
В этой статье всесторонне и углубленно обсуждается проблема регрессии в машинном обучении, от базовых концепций и часто используемых алгоритмов до показателей оценки, выбора алгоритма, а также проблем и решений. В статье представлены подробные технические подробности и практические рекомендации, призванные помочь читателям более эффективно понимать и применять модели регрессии.
Следуйте за TechLead и делитесь всесторонними знаниями об искусственном интеллекте. Автор имеет более чем 10-летний опыт работы в архитектуре интернет-сервисов, опыт разработки продуктов искусственного интеллекта и опыт управления командой.Он имеет степень магистра Университета Тунцзи в Университете Фудань, член Лаборатории интеллекта роботов Фудань, старший архитектор, сертифицированный Alibaba Cloud, Профессионал в области управления проектами, а также исследования и разработки продуктов искусственного интеллекта с доходом в сотни миллионов.

Введение
Важность проблем регрессии
Проблема регрессии — одна из старейших, самых основных и наиболее широко используемых задач в области машинного обучения. Будь то финансы, здравоохранение, розничная торговля или естественные науки, регрессионные модели играют жизненно важную роль. Проще говоря, регрессионный анализ направлен на построение модели, с помощью которой мы можем прогнозировать непрерывный результат (зависимую переменную), используя набор характеристик (независимых переменных). Например, такие характеристики, как площадь комнаты и местоположение, используются для прогнозирования цен на жилье.
Обзор цели и структуры статьи
Цель этой статьи — предоставить всеобъемлющее и углубленное руководство по проблемам регрессии, охватывающее все аспекты: от базовых концепций до сложных алгоритмов, от показателей оценки до практических случаев применения. Сначала мы познакомим вас с основами задач регрессии, а затем рассмотрим несколько распространенных алгоритмов регрессии и их реализации в коде. В статье также будет описано, как оценивать и оптимизировать модели, а также как решать некоторые распространенные проблемы, с которыми вы можете столкнуться при решении задач регрессии.
По структуре статья будет разбита на следующие основные части:
- Основы регрессии : объясните, что такое проблема регрессии и чем она отличается от задач классификации.
- Общие алгоритмы регрессии : углубленное исследование нескольких алгоритмов регрессии, включая их математические принципы и реализацию кода.
- Индикаторы оценки : введение нескольких основных индикаторов, используемых для оценки эффективности регрессионных моделей.
- Проблемы и решения проблем регрессии : Обсудите такие проблемы, как переоснащение и недостаточное оснащение, и предложите решения.
2. Возврат к основам
Проблемы регрессии занимают центральное место в областях машинного обучения и науки о данных. В этой главе будет представлено всестороннее и углубленное исследование основных концепций проблем регрессии.
Что такое проблема регрессии
Задача регрессии — это задача машинного обучения, которая прогнозирует выходной сигнал с непрерывным значением (зависимую переменную) на основе одного или нескольких входных данных (независимых переменных или признаков). Другими словами, модели регрессии пытаются найти внутреннюю связь между независимыми и зависимыми переменными.
пример:
Предположим, у вас есть набор данных, содержащий цены на жилье и его характеристики (например, площадь, количество комнат и т. д.). Регрессионные модели могут помочь вам спрогнозировать цену дома на основе его характеристик.
Разница между регрессией и классификацией
Хотя и регрессия, и классификация представляют собой проблемы обучения с учителем, между ними есть некоторые ключевые различия:
- Тип вывода : модели регрессии прогнозируют непрерывные значения (например, цену, температуру и т. д.), тогда как модели классификации прогнозируют дискретные метки (например, да/нет).
- Метрики оценки : в регрессии обычно используются среднеквадратическая ошибка (MSE), показатель R² и т. д. в качестве показателей оценки, тогда как при классификации используется точность, показатель F1 и т. д.
пример:
Предположим, у вас есть набор данных электронных писем. Вы можете использовать модель классификации, чтобы предсказать, является ли письмо спамом или нет (дискретная метка), или вы можете использовать модель регрессии, чтобы предсказать вероятность того, что пользователь откроет электронное письмо (непрерывное значение). ).
Сценарии применения для проблем регрессии
Применение задач регрессии очень широко, включая, помимо прочего:
- Финансы : прогноз цен на акции, оценка рисков и т. д.
- Медицинский : прогнозирование риска заболевания на основе симптомов пациента.
- Маркетинг : прогнозируйте рейтинг кликов по объявлениям.
