

Le paradigme de génération visuelle nouvelle génération « VAR : Visual Auto Regressive » est là ! Le modèle autorégressif de style GPT surpasse pour la première fois le modèle de diffusion dans la génération d'images , et la loi de mise à l'échelle des lois de mise à l'échelle et la capacité de généralisation de la généralisation des tâches Zero-shot similaires au grand modèle de langage sont observées :
论文标题:Modélisation visuelle autorégressive : génération d'images évolutives via une prédiction à l'échelle suivante
Ce nouveau travail appelé VAR a été proposé par des chercheurs de l'Université de Pékin et de ByteDance . Il figurait sur les listes chaudes de GitHub et Paperwithcode et a reçu beaucoup d'attention de la part de ses pairs :
Actuellement, le site Web de l'expérience, les articles, les codes et les modèles ont été publiés :
- Site Web de l'expérience : https://var.vision/
- Lien papier : https://arxiv.org/abs/2404.02905
- Code source ouvert : https://github.com/FoundationVision/VAR
- Modèle open source : https://huggingface.co/FoundationVision/var
Introduction au contexte
Dans le traitement du langage naturel, le modèle autorégressif autorégressif, prenant comme exemples de grands modèles de langage tels que les séries GPT et LLaMa, a obtenu un grand succès. En particulier, la loi de mise à l'échelle de la loi de mise à l'échelle et la généralisabilité des tâches zéro ont une généralisation très impressionnante des tâches zéro. capacités, montrant dans un premier temps le potentiel de conduire à une « intelligence artificielle générale AGI ».
