01 Modèle de langage pré-entraîné VS modèle de dialogue pré-entraîné
1. Modèle linguistique à grande échelle
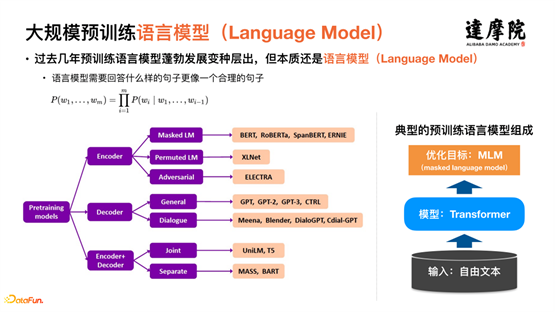
Le progrès majeur dans le domaine de la PNL ces dernières années a été l’émergence et l’utilisation à grande échelle de modèles pré-entraînés à grande échelle. Les modèles linguistiques pré-entraînés se sont considérablement développés et de nombreuses variantes sont apparues. Cependant, il s'agit toujours essentiellement de modèles de langage. Comme le montre l'organigramme situé à droite de la figure ci-dessus, l'entrée est essentiellement du texte libre sur Internet, les modèles sont essentiellement des structures Transformer et les objectifs d'optimisation sont essentiellement MLM (Mask Modèle de langage). .

Les modèles linguistiques pré-entraînés ont apporté de grands progrès dans l'ensemble du domaine de la PNL.Après avoir atteint le domaine du dialogue, des caractéristiques plus uniques dans le domaine du dialogue peuvent être extraites davantage. Comme le montre la figure ci-dessus, le texte libre sur le réseau à gauche est le corpus requis pour les modèles de pré-formation à grande échelle, et le corpus à droite représente le dialogue. Intuitivement, il y a une grande différence.

Le dialogue est une application avancée du langage et présente les principales caractéristiques suivantes :
① Expression familière et informelle, pas nécessairement grammaticale, phrases incomplètes, beaucoup de bruit et de nombreuses erreurs ASR.
② Divisez les rôles en plusieurs tours, avec au moins deux sujets participants. Il y a des omissions, des références, un héritage d'état, un oubli d'état, etc.
③Contraintes de connaissances verticales.Chaque tâche de dialogue a ses propres contraintes de connaissances et le modèle doit être utilisé de manière ciblée.
④ Une compréhension sémantique approfondie nécessite une compréhension approfondie du langage, des Intent-Slots/du raisonnement logique, etc.
⑤ Faites attention aux stratégies de dialogue. Afin d'atteindre des objectifs de tâche spécifiques, vous devez savoir quoi dire.
2. Modèle de langage pré-entraîné VS modèle de dialogue pré-entraîné
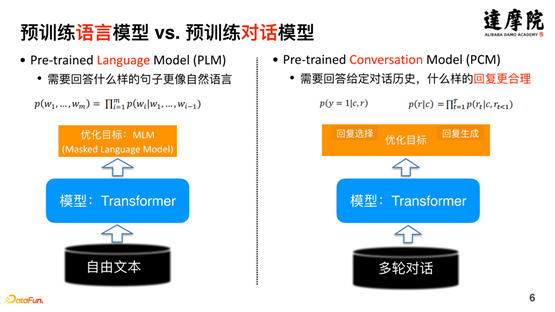
Sur la base des caractéristiques uniques des données de dialogue, un modèle de dialogue pré-entraîné unique est développé sur la base du modèle pré-entraîné. Comme le montre le côté gauche de la figure ci-dessus, l'objectif d'optimisation du modèle de langage pré-entraîné est de déterminer quels types de phrases ressemblent le plus au langage naturel ; tandis que le côté droit de la figure ci-dessus représente le modèle de dialogue pré-entraîné. D'un point de vue de bout en bout, son objectif d'optimisation Il est nécessaire de déterminer quel type de réponse est le plus raisonnable compte tenu de l'historique de la conversation. Il s'agit d'une grande différence entre les modèles de langage pré-entraînés et les modèles de dialogue pré-entraînés.
3. Progrès dans les modèles de dialogue pré-formation
Le dialogue est principalement divisé en trois parties : la compréhension du dialogue, la stratégie de dialogue et la génération du dialogue. Début 2021, les modèles de dialogue pré-entraînés ont beaucoup évolué. Comme le montre la figure ci-dessous, dans le domaine de la compréhension du dialogue, PolyAI a proposé le modèle ConveRT en 2019, Salesforce a proposé le modèle TOD-BERT en 2020 et JingDong a proposé le modèle DialogBERT en 2021.


L'émergence de modèles de dialogue pré-entraînés axés sur la compréhension a apporté d'énormes améliorations à la compréhension du dialogue par rapport aux modèles de langage pré-entraînés. Comme le montre la figure ci-dessus, un article sur les résultats expérimentaux d'EMNLP2020 (Probing Task-Oriented Dialogue Representation from Language Models). montrent que par rapport aux modèles de langage pré-entraînés, les modèles de dialogue pré-entraînés peuvent améliorer les performances des tâches de compréhension du dialogue de plus de 10 % ; dans l'apprentissage des représentations, ils peuvent également apprendre de meilleures représentations et avoir un meilleur effet de regroupement. Cela peut être compris de manière courante, car les modèles de pré-formation actuels (y compris les modèles de langage et de dialogue) sont essentiellement basés sur les données. Par conséquent, les modèles de pré-formation formés sur les données de dialogue sont naturellement meilleurs en dialogue que les modèles formés sur du texte libre. Les champs sont plus expressifs.