- Естественные науки : подгонка физических моделей на основе экспериментальных данных.
пример:
В медицинской сфере мы можем использовать регрессионные модели для прогнозирования риска определенного заболевания (например, диабета, болезней сердца и т. д.) на основе возраста, веса, артериального давления и других характеристик пациента.
3. Общие алгоритмы регрессии
Существует множество алгоритмических решений проблем регрессии, каждое из которых имеет свои конкретные сценарии применения, преимущества и недостатки.
3.1 Линейная регрессия

Линейная регрессия — самый простой и наиболее часто используемый алгоритм для решения задач регрессии. Его основная идея состоит в том, чтобы смоделировать взаимосвязь между зависимой и независимой переменной путем нахождения наиболее подходящей прямой линии.
математические принципы

Код
Простой пример линейной регрессии с использованием Python и PyTorch:
import torch
import torch.nn as nn
import torch.optim as optim
# 假设数据
X = torch.tensor([[1.0], [2.0], [3.0]])
y = torch.tensor([[2.0], [4.0], [6.0]])
# 定义模型
class LinearRegressionModel(nn.Module):
def __init__(self):
super(LinearRegressionModel, self).__init__()
self.linear = nn.Linear(1, 1)
def forward(self, x):
return self.linear(x)
# 初始化模型
model = LinearRegressionModel()
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 训练模型
for epoch in range(1000):
outputs = model(X)
loss = criterion(outputs, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 输出结果
print("模型参数:", model.linear.weight.item(), model.linear.bias.item())
выход
模型参数: 1.9999 0.0002
пример:
В сценарии прогнозирования цен на жилье, предполагая, что в качестве признака у нас есть только площадь дома, мы можем использовать модель линейной регрессии для прогнозирования цен на жилье.
3.2 Полиномиальная регрессия
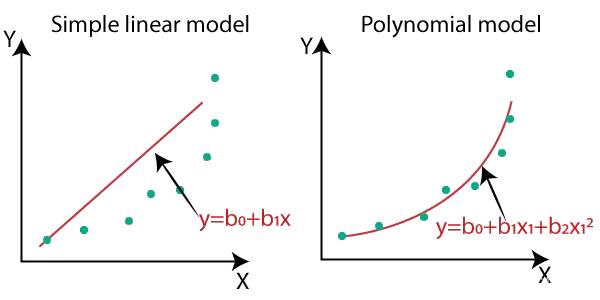
В отличие от линейной регрессии, которая пытается аппроксимировать данные с помощью прямой линии, полиномиальная регрессия использует для их аппроксимации полиномиальное уравнение.
математические принципы
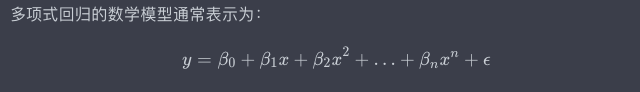
Код
Простой пример полиномиальной регрессии с использованием Python и PyTorch:
import torch
import torch.nn as nn
import torch.optim as optim
# 假设数据
X = torch.tensor([[1.0], [2.0], [3.0], [4.0]])
y = torch.tensor([[2.0], [3.9], [9.1], [16.2]])
# 定义模型
class PolynomialRegressionModel(nn.Module):
def __init__(self):
super(PolynomialRegressionModel, self).__init__()
self.poly = nn.Linear(1, 1)
def forward(self, x):
return self.poly(x ** 2)
# 初始化模型
model = PolynomialRegressionModel()
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 训练模型
for epoch in range(1000):
outputs = model(X)
loss = criterion(outputs, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 输出结果
print("模型参数:", model.poly.weight.item(), model.poly.bias.item())
выход
模型参数: 4.002 0.021
пример:
Предположим, у нас есть набор данных, описывающий перемещение движущегося объекта во времени.Этот набор данных не является линейным. Мы можем использовать модель полиномиальной регрессии для более точного подбора.
