Auteur : Cheyang
Avis précédent :
Cette série présentera comment prendre en charge et optimiser les scénarios d'accès aux données dans le cloud hybride basés sur ACK Fluid. Veuillez vous référer aux articles connexes :
-Accès aux données optimisé pour le cloud hybride basé sur ACK Fluid (1) : Scénarios et architecture
Dans l'article précédent, nous avons discuté du premier jour de combinaison de Kubernetes et de données dans un scénario de cloud hybride : résoudre le problème de l'accès aux données et réaliser la connexion entre le cloud computing et le stockage hors ligne. Sur cette base, ACK Fluid résout davantage les problèmes de coût et de performances de l’accès aux données. Au début du deuxième jour, lorsque les utilisateurs utilisent réellement cette solution dans un environnement de production, le principal défi est de savoir comment gérer la synchronisation des données des clusters multirégionaux du côté de l'exploitation et de la maintenance.
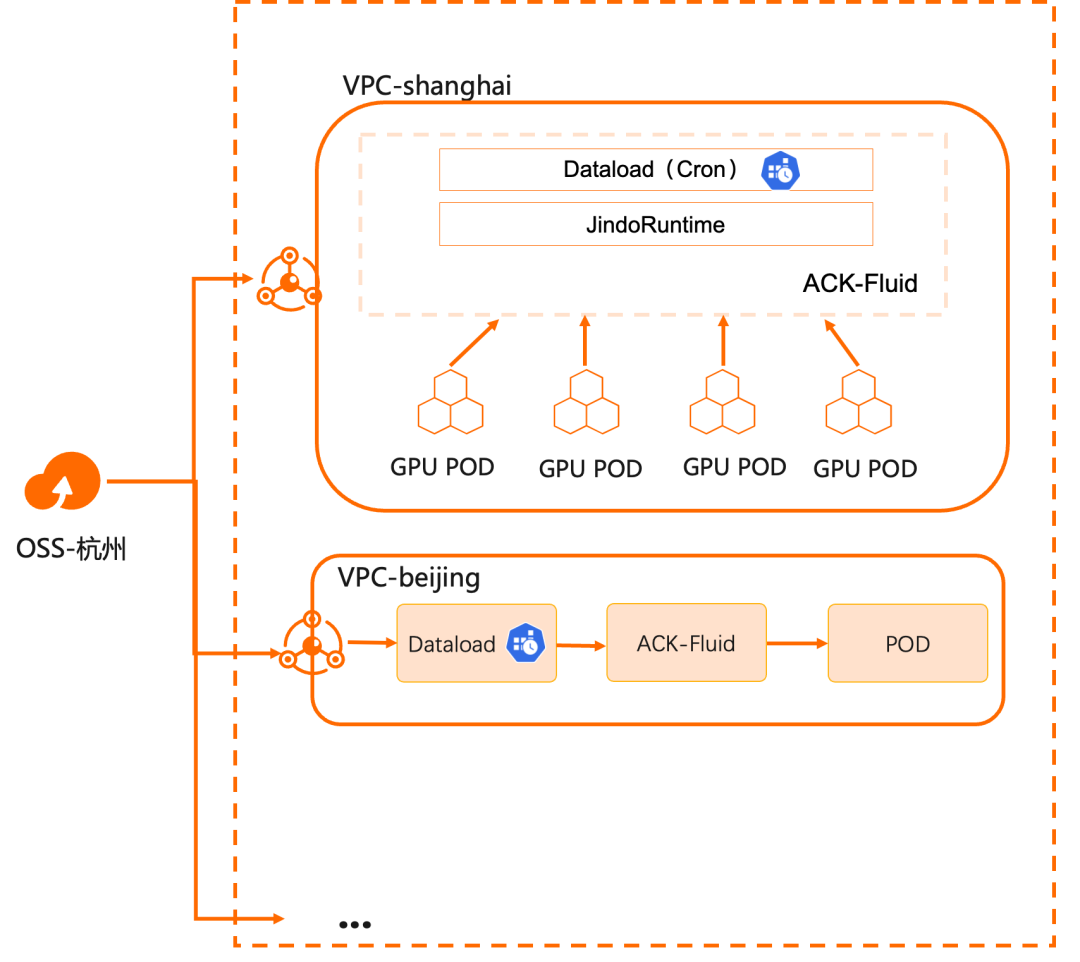
Aperçu
De nombreuses entreprises établiront plusieurs clusters informatiques dans différentes régions à des fins de performances, de sécurité, de stabilité et d'isolation des ressources. Et ces clusters informatiques nécessitent un accès à distance à un magasin de données unique et centralisé. Par exemple, à mesure que les grands modèles de langage mûrissent progressivement, les services d'inférence multirégionaux basés sur ceux-ci sont progressivement devenus des capacités que diverses entreprises doivent prendre en charge. Ceci est un exemple spécifique de ce scénario, qui présente des défis considérables :
- La synchronisation manuelle des données sur plusieurs clusters informatiques dans les centres de données prend beaucoup de temps
- En prenant comme exemple un grand modèle de langage, il existe de nombreux paramètres, des fichiers volumineux, de grandes quantités et une gestion complexe : différentes entreprises choisissent différents modèles de base et données commerciales, il existe donc des différences dans les modèles finaux.