Outre la compréhension du dialogue, il existe également le domaine de la génération du dialogue.
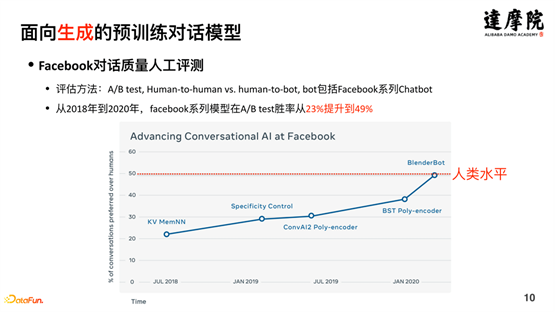
Microsoft a proposé DialoGPT en 2019, Google a proposé Meena en 2020, Facebook a proposé Blender en 2020 et Baidu a proposé PLATO-2 en 2021. L'émergence de ces modèles a également apporté de grandes améliorations à la qualité de la génération de dialogues à promouvoir. Comme le montre la figure ci-dessous, le modèle Blender de Facebook a augmenté son taux de réussite aux tests A/B de 23 % à 49 % de 2018 à 2020.
Ce qui précède est une brève introduction à l'ensemble du modèle de dialogue pré-entraîné, ce qui est très utile pour comprendre le modèle proposé dans cet article. En général, l'émergence de modèles de langage pré-entraînés a considérablement amélioré les performances de toutes les tâches de PNL, et les modèles de dialogue pré-entraînés basés sur des modèles de langage pré-entraînés ont encore amélioré les performances des tâches de PNL dans le domaine du dialogue. Par conséquent, le dialogue intelligent basé sur des modèles de dialogue pré-entraînés est devenu un modèle de base.
--
02 « Pas de dialogue sans connaissance » : La connaissance est la base du dialogue
Une autre caractéristique très importante du dialogue est qu’il s’appuie fortement sur la connaissance. En d’autres termes, la connaissance est la base du dialogue.
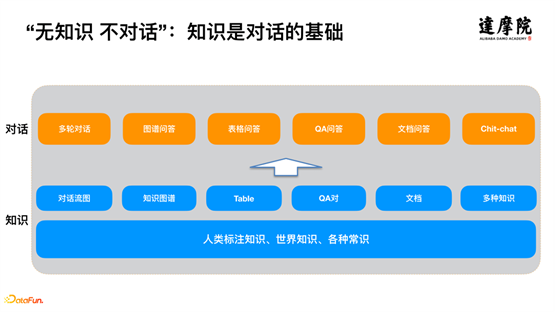
Comme le montre l'architecture de dialogue de la figure ci-dessus, les moteurs de dialogue traditionnels de niveau supérieur , tels que le dialogue à plusieurs tours, les questions-réponses sur graphiques, les questions-réponses sur table, les questions-réponses sur l'assurance qualité, les questions-réponses sur les documents, les discussions en direct, etc., sont divisés en fonction sur les connaissances sous-jacentes . Par exemple, le moteur de dialogue multi-tours est principalement basé sur l'organigramme de dialogue ; le graphique question-réponse repose sur la connaissance du graphe de connaissances, etc. En plus de ces connaissances évidentes, si vous voulez faire du bon travail dans un dialogue intelligent, vous avez également besoin d'autres connaissances, telles que la connaissance des annotations humaines, la connaissance du monde, divers bons sens, etc.
Ici, nous prenons comme cas de référence la tâche de gestion de l’assurance automobile. Cette tâche est une tâche de type processus, c'est-à-dire qu'il existe des étapes et des processus pour souscrire une assurance. Tout d'abord, vérifiez les informations personnelles et les documents, y compris la carte d'identité, le permis de conduire, le permis de conduire, etc. ; puis démarrez l'inspection du véhicule et générez le résultat de l'inspection du véhicule : si le résultat de l'inspection du véhicule échoue, la raison de l'échec de l'inspection du véhicule sera informée. , et le processus se termine, le résultat étant Vous ne pouvez pas demander d'assurance automobile ; si le résultat de l'inspection automobile est réussi, suivez les étapes pour remplir la police, y compris le type d'assurance automobile, les informations assurées, etc., puis payez la prime d'assurance. et obtenez le talon d'assurance.
Il s'agit d'une tâche de processus typique qui doit être gérée via un dialogue basé sur les tâches. Une caractéristique distinctive de la connaissance des processus est que, dans la plupart des cas, l’ordre des tâches est immuable. Par exemple, vous ne pouvez pas effectuer d'abord la troisième étape, puis la première étape, sinon l'ensemble du processus sera incorrect et ne pourra pas être exécuté. La deuxième caractéristique de la connaissance des processus est que si vous examinez chaque étape de la connaissance des processus, elle contient de nombreuses autres connaissances. Par exemple, la première étape consiste à vérifier les informations personnelles et documentaires, telles que les noms. Pour les Chinois, il s'agit essentiellement de caractères chinois, et le nombre de caractères est compris entre 2 et 10 caractères. Ceux-ci appartiennent à la connaissance du monde ou au bon sens de base. ainsi que les numéros d'identification. Les cartes d'identité du continent sont toutes à 18 chiffres, etc., et elles sont toutes des catégories dans la connaissance mondiale. De plus, afin de former un dialogue basé sur des tâches utilisable, une certaine quantité de données annotées est nécessaire, et ces données annotées contiennent des connaissances humaines. Par exemple, l’étiquetage des intentions, des catégories et des émotions inscrit explicitement les connaissances humaines sur les données, formant ainsi de nouvelles connaissances. En résumé, tout le dialogue tourne autour de la connaissance : sans connaissance, il n’y a pas de dialogue.
L'introduction et l'introduction de base ont été faites ci-dessus. D'une part, pour le dialogue intelligent, le modèle de dialogue pré-entraîné est devenu le modèle de base, d'autre part, pour l'ensemble du système de dialogue, il est centré sur la connaissance. Par conséquent, nos recherches et explorations (de l’équipe d’IA conversationnelle de la Dharma Academy) au cours de la période écoulée se sont concentrées sur ces deux points. L'idée principale est de combiner les connaissances avec des modèles de dialogue pré-entraînés. Plus précisément, comme le montre la figure ci-dessus, la tâche est divisée en deux sous-tâches : l'une sous-tâche concerne la façon dont nous injectons des connaissances dans le modèle de dialogue pré-entraîné afin que le modèle ait une meilleure capacité de connaissance ; l'autre sous-tâche concerne l'application. extraire une grande quantité de connaissances apprises dans le modèle de dialogue pré-entraîné, et mieux les combiner et les utiliser avec des tâches en aval. En se concentrant sur ces deux aspects, cet article s’attachera à partager quelques travaux exploratoires.
--
03 Pré-formation semi-supervisée : une nouvelle manière d'injection de connaissances
1. Connaissance des étiquettes

