
01
arrière-plan
02
Présentation de la plateforme de journalisation Venus
Venus est une plate-forme de services de journaux développée par iQiyi. Elle fournit des fonctions de collecte, de traitement, de stockage, d'analyse et autres. Elle est principalement utilisée pour le dépannage des journaux, l'analyse des mégadonnées, la surveillance et les alarmes au sein de l'entreprise. 1. montré.
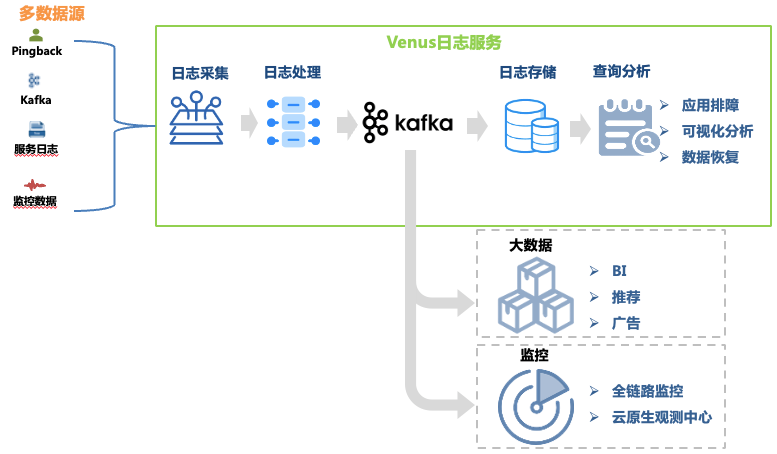 Figure 1 Lien Vénus
Figure 1 Lien Vénus
Cet article se concentre sur l'évolution architecturale du lien de dépannage des journaux. Ses liens de données incluent :
Collecte de journaux : en déployant des agents de collecte sur les machines et les hôtes de conteneurs, les journaux du front-end, du back-end, de la surveillance et d'autres sources de chaque secteur d'activité sont collectés, et l'entreprise est également prise en charge pour auto-livrer les journaux qui répondent aux exigences de format. . Plus de 30 000 agents ont été déployés, prenant en charge 10 sources de données telles que Kafka, MySQL, K8 et des passerelles.
Traitement des journaux : après la collecte des journaux, ils subissent un traitement standardisé tel qu'une extraction régulière et une extraction par l'analyseur intégré, et sont uniformément écrits sur Kafka au format JSON, puis écrits sur le système de stockage par le programme de vidage.
Stockage des journaux : Venus stocke près de 10 000 flux de journaux professionnels, avec un pic d'écriture de plus de 10 millions de QPS, et de nouveaux journaux quotidiens dépassant 500 To. À mesure que l'échelle de stockage évolue, la sélection des systèmes de stockage a subi de nombreux changements, depuis ElasticSearch jusqu'au lac de données.
Analyse des requêtes : Venus fournit une analyse visuelle des requêtes, une requête contextuelle, un disque de journal, une reconnaissance de formes, un téléchargement de journaux et d'autres fonctions.
Afin de répondre au stockage et à l'analyse rapide de données de log massives, la plateforme de log Venus a subi trois mises à niveau architecturales majeures, évoluant progressivement de l'architecture ELK classique à un système auto-développé basé sur des lacs de données. Cet article présentera les problèmes rencontrés. lors de la transformation de l'architecture et des solutions de Vénus.
03
Venus 1.0 : basée sur l'architecture ELK
Venus 1.0 a démarré en 2015 et a été construit sur la base du populaire ElasticSearch+Kibana, comme le montre la figure 2. ElasticSearch est responsable des fonctions de stockage et d'analyse des journaux, et Kibana fournit des capacités de requête et d'analyse visuelles. Il vous suffit de consommer Kafka et d'écrire des journaux sur ElasticSearch pour fournir des services de journalisation.
