Annuaire d'articles

Réflexions déclenchées par la question de l'entretien « Redis est-il monothread ? »
Auteur : Li Le
Source : IT Reading Ranking
De nombreuses personnes ont été confrontées à une telle question d'entretien : Redis est-il monothread ou multithread ? Cette question est à la fois simple et complexe. On dit que c'est simple parce que la plupart des gens savent que Redis est monothread, et on dit que c'est complexe parce que la réponse est en réalité inexacte.
Redis n'est-il pas monothread ? Nous démarrons une instance Redis et la vérifions. La méthode d'installation et de déploiement de Redis est la suivante :
// 下载
wget https://download.redis.io/redis-stable.tar.gz
tar -xzvf redis-stable.tar.gz
// 编译安装
cd redis-stable
make
// 验证是否安装成功
./src/redis-server -v
Redis server v=7.2.4
Ensuite, démarrez l'instance Redis et utilisez la commande ps pour afficher tous les threads, comme indiqué ci-dessous :
// 启动Redis实例
./src/redis-server ./redis.conf
// 查看实例进程ID
ps aux | grep redis
root 385806 0.0 0.0 245472 11200 pts/2 Sl+ 17:32 0:00 ./src/redis-server 127.0.0.1:6379
// 查看所有线程
ps -L -p 385806
PID LWP TTY TIME CMD
385806 385806 pts/2 00:00:00 redis-server
385806 385809 pts/2 00:00:00 bio_close_file
385806 385810 pts/2 00:00:00 bio_aof
385806 385811 pts/2 00:00:00 bio_lazy_free
385806 385812 pts/2 00:00:00 jemalloc_bg_thd
385806 385813 pts/2 00:00:00 jemalloc_bg_thd
Il y a en fait 6 sujets ! N'est-il pas dit que Redis est monothread ? Pourquoi y a-t-il autant de sujets ?
Vous ne comprenez peut-être pas la signification de ces six threads, mais cet exemple montre au moins que Redis n'est pas monothread.
01 Multithreading dans Redis
Ensuite, nous introduisons les fonctions des 6 threads ci-dessus une par une :
1)redis-server:
Le thread principal est utilisé pour recevoir et traiter les demandes des clients.
2)jemalloc_bg_thd
jemalloc est une nouvelle génération d'allocateur de mémoire, utilisé par la couche inférieure de Redis pour gérer la mémoire.
3)bio_xxx:
Ceux commençant par le préfixe bio sont tous des threads asynchrones, utilisés pour effectuer certaines tâches chronophages de manière asynchrone. Parmi eux, le thread bio_close_file est utilisé pour supprimer des fichiers de manière asynchrone, le thread bio_aof est utilisé pour vider de manière asynchrone les fichiers AOF sur le disque et le thread bio_lazy_free est utilisé pour supprimer des données de manière asynchrone (suppression paresseuse).