La première partie concerne principalement l’infusion de connaissances. Comment injecter des connaissances dans le modèle, cet article propose une nouvelle méthode, la méthode de pré-formation semi-supervisée.

Examinez d’abord les connaissances. Il existe un type de connaissance très important : la connaissance de l'étiquetage. Sans connaissance des annotations, il est difficile de bien exécuter les tâches de PNL. Les connaissances étiquetées manuellement contiennent une grande quantité de connaissances liées aux tâches. Classification schématique, correspondance d'intentions, reconnaissance d'entités, stratégies de dialogue, émotions, etc. Ces données étiquetées expriment explicitement les connaissances humaines dans les données. Les connaissances annotées manuellement présentent les caractéristiques suivantes :
Premièrement, il est crucial d'améliorer les performances de tâches spécifiques . Bien que l'annotation de petites quantités de données telles que Few-Shot soit très populaire aujourd'hui, ce type de modèle qui ne nécessite pas de données annotées ou une petite quantité de données annotées n'a pas encore été développé. répond aux exigences de lancement d'une entreprise. Par conséquent, les données d'annotation sont très utiles pour améliorer les tâches ;
Deuxièmement, les tâches sont liées et les données sont dispersées . Autrement dit, les données marquées sur la tâche A ne peuvent pas être utilisées sur la tâche B et doivent être réétiquetées ;
Troisièmement, le montant total est faible . Par rapport aux données non supervisées, qui contiennent souvent des dizaines ou des centaines de millions d’éléments, les données étiquetées peuvent ne contenir que des centaines ou des milliers d’éléments.
Comment rassembler ces données annotées dispersées et injecter les connaissances qu'elles contiennent dans le modèle de dialogue pré-entraîné pour améliorer les capacités du modèle ? Cet article étudie et explore cette question. Si une telle opération peut être réalisée, le transfert de connaissances peut être réalisé et les connaissances des données annotées dans la tâche A peuvent être utilisées sur la tâche B, améliorant ainsi l'effet de la tâche B. Les avantages sont les suivants : premièrement, cela résout le problème du démarrage à froid ; deuxièmement, moins de données annotées sont nécessaires pour obtenir la même précision.
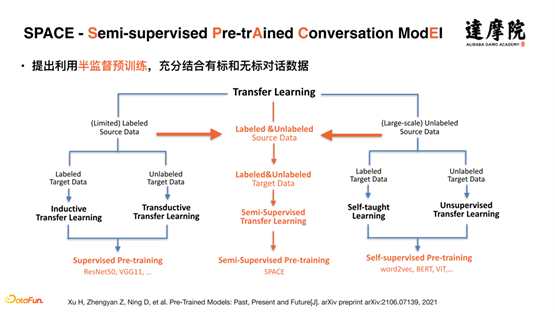
Tout d’abord, passons en revue le développement de modèles pré-entraînés. Les modèles pré-entraînés ont d’abord été utilisés dans le domaine de l’image et étaient basés sur des données supervisées. Lorsque Bert et d'autres modèles de pré-formation ont été proposés, la pré-formation a commencé à partir d'une grande quantité de données non supervisées, c'est-à-dire par un apprentissage auto-supervisé. Il existait deux méthodes de modèles de pré-formation : l'une était l'apprentissage supervisé sur des données supervisées ; l'autre était l'apprentissage auto-supervisé sur des données non supervisées. Les tâches auxquelles nous sommes confrontés aujourd'hui sont une grande quantité de données non supervisées et une petite quantité de données supervisées. Nous proposons un apprentissage semi-supervisé, qui combine des données supervisées et des données non supervisées de manière semi-supervisée. Comme le montre la figure ci-dessus, nous proposons Un modèle SPACE (Semi-supervised Pre-trAined Conversation ModEl) a été développé.
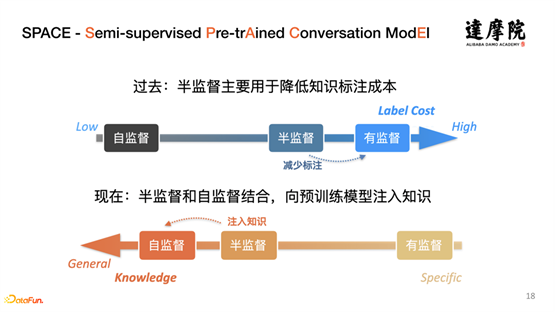
Le concept de semi-supervision a été développé depuis de nombreuses années. La méthode semi-supervisée proposée ici est différente de la méthode semi-supervisée précédente. La principale différence est : dans le passé, semi-supervisée combinant semi-supervisée et supervisée pour réduire Coût d'étiquetage ; désormais, nous combinons principalement semi-supervisé et auto-supervisé pour injecter des connaissances dans le modèle pré-entraîné.
2. Développement d'un modèle de dialogue pré-formé