Cependant, dans le domaine de la génération d'images, les modèles autorégressifs sont généralement à la traîne des modèles de diffusion : DALL-E3, Stable Diffusion3, SORA et d'autres modèles populaires récemment appartiennent tous à la famille Diffusion. De plus, on ne sait toujours pas s'il existe une « loi d'échelle » dans le domaine de la génération visuelle , c'est-à-dire si la perte d'entropie croisée de l'ensemble de test peut montrer une tendance à la baisse prévisible de la loi de puissance avec des frais généraux de modèle ou de formation . à explorer.
Les puissantes capacités et la loi d'échelle du modèle autorégressif formel GPT semblent être « verrouillées » dans le domaine de la génération d'images :

Le modèle autorégressif est en retard par rapport à de nombreux modèles de diffusion dans la liste des effets de génération
En se concentrant sur le « déverrouillage » de la capacité des modèles autorégressifs et des lois de mise à l'échelle, l'équipe de recherche est partie de la nature inhérente des modalités d'image, a imité la séquence logique du traitement de l'image humaine et a proposé un nouveau paradigme de génération « visuelle autorégressive » : VAR, Visual AutoRegressive. Modélisation , pour la première fois, la génération visuelle autorégressive de style GPT surpasse la diffusion en termes d'effet, de vitesse et de capacités de mise à l'échelle, et a inauguré des lois de mise à l'échelle dans le domaine de la génération visuelle :

Le cœur de la méthode VAR : imiter la vision humaine et redéfinir la séquence autorégressive de l'image
Lorsque les humains perçoivent des images ou peignent, ils ont tendance à avoir d’abord une vue d’ensemble, puis à approfondir les détails. Ce genre de réflexion du grossier au fin, de la saisie du tout à l'ajustement fin de la partie est très naturel :