Il convient de noter que le thread principal distribue les tâches aux threads asynchrones via la file d'attente et que cette opération nécessite un verrouillage. La relation entre le thread principal et le thread asynchrone est la suivante :
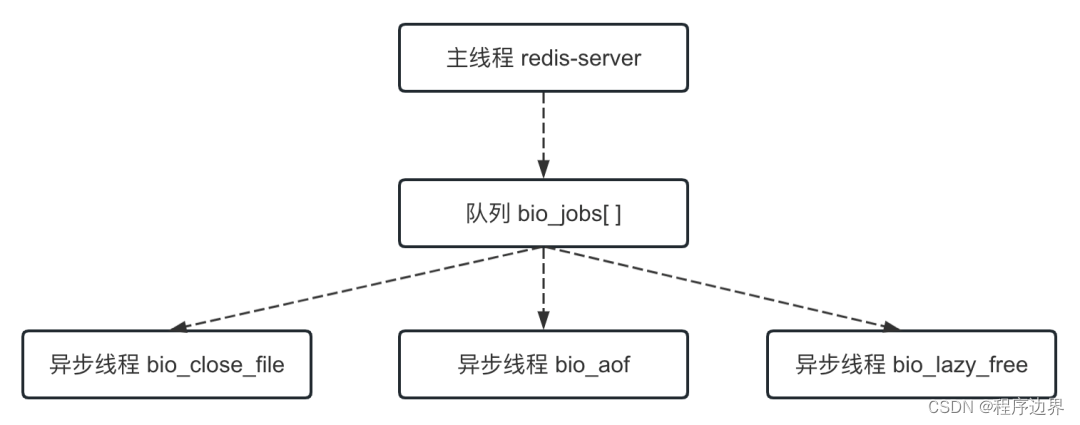
Thread principal et thread asynchrone Thread principal et thread asynchroneThread principal et thread asynchrone
Nous prenons ici la suppression différée comme exemple pour expliquer pourquoi le thread asynchrone doit être utilisé. Redis est une base de données en mémoire qui prend en charge plusieurs types de données, notamment les chaînes, les listes, les tables de hachage, les ensembles, etc. Pensez-y, quel est le processus de suppression des données de type liste (DEL) ? La première étape consiste à supprimer la paire clé-valeur du dictionnaire de base de données, et la deuxième étape consiste à parcourir et supprimer tous les éléments de la liste (libérant de la mémoire). Pensez-vous que se passerait-il si le nombre d'éléments dans la liste était très grand ? Cette étape prendra beaucoup de temps. Cette méthode de suppression est appelée suppression synchrone et le processus est illustré dans la figure ci-dessous :
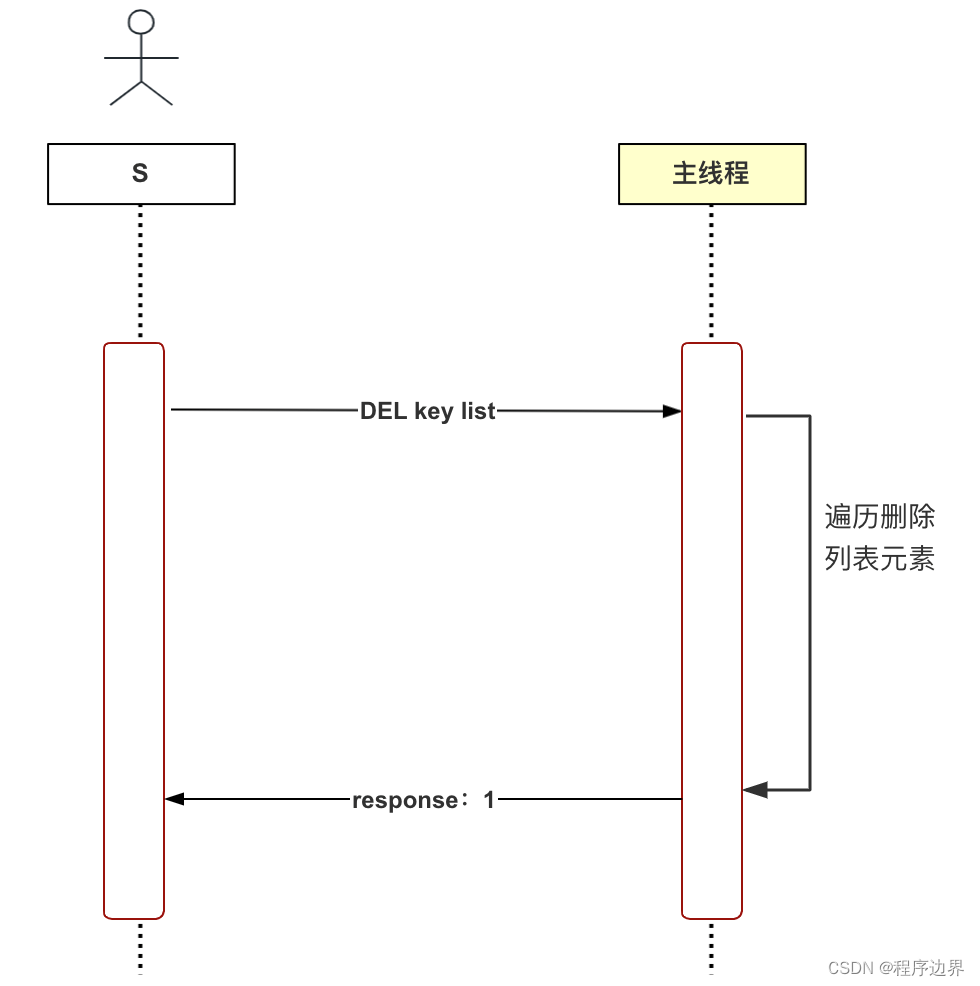
Organigramme de suppression synchrone Organigramme de suppression synchroneOrganigramme de suppression synchrone