Sur la base du concept et du cadre du modèle semi-supervisé que nous avons proposé, examinons les progrès des modèles de dialogue pré-entraînés. Comment intégrer des idées semi-supervisées dans des modèles de dialogue pré-entraînés et mener des expériences et une mise en œuvre dans un scénario commercial spécifique. Comme le montre la figure ci-dessus, de nombreuses institutions ont élaboré de nombreux modèles autour de la compréhension et de la génération du dialogue, mais très peu a été fait sur les stratégies de dialogue et il n'existe pratiquement aucune recherche pertinente. Cependant, la stratégie de dialogue est très critique et importante.

Alors, qu’est-ce qu’une stratégie de conversation ? Entre la compréhension du dialogue et la génération du dialogue, il existe des stratégies de dialogue. La stratégie de dialogue consiste à décider comment répondre à la phrase suivante en fonction du résultat de la compréhension du dialogue et du statut historique.
Par exemple, deux personnes A et B, pendant la conversation, A n'arrête pas de dire, B peut continuer à répondre, euh, d'accord, c'est vrai. C’est une stratégie de dialogue. La stratégie de B signifie que j’écoute et que je comprends. Il y a aussi une stratégie. Pendant le processus d'écoute, B ne comprend pas certaines parties et a besoin de poser des questions sur un certain point. C'est aussi une stratégie qui consiste à poser des questions sur certaines parties de ce que A a dit et à demander des éclaircissements. La stratégie de dialogue est donc une étape cruciale pour garantir le bon déroulement du dialogue.
La définition de la stratégie de dialogue dans les milieux universitaires est DA (Dialog act). Comme le montre la figure ci-dessus, la définition et le nom de DA sont différents à différents moments. Bien que l'ensemble de la stratégie de dialogue ait été développée pendant de nombreuses années, elle présente des lacunes telles que comme la complexité et l'incohérence. En conséquence, il est plus difficile de l’appliquer aujourd’hui.
3. Préparation
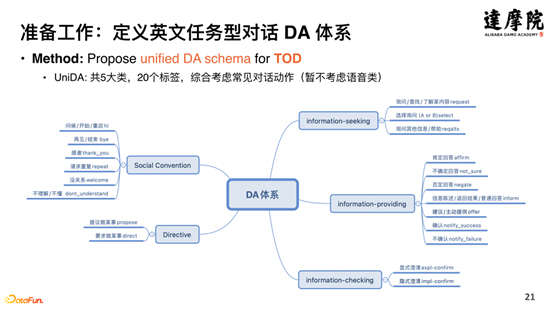
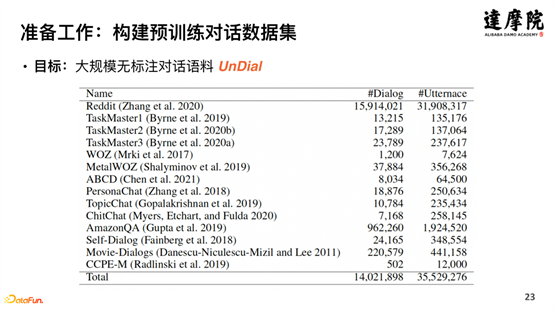
Injecter des stratégies de dialogue sous forme de connaissances dans le modèle de dialogue pré-entraîné nécessite un certain travail de préparation au niveau des données et des connaissances. Comme le montre la figure ci-dessus, les ensembles de données open source anglais sont synthétisés pour former un système DA de dialogue basé sur des tâches en anglais - UniDA, avec un total de 5 catégories, 20 balises, 1 million de données étiquetées et 35 millions de données non étiquetées, comme montré ci-dessous Montré :

Après avoir fait le tri des connaissances ci-dessus, comment définir la tâche de pré-formation ? Comme le montre la figure ci-dessus, la stratégie de dialogue de modélisation explicite est utilisée, c'est-à-dire, compte tenu de l'historique du dialogue, prédire le prochain cycle de DA côté système, c'est-à-dire en faire une tâche de classification et prédire le prochain cycle d'étiquettes DA. .
4. Conception de programmes semi-supervisés

