du système.
En tant que membre de l'équipe technique back-end d'iQiyi, nous avons enregistré en détail le processus de résolution des problèmes liés à la mémoire liés à l'entraînement en profondeur, dans l'espoir de fournir une certaine inspiration à nos pairs qui travaillent dur pour résoudre des problèmes épineux.
arrière-plan
Au cours du dernier trimestre, nous avons observé des phénomènes aléatoires de MOO de mémoire CPU dans le cluster A100. Avec l'introduction de la formation sur de grands modèles, oom est devenu encore plus insupportable, ce qui nous a déterminés à résoudre ce problème.
En repensant à d’où je viens, je me suis senti soudainement éclairé. En fait, nous étions autrefois très proches de la vérité du problème, mais nous manquions d’assez d’imagination et nous l’avons raté.
processus
Au tout début, nous avons procédé à une analyse inductive des journaux historiques. Plusieurs règles ont été découvertes, qui ont une très bonne signification pour la solution finale :
-
Il s'agit d'un nouveau problème rencontré dans le cluster A100 et qui n'a pas été rencontré dans d'autres clusters.
-
Le problème est lié à la formation distribuée ddp de pytorch ; aucun autre mode de formation utilisant pytorch n'a été rencontré.
-
Ce problème de MOO est assez aléatoire, certains surviennent dans les 3 heures et d’autres seulement après plus d’une semaine.
-
Une augmentation de la mémoire se produit pendant le MOO, complétant essentiellement l'augmentation de 10 % à 90 % en 1 minute et demie, comme le montre la figure ci-dessous :
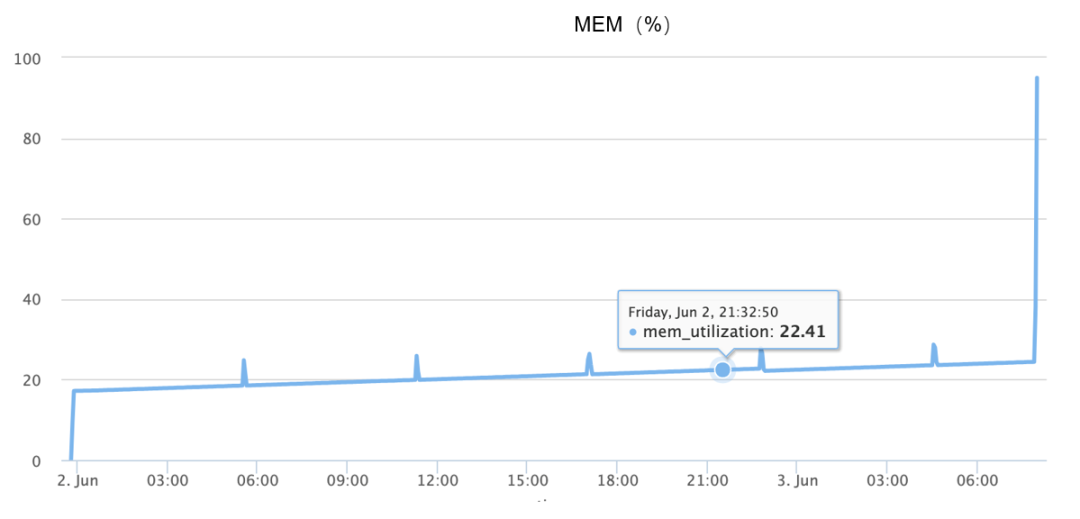
Bien que les informations ci-dessus soient disponibles, comme le problème ne peut pas être reproduit de manière fiable, au début, je me suis entièrement appuyé sur une imagination divergente, j'ai deviné de nombreuses causes possibles, telles que :
-
Serait-ce un problème de code, car l'objet n'est pas recyclé, provoquant des fuites de mémoire continues ?
-
Serait-ce un problème avec l'allocateur de mémoire sous-jacent, similaire au fait que l'allocateur PTMALLOC de la glibc a trop de fragments, donc à un certain moment, des demandes de mémoire soudaines conduisent à une allocation de mémoire continue ?
-
Serait-ce un problème matériel ?
-
Serait-ce un bug dans une version spécifique du logiciel ?
Nous présentons ci-dessous les deux premières hypothèses en détail.
-
Est-ce un problème avec le code ?