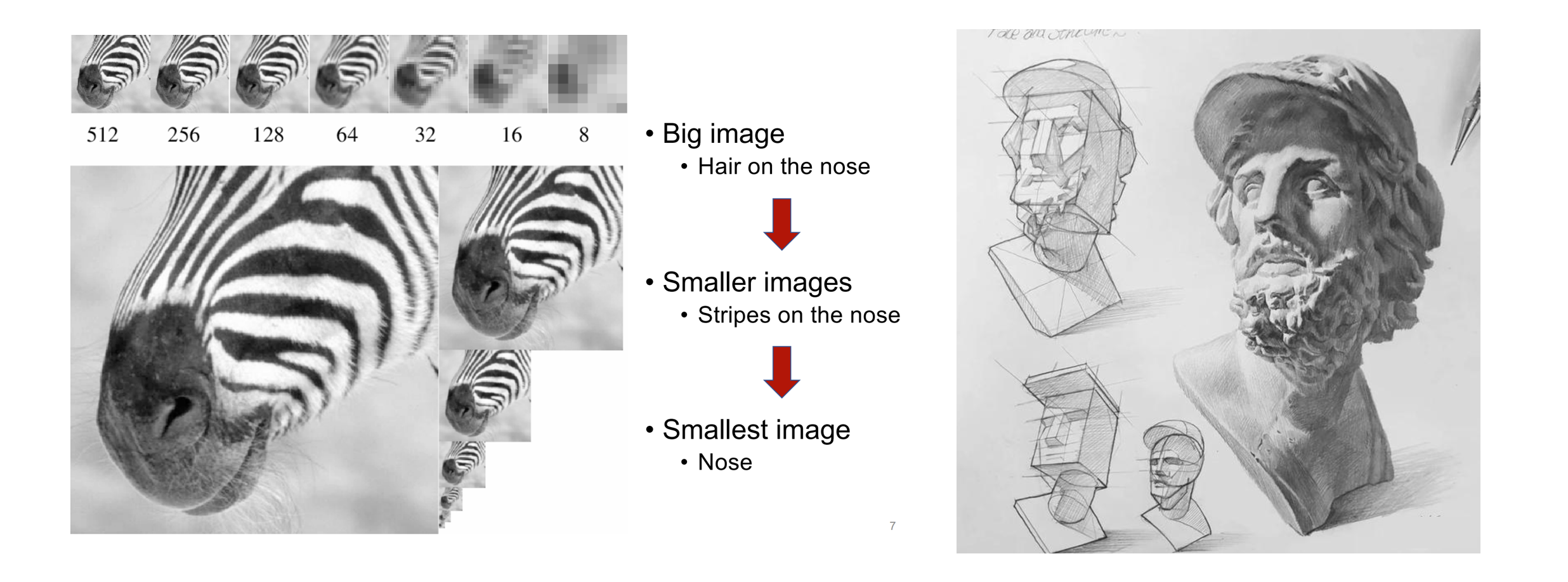
La séquence logique du grossier au fin de la perception humaine des images (à gauche) et de la création de peintures (à droite)
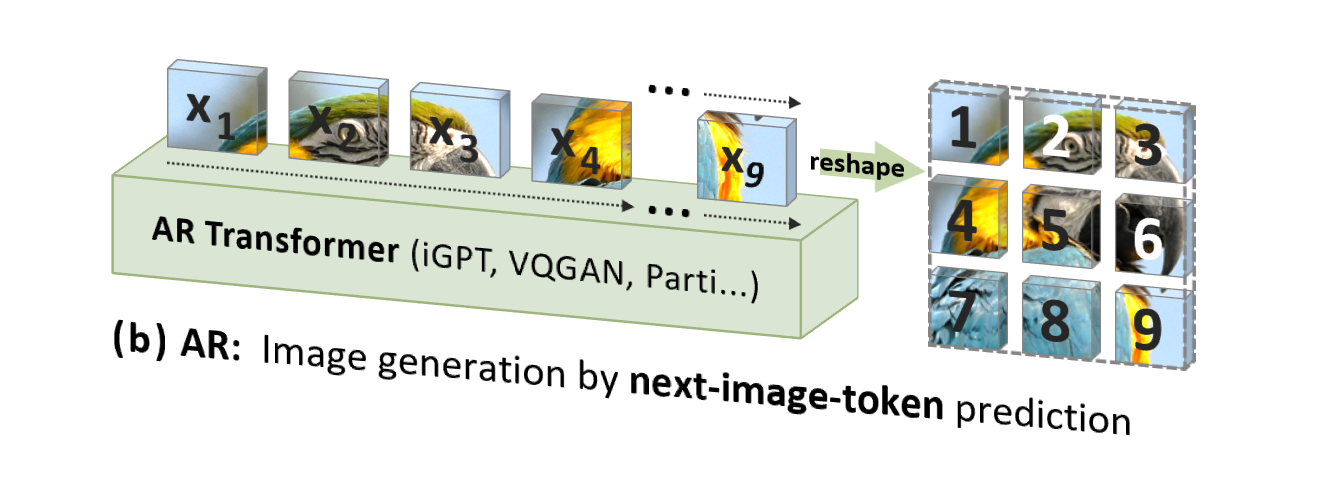
Cependant, l'autorégression d'image (AR) traditionnelle utilise un ordre qui n'est pas conforme à l'intuition humaine (mais adapté au traitement informatique), c'est-à-dire un ordre raster descendant, ligne par ligne, pour prédire les jetons d'image un par un. :
VAR est « orienté vers les personnes », imitant la séquence logique de la perception humaine ou des images créées par l'homme , et génère progressivement une carte symbolique en utilisant une séquence multi-échelles allant du tout aux détails :
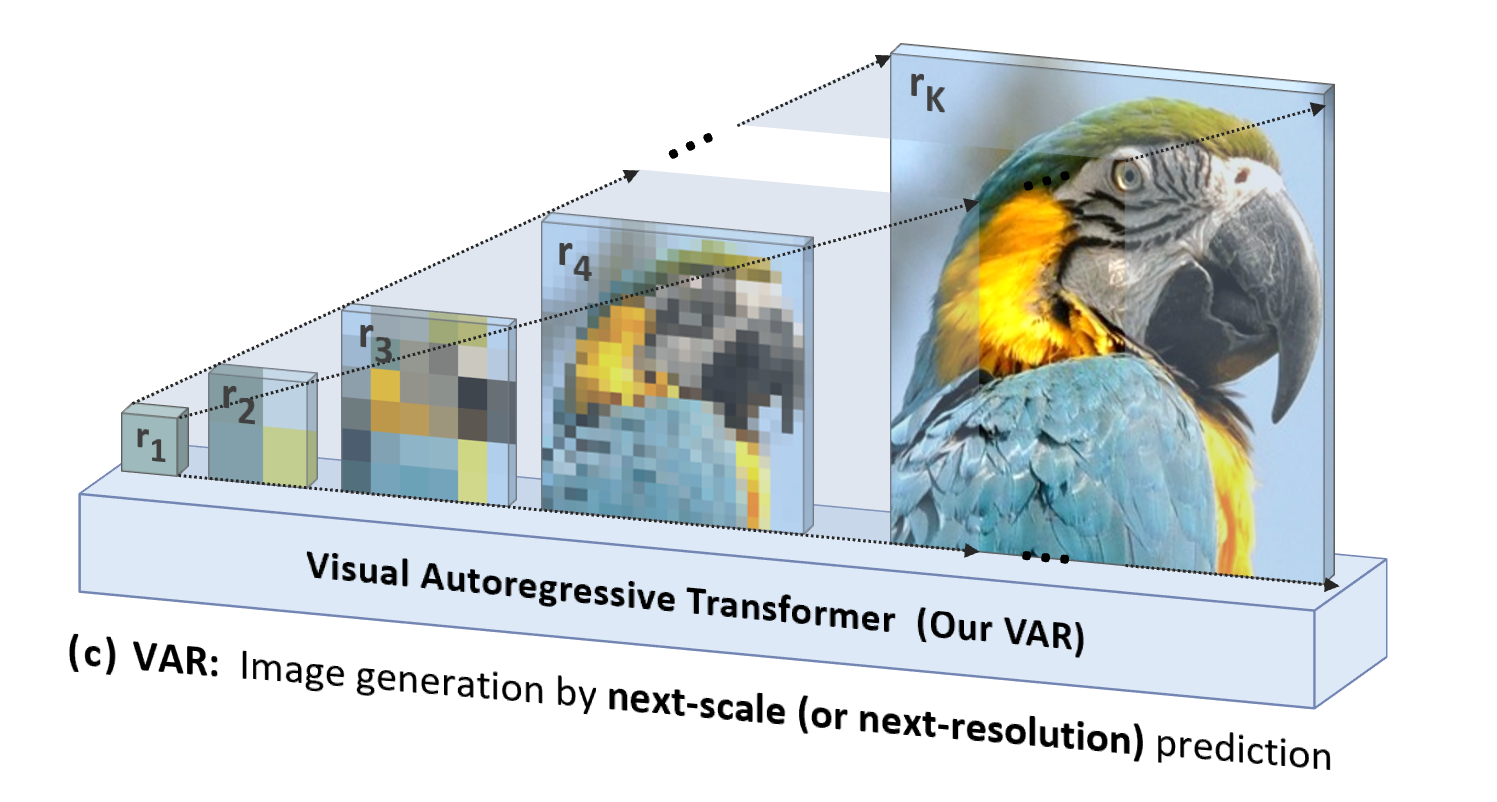
En plus d'être plus naturel et conforme à l'intuition humaine, un autre avantage significatif apporté par VAR est qu'il augmente considérablement la vitesse de génération : à chaque étape d'autorégression (au sein de chaque échelle), tous les jetons d'image sont générés en parallèle en même temps ; échelles C'est autorégressif. Cela rend le VAR des dizaines de fois plus rapide que l'AR traditionnel lorsque les paramètres du modèle et les tailles d'image sont équivalents. De plus, dans l’expérience, l’auteur a également observé que le VAR présente des performances et des capacités de mise à l’échelle supérieures à celles de l’AR.
Détails de la méthode VAR : formation en deux étapes
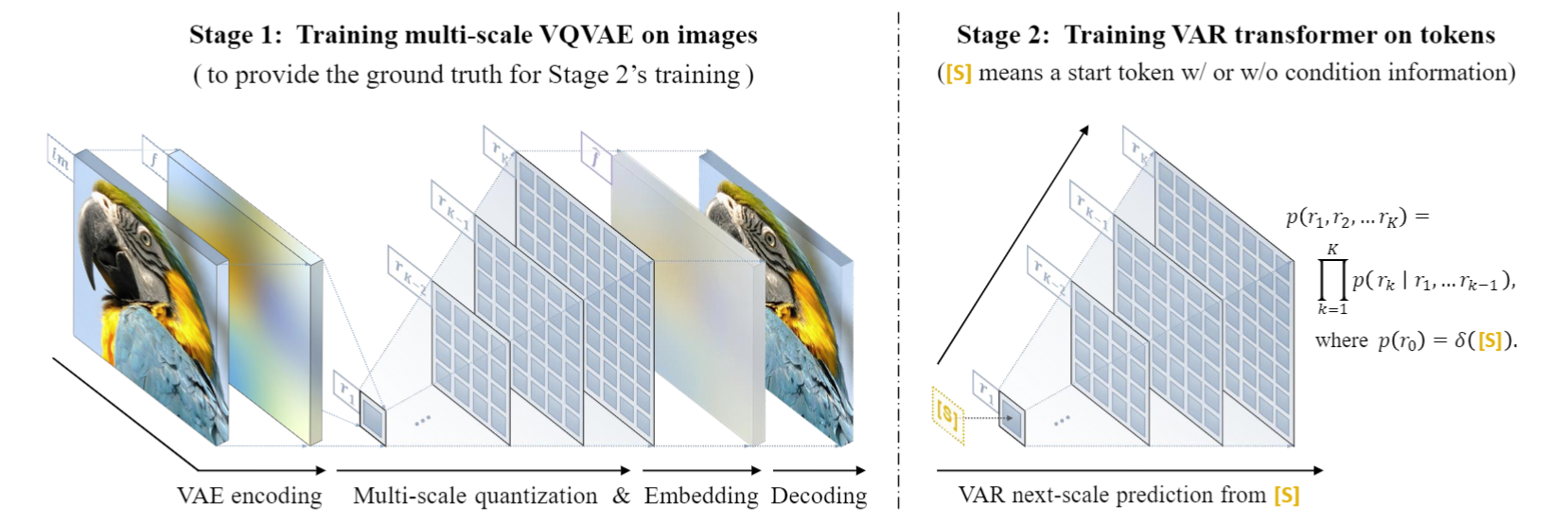
VAR entraîne un auto-encodeur de quantification multi-échelle (VQVAE multi-échelle) dans la première étape, et entraîne un transformateur autorégressif cohérent avec la structure GPT-2 (combiné avec AdaLN) dans la deuxième étape.
