Dies ist ein Problem, auf das ein Klassenkamerad bei der Teilnahme an Dewu Java in diesem Herbst gestoßen ist. Das vollständige Interview lautet wie folgt:

Diese Frage wird in Interviews relativ leicht gestellt, insbesondere wenn Wissenspunkte im Zusammenhang mit der Redis-Leistungsoptimierung untersucht werden.
Normalerweise werden Sie nach der Frage nach Bigkey (Big Key) weiterhin nach Hotkey (Hotkey) fragen. Auch wenn Sie sich nicht auf ein Vorstellungsgespräch vorbereiten, empfiehlt es sich, einen Blick darauf zu werfen. Es kann auch in der tatsächlichen Entwicklung verwendet werden.
Hotkey-bezogene Inhalte werden im nächsten Artikel abgefragt und auch in das Interviewfragenalbum „Detaillierte Erläuterungen zu häufigen Java-Interviewfragen“ aufgenommen.
Was ist Bigkey?
Einfach ausgedrückt: Wenn der Speicher, der durch den einem Schlüssel entsprechenden Wert belegt wird, relativ groß ist, kann der Schlüssel als Bigkey betrachtet werden. Wie groß gilt genau als groß? Es gibt einen Referenzstandard, der nicht besonders präzise ist:
- Der Wert des Zeichenfolgentyps überschreitet 1 MB
- Der Wert eines zusammengesetzten Typs (Liste, Hash, Set, sortierter Satz usw.) enthält mehr als 5000 Elemente (bei einem Wert eines zusammengesetzten Typs gilt jedoch: Je mehr Elemente er enthält, desto mehr Speicher nimmt er ein).

große Beurteilungskriterien
Wie ist bigkey entstanden? Was ist der Schaden?
Bigkey wird normalerweise aus folgenden Gründen generiert:
- Unsachgemäßes Programmdesign, z. B. die direkte Verwendung des String-Typs zum Speichern von Binärdaten, die größeren Dateien entsprechen.
- Der Umfang der Geschäftsdaten wird nicht sorgfältig berücksichtigt. Beispielsweise wird bei der Verwendung von Sammlungstypen das schnelle Wachstum des Datenvolumens nicht berücksichtigt.
- Junk-Daten werden nicht rechtzeitig bereinigt, beispielsweise eine große Anzahl redundanter, nutzloser Schlüssel-Wert-Paare im Hash.
Bigkey verbraucht nicht nur mehr Speicherplatz und Bandbreite, sondern hat auch einen relativ großen Einfluss auf die Leistung.
Im Artikel Zusammenfassung häufiger Blockierungsursachen in Redis [1] haben wir erwähnt, dass große Schlüssel auch Blockierungsprobleme verursachen können. Konkret spiegelt es sich vor allem in den folgenden drei Aspekten wider:
- Client-Timeout-Blockierung: Da Redis Befehle in einem einzelnen Thread ausführt und die Bedienung großer Schlüssel mehr Zeit in Anspruch nimmt, wird Redis blockiert. Aus Sicht des Clients erfolgt für längere Zeit keine Antwort.
- Netzwerkblockierung: Jedes Mal, wenn ein großer Schlüssel abgerufen wird, ist der generierte Netzwerkverkehr groß. Wenn die Größe eines Schlüssels 1 MB beträgt und die Anzahl der Besuche pro Sekunde 1.000 beträgt, werden 1.000 MB Datenverkehr pro Sekunde generiert. Das ist Für einen Server mit einer gewöhnlichen Gigabit-Netzwerkkarte ist es katastrophal.
- Blockierung des Arbeitsthreads: Wenn Sie mit del einen großen Schlüssel löschen, wird der Arbeitsthread blockiert, sodass nachfolgende Befehle nicht verarbeitet werden können.
Das durch große Schlüssel verursachte Blockierungsproblem wirkt sich weiter auf die Master-Slave-Synchronisation und die Clustererweiterung aus.
Zusammenfassend lässt sich sagen, dass es viele potenzielle Probleme gibt, die durch große Schlüssel verursacht werden, und wir sollten versuchen, die Existenz großer Schlüssel in Redis zu vermeiden.
