Cressy du temple Aofei
Qubit | Compte public QbitAI
La famille multimodale des grands modèles s'agrandit !
Non seulement plusieurs images et textes peuvent être combinés et analysés, mais la relation spatio-temporelle dans la vidéo peut également être traitée.
Ce modèle gratuit et open source est en tête des listes MMbench et MME, et reste actuellement dans les trois premiers classements flottants.
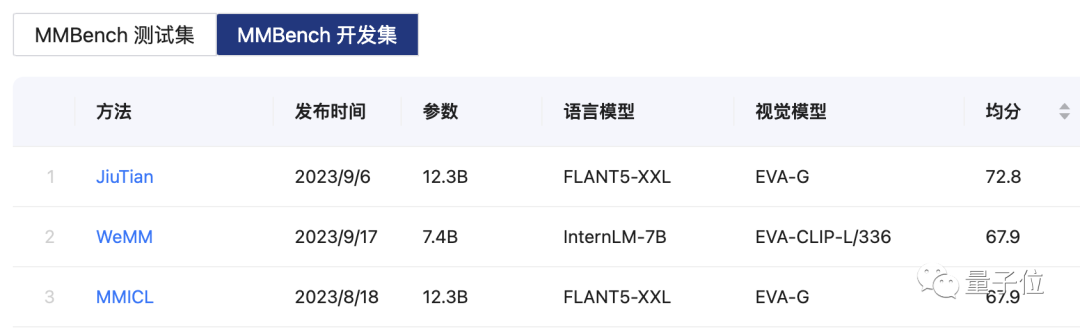
△MMBench list, MMBench est un système complet d'évaluation des capacités multimodes basé sur ChatGPT lancé conjointement par le laboratoire d'IA de Shanghai et l'Université technologique de Nanyang.
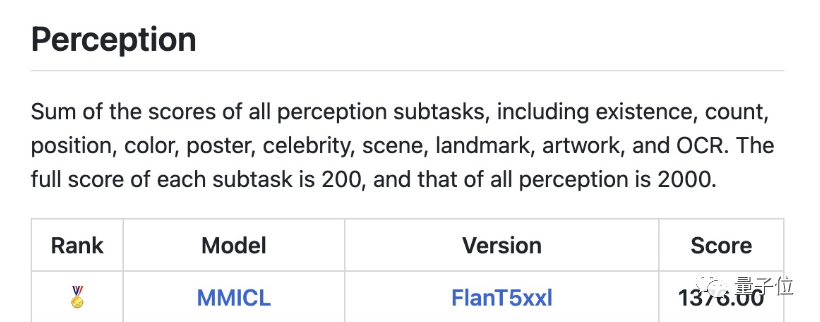
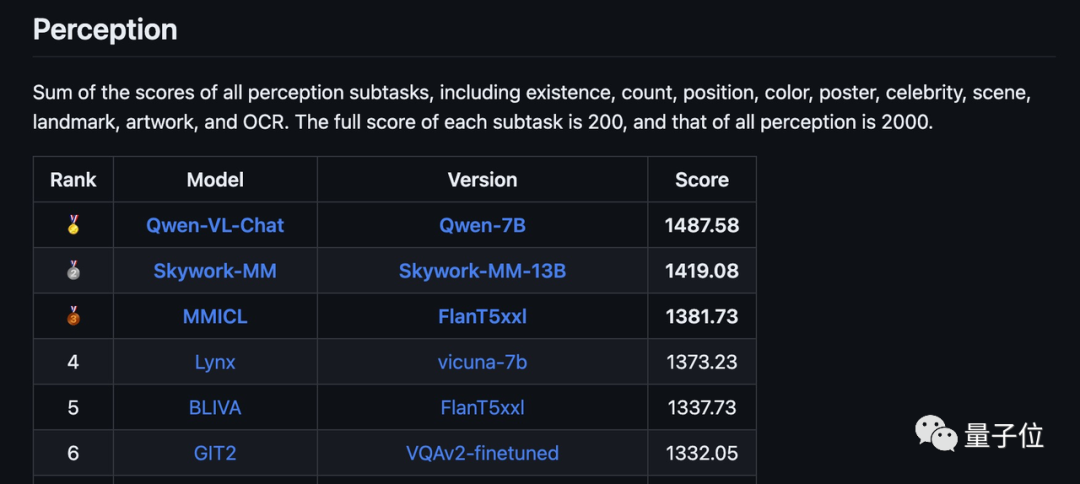
△MME list, MME est une évaluation multimodale de grands modèles de langage menée par Tencent Youtu Lab et l'Université de Xiamen
Ce grand modèle multimodal s'appelle MMICL et a été lancé conjointement par l'Université Jiaotong de Pékin, l'Université de Pékin, l'UCLA, la Zuzhi Multi-Mode Company et d'autres institutions.