Comme le montre l'image de gauche, les détails de la formation préalable à VQVAE sont les suivants :
- Codage discret : L'encodeur convertit l'image en une carte de jetons discrets R=(r1, r2, ..., rk), avec des résolutions de petite à grande
- Continuisation : r1 à rk sont d'abord convertis en cartes de caractéristiques continues à travers la couche d'intégration, puis uniformément interpolées à la résolution maximale correspondant à rk, et additionnées
- Décodage continu : La carte de caractéristiques sommée passe par le décodeur pour obtenir l'image reconstruite, et est entraînée par un mélange de trois pertes : reconstruction + perception + confrontation.
Comme le montre la figure de droite, une fois la formation VQVAE terminée, la deuxième étape de la formation autorégressive Transformer sera effectuée :
- La première étape de l'autorégression consiste à prédire la carte de jeton 1x1 initiale à partir du jeton dieu de départ [S]
- À chaque étape suivante, VAR prédit la prochaine carte de jetons à plus grande échelle sur la base de toutes les cartes de jetons historiques .
- Pendant la phase de formation, VAR utilise une perte d'entropie croisée standard pour superviser la prédiction de probabilité de ces cartes de jetons.
- Au cours de la phase de test, la carte de jetons échantillonnée sera sérialisée, interpolée, additionnée et décodée à l'aide du décodeur VQVAE pour obtenir l'image finale générée.
L'auteur a déclaré que le cadre autorégressif du VAR est tout nouveau et que la technologie spécifique a absorbé les points forts d'une série de technologies classiques telles que le VAE résiduel de RQ-VAE, l'AdaLN de StyleGAN et DiT, ainsi que la formation progressive de PGGAN. VAR repose en fait sur les épaules de géants et se concentre sur l’innovation de l’algorithme autorégressif lui-même.
Comparaison des effets expérimentaux
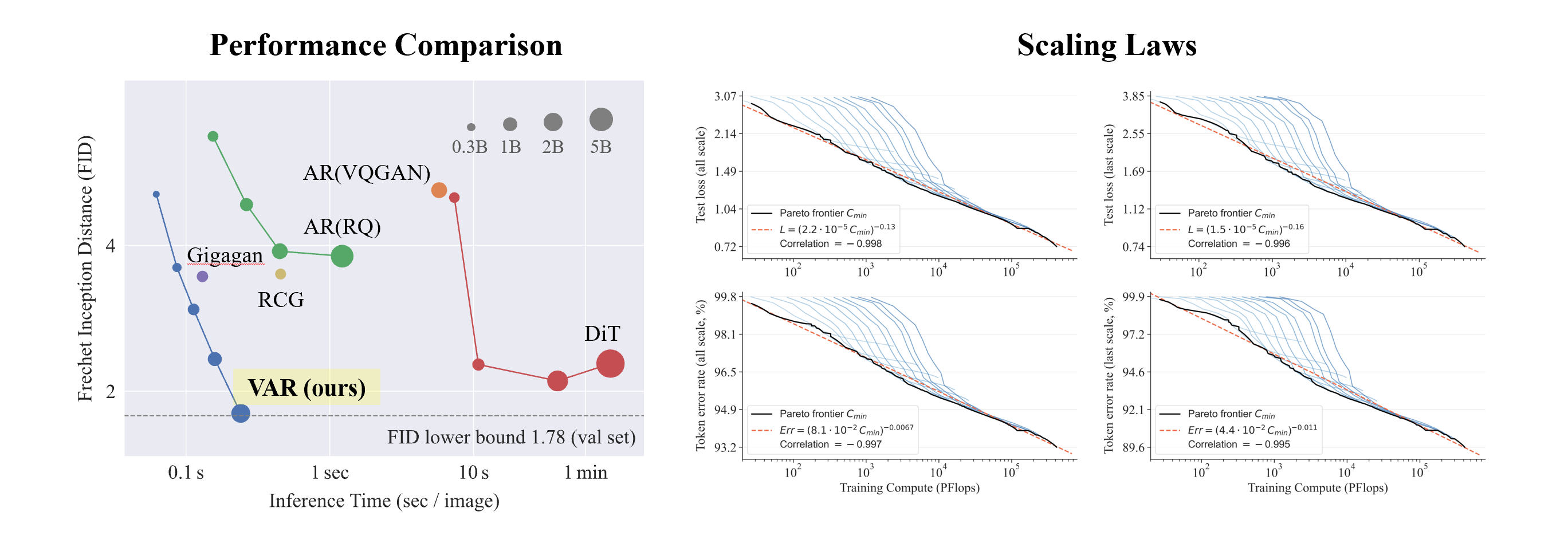
Expériences VAR sur ImageNet conditionnel 256 x 256 et 512 x 512 :
- VAR a considérablement amélioré l'effet de l'AR, faisant en sorte que l'AR ne soit plus en retard par rapport à la diffusion .