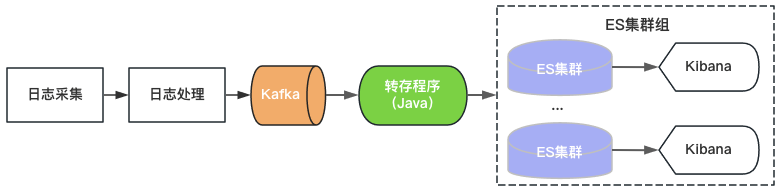 Figure 2 : Architecture de Vénus 1.0
Figure 2 : Architecture de Vénus 1.0
Étant donné qu'il existe des limites supérieures en matière de débit, de capacité de stockage et de nombre de fragments d'index d'un seul cluster ElasticSearch, Venus continue d'ajouter de nouveaux clusters ElasticSearch pour faire face à la demande croissante de journaux. Afin de contrôler les coûts, la charge de chaque ElasticSearch est à un niveau élevé et l'index est configuré avec 0 copie. Des problèmes tels qu'une écriture soudaine du trafic, une requête de données volumineuse ou une panne de machine entraînant une indisponibilité du cluster sont souvent rencontrés. Dans le même temps, en raison du grand nombre d'index sur le cluster, de la grande quantité de données et du long temps de récupération, les journaux sont indisponibles pendant une longue période et l'expérience d'utilisation de Venus devient de plus en plus mauvaise.
04
Venus 2.0 : basé sur ElasticSearch + Hive
Classification des clusters : les clusters ElasticSearch sont divisés en deux catégories : de haute qualité et de mauvaise qualité. Les entreprises clés utilisent des clusters de haute qualité, la charge du cluster est contrôlée à un niveau bas et l'index est activé avec une configuration à 1 copie pour tolérer la défaillance d'un seul nœud. Les entreprises non clés utilisent un cluster de faible qualité, la charge ; est contrôlé à un niveau élevé et l'index utilise toujours une configuration à 0 copie.
Classification du stockage : double écriture d'ElasticSearch et de Hive pour les journaux de stockage long. ElasticSearch enregistre les journaux des 7 derniers jours et Hive enregistre les journaux pendant une période plus longue, ce qui réduit la pression de stockage d'ElasticSearch et réduit également le risque qu'ElasticSearch soit bloqué par des requêtes de données volumineuses. Cependant, comme Hive ne peut pas effectuer de requêtes interactives, les journaux de Hive doivent être interrogés via une plate-forme informatique hors ligne, ce qui entraîne une mauvaise expérience de requête.
Portail de requêtes unifié : fournit un portail visuel unifié de requêtes et d'analyse similaire à Kibana, protégeant le cluster ElasticSearch sous-jacent. Lorsqu'un cluster échoue, les journaux nouvellement écrits sont planifiés sur d'autres clusters sans affecter l'interrogation et l'analyse des nouveaux journaux. Planifiez de manière transparente le trafic entre les clusters lorsque la charge du cluster est déséquilibrée.
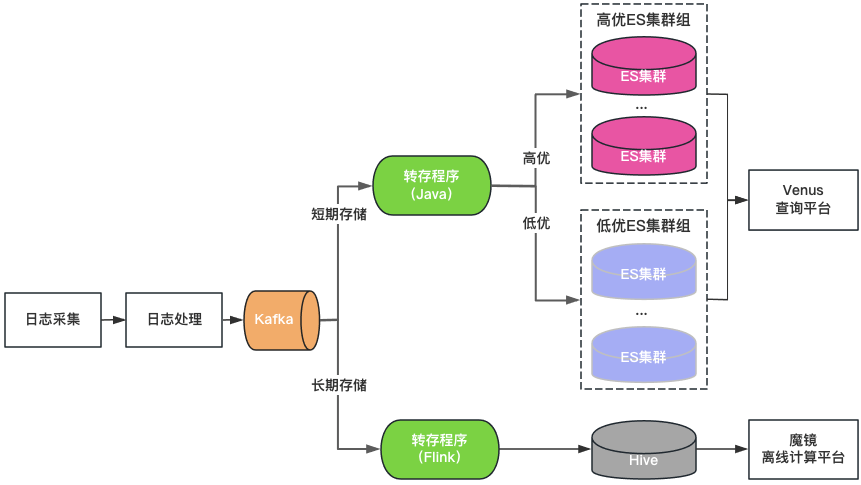
Figure 3 Architecture de Vénus 2.0
Venus 2.0 est une solution de compromis pour protéger les entreprises clés et réduire le risque et l'impact des pannes. Elle présente toujours les problèmes d'un coût élevé et d'une mauvaise stabilité :
ElasticSearch a une durée de stockage courte : en raison de la grande quantité de journaux, ElasticSearch ne peut stocker que 7 jours, ce qui ne peut pas répondre aux besoins quotidiens de l'entreprise.
Il existe de nombreuses entrées et fragmentations des données : plus de 20 clusters ElasticSearch + 1 cluster Hive, il existe de nombreuses entrées de requêtes, ce qui est très gênant pour les requêtes et la gestion.