MMICL propose deux versions basées sur différents LLM, basées sur deux modèles de base : Vicuna et FlanT5XL.
Les deux versions sont open source, parmi lesquelles la version FlanT5XL peut être utilisée à des fins commerciales, tandis que la version Vicuna ne peut être utilisée qu'à des fins de recherche scientifique.
Dans le test multitâche de MME, la version FlanT5XL de MMICL maintient sa position de leader depuis plusieurs semaines.
Parmi eux, l'aspect cognitif a obtenu un score total de 428,93 (score total de 800), se classant au premier rang, dépassant largement les autres modèles.
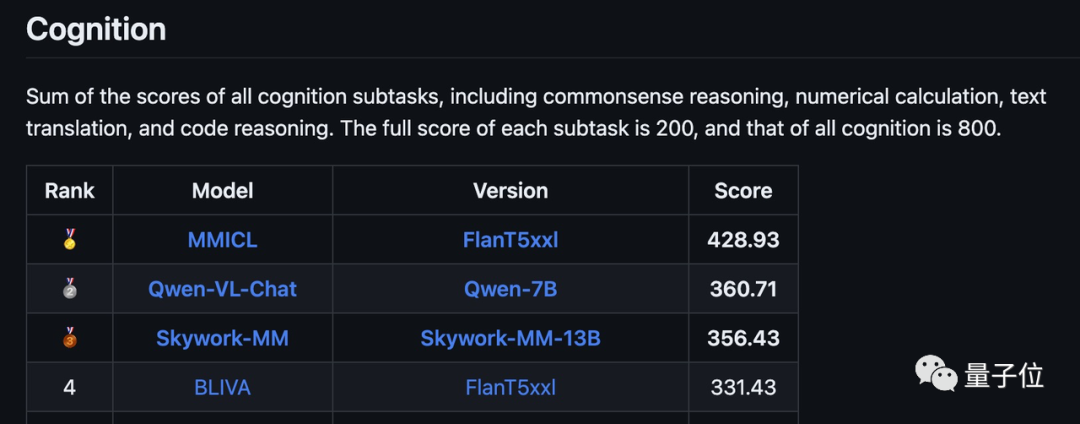
Le score total en termes de perception est de 1 381,78 (sur 2000), se classant deuxième derrière le modèle Qianwen-7B d’Alibaba et le modèle Tiangong de Kunlun Wanwei dans la dernière version de la liste.
En termes de configuration requise, la déclaration officielle est que six A40 sont nécessaires pendant la phase de formation et que la phase d'inférence peut s'exécuter sur un seul A40.
Seulement 0,5 million de données construites à partir de l’ensemble de données open source sont nécessaires pour terminer la deuxième phase de formation, qui ne prend que des dizaines d’heures.
Alors, quelles sont les caractéristiques de ce grand modèle multimodal ?
Je peux regarder des vidéos et « apprendre et vendre maintenant »
MMICL prend en charge les invites sous forme de texte et d'images entrecoupées, et son utilisation est aussi naturelle que le chat WeChat.
Introduisez les deux images dans MMICL de manière normale et vous pourrez analyser leurs similitudes et leurs différences.

