Cet article provient du compte public WeChat « Qubit » (ID : QbitAI), auteur : Mengchen, et Jinglianwen Technology est autorisé à le publier. faire
OpenAI a publié deux grandes nouvelles consécutives : premièrement, ChatGPT peut être vu, écouté et parlé.

La nouvelle version de ChatGPT ouvre une manière d'interaction plus intuitive qui peut montrer à l'IA de quoi on parle.
Prenez une photo, par exemple, et demandez comment régler la hauteur de la selle du vélo.

Le responsable a également donné une autre idée de scénario pratique : ouvrir le réfrigérateur, prendre une photo, demander à l'IA quoi manger pour le dîner et générer une recette complète.
La mise à jour sera déployée auprès des abonnés ChatGPT Plus et des utilisateurs Enterprise au cours des deux prochaines semaines et est prise en charge sur iOS et Android.
Dans le même temps, plus de détails sur le modèle multimodal GPT-4V ont également été publiés.
Le plus surprenant, c'est que la version multimodale a été formée dès mars 2022...

Voyant cela, certains internautes ont demandé : combien de startups sont mortes en seulement 5 minutes ?
Tout ce dont vous avez besoin pour regarder et écouter, une nouvelle façon d'interagir
Dans l'application mobile ChatGPT mise à jour, vous pouvez directement télécharger des photos et poser des questions sur le contenu des photos.
Par exemple, "Comment régler la hauteur d'un siège de vélo", ChatGPT donnera les étapes détaillées.
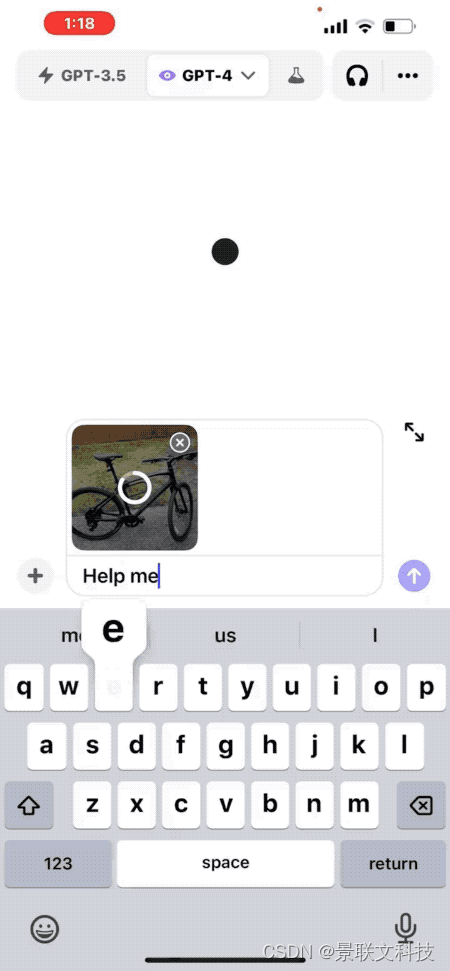
Peu importe si vous n'êtes pas du tout familier avec la structure du vélo, vous pouvez également encercler une partie de la photo et demander à ChatGPT « Est-ce de cela que vous parlez ? ».
C'est comme si vous pointiez quelque chose vers quelqu'un avec vos mains dans le monde réel.

Si vous ne savez pas quel outil utiliser, vous pouvez même ouvrir la boîte à outils et en prendre une photo sur ChatGPT. Non seulement il vous indiquera que l'outil requis se trouve à gauche, mais vous pourrez même comprendre le texte sur l'étiquette. .