- Les données du modèle seront continuellement mises à jour et itérées en fonction des entrées de l'entreprise, et les données du modèle seront mises à jour fréquemment.
- Le service d'inférence de modèle démarre lentement et prend beaucoup de temps pour extraire les fichiers : l'échelle de paramètres des modèles de langage à grande échelle est assez grande et le volume est généralement très important, voire des centaines de Go, ce qui entraîne une extraction extrêmement longue vers le Mémoire GPU et temps de démarrage très lent.
- Les mises à jour de modèles nécessitent que toutes les régions soient mises à jour simultanément, et les tâches de réplication sur un cluster de stockage surchargé ont un impact important sur les performances des charges de travail existantes.
En plus de fournir les capacités d'accélération d'un client de stockage universel, ACK Fluid fournit également des capacités de migration et de préchauffage de données planifiées et déclenchées, simplifiant ainsi la complexité de la distribution des données.
- Économisez sur les coûts de réseau et de calcul : les coûts de trafic interrégional sont considérablement réduits, le temps de calcul est considérablement réduit et les coûts des clusters informatiques sont légèrement augmentés ; et cela peut être encore optimisé grâce à l'élasticité.
- Les mises à jour des données des applications sont considérablement accélérées : étant donné que l'accès aux données calculé est communiqué au sein du même centre de données ou de la même zone de disponibilité, la latence est réduite et la capacité de simultanéité du débit du cache peut être étendue de manière linéaire.
- Réduisez les opérations complexes de synchronisation des données : contrôlez les opérations de synchronisation des données grâce à des politiques personnalisées, réduisez les conflits d'accès aux données et réduisez la complexité de l'exploitation et de la maintenance grâce à l'automatisation.
Démo
Cette démonstration présente comment mettre à jour les données accessibles aux clusters informatiques de l'utilisateur dans différentes régions via le mécanisme de préchauffage programmé d'ACK Fluid.
Conditions préalables
- Un cluster de version ACK Pro a été créé et la version du cluster est 1.18 et supérieure. Pour des opérations spécifiques, voir Création d'un cluster ACK Pro Edition [ 1] .
- La suite d'IA native cloud a été installée et le composant ack-fluid a été déployé. Important : Si vous avez installé Fluid open source, veuillez le désinstaller avant de déployer le composant ack-fluid.
<!---->
- La suite d'IA native cloud n'est pas installée : activez l'accélération fluide des données lors de l'installation . Pour des opérations spécifiques, voir Installation de Cloud Native AI Suite [ 2] .
- La suite d'IA native cloud a été installée : déployez ack-fluid sur la page de la suite d'IA native du cloud de la console de gestion de Container Service [ 3] .
<!---->
- Le cluster Kubernetes a été connecté via kubectl. Pour des opérations spécifiques, voir Connexion au cluster via l'outil kubectl [ 4] .
Informations d'arrière-plan
Préparez les conditions pour les environnements K8 et OSS, et cela ne prend que 10 minutes environ pour terminer le déploiement de l'environnement JindoRuntime.
Étape 1 : Préparer les données du compartiment OSS
- Exécutez la commande suivante pour télécharger une copie des données de test.
$ wget https://archive.apache.org/dist/hbase/2.5.2/RELEASENOTES.md
- Téléchargez les données de test téléchargées dans le bucket correspondant à Alibaba Cloud OSS. Vous pouvez utiliser l'outil client ossutil fourni par OSS pour la méthode de téléchargement. Pour des opérations spécifiques, voir Installation d'ossutil [ 5] .
$ ossutil cp RELEASENOTES.md oss://<bucket>/<path>/RELEASENOTES.md
Étape 2 : Créer un ensemble de données et JindoRuntime
- Avant de créer un ensemble de données, vous pouvez créer un fichier mySecret.yaml pour enregistrer l'accessKeyId et l'accessKeySecret d'OSS.