- VAR ne nécessite que 10 étapes autorégressives, et sa vitesse de génération dépasse largement AR et Diffusion, et se rapproche même de l'efficacité du GAN.
- En augmentant VAR à 2B/3B , VAR a atteint le niveau SOTA, montrant une nouvelle famille potentielle de modèles génératifs.

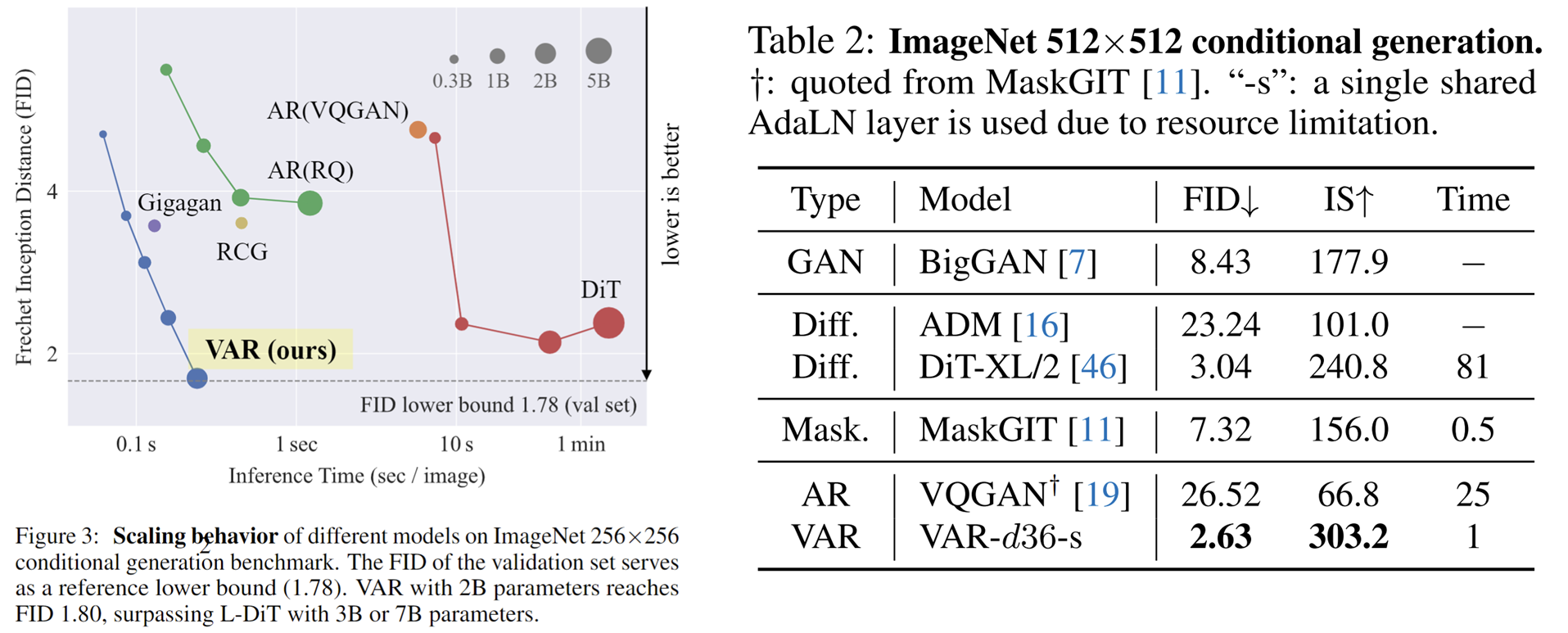
Ce qui est intéressant est que, comparé à SORA et Diffusion Transformer (DiT), le modèle clé de Stable Diffusion 3 , VAR montre :
- Meilleurs résultats : après mise à l'échelle , VAR a finalement atteint FID=1,80, se rapprochant de la limite inférieure théorique du FID de 1,78 (ensemble de validation ImageNet), nettement meilleur que l'optimal 2,10 de DiT.