Wie entdeckt man Bigkey?
1. Verwenden Sie zum Suchen den mit Redis gelieferten Parameter --bigkeys.
# redis-cli -p 6379 --bigkeys
# Scanning the entire keyspace to find biggest keys as well as
# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec
# per 100 SCAN commands (not usually needed).
[00.00%] Biggest string found so far '"ballcat:oauth:refresh_auth:f6cdb384-9a9d-4f2f-af01-dc3f28057c20"' with 4437 bytes
[00.00%] Biggest list found so far '"my-list"' with 17 items
-------- summary -------
Sampled 5 keys in the keyspace!
Total key length in bytes is 264 (avg len 52.80)
Biggest list found '"my-list"' has 17 items
Biggest string found '"ballcat:oauth:refresh_auth:f6cdb384-9a9d-4f2f-af01-dc3f28057c20"' has 4437 bytes
1 lists with 17 items (20.00% of keys, avg size 17.00)
0 hashs with 0 fields (00.00% of keys, avg size 0.00)
4 strings with 4831 bytes (80.00% of keys, avg size 1207.75)
0 streams with 0 entries (00.00% of keys, avg size 0.00)
0 sets with 0 members (00.00% of keys, avg size 0.00)
0 zsets with 0 members (00.00% of keys, avg size 0.00Aus den Ausführungsergebnissen dieses Befehls können wir ersehen, dass dieser Befehl alle Schlüssel in Redis scannt (scan), was sich geringfügig auf die Leistung von Redis auswirkt. Darüber hinaus kann diese Methode nur den obersten 1 großen Schlüssel jeder Datenstruktur finden (den String-Datentyp, der den größten Speicher beansprucht, und den zusammengesetzten Datentyp, der die meisten Elemente enthält). Allerdings bedeutet die Tatsache, dass ein Schlüssel viele Elemente enthält, nicht, dass er mehr Speicher beansprucht. Wir müssen weitere Beurteilungen auf der Grundlage spezifischer Geschäftsbedingungen vornehmen.
Wenn Sie diesen Befehl online ausführen, müssen Sie den Parameter -i angeben, um die Häufigkeit des Scannens zu steuern, um die Auswirkungen auf Redis zu verringern. redis-cli -p 6379 --bigkeys -i 3 bedeutet, dass das Ruheintervall nach jedem Scan während des Scanvorgangs 3 Sekunden beträgt.
2. Verwenden Sie den SCAN-Befehl, der mit Redis geliefert wird
Der SCAN-Befehl kann passende Schlüssel nach einem bestimmten Muster und einer bestimmten Anzahl zurückgeben. Nachdem Sie den Schlüssel erhalten haben, können Sie STRLEN, HLEN, LLEN und andere Befehle verwenden, um seine Länge oder Anzahl der Mitglieder zurückzugeben.
Ergebnis der Befehlskomplexität der Datenstruktur (entsprechend dem Schlüssel) StringSTRLENO (1) Die Länge des Zeichenfolgenwerts HashHLENO (1) Die Anzahl der Felder in der Hash-Tabelle ListLLENO (1) Die Anzahl der Listenelemente SetSCARDO (1) Die Anzahl der Mengenelemente Sortierte MengeZCARDO (1) Ja Die Anzahl der Elemente in der sortierten Menge
Für Sammlungstypen können Sie auch den Befehl MEMORY USAGE (Redis 4.0+) verwenden. Dieser Befehl gibt den von Schlüssel-Wert-Paaren belegten Speicherplatz zurück.
3. Verwenden Sie Open-Source-Tools, um RDB-Dateien zu analysieren.
Finden Sie den großen Schlüssel, indem Sie die RDB-Datei analysieren. Die Voraussetzung dieser Lösung ist, dass Ihr Redis RDB-Persistenz verwendet.
Online stehen vorgefertigte Codes/Tools zur Verfügung, die direkt genutzt werden können:
- redis-rdb-tools[2] : Ein in Python-Sprache geschriebenes Tool zur Analyse von Redis RDB-Snapshot-Dateien
- rdb_bigkeys[3] : Ein in der Go-Sprache geschriebenes Tool zur Analyse von Redis RDB-Snapshot-Dateien mit besserer Leistung.