L'exemple YAML pour créer le fichier mySecret.yaml est le suivant :
apiVersion: v1
kind: Secret
metadata:
name: mysecret
stringData:
fs.oss.accessKeyId: xxx
fs.oss.accessKeySecret: xxx
- Exécutez la commande suivante pour générer un secret.
$ kubectl create -f mySecret.yaml
- Utilisez l'exemple de fichier YAML suivant pour créer un fichier nommé dataset.yaml et contenant deux parties :
- Créez un ensemble de données pour décrire l'ensemble de données de stockage distant et les informations UFS.
- Créez un JindoRuntime et démarrez un cluster JindoFS pour fournir des services de mise en cache.
apiVersion: data.fluid.io/v1alpha1
kind: Dataset
metadata:
name: demo
spec:
mounts:
- mountPoint: oss://<bucket-name>/<path>
options:
fs.oss.endpoint: <oss-endpoint>
name: hbase
path: "/"
encryptOptions:
- name: fs.oss.accessKeyId
valueFrom:
secretKeyRef:
name: mysecret
key: fs.oss.accessKeyId
- name: fs.oss.accessKeySecret
valueFrom:
secretKeyRef:
name: mysecret
key: fs.oss.accessKeySecret
accessModes:
- ReadOnlyMany
---
apiVersion: data.fluid.io/v1alpha1
kind: JindoRuntime
metadata:
name: demo
spec:
replicas: 1
tieredstore:
levels:
- mediumtype: MEM
path: /dev/shm
quota: 2Gi
high: "0.99"
low: "0.8"
fuse:
args:
- -okernel_cache
- -oro
- -oattr_timeout=60
- -oentry_timeout=60
- -onegative_timeout=60
Les paramètres pertinents sont expliqués dans le tableau suivant :
| paramètre | illustrer |
|---|---|
| point de montage | oss://<oss_bucket>/<path> indique le chemin d'accès pour monter UFS et le chemin n'a pas besoin de contenir d'informations sur le point de terminaison. |
| fs.oss.endpoint | Les informations de point de terminaison du compartiment OSS peuvent être soit une adresse de réseau public, soit une adresse de réseau privé. |
| Modes d'accès | Représente le mode d'accès de l'ensemble de données. |
| les répliques | Indique le nombre de Workers créant le cluster JindoFS. |
| type moyen | Indique le type de cache. Lors de la définition et de la création d'exemples de modèles JindoRuntime, JindoFS prend temporairement en charge l'un des types de cache dans HDD/SSD/MEM. |
| chemin | Indique le chemin de stockage. Actuellement, un seul chemin est pris en charge. Lorsque vous sélectionnez MEM pour la mise en cache, vous devez spécifier un chemin local pour stocker les fichiers tels que le journal. |
| quota | Indique la capacité maximale du cache, en Go. La capacité du cache peut être configurée en fonction de la taille des données UFS. |
| haut | Indique la limite supérieure de la capacité de stockage. |
| faible | Indique la limite inférieure de la capacité de stockage. |
| fusible.args | Représente les paramètres facultatifs de montage du client de fusible. Généralement utilisé en conjonction avec le mode d'accès de Dataset. Lorsque le mode d'accès à l'ensemble de données est ReadOnlyMany, nous permettons à kernel_cache d'utiliser le cache du noyau pour optimiser les performances de lecture. À ce stade, nous pouvons définir attr_timeout (durée de rétention du cache d'attribut de fichier), Entry_timeout (durée de rétention du cache de lecture du nom de fichier), négative_timeout (durée de rétention du cache d'échec de lecture du nom de fichier), la valeur par défaut est 7 200 s. Lorsque le mode d'accès au Dataset est ReadWriteMany, nous vous recommandons d'utiliser la configuration par défaut. Les paramètres à ce stade sont les suivants : - -oauto_cache - -oattr_timeout=0 - -oentry_timeout=0 - -onegative_timeout=0 Utilisez auto_cache pour garantir que si la taille du fichier ou l'heure de modification change, le cache ne sera pas valide. Dans le même temps, définissez le délai d'attente sur 0. |
- Exécutez les commandes suivantes pour créer JindoRuntime et Dataset.
$ kubectl create -f dataset.yaml
- Exécutez la commande suivante pour afficher le déploiement de Dataset.