En plus de ses fortes capacités d'analyse d'images, MMICL sait également « apprendre maintenant et vendre maintenant ».
Par exemple, nous avons donné à MMICL une image d'un cheval de style pixel dans "Minecraft".
Étant donné que les données d'entraînement sont toutes des scènes du monde réel, MMICL ne reconnaît pas ce style de pixel trop abstrait.

Mais tant que nous laissons MMICL apprendre quelques exemples, il peut rapidement effectuer un raisonnement analogique .
Dans l'image ci-dessous, MMICL a appris trois scénarios : des chevaux, des ânes et rien, puis a jugé correctement le cheval pixel après avoir modifié l'arrière-plan.

En plus des images, les vidéos dynamiques ne posent pas non plus de problème à MMICL : il comprend non seulement le contenu de chaque image, mais analyse également avec précision la relation spatio-temporelle.
Jetons un coup d'œil à cette bataille de football entre le Brésil et l'Argentine. MMICL a analysé avec précision les actions des deux équipes.

Vous pouvez également demander à MMICL les détails de la vidéo, comme la manière dont les joueurs brésiliens ont bloqué les joueurs argentins.

En plus de saisir avec précision la relation spatio-temporelle dans la vidéo, MMICL prend également en charge l'entrée de flux vidéo en temps réel.
Nous pouvons voir que la personne sur l'écran de surveillance est en train de tomber. MMICL a détecté cette anomalie et a émis une invite demandant si de l'aide est nécessaire.

Si nous comparons les cinq premiers en matière de perception et de cognition sur la liste MME sur une seule image, nous pouvons voir que les performances de MMICL ont obtenu de bons résultats dans tous les aspects.
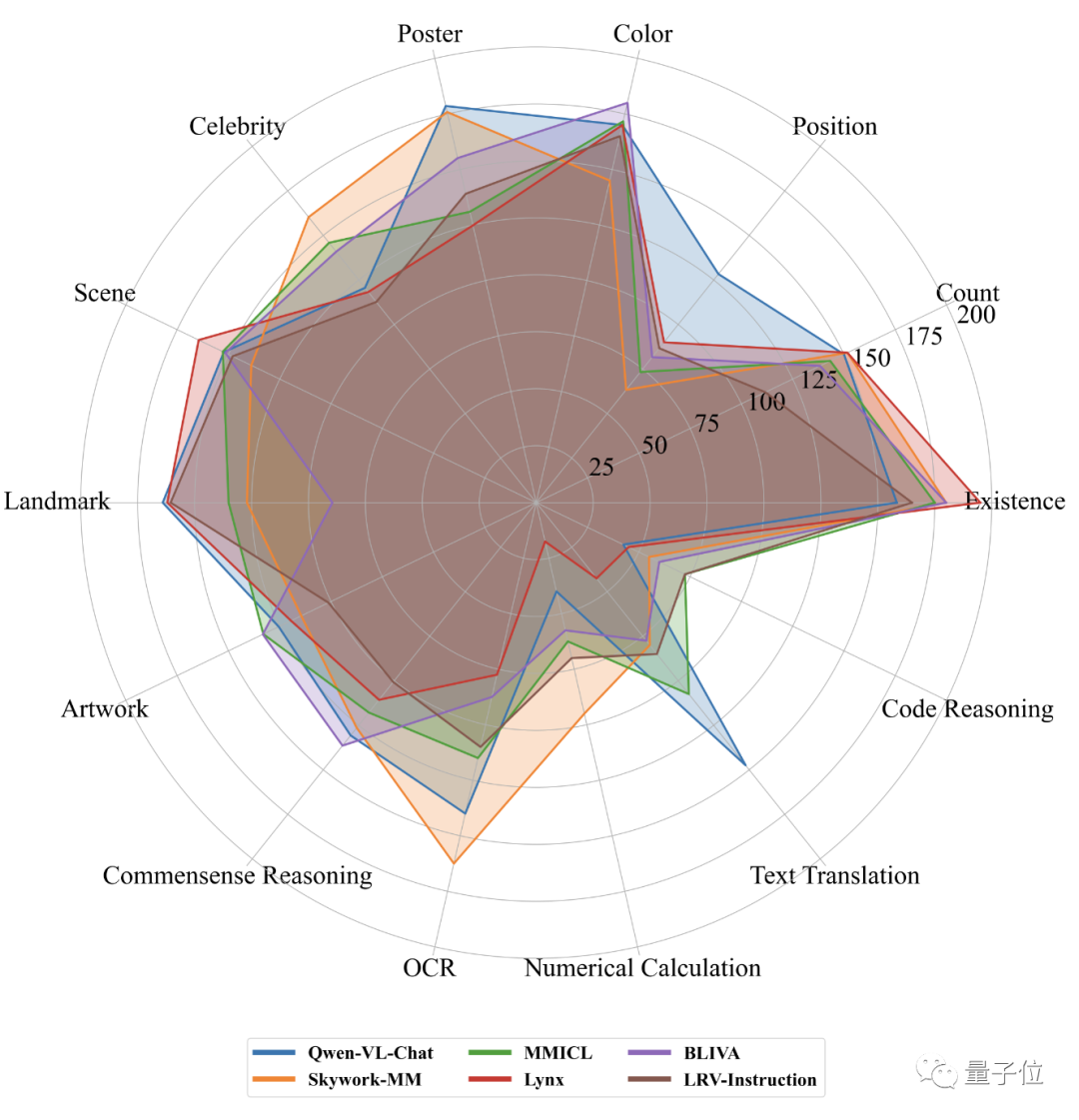
Alors, comment MMICL procède-t-il et quels sont les détails techniques qui se cachent derrière ?
La formation se déroule en deux phases
MMICL vise à résoudre les problèmes rencontrés par les modèles de langage visuel dans la compréhension des entrées multimodales complexes avec plusieurs images.
MMICL utilise le modèle Flan-T5 XXL comme épine dorsale. La structure et le processus de l'ensemble du modèle sont présentés dans la figure ci-dessous :
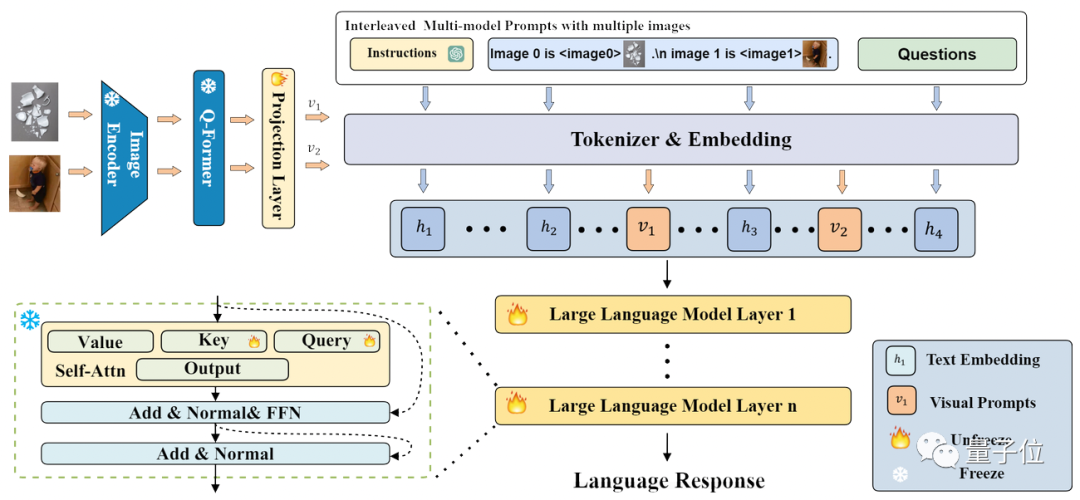
MMICL utilise une structure similaire à BLIP2, mais peut accepter des graphiques entrelacés et la saisie de texte.