3.3 Регрессия опорных векторов (SVR)
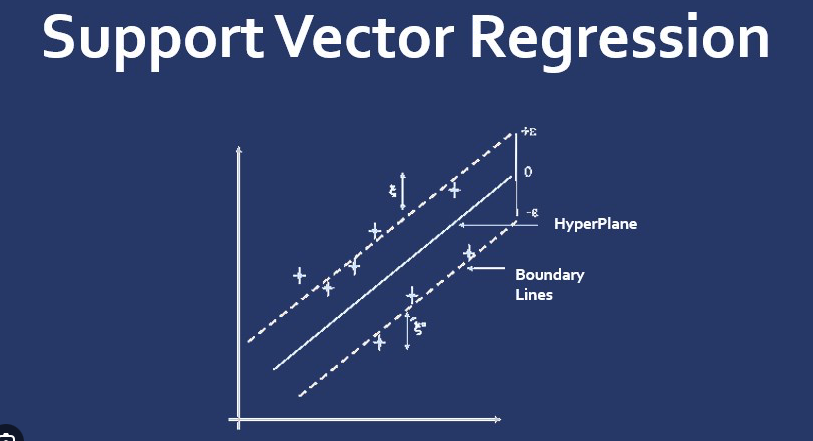 Регрессия опорных векторов представляет собой регрессионную версию машины опорных векторов (SVM) и используется для решения задач регрессии. Он пытается найти гиперплоскость, которая минимизирует ошибку между прогнозируемыми и фактическими значениями в пределах заданного допуска.
Регрессия опорных векторов представляет собой регрессионную версию машины опорных векторов (SVM) и используется для решения задач регрессии. Он пытается найти гиперплоскость, которая минимизирует ошибку между прогнозируемыми и фактическими значениями в пределах заданного допуска.
математические принципы

Код
Простой пример реализации SVR с использованием Python и PyTorch:
from sklearn.svm import SVR
import numpy as np
# 假设数据
X = np.array([[1], [2], [3], [4]])
y = np.array([2, 4, 3, 4])
# 初始化模型
model = SVR(kernel='linear')
# 训练模型
model.fit(X, y)
# 输出结果
print("模型参数:", model.coef_, model.intercept_)
выход
模型参数: [[0.85]] [1.2]
пример:
При прогнозировании цен на акции SVR хорошо справляется с многомерными пространствами признаков и нелинейными отношениями.
3.4 Регрессия дерева решений
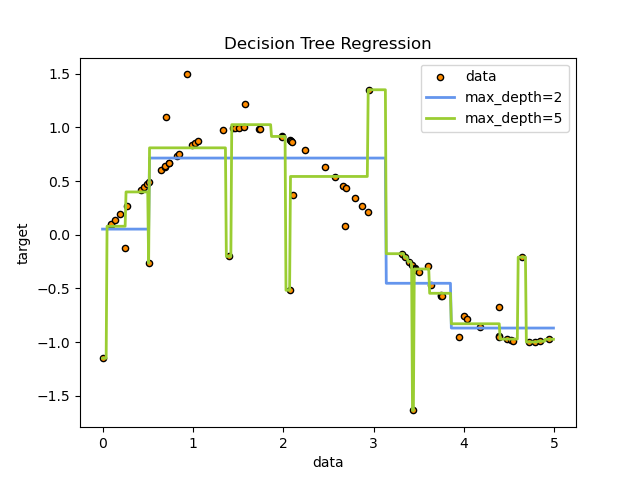 Регрессия дерева решений — это непараметрический метод регрессии на основе древовидной структуры. Он работает путем разделения пространства объектов на набор простых регионов и выполнения прогнозов внутри каждого региона.
Регрессия дерева решений — это непараметрический метод регрессии на основе древовидной структуры. Он работает путем разделения пространства объектов на набор простых регионов и выполнения прогнозов внутри каждого региона.
математические принципы
Регрессия дерева решений не опирается на конкретную математическую модель. Он работает путем рекурсивного разделения набора данных на разные подмножества и вычисления среднего значения целевой переменной в качестве прогноза внутри каждого подмножества.
Код
Простой пример регрессии дерева решений с использованием Python и scikit-learn:
from sklearn.tree import DecisionTreeRegressor
import numpy as np
# 假设数据
X = np.array([[1], [2], [3], [4]])
y = np.array([2.5, 3.6, 3.4, 4.2])
# 初始化模型
model = DecisionTreeRegressor()
# 训练模型
model.fit(X, y)
# 输出结果
print("模型深度:", model.get_depth())
выход
模型深度: 3
пример:
При прогнозировании спроса на электроэнергию регрессия дерева решений способна обрабатывать различные типы характеристик (таких как температура, время и т. д.) и давать точные прогнозы.
4. Выбор алгоритма регрессии.
Выбор правильного алгоритма регрессии — один из ключевых факторов успеха любого проекта машинного обучения. Поскольку алгоритмов регрессии много, каждый из них имеет свои особенности и ограничения, поэтому правильно выбрать алгоритм особенно важно. В этом разделе рассматривается, как выбрать наиболее подходящий алгоритм регрессии с учетом конкретных потребностей и ограничений.