$ kubectl get dataset
Production attendue:
NAME UFS TOTAL SIZE CACHED CACHE CAPACITY CACHED PERCENTAGE PHASE AGE
demo 588.90KiB 0.00B 10.00GiB 0.0% Bound 2m7s
Étape 3 : Créer un chargement de données prenant en charge l'exécution planifiée
- Utilisez l'exemple de fichier YAML suivant pour créer un fichier nommé dataload.yaml.
apiVersion: data.fluid.io/v1alpha1
kind: DataLoad
metadata:
name: cron-dataload
spec:
dataset:
name: demo
namespace: default
policy: Cron
schedule: "*/2 * * * *" # Run every 2 min
Les paramètres pertinents sont expliqués dans le tableau suivant :
| paramètre | illustrer |
|---|---|
| base de données | Indique le nom et l'espace de noms de l'ensemble de données dans lequel le chargement de données est exécuté. |
| politique | Indique la stratégie d'exécution, prend actuellement en charge Once et Cron. Créez ici une tâche de chargement de données planifiée. |
| calendrier | Indique la stratégie de déclenchement du chargement de données. |
scheule utilise le format cron suivant :
# ┌───────────── 分钟 (0 - 59)
# │ ┌───────────── 小时 (0 - 23)
# │ │ ┌───────────── 月的某天 (1 - 31)
# │ │ │ ┌───────────── 月份 (1 - 12)
# │ │ │ │ ┌───────────── 周的某天 (0 - 6)(周日到周一;在某些系统上,7 也是星期日)
# │ │ │ │ │ 或者是 sun,mon,tue,web,thu,fri,sat
# │ │ │ │ │
# │ │ │ │ │
# * * * * *
De plus, cron prend en charge les opérateurs suivants :
- La virgule (,) indique une énumération, par exemple : 1,3,4,7 * * * * indique que Dataload sera exécuté à 1, 3, 4 et 7 minutes toutes les heures.
- Le trait d'union (-) représente la plage, par exemple : 1-6 * * * * signifie qu'il sera exécuté toutes les minutes entre 1 et 6 minutes chaque heure.
- Un astérisque (*) représente toute valeur possible. Par exemple : un astérisque dans le « champ heure » équivaut à « toutes les heures ».
- Le signe pourcentage (%) signifie « chaque ». Par exemple : *%10 * * * * signifie une exécution toutes les 10 minutes.
- Les barres obliques (/) sont utilisées pour décrire les incréments de plage. Par exemple : */2 * * * * signifie une exécution toutes les 2 minutes.
Vous pouvez également consulter plus d’informations ici.
Pour la configuration avancée liée à Dataload, veuillez vous référer au fichier de configuration suivant :
apiVersion: data.fluid.io/v1alpha1
kind: DataLoad
metadata:
name: cron-dataload
spec:
dataset:
name: demo
namespace: default
policy: Cron # including Once, Cron
schedule: * * * * * # only set when policy is cron
loadMetadata: true
target:
- path: <path1>
replicas: 1
- path: <path2>
replicas: 2
Les paramètres pertinents sont expliqués dans le tableau suivant :
| paramètre | illustrer |
|---|---|
| politique | Indique la stratégie d'exécution du chargement de données, y compris [Once, Cron]. |
| calendrier | Indique le plan utilisé par cron. Il n'est valide que lorsque la politique est Cron. |
| charger les métadonnées | Indique s’il faut synchroniser les métadonnées avant le chargement des données. |
| cible | Indique la cible du chargement de données et prend en charge la spécification de plusieurs cibles. |
| chemin | Indique le chemin pour exécuter le chargement de données. |
| les répliques | Indique le nombre de copies mises en cache. |
- Exécutez la commande suivante pour créer Dataload.
$ kubectl apply -f dataload.yaml
- Exécutez la commande suivante pour vérifier l'état du chargement de données.
$ kubectl get dataload
Production attendue:
NAME DATASET PHASE AGE DURATION
cron-dataload demo Complete 3m51s 2m12s
- Après avoir attendu que l'état du chargement de données soit terminé, exécutez la commande suivante pour afficher l'état actuel de l'ensemble de données.
$ kubectl get dataset
Production attendue:
NAME UFS TOTAL SIZE CACHED CACHE CAPACITY CACHED PERCENTAGE PHASE AGE
demo 588.90KiB 588.90KiB 10.00GiB 100.0% Bound 5m50s
On peut voir que tous les fichiers d'oss ont été chargés dans le cache.
Étape 4 : Créer un conteneur d'applications pour accéder aux données dans OSS
Cet article crée un conteneur d'application pour accéder aux fichiers ci-dessus afin de voir l'effet du chargement de données planifié.
- À l’aide de l’exemple de fichier YAML suivant, créez un fichier nommé app.yaml.
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
volumeMounts:
- mountPath: /data
name: demo-vol
volumes:
- name: demo-vol
persistentVolumeClaim:
claimName: demo
- Exécutez la commande suivante pour créer un conteneur d'application.
