1. Présentation des robots
简单来说,爬虫就是获取网页并提取和保存信息的自动化程序,下面概要介绍一下。
(1) Obtenez la page Web
La première chose que le robot doit faire est d’obtenir la page Web, ici il s’agit d’obtenir le code source de la page Web. Le code source contient des informations utiles sur la page Web, donc tant que vous obtenez le code source, vous pouvez en extraire les informations souhaitées.
Nous avons parlé plus tôt des concepts de requête et de réponse. Lorsque vous envoyez une requête au serveur du site Web, le corps de la réponse renvoyé est le code source de la page Web. Par conséquent, la partie la plus critique est de construire une requête et de l'envoyer au serveur, puis de recevoir la réponse et de l'analyser. Alors, comment mettre en œuvre ce processus ? Vous ne pouvez pas intercepter manuellement le code source d’une page Web, n’est-ce pas ?
Ne vous inquiétez pas, Python fournit de nombreuses bibliothèques pour nous aider à réaliser cette opération, comme l'urllib, les requêtes, etc. Nous pouvons utiliser ces bibliothèques pour nous aider à implémenter des opérations de requête HTTP. Les requêtes et les réponses peuvent être représentées par la structure de données fournie par la bibliothèque de classes. Après avoir obtenu la réponse, il nous suffit d'analyser la partie Body de la structure de données, c'est-à-dire , obtenez le code source de la page Web. De cette façon, nous pouvons utiliser un programme pour mettre en œuvre le processus d'obtention de pages Web.
(2) Extraire les informations
Après avoir obtenu le code source de la page Web, l’étape suivante consiste à analyser le code source de la page Web et à en extraire les données souhaitées. Tout d'abord, la méthode la plus courante consiste à utiliser l'extraction d'expressions régulières. Il s'agit d'une méthode universelle, mais elle est plus compliquée et sujette aux erreurs lors de la construction d'expressions régulières.
De plus, étant donné que la structure des pages Web a certaines règles, certaines bibliothèques extraient également des informations sur les pages Web en fonction des attributs des nœuds de page Web, des sélecteurs CSS ou XPath, comme Beautiful Soup, pyquery, lxml, etc. Grâce à ces bibliothèques, nous pouvons extraire efficacement et rapidement les informations des pages Web, telles que les attributs des nœuds, les valeurs de texte, etc.
L'extraction d'informations est une partie très importante du robot d'exploration, qui peut organiser des données désordonnées afin que nous puissions ensuite les traiter et les analyser.
(3) Enregistrer les données
Après avoir extrait les informations, nous sauvegardons généralement les données extraites quelque part pour une utilisation ultérieure. Il existe différentes manières d'enregistrer ici. Par exemple, il peut être simplement enregistré sous forme de texte TXT ou de texte JSON, ou il peut être enregistré dans une base de données, telle que MySQL et MongoDB, ou encore sur un serveur distant, tel que fonctionnant avec SFTP.
(4) Procédures automatisées
Lorsqu’il s’agit de programmes automatisés, cela signifie que les robots peuvent effectuer ces opérations à la place des humains. Tout d'abord, bien sûr, nous pouvons extraire ces informations manuellement, mais si le volume est particulièrement important ou si nous voulons obtenir rapidement une grande quantité de données, nous devons quand même utiliser un programme. Un robot d'exploration est un programme automatisé qui effectue le travail d'exploration en notre nom. Il peut effectuer diverses opérations de gestion des exceptions, de nouvelles tentatives d'erreur et d'autres opérations pendant le processus d'exploration pour garantir que l'exploration continue de s'exécuter efficacement.
2. L'utilisation de robots d'exploration
De nos jours, l'ère du big data est arrivée et la technologie des robots d'exploration Web est devenue un élément indispensable de cette ère. Les entreprises ont besoin de données pour analyser le comportement des utilisateurs, les défauts de leurs propres produits, les informations sur les concurrents, etc., et la première condition pour tout cela. est la collecte de données. La valeur des robots d'exploration du Web est en réalité la valeur des données. Dans la société Internet, les données n'ont pas de prix et tout est donnée. Celui qui possède une grande quantité de données utiles a l'initiative de prendre des décisions.