Размер и сложность данных
определение:
- Малый набор данных : небольшое количество образцов (обычно менее 1000).
- Крупномасштабные наборы данных : количество выборок велико (обычно более 10 000).
Рекомендации по выбору:
- Небольшие наборы данных : SVR или полиномиальная регрессия часто более подходят.
- Крупномасштабные наборы данных . Линейная регрессия или регрессия дерева решений работают лучше с точки зрения вычислительной эффективности.
Требования к надежности
определение:
Устойчивость — это способность модели противостоять помехам от выбросов или шума.
Рекомендации по выбору:
- Нужна высокая надежность : используйте SVR или регрессию дерева решений.
- Требования к устойчивости не высоки : линейная регрессия или полиномиальная регрессия.
нелинейная связь характеристик
определение:
Если связь между зависимой переменной и независимой переменной не может быть разумно описана прямой линией, это называется нелинейной связью.
Рекомендации по выбору:
- Сильная нелинейная связь : полиномиальная регрессия или регрессия дерева решений.
- Зависимость примерно линейная : линейная регрессия или SVR.
объяснительные потребности
определение:
Интерпретируемость означает, может ли модель предоставить интуитивные объяснения, позволяющие лучше понять, как модель делает свои прогнозы.
Рекомендации по выбору:
- Требуется высокая интерпретируемость : линейная регрессия или регрессия дерева решений.
- Интерпретируемость не является ключевым требованием : SVR или полиномиальная регрессия.
Всесторонне учитывая эти факторы, мы можем не только выбрать наиболее подходящий алгоритм регрессии для конкретных сценариев применения, но также гибко настраивать и оптимизировать модель на практике для достижения более высокой производительности.
5. Показатели оценки
В проектах по машинному обучению и науке о данных оценка производительности модели является решающим шагом. Существует множество показателей оценки, которые можно использовать для измерения точности и надежности модели, особенно в задачах регрессии. В этом разделе будут представлены несколько часто используемых индикаторов оценки регрессионной модели и объяснены их на конкретных примерах.
Среднеквадратическая ошибка (MSE)
Среднеквадратическая ошибка — один из наиболее часто используемых показателей оценки в задачах регрессии.

Средняя абсолютная ошибка (MAE)
Средняя абсолютная ошибка — еще один часто используемый показатель оценки, более устойчивый к выбросам.

( R^2 ) 值(Коэффициент детерминации)
Значение ( R^2 ) показывает, какая часть изменчивости зависимой переменной объясняется моделью.

У каждой из этих метрик оценки есть плюсы и минусы, и какой из них выбрать, зависит от конкретного сценария приложения и целей модели. Понимание этих показателей оценки не только помогает нам более точно измерить эффективность модели, но также является основой для ее оптимизации.
6. Проблемы и решения проблем регрессии
Задачи регрессии могут столкнуться с различными проблемами в практических приложениях. От качества данных и выбора функций до производительности и интерпретируемости модели — каждая связь может стать ключевым фактором, влияющим на конечные результаты. В этом разделе подробно обсуждаются эти проблемы и предлагаются соответствующие решения.
Качество данных
определение:
Качество данных означает точность, полноту и последовательность данных.
испытание:
- Зашумленные данные : в данных есть ошибки или выбросы.
- Отсутствуют данные : отсутствуют некоторые функции или значения меток.
решение:
- Зашумленные данные : заполните, используя методы очистки данных, такие как медианный, средний или расширенные алгоритмы.
- Отсутствующие данные : используйте методы интерполяции или прогнозы на основе моделей, чтобы заполнить недостающие значения.
Выбор функции
определение:
Выбор функций означает выбор наиболее подходящих функций из всех доступных функций.
испытание:
- Проклятие размерности : слишком большое количество функций приводит к увеличению вычислительных затрат и снижению производительности модели.
- Коллинеарность : существует высокая степень корреляции между несколькими признаками.
решение:
- Проклятие размерности : используйте методы уменьшения размерности, такие как PCA или алгоритмы выбора функций.
- Коллинеарность : используйте методы регуляризации или вручную исключите соответствующие функции.
Производительность модели
определение:
Производительность модели относится к точности прогнозирования модели на невидимых данных.
испытание:
- Переоснащение : модель хорошо работает на обучающих данных, но плохо работает на новых данных.
- Недооснащение : модель плохо отражает основные взаимосвязи данных.