Avec des données, des connaissances et des méthodes de modélisation explicites, un apprentissage semi-supervisé peut être effectué. Comme le montre la figure ci-dessus, les solutions d'apprentissage semi-supervisé incluent principalement les trois méthodes ci-dessus : méthode discriminative, méthode générative, méthode d'apprentissage comparative, etc.
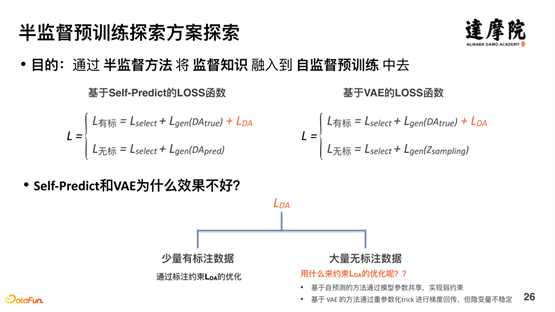
La méthode discriminante et la méthode générative étant relativement conventionnelles, les deux méthodes ci-dessus seront explorées en premier. Les résultats montrent que les deux méthodes ci-dessus ne sont pas efficaces. Comme le montre la figure ci-dessus, pour la méthode discriminante, une nouvelle fonction de perte LDA peut être ajoutée pour les données étiquetées, mais pour les données non étiquetées, la fonction de perte ne peut pas être ajoutée. Il en va de même pour les méthodes génératives. Autrement dit, les méthodes Self-Predict et VAE sont bonnes pour modéliser des données étiquetées, mais l'effet de modélisation pour les données non standardisées n'est pas bon, car la méthode basée sur l'auto-prédiction atteint des contraintes faibles grâce au partage des paramètres du modèle, et la méthode basée sur VAE La méthode effectue une rétropropagation de gradient grâce à un paramétrage important de Trick, mais les variables cachées sont instables.
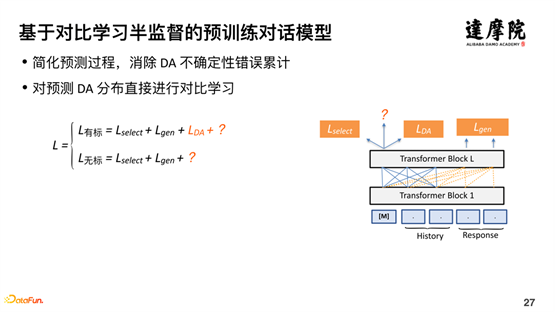
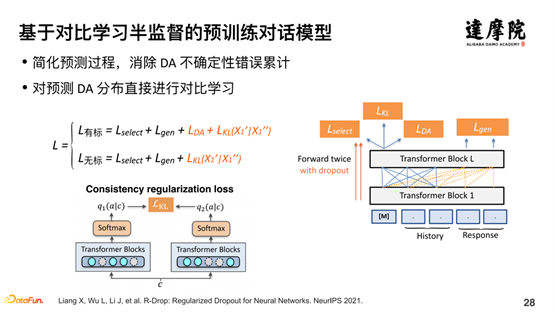
Sur la base des problèmes ci-dessus, nous espérons explorer l’apprentissage semi-supervisé à travers l’apprentissage contrastif. Pour les données étiquetées, la fonction de perte LDA peut être facilement ajoutée. Pour les données non standardisées, voici l'introduction de la fonction de perte de cohérence. Comme le montre la figure ci-dessus, nous transmettons la structure du modèle sur le côté droit de la figure deux fois pour le même échantillon. Chaque passage comporte un abandon pour le traitement aléatoire. Par conséquent, les deux exemples de codes sont incohérents, mais la différence n'est pas très grande et la distance devrait être très proche. L'idée générale est la suivante :
Sur la base d'une petite quantité de données étiquetées et d'une grande quantité de données non standardisées, une distribution de probabilité prise en charge est apprise grâce aux données étiquetées. Pour les données non étiquetées, deux apprentissages sont effectués. Chaque fois que le modèle est passé, un vecteur est généré. deux vecteurs générés sont La distance doit être très proche. Grâce à cette méthode d'apprentissage semi-supervisé d'apprentissage contrastif, le problème de la combinaison de données étiquetées et de données non étiquetées dans un apprentissage semi-supervisé est bien résolu.
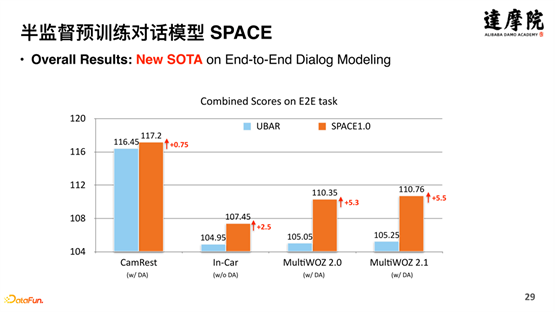
Le modèle a très bien fonctionné, obtenant des améliorations de 5,3 % et 5,5 % dans MultiWOZ2.0 et MultiWOZ2.1. Les améliorations des modèles précédents ne pouvaient apporter que des améliorations de 1 % ou 2 %, tandis que SPACE apporte des améliorations de plus de 5 %.