Les principaux domaines d'application actuels des robots d'exploration Web comprennent : les moteurs de recherche, la collecte de données, l'analyse de données, l'agrégation d'informations, la surveillance des produits concurrentiels, l'intelligence cognitive, l'analyse de l'opinion publique, etc. Il existe d'innombrables entreprises liées aux activités des robots d'exploration, telles que Baidu, Google, Tianyancha, Qi. Chacha, Xinbang, Feigua... À l'ère du big data, les robots d'exploration ont un large éventail d'applications et une forte demande. Voici quelques exemples proches de la réalité :
-
**Exigences du poste :** Obtenez des informations de recrutement et des normes salariales dans diverses villes pour sélectionner facilement celles qui vous conviennent ;
-
**Demande de location :** Obtenez des informations sur les locations dans différentes villes pour sélectionner votre logement préféré ;
-
**Besoins gastronomiques :** Obtenez de bonnes critiques de divers endroits afin que les gourmets ne se perdent pas ;
-
**Besoins d'achat :** Obtenez des informations sur le prix et les remises du même produit auprès de divers marchands pour rendre les achats plus abordables ;
-
**Besoins d'achat de voitures : **Obtenez les fluctuations de prix de vos véhicules préférés au cours des dernières années, ainsi que les prix des différents modèles via différents canaux, pour vous aider à choisir votre voiture.
3. La signification de l'URI et de l'URL
URI (Uniform Resource Identifier), qui est l'Uniform Resource Identifier, URI (Uniform Resource Location), qui est l'Uniform Resource Locator, par exemplehttps://www. kuaidaili.com / est à la fois un URI et une URL. L'URL est un sous-ensemble de l'URI. Pour les liens Web généraux, il est d'usage de l'appeler URL. Le format de composition de base d'une URL est le suivant suit :
scheme://[username:password@]host[:port][/path][;parameters][?query][#fragment]
La signification de chaque partie est la suivante :
-
**schéma :** Le protocole utilisé pour obtenir des ressources, telles que http, https, ftp, etc., il n'y a pas de valeur par défaut, le schéma est également appelé protocole ;
-
**nom d'utilisateur:mot de passe:**Nom d'utilisateur et mot de passe. Dans certains cas, l'URL nécessite un nom d'utilisateur et un mot de passe pour y accéder. Il s'agit d'une existence particulière. Il est généralement utilisé lors de l'accès à FTP. Il indique explicitement le nom d'utilisateur pour accéder aux ressources. et mot de passe, mais vous n'êtes pas obligé de l'écrire. Si vous ne l'écrivez pas, il vous sera peut-être demandé de saisir votre nom d'utilisateur et votre mot de passe ;
-
**host : **Adresse de l'hôte, qui peut être un nom de domaine ou une adresse IP, telle quewww.kuaidaili.com, 112.66.251.209;
-
**port : **port, le port de service défini par le serveur, le port par défaut du protocole http est 80, le port par défaut du protocole https est 443, par exemple https://www.kuaidaili.com/ est équivalent àhttps://www.kuaidaili.com:443;
-
**path : **path fait référence à l'adresse spécifiée des ressources réseau sur le serveur. Nous pouvons trouver l'hôte via host:port, mais il existe de nombreux fichiers sur l'hôte. Des fichiers spécifiques peuvent être localisés via path . Par exemplehttps://www.baidu.com/file/index.html, le chemin est /file/index.html, ce qui signifie que nous accédons /file/ index.html ce fichier ;
-
**paramètres : **paramètres, utilisés pour spécifier des informations supplémentaires lors de l'accès à une ressource. La fonction principale est de fournir des paramètres supplémentaires au serveur pour représenter certaines caractéristiques de cette requête, telles que https://www.kuaidaili.com/dps;kspider, kspider est un paramètre, il est rarement utilisé maintenant, la plupart d'entre eux utilisent la partie requête comme paramètre ;
-
**query : **Requête, en raison de l'interrogation de certains types de ressources, s'il existe plusieurs requêtes, utilisez & pour séparer les paramètres demandés via GET, par exemple : https ://www.kuaidaili.com/dps/?username=kspider&type=spider, la partie requête est username=ksspider&type=spider, le nom d'utilisateur est kspider et le type est araignée;
-
**fragment : **Fragment, un complément partiel à la description de la ressource, utilisé pour identifier les ressources secondaires, telles quehttps://www.kuaidaili.com/dps# kspider , kspider est la valeur du fragment :
-
Application : routage d'une seule page, ancre HTML ;
-
#est différent de?, la chaîne de requête qui suit?sera amenée au serveur par la requête réseau, mais le fragment ne sera pas envoyé à le serveur; < /span> -
Les modifications apportées au fragment n'entraîneront pas l'actualisation de la page par le navigateur, mais généreront un historique de navigation ;
-
Les fragments seront traités par le navigateur en fonction du type de support de fichier (type MIME) ;
-
Par défaut, le moteur de recherche de Google ignorera
#et les chaînes suivantes. Si vous souhaitez qu'il soit lu par le moteur du navigateur, vous devez suivre#Suite à un!, Google convertira automatiquement le contenu suivant en la valeur de la chaîne de requête_escaped_fragment_, telle que https : //www.kuaidaili.com/dps#!kspider, converti en https://www.kuaidaili.com/dps< a i=8>?escaped_fragment=kspider.