En réponse aux problèmes ci-dessus, Redis a proposé une suppression paresseuse (suppression asynchrone). Lorsque le thread principal reçoit la commande de suppression (UNLINK), il supprime d'abord la paire clé-valeur du dictionnaire de base de données, puis distribue la suppression tâche au thread asynchrone. bio_lazy_free, la deuxième étape de la logique chronophage est exécutée par le thread asynchrone. Le processus à ce stade est illustré ci-dessous :
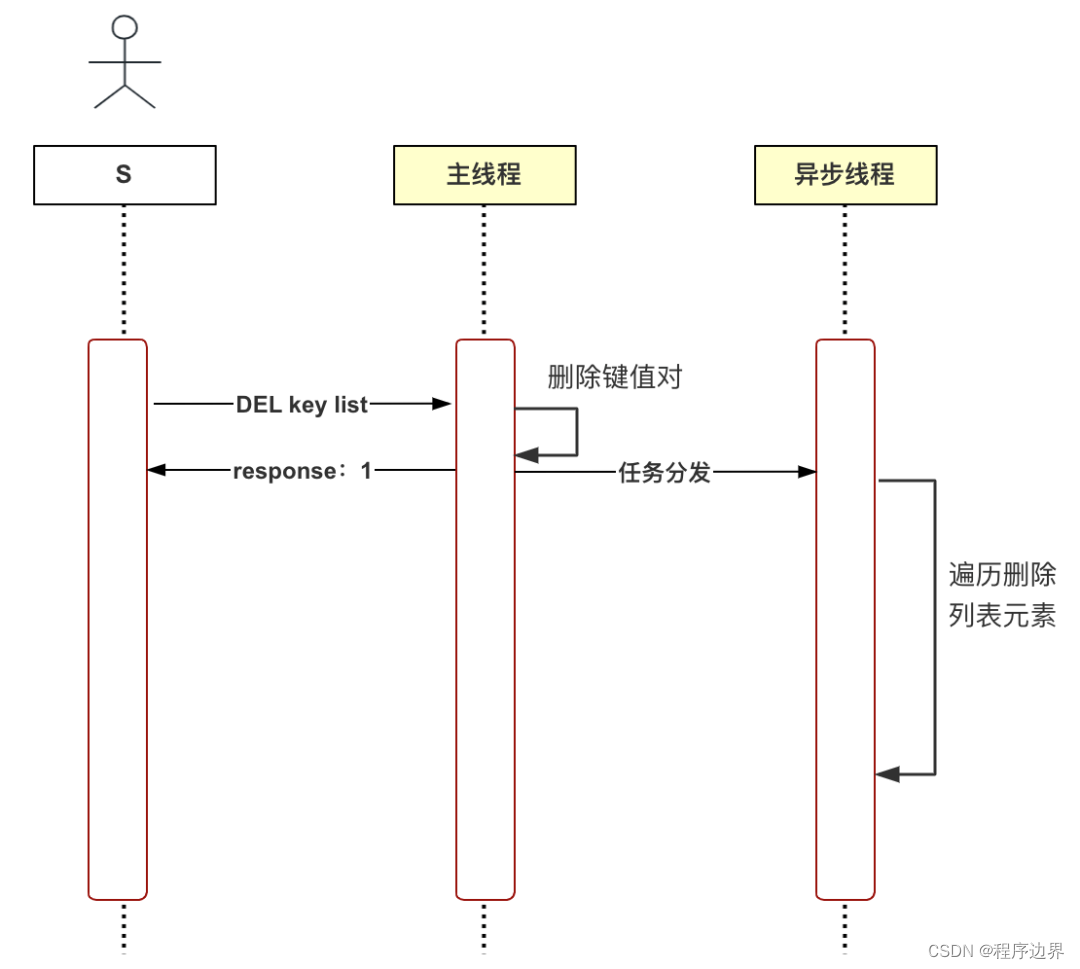
Organigramme de suppression différée Organigramme de suppression différéeOrganigramme de suppression différée
02 Multithread E/S
Redis est-il multithread ? Alors pourquoi disons-nous toujours que Redis est monothread ? En effet, la lecture des demandes de commandes client, l'exécution de commandes et le renvoi des résultats au client sont tous effectués dans le thread principal. Sinon, si plusieurs threads exploitent la base de données en mémoire en même temps, comment résoudre le problème de concurrence ? Si un verrou est verrouillé avant chaque opération, quelle est la différence entre celui-ci et un seul thread ?
Bien sûr, ce processus a également changé dans la version Redis 6.0. Les responsables de Redis ont souligné que Redis est une base de données clé-valeur basée sur la mémoire. Le processus d'exécution des commandes est très rapide. Il lit la demande de commande du client et renvoie les résultats à le client (c'est-à-dire les E/S réseau) devient généralement le goulot d'étranglement des performances de Redis.
Par conséquent, dans la version Redis 6.0, l'auteur a ajouté la capacité d'E/S multithread, c'est-à-dire que plusieurs threads d'E/S peuvent être ouverts, les demandes de commande client peuvent être lues en parallèle et les résultats peuvent être renvoyés au client. en parallèle. La capacité multithread d’E/S double au moins les performances de Redis.