4. Nutzen Sie den Redis-Analysedienst der Public Cloud.
Wenn Sie den Redis-Dienst der öffentlichen Cloud verwenden, können Sie sehen, ob er wichtige Analysefunktionen bietet (normalerweise ist dies der Fall).
Hier nehmen wir Alibaba Cloud Redis als Beispiel. Es unterstützt Bigkey-Echtzeitanalyse und -erkennung. Dokumentadresse: https://www.alibabacloud.com/help/zh/apsaradb-for-redis/latest/use-the-real -time- key-statistics-feature .
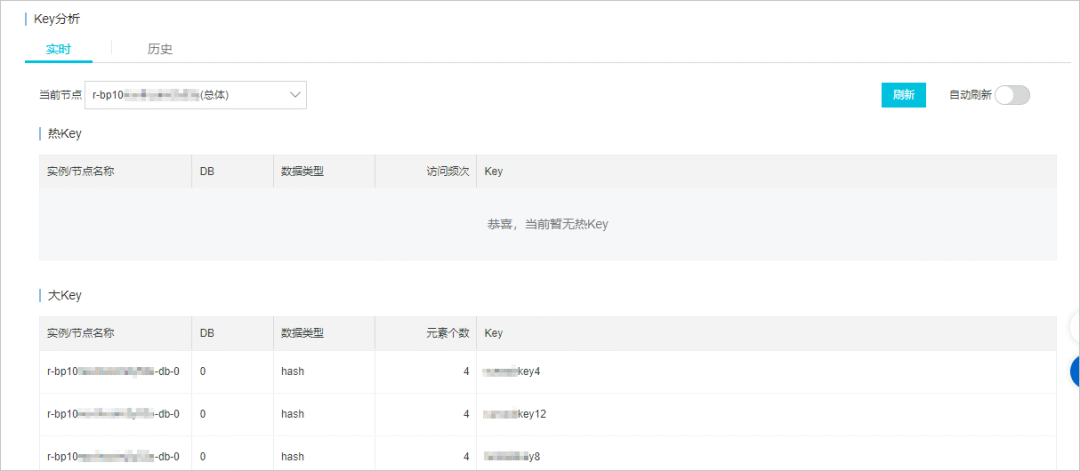
Alibaba Cloud-Schlüsselanalyse
Wie gehe ich mit Bigkey um?
Übliche Verarbeitungs- und Optimierungsmethoden für Bigkey sind wie folgt (diese Methoden können zusammen verwendet werden):
- Großschlüssel aufteilen : Teilen Sie einen Großschlüssel in mehrere kleine Schlüssel auf. Beispielsweise wird ein Hash, der Zehntausende Felder enthält, gemäß einer bestimmten Strategie (z. B. sekundärem Hashing) in mehrere Hashes aufgeteilt.
- Manuelle Bereinigung : Redis 4.0+ kann den UNLINK-Befehl verwenden, um einen oder mehrere angegebene Schlüssel asynchron zu löschen. Für Redis 4.0 und niedriger können Sie erwägen, den SCAN-Befehl in Kombination mit dem DEL-Befehl zu verwenden, um stapelweise zu löschen.
- Verwenden Sie geeignete Datenstrukturen : Verwenden Sie beispielsweise nicht String zum Speichern von Dateibinärdaten, verwenden Sie HyperLogLog zum Zählen von Seiten-UVs und Bitmap zum Speichern von Statusinformationen (0/1).
- Lazy-Free aktivieren (verzögertes Löschen/verzögerte Freigabe) : Die Lazy-Free-Funktion wurde in Redis 4.0 eingeführt. Sie bezieht sich darauf, dass Redis eine asynchrone Methode verwenden kann, um die Freigabe des vom Schlüssel verwendeten Speichers zu verzögern und ihn zu übergeben Führen Sie den Vorgang in einen separaten Unterthread aus, um ein Blockieren des Hauptthreads zu vermeiden.