En le démontant et en y regardant de plus près, en prenant MultiWOZ2.0 comme exemple, l'amélioration du modèle se reflète principalement dans des aspects tels que le succès et le BLEU, car la stratégie de dialogue est cruciale pour le taux d'achèvement du dialogue réussi et la génération de réponses au dialogue BLEU. , ce qui montre que grâce à la semi-supervision, le modèle a très bien appris ce genre de connaissances.
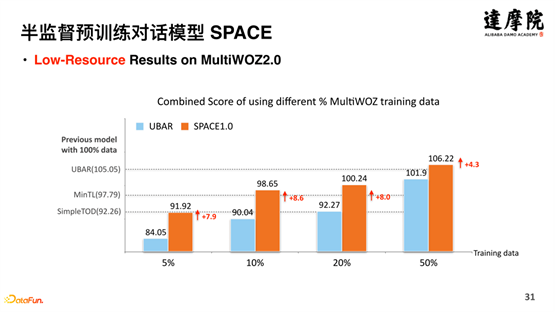
En plus de tester la totalité des données, il a également testé une petite quantité de données. Comme le montre la figure ci-dessus, des expériences comparatives ont été menées sur des quantités de données de 5 %, 10 %, 20 %, 50 %, etc. On a constaté que le modèle SPACE fonctionne bien sur différentes quantités de données et a également apporté des améliorations significatives.
Ce qui précède explique principalement la méthode d'injection de connaissances que nous avons proposée, la formation semi-supervisée du modèle SPACE, qui améliore considérablement l'effet du modèle de pré-formation sur la pré-formation.
--
04 Proton : Exploration de l'utilisation des connaissances dans des modèles pré-entraînés
Ensuite, l'utilisation des connaissances dans le modèle pré-entraîné est expliquée. Étant donné que le modèle de pré-formation est formé avec des données massives et contient des connaissances massives, si les connaissances peuvent être utilisées, elles apporteront sans aucun doute une grande aide et une amélioration aux tâches de PNL. Nous proposons une méthode - Sondage tuning.
1. Tâches TableQA

Pour vérifier le rôle des connaissances, des tâches à forte intensité de connaissances sont nécessaires . Comme le montre la figure ci-dessus, la tâche TableQA est très appropriée. La tâche principale de TableQA est de convertir le langage texte en SQL.
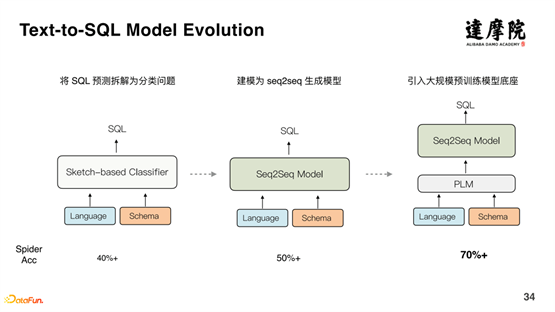
La figure ci-dessus montre le processus de développement de Text-to-SQL. Initialement, la prédiction SQL était décomposée en un problème de classification, et la précision était d'environ 40 % ; plus tard, Seq2Seq a été utilisé pour générer un modèle, et la précision a été augmentée à plus de 50 % ; en outre, un pré-entraînement à grande échelle Le modèle a été introduit et la précision a été augmentée à 70 % ci-dessus. Par conséquent, on peut constater que le modèle de dialogue pré-entraîné améliore considérablement l’ensemble du système de dialogue. Mais certains problèmes subsistent.

En prenant l'ensemble de données Spider comme exemple, tout en marquant l'ensemble de données Spider, ils ont vu l'ensemble de données. Par conséquent, lorsqu'ils ont écrit l'ensemble de données, les mots qu'ils ont utilisés étaient tous des mots qui existaient dans le texte original. Il manque également des changements et des connaissances du monde, etc. Par exemple, dans le domaine de l'achat d'une maison, il existe un modèle de canapé appelé en forme de L, qui est un terme officiel. Cependant, pour les utilisateurs ou les consommateurs, ils ne savent pas ce qu'est un canapé en forme de L. Ils ne connaissent que « chaise ». . La « chaise chair » est le nom commun du canapé en forme de L. Par conséquent, quelqu'un a transformé les synonymes de l'ensemble de données Spider et a construit un nouvel ensemble de données Spider-Syn, mais les performances du modèle d'origine sur le nouvel ensemble de données ont chuté de manière significative.
Outre le problème des synonymes, comme mentionné sur le côté droit de l'image ci-dessus, "... dans les pays africains, qui sont des républiques ?" Autrement dit, que sont les républiques en Afrique ? Républiques, le mot signifie « république », et pour ce sens, le modèle ne peut pas apprendre des données et nécessite une connaissance du monde.