MMICL traite les images et les textes de la même manière, et fusionne les caractéristiques de l'image et du texte traitées en une forme d'image et de texte entrelacée en fonction du format d'entrée et les entre dans le modèle de langage à des fins de formation et d'inférence.
Semblable à InstructBLIP, le processus de développement de MMICL consiste à geler le LLM, à former le Q-former et à l'affiner sur un ensemble de données spécifique.
Le processus de formation et la structure des données de MMICL sont présentés dans la figure ci-dessous :
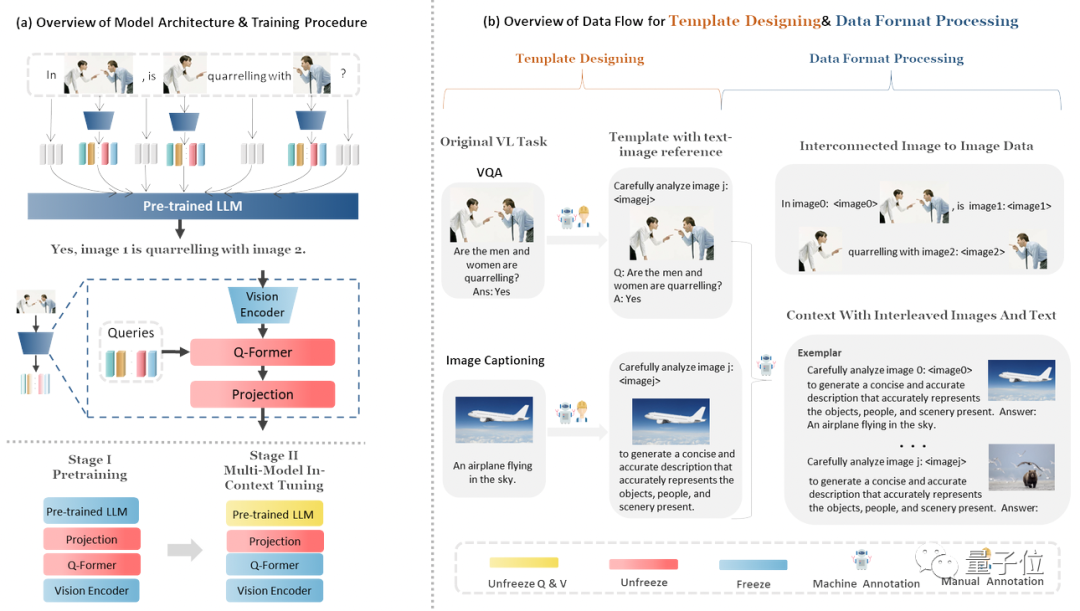
Concrètement, la formation du MMICL se divise en deux étapes :
Dans la phase de pré-formation, l'ensemble de données LAION-400M (voir LLaVA) a été utilisé
Réglage multimodal en contexte, en utilisant son propre ensemble de données MIC (Multi-Model In-Context Learning)

L'ensemble de données MIC est construit à partir d'ensembles de données publics. La figure ci-dessus montre le contenu contenu dans l'ensemble de données MIC. L'ensemble de données MIC présente également les caractéristiques suivantes :
Le premier est la référence explicite établie entre les images et les textes. MIC insère des déclarations d'images dans les données entrelacées des images et des textes, utilise des jetons de proxy d'image pour proxy différentes images et utilise le langage naturel pour créer des images. Relations référentielles entre les textes.

Le second est un ensemble de données multi-images interconnectées dans l’espace, le temps ou la logique, garantissant que le modèle MMICL peut avoir une compréhension plus précise de la relation entre les images.

La troisième caractéristique est l'exemple d'ensemble de données, qui est similaire au processus « d'apprentissage sur site » de MMICL. Il utilise l'apprentissage contextuel multimodal pour améliorer la compréhension de MMICL de la saisie complexe d'images et de texte entrecoupée d'images et de texte.