Afin d'activer la fonctionnalité d'E/S multithread, vous devez d'abord modifier le fichier de configuration redis.conf :
io-threads-do-reads yes
io-threads 4
Les significations de ces deux configurations sont les suivantes :
-
io-threads-do-reads : s'il faut activer la fonctionnalité d'E/S multithread, la valeur par défaut est "non" ;
-
io-threads : nombre de threads d'E/S, la valeur par défaut est 1, c'est-à-dire que seul le thread principal est utilisé pour effectuer les E/S réseau et le nombre maximum de threads est de 128 ; cette configuration doit être définie en fonction des nombre de cœurs de processeur. L'auteur recommande de définir 2 à 3 pour un processeur à 4 cœurs de threads d'E/S, un processeur à 8 cœurs définit 6 threads d'E/S.
Après avoir activé la fonctionnalité d'E/S multithread, redémarrez l'instance Redis et affichez tous les threads. Les résultats sont les suivants :
ps -L -p 104648
PID LWP TTY TIME CMD
104648 104648 pts/1 00:00:00 redis-server
104648 104654 pts/1 00:00:00 io_thd_1
104648 104655 pts/1 00:00:00 io_thd_2
104648 104656 pts/1 00:00:00 io_thd_3
……
Puisque nous définissons les io-threads à 4, 4 threads seront créés pour effectuer les opérations d'E/S (y compris le thread principal). Les résultats ci-dessus sont conformes aux attentes.
Bien entendu, seule la phase d'E/S utilise le multithreading et le traitement des demandes de commandes est toujours monothread.Après tout, il existe des problèmes de concurrence dans les opérations multithreads sur les données en mémoire.