-
Étant donné que l'objectif du robot d'exploration est d'obtenir des ressources et que les ressources sont stockées sur un hôte spécifique, lorsque le robot d'exploration analyse les données, il doit disposer d'une URL cible pour obtenir les données. Par conséquent, l'URL constitue la base de base permettant au robot d'exploration de obtenir des données. Comprendre avec précision l'URL. La signification est très utile pour l'apprentissage des robots.
4. Processus de base du robot d'exploration
- **Lancer une requête :** Lancer une requête de requête auprès du serveur via l'URL (identique à l'ouverture d'un navigateur et à la saisie de l'URL pour naviguer sur le Web). La requête peut contenir des en-têtes supplémentaires, des cookies, des proxys, des données et d'autres informations. Python fournit de nombreuses bibliothèques pour nous aider à implémenter. Ce processus complète les opérations de requête HTTP, telles que urllib, requêtes, etc. ;
- **Obtenir le contenu de la réponse :** Si le serveur répond normalement, il recevra la réponse. La réponse est le contenu de la page Web que nous avons demandé, y compris le HTML (code source de la page Web), les données JSON ou les données binaires (vidéo, audio, photos), etc. ;
- **Analyse du contenu :** Après avoir reçu le contenu de la réponse, il doit être analysé et le contenu des données extrait. S'il s'agit de HTML (code source de page Web), il peut être analysé à l'aide d'un analyseur de page Web, tel qu'une expression régulière ( re), Beautiful Soup, pyquery, lxml, etc. ; s'il s'agit de données JSON, elles peuvent être converties en un objet JSON pour l'analyse ; s'il s'agit de données binaires, elles peuvent être enregistrées dans un fichier pour un traitement ultérieur ;
- **Enregistrer les données :** Elles peuvent être enregistrées dans un fichier local (txt, json, csv, etc.), ou dans une base de données (MySQL, Redis, MongoDB, etc.), ou sur un serveur distant, par exemple en utilisant SFTP.
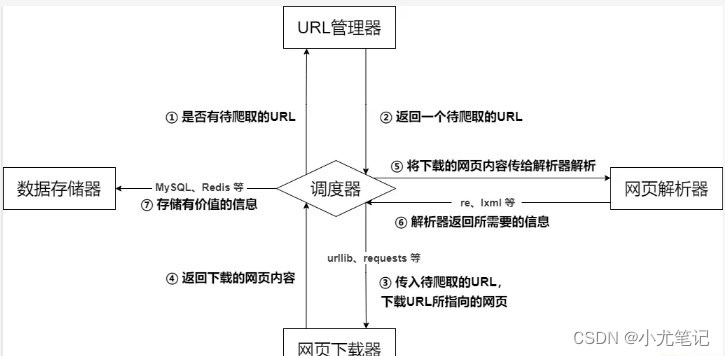
5. Architecture de base du robot
L'architecture de base du robot d'exploration se compose principalement de cinq parties, à savoir le planificateur de robot, le gestionnaire d'URL, le téléchargeur de pages Web, l'analyseur de pages Web et le collecteur d'informations :
- **Planificateur d'exploration :** Équivalent au processeur d'un ordinateur. Il est principalement responsable de la planification de la coordination entre le gestionnaire d'URL, le téléchargeur et l'analyseur. Il est utilisé pour la communication entre les différents modules. Il peut être compris comme l'entrée et sortie du robot.Core, la stratégie d'exécution du robot est définie dans ce module ;
- **Gestionnaire d'URL : **Inclut les adresses URL à explorer et les adresses URL à analyser pour empêcher l'exploration répétée des URL et l'analyse en boucle des URL. Il existe trois manières principales d'implémenter le gestionnaire d'URL : via la mémoire, la base de données et le cache. atteindre;
- **Téléchargeur de pages Web : **Responsable du téléchargement de pages Web via des URL, effectuant principalement le traitement de camouflage correspondant pour simuler l'accès au navigateur et télécharger des pages Web. Les bibliothèques couramment utilisées sont urllib, requêtes, etc. ;
- **Analyseur de pages Web :** Responsable de l'analyse des informations des pages Web. Il peut extraire des informations utiles selon les besoins et peut également les analyser selon la méthode d'analyse de l'arborescence DOM. Comme les expressions régulières (re), Beautiful Soup, pyquery, lxml, etc., qui peuvent être utilisées de manière flexible en fonction de la situation réelle ;
- **Stockage des données :** Responsable du stockage, de l'affichage et d'autres traitements de données des informations analysées.