Afin de déterminer s'il s'agit d'un problème de code, nous avons ajouté du code de débogage à la scène où le problème s'est produit et l'avons appelé périodiquement. Le code suivant imprimera tous les objets qui ne peuvent pas être recyclés par le module python gc actuel.
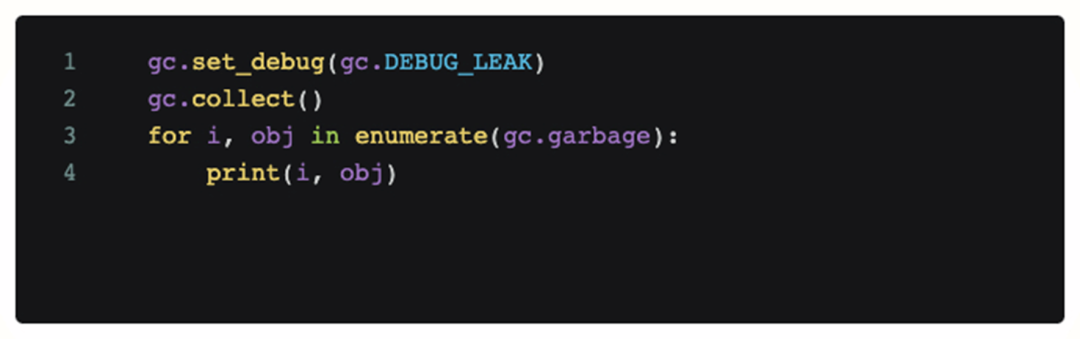 Cependant, après avoir ajouté ce code, l'analyse du journal obtenue montre qu'il n'y a aucun objet inaccessible qui occupe beaucoup de mémoire pendant le MOO, et le gc continu ne peut pas atténuer le MOO lui-même. Donc à ce stade, notre première hypothèse est fausse, le problème n'est pas causé par le code (fuite de mémoire).
Cependant, après avoir ajouté ce code, l'analyse du journal obtenue montre qu'il n'y a aucun objet inaccessible qui occupe beaucoup de mémoire pendant le MOO, et le gc continu ne peut pas atténuer le MOO lui-même. Donc à ce stade, notre première hypothèse est fausse, le problème n'est pas causé par le code (fuite de mémoire).
-
Est-ce dû à l'allocateur de mémoire ?
À ce stade, nous avons introduit l'allocateur de mémoire jemalloc. Par rapport au PTMALLOC par défaut de la glibc, son avantage est qu'il peut fournir une allocation de mémoire plus efficace et une meilleure prise en charge du débogage de l'allocation de mémoire elle-même.
-
Serait-ce un problème avec l'allocateur de mémoire par défaut ?
-
De meilleurs outils de débogage et d’analyse
Afin de visualiser directement l'état actuel de jemalloc en python sans modifier le code de la torche lui-même, nous avons utilisé des ctypes pour exposer l'interface jemalloc directement en python :
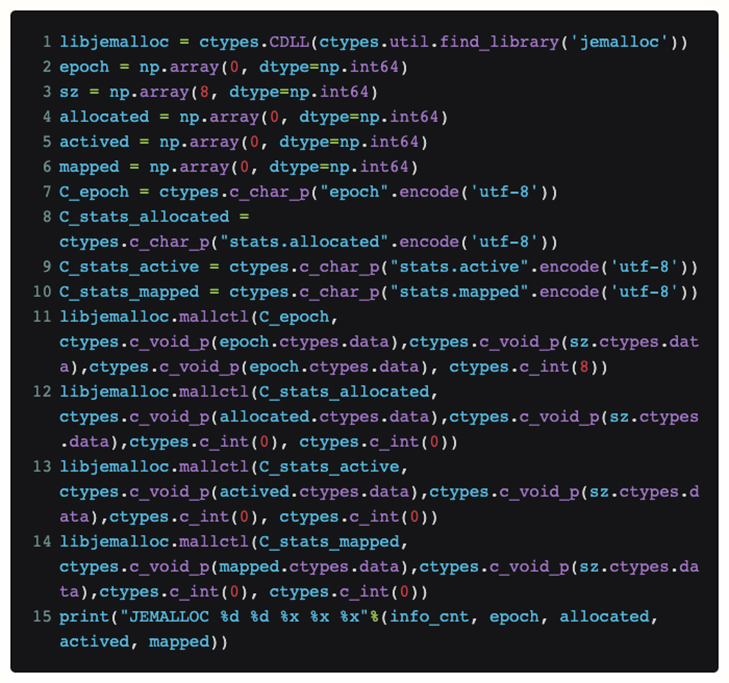
De cette façon, si nous mettons ce code dans une fonction, nous pouvons connaître périodiquement la requête [allouée] actuellement reçue par jemalloc de la couche supérieure, et la taille réelle de la mémoire physique [mappée] qu'il demande au système.