Enfin, une fois le multithreading d'E/S activé, le flux d'exécution de la commande est le suivant :
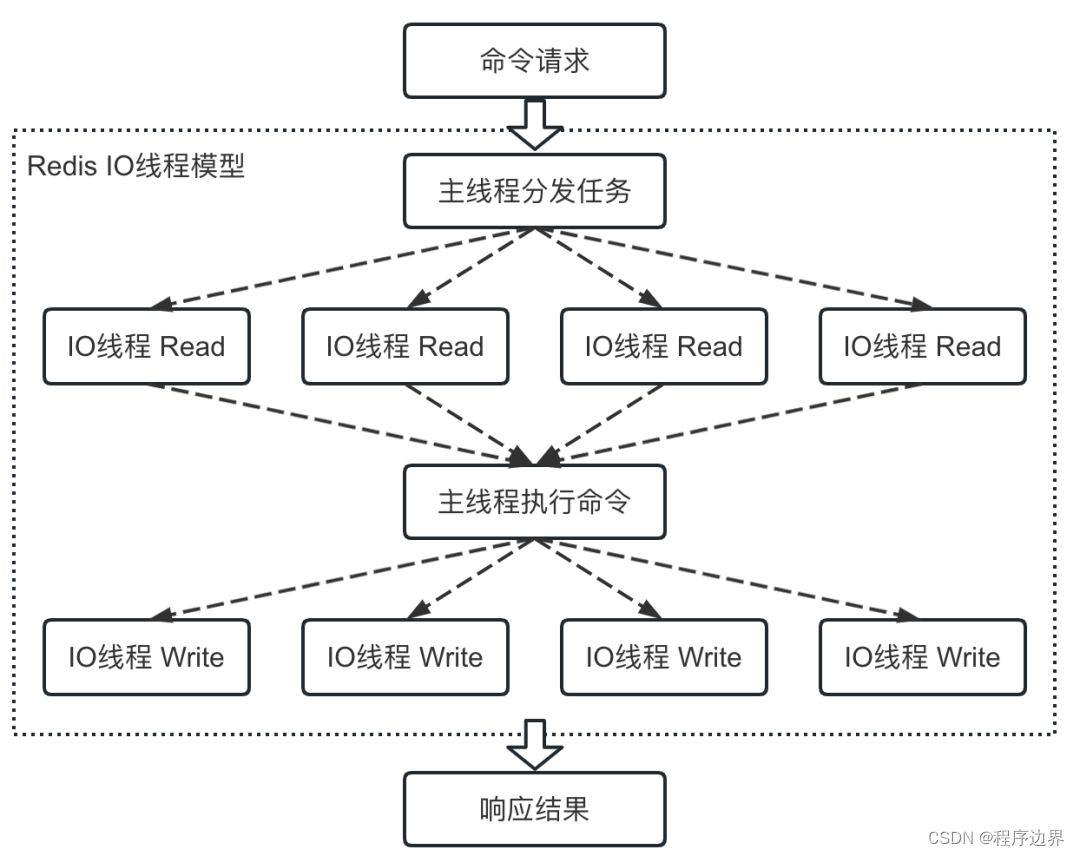
Organigramme multithread d'E/S Organigramme multithread d'E/SOrganigramme multithread d'E / S
03 Multi-processus dans Redis
Redis a-t-il plusieurs processus ? Oui. Dans certains scénarios, Redis créera également plusieurs sous-processus pour effectuer certaines tâches. En prenant la persistance comme exemple, Redis prend en charge deux types de persistance :
-
AOF (Append Only File) : il peut être considéré comme un fichier journal de commandes. Redis ajoutera chaque commande d'écriture au fichier AOF.
-
RDB (Redis Database) : stocke les données dans la mémoire Redis sous forme d'instantanés. La commande SAVE permet de déclencher manuellement la persistance RDB. Pensez-y si la quantité de données dans Redis est très importante, l'opération de persistance doit prendre beaucoup de temps et Redis traite les demandes de commande dans un seul thread, donc lorsque le temps d'exécution de la commande SAVE est trop long, cela affectera inévitablement l'exécution d'autres commandes.
