Comme nous le savons tous, dans la plupart des scénarios, les données de séries chronologiques sont stockées dans la base de données par ordre de temps croissant. Cependant, en raison des retards du réseau, des pannes d'équipement, etc., il n'est pas possible de garantir que les données collectées arrivent dans l'ordre. Traditionnellement, nous appelez ces données chaotiques. Les données dans le désordre sont un phénomène courant, et le traitement des données dans le désordre est également un scénario que les bases de données de séries chronologiques doivent prendre en charge.
Cet article présente principalement comment openGemini gère efficacement les données dans le désordre.
Ingestion à haut débit de données dans le désordre
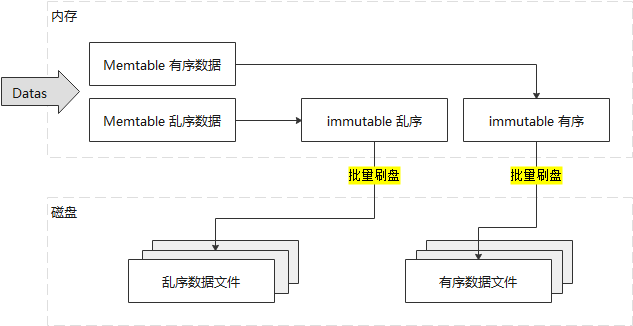
Le moteur de stockage openGemini adopte la structure LSM pour prendre en charge une ingestion efficace des données. Les données seront agrégées jusqu'à une certaine taille dans la table mémorisable, puis le vidage du disque sera déclenché, réduisant considérablement les E/S du disque.
Chaque donnée de chronologie comporte deux zones, ordonnées et désordonnées, dans la mémoire. Les données de séries chronologiques ordonnées sont écrites dans la zone ordonnée et la zone temporelle désordonnée est écrite dans la zone désordonnée. Lorsque la table mémoire est vidée, les données ordonnées sont vidées vers la zone ordonnée du disque pour générer un fichier ordonné ; les données dans le désordre sont vidées vers la zone ordonnée du disque pour générer un fichier dans le désordre. Les données en désordre et ordonnées sont traitées de manière cohérente et l'ingestion à grande vitesse peut être maintenue.
Fusion efficace des données dans le désordre

Les fichiers dans le désordre appartenant aux fichiers de niveau 0 dans le moteur de stockage openGemini tenteront d'abord de fusionner les fichiers dans le désordre. Ce n'est que lorsqu'ils atteindront la taille seuil définie qu'ils seront fusionnés avec les fichiers ordonnés pour éviter l'amplification en écriture causée par fusion avec des fichiers ordonnés et des fichiers de haut niveau.
Lors de la fusion de fichiers dans le désordre et ordonnés, nous profitons de la faible proportion de fichiers dans le désordre. Le fichier ordonné ne contient pas les données chronologiques des fichiers dans le désordre. Il vous suffit de lire le Métadonnées CunkMeta, modifiez le décalage et lisez-le directement. Il suffit d'écrire un nouveau fichier, ce qui réduit un grand nombre d'opérations de décompression et de compression des données et réduit considérablement le CPU. Cette optimisation est déjà dans la version v1.1.0-rc1.
Résultats mesurés avant et après optimisation
Tester que les données hors service et les données ordonnées ne croisent que 5 % des lignes temporelles. Écrivez 2,19 G de données ordonnées, dont 50 000 chronologies, et écrivez 3,5 Mo de données dans le désordre, dont 2 500 chronologies.
Les résultats des tests sont présentés dans le tableau ci-dessous :

La surcharge du processeur est réduite de 88,76 %, le délai total est réduit de 83 % et l'amélioration de l'efficacité est très évidente.
Résumer
Les premières versions d'openGemini prenaient en charge l'écriture de données dans le désordre, et la méthode utilisée était relativement simple et grossière. En conséquence, dans les scénarios d'application réels, en raison de l'augmentation continue des données dans le désordre, les ressources informatiques des nœuds étaient consommées significativement. Après avoir reçu des commentaires sur les problèmes, la communauté a procédé à une optimisation détaillée et, à en juger par les résultats des tests, les objectifs d'optimisation ont été atteints . À en juger par l'effet réel de l'application, dans l'environnement de production d'une certaine entreprise au sein de Huawei Cloud, il y a environ 10 000 fichiers en panne et le nombre de oscille entre un million et cent millions. d'environ cent fois +.
L'expérience utilisateur ultime est la direction . Tout le monde est invité à faire part de ses commentaires à la communauté sur les problèmes courants rencontrés lors de l'utilisation pour aider openGemini à se développer.
Site officiel d'openGemini : http://www.openGemini.org
Adresse open source openGemini : https://github.com/openGemini
Compte public openGemini :

Bienvenue à prêter attention ~ Nous vous invitons sincèrement à rejoindre la communauté openGemini pour construire, gouverner et partager l'avenir ensemble !
L'auteur du framework open source NanUI s'est tourné vers la vente d'acier et le projet a été suspendu. La liste gratuite numéro un dans l'App Store d'Apple est le logiciel pornographique TypeScript. Il vient de devenir populaire, pourquoi les grands commencent-ils à l'abandonner ? Liste TIOBE d'octobre : Java connaît la plus forte baisse, C# se rapproche de Java Rust 1.73.0 publié Un homme a été encouragé par sa petite amie IA à assassiner la reine d'Angleterre et a été condamné à neuf ans de prison Qt 6.6 officiellement publié Reuters : RISC-V la technologie devient la clé de la guerre technologique sino-américaine Nouveau champ de bataille RISC-V : non contrôlé par une seule entreprise ou un seul pays, Lenovo prévoit de lancer un PC Android