Après le processus de reproduction proprement dit, il a finalement été constaté que les deux valeurs attribuées et mappées sont très proches lorsque le MOO se produit. Notre hypothèse sur la fragmentation de la mémoire échoue donc.
-
Quelle est exactement la cause du problème ?
Lorsque nous étions au bout du rouleau, nous avons une fois de plus trié les journaux de MOO existants et avons découvert qu'il y avait une direction sur laquelle nous n'avions pas mis l'accent auparavant : c'est-à-dire que nous avions plusieurs machines fonctionnant à des moments similaires (1-2 minutes adjacentes) plusieurs fois) MOO se produit.
Alors, quelle explication logique y a-t-il à cette synchronicité magique ? Les bugs ordinaires ne devraient pas provoquer la répétition d’une telle cohérence. Il peut donc y avoir un lien inévitable entre eux.
Alors d’où vient cette corrélation ? Pour explorer cette question, la perspective analytique se déplace vers la communication en réseau dans la formation distribuée.
Les soupçons initiaux concernant la communication se concentraient sur les machines qui rencontraient un MOO. On soupçonnait qu'elles communiquaient entre elles pour une raison quelconque, ce qui entraînerait des problèmes entre elles. Par conséquent, tcpdump a été ajouté à la formation quotidienne pour surveiller le trafic réseau.
Finalement, après avoir rejoint tcpdump, j'ai détecté la communication la plus douteuse lors d'un MOO. Autrement dit, la machine MOO a reçu le trafic d'analyse de sécurité quelques minutes avant que le problème ne se produise.
positionnement final
Après avoir surpris l'équipe de sécurité en train d'analyser l'objet suspect, nous avons collaboré avec l'équipe de sécurité pour effectuer une analyse et avons finalement découvert que le problème du MOO pouvait être reproduit de manière stable sur la base de l'analyse, de sorte que la cause déclenchante était presque certaine. Cependant, à ce stade, nous ne pouvons que reproduire et modifier la stratégie d'analyse de sécurité pour éviter le problème du MOO. Nous devons également analyser davantage le code et enfin le localiser.
Après avoir analysé et positionné le code, il a finalement été déterminé que le problème réside dans le protocole de formation distribué DDP de pytorch. Le code pertinent est le suivant :
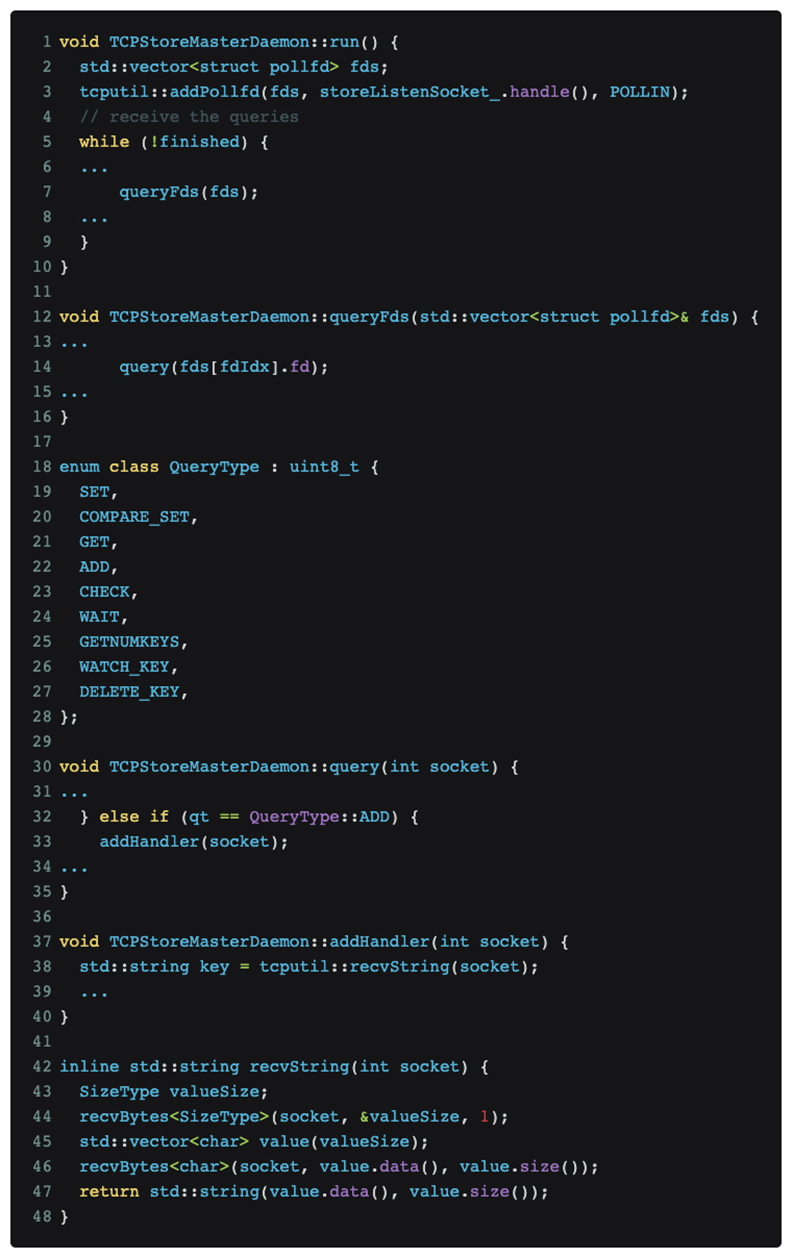
Comme le montre la figure ci-dessus, la formation distribuée pytorch continue d'écouter les messages sur le port maître.