La commande SAVE peut bloquer d'autres requêtes. Pour cette raison, Redis a introduit la commande BGSAVE, qui créera un sous-processus pour effectuer des opérations de persistance, afin que cela n'empêche pas le processus principal d'exécuter d'autres requêtes.
Nous pouvons exécuter manuellement la commande BGSAVE pour vérifier. Tout d'abord, utilisez GDB pour suivre le processus Redis, ajouter des points d'arrêt et laisser le processus enfant se bloquer dans la logique de persistance. Comme suit:
// 查询Redis进程ID
ps aux | grep redis
root 448144 0.1 0.0 270060 11520 pts/1 tl+ 17:00 0:00 ./src/redis-server 127.0.0.1:6379
// GDB跟踪进程
gdb -p 448144
// 跟踪创建的子进程(默认GDB只跟踪主进程,需手动设置)
(gdb) set follow-fork-mode child
// 函数rdbSaveDb用于持久化数据快照
(gdb) b rdbSaveDb
Breakpoint 1 at 0x541a10: file rdb.c, line 1300.
(gdb) c
Après avoir défini le point d'arrêt, utilisez le client Redis pour envoyer la commande BGSAVE. Les résultats sont les suivants :
// 请求立即返回
127.0.0.1:6379> bgsave
Background saving started
// GDB输出以下信息
[New process 452541]
Breakpoint 1, rdbSaveDb (...) at rdb.c:1300
Comme vous pouvez le voir, GDB suit actuellement le processus enfant et l'ID du processus est 452541. Vous pouvez également visualiser tous les processus via la commande Linux ps. Les résultats sont les suivants :
ps aux | grep redis
root 448144 0.0 0.0 270060 11520 pts/1 Sl+ 17:00 0:00 ./src/redis-server 127.0.0.1:6379
root 452541 0.0 0.0 270064 11412 pts/1 t+ 17:19 0:00 redis-rdb-bgsave 127.0.0.1:6379
Vous pouvez voir que le nom du processus enfant est redis-rdb-bgsave, ce qui signifie que ce processus conserve des instantanés de toutes les données dans les fichiers RDB.
Enfin, considérons deux questions.
- Question 1 : Pourquoi utiliser un sous-processus au lieu d'un sous-thread ?
Étant donné que RDB stocke des instantanés de données de manière persistante, si des sous-threads sont utilisés, le thread principal et les sous-threads partageront les données de mémoire. Le thread principal modifiera également les données de mémoire tout en persistant, ce qui peut entraîner une incohérence des données. Les données mémoire du processus principal et du processus enfant sont complètement isolées, et ce problème n'existe pas.
- Question 2 : Supposons que 10 Go de données soient stockées dans la mémoire Redis. Après avoir créé un processus enfant pour effectuer des opérations de persistance, le processus enfant a-t-il également besoin de 10 Go de mémoire à ce moment-là ? Copier 10 Go de données de mémoire prendra beaucoup de temps, n'est-ce pas ? De plus, si le système ne dispose que de 15 Go de mémoire, la commande BGSAVE peut-elle quand même être exécutée ?
Il existe ici un concept appelé copie lors de l'écriture.Après avoir utilisé l'appel système fork pour créer un processus enfant, les données mémoire du processus principal et du processus enfant sont temporairement partagées, mais lorsque le processus principal doit modifier les données mémoire, le Le système fera automatiquement une copie de ce bloc de mémoire pour obtenir l'isolation des données de mémoire.