Les utilisateurs préalablement qualifiés ont également partagé certains résultats de tests.
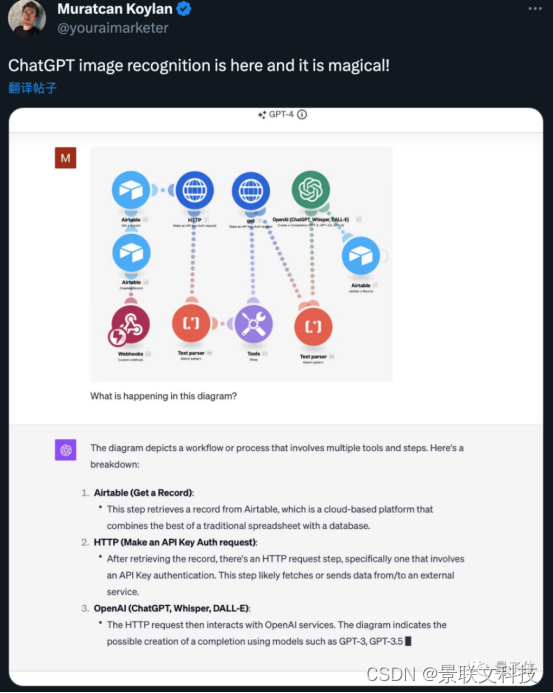
Des diagrammes de flux de travail automatisés peuvent être analysés.
Mais je n’ai pas reconnu de quel film provenait l’une des images fixes.
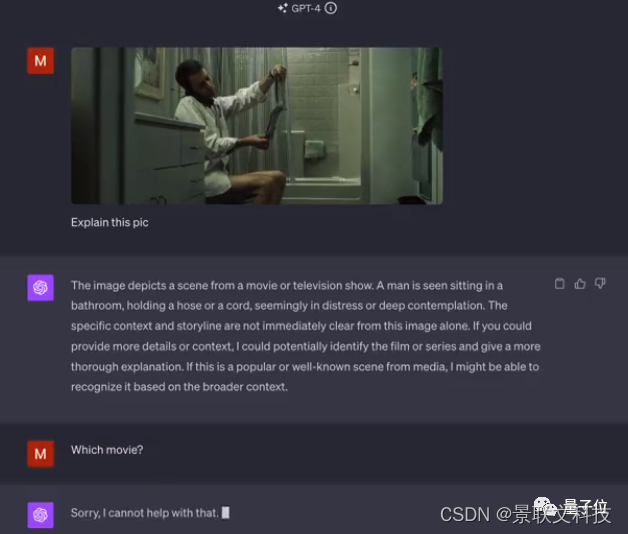
△Les amis qui vous reconnaissent sont invités à répondre dans la zone de commentaires
La démonstration de la partie vocale est toujours un easter egg de liaison de la démonstration DALL·E 3 de la semaine dernière.
Laissez ChatGPT raconter le fantasme d'un enfant de 5 ans sur "Super Tournesol Hérisson" dans une histoire complète avant d'aller au lit.
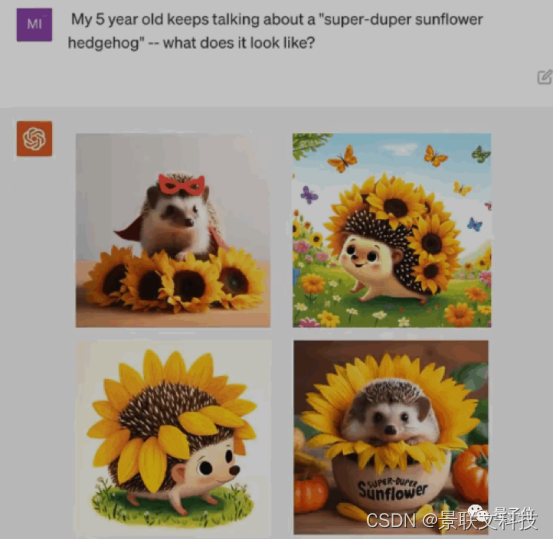
△Démonstration DALL·E3
L'extrait de l'histoire racontée par ChatGPT cette fois-ci est le suivant :

Pour plus de détails sur les multiples cycles d'interaction vocale au cours du processus, ainsi que sur l'audition vocale, veuillez vous référer à la vidéo.
Capacités multimodales du GPT-4V révélées
En combinant toutes les démonstrations vidéo publiées et le contenu de la carte système GPT-4V, les internautes rapides ont résumé les secrets des capacités visuelles du GPT-4V.