Coût élevé : bien qu'ElasticSearch ne stocke les journaux que pendant 7 jours, il consomme tout de même plus de 500 machines.
Lecture et écriture intégrées : le serveur ElasticSearch est responsable de la lecture et de l'écriture en même temps, s'affectant mutuellement.
De nombreux défauts : les défauts d'ElasticSearch représentent 80 % du total des défauts de Venus. Une fois les défauts bloqués, les journaux sont facilement perdus et le traitement est difficile.
05
Venus 3.0 : Nouvelle architecture basée sur un lac de données
Vous envisagez d'introduire un lac de données
Après une analyse approfondie du scénario logarithmique de Vénus, nous résumons ses caractéristiques comme suit :
Grande quantité de données : près de 10 000 flux de journaux d'entreprise avec une capacité d'écriture maximale de 10 millions de QPS et un stockage de données au niveau du PB.
Écrivez plus et vérifiez moins : les entreprises n'interrogent généralement les journaux que lorsqu'un dépannage est nécessaire. La plupart des journaux n'ont aucune exigence de requête dans la journée, et le QPS global des requêtes est également extrêmement faible.
Requête interactive : les journaux sont principalement utilisés pour dépanner des scénarios urgents qui nécessitent plusieurs requêtes consécutives et nécessitent une expérience de requête interactive de deuxième niveau.
Concernant les problèmes rencontrés lors de l'utilisation d'ElasticSearch pour stocker et analyser les logs, nous pensons que cela ne correspond pas tout à fait au scénario du log Venus pour les raisons suivantes :
Un seul cluster a un QPS d'écriture et une échelle de stockage limités, plusieurs clusters doivent donc partager le trafic. Des problèmes complexes de stratégie de planification tels que la taille du cluster, le trafic d'écriture, l'espace de stockage et le nombre d'index doivent être pris en compte, ce qui augmente la difficulté de gestion. Étant donné que le trafic des journaux d'entreprise varie considérablement et est imprévisible, afin de résoudre l'impact d'un trafic soudain sur la stabilité du cluster, il est souvent nécessaire de réserver davantage de ressources inutilisées, ce qui entraîne un énorme gaspillage de ressources de cluster.