Le flux d'exécution de la commande BGSAVE est illustré dans la figure ci-dessous :
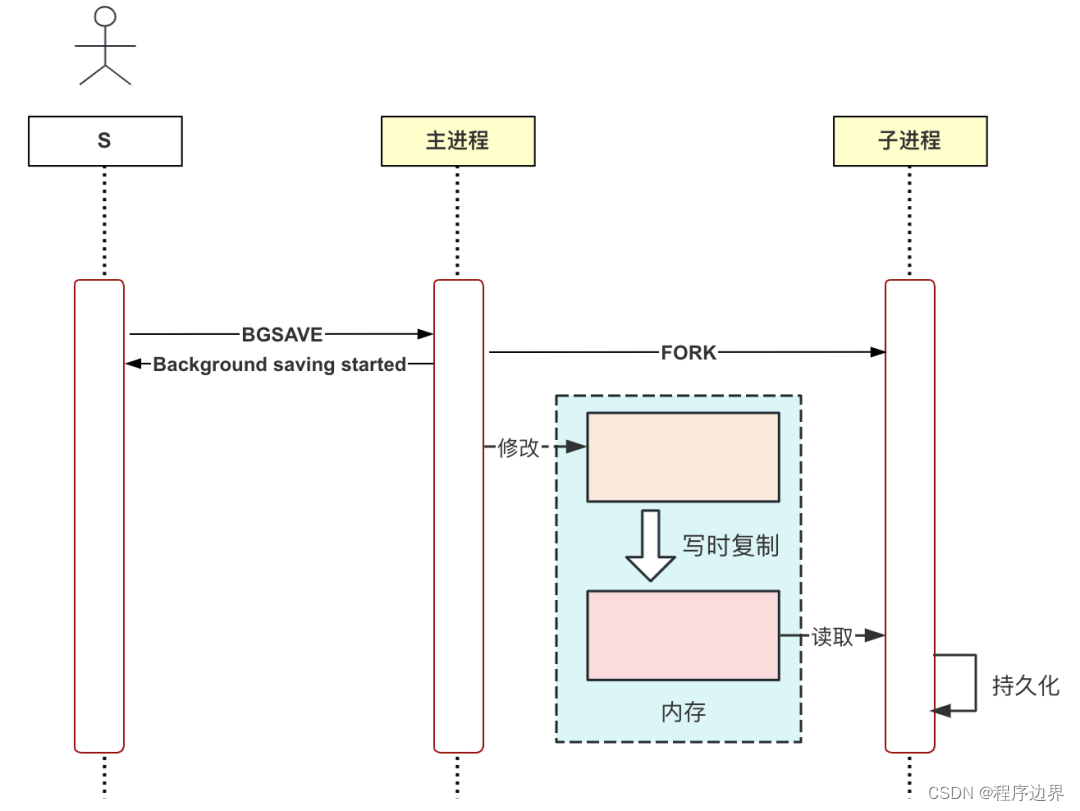
Processus d'exécution BGSAVE Processus d'exécution BGSAVEProcessus d’exécution du BGS A V E
04 Conclusion
Le modèle de processus/modèle de thread de Redis est encore relativement complexe. Ici, nous n'introduisons que brièvement le multi-threading et le multi-traitement dans certains scénarios. Le multi-threading et le multi-traitement dans d'autres scénarios n'ont pas encore été étudiés par les lecteurs eux-mêmes.
À propos de l'auteur
Li Le : expert en développement Golang chez TAL et titulaire d'une maîtrise de l'Université des sciences et technologies électroniques de Xi'an. Il a déjà travaillé pour Didi. Il est prêt à se plonger dans la technologie et le code source. Il est le co-auteur de "Utiliser Redis efficacement : découvrez le stockage de données et les clusters à haute disponibilité dans un seul livre" et "Redis5" Conception et analyse du code source " " Conception sous-jacente à Nginx et analyse du code source ".
▼Lecture approfondie

"Utiliser efficacement Redis : découvrez le stockage de données et les clusters haute disponibilité dans un seul livre" "Utiliser efficacement Redis : découvrez le stockage de données et les clusters haute disponibilité dans un seul livre""Utiliser Redis efficacement : découvrez le stockage de données et les clusters haute disponibilité dans un seul livre "
Mots recommandés : approfondissez la structure des données Redis et la mise en œuvre sous-jacente, et surmontez les problèmes de stockage des données Redis et de gestion des clusters.