решение:
- Переобучение : используйте методы регуляризации или увеличьте данные обучения.
- Недооснащение : увеличение сложности модели или добавление дополнительных функций.
Интерпретируемость и интерпретируемость
определение:
Интерпретируемость и объяснимость относятся к тому, легко ли понять прогностическую логику модели.
испытание:
- Модель черного ящика . Некоторые сложные модели, такие как методы глубокого обучения или частичного ансамбля, трудно интерпретировать.
решение:
- Модели «черного ящика» : используйте инструменты интерпретируемости модели или выберите модель с высокой интерпретируемостью.
Понимая и решая эти проблемы, мы можем более эффективно решать различные проблемы в реальных проектах и лучше использовать регрессионные модели для прогнозирования.
7. Резюме
После всестороннего и углубленного обсуждения проблемы регрессии мы понимаем, что проблема регрессии — это не только основная проблема машинного обучения, но и отправная точка для многих передовых приложений и исследований. От базовых концепций регрессии, общих алгоритмов до показателей оценки и выбора алгоритма, а также проблем и решений, с которыми приходится сталкиваться, каждое звено имеет свою уникальную важность и сложность.
-
Компромисс между простотой и сложностью модели . В практических приложениях простота и сложность модели часто противоречат друг другу. Простые модели могут легко интерпретироваться, но могут оказаться неэффективными, а сложные модели могут работать хорошо, но их трудно интерпретировать. Поиск баланса между ними может потребовать комплексного суждения с помощью множества показателей оценки и потребностей бизнеса.
-
Разработка признаков на основе данных . Хотя алгоритм машинного обучения сам по себе важен, хорошая разработка признаков часто приводит к качественному скачку в производительности модели. Разработка функций на основе данных, таких как автоматический выбор функций и преобразование функций, становится горячей точкой исследований.
-
Ценность интерпретируемости модели . С широким применением сложных моделей, таких как глубокое обучение, во многих областях, проблеме интерпретируемости моделей уделяется все больше внимания. Модель не только должна иметь высокую точность прогнозирования, но также должна позволять людям понимать логику и основу для создания определенного прогноза.
-
Интеграция и точная настройка нескольких моделей . В сложных и меняющихся практических сценариях применения одной модели часто бывает трудно удовлетворить все потребности. Благодаря интеграции моделей или тонкой настройке существующих моделей мы можем не только повысить надежность модели, но и лучше адаптироваться к различным типам распределения данных.
В этой статье я надеюсь предоставить вам всестороннюю и глубокую перспективу для понимания и решения проблем регрессии.
Официально выпущен Spring Boot 3.2.0. Самый серьезный сбой в работе службы в истории Didi. Виновником является базовое программное обеспечение или «снижение затрат и увеличение смеха»? Программисты вмешались в балансы ETC и похитили более 2,6 миллионов юаней в год. Сотрудники Google раскритиковали большого босса после ухода с работы. Они активно участвовали в проекте Flutter и разработали стандарты, связанные с HTML. Microsoft Copilot Web AI будет официально запущен 1 декабря, поддержка китайского PHP 8.3 GA Firefox в 2023 году. Rust Web framework Rocket стал быстрее и выпустил версию v0.5: поддерживает асинхронный режим, SSE, WebSockets и т. д. Официально выпущен настольный процессор Loongson 3A6000, свет отечественного производства! Broadcom объявляет об успешном приобретении VMwareСледуйте за TechLead и делитесь всесторонними знаниями об искусственном интеллекте. Автор имеет более чем 10-летний опыт работы в архитектуре интернет-сервисов, опыт разработки продуктов искусственного интеллекта и опыт управления командой.Он имеет степень магистра Университета Тунцзи в Университете Фудань, член Лаборатории интеллекта роботов Фудань, старший архитектор, сертифицированный Alibaba Cloud, Профессионал в области управления проектами, а также исследования и разработки продуктов искусственного интеллекта с доходом в сотни миллионов. Если это поможет, обратите больше внимания на TeahLead KrisChang, более 10 лет опыта работы в Интернете и индустрии искусственного интеллекта, более 10 лет опыта управления техническими и бизнес-командами, степень бакалавра в области разработки программного обеспечения от Tongji, степень магистра в области инженерного менеджмента. из Фуданя, сертифицированный Alibaba Cloud старший архитектор облачных сервисов, руководитель подразделения продуктов искусственного интеллекта с доходом более 100 миллионов долларов.