Généralement, il existe deux manières d'utiliser les modèles pré-entraînés : le réglage fin et le réglage rapide. Pour le réglage fin, le modèle pré-entraîné est directement utilisé comme représentation des tâches en aval. La plupart des tâches peuvent tirer parti des capacités du modèle pré-entraîné, mais il existe un écart important entre le modèle pré-entraîné et le modèle en aval. . En termes simples, le modèle pré-entraîné possède beaucoup de connaissances, mais les tâches en aval ne peuvent obtenir qu'un très petit débouché de sortie et ne peuvent pas obtenir pleinement l'expression des connaissances. Les modèles Prompt Tuning, qui améliorent les performances en modifiant la méthode de prédiction, sont récemment apparus dans les tâches de classification, en particulier dans les situations de petits échantillons. Mais qu’en est-il des tâches plus complexes ? Parsin, par exemple, ne fonctionne pas très bien. En résumé, une grande quantité de connaissances a été acquise en formant un vaste modèle de pré-formation, mais elles ne peuvent pas être correctement utilisées dans les tâches en aval.
2. Méthode de réglage du sondage
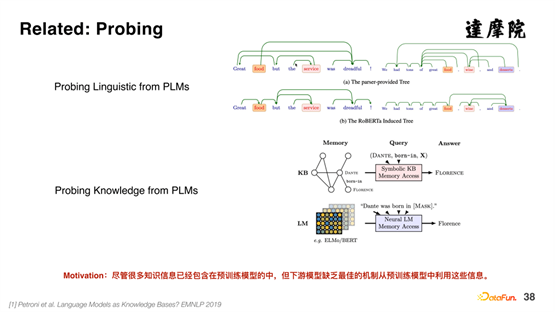
Il existe également de nombreuses recherches autour de l’utilisation des connaissances issues de grands modèles pré-entraînés, généralement appelées sondages. Le sondage peut explorer les structures syntaxiques, les structures de dépendance, etc. à partir de modèles pré-entraînés, et peut également explorer des connaissances telles que les triplets à partir de modèles pré-entraînés. Cependant, il y a actuellement relativement peu de travaux sur la façon de représenter explicitement les connaissances dans le modèle pré-entraîné et de les combiner avec des tâches en aval. Nous proposons une nouvelle méthode Finetune à cet égard - la méthode Probing Tuning.
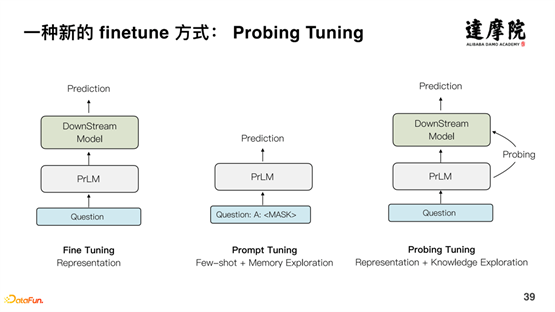
Comme le montre la figure ci-dessus, la méthode Prompt Tuning est basée sur la formation de modèles, qui affine essentiellement le modèle en ajoutant une petite quantité de données via l'expression de la mémoire. Dans la méthode Probing Tuning que nous avons proposée, le problème d'origine est représenté par un vecteur dense à travers le modèle pré-entraîné, et grâce au Probing, l'expression structurelle des connaissances est obtenue et entrée dans la représentation vectorielle dense, ce qui améliore les tâches en aval.
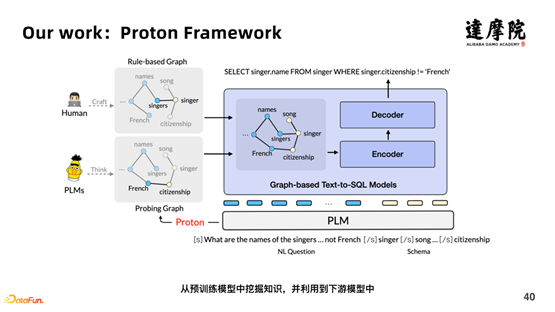
Comme le montre la figure ci-dessus, nous avons proposé un framework - Proton Framework . Tout d'abord, les données entrées dans le modèle de pré-formation contiennent les questions originales et les phrases correspondant au tableau ; d'autre part, elles contiennent également la connaissance des règles définies par les humains, qui n'ont pas de connaissances généralisables ; et, grâce à Proton, les connaissances s'apprennent Expression et généralisation.

Le principe de fonctionnement spécifique de Probing est expliqué avec l'exemple ci-dessus .
La question est : "D'où vient le plus jeune enseignant ?", et les données du tableau sont "SELECT hometown FROM professeur ORDER BY age ASC LIMIT 1". La phrase originale extrait les informations nominales dans les données du tableau, "enseignant, enseignant.âge , professeur.ville natale ", combinés en un tout : "[CLS] D'où vient le plus jeune enseignant ? [SEP] professeur, professeur.âge, professeur.ville natale". Ensuite, MASQUEZ au hasard un mot, tel que "où", puis calculez la " La distance entre « professeur.ville natale » et « professeur.ville natale » du vecteur de phrase d'origine. Si la distance est plus grande, cela signifie que « où » et « professeur.ville natale » sont plus similaires, c'est-à-dire des connaissances pertinentes a été appris. Comme le montre la matrice de corrélation dans la figure ci-dessus, " La corrélation entre « enseignant.âge » et « le plus jeune » est de 0,83, ce qui est très élevé, ce qui indique que les deux ont une très forte corrélation. Ensuite, le graphique dans Le proton et le poids des bords peuvent être construits.
Ce qui précède représente l'ensemble du processus de sondage, qui combine les connaissances construites manuellement et les connaissances apprises par Proton dans le modèle de pré-formation pour améliorer les performances des tâches en aval.
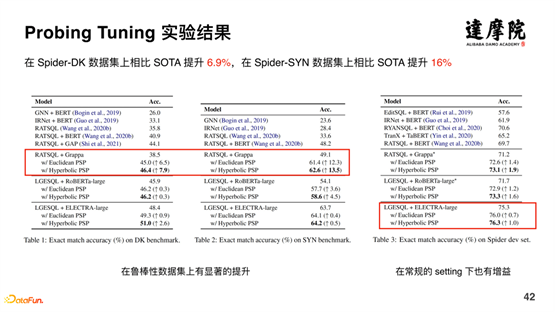
La méthode basée sur Probing Tuning s'est améliorée de 6,9 % par rapport à SOTA sur l'ensemble de données Spider-DK, et s'est améliorée de 16 % par rapport à SOTA sur l'ensemble de données Spider-SYN. L'amélioration de l'effet est très évidente.
Dans l’ensemble, en détectant les connaissances acquises par le modèle de pré-formation et en les appliquant explicitement au modèle en aval de manière structurée, nous pouvons apporter des améliorations significatives à des tâches spécifiques en aval.
3. Perspectives de travaux de suivi