- Vitesse plus rapide : VAR peut générer une image 256 en moins de 0,3 seconde , ce qui est 45 fois plus rapide que DiT sur 512, c'est 81 fois plus rapide que DiT ;
- Meilleures capacités de mise à l'échelle : comme le montre la figure de gauche, le grand modèle DiT a montré une saturation après avoir atteint 3B et 7B et n'a pas pu se rapprocher de la limite inférieure du FID, tandis que le VAR a été mis à l'échelle à 2 milliards de paramètres, ses performances ont continué à s'améliorer ; a finalement touché la limite inférieure du FID
- Utilisation plus efficace des données : VAR ne nécessite qu'une formation de 350 époques, soit plus que la formation DiT de 1 400 époques.
Ces preuves qu'il est plus efficace, plus rapide et plus évolutif que DiT apportent plus de possibilités à la prochaine génération de chemins d'infrastructure de génération visuelle.
Expérience de loi de mise à l'échelle
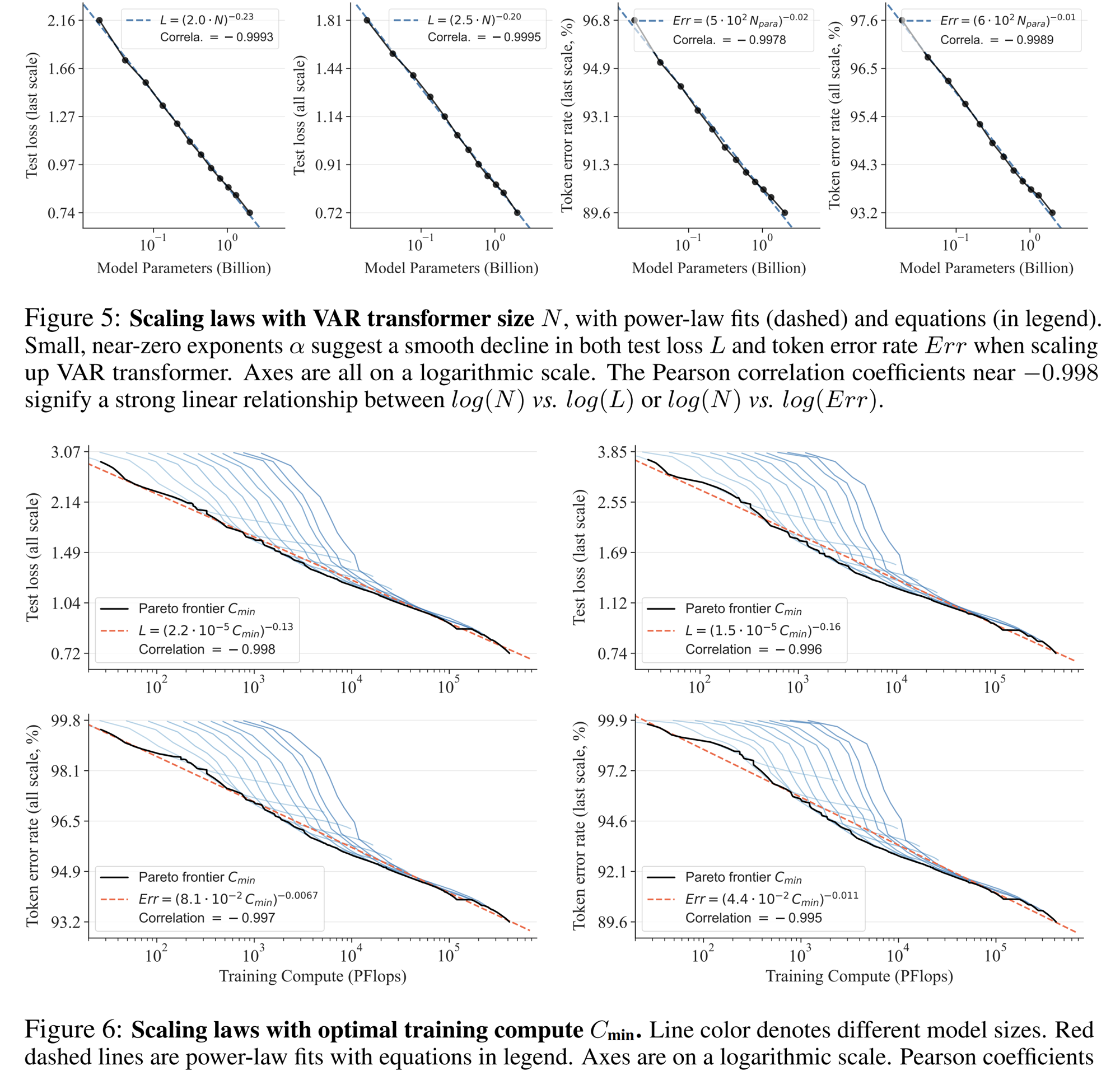
La loi de mise à l'échelle peut être décrite comme le « joyau » des grands modèles de langage. Des recherches pertinentes ont déterminé que dans le processus de mise à l'échelle des modèles de langage autorégressifs à grande échelle, la perte d'entropie croisée L sur l'ensemble de test diminuera de manière prévisible avec le nombre de paramètres du modèle N, le nombre de jetons d'entraînement T et la surcharge de calcul. Cmin . Exposer la relation puissance-loi.