01
6. Protocole des robots
Le protocole robots, également connu sous le nom de protocole d'exploration, règles d'exploration, etc., signifie que le site Web peut créer un fichier robots.txt pour indiquer au moteur de recherche quelles pages peuvent être explorées et quelles pages ne peuvent pas être explorées, et le moteur de recherche les identifie. en lisant le fichier robots.txt. Si cette page est autorisée à être explorée. Cependant, ce protocole robots n'est pas un pare-feu et n'a aucun pouvoir d'application. Les moteurs de recherche peuvent ignorer complètement le fichier robots.txt et récupérer un instantané de la page Web**. ** Si vous souhaitez définir séparément le comportement des robots des moteurs de recherche lors de l'accès aux sous-répertoires, vous pouvez fusionner les paramètres personnalisés dans robots.txt dans le répertoire racine ou utiliser les métadonnées des robots (métadonnées, également appelées métadonnées).
L'accord sur les robots n'est pas une spécification, mais juste une convention, il ne garantit donc pas la confidentialité du site Web. Il est communément appelé « gentleman's accord ».
La signification du contenu du fichier robots.txt :
User-agent:*, où * représente tous les types de moteurs de recherche, * est un caractère générique- Interdire : /admin/, la définition ici est d'interdire l'exploration des répertoires sous le répertoire admin
- Interdire : /require/, la définition ici est d'interdire l'exploration des répertoires sous le répertoire require.
- Disallow:/ABC/, la définition ici est d'interdire l'exploration des répertoires sous le répertoire ABC
- Interdire :
/cgi-bin/*.htm, interdit l'accès à toutes les URL avec le suffixe « .htm » (y compris les sous-répertoires) dans le répertoire /cgi-bin/ - Interdire :
/*?*, interdit l'accès à toutes les URL du site qui contiennent un point d'interrogation (?) - Disallow :/.jpg$, interdit l'exploration de toutes les images au format .jpg sur la page Web
- Interdire :/ab/adc.html, interdire l'exploration du fichier adc.html sous le dossier ab
- Autoriser :/cgi-bin/, la définition ici est d'autoriser l'exploration des répertoires sous le répertoire cgi-bin
- Allow:/tmp, cette définition permet d'explorer tout le répertoire de tmp
- Autoriser : .htm$, autorise uniquement l'accès aux URL avec le suffixe « .htm »
- Autoriser : .gif$, permet d'explorer les pages Web et les images au format gif
- Plan du site : plan du site, indique aux robots d'exploration que cette page est un plan du site
Vérifiez le protocole robots du site Web. Ajoutez simplement le suffixe robotst.txt à l'URL du site Web. Prenons l'exemple du proxy rapide :
https://www.kuaidaili.com/

02
- Empêcher tous les moteurs de recherche d'accéder à n'importe quelle partie du site
- Désactiver l'exploration des répertoires sous le répertoire /doc/using/
- Il est interdit d'explorer tous les répertoires et fichiers commençant par sdk sous le répertoire /doc/dev