$ kubectl create -f app.yaml
- Attendez que le conteneur d'application soit prêt et exécutez la commande suivante pour afficher les données dans OSS :
$ kubectl exec -it nginx -- ls -lh /data
Production attendue:
total 589K
-rwxrwxr-x 1 root root 589K Jul 31 04:20 RELEASENOTES.md
- Afin de vérifier l'effet du chargement de données mettant régulièrement à jour le fichier sous-jacent, nous modifions le contenu de RELEASENOTES.md et le téléchargeons à nouveau avant le déclenchement du chargement de données planifié.
$ echo "hello, crondataload." >> RELEASENOTES.md
Téléchargez à nouveau le fichier sur oss.
$ ossutil cp RELEASENOTES.md oss://<bucket-name>/<path>/RELEASENOTES.md
- Attendez que la tâche de chargement de données se déclenche. Une fois la tâche Dataload terminée, exécutez la commande suivante pour afficher l'état d'exécution de la tâche Dataload :
$ kubectl describe dataload cron-dataload
Production attendue:
...
Status:
Conditions:
Last Probe Time: 2023-07-31T04:30:07Z
Last Transition Time: 2023-07-31T04:30:07Z
Status: True
Type: Complete
Duration: 5m54s
Last Schedule Time: 2023-07-31T04:30:00Z
Last Successful Time: 2023-07-31T04:30:07Z
Phase: Complete
...
Parmi eux, la dernière heure de planification dans Status est l'heure de planification de la dernière tâche de chargement de données, et la dernière heure de réussite est l'heure d'achèvement de la dernière tâche de chargement de données.
À ce stade, vous pouvez exécuter la commande suivante pour afficher l'état actuel de l'ensemble de données :
$ kubectl get dataset
Production attendue:
NAME UFS TOTAL SIZE CACHED CACHE CAPACITY CACHED PERCENTAGE PHASE AGE
demo 588.90KiB 1.15MiB 10.00GiB 100.0% Bound 10m
On peut voir que le fichier mis à jour a également été chargé dans le cache.
- Exécutez la commande suivante pour afficher les fichiers mis à jour dans le conteneur d'application :
$ kubectl exec -it nginx -- tail /data/RELEASENOTES.md
Production attendue:
\<name\>hbase.config.read.zookeeper.config\</name\>
\<value\>true\</value\>
\<description\>
Set to true to allow HBaseConfiguration to read the
zoo.cfg file for ZooKeeper properties. Switching this to true
is not recommended, since the functionality of reading ZK
properties from a zoo.cfg file has been deprecated.
\</description\>
\</property\>
hello, crondataload.
Comme vous pouvez le voir sur la dernière ligne, le fichier mis à jour est désormais accessible au conteneur d'application.
nettoyage de l'environnement
Lorsque vous n'utilisez plus la fonctionnalité d'accélération des données, vous devez nettoyer l'environnement.
Exécutez la commande suivante pour supprimer JindoRuntime et les conteneurs d'applications.
$ kubectl delete -f app.yaml
$ kubectl delete -f dataset.yaml
Résumer
La discussion sur l'accès aux données optimisé pour le cloud hybride basé sur ACK Fluid se termine ici. L'équipe Alibaba Cloud Container Service continuera à itérer et à optimiser avec les utilisateurs dans ce scénario. À mesure que la pratique continue de s'approfondir, cette série continuera à être mise à jour.
Liens connexes:
[1] Créer un cluster de version ACK Pro https://help.aliyun.com/document_detail/176833.html#task-skz-qwk-qfb
[2] Installer la suite d'IA native du cloud
[3] Console de gestion des services de conteneurs
https://account.aliyun.com/login/login.htm?oauth_callback=https%3A%2F%2Fcs.console.aliyun.com%2F
[4] Connectez-vous au cluster via l'outil kubectl
[5] Installer ossutil
https://help.aliyun.com/zh/oss/developer-reference/install-ossutil#concept-303829
L'auteur du framework open source NanUI s'est tourné vers la vente d'acier et le projet a été suspendu. La liste gratuite numéro un dans l'App Store d'Apple est le logiciel pornographique TypeScript. Il vient de devenir populaire, pourquoi les grands commencent-ils à l'abandonner ? Liste TIOBE d'octobre : Java connaît la plus forte baisse, C# se rapproche de Java Rust 1.73.0 publié Un homme a été encouragé par sa petite amie IA à assassiner la reine d'Angleterre et a été condamné à neuf ans de prison Qt 6.6 officiellement publié Reuters : RISC-V la technologie devient la clé de la guerre technologique sino-américaine Nouveau champ de bataille RISC-V : non contrôlé par une seule entreprise ou un seul pays, Lenovo prévoit de lancer un PC Android