La loi de mise à l'échelle permet non seulement de prédire les performances de grands modèles basés sur de petits modèles, économisant ainsi la charge de calcul et l'allocation des ressources, mais reflète également la puissante capacité d'apprentissage du modèle AR autorégressif. Les performances de l'ensemble de test augmentent avec N, T et. Cmin.
Grâce à des expériences, les chercheurs ont observé que VAR présente une loi de mise à l'échelle de loi de puissance presque identique à celle de LLM : les chercheurs ont formé 12 tailles de modèles, avec un nombre de paramètres de modèle de mise à l'échelle allant de 18 millions à 2 milliards, et la quantité totale de calcul s'étendait sur 6. ordres de grandeur, le nombre total maximum de jetons atteint 305 milliards, et on observe que la perte de l'ensemble de test L ou le taux d'erreur de l'ensemble de test et N, entre L et Cmin montrent une relation de loi de puissance douce, et l'ajustement est bon. :
Au cours du processus de mise à l'échelle des paramètres du modèle et du volume de calcul, la capacité de génération du modèle peut être progressivement améliorée (comme les bandes de l'oscilloscope ci-dessous) :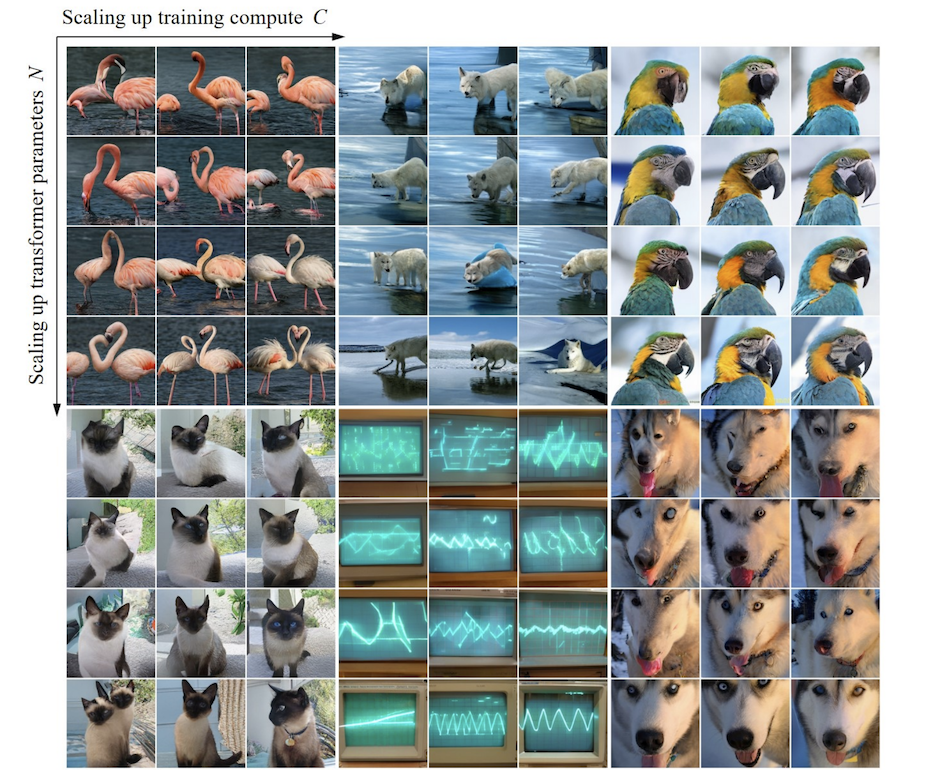
Expérience zéro tir
Grâce à l'excellente propriété du modèle autorégressif selon laquelle il peut utiliser le mécanisme de forçage de l'enseignant pour forcer certains jetons à rester inchangés, VAR présente également certaines capacités de généralisation de tâches à échantillon nul. Le transformateur VAR formé sur la tâche de génération conditionnelle peut se généraliser à certaines tâches génératives sans aucun réglage fin, telles que la complétion d'image (inpainting), l'extrapolation d'image (outpainting) et l'édition d'image (édition de condition de classe). ), et obtenu certains résultats :
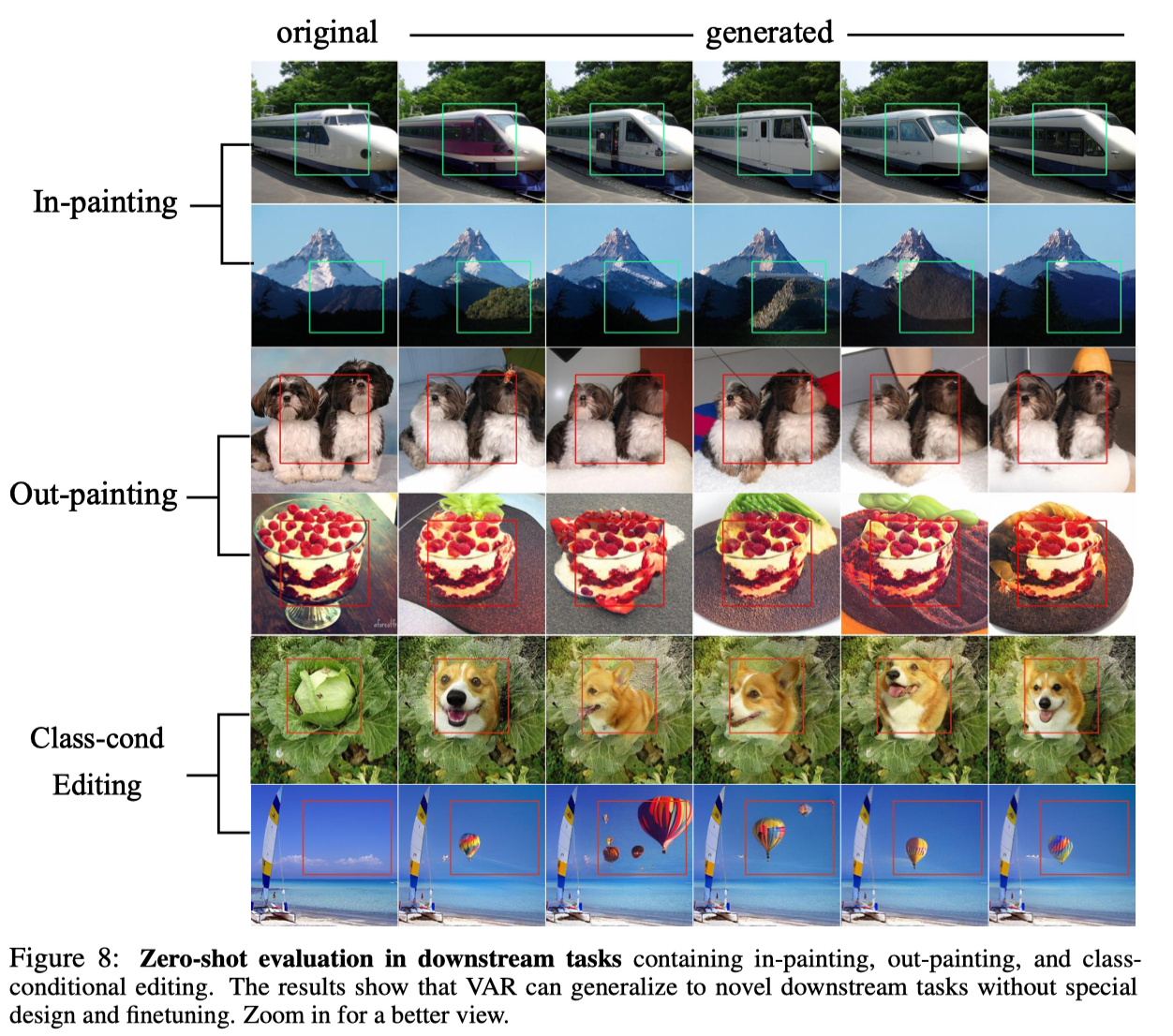
en conclusion