L'indexation de texte intégral lors de l'écriture consomme beaucoup de CPU, ce qui entraîne une expansion des données et une augmentation significative des coûts de calcul et de stockage. Dans de nombreux scénarios, le stockage des journaux d’analyse nécessite plus de ressources que les ressources du service en arrière-plan. Pour les scénarios tels que les journaux où il y a de nombreuses écritures et peu de requêtes, le précalcul de l'index de texte intégral est plus luxueux.
Les données de stockage et les calculs se trouvent sur la même machine. Les requêtes de gros volumes de données ou l'analyse globale peuvent facilement affecter l'écriture, provoquant des retards d'écriture ou même des pannes de cluster.
为了解决上述问题,我们调研了ClickHouse、Iceberg数据湖等替代方案。其中,Iceberg是爱奇艺内部选择的数据湖技术,是一种存储在HDFS或对象存储之上的表结构,支持分钟级的写入可见性及海量数据的存储。Iceberg对接Trino查询引擎,可以支持秒级的交互式查询,满足日志的查询分析需求。
针对海量日志场景,我们对ElasticSearch、ElasticSearch+Hive、ClickHouse、Iceberg+Trino等方案做了对比评估:
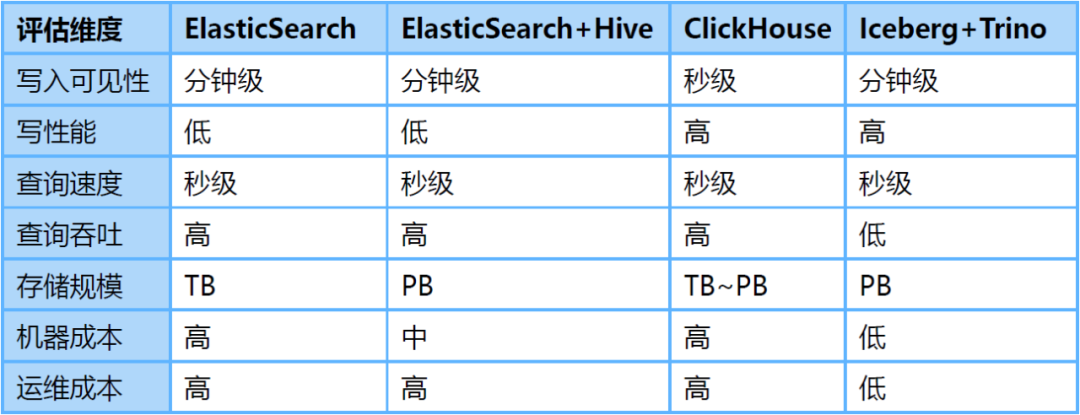
-
存储空间大:Iceberg底层数据存储在大数据统一的存储底座HDFS上,意味着可以使用大数据的超大存储空间,不需要再通过多个集群分担存储,降低了存储的维护代价。 -
存储成本低:日志写入到Iceberg不做全文索引等预处理,同时开启压缩。HDFS开启三副本相比于ElasticSearch的三副本存储空间降低近90%,相比ElasticSearch的单副本存储空间仍然降低30%。同时,日志存储可以与大数据业务共用HDFS空间,进一步降低存储成本。 -
计算成本低:对于日志这种写多查少的场景,相比于ElasticSearch存储前做全文索引等预处理,按查询触发计算更能有效利用算力。 -
存算隔离:Iceberg存储数据,Trino分析数据的存算分离架构天然的解决了查询分析对写入的影响。
基于数据湖架构的建设
通过上述评估,我们基于Iceberg和Trino构建了Venus 3.0。采集到Kafka中的日志由转存程序写入Iceberg数据湖。Venus查询平台通过Trino引擎查询分析数据湖中的日志。架构如图4所示。
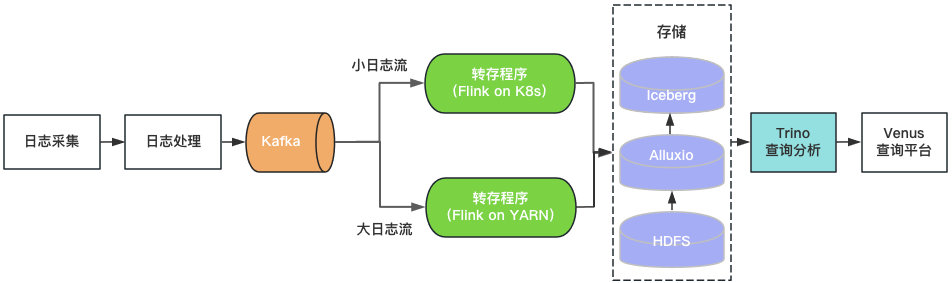 图4 Venus 3.0架构
图4 Venus 3.0架构
-
日志存储
-
查询分析
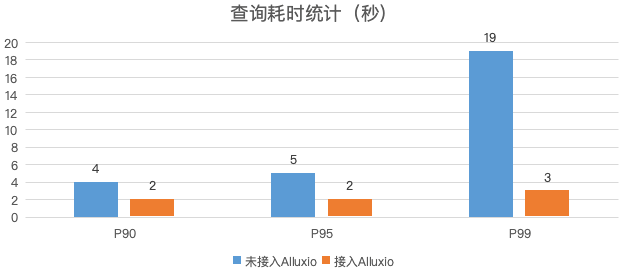
图5 日志查询性能对比
-
转存程序
-
落地效果
-
存储空间 :日志的物理存储空间降低30%,考虑到ElasticSearch集群的磁盘存储空间利用率较低,实际存储空间降低50%以上。 -
计算资源 :Trino使用的CPU核数相比于ElasticSearch减少80%,转存程序资源消耗降低70%。 -
稳定性提升:迁移到数据湖后,故障数降低了85%,大幅节省运维人力。
06
总结与规划
-
Iceberg+Trino的数据湖架构支持的查询并发较低,我们将尝试使用Bloomfilter、Zorder等轻量级索引提升查询性能,提高查询并发,满足更多的实时分析的需求。 -
目前Venus存储了近万个业务日志流,日新增日志超过500TB。计划引入基于数据热度的日志生命周期管理机制,及时下线不再使用的日志,进一步节省资源。 -
如图1所示,Venus同时也承载了大数据分析链路的Pingback用户数据的采集与处理,该链路与日志数据链路比较类似,参考日志入湖经验,我们对Pingback数据的处理环节进行基于数据湖的流批一体化改造。目前已完成一期开发与上线,应用于直播监控、QOS、DWD湖仓等场景,后续将继续推广至更多的湖仓场景。详细技术细节将在后续的数据湖系列文章中介绍。

本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。