L'analyse Nmap [nmap -sS -sV] a déclenché le type de message QueryType::ADD, qui est le numéro de la case verte [03] dans la partie données affichée dans l'image tcpdump ci-dessus, ce qui a amené pytorch à essayer d'utiliser le recvString fonction pour pré-allouer un tampon pour recevoir ce qu'il considère comme des messages de suivi. Mais cette longueur de tampon est analysée à l'aide d'un type uint64_t[little-endian] après [03], qui est le numéro de la boîte rouge [e0060b0000], qui est de 962174058496 octets. Cette valeur signifie que des données 1T seront reçues et pytorch. will Après que l'allocateur de mémoire ait demandé la mémoire correspondante, l'allocateur de mémoire demande en outre la page physique correspondante au noyau. Étant donné que notre cluster de formation GPU n'est pas configuré avec une énorme table de pages, Linux ne peut satisfaire que progressivement la demande de mémoire 1T de l'allocateur de mémoire lors des interruptions de page manquantes selon la granularité 4K, ce qui signifie qu'il faut environ 1 minute pour allouer toute la mémoire, et le Le MOO observé plus tôt se produit probablement en réponse à une croissance rapide de la mémoire d'environ 1 minute.
solution
Après avoir connu la cause et l’effet, la solution devient naturelle :
1. À court terme : modifier la politique d'analyse de sécurité pour éviter
2. Long terme : communiquer avec la communauté pour renforcer la robustesse [ 1 ]
Résumer
Après avoir effectué le retour en arrière du processus d'enquête sur les problèmes de MOO, nous avons constaté qu'au cours de ce processus, nous avions effectivement effectué une série de tests efficaces sur les outils liés à la mémoire et les méthodes de débogage.
Au cours de ce processus, nous avons découvert qu'il existe certains points communs qui peuvent être utilisés comme référence dans les recherches et développements ultérieurs :
-
Jemalloc peut fournir une analyse quantitative très efficace des problèmes de mémoire et capturer les problèmes sous-jacents liés à la mémoire dans les systèmes de programmation hybrides tels que python+C.
-
Mémoire. Nous en attendions beaucoup pendant le processus de débogage, mais à la fin, nous avons constaté que le domaine dans lequel memray peut fonctionner le mieux est toujours du côté de Python pur, et il n'est pas capable de systèmes de programmation hybrides tels que pytorch DDP.
Parfois, nous devons encore réfléchir aux problèmes dans une dimension plus large. Par exemple, si le processus de communication avec des services externes non liés n’est pas pris en compte, la véritable cause profonde ne sera pas découverte.
Peut-être que tu veux aussi voir