VAR offre une nouvelle perspective sur la façon de définir la séquence autorégressive d'images, c'est-à-dire la séquence du plus grossier au plus fin, des contours globaux au réglage fin local . Bien que cohérent avec l'intuition, un tel algorithme autorégressif apporte de bons résultats : VAR améliore considérablement la vitesse et la qualité de génération du modèle autorégressif, permettant au modèle autorégressif de surpasser le modèle de diffusion pour la première fois à bien des égards . Dans le même temps, VAR présente des lois de mise à l'échelle et une généralisabilité Zero-shot similaires à celles du LLM. Les auteurs espèrent que les idées, les conclusions expérimentales et l'open source de VAR pourront contribuer à l'exploration par la communauté de l'utilisation du paradigme autorégressif dans le domaine de la génération d'images et promouvoir le développement d'algorithmes multimodaux unifiés basés sur l'autorégression à l'avenir.
À propos de l'équipe Bytedance Commercialisation-GenAI
L'équipe ByteDance Commercialization-GenAI se concentre sur le développement d'une technologie avancée d'intelligence artificielle générative et sur la création de solutions techniques de pointe, notamment du texte, des images et des vidéos. En utilisant l'IA générative pour réaliser un flux de travail créatif automatisé, elle offre aux annonceurs et aux créateurs une efficacité et un dynamisme créatifs améliorés. valeur.
D'autres postes dans les directions de génération visuelle et LLM de l'équipe sont ouverts. Bienvenue pour prêter attention aux informations de recrutement de ByteDance.
Un camarade de poulet "open source" deepin-IDE et a finalement réalisé l'amorçage ! Bon gars, Tencent a vraiment transformé Switch en une « machine d'apprentissage pensante » Examen des échecs de Tencent Cloud le 8 avril et explication de la situation Reconstruction du démarrage du bureau à distance RustDesk Client Web La base de données de terminal open source de WeChat basée sur SQLite WCDB a inauguré une mise à niveau majeure Liste d'avril TIOBE : PHP est tombé à un plus bas historique, Fabrice Bellard, le père de FFmpeg, a sorti l'outil de compression audio TSAC , Google a sorti un gros modèle de code, CodeGemma , est-ce que ça va vous tuer ? C'est tellement bon qu'il est open source - outil d'édition d'images et d'affiches open source