La technologie de sondage peut nous amener à l'étape suivante de l'exploration, à savoir comment obtenir explicitement les connaissances dans le modèle pré-entraîné. Dans ce domaine, AlphaZero a effectué des explorations connexes. Comme le montre le côté gauche de l'image ci-dessus, les côtés gauche et droit représentent respectivement l'espace vectoriel automatiquement appris par l'humain et le modèle. Le modèle a appris certains enregistrements d'échecs que les humains ont jamais connu, ce qui indique que le modèle peut apprendre des choses que les humains ne connaissent pas.
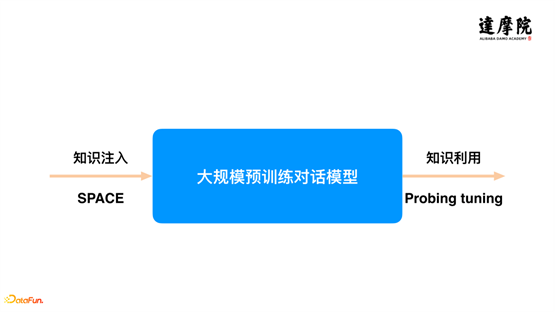
Aujourd'hui, nous avons d'abord parlé de l'importance des modèles de dialogue pré-entraînés pour l'ensemble du système de dialogue ; deuxièmement, de l'importance des connaissances dans le système de dialogue. Sur la base des deux points ci-dessus, nous espérons combiner des connaissances et des modèles de dialogue pré-entraînés, qui sont spécifiquement divisés en deux tâches :
Premièrement, comment injecter des connaissances dans le modèle de dialogue pré-entraîné, nous proposons un modèle de pré-formation semi-supervisé - SPACE.
Deuxièmement, comment extraire et utiliser explicitement les connaissances dans le modèle de dialogue pré-entraîné, nous proposons un modèle Proton.
--
05
Séance de questions-réponses
Q1 : Les tâches de supervision du modèle de pré-formation semi-supervisé doivent-elles être cohérentes avec les tâches en aval ? Par exemple, certaines tâches de classification d'intention dans des modèles pré-entraînés ?
A1 : La pré-formation semi-supervisée que nous effectuons actuellement est toujours une pré-formation pour les tâches en aval. C'est-à-dire un apprentissage semi-supervisé pour les tâches en aval. Bien entendu, nous explorons également désormais la formation aux tâches en aval des tâches multiples et explorons si les tâches multiples peuvent améliorer les effets des tâches associées.
Q2 : Unified DA considère-t-il les déclarations dénuées de sens, etc. ?
A2 : Oui, il y a des phrases dans la classification que je ne comprends pas/ne comprends pas.
Q3 : Quelle est la différence entre Acte et Intention ?
A3 : L'intention est une chose concrète, liée à une tâche spécifique. Par exemple, si vous souhaitez collecter des économies de bureau, dans ce scénario, vous pouvez définir 5 intentions ; dans le scénario d'achat de billets d'avion, vous pouvez définir 10 intentions. Il n’y a essentiellement aucune relation entre les intentions de ces deux scénarios. L'acte transcende les scénarios spécifiques, comme les scénarios de prévoyance ou de réservation de billets d'avion. Des actes communs peuvent être définis, comme la clarification explicite, la clarification implicite, etc., qui n'ont rien à voir avec des scénarios spécifiques. Act et Intent sont tous deux des représentations de la sémantique. Intent est une représentation à un niveau concret et Act est une représentation à un niveau abstrait.
Q4 : Les ensembles de données sont tous en anglais. Envisagerez-vous une exploration en chinois à l'avenir ?
A4 : Notre équipe est une équipe qui accorde la même attention à la recherche et aux affaires. Nous travaillons simultanément sur le chinois et l'anglais. Aujourd'hui, nous partageons principalement le modèle anglais, et nous avons déjà terminé le modèle chinois et l'avons dans Alibaba Cloud Intelligence. Il a été entièrement implémenté dans les produits de service client et est devenu la base du système de dialogue. En prenant comme exemple la classification des intentions, la quantité d'annotations de données d'échantillons de formation basées sur SPACE a été réduite d'environ 70 %. Aujourd'hui, nous partageons simplement nos travaux les plus anciens et les plus classiques, et nous partagerons à l'avenir des travaux liés au chinois.
Q5 : Comment le modèle de bout en bout est-il combiné avec le NLG dans SPACE ?
A5 : Le modèle de bout en bout est divisé en trois parties : compréhension, stratégie et génération. Pour la tâche de génération, il s'agit d'une distribution de probabilité basée sur la compréhension et la stratégie. Autrement dit, si la prédiction de l'acte précédent est exacte, la tâche de génération suivante sera plus précise.