MMICL obtient de meilleurs résultats sur plusieurs ensembles de données de test que BLIP2 et InstructionBLIP, qui utilisent également FlanT5XXL.
Surtout pour les tâches impliquant plusieurs images, MMICL a montré une grande amélioration pour une saisie d'images et de texte aussi complexe.
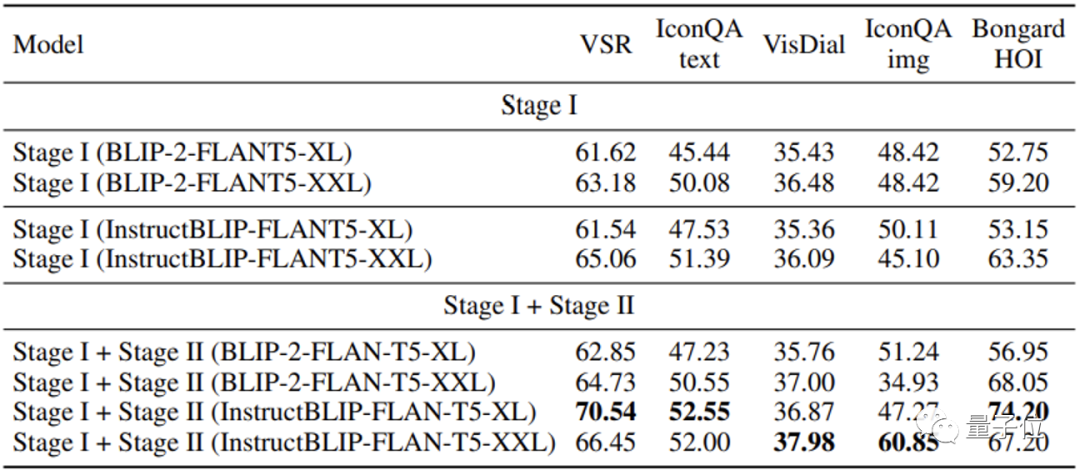
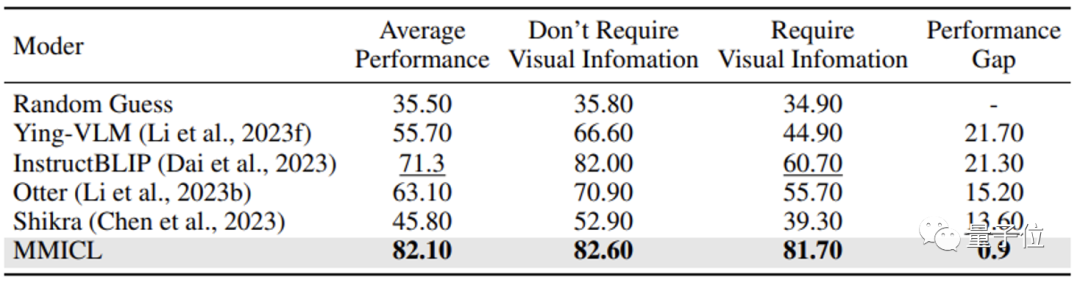
L'équipe de recherche estime que MMICL résout le problème du biais linguistique qui existe souvent dans les modèles de langage visuel et constitue l'une des raisons de ses excellents résultats.
La plupart des modèles de langage visuel ignorent le contenu visuel lorsqu’ils sont confrontés au contenu contextuel de grandes quantités de texte, ce qui constitue un défaut fatal lorsqu’il s’agit de répondre à des questions nécessitant des informations visuelles.
Grâce à l’approche de l’équipe de recherche, MMICL atténue avec succès ce biais linguistique dans les modèles de langage visuel.
Les lecteurs intéressés par ce grand modèle multimodal peuvent consulter la page ou l'article GitHub pour plus de détails.
Page GitHub :
https://github.com/HaozheZhao/MIC
Adresse papier :
https://arxiv.org/abs/2309.07915
Démo en ligne :
http://www.testmmicl.work/