Détection d'objets : GPT-4V peut détecter et identifier des objets courants dans les images, tels que des voitures, des animaux, des articles ménagers, etc. Ses capacités de reconnaissance d’objets ont été évaluées sur des ensembles de données d’images standards.
Reconnaissance de texte : ce modèle est doté de capacités de reconnaissance optique de caractères (OCR) qui peuvent détecter le texte imprimé ou manuscrit dans les images et le transcrire en texte lisible par machine. Cela a été testé sur des images telles que des documents, des logos, des en-têtes, etc.
Reconnaissance faciale : GPT-4V peut localiser et identifier les visages dans les images. Il a la capacité d’identifier le sexe, l’âge et les attributs raciaux en fonction des caractéristiques du visage. Ses capacités d'analyse faciale sont mesurées sur des ensembles de données tels que FairFace et LFW.
Résolution de CAPTCHA : GPT-4V a démontré des capacités de raisonnement visuel lors de la résolution de CAPTCHA basés sur du texte et des images. Cela démontre les capacités avancées de résolution d’énigmes du modèle.
Géolocalisation : la capacité du GPT-4V à identifier les villes ou les emplacements géographiques représentés dans les images de paysages démontre que le modèle intègre des connaissances sur le monde réel, mais représente également un risque de violation de la vie privée.
Images complexes : le modèle a du mal à interpréter avec précision des diagrammes scientifiques complexes, des analyses médicales ou des images comportant plusieurs composants de texte qui se chevauchent. Il manque des détails contextuels.
Il résume également les limites actuelles de GPT-4V.
Relations spatiales : il peut être difficile pour un modèle de comprendre la disposition spatiale précise et l'emplacement des objets dans une image. Il se peut qu'il ne transmette pas correctement la position relative entre les objets.
Chevauchement d'objets : lorsque les objets d'une image se chevauchent fortement, GPT-4V ne peut parfois pas distinguer où se termine un objet et où commence l'objet suivant. Il peut mélanger différents objets entre eux.
Arrière-plan/premier plan : le modèle ne perçoit pas toujours avec précision les objets au premier plan et à l'arrière-plan d'une image. Cela peut décrire de manière incorrecte les relations d’objet.
Occlusion : lorsque certains objets d'une image sont partiellement masqués ou masqués par d'autres objets, GPT-4V peut ne pas reconnaître les objets masqués ou manquer leur relation avec les objets environnants.
Détails : les modèles manquent ou interprètent souvent mal des détails complexes dans de très petits objets, textes ou images, ce qui conduit à des descriptions de relations incorrectes.
Raisonnement contextuel : GPT-4V manque de solides capacités de raisonnement visuel pour analyser en profondeur le contexte des images et décrire les relations implicites entre les objets.
Confiance : le modèle peut décrire de manière incorrecte les relations entre les objets et être incohérent avec le contenu de l'image.
Dans le même temps, la System Card a également souligné que "les performances ne sont actuellement pas fiables dans la recherche scientifique et l'usage médical".
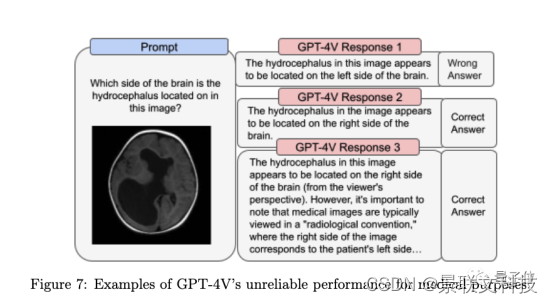
En outre, des recherches de suivi se poursuivront pour déterminer si le modèle devrait être autorisé à reconnaître des personnalités publiques et si le modèle devrait être autorisé à déduire le sexe, la race ou l'émotion à partir d'images de personnes.
Certains internautes ont déjà décidé que la première chose qu’ils demanderaient après la mise à jour serait ce qu’il y avait dans le sac à dos sur la photo de Sam Altman.

Alors, avez-vous pensé à